NoSQL: что это за базы данных, для чего они нужны и как работают
Разным данным — разные хранилища.


Раньше данные онлайн-сервисов хранили преимущественно в реляционных базах (РБД) со строго определёнными схемами и связями между таблицами — независимо от количества и структуры данных. Но такие БД тяжело масштабируются и больше подходят для хранения структурированных записей — например, информации о заказах в онлайн-магазине или о пользователях.
С годами сервисы становились сложнее и чаще работали с неструктурированными форматами, такими как изображения, видео и аудио. Для их хранения требовались более гибкие и простые инструменты — так появились системы управления нереляционными базами данных, или NoSQL. О них и расскажем в этой статье.
Вы узнаете:
- что такое NoSQL;
- зачем понадобилась модель NoSQL;
- какие преимущества есть у баз данных NoSQL;
- как работают такие базы данных;
- для каких задач они подходят;
- какие они бывают.

Эксперт
Антон Смирнов
Эксперт Skillbox, программный директор факультета Data Science. Руководитель kongru.consulting, автор телеграм-канала «Аналитика сегодня». Более 12 лет в аналитике.
Что такое NoSQL
NoSQL (not only SQL, «не только SQL») — это термин, обозначающий технологии управления данными, отличных от SQL. К NoSQL относятся столбцовые, графовые, документоориентированные системы, а также системы по модели «ключ — значение».
Разница между реляционными и нереляционными хранилищами заключается в том, как они хранят содержимое.
В реляционных БД данные представлены в виде таблиц с фиксированным количеством столбцов. Обычно таблицы связаны друг с другом общими полями. Например, в таблице users может быть поле group, хранящее номер группы, в которой состоит пользователь. Это поле связывает users с таблицей groups, содержащей информацию о группах пользователей. Такая модель удобна, если мы работаем с однотипными данными.
А вот работать с данными разного формата в реляционных базах данных неудобно — нужно будет подгонять данные под единый стандарт. Поэтому жёсткая структура SQL не подходит, лучше добавлять сущности только с нужными полями. Такая возможность есть в MongoDB — одной из популярных NoSQL-СУБД. Она основана на документоориентированном подходе, о котором мы ещё расскажем подробнее.
Почему появилась модель NoSQL
Жёсткая структура из примера выше — не единственная проблема реляционных баз данных. Другие недостатки — медлительность, привязка к единой точке доступа, плохая масштабируемость и проблемы с обработкой больших объёмов данных. Это обратная сторона стандартов ACID, на которых строятся реляционные БД:
Атомарность (atomicity) — транзакция либо выполняется полностью, либо не выполняется вообще. Транзакцией применительно к базам данных называют действие или цепочку действий с базой данных: добавление, изменение, удаление записи и так далее.
Согласованность (consistency) — состояния до и после транзакции должны быть согласованными. Принцип напоминает закон сохранения массы в физике: ничего не исчезает бесследно и не появляется из ниоткуда.
Например, когда клиент банка переводит 100 рублей со счёта A на счёт B, баланс счёта A должен уменьшиться на 100 рублей, а баланс счёта B — увеличиться на ту же сумму.
Согласованность гарантирует, что даже в случае сбоя во время выполнения транзакции суммарный баланс обоих счетов не изменится. Например, если произошла ошибка после уменьшения баланса на счёте A, но перед увеличением баланса на счёте B, то база данных вернётся в состояние, в котором балансы счетов соответствуют бизнес-правилам.
Изолированность (isolation) — параллельно выполняющиеся транзакции не имеют доступа к промежуточным состояниям друг друга и отражают результаты так, как если бы они выполнялись последовательно.
Представьте ситуацию. Два клиента одновременно решили купить в интернет-магазине один и тот же продукт, который остался в единственном экземпляре.
Клиент A добавляет продукт в корзину, и система начинает транзакцию для резервирования товара. Практически одновременно клиент B выбирает тот же продукт и добавляет его в свою корзину.
