Что такое CSV и зачем он нужен, если есть Excel
Простой способ хранить и передавать таблицы.


CSV — это текстовый формат для хранения табличных данных. Аббревиатура расшифровывается как comma-separated values — то есть «значения, разделённые запятыми». Каждая строка CSV-файла соответствует строке таблицы, а значения внутри могут разделяться запятыми или другими символами. По сути, это обычные таблицы, только записанные в виде текста.
Такой формат применяется повсеместно в разных сферах: аналитики используют CSV для анализа отчётов, интернет-магазины — для выгрузки каталогов и обновления цен, финансисты — для хранения транзакций, разработчики — для миграции данных между системами, а специалисты по машинному обучению — для организации и предобработки датасетов.
Если кто-то пришлёт вам CSV-файл, после чтения этой статьи вы будете знать, что с ним делать. Мы разберём, как его открыть, поправить и создать с нуля. А если вы изучаете Python и работу с данными, то для вас будет отдельный раздел, где мы используем для обработки CSV библиотеку Pandas.
Содержание
- Синтаксис и правила форматирования CSV
- Как создать и сохранить CSV-файл
- Работа с CSV в Python с помощью Pandas
Как и чем открыть CSV-файл
CSV-файлы можно открыть в большинстве популярных программ для работы с таблицами. Но прежде чем что-то открывать, давайте посмотрим, как выглядит такой файл. Для примера запишем таблицу умножения от 1 до 5:
,1,2,3,4,5
1,1,2,3,4,5
2,2,4,6,8,10
3,3,6,9,12,15
4,4,8,12,16,20
5,5,10,15,20,25А вот та же самая информация в виде обычной таблицы:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 4 | 5 |
| 2 | 3 | 4 | 6 | 8 | 10 |
| 3 | 3 | 6 | 9 | 12 | 15 |
| 4 | 4 | 8 | 12 | 16 | 20 |
| 5 | 5 | 10 | 15 | 20 | 25 |
Обратите внимание: первая ячейка таблицы пустая, поэтому в CSV-файле перед первой запятой нет значения. Подробнее об этом мы поговорим в следующем разделе, когда будем рассматривать синтаксис формата.
Перейдём к программам. CSV-файлы чаще всего открывают на компьютере или ноутбуке, поскольку на небольших экранах неудобно просматривать и редактировать таблицы. Поэтому для большинства задач вам будет достаточно использовать Microsoft Excel, LibreOffice Calc или «Google Таблицы».
Microsoft Excel
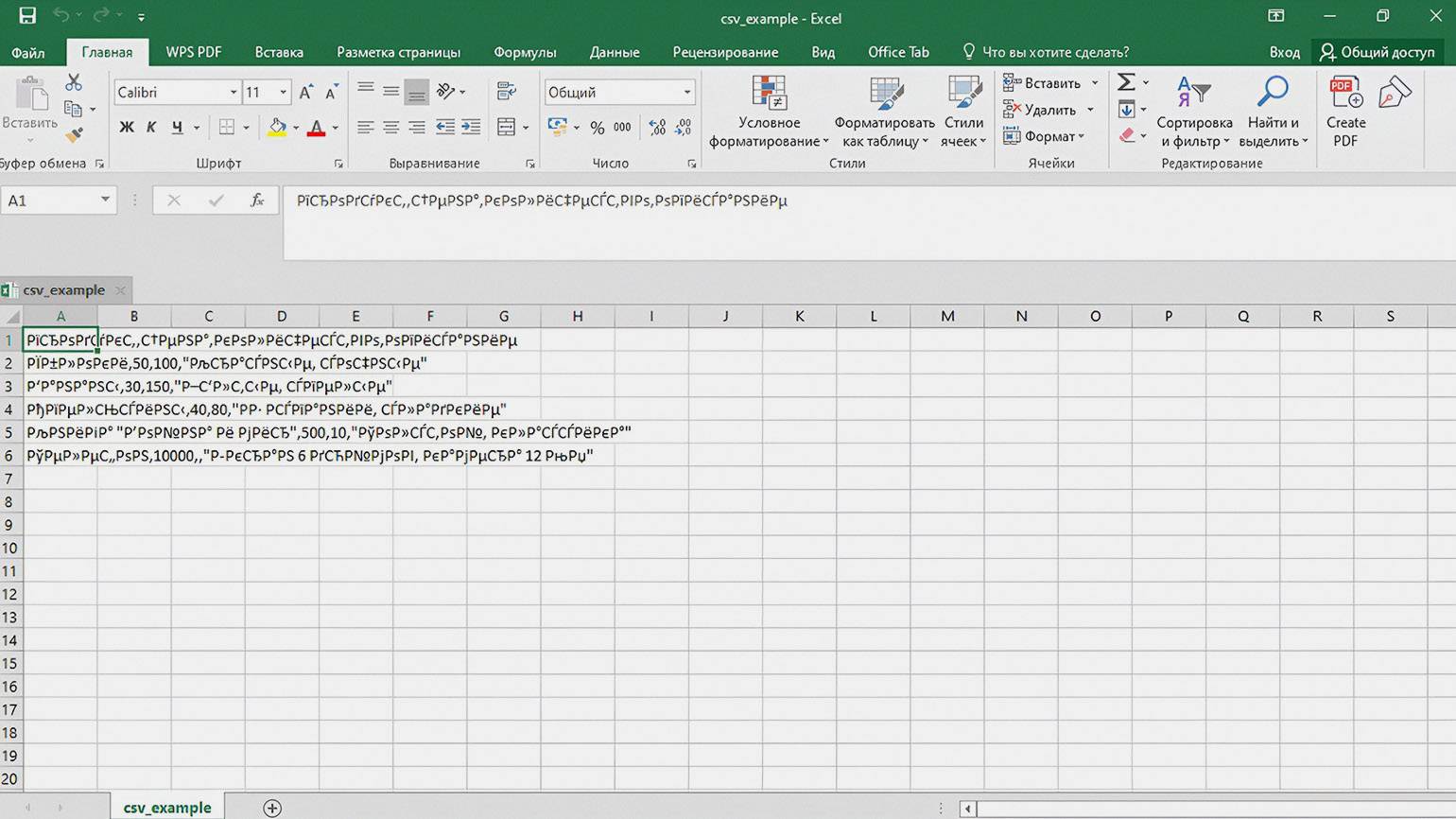
