Как парсить сайты и материалы СМИ с помощью JavaScript и Node.js
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.


Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Как устроен парсинг сайтов
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Устанавливаем необходимое ПО
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
Парсим сайт с первым типом пагинации: отдельные страницы, переход по кнопке
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал :)
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.
На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Определяем структуру сайта
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида "https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида "https://jrnlst.ru/?page=[номер страницы]", которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с "page=200" (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом "block-views-articles-latest-on-front-block" → первый элемент с классом "view-content" → все элементы с классом "flex-teaser-square" (по очереди) → в каждом из них первый элемент с классом "views-field views-field-title" → в каждом из них первый элемент с тегом 'a' (то есть гиперссылка с названием статьи).
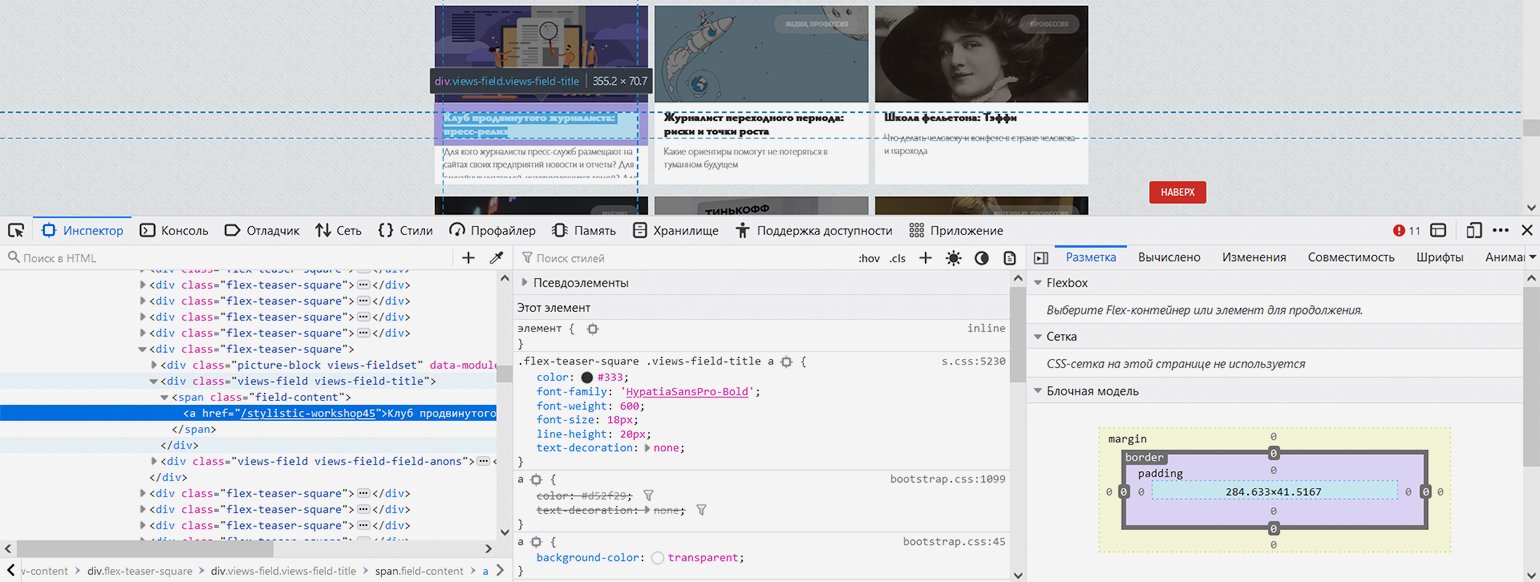
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Пишем код парсера
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
cd "D:\ваш_путь\JJ Articles Parser"
node JJ_articles_parser.js
pauseЗдесь всё просто:
- Первая строка — командой cd переходим в нужные диск и папку.
- Вторая строка запускает интерпретатор Node.js и тут же передаёт ему в обработку наш JS-файл.
