NLP: что это такое и как она работает
Технология не для пикаперов, а для дата-сайентистов.


ChatGPT, GigaChat и подобные им программы могут удивить кого угодно — они не просто общаются с пользователем в чате, а могут подготовить ответ на письмо или даже сгенерировать изображение по нашему запросу. Как это стало возможным?
Их основа — NLP, или наука об обработке естественного языка, позволяющая компьютерам понимать и генерировать человеческую речь.
Сегодня разберёмся:
Что такое NLP
NLP (natural language processing), или обработка естественного языка, — это область искусственного интеллекта, задача которой — дать компьютерам возможность понимать и обрабатывать естественный язык. Это тот язык, который мы — люди — используем для общения между собой.
NLP как наука находится на стыке компьютерной лингвистики и технологии машинного обучения. С помощью обработки естественного языка компьютеры учатся вести беседы, отвечать на вопросы, переводить текст на разные языки или генерировать их с нуля. Машинам можно передать рутинные задачи, например попросить автоматически классифицировать заявки в службу поддержки по темам или языкам, на которых они написаны, отправляя их сразу к нужному специалисту.
Задачи NLP
С помощью NLP можно решить множество задач, связанных с обработкой естественного языка.
Распознавание речи. Компьютер может переводить голосовую речь в текст. Это требуется для любого приложения, которое выполняет голосовые команды или общается с человеком в чате. Например, так работают умные колонки с голосовым помощником Алисой.
Генерация естественного языка. Перевод структурированных, то есть табличных, данных, в текст на естественном языке. Можно сказать, что эта задача противоположна распознаванию речи.
Определение смысла слова. Компьютер может точно определить значение слова после семантического анализа предложения. Например, слово «замок» может иметь разные значения: «механическое устройство для запирания дверей» или «здание с фортификационными сооружениями». Задача NLP — определить, какой смысл имеет это слово в тексте.
Анализ эмоциональной окраски текста. Алгоритмы обработки естественного языка могут получать из текста его субъективные характеристики, например эмоции.
Определение перекрестных ссылок. Во время анализа текста он разбивается на токены — небольшие фрагменты, например отдельные слова. При дальнейшем анализе требуется сохранить и учесть их взаимосвязь.
Распознавание именованных сущностей. В текстах часто встречаются имена собственные: имя человека, название города, валюты и так далее. Задача NLP — правильно их выявить, чтобы корректно использовать при обработке текста и генерации ответа.
Кто и как использует NLP
NLP применяют в областях, где требуется обрабатывать и анализировать большие объёмы текстовой информации.
Маркетинг
Обработку естественного языка используют для анализа отзывов клиентов, чтобы понять, как улучшить продукт или услугу. С помощью парсинга можно собрать информацию о том, что говорят пользователи в социальных сетях. А затем провести семантический анализ, чтобы определить, насколько положительно отзываются о компании клиенты и какие проблемы есть у клиентов.
Чат-боты
На основе NLP работают многочисленные инструменты для генерации текстов, например ChatGPT от OpenAI, GigaChat от «Сбера» и YandexGPT от «Яндекса». Они отвечают на вопросы пользователей, генерируют тексты на разные темы и в разных форматах, составляют отчёты и так далее. Некоторые из них умеют рисовать изображения по текстовому запросу.
Скриншот: GigaChat / Skillbox Media

Читайте также:
Инвестиции
Инвесторам важно знать, что происходит с компаниями, акции которых они купили или только собираются приобрести. NLP может помочь проанализировать данные о них: новости, финансовые отчёты и упоминания в соцсетях. После этого алгоритмы машинного обучения можно использовать для создания структурированного отчёта для финансистов и инвесторов.
Такой сервис готов запустить один из крупнейших банков мира JPMorgan Chase. Подробности разработки новой нейросети для инвесторов держатся в секрете, но уже известно её имя — IndexGPT.
Право и юриспруденция
NLP помогает анализировать законы, судебные решения и договоры или составлять их с нуля. Один из таких сервисов ― Law ChatGPT.
Он генерирует разные варианты юридических документов. Например, можно сделать короткое соглашение о неразглашении конфиденциальной информации на русском языке за несколько секунд.
Медицина
Технологии NLP используются для озвучки текста в программах и устройствах для людей с нарушениями речи.