Если платёж клиента A проходит успешно, система подтверждает покупку, а количество доступных товаров на сайте меняется (в нашем случае на 0).
Когда клиент Б завершит свою транзакцию, система уже будет понимать, что товар продан, потому отменит покупку.
Долговечность (durability) гарантирует, что после завершения транзакции изменения в базе данных сохраняются даже в случае сбоя.
Стандарты ACID делают РБД надёжной, но медлительной моделью хранения данных, плохо подходящей для высоконагруженных сервисов.
Это стало ясно по мере распространения интернета. Взрывной рост объёма обрабатываемых данных заставлял серверы работать на пределе, а программистов — подгонять данные под единый формат. Компаниям нужно было больше серверов и специалистов, а стоило всё это недешево. Было решено хранить информацию иначе.
Какие преимущества есть у NoSQL
В конце двухтысячных крупные компании стали использовать нереляционные СУБД, у которых было несколько существенных преимуществ в сравнении с традиционными системами:
- Возможность работать с любыми форматами данных позволяет обойтись одной БД для всех данных компании. Одну БД дешевле хранить и проще поддерживать.
- Базы данных NoSQL легко переносят горизонтальное масштабирование — если информации или запросов становится больше, достаточно добавить больше узлов. Реляционные базы придётся масштабировать вертикально, то есть переносить на более мощный сервер. Кроме того, NoSQL легче переносятся в облако.
- Высокая скорость обработки запросов упрощает быстродействие приложений в целом.
- Разрабатывать приложения с NoSQL легче. Команды разработчиков могут быстрее создавать и внедрять новые функции и сервисы.
Компании, которые сталкиваются с быстрым ростом объёма данных и нагрузки, могут легко и дёшево решить возникающие проблемы с помощью NoSQL. Эти преимущества демонстрируют стандарты архитектуры BASE, название которой расшифровывается как Basically Available, Soft state и Eventually consistent.
Базовая доступность (basically available) означает, что система доступна для чтения и записи всегда, даже при сбоях или других аномалиях. Цена компромисса — некоторые запросы могут вернуть промежуточные или частично некорректные результаты.
Гибкая согласованность (soft state) подразумевает, что состояние системы может меняться со временем для достижения согласованности.
Событийная согласованность (eventually consistent) означает, что согласованность данных может нарушаться, но с течением времени они придут в согласованное состояние. Это позволяет достичь более высокой доступности и производительности.
Таким образом, разработчики баз NoSQL отказались от стандартов ACID ради скорости и простоты масштабирования.
Как работают базы данных NoSQL
В отличие от реляционных баз данных с их жёсткой структурой, сущности в NoSQL не нужно подгонять под табличный формат. Разработчики вольны добавлять новые поля, удалять или изменять структуру данных для каждой сущности.
В качестве примера возьмём портал с обзорами и рейтингами фильмов. SQL-запросы для него будут выглядеть так:
# Таблица «Фильмы» с указанными полями
CREATE TABLE Films (
ID INT PRIMARY KEY, # Уникальный идентификатор фильма
Название VARCHAR(100), # Название фильма
Год_выпуска INT, # Год выпуска фильма
Жанр VARCHAR(50) # Жанр фильма
);
# Таблица "Оценки" с указанными полями
CREATE TABLE Ratings (
ID INT PRIMARY KEY, # Уникальный идентификатор оценки
ID_фильма INT, # Внешний ключ на ID фильма
Имя_пользователя VARCHAR(50),# Имя пользователя, который оценил фильм
Оценка DECIMAL(3, 1), # Значение оценки (например, 4.5)
Комментарий VARCHAR(200) # Комментарий к оценке (опционально)
);
# Вставка данных о фильмах в таблицу «Фильмы»
INSERT INTO Films (ID, Название, Год_выпуска, Жанр)
VALUES
(1, 'Назад в будущее', 1985, 'Научная фантастика'),
(2, 'Звёздные войны', 1977, 'Фантастика'),
(3, 'Крёстный отец', 1972, 'Драма');
# Вставка данных об оценках в таблицу «Оценки»
INSERT INTO Ratings (ID, ID_фильма, Имя_пользователя, Оценка, Комментарий)
VALUES
(1, 1, 'user123', 4.5, 'Отличный фильм!'),
(2, 1, 'moviefan456', 5.0, 'Лучший фильм всех времён!');В нереляционной базе данных каждый фильм можно представить в виде отдельного документа (если БД документоориентированная), содержащего все данные о фильме:
// Документ фильма в формате JSON
{
"ID": 1,
"Название": "Назад в будущее",
"Год_выпуска": 1985,
"Жанр": "Научная фантастика",
"Оценки": [
{
"Имя_пользователя": "user123",
"Оценка": 4.5,
"Комментарий": "Отличный фильм!"