- Команда pause делает так, чтобы командная строка не выключалась после выполнения кода.
Теперь займёмся кодом самого парсера:
/* Парсер статей журнала «Журналист» (https://jrnlst.ru) */
// Записывает заголовки и ссылки на статьи в HTML-файл
// Написан на Node.js с использованием модулей axios и jsdom
const axios = require('axios'); // Подключение модуля axios для скачивания страницы
const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой
const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1)
const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2)
const pagesNumber = 162; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице до 18 статей
const baseLink = 'https://jrnlst.ru/?page='; // Типовая ссылка на страницу со статьями (без номера в конце)
var page = 0; // Номер первой страницы для старта перехода по страницам с помощью пагинатора
var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто)
function paginator() {
function getArticles() {
var link = baseLink + page; // Конструктор ссылки на страницу со статьями для запроса по ней
console.log('Запрос статей по ссылке: ' + link); // Уведомление о получившейся ссылке
// Запрос к странице сайта
axios.get(link)
.then(response => {
var currentPage = response.data; // Запись полученного результата
const dom = new JSDOM(currentPage); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере
// Определение количества ссылок на странице, потому что оно у них не всегда фиксированное. Это значение понадобится в цикле ниже
var linksLength = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square').length;
// Перебор и запись всех статей на выбранной странице
for (i = 0; i < linksLength; i++) {
// Получение относительных ссылок на статьи (так в оригинале)
var relLink = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square')[i].getElementsByClassName('views-field views-field-title')[0].getElementsByTagName('a')[0].outerHTML;
// Превращение ссылок в абсолютные
var article = relLink.replace('/', 'https://jrnlst.ru/') + '<br>' + '\n';
// Уведомление о найденных статьях
console.log('На странице ' + 'найдена статья: ' + article);
// Запись результата в файл
fs.appendFileSync('ПУТЬ/articles.html', article, (err) => {
if (err) throw err;
});
};
if (page > pagesNumber) {
console.log('Парсинг завершён.')}; // Уведомление об окончании работы парсера
});
page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу
};
for (var i = page; i <= pagesNumber; i++) {
var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой
parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице)
};
return; // Завершение работы функции
};
paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
На всё ровно 50 строк с учётом детальных комментариев для читающего и уведомлений в консоль о ходе выполнения программы.
Концептуально этот парсер работает так:
- Подключаем нужные модули.
- Определяем константы: количество страниц сайта, основную часть ссылки (кроме номера страницы, который как раз меняется).
- Определяем стартовые значения основных переменных: начало прохода с нулевой страницы и нулевую задержку запросов, которая будет постоянно увеличиваться.
- Определяем основную функцию парсера под названием paginator(), в которой находится почти весь код.
- Последней строкой запускаем эту функцию.
Отдельно скажем об устройстве функции paginator().
Внутри неё есть ещё одна функция — getArticles(), которая конструирует ссылку на последующую страницу из постоянной «базовой части» и номера, делает GET-запрос с помощью команды модулю axios, разбирает результат как DOM-дерево с помощью модуля jsdom, вынимает все ссылки на странице, превращает их из относительных в абсолютные, записывает результат в файл и увеличивает переменную с номером страницы для использования в следующем запросе.
Цикл for, который запускает внутреннюю функцию getArticles() — по расписанию и со всё увеличивающейся задержкой. Установлена задержка в 10 секунд, потому что это не будет сильно нагружать сайт, а общее время выполнения не окажется слишком долгим — плюс разработчики сайта сами рекомендовали такое время в директиве crawl-delay в файле robots.txt (хотя так делают разработчики далеко не всех сайтов, потому что эта директива считается устаревшей). Каждый последующий запуск функции инициирует запрос к более старой странице, поскольку каждый предыдущий запуск увеличивает переменную с номером страницы на 1.