Microsoft Excel — пожалуй, самая известная программа для работы с таблицами. CSV-файлы в ней открываются очень просто: достаточно дважды щёлкнуть по файлу, и данные отобразятся в виде таблицы. Это удобно для быстрого просмотра списков товаров, клиентов или финансовых отчётов.
Однако в некоторых случаях Excel может неправильно отобразить данные:
- длинные числа он иногда превращает в даты — вместо «010125» может появиться «1 января 2025 года»;
- числа с ведущими нулями теряют их — например, «00123» превращается в «123»;
- а если кодировка файла не совпадает с настройками программы, вместо текста на русском вы увидите непонятные символы «Ð¢Ð¾Ð²Ð°Ñ€Ñ».
Если в Excel возникают такие ошибки и исправить их через настройки не получается, попробуйте открыть файл в LibreOffice Calc или в «Google Таблицах» — эти программы лучше справляются с разделителями и кодировками.
Скриншот: MS Excel / Skillbox Media
LibreOffice Calc
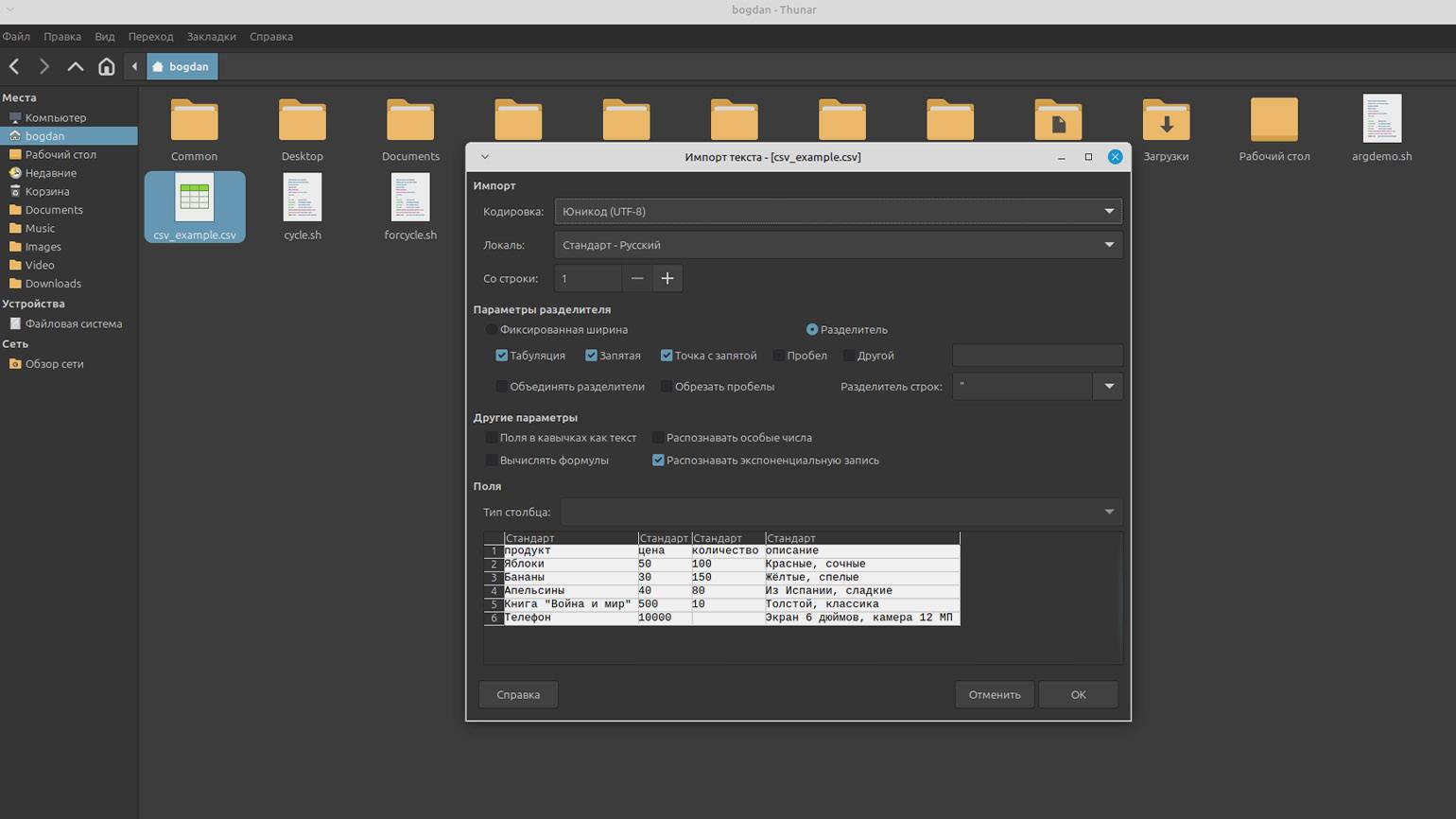
LibreOffice Calc — бесплатная альтернатива Excel. Чтобы открыть файл, выберите в меню «Файл» пункт «Открыть», и программа предложит указать разделитель вместе с кодировкой. Это делает Calc очень гибким редактором: например, если в вашем CSV-файле вместо запятых используются табуляции, вы сможете задать это при импорте и корректно отобразить нужные данные.