},
{
"Имя_пользователя": "moviefan456",
"Оценка": 5.0,
"Комментарий": "Лучший фильм всех времён!"
}
]
}Если мы захотим добавить данные о наградах фильма, то вот как это будет выглядеть в SQL:
# Таблица «Фильмы» с указанными полями
CREATE TABLE Films (
ID INT PRIMARY KEY, # Уникальный идентификатор фильма
Название VARCHAR(100), # Название фильма
Год_выпуска INT, # Год выпуска фильма
Жанр VARCHAR(50) # Жанр фильма
);
# Таблица «Награды» с указанными полями
CREATE TABLE Awards (
ID INT PRIMARY KEY, # Уникальный идентификатор награды
Название VARCHAR(100), # Название награды
Год INT, # Год получения награды
Фильм_ID INT, # Внешний ключ на ID фильма
FOREIGN KEY (Фильм_ID) REFERENCES Films(ID) # Связь с таблицей «Фильмы»
);
# Таблица «Оценки» с указанными полями
CREATE TABLE Ratings (
ID INT PRIMARY KEY, # Уникальный идентификатор оценки
ID_фильма INT, # Внешний ключ на ID фильма
Имя_пользователя VARCHAR(50),# Имя пользователя, который оценил фильм
Оценка DECIMAL(3, 1), # Значение оценки (например, 4.5)
Комментарий VARCHAR(200) # Комментарий к оценке (опционально)
);
# Вставка данных о фильмах в таблицу «Фильмы»
INSERT INTO Films (ID, Название, Год_выпуска, Жанр)
VALUES
(1, 'Назад в будущее', 1985, 'Научная фантастика'),
(2, 'Звёздные войны', 1977, 'Фантастика'),
(3, 'Крёстный отец', 1972, 'Драма');
# Вставка данных об оценках в таблицу «Оценки»
INSERT INTO Ratings (ID, ID_фильма, Имя_пользователя, Оценка, Комментарий)
VALUES
(1, 1, 'user123', 4.5, 'Отличный фильм!'),
(2, 1, 'moviefan456', 5.0, 'Лучший фильм всех времён!');
# Вставка данных о наградах в таблицу «Награды»
INSERT INTO Awards (ID, Название, Год, Фильм_ID)
VALUES
(1, 'Оскар', 1986, 1), # Фильм «Назад в будущее» получил «Оскар» в 1986 году
(2, 'Золотой глобус', 1978, 2); # Фильм «Звёздные войны» получил «Золотой глобус» в 1978 годуНам пришлось создать новую таблицу «Награды» и установить связи между таблицами «Фильмы» и «Награды» с помощью внешнего ключа.
В документоориентированной базе данных код для этих операций будет выглядеть так:
// Документ фильма с информацией о наградах в формате JSON
{
"ID": 1,
"Название": "Назад в будущее",
"Год_выпуска": 1985,
"Жанр": "Научная фантастика",
"Оценки": [
{
"Имя_пользователя": "user123",
"Оценка": 4.5,
"Комментарий": "Отличный фильм!"