Функция getArticles() запускается, пока переменная с номером следующей страницы не превысит константу с общим количеством страниц. Тогда выполнение всего кода завершается с уведомлением в консоль. В противном случае парсер пытался бы стучаться в двери сайта бесконечно, в чём нет никакого смысла.
Процесс парсинга
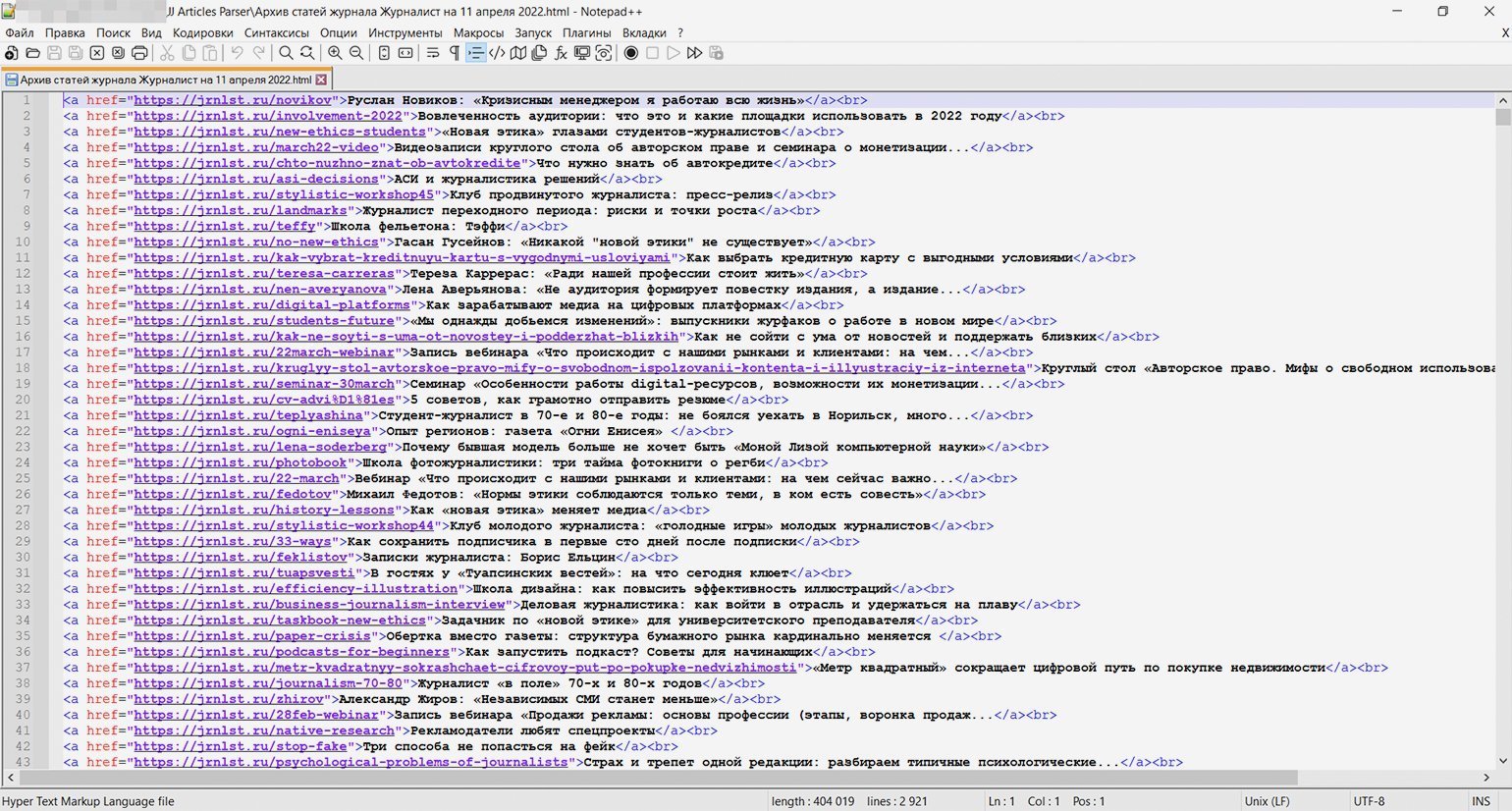
Скриншот: Евгений Колесников для Skillbox Media
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.