Скриншот: LibreOffice Calc / Skillbox Media
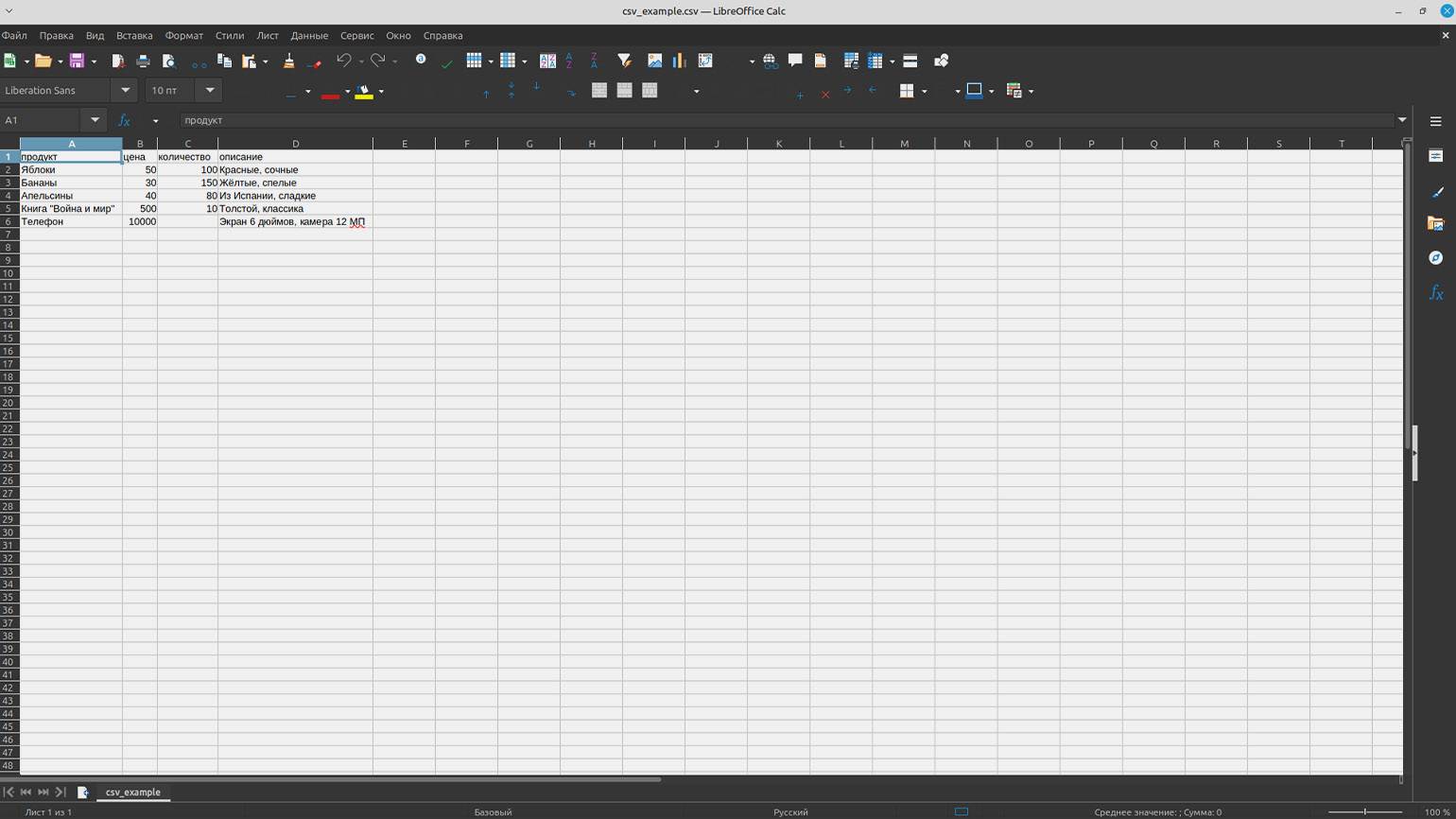
Другой пример: если у вас есть файл с данными Иванов;Петр;35;Москва, где разделителем выступает точка с запятой, LibreOffice Calc позволит указать этот символ как разделитель полей и корректно разнести данные по ячейкам. При правильных настройках вы получите таблицу с четырьмя столбцами вместо одной ячейки, в которой записана вся строка целиком.
Скриншот: LibreOffice Calc / Skillbox Media
«Google Таблицы»
«Google Таблицы» — бесплатный онлайн-аналог Excel. Сервис хранит ваши CSV-файлы в облаке, автоматически сохраняет изменения и ведёт историю версий, чтобы в случае чего вы могли откатить файл к предыдущему состоянию.
Но главное преимущество «Google Таблиц» в том, что вы можете поделиться ссылкой на документ с коллегами для совместной работы. Например, при подготовке отчёта о продажах вся команда сможет просматривать и редактировать данные в режиме реального времени без пересылки файлов друг другу.
Чтобы начать, откройте меню «Файл» и выберите пункт «Импортировать»:
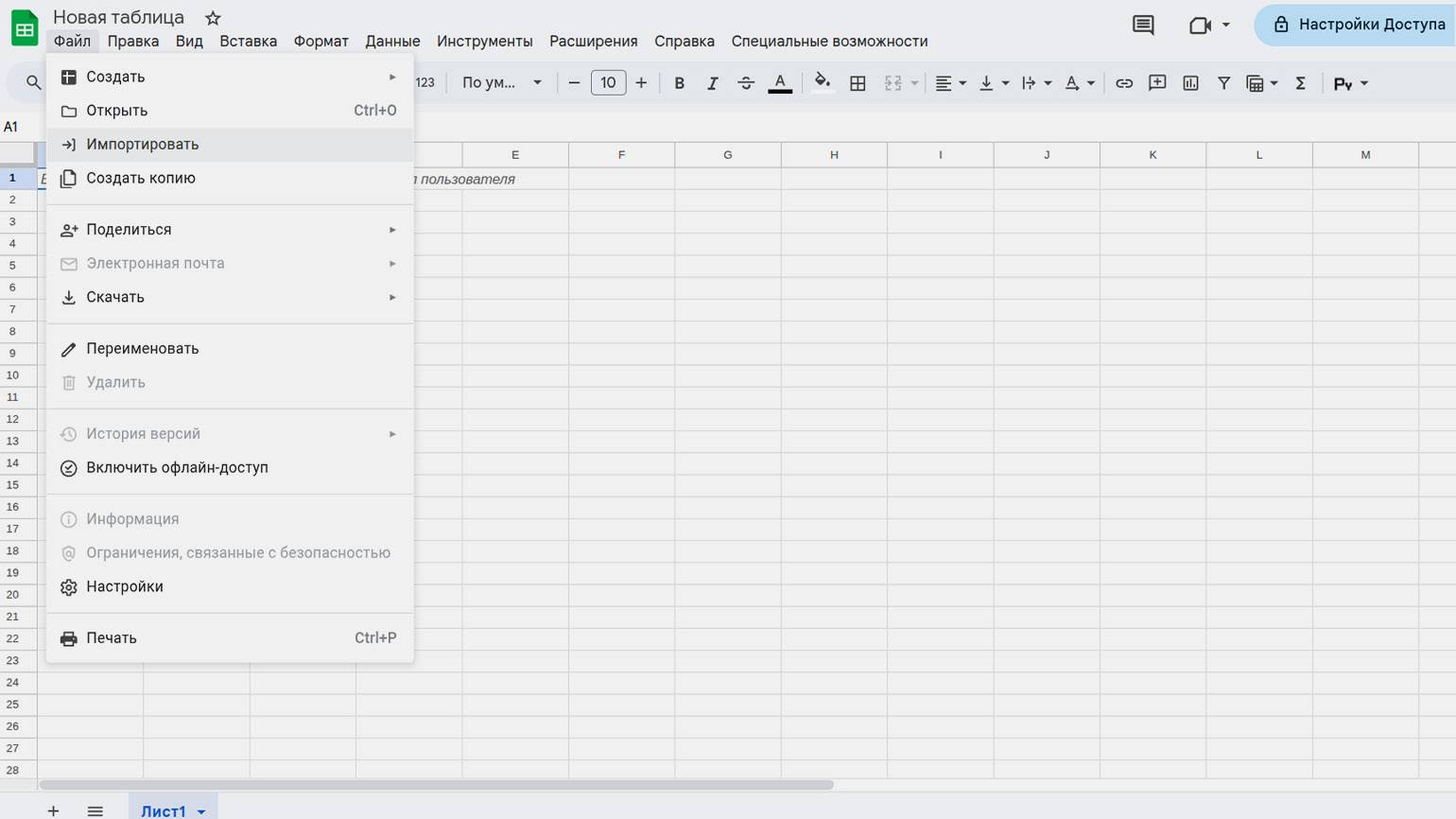
Затем загрузите CSV-файл с вашего компьютера:
