Простые инструменты машинного обучения
Краткий обзор возможностей low-code-платформ PyCaret, BigQuery ML и fastai.



Ребекка Викери
(Rebecca Vickery)
Об авторе
Исследователь данных в Holiday Extras. Автор, докладчик, основатель в DatAcademy.
Переводчик
Сергей Попов
Теоретически машинное обучение позволяет справиться с кучей проблем как в бизнесе, так и в жизни вообще. Но чтобы разработать и адекватно внедрить обучающие модели, требуются глубокие познания в программировании и отличное понимание соответствующих алгоритмов. Это сильно ограничивает круг потенциальных пользователей и количество задач, которые можно было бы решить с помощью этих моделей.
К счастью, в последние годы появилось немало библиотек и инструментов, которые уменьшают количество необходимого кода, а порой и вовсе делают его необязательным. Благодаря этому специалисты по Data Science могут значительно быстрее создавать прототипы, а представители других профессий — пользоваться возможностями машинного обучения, не погружаясь в специфику работы с данными.
Вот некоторые из моих любимых low-code-инструментов.
PyCaret
Фактически это оболочка Python над популярными библиотеками машинного обучения вроде scikit-learn и XGBoost. Она позволяет разработать готовую для развёртывания модель с помощью всего нескольких строк кода. PyCaret можно установить с помощью pip. Более подробные инструкции по установке есть в документации.
pip install pycaret
Репозиторий открытых датасетов можно установить напрямую, используя модуль pycaret.datasets (полный список доступен на сайте PyCaret). В целях наглядности в этой статье для решения задачи классификации использован очень простой датасет под названием «Качество вина».
Библиотека PyCaret содержит набор модулей для решения всех самых распространённых задач:
- классификация;
- регрессия;
- кластеризация;
- обработка естественного текста (NLP);
- обучение ассоциативным правилам;
- поиск аномалий.
Для запуска модели используется модуль pycaret.classification. Процесс очень прост: нужно всего лишь вызвать функцию create_model(), принимающую в качестве параметра имя модели. Полный список поддерживаемых моделей и их имён тоже есть на сайте PyCaret, либо можно просмотреть его после импорта соответствующего модуля:
from pycaret.classification import *
models()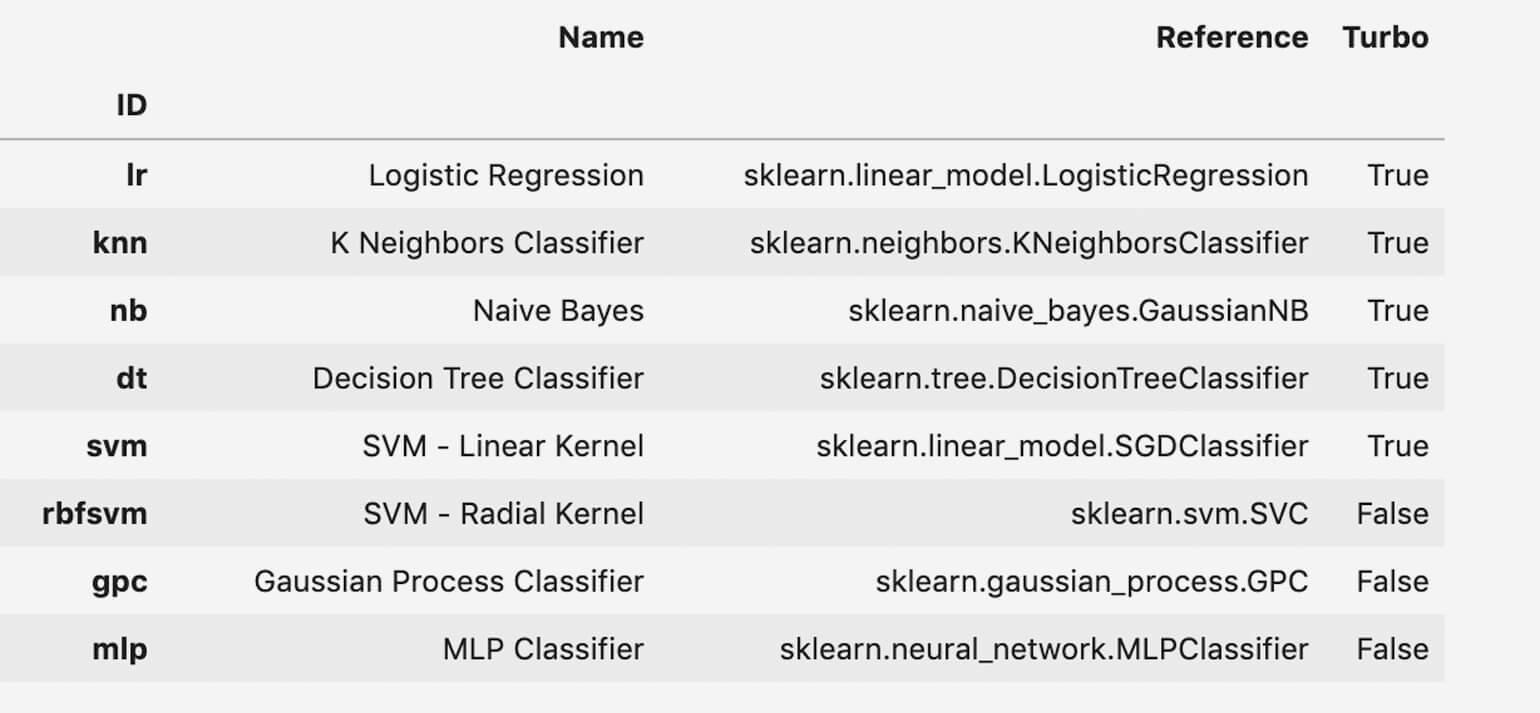
Скриншот: Ребекка Викери