Парсим сайт со вторым типом пагинации: бесконечная подгрузка по клику
Напомним, второй способ — это загрузка дополнительных статей на ту же страницу. Обычно в таких случаях простых способов перейти на какую-то дату или в конец просто нет. Страницы со статьями, конечно же, существуют, но только для сервера, обрабатывающего запрос на подгрузку, а не для пользователя.
Для демонстрации этого способа пагинации по предложению редактора Тимура спарсим рубрику «Код» Skillbox Media (без новостей, только статьи). Как тут, спрашивается, применить описанные выше принципы сбора, если видимой нумерации страниц нет? Пойдём по тем же шагам, что и в прошлом примере.
Определяем структуру сайта
В этом случае наши действия будут иными: нужно открыть в браузере инструменты веб-разработки на вкладке «Сеть», чтобы пошпионить за выполняемыми сайтом запросами, а после этого нажать на странице рубрики на кнопку «Показать ещё», подгружающую дополнительные материалы.

Скриншот: Евгений Колесников для Skillbox Media
В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
{
"params[SECTION_ID]": "10",
"params[CODE_EXCLUDE]": "news",
"params[FIRST_IS_FULL]": "Y",
"params[COUNT]": "7",
"params[PAGE_NUM]": "2",
"params[FIELDS][]": "PROPERTY_FAKE_COUNTER",
"params[CACHE_TYPE]": "A",
"params[COMPONENT_TEMPLATE]": "articles"
}Параметр "PAGE_NUM", равный в данном случае 2, соответствует как раз номеру страницы, "SECTION_ID", равный 10, соответствует рубрике «Код», которую мы собрались парсить, а "COUNT", равный 7, — количеству выводимых на странице материалов.
Обратите внимание, что загрузка дополнительных статей в данном случае оформлена как POST-запрос, а не GET- (обычно GET-запрос используется для получения данных с сервера, а POST-запрос — для отправки). Почему это так — отдельный вопрос, выходящий за рамки статьи. При разработке парсера мы должны подстроиться под логику разработчиков сайта, однако ради любопытства попробуем провести небольшой эксперимент.
Если мы скопируем указанную выше ссылку и перейдём по ней без указания параметров, то сайт выдаст ошибку ("status: error") — он просто не будет знать, какую информацию мы у него просим. Здесь браузер передаст именно GET-запрос, а не POST-, однако сайт всё равно нам отвечает (сообщение об ошибке — тоже сообщение).
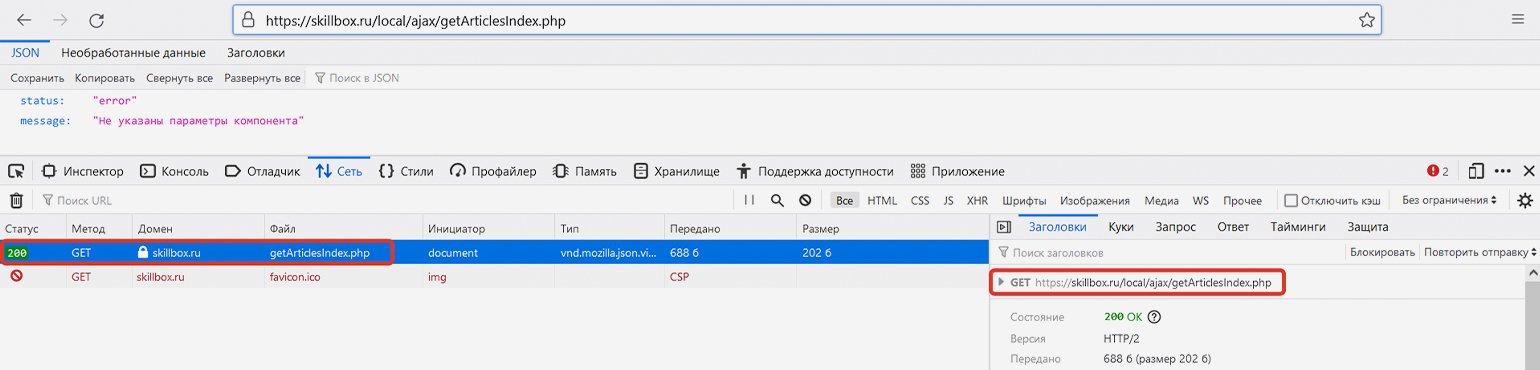
Скриншот: Евгений Колесников для Skillbox Media
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом "ok".