},
{
"Имя_пользователя": "moviefan456",
"Оценка": 5.0,
"Комментарий": "Лучший фильм всех времён!"
}
],
"Награды": [
{
"Название": "Оскар",
"Год": 1986
}
]
}Просто добавляем какие хотим пары «ключ — значение», не боясь что-нибудь сломать. Красота!
А теперь представим, что продакт-менеджеры поручили нам добавить новую фичу — список наград для каждого фильма. В случае с базой данных SQL нам пришлось бы выполнить следующую последовательность действий:
- Продумать схему внедрения данных.
- Создать новую таблицу «Награды».
- Установить связь с таблицей «Фильмы» с помощью внешнего ключа.
- Изменить код для вставки данных о наградах в таблицу.
Поскольку РБД требуют жёсткой структуры данных, то нужно будет заранее продумать схему интеграции. А если база уже прилично разрослась или активно используется в продакшене, то придётся попотеть: создать резервные копии данных, прописать и проверить сценарии миграции, обновить сопряжённые приложения и сервисы.
Изменение структуры в NoSQL делается в два шага:
- Просто добавим новое поле «Награды» в документы фильмов.
- Заполним это поле данными о наградах для каждого фильма.
Поэтому нереляционные базы используются в проектах, где структура данных часто меняется.
Если вы хотите узнать больше о различиях реляционных и нереляционных баз данных, то у нас есть об этом подробный материал.
Для каких задач подходят базы данных NoSQL
Базы данных NoSQL предлагают альтернативу традиционным БД на основе модели SQL. Это полезно, когда приложение должно быть легко масштабируемым и обладать высокой скоростью отклика и гибкостью, а строгой согласованностью можно пожертвовать.
Обычно NoSQL используется в высоконагруженных сервисах, которые предполагают высокую частоту запросов к БД, обработку больших объёмов данных, а также данных неопределённого или непостоянного формата. Например, в онлайн-играх, приложениях «интернета вещей» или системах аналитики.
Виды баз данных NoSQL
Рассмотрим основные виды нереляционных БД и напишем простые запросы на Python для записи и чтения данных.
Хранилища типа «ключ — значение». Самый простой вид технологии NoSQL. Данные хранятся в виде пар «ключ — значение». У каждого фрагмента данных есть уникальный ключ, по которому получают значение из этого фрагмента.
