Как спроектировать архитектуру приложения с нуля
Пошаговое руководство для начинающих тимлидов и архитекторов.
Опытные разработчики знают, что любую систему — приложение или сервис — сначала необходимо спроектировать и описать. И только потом можно открывать редактор кода и переходить к реализации.
Но далеко не все делают именно так. Наоборот, многие команды сразу приступают к разработке на привычном технологическом стеке, имея лишь слабый набросок того, как должен выглядеть продукт.

Зачем нужно проектировать приложение
Может возникнуть вполне резонный вопрос: а зачем вообще тратить время на продумывание и подробное описание архитектуры?
Если пропустить этот шаг, то вы рискуете столкнуться с двумя крайне неприятными последствиями: результат вашей работы не будет соответствовать ожиданиям заказчика и, вполне вероятно, в будущем вам придётся потратить много сил на рефакторинг.
Образ приложения в голове разработчика может не совпадать с представлениями продуктового менеджера или владельца продукта. Может выясниться, что ваше решение не закрывает ключевые потребности пользователей, или закрывает не так, как надо, или не соответствует инфраструктуре компании. В результате придётся вносить множество изменений, а может, и вовсе переделывать проект.
Когда человек строит сложные системы в голове, то часто упускает из виду существенные детали и связи между компонентами. Они могут не выдерживать нагрузок, плохо масштабироваться. Скорее всего, проблемы вскроются ещё на этапе тестирования и код придётся рефакторить до или сразу после сдачи проекта.
Поэтому всегда описывайте структуру приложения, его компоненты и взаимодействие между ними в отдельном документе. Такое описание нужно согласовывать с коллегами и заказчиками — это позволяет синхронизировать видение проекта и убедиться в том, что ничего важного не было упущено.
В этой статье мы составим и опишем логику работы приложения, которое будет работать внутри существующей микросервисной архитектуры. Пройдём все этапы проектирования: от сбора требований до интеграции нового проекта с другими продуктами в компании.
Дисклеймер!
В этой статье я не показываю пример правильной архитектуры. Цель публикации — описать процесс мышления разработчика, который создаёт проект с нуля, и объяснить, как выстраивать процессы, чтобы получить продукт, устраивающий заказчика.
С чего начать: сбор информации и требований о продукте
Первым делом необходимо собрать полную информацию о разрабатываемом продукте. Для этого потребуется человек, который больше остальных в него погружён. Обычно это продуктовый менеджер или владелец продукта.
Сбор функциональных требований: мнения и вводные данные от заказчика
Собираем детальное описание продукта с точки зрения бизнеса:
- какие бизнес-цели мы ставим перед сервисом. Например, увеличение доли компании на существующем рынке;
- какие потребности бизнеса он закрывает. Например, продукт может быть направлен на максимизацию прибыли, а может — на повышение лояльности клиентов;
- какие требования к продукту есть у пользователей;
- какие функциональные требования и ограничения существуют со стороны компании;
- какие зависимости от других систем стоит учесть.
Будьте готовы к тому, что заказчик не сразу ответит на все вопросы, а ответы, скорее всего, будут поверхностными. Поэтому не стесняйтесь задавать уточняющие вопросы, а при необходимости договаривайтесь на новую встречу, дав собеседнику время на подготовку.
Ваша задача на этом этапе — получить максимально возможное количество информации о продукте и собрать её в один структурированный документ. Он нам ещё пригодится на следующих этапах.
Определение и описание нефункциональных требований
После того как вся доступная информация будет собрана, необходимо продумать нефункциональные требования. К ним относят аспекты работы приложения, которые напрямую не влияют на бизнес-показатели, но касаются пользователей и тех, кто будет поддерживать систему.
Нам нужно будет подумать о следующих факторах:
- доступность;
- изменяемость;
- производительность;
- безопасность;
- тестируемость;
- удобство использования;
- расширяемость;
- поддерживаемость;
- взаимодействие с другими системами.
Разберём подробно каждый пункт.
