Парсим данные в Telegram на Python. Часть 1. Выбираем библиотеку и изучаем подписчиков
Собираем данные о подписчиках телеграм-каналов и чатов с помощью библиотеки Telethon.


Для анализа телеграм-каналов и чатов используют парсеры данных. Это специальные программы, которые позволяют получить информацию о подписчиках, публикациях и обсуждениях с помощью механизмов самого мессенджера (API). Существует немало коммерческих парсеров, однако создать их можно и самостоятельно — используя специальные библиотеки для языков программирования.
В этой статье мы научимся работать с библиотекой Telethon для Python, которая автоматизирует работу по сбору данных из мессенджера: напишем на ней простой парсер для получения информации о подписчиках телеграм-групп или каналов. Это первая часть урока — во второй части будем парсить уже сообщения пользователей.
Библиотека Telethon и особенности парсинга
Написать парсер для Telegram можно на любом языке программирования, позволяющем работать с API: Python, JavaScript, Go и так далее. Каждый из них имеет свою универсальную библиотеку для работы с любыми API, а некоторые — даже специализированные библиотеки для Telegram.
Мы остановимся на Python — одном из самых популярных языков программирования. В экосистеме Python есть удобная асинхронная библиотека для работы с API Telegram — Telethon. Её используют для парсинга информации из мессенджера, управления сообществами и создания ботов. У Telethon два больших преимущества: подробная документация и большая популярность в комьюнити. Работает библиотека тоже отлично :)
Ограничения на парсинг данных из Telegram
В мессенджере две сущности: каналы и чаты. Они различаются тем, что в каналах пишут только администратор или модераторы, а в чатах может писать любой пользователь. Нам это интересно потому, что возможности парсинга для них различаются.
Канал. Если к каналу не подключены комментарии, то список пользователей можно спарсить только при выполнении следующих условий:
- это ваш канал;
- в нём более 200 подписчиков.
Если одно из условий не выполняется, получить информацию о пользователях будет невозможно. Если же к каналу подключён чат, то работа с ним не отличается от парсинга чатов.