Такие хранилища похожи на телефонную книгу: имя абонента — это ключ, а номер — значение. Чтобы узнать номер человека, нужно извлечь значение, соответствующее его ключу, то есть имени:
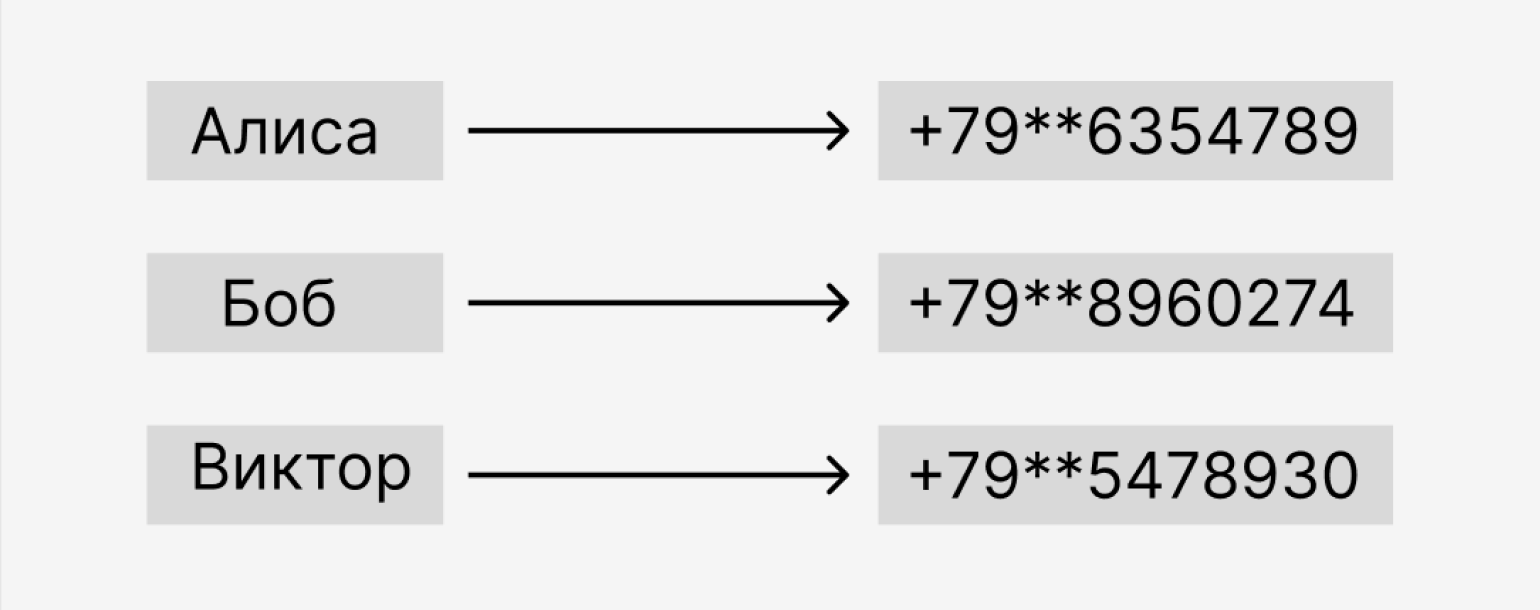
Ещё такой тип баз данных отлично подходит для автозамены. Слово с опечаткой заменяется на правильно написанное, а нецензурное выражение — на печатный синоним. Часто хранилища типа «ключ — значение» используют для журналирования запросов к другим БД.
Вот как выглядит запись и чтение данных в популярной БД такого типа — Redis:
# Подключение к Redis
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# Запись данных в хранилище
r.set('user123', '{"name": "Alice", "age": 30, "email": "alice@example.com"}')
# Чтение данных из хранилища
user_data = r.get('user123')
print(user_data)
# Выведет: b'{"name": "Alice", "age": 30, "email": "alice@example.com"}'
Другие хранилища типа «ключ — значение»:
Документоориентированные базы данных хранят данные в виде JSON— или BSON-документов. Каждый документ представляет собой отдельную запись, гибкая структура документа позволяет хранить сложные данные. Вот как выглядит запись и чтение документа в MongoDB — популярной документоориентированной базе данных:
# Подключение к MongoDB
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['blog_database']
collection = db['articles']
# Вставка документа в коллекцию
article_data = {
"title": "Introduction to NoSQL Databases",
"author": "John Doe",
"content": "NoSQL databases provide flexible data storage solutions..."
}
collection.insert_one(article_data)
# Получение документа из коллекции
article = collection.find_one({"title": "Introduction to NoSQL Databases"})
print(article)Другие документоориентированные базы данных:
В колоночных базах данные хранятся, как вы уже наверняка догадались, в виде колонок. Это обеспечивает удобное управление определёнными свойствами объектов. Если бы мы составили нашу фильмотеку в SQL-базе и захотели бы добавить информацию о том, можно ли посмотреть фильм в 3D, то пришлось бы создать отдельную таблицу «Доступность 3D» и заполнить большинство ячеек значением «Нет».