Нажмите «Импортировать данные» и подождите, пока файл откроется:
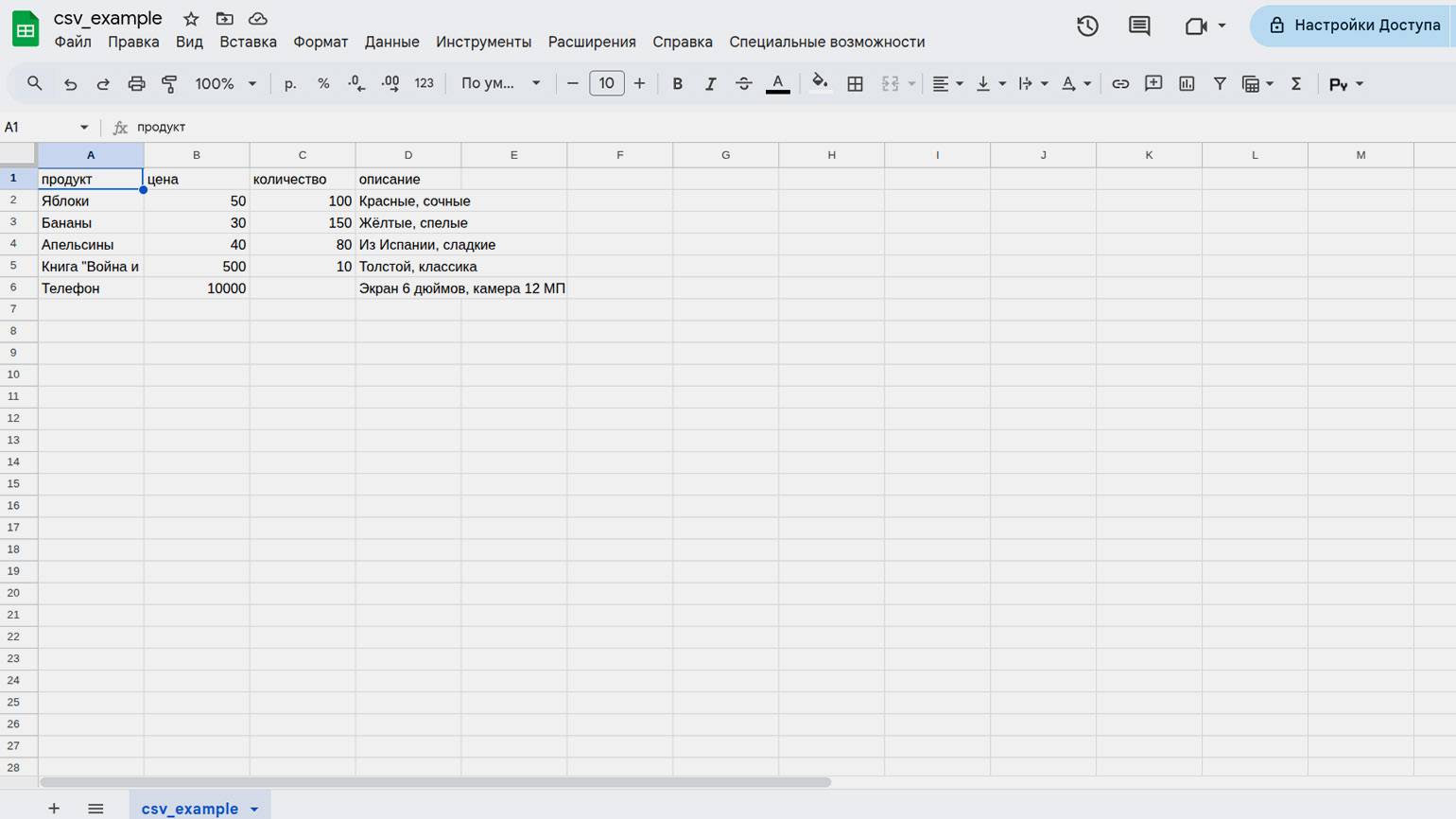
Пример отображения простого CSV-файла в «Google Таблицах»:
Синтаксис и правила форматирования CSV
В отличие от проприетарных форматов наподобие Excel, где вместе с данными сохраняются формулы, стили оформления и макросы, CSV содержит только текст и разделители. Благодаря этому такие файлы остаются компактными и не зависят от конкретных программ. Однако, чтобы информация отображалась корректно, данные необходимо записывать по определённым правилам.
Основной синтаксис
CSV хранит данные в виде текста со строками, столбцами и заголовками:
- Строки — это горизонтальные элементы таблицы, каждый из которых представляет отдельную запись данных. В файле они располагаются на отдельных строках. Например, запись Анна,25,Москва содержит набор данных об одном человеке — его имя, возраст и город.
- Столбцы — значения внутри строки, которые разделены запятыми или другими символами. Например, в записи Иван,30,Санкт-Петербург три столбца: имя «Иван», возраст «30» и город «Санкт-Петербург».
- Заголовки — первая строка файла, где обычно указываются названия столбцов. Например, строка имя,возраст,город задаёт три заголовка для соответствующих столбцов данных.
Соберём наш CSV-файл с тремя столбцами, заголовком и двумя строками:
имя,возраст,город
Анна,25,Москва
Иван,30,Санкт-Петербург
Если данных немного и их смысл понятен из контекста, заголовок можно не указывать. Просто заполните первую строку файла нужными значениями:
Анна,25,Москва
Иван,30,Санкт-Петербург
Правила форматирования
Для корректной работы CSV-файлов необходимо следовать рекомендациям, описанным в стандарте RFC 4180. В этом документе сформулированы общепринятые принципы построения CSV-файлов, которыми чаще всего руководствуются разработчики и программы, чтобы обеспечить правильное чтение данных и обмен ими. Давайте рассмотрим основные положения этого стандарта.
Разделитель полей. По умолчанию в CSV используется запятая, но в разных странах применяются и другие символы. Например, в России часто используют точку с запятой, так как запятая служит десятичным разделителем в числах. Вот пример CSV-файла с точкой с запятой:
имя;возраст;город
Анна;25;Москва
Пётр;32;Казань
Мария;27,5;НовосибирскВ последней строке значение «27,5» корректно воспринимается как число с дробной частью, поскольку точка с запятой не конфликтует с записью чисел.