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
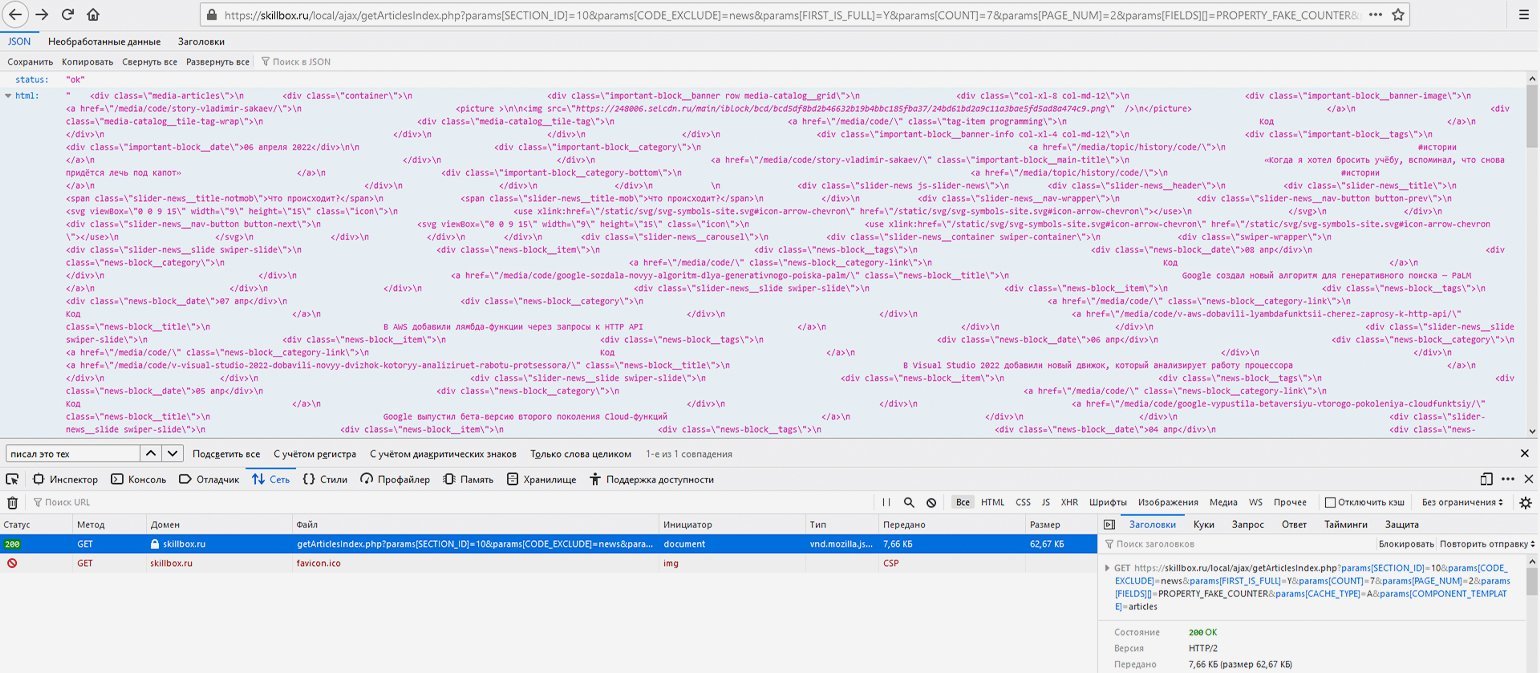
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра "[PAGE_NUM]". Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
Скриншот: Евгений Колесников для Skillbox Media