Но прежде чем использовать create_model(), нужно вызвать функцию setup() и задать нужные для эксперимента параметры. Можно, например, указать размер обучающей и контрольной выборок, а также добавить скользящий контроль, если он требуется.
from pycaret.classification import *
rf = setup(data = data,
target = 'type',
train_size=0.8)
rf_model = create_model('rf')Функция create_model() сама определяет тип данных и обрабатывает их методом по умолчанию. Например, вот так автоматически определяется тип данных для каждой переменной в модели из нашего примера:
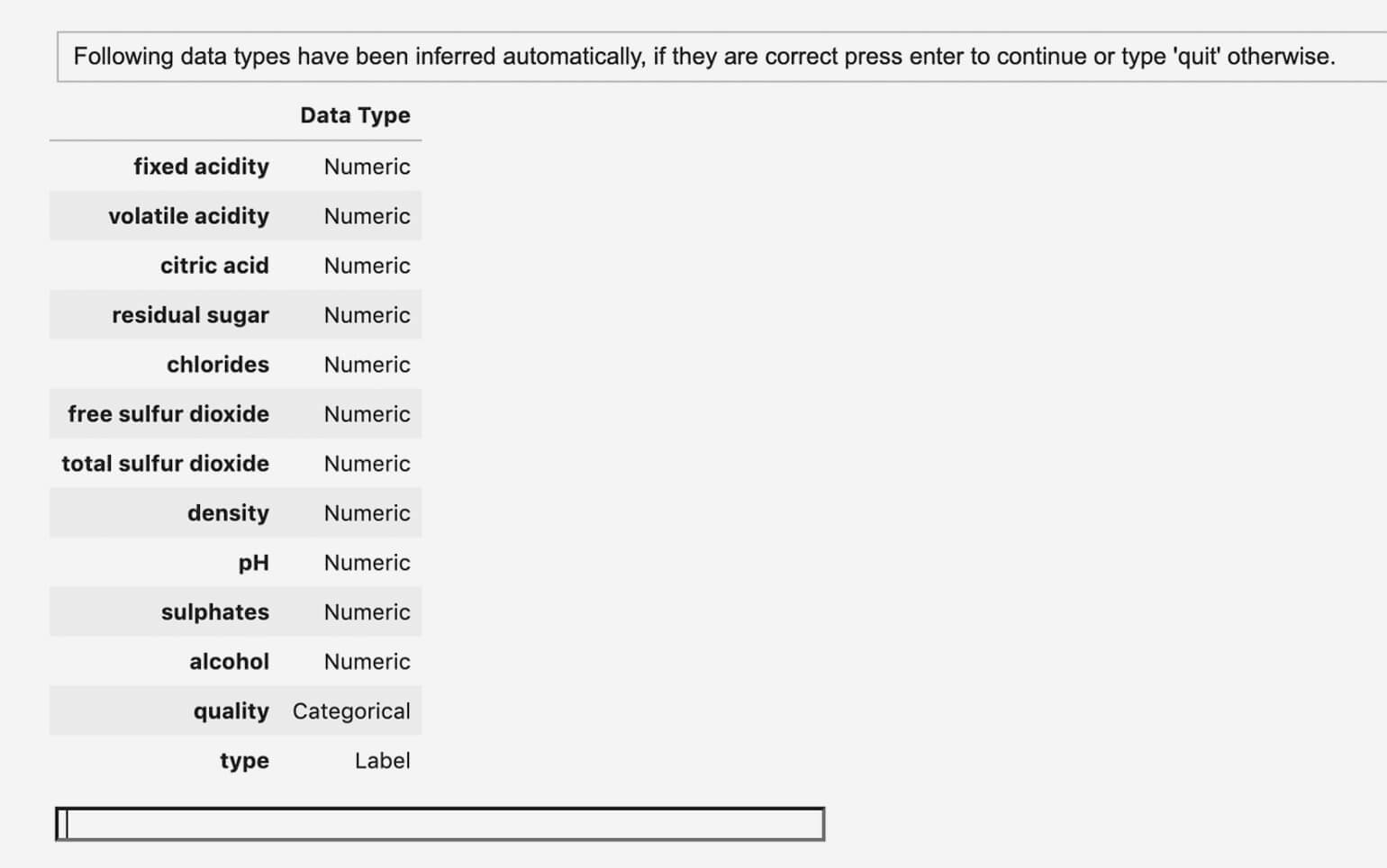
Скриншот: Ребекка Викери
Для таких операций, как обработка категориальных переменных и дополнение пропущенных значений, PyCaret использует стандартные препроцессинговые шаги. Если же требуется более специализированное решение, вы можете изменить в настройках модели соответствующий параметр — например, в примере ниже в numeric_imputation указан median.
from pycaret.classification import *
rf = setup(data = data,
target = 'type',
numeric_imputation='median')
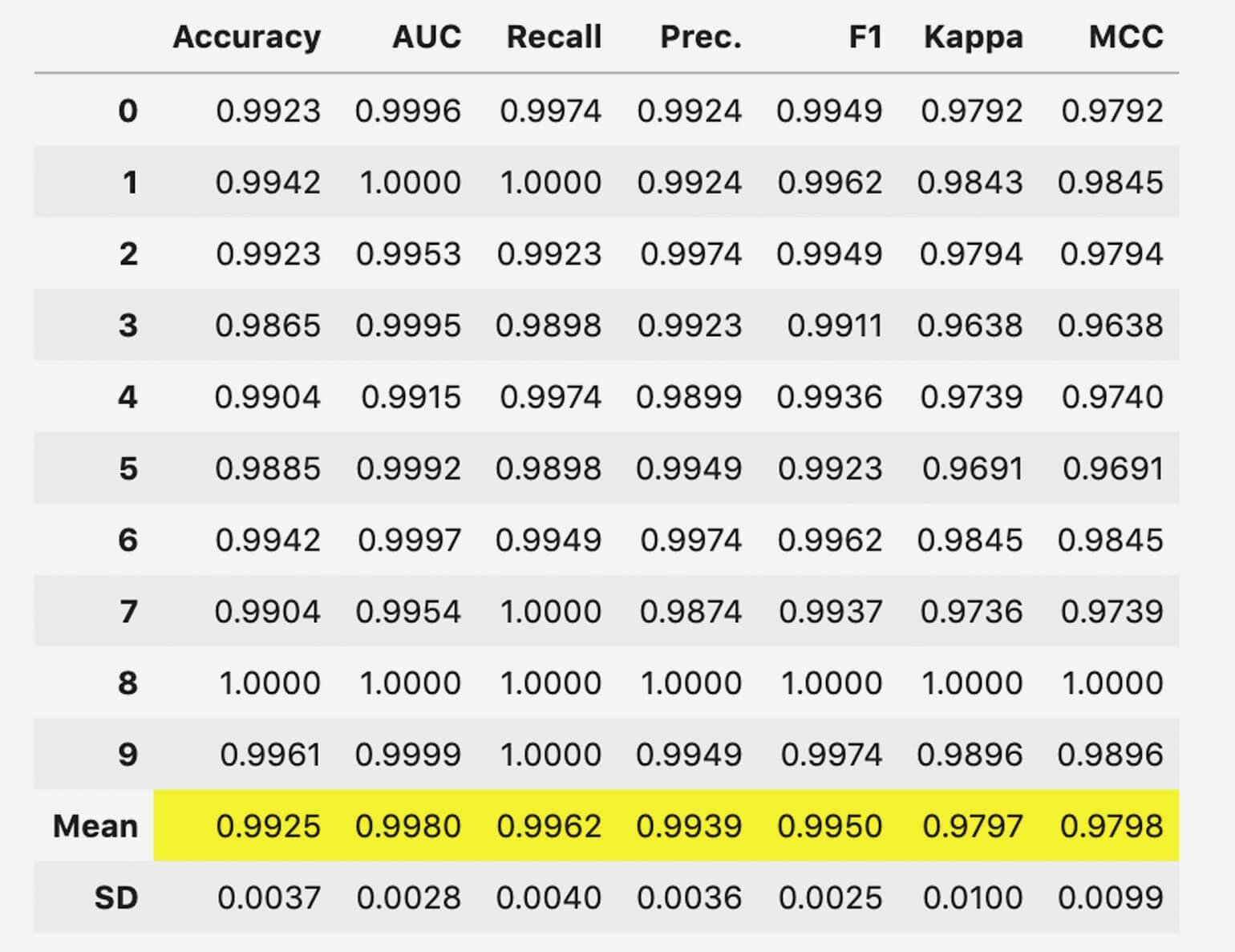
rf_model = create_model('rf')Как только все используемые параметры указаны верно, нажимаем Enter. Модель обработает данные и отобразит сетку результатов.