Чат. Ограничений на парсинг нет. Главное — чтобы вы были участником этого чата. Если вас в нём нет и он закрыт, спарсить ничего не получится.
Перейдём к написанию кода: получим данные для доступа к API Telegram и напишем парсер списка участников.
Шаг 1
Регистрируемся в разделе инструментов разработчика Telegram
Для работы с API Telegram нам необходимо получить api_id и api_hash. Сделать это можно в разделе инструментов разработчика Telegram. Это обязательное действие не только при создании нашего бота, но и при создании любого бота или парсера, который задействует API мессенджера.
Переходим по ссылке и авторизуемся, используя номер телефона, привязанный к вашему профилю в мессенджере. После авторизации необходимо выбрать пункт API development tools:
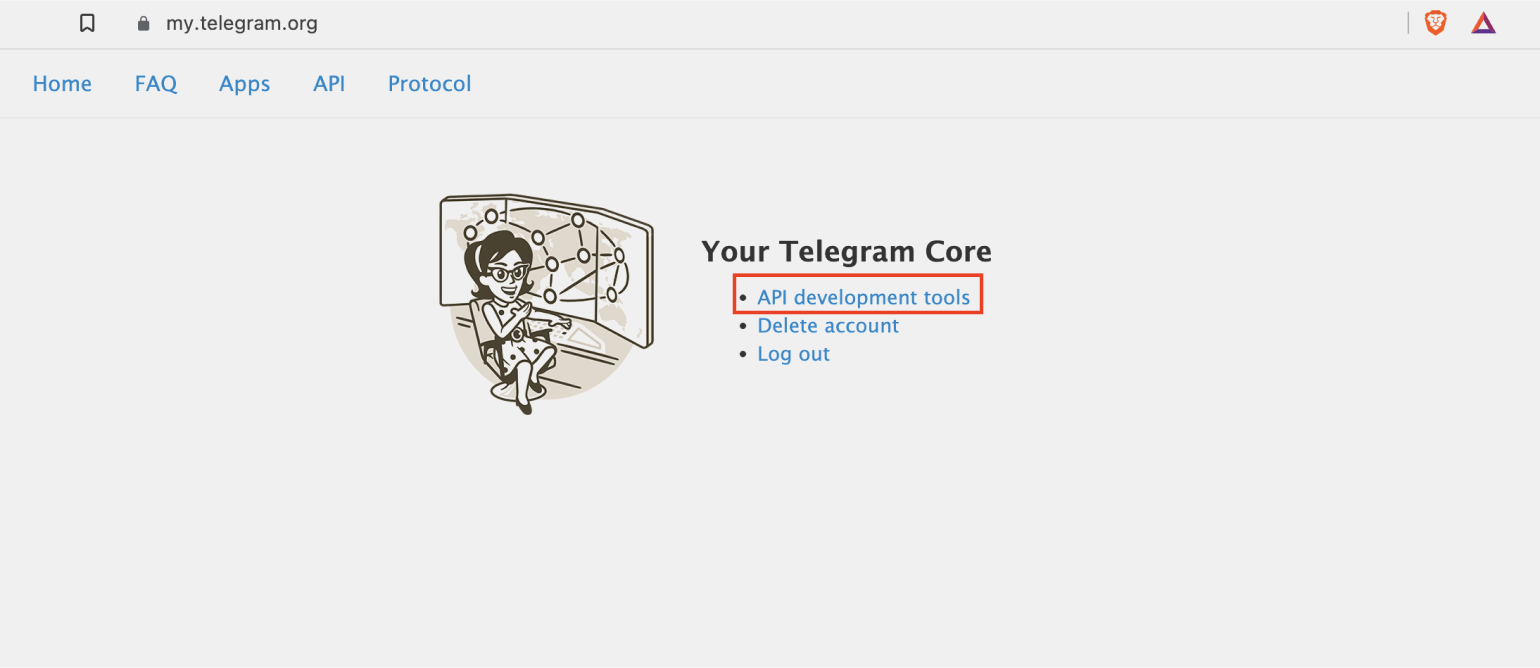
В открывшейся форме заполняем пустые поля. Всё заполнять необязательно, главное — указать полное и краткое имя приложения:
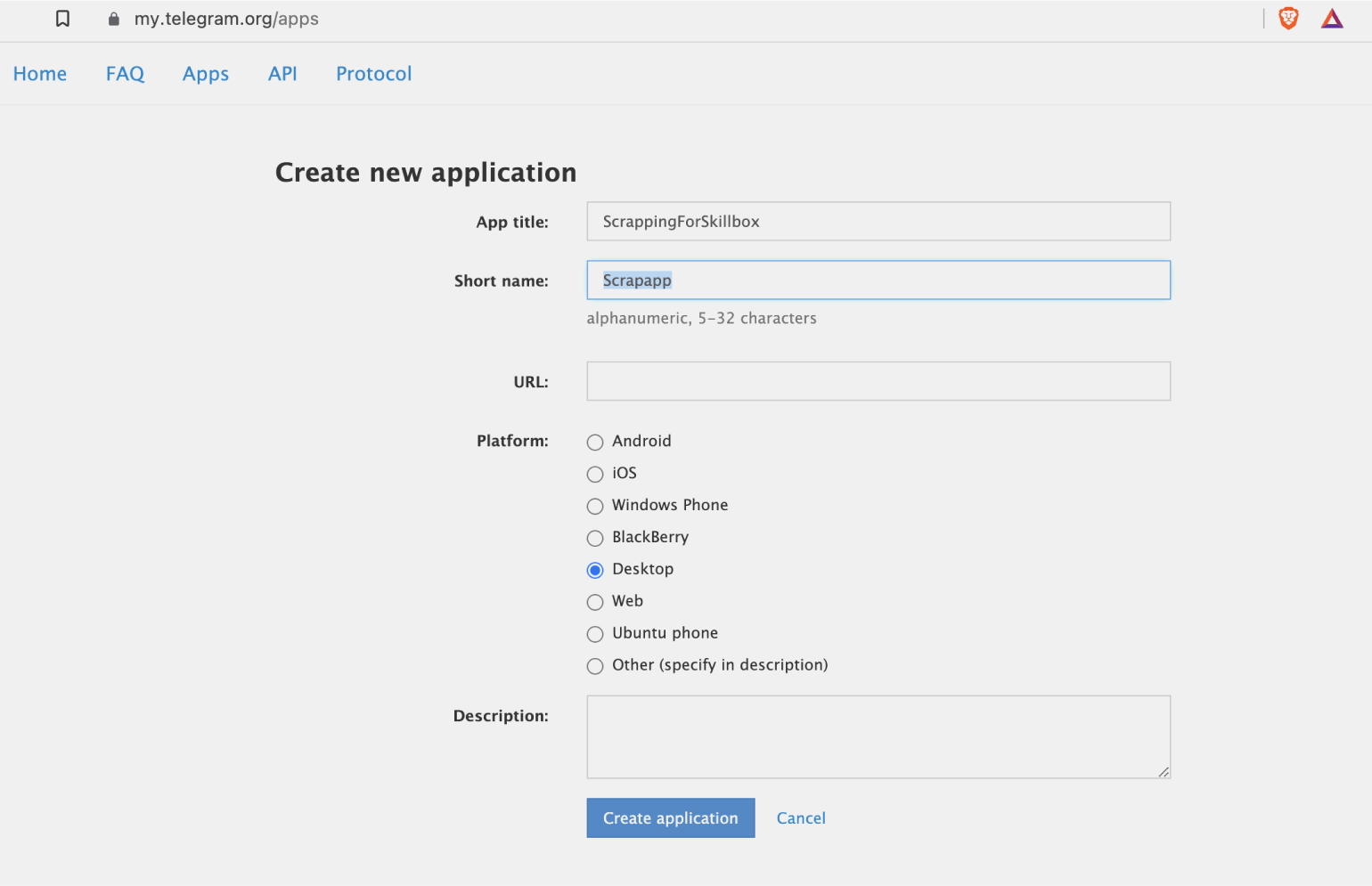
После нажатия Create application откроется страница, на которой нас интересует два параметра:
- api-id — 18377495;
- api-hash — a0c785ad0fd3e92e7c131f0a70987987.
Важно!
Не отправляйте свои api-id и api-hash третьим лицам. Их могут использовать для работы с мессенджером от вашего имени.
Шаг 2
Импортируем библиотеки и запускаем клиент
Для написания кода парсера мы будем использовать Visual Studio Code. Это стандартная IDE, которую можно заменить на любую другую — например, на PyCharm или онлайн-редактор типа Google Colab.
Если вы никогда не работали на своём компьютере с Python, его будет необходимо установить. Сделать это проще всего по нашей инструкции.
Теперь откроем вкладку «Терминал» в нашей IDE и установим библиотеку для парсинга данных:
python3 -m pip install telethon
Импортируем её и дополнительные библиотеки:
from telethon.sync import TelegramClient
import csv
from telethon.tl.functions.messages import GetDialogsRequest
from telethon.tl.types import InputPeerEmptyРазберём все импорты построчно:
- from telethon.sync import TelegramClient — класс, позволяющий нам подключаться к клиенту мессенджера и работать с ним;