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
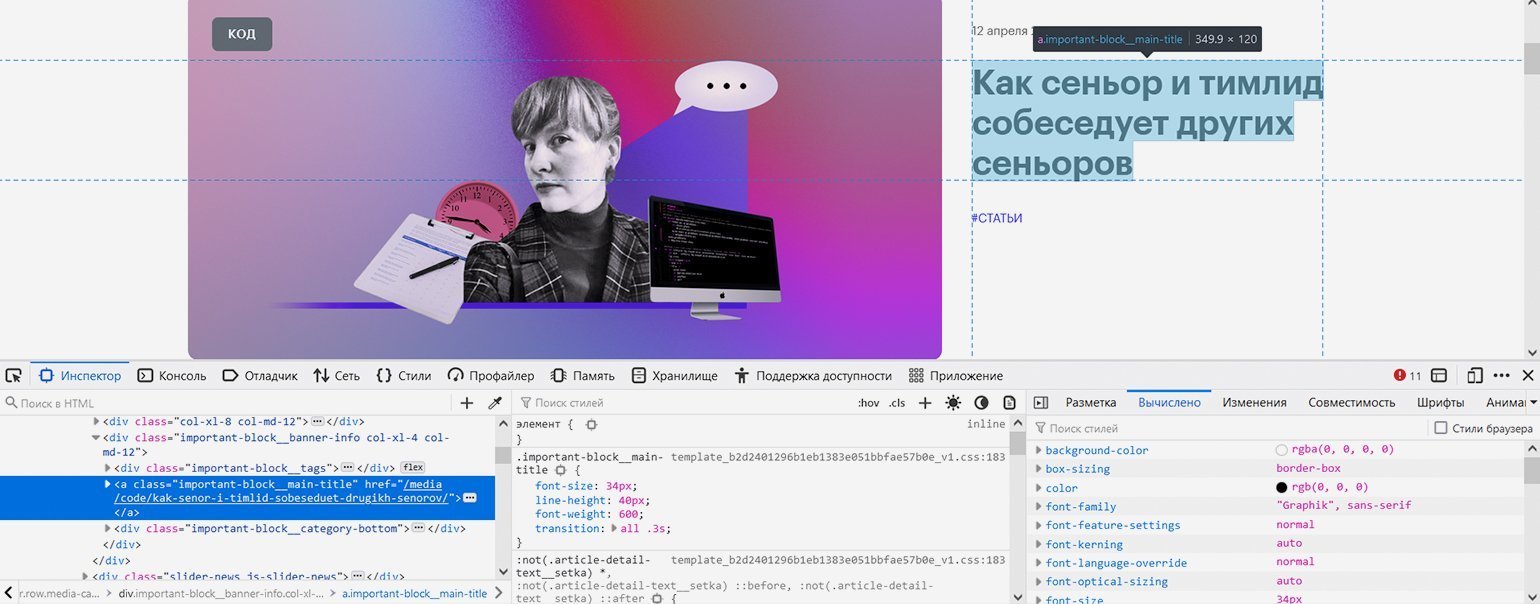
Скриншот: Евгений Колесников для Skillbox Media
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом "important-block__main-title".