Синтезировать речь умели и 15 лет назад, но тогда для этого комбинировали предзаписанные MP3-файлы и она звучала неестественно. С помощью NLP можно превращать текст в речь в реальном времени. А ещё для каждого пользователя можно сгенерировать оригинальный и уникальный голос на основе его собственного.
С помощью синтезатора речи общался с миром известный учёный Стивен Хокинг. Он вводил текст в программу при помощи единственной мышцы на щеке, которой ещё мог двигать. Программа подсказывала следующие фразы, ускоряя набор, и затем преобразовывала текст в речь.
Робототехника
Роботы, которые взаимодействуют с человеком, должны правильно воспринимать и выполнять его команды. Здесь не обойтись без NLP — речь необходимо сначала перевести в текстовый формат, а затем в понятные для машины инструкции.
Человекоподобный робот София использует NLP, чтобы воспринимать речь и эмоциональное состояние говорящего, а также генерировать собственные ответы. Но до универсального интеллекта ей далеко. Обычно журналисты заранее передают разработчику Софии список вопросов, которые собираются обсудить с роботом.
Как работает NLP
Модели по обработке естественного языка складываются из двух составляющих — данных для обучения и специальных алгоритмов. Разберём каждый из этих пунктов.
Сбор данных
Для сбора данных дата-сайентисты используют два подхода: либо собирают их из открытых источников, например из социальных сетей, либо пользуются информацией, собранной компанией. Например, крупные онлайн-магазины могут обучать модели на истории заказов своих клиентов. Это становится возможным благодаря их объёму — информации о миллионах и десятках миллионов покупок.
Данные из открытых источников за счёт своего разнообразия помогают построить универсальные языковые модели. ChatGPT был обучен на большом массиве открытых данных, поэтому он одинаково хорошо генерирует как сказки, так и юридические документы.
Модель NLP можно собрать на данных одного человека. Например, сделать чат-бота, который будет имитировать речь и манеру общения своего живого прототипа. Инфлюенсер из США Карин Марджори сделала свою копию, которая может стать виртуальной девушкой для любого желающего — всего за один доллар в минуту. Виртуальная копия Карин обучалась на видео с её ютуб-канала.
Подготовка данных
Полученные на предыдущем этапе неструктурированные данные, к которым относится текст, необходимо предварительно обработать. Иначе наша модель их просто не поймёт.
Процесс проходит в несколько этапов:
Очистка данных. Первичные данные могут содержать в себе информацию, которая не нужна для работы или дублируется. Такие данные дата-сайентисты называют «грязными». Чем больше они загрязнены, тем сложнее модели будет понять, что важно, а что нет. Поэтому специалисты предварительно удаляют повторы, приводят строки к одному регистру и удаляют ненужные символы.
Токенизация. Чтобы модель могла работать с текстом на уровне смыслов, очищенные данные разбивают на отдельные единицы — токены. Токены могут быть словами, символами, фразами или другими элементами, в зависимости от задачи и контекста.
Примеры токенизации:
- Разделение текста на отдельные слова: Привет, как дела? → [Привет, ,, как, дела, ?].
- Разделение текста на символы: Hello → [H, e, l, l, o].
- Разделение текста на фразы: Купите сегодня и получите скидку 20%! → [Купите сегодня, и получите скидку, 20%!].
- Разделение текста на предложения: Мама мыла раму. Папа готовил ужин. → [Мама мыла раму., Папа готовил ужин.].
Токенизация позволяет преобразовать текст в структурированное представление, которое используется для дальнейшего анализа или обработки. Об этом мы расскажем дальше.
В русском и многих других языках есть суффиксы, которые меняют форму слова, но не его значение. Чтобы не путать программу, слова нужно привести к словарной форме — лемме, то есть провести лемматизацию. Например, леммой для слов «горячее» и «горячая» будет «горячий» (именительный падеж, единственное число).
Стемминг ― похожий процесс, когда вычленяется основа слова. Например, основа слова «горячий», «горячка», «горячо» ― «горяч».
Лемматизация и стемминг повышают эффективность обработки текстов, так как снижают количество уникальных токенов. Если мы разрабатываем поисковую систему, то можем добавить в словарь NLP-модели только одно слово «горячий», а не все его возможные формы. Модель будет работать быстрее, а памяти для хранения слов потребуется меньше.