- from telethon.tl.functions.messages import GetDialogsRequest — функция, позволяющая работать с сообщениями в чате;
- from telethon.tl.types import InputPeerEmpty — конструктор для работы с InputPeer, который передаётся в качестве аргумента в GetDialogsRequest;
- import csv — библиотека для работы с файлами в формате CSV.
После импорта библиотек запустим клиент Telegram API. Для этого добавим код с нашими api-id, api-hash и номером телефона:
api_id = 18377495
api_hash = 'a0c785ad0fd3e92e7c131f0a70987987'
phone = 'ваш номер телефона, привязанный к профилю'
client = TelegramClient(phone, api_id, api_hash)Теперь остаётся запустить клиент:
client.start()
Сохраним и запустим код парсера. В терминале нам предложат ввести номер телефона, который мы использовали для получения api-id и api-hash, а после этого в мессенджер придёт пятизначный код, который также потребуется вести. Важно, что номер мы вводим без символа +. Если данные верны, появится сообщение о том, что авторизация прошла успешно:

После входа в систему в папке с кодом появится файл .session. Это файл базы данных, который делает сессию постоянной, то есть как бы не даёт нам разлогиниться. База данных благодаря библиотеке Telethon создаётся автоматически (формат — SQLite) — в ней хранится информация о текущей сессии парсинга: хеш, IP-адрес, с которого она производится, время сессии и другие технические данные подключения.
Шаг 3
Получаем список каналов и чатов, доступных для парсинга
Будем собирать информацию из чатов, на которые подписан пользователь. Это удобно, так как позволяет обращаться к ним, не указывая конкретный адрес, а выбирая из списка.
Начнём с создания пустых списков, которые пригодятся для хранения списка чатов, и инициализируем две переменные (они используются для фильтрации чатов):
chats = []
last_date = None
size_chats = 200
groups=[]Теперь создадим два списка: chats и groups. Первый будем использовать, чтобы получать список чатов. А во второй будем складывать список чатов после проверки. Кроме того, ограничим максимальное количество получаемых групп с помощью переменной size_chats (присвоим ей значение 200) и создадим переменную last_date со значением None, которой воспользуемся позже.