Скриншот: Евгений Колесников для Skillbox Media
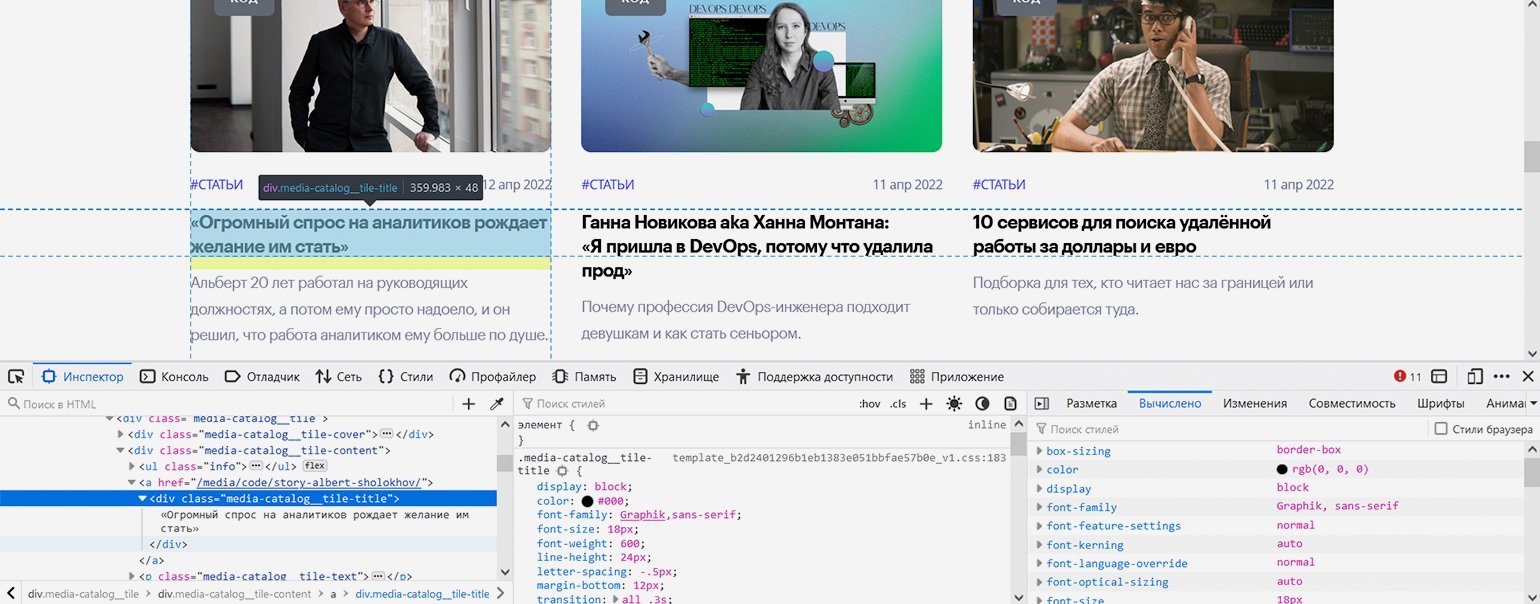
С остальными посложнее: блочный элемент <div> с классом "media-catalog__tile-title" вложен в ссылку — элемент <a>, что довольно необычно. <div> содержит только текст заголовка, а у ссылки <a> не указан класс — но всё это мы решим с помощью правильной навигации.