Кавычки для спецсимволов. Если в данных есть запятые, кавычки или переносы строк, такие значения нужно заключать в двойные кавычки:
имя,описание,комментарий
"Книга ""Война и мир""","Толстой, классика","Многословно,
но глубоко"Разберёмся, что здесь происходит:
- Кавычки в тексте — во фрагменте "Книга ""Война и мир""" внешние кавычки ограничивают всё поле, а двойные кавычки внутри ("") экранируют сам символ кавычки. Это значит, что он отображается в тексте как обычная " и не воспринимается программой как конец поля.
- Запятая внутри поля — в значении Толстой, классика запятая не разделяет столбцы, поскольку всё выражение заключено в кавычки.
- Перенос строки — комментарий Многословно, но глубоко сейчас занимает несколько строк, но из-за кавычек считается одним полем.
Кодировка. Наиболее универсальный вариант — UTF-8. Она обеспечивает корректное отображение кириллицы, иероглифов и других символов:
// В кодировке UTF-8
имя,город,страна
Иван,Москва,Россия
// То же самое при открытии в неправильной кодировке
РёРјСЏ,РіРѕСЂРѕРґ,СЃС'рана
РРІРаЅ,РњРѕСЃРєРІР°,Р РѕСЃСЃРёСЏЧтобы избежать подобных ошибок, всегда сохраняйте CSV в UTF-8 и при импорте указывайте кодировку в настройках программы, с которой работаете.
Одинаковое количество полей. Каждая строка должна содержать одинаковое число значений (столбцов), чтобы файл корректно считывался. Если какого-то значения нет, его всё равно нужно обозначить — вы должны оставить пустое поле, но не пропускать разделитель. Например, если мы не укажем у Ивана возраст, то структура таблицы сохранится благодаря запятой:
имя,возраст,город
Анна,25,Москва
Иван,,Санкт-ПетербургА вот если не указать пустое поле, то программа подумает, что у строки только два столбца. В итоге из-за этого нарушится структура файла CSV:
имя,возраст,город
Анна,25,Москва
Иван,Санкт-Петербург # здесь пропущен разделитель после имени,
# из-за этого «Санкт-Петербург» попадает в столбец «возраст»,
# а поле «город» остаётся пустымКак создать и сохранить CSV-файл
Самый простой способ создать CSV-файл — открыть любой текстовый редактор и ввести данные таблицы, разделяя значения запятыми или другими разделителями. Затем сохраните файл с расширением .csv — и всё готово:
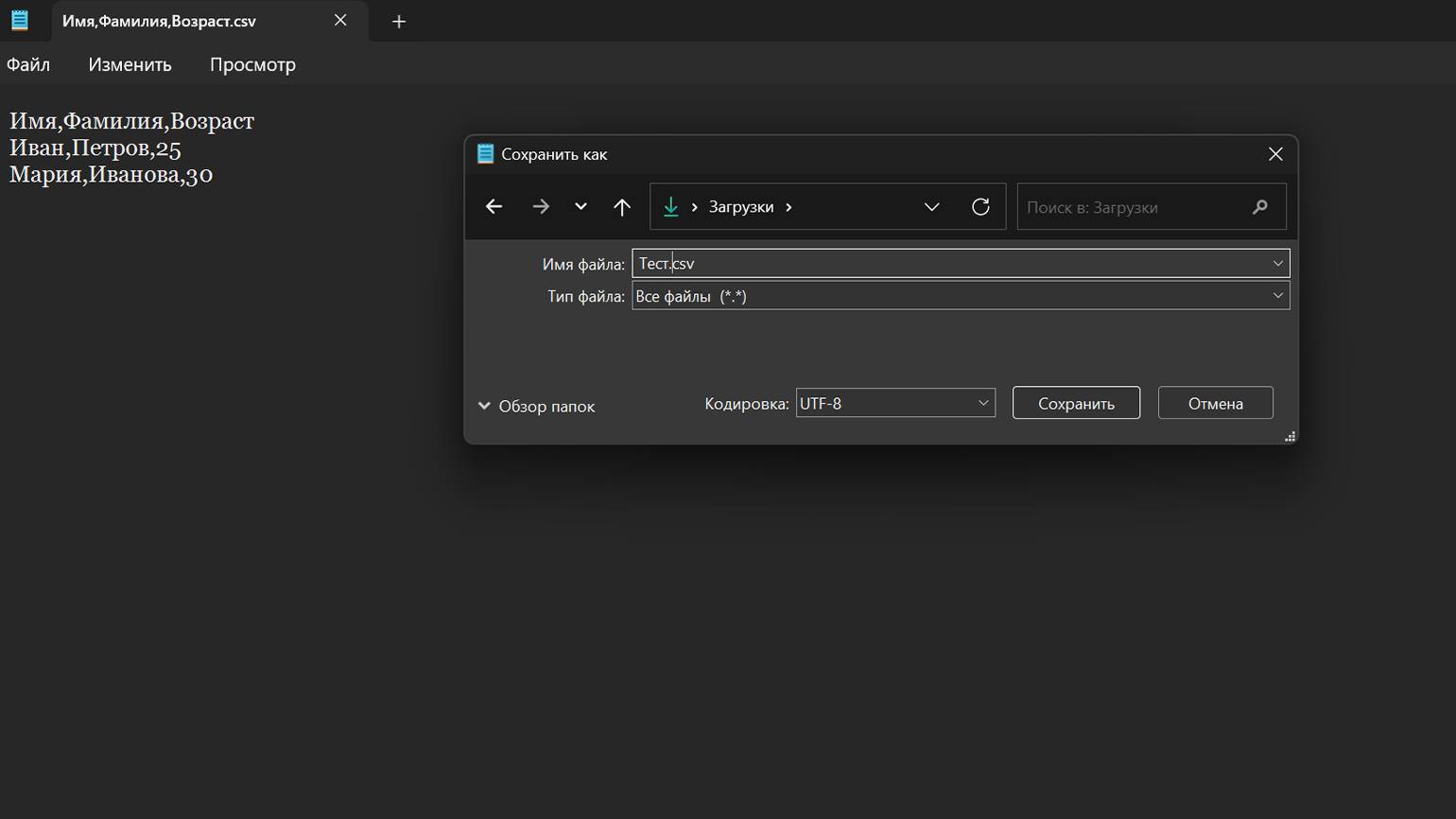
Скриншот: Windows / Skillbox Media