Напишем запрос для получения списка групп:
result = client(GetDialogsRequest(
offset_date=last_date,
offset_id=0,
offset_peer=InputPeerEmpty(),
limit=size_chats,
hash = 0
))
chats.extend(result.chats)offset_date и offset_peer мы передаём с пустыми значениями. Обычно они используются для фильтрации полученных данных, но здесь мы хотим получить весь список. Лимит по количеству элементов в ответе задаём 200, передавая в параметр limit переменную size_chats.
Так как мы планируем, что парсер будет работать только с каналами, а не с личными чатами (то есть перепиской) пользователя, необходимо добавить ещё одну проверку:
for chat in chats:
try:
if chat.megagroup== True:
groups.append(chat)
except:
continueПроверка работает очень просто: если у группы будет стандартный параметр megagroup, то мы добавляем её в наш список. Если параметра нет, мы пропускаем группу.
Шаг 4
Выбираем группу для парсинга участников
Настроим выведение списка всех полученных групп, чтобы пользователь мог самостоятельно выбрать нужную. Создадим простой цикл, который выведет названия групп с их номерами:
print('Выберите номер группы из перечня:')
i=0
for g in groups:
print(str(i) + '- ' + g.title)
i+=1Теперь дадим пользователю возможность выбрать нужную группу из списка для последующего парсинга:
g_index = input("Введите нужную цифру: ")
target_group=groups[int(g_index)]Теперь всё готово к парсингу.
Шаг 4
Собираем данные о пользователях и сохраняем их в CSV
Перейдём к парсингу. Напишем код и разберёмся в его логике:
print('Узнаём пользователей...')
all_participants = []
all_participants = client.get_participants(target_group)
print('Сохраняем данные в файл...')
with open("members.csv","w",encoding='UTF-8') as f:
writer = csv.writer(f,delimiter=",",lineterminator="\n")
writer.writerow(['username','name','group'])
for user in all_participants:
if user.username:
username= user.username
else:
username= ""
if user.first_name:
first_name= user.first_name
else:
first_name= ""
if user.last_name:
last_name= user.last_name
else:
last_name= ""
name= (first_name + ' ' + last_name).strip()
writer.writerow([username,name,target_group.title])
print('Парсинг участников группы успешно выполнен.')В первой части кода мы создаём переменную all_participants, в которой сохраняем данные пользователей, полученные в результате парсинга. Сам парсинг происходит в одну строку — мы используем стандартный метод Telethon client.get_participants(), где в скобках передаём целевую группу или канал, откуда хотим парсить данные.
После этого переходим к сохранению данных в файл формата CSV. Для этого мы используем стандартный модуль csv, позволяющий работать с этим типом файлов. Подробнее о модуле можно узнать из его документации.
Для начала откроем файл в режиме записи (если файла с таким названием в директории нет, он автоматически создаётся), явно указав кодировку UTF-8. Это важно, так как пользователи в мессенджере часто устанавливают себе имена не в кодировке ASCII. Затем создадим объект CSV writer и запишем первую строку (заголовок) в CSV-файл. Теперь остаётся пройтись по каждому элементу списка all_participants и записать все элементы в CSV-файл.
Парсим для каждого участника его юзернейм, имя и название группы. Так как имя может состоять из имени и фамилии, то для присвоения значения конечной переменной name воспользуемся конкатенацией строк, объединив имя и фамилию в одну строку.
Важно!
Не каждый пользователь имеет юзернейм, видимый для нас. Если у пользователя нет юзернейма, API вернёт None. Чтобы избежать записи None, явно укажем в условиях добавление вместо этого пустой строки. Аналогичную опцию сделаем для имени и фамилии.