Пишем код парсера
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
/* Парсер статей рубрики «Код» портала Skillbox Media (https://skillbox.ru/media/code/) */
// Записывает заголовки и ссылки на статьи в HTML-файл
// Написан на Node.js с использованием модулей axios и jsdom
const axios = require('axios'); // Подключаем к Node.js модуль axios для скачивания страницы
const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой
const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1)
const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2)
const pagesNumber = 101; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице по семь статей
var page = 1; // Номер первой страницы для старта перехода по страницам с помощью пагинатора
var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто)
// Определяем стартовые параметры запроса (меняться будет только номер страницы)
var params = new URLSearchParams();
params.append('params[SECTION_ID]', '10');
params.append('params[CODE_EXCLUDE]', 'news');
params.append('params[FIRST_IS_FULL]', 'Y');
params.append('params[COUNT]', '7');
params.append('params[PAGE_NUM]', '1');
params.append('params[FIELDS][]', 'PROPERTY_FAKE_COUNTER');
params.append('params[CACHE_TYPE]', 'A');
params.append('params[COMPONENT_TEMPLATE]', 'articles');
function paginator() {
function getArticles() {
console.log('Запрос статей со страницы ' + params.get('params[PAGE_NUM]')); // Уведомление о номере текущей страницы
// Запрос к странице сайта
axios.post('https://skillbox.ru/local/ajax/getArticlesIndex.php?', params)
.then(response => {
var currentPage = response.data; // Запись полученного результата
var jsonToHtml = currentPage.html; // Получаем из JSON-ответа только HTML-код
const dom = new JSDOM(jsonToHtml); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере
// Парсинг закреплённой статьи
var pinnedHeaderSpaces = dom.window.document.getElementsByClassName('important-block__main-title')[0].innerHTML; // Получение заголовка закреплённой статьи с лишними пробелами
var pinnedHeader = pinnedHeaderSpaces.trim(); // Заголовок закреплённой статьи с удалёнными лишними пробелами
var pinnedLink = dom.window.document.getElementsByClassName('important-block__main-title')[0].getAttribute('href'); // Получение относительной ссылки на закреплённую статью
var pinnedArticle = '<a href="https://skillbox.ru' + pinnedLink + '">' + pinnedHeader + '</a><br>'+ '\n'; // Итоговая ссылка с заголовком закреплённой статьи
console.log('На странице найдена закреплённая статья: ' + pinnedArticle);
// Запись закреплённой статьи в файл
fs.appendFileSync('ПУТЬ/articles.html', pinnedArticle, (err) => {
if (err) throw err;
});
// Парсинг остальных шести статей на странице
var articlesNumber = dom.window.document.getElementsByClassName('media-catalog__tile-title').length; // Определение количества ссылок на странице, потому что на последней странице их меньше. Эта цифра понадобится в цикле ниже
for (var art = 0; art < articlesNumber; art++) {
var articleHeaderSpaces = dom.window.document.getElementsByClassName('media-catalog__tile-title')[art].innerHTML; // Получение заголовка статьи с лишними пробелами
var articleHeader = articleHeaderSpaces.trim(); // Заголовок статьи с удалёнными лишними пробелами
var articleLink = dom.window.document.getElementsByClassName('media-catalog__tile')[art].getElementsByClassName('media-catalog__tile-title')[0].parentElement.getAttribute('href'); // Получение относительной ссылки на статью
var article = '<a href="https://skillbox.ru' + articleLink + '">' + articleHeader + '</a><br>'+ '\n'; // Итоговая ссылка с заголовком статьи
console.log('На странице найдена статья: ' + article);
// Запись статьи в файл
fs.appendFileSync('ПУТЬ/articles.html', article, (err) => {
if (err) throw err;
});
};
if (page > pagesNumber) {
console.log('Парсинг завершён.'); // Уведомление об окончании работы парсера
};
});
page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу
params.set('params[PAGE_NUM]', page);
return;
};
for (var i = page; i <= pagesNumber; i++) {
var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой
parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице)
};
return;
};
paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
Наш код изменился, но всё ещё похож на прошлый. Обратите внимание на ряд нюансов:
- Делаем не GET-, а POST-запрос, поэтому вместо метода axios.get() будем использовать axios.post() (строка 29).
- Используем интерфейс URLSearchParams для передачи и чтения найденных выше параметров сетевого запроса в особом формате (строки 14–23, 27 и 62–63).
- Немного затрагиваем получение данных из JSON-формата, но только в одной строчке (строки 32–33).
- На каждой странице сначала отдельно парсим закреплённую статью, а потом шесть обычных, следуя логике вёрстки сайта.
Процесс парсинга
Скриншот: Евгений Колесников для Skillbox Media
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
Ничто не вечно
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Заключение
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.