В PyCaret также есть функция plot_model(), которая выводит результат работы модели в графическом виде.
plot_model(rf_model)
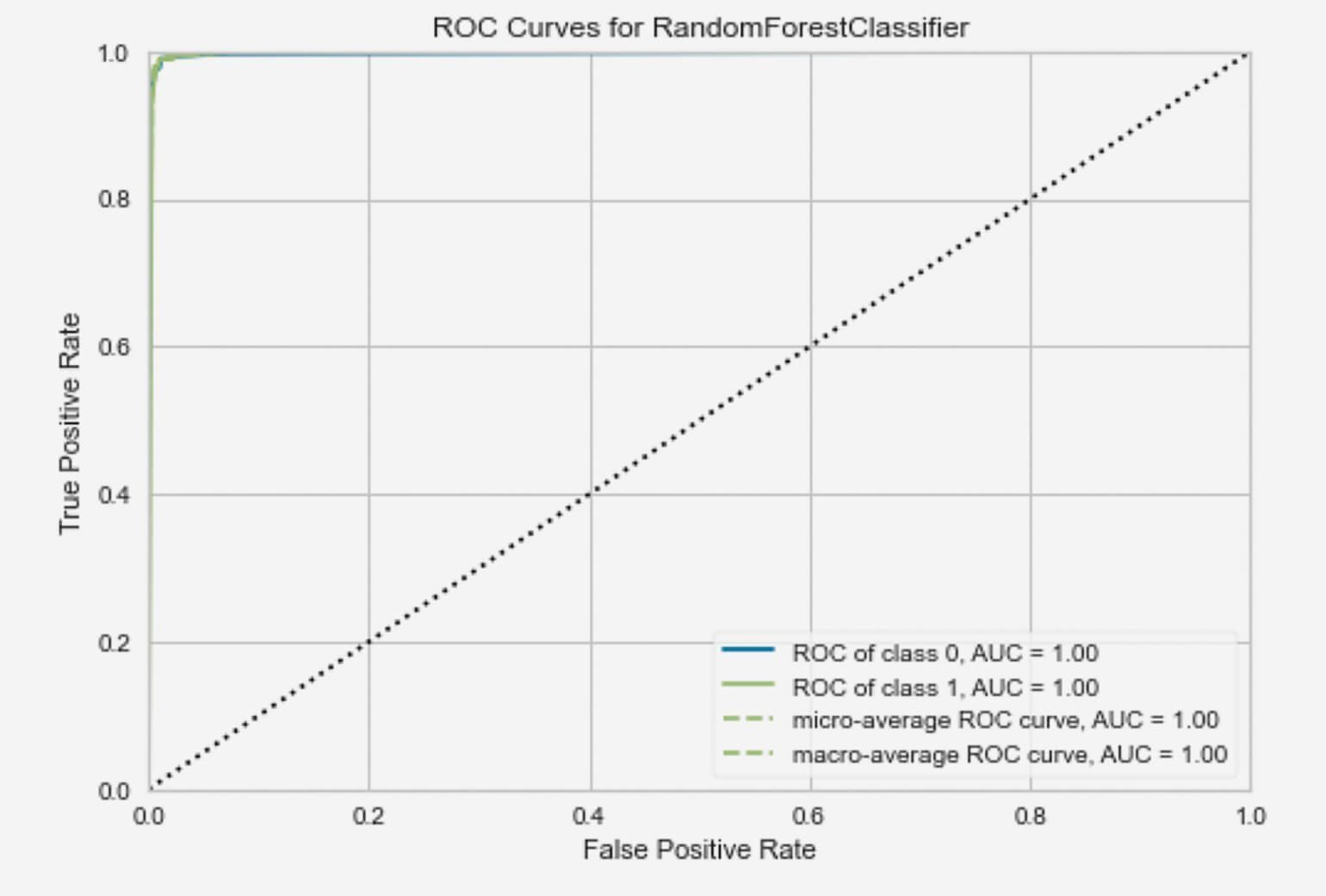
Я продемонстрировала вам лишь самые основы использования библиотеки. В ней есть ещё множество функций и модулей. В совокупности это отличный инструмент для машинного обучения, включающий в себя конструирование и настройку моделей, их сохранение и развёртывание.
BigQuery ML
В 2018 году компания Google выпустила новый инструмент под названием BigQuery ML. Это облачное решение, призванное предоставить аналитикам и специалистам по Data Science быстрый доступ к большим объёмам данных. Можно разрабатывать модели машинного обучения прямо из облака BigQuery, используя только SQL.
C момента релиза возможности BigQuery ML значительно расширились. Теперь он поддерживает большинство задач машинного обучения — в частности классификацию, регрессию и кластеризацию. Можно даже импортировать в него собственные модели TensorFlow.
По моему опыту, BigQuery ML — крайне полезный инструмент для ускорения прототипирования моделей и вполне годная основная система для решения несложных задач.
Разберём, как построить и оценить классификационную модель логистической регрессии в BigQuery ML. Для примера возьмём датасет «Доход взрослого человека». Его можно найти в UCI Machine Learning Repository. Скачиваем датасет в виде CSV-файла и загружаем, используя следующий код на Python:
import pandas as pd
import numpy as np
url_data = 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data'
column_names = ['age', 'workclass', 'fnlwgt', 'education', 'educational-num', 'marital-status', 'occupation', 'relationship', 'race', 'gender', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country','income']
adults_data = pd.read_csv(url_data, names=column_names)
adults_data.to_csv('adults_data.csv')Работа с BigQuery ML идёт через Google Cloud Platform (GCP). На официальном сайте есть и страница регистрации. После регистрации вы получите бесплатный кредит в 300 долларов США — этого вполне достаточно, чтобы самостоятельно проработать наш пример и решить, нужен ли вам данный инструмент.
На сайте GCP выберите BigQuery в выпадающем меню. Если вы пользуетесь платформой впервые, придётся сначала создать проект и настроить его на BigQuery ML. Руководство по началу работы от Google тоже имеется.
CSV-файл датасета, который мы скачали раньше, можно загрузить в GCP и напрямую и вывести данные из него в виде таблицы.