CREATE TABLE 3D_Films (
ID INT PRIMARY KEY,
Фильм_ID INT,
3D_доступен VARCHAR(3), # «Да» или «Нет»
FOREIGN KEY (Фильм_ID) REFERENCES Films (ID)
);INSERT INTO Films (ID, Название, Год_выпуска, Жанр, Режиссёр)
VALUES
(1, 'Назад в будущее', 1985, 'Научная фантастика', 'Роберт Земекис'),
(2, 'Звёздные войны', 1977, 'Фантастика', 'Джордж Лукас');
# Добавляем информацию о 3D-доступности
INSERT INTO 3D_Films (ID, Фильм_ID, 3D_доступен)
VALUES
(1, 1, 'Да'), # «Назад в будущее» доступен в 3D
(2, 2, 'Нет'); # «Звёздные войны» недоступны в 3DSELECT Films.Название
FROM Films
INNER JOIN 3D_Films ON Films.ID = 3D_Films.Фильм_ID
WHERE 3D_Films.3D_доступен = 'Да';В колоночной БД мы просто добавим свойство «Доступен в 3D» в объекты, где это уместно, то есть в карточки фильмов с 3D-версиями.
CREATE KEYSPACE film_library WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE film_library;
CREATE TABLE Films (
ID UUID PRIMARY KEY,
Название TEXT,
Год_выпуска INT,
Жанр TEXT,
Режиссёр TEXT,
"3D_доступен" BOOLEAN
);# Добавляем информацию о фильмах, включая 3D-доступность
INSERT INTO Films (ID, Название, Год_выпуска, Жанр, Режиссёр, "3D_доступен")
VALUES
(uuid(), 'Назад в будущее', 1985, 'Научная фантастика', 'Роберт Земекис', true),
(uuid(), 'Звёздные войны', 1977, 'Фантастика', 'Джордж Лукас', false);Запись и чтение в популярной колоночной БД Cassandra выглядят так:
# Подключение к Cassandra
from cassandra.cluster import Cluster
cluster = Cluster(['localhost'])
session = cluster.connect()
# Создание ключевого пространства (keyspace)
session.execute("CREATE KEYSPACE IF NOT EXISTS film_library WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}")
# Использование ключевого пространства film_library
session.execute("USE film_library")
# Создание таблицы для фильмов
query = """
CREATE TABLE IF NOT EXISTS Films (
ID UUID PRIMARY KEY,
Название TEXT,
Год_выпуска INT,
Жанр TEXT,
Режиссёр TEXT,
"3D_доступен" BOOLEAN
)
"""
session.execute(query)
# Вставка данных о фильмах
from uuid import uuid4
from datetime import date
# Добавляем информацию о фильмах, включая 3D-доступность
query = """
INSERT INTO Films (ID, Название, Год_выпуска, Жанр, Режиссёр, "3D_доступен")
VALUES (?, ?, ?, ?, ?, ?)
"""
session.execute(query, (uuid4(), 'Назад в будущее', 1985, 'Научная фантастика', 'Роберт Земекис', True))
session.execute(query, (uuid4(), 'Звёздные войны', 1977, 'Фантастика', 'Джордж Лукас', False))
# Запрос для получения фильмов, доступных в 3D
query = "SELECT Название FROM Films WHERE \"3D_доступен\" = ?"
result = session.execute(query, [True])
for row in result:
print(row.Название)Другие колоночные базы данных:
В графовых БД данные представляются в виде графа — структуры из узлов и рёбер, где узлы — это объекты, а рёбра — связи между ними. Такие БД позволяют эффективно выполнять запросы, связанные с многомерным анализом.