Однако первый способ подходит только для создания небольших файлов, которые вам нужно срочно оформить и передать. Большие таблицы так заполнять долго и неудобно, а без визуального разделения текста на ячейки легко ошибиться.
Поэтому рекомендуем воспользоваться одной из программ, о которых мы говорили выше. Заполните ячейки вручную или с помощью встроенных функций и формул, а затем при сохранении выберите формат CSV.
Скриншот: Google Sheets / Skillbox Media
Работа с CSV в Python с помощью Pandas
Вместо привычных таблиц разработчики и аналитики часто используют Python с библиотекой Pandas. Она позволяет автоматизировать работу с большими массивами данных, выполнять сложные преобразования и получать предсказуемый результат при каждом повторном запуске.
Чтобы поработать с Pandas, достаточно установить Python на компьютер или воспользоваться бесплатным онлайн-сервисом Google Colab.

Откроем в Google Colab новый блокнот и вставим в ячейку этот код:
import pandas as pd # Импортируем библиотеку Pandas
# Создаём данные в виде словаря
data = {
'имя': ['Анна', 'Иван', 'Мария'],
'возраст': [25, 30, 28]
}
# Преобразуем словарь в таблицу (DataFrame)
df = pd.DataFrame(data)
# Сохраняем таблицу в CSV-файл
df.to_csv('people.csv', index=False) # index=False убирает лишний столбец с номерами строкМы создали словарь с данными, преобразовали его в таблицу Pandas (DataFrame) и сохранили её в CSV-файл без лишнего столбца индексов.
Чтобы увидеть результат, вставьте в новую ячейку следующий фрагмент:
# Считываем CSV-файл
df_from_csv = pd.read_csv('people.csv')
# Отображаем таблицу
display(df_from_csv)Сейчас файл people.csv находится во временном хранилище Colab. Чтобы скачать его на компьютер, создайте ещё одну ячейку и добавьте такой блок:
from google.colab import files
files.download('people.csv')С помощью Pandas вы можете не просто сохранять и считывать таблицы, но ещё и выполнять множество других операций. Например, попробуйте отфильтровать данные, вычислить средний возраст и добавить столбец:
# Отобрать только пользователей старше 26 лет
print(df[df['возраст'] > 26])
# Считаем средний возраст
print(df['возраст'].mean())
# Добавляем новый столбец
df['год рождения'] = 2025 - df['возраст']
print(df)
Читайте также:
Python для всех
Вы освоите Python на практике и создадите проекты для портфолио — телеграм-бот, веб-парсер и сайт с нуля. А ещё получите готовый план выхода на удалёнку и фриланс. Спикер — руководитель отдела разработки в «Сбере».
Пройти бесплатно