Теперь запустим и проверим работоспособность нашего парсера. Для этого открываем терминал и переходим в папку, где сохранён наш код:

Запустим файл main.py. Для этого напишем в терминале:
python3 main.py
В ответ на это мы получим запрос на выбор группы для парсинга:
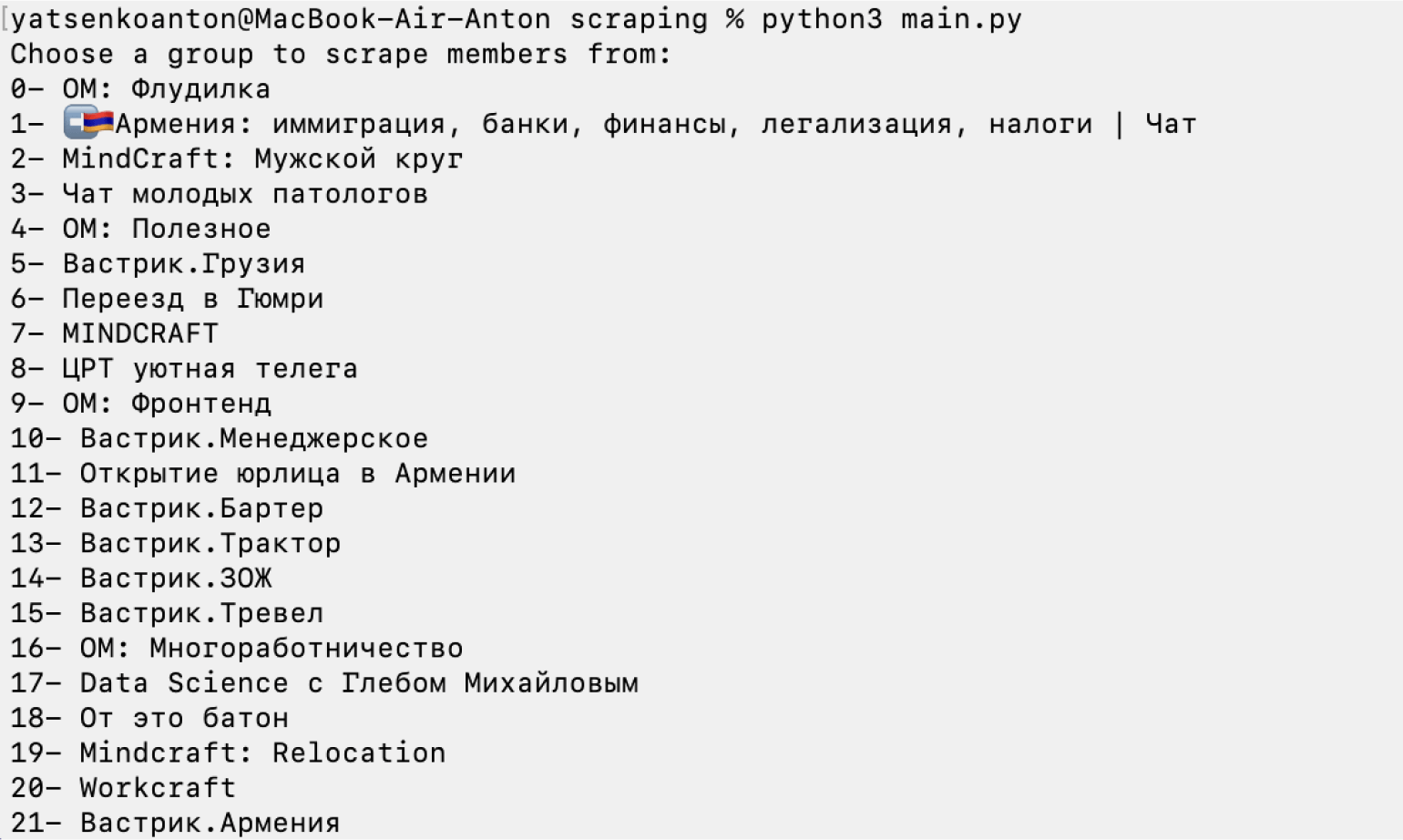
Выберем любую группу, введя в терминал нужную цифру. В нашем случае это будет группа «Вастрик.ЗОЖ».

Теперь мы видим текстовые сообщения, которые «зашивали» в код. И главное, понимаем, что парсинг прошёл удачно.
Откроем нашу папку. В ней появился файл members.csv:

Откроем его и посмотрим на содержимое:

Скриншот: Telethon / Skillbox Media
Всё получилось! В файле мы видим всех пользователей группы с указанием их юзернейма и имени, включающего также фамилию с дополнительными символами.
Что дальше?
В следующей части мы научимся парсить сообщения из чатов. Изучим новые методы и объекты библиотеки Telethon и поработаем с форматом JSON, который особенно удобен для хранения текстовой информации.
Python для всех
Вы освоите Python на практике и создадите проекты для портфолио — телеграм-бот, веб-парсер и сайт с нуля. А ещё получите готовый план выхода на удалёнку и фриланс. Спикер — руководитель отдела разработки в «Сбере».
Пройти бесплатно