Доступность — это период времени, в течение которого система функционирует без сбоев. Идеальное значение — 99,99%. Все стремятся к этой цифре. Ведь если компания не хочет терять пользователей, приложение должно работать в режиме 24/7.
Изменяемость определяет то, насколько легко мы сможем вносить корректировки в продукт или его часть, не влияя при этом на остальную функциональность. Другими словами, систему надо проектировать таким образом, чтобы модификация той или иной части кода не затронула других частей системы.
Производительность — одна из самых понятных характеристик, которая показывает, какую нагрузку может выдержать система и не уйти в отказ. Ориентируйтесь не на среднестатистические, а на предельные показатели нагрузки. Чтобы получить значение, которое способна выдерживать ваша инфраструктура, нужно к этим экстремальным показателям прибавить ещё примерно 20%.
Безопасность — у системы не должно быть уязвимостей. Ориентируйтесь на список OWASP Top 10 и консультируйтесь со специалистами по информационной безопасности, если таковые имеются в компании.
Тестируемость — система считается тестируемой, если она легко «отдаёт» свои ошибки. То есть их легко выявить стандартными способами, например отладчиком или с помощью автоматизированного тестирования. Чем сложнее тестировать продукт, тем дороже его поддержка будет обходиться бизнесу.
Удобство использования определяет, насколько легко пользователю выполнять свои задачи и как быстро он может найти решение возникшей проблемы в документации или благодаря службе поддержки. Очевидно, что чем выше уровень удобства, тем лучше.
Расширяемость. Заказчик может решить через год добавить в приложение новые фичи для пользователя или для команды поддержки. При их разработке и внедрении старый код не должен мешать этому.
Поддерживаемость. Работа над продуктом не заканчивается после приёмки — его необходимо поддерживать, причём не только код, но и серверную архитектуру. Поэтому система должна быть удобной для тех, кто будет её использовать в дальнейшем. Например, если разработчики в компании работают на определённом стеке технологий, то желательно, чтобы продукт был написан на нём.
Взаимодействие с другими системами — так как сервис разрабатывается внутри имеющейся микросервисной архитектуры, то важно обеспечить его взаимодействие с другими компонентами системы. Это необходимо заранее продумать, так как существующие системы никто не будет подстраивать под разрабатываемые.
В любой компании параллельно идёт разработка десятков сервисов, поэтому попытки вносить изменения в существующий код для их запуска, приведут к хаосу. Поэтому компании проектируют микросервисы, подстраивая новые под уже работающие, а не наоборот.
Все перечисленные факторы необходимо расписать для создаваемой системы и оформить в том же документе, что и функциональные требования, собранные от заказчика на предыдущем шаге. Теперь общее описание можно передать на согласование заказчику.
Продумываем технические детали реализации приложения
После того как все требования согласуют, архитектор или разработчик может быть уверен, что его представление о продукте совпадает с видением заказчика. Теперь можно погружаться в технические детали.
Что собой представляет приложение и какие источники данных оно использует
Создание архитектуры приложения разберём на примере сервиса для крупного застройщика, который возводит элитные жилые комплексы по всей России и за рубежом. Все они объединены в общую IT-инфраструктуру.
Для него мы будем создавать сервис для оплаты услуг. Может показаться, что это будет легко. Но это не так — чем больше вопросов будет задавать архитектор, тем больше важных нюансов он узнает.
На первом этапе общения с заказчиком разработчик выяснил, что у компании тысячи жилых комплексов и коттеджных посёлков. Их жильцы оплачивают услуги ЖКХ, телевидение, интернет, вывоз мусора и так далее. Важно, что это не разовые платежи, а постоянные, совершаемые в разное время суток.

Управляющая компания каждого комплекса — отдельное юридическое лицо, не связанное с организацией, где работает команда разработчика.
Часть платежей от УК приходит в другой микросервис компании, который обрабатывает их и складывает данные о проведённых транзакциях в DWH. Это первый источник информации.