Разметка данных. Каждому документу, фрагменту текста или слову, то есть токену, говоря языком дата-сайентистов, нужно присвоить метку, которая описывает, что за объект перед нами. Формат и содержание метки зависят от решаемой задачи.
Например, если мы создаём программу-переводчик, нужно указать, на каком языке написано каждое слово, а также обозначить часть речи, поскольку от этого зависит роль слова в предложении. Это помогает модели лучше ориентироваться в данных и выдавать более точные прогнозы.
Создание датасета. Размеченные данные перед обучением модели необходимо преобразовать в датасет — то есть структурировать.
Датасет выглядит как таблица токенов с релевантными для них признаками и метками. Для текстовых данных она хранится в формате CSV или JSON.
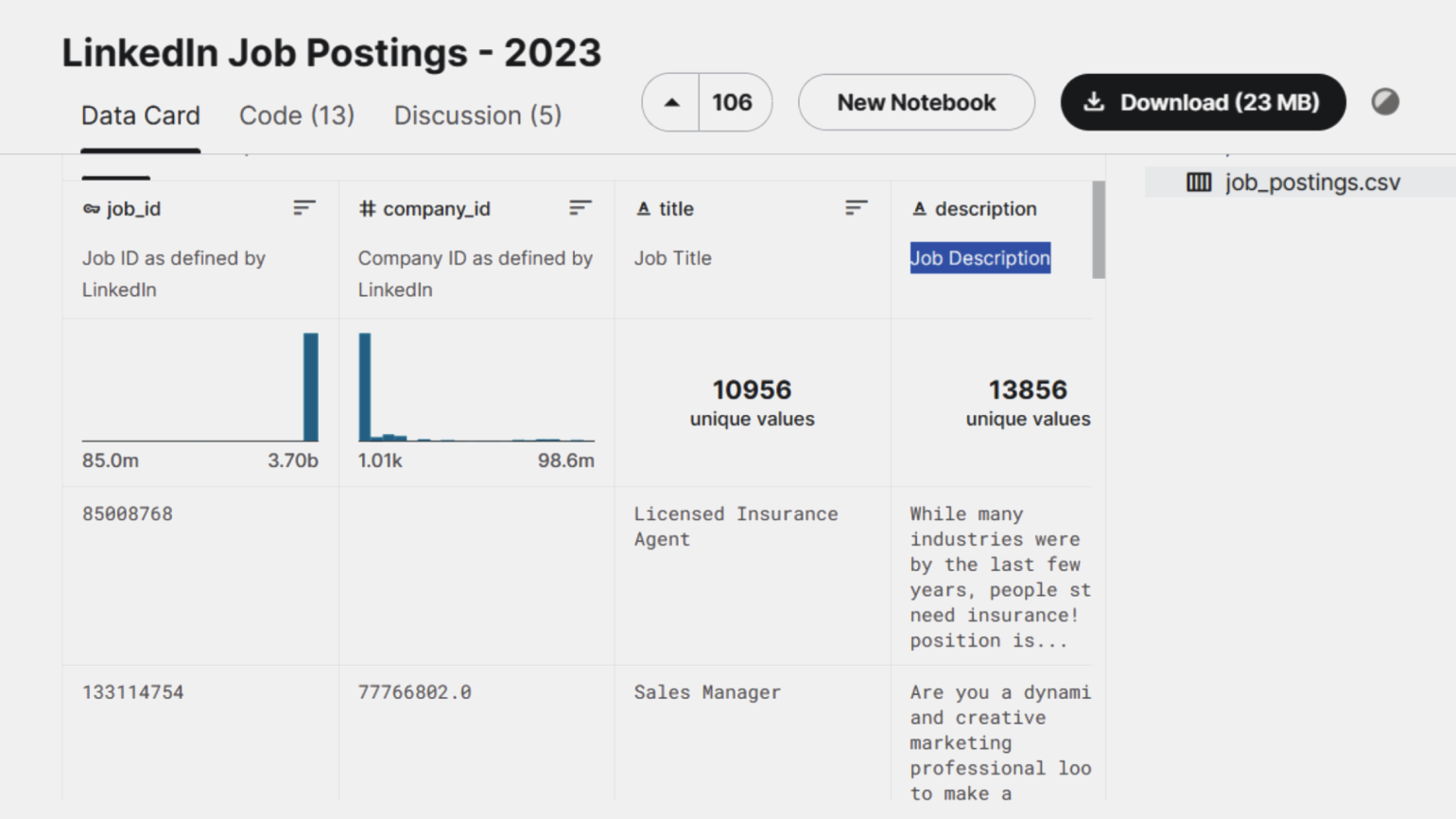
Скришнот: Kaggle / Skillbox Media
Выбор способа представления данных
Подготовленные данные нужно представить машине так, чтобы она поняла, что от неё требуется.