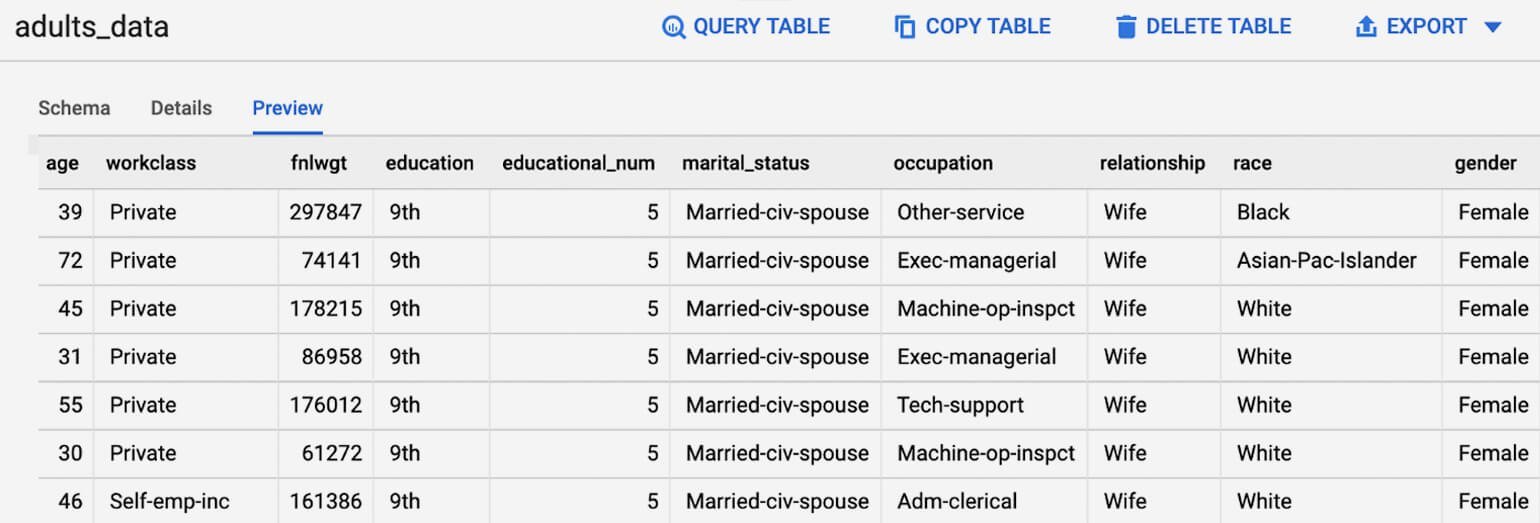
Если нужно изучить данные самостоятельно, нажмите на название таблицы на боковой панели и выберите «Предварительный просмотр».
Далее пишем SQL-запрос, который берёт все данные (*) из таблицы, переименовывает целевую переменную (income) в label и добавляет логику для создания модели логистической регрессии под названием adults_log_reg.
Все параметры модели можно найти здесь.
CREATE MODEL `mydata.adults_log_reg`
OPTIONS(model_type='logistic_reg') AS
SELECT *,
ad.income AS label
FROM
`mydata.adults_data` adЕсли кликнуть по модели, которая теперь отображается рядом с таблицей данных, мы увидим оценку эффективности её обучения.
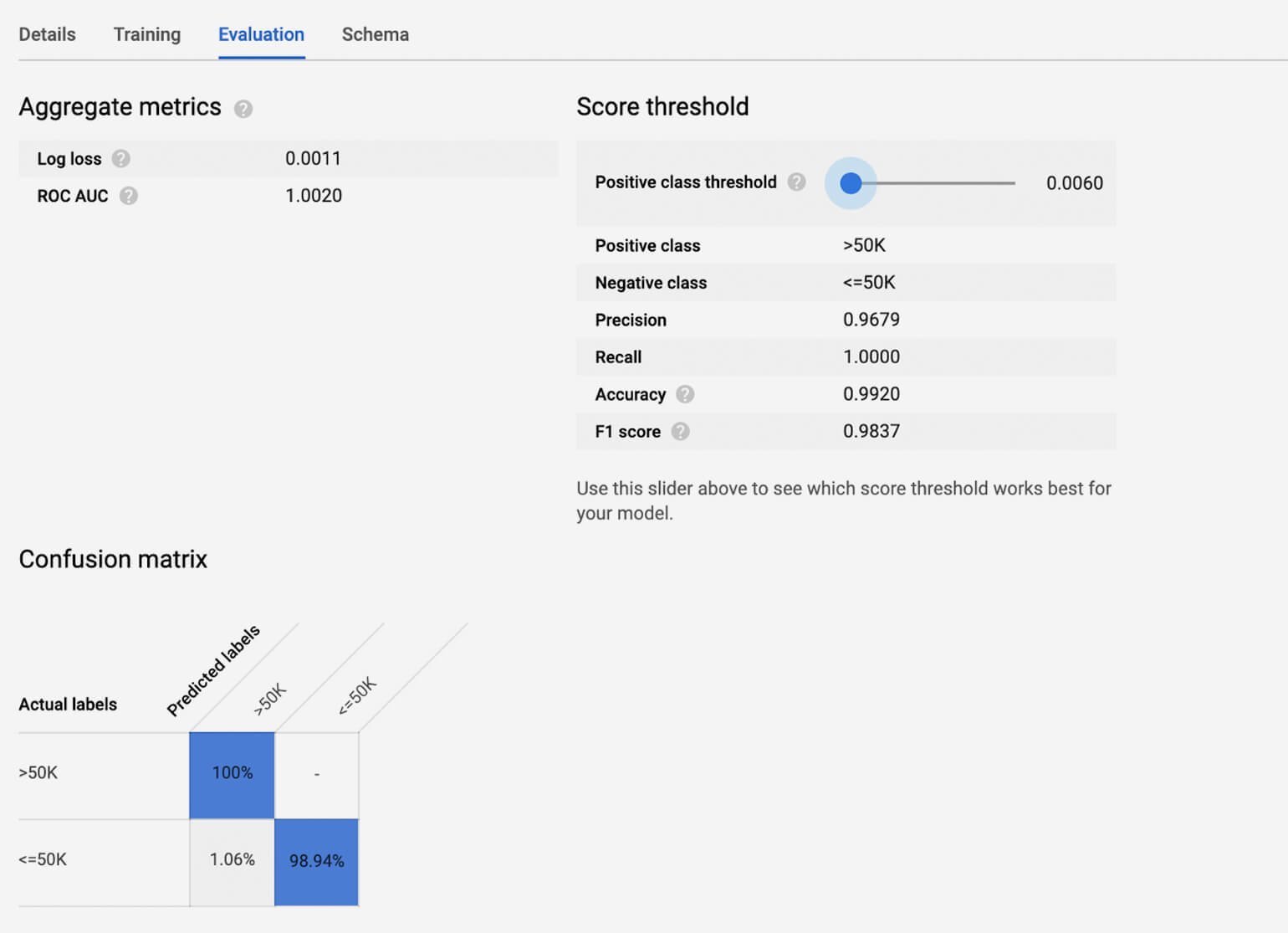
Теперь можно использовать модель для постройки прогнозов с помощью функции ML.PREDICT.
fastai
Известно, что популярные фреймворки для глубокого машинного обучения, например TensorFlow, весьма сложны в освоении, и начинающим дата-сайентистам и аналитикам пользоваться ими практически невозможно. Эту проблему может решить библиотека fastai — она предлагает развитый программный интерфейс, позволяющий обучать нейронную сеть с помощью нескольких строк несложного кода.
fastai работает с PyTorch, поэтому нужно установить обе библиотеки.
pip install pytorch
pip install fastai
Здесь есть модули для работы как со структурированными, так и с неструктурированными данными (например, текстом и изображениями). В своём примере я беру модуль fastai.tabular.all для решения классификационной задачи по тому же датасету «Качество вина», который мы использовали в разборе PyCaret.
Как и PyCaret, fastai предварительно обрабатывает все данные нечисловых типов через эмбеддинг. Для подготовки этих данных я использую вспомогательную функцию TabularDataLoaders, указывая в ней название датафрейма, типы данных колонок и препроцессинговые шаги, которые требуются от модели.
dl = TabularDataLoaders.from_df(data, y_names="type",
cat_names = ['quality'],
cont_names = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol'],
procs = [Categorify, FillMissing, Normalize])Для обучения нейронной сети берём функцию tabular_learner(), как показано ниже.
learn = tabular_learner(dl, metrics=accuracy)
learn.fit_one_cycle(1)Результаты работы модели:

Чтобы применять эту модель для построения прогнозов, можно просто использовать learn.predict(df.iloc[0]).
Более подробно изучить библиотеку fastai можно по официальной документации.