Второй источник данных — отчёты от управляющих компаний. Важный нюанс в том, что управляющие компании предоставляют данные в разных форматах. У кого-то это CSV-файлы, отправляемые на почтовый ящик, у кого-то это JSON, передаваемый по API и так далее.
Задача разрабатываемого микросервиса в том, чтобы сверять данные из DWH с данными, которые предоставляют управляющие компании. Это нужно для того, чтобы контролировать управляющие компании и внутренние системы на предмет сбоев и ошибок.
Разработчик предполагает, что пользователями системы будут сотрудники его организации, которых мы дальше будем называть саппортами, и им потребуется админка для отслеживания данных. Она будет находиться в отдельном микросервисе и сможет взаимодействовать с создаваемым приложением по API.
В логике приложения появились новые действующие лица — саппорты. Разработчик, исполняющий роль архитектора, должен обсудить с ними продукт и собрать информацию о том, какие функции и аспекты работы приложения они считают необходимыми. Параллельно можно узнать у саппортов, как они взаимодействуют с управляющими компаниями сейчас. Например, может выясниться, что они в ручном режиме сверяют Excel-файлы с самописными макросами, которые перешли к ним в наследство от предыдущих сотрудников.
Давайте суммируем все требования и условия, которые смог выяснить разработчик к этому моменту:
- микросервис должен обмениваться данными с DWH. Для этого можно использовать интеграцию по API;
- отчёты предоставляются в разных форматах и разным «транспортом»;
- управляющие компании запускают сверку в разное время суток;
- расчётные нагрузки на систему на одну сверку составляют от 1000 до 500 000 операций. Цифры получены после обсуждения сервиса с саппортами;
- текущее количество сверок — до 40 в день;
- у некоторых управляющих компаний есть отдельный подвид финансовых операций, которые должны обрабатываться вместе с другими операциями из одной транзакции;
- отчёты предоставляются посуточно с данными за предыдущий день;
- некоторые управляющие компании не присылают отчёты по выходным и праздничным дням. Поэтому их отчёты в понедельник содержат данные за несколько дней;
- данные в отчётах распределяются не ровно посуточно, а приблизительно посуточно. То есть не получится делать выборки ровно с 00:00:00 до 23:59:59. Это связано с тем, что управляющие компании работают в разных временных зонах и имеют разное время закрытия бизнес-дня;
- часто управляющие компании не присылают отчёты вовремя.
Также удалось сформировать ряд технических требований к продукту:
- код должен быть покрыт автотестами не менее чем на 98%;
- нужна система мониторинга;
- нужна система логирования.
От этих данных уже можно отталкиваться и переходить к проектированию.
Выбор стека технологий и первый набросок архитектуры
Лучший способ визуализировать внутреннее устройство продукта — представить его в виде диаграммы. Но, прежде чем это сделать, потребуется определить основной технологический стек.
Предположим, что в команде есть два PHP-разработчика, один фронтенд-разработчик и сам сеньор-разработчик (архитектор или тимлид), который занимается проектированием. Так как он не хочет собирать новую команду разработки под новый технологический стек, то будет использовать привычный для команды с актуальной версией PHP 8.2.
Что дальше? Ограничений по использованию фреймворков нет, а значит, можно выбрать между Symfony и Laravel. Архитектору стоит посоветоваться с командой, чтобы лучше понять их различия, преимущества и недостатки. Дополнительно можно почитать аналитические статьи со сравнением в профильных изданиях. Предположим, что решили остановиться на актуальной на текущий момент версии Symfony 6.4.

В проекте не обойтись без базы данных. Проще всего использовать реляционную БД, например MySQL или Postgres. Прежде чем выбрать конкретное решение, архитектор сравнивает их между собой и определяет, есть ли в команде разработки специалист по работе с конкретной базой данных.
Для нового сервиса была выбрана Percona Server for MySQL 8.0, так как с ней имеют опыт работы все члены команды, а у админов есть готовые настроенные пресеты, которые они смогут быстро развернуть на стенд.
У нас сформировался базовый технологический стек:
- PHP 8.2;
- Symfony 6.4;
- Percona Server for MySQL 8.0.