Для этого можно составить терм-документную матрицу:
| d1 | d2 | d3 | d4 | d5 | |
|---|---|---|---|---|---|
| Корабль | 1 | 0 | 1 | 0 | 0 |
| Море | 0 | 1 | 0 | 0 | 0 |
| Путешествие | 1 | 1 | 0 | 0 | 1 |
Она представляет текст в виде матрицы, где первый столбец — это токен, а первая строка — номер анализируемого документа. В ячейках на пересечении строк и столбцов показано, как часто определённые слова встречаются в конкретном документе. С помощью таких матриц тексты классифицируют по темам.
Другой популярный способ представления данных ― векторное представление слов (word embedding). Благодаря ему можно отследить, как анализируемые токены связаны с другими токенами в предложении или тексте.
Этот способ представления данных используется в машинном переводе, поисковых системах и чат-ботах, поскольку модель NLP в этих задачах должна воспринимать не просто отдельные слова в тексте, но и то, как они связаны между собой.
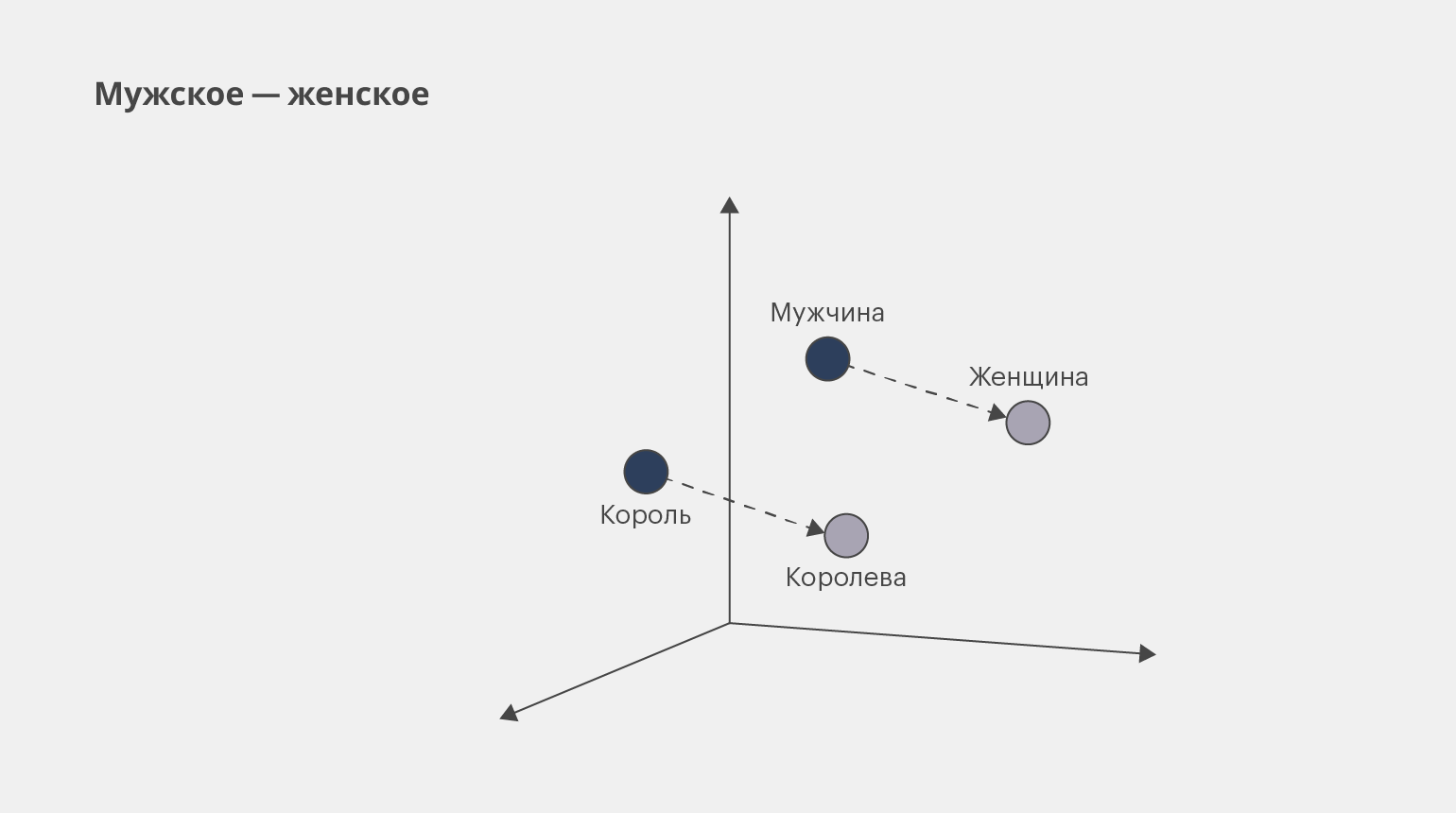
Инфографика: Майя Мальгина для Skillbox Media
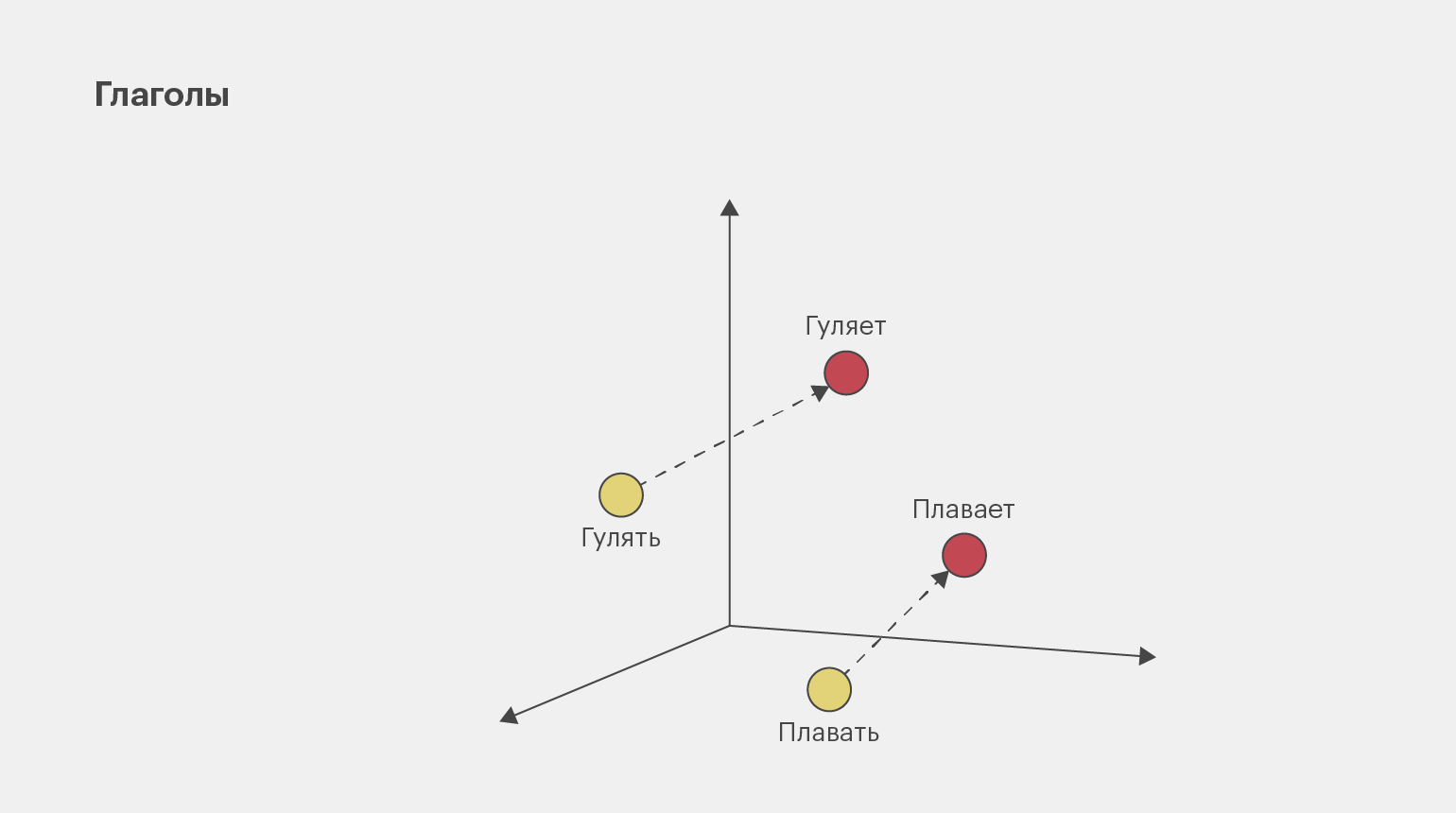
Инфографика: Майя Мальгина для Skillbox Media
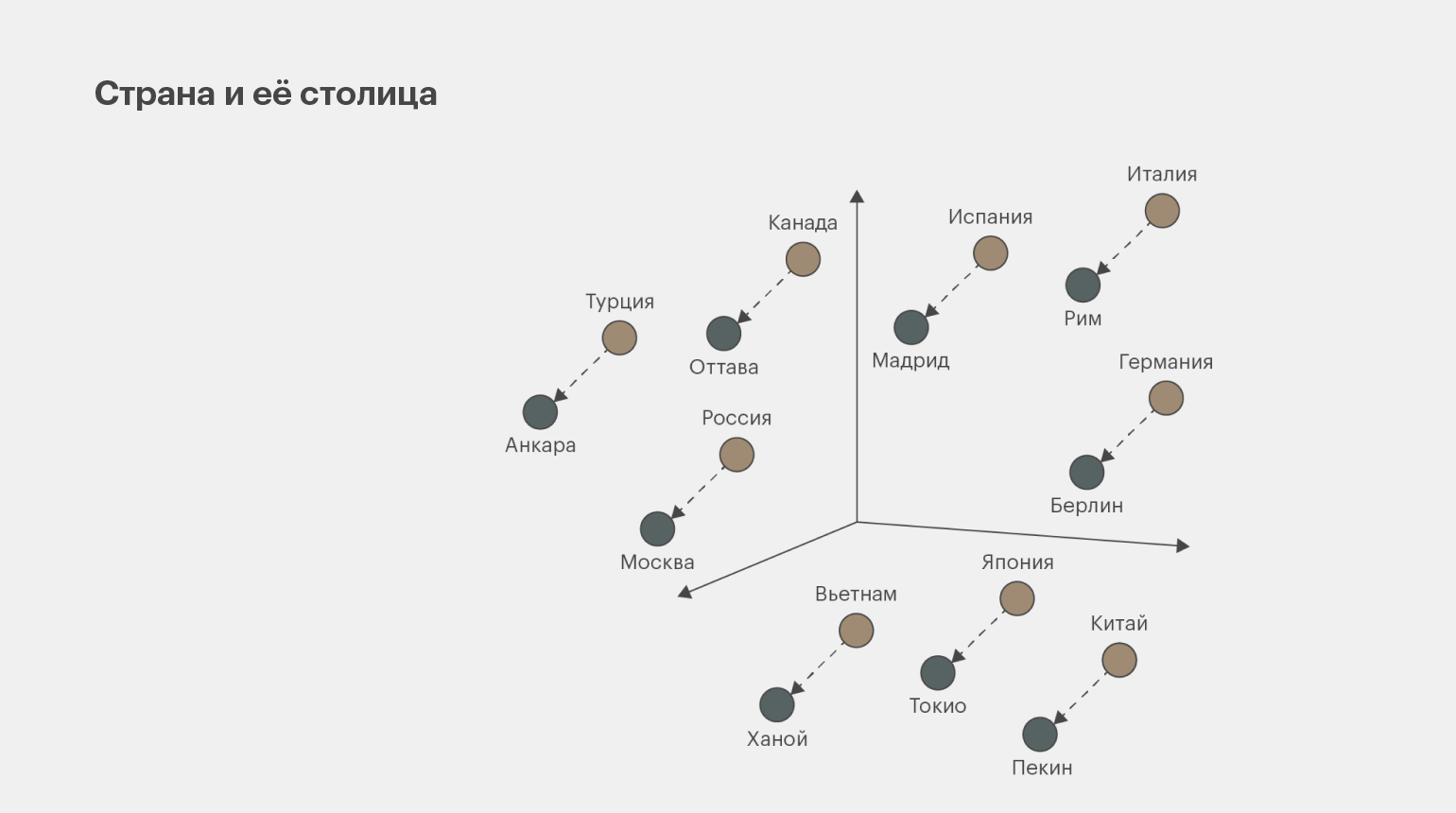
Инфографика: Майя Мальгина для Skillbox Media
Векторизация данных
На самом деле модели машинного обучения не умеют работать с текстовыми данными, а воспринимают только числа. Поэтому дата-сайентистам необходимо перевести токены в набор числовых значений.