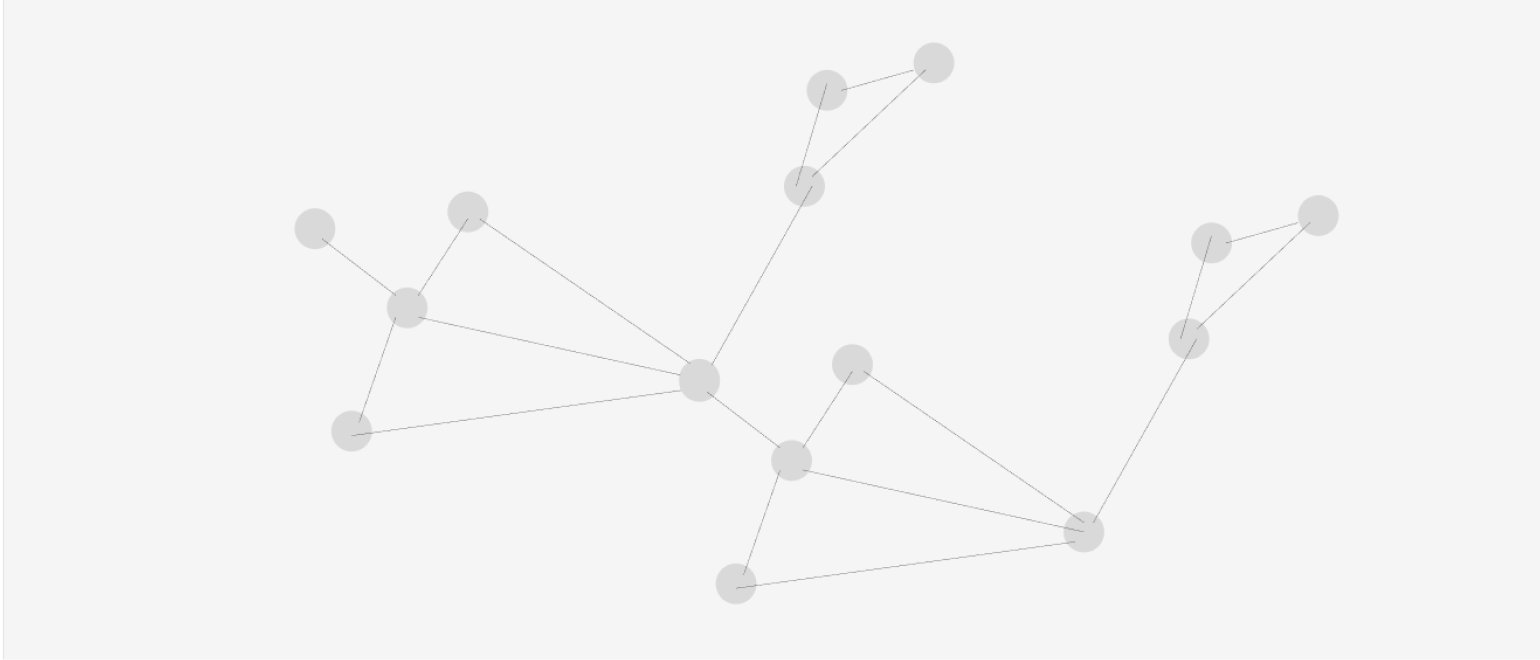
Социальная сеть может использовать графовую базу данных для хранения информации о пользователях (узлах) и их связях (рёбрах) — друзьях, подписках и так далее.
Так выглядят запросы в популярной графовой БД Neo4j:
# Подключение к Neo4j
from neo4j import GraphDatabase
driver = GraphDatabase.driver('bolt://localhost:7687', auth=('neo4j', 'password'))
# Создание узла и связи
with driver.session() as session:
session.run("CREATE (u:User {name: 'John'})")
session.run("CREATE (u:User {name: 'Alice'})")
session.run("MATCH (u:User {name: 'John'}), (u2:User {name: 'Alice'}) CREATE (u)-[:FRIEND]->(u2)")
# Получение данных
with driver.session() as session:
result = session.run("MATCH (u:User)-[:FRIEND]->(u2:User) RETURN u, u2")
for record in result:
print(record)Другие графовые базы данных:
Что дальше
Узнать больше о нереляционных базах данных можно из книг «NoSQL. Методология разработки нереляционных баз данных» Прамодкумара Садаладжа и Мартина Фаулера и «Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL» Эрика Редмонда. Также на Stepik есть неплохой бесплатный курс по работе с MongoDB в Python, а в Skillbox — большой курс по базам данных, который включает как SQL, так и NoSQL.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!