Теперь можно сделать первый набросок архитектуры приложения. Для этого подойдёт онлайн-сервис draw.io или любой аналог.
Итак, первый набросок архитектуры:
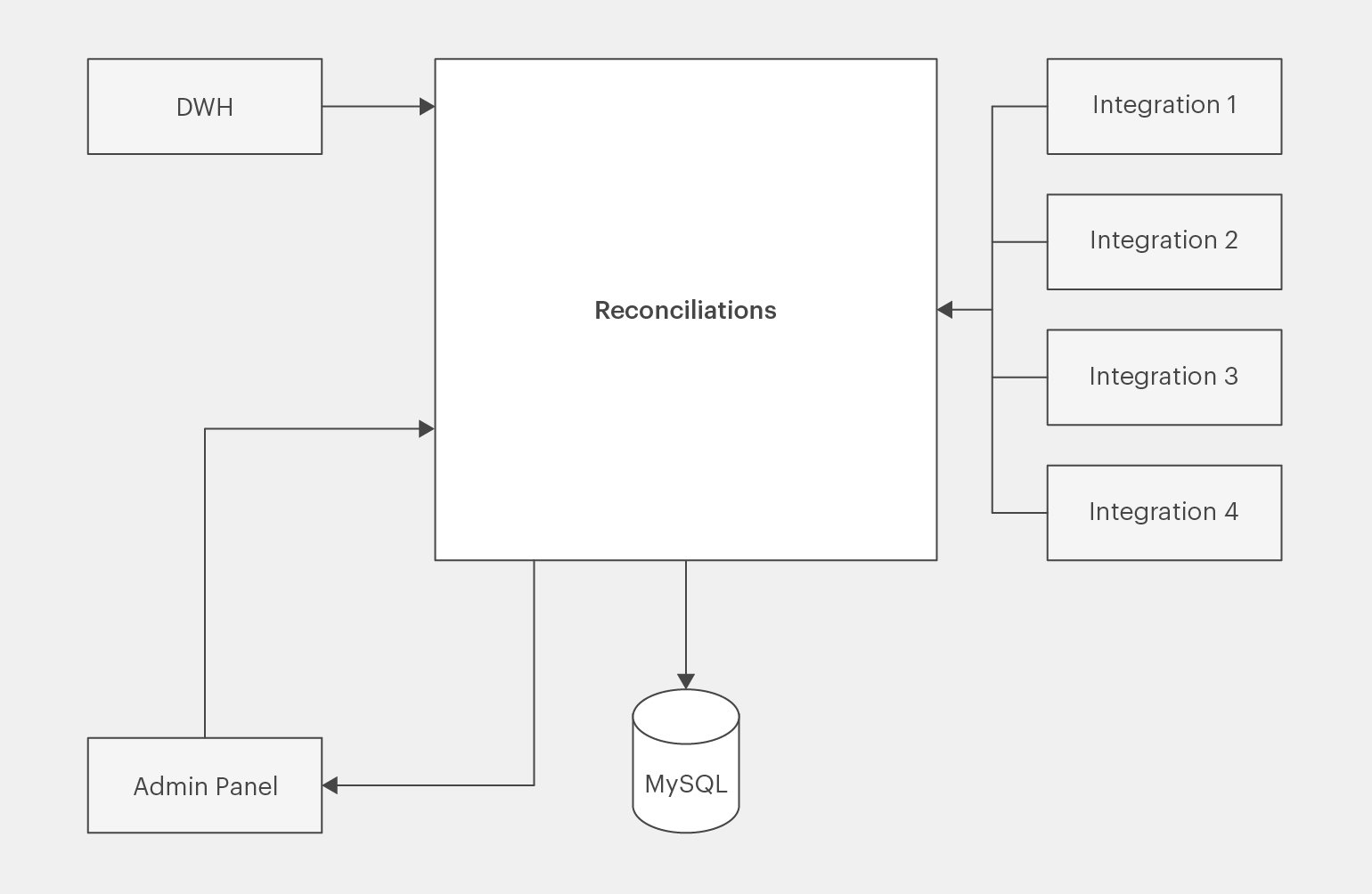
Инфографика: Майя Мальгина для Skillbox Media
Что же есть на диаграмме? Слева сверху расположен DWH, хранящий данные от компании. Справа на диаграмме указано несколько интеграций с управляющими компаниями, которые для краткости будем называть просто интеграциями. Также отмечена админка для управления сервисом, база данных и сам сервис в центре изображения.