Для этого существуют разные подходы. Два самых популярных — мешок слов и N-граммы. Мешок слов просто кодирует токены в цифры, учитывая их количество, но не учитывая контекст и конкретный порядок. При использовании N-грамм слова кодируются не по одному, а по два или три за раз. Благодаря этому сохраняется структура предложений и их контекст.
Применение алгоритмов машинного обучения
Заключительный этап работы в NLP — обучение модели на полученных данных с помощью специальных алгоритмов. Их можно написать с нуля или использовать готовые библиотеки, например NLTK, TextBlob и CoreNLP.
Для обработки естественного языка используют несколько основных алгоритмов:
- Наивный байесовский классификатор применяют для классификации текстов по тематикам на основе теории вероятностей. Например, так работают системы спам-фильтрации в электронной почте.
- Длинную цепь элементов краткосрочной памяти (LSTM, long short-term memory) используют для обработки последовательностей данных, чтобы учитывать общий контекст при обработке каждого слова. Такой подход применяют для генерации текстов.
- Нейронные сети, особенно рекуррентные нейронные сети (RNN) и трансформеры, участвуют в решении задач распознавания речи, машинного перевода и классификации текстов.
- Марковские модели применяют для анализа последовательностей слов и предсказания следующего слова в последовательности. Это полезно при переводе или генерации текста.

Выбор алгоритма зависит от типа и масштаба задач, которые стоят перед дата-сайентистом. Например, нейронные сети используют для анализа больших объёмов данных и построения больших языковых моделей. Последние могут не только понимать человеческую речь, но и генерировать её. Одной из самых известных больших языковых моделей является GPT-4 (Generative Pre-trained Transformer 4) от компании OpenAI, на базе которой построен ChatGPT.
Недостатки NLP
Несмотря на то что за последние годы инженерам удалось добиться больших успехов в NLP, предстоит решить ещё множество нетривиальных задач.
Компьютеры пока не понимают тонкостей значения слов, поэтому им сложно работать с омографами и омофонами: слова с разным смыслом могут иметь одинаковое написание и разное звучание или, наоборот, звучать одинаково, но написание будет различаться.

Пример проблемы с омонимами, когда написание слова совпадает, а значение различается. Компьютерам пока ещё трудно справляться с такими предложениями, как «Will, will Will will will Will Will’s will?» (пер. «Уилл, будет Уилл завещать Уиллу завещание Уилла?»). Google Translate, например, не может его правильно перевести.
К тому же понимать человеческую речь означает понимать эмоции. Одна из самых трудных для восприятия компьютером эмоций — сарказм. Модели NLP не всегда могут отличить серьёзный монолог от шутки.
Что почитать?
В этой статье мы рассмотрели только базовые принципы обработки естественного языка. Если вы хотите глубже погрузиться в тему NLP или даже написать собственную модель для распознавания текста, вот несколько ресурсов:
- «Обработка естественного языка в действии» Лейна Хобсона и других авторов.
- Natural Language Processing with Python Стивена Бёрда и других авторов.
- Курс «Нейронные сети и обработка текста» от Samsung Russia Open Education.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!

Курс с помощью в трудоустройстве

Профессия Data scientist + ИИ
- Реальные задачи от «СберАвтоподписки» и «СберМаркета»
- 8 сильных проектов в портфолио
- Спикеры из VK, ВТБ, «Сбера», Wildberries