Сейчас это общая диаграмма, которая показывает только то, как сервис взаимодействует с другими элементами. Но пока что неясно, что собой представляет он сам.
Определение ключевых сущностей в работе сервиса
Задача разрабатываемого сервиса — сверять пачки (чанки) операций между DWH и данными от управляющих компаний посуточно или около того. Если обобщить, то за какой-либо не полностью нормированный интервал, который чаще равен суткам и не превышает трёх дней. Напомню, что некоторые управляющие компании не работают в выходные, поэтому их данные накапливаются в течение субботы, воскресенья и понедельника.
Исходя из задачи сервиса можно определить, какие ключевые сущности он будет содержать.
Сразу запишем самые очевидные из них:
- DwhOperation — операция со стороны DWH, которой должна найтись пара на стороне вендора — управляющей компании через интеграции;
- VendorOperation — операция со стороны вендора;
- ReconciliationResult — результат сверки конкретных операций;
- ReconciliationTask — сущность, которая отражает процесс сверки;
- ReconciliationCalendar — календарь сверок, который будет регламентировать праздничные и выходные дни разных компаний.
Названия сущностей должны быть понятными и отражать то, что эта сущность делает. Пока что может быть сложно понять их назначение, но мы подробно разберём это дальше.
Далее я приведу атрибуты каждой сущности.
DwhOperation:
- operationId — основной идентификатор операции на стороне нашей компании;
- transactionId — транзакция в которую входит несколько операций;
- amount — сумма операции в заданных единицах;
- currency — валюта проведения операции;
- createdAt — дата и время создания операции по UTC;
- vendorPaymentId — идентификатор операции на стороне вендора;
- operationTypeId — тип операции: оплата, возврат, кешбэк, комиссия, списание по подписке и так далее;
- operationStatusId — статус операции: success, decline, outdated и другие.
VendorOperation:
- vendorPaymentId — идентификатор операции на стороне вендора;
- amount — сумма операции в заданных единицах;
- currency — валюта проведения операции;
- createdAt — дата и время создания операции, приведённое к UTC;
- operationTypeId — тип операции по версии вендора, который, вероятнее всего, не будет совпадать с нашими типами;
- operationStatusId — статус операции по версии вендора, который, вероятнее всего, не будет совпадать с нашими статусами.
ReconciliationResult:
- dwhOperationId — идентификатор операции DWH;
- vendorOperationId — идентификатор операции вендора;
- reconciliationTaskId — идентификатор задачи сверки, к которому относится результат сверки;
- status — статус сверки.
ReconciliationTask:
- id — идентификатор задачи сверки;
- reportDate — дата отчёта;
- status — статус задачи сверки;
- vendor — название управляющей компании;
- createdAt — дата и время создания задачи сверки;
- updatedAt — дата и время обновления задачи сверки;
- error — текст ошибки, если такая имеется.
ReconciliationCalendar
- id — идентификатор записи в календаре;
- date — дата;
- process — запускать процесс или нет (boolean-поле);
- vendor — название вендора;
- createdAt — дата и время создания записи в календаре;
- updatedAt — дата и время обновления записи в календаре.
Откуда взялись эти сущности и атрибуты? Их определил разработчик на основе всей собранной ранее информации. На этом этапе проектирования требуется включить воображение и подумать о тех сущностях, которые будут описывать бизнес-процессы продукта и события из реального мира.
Попробуем обобщить задачу. У компании есть операция на её стороне, которую необходимо сверить с операцией на стороне вендора и в результате получить какой-то результат сверки. Это может быть информация о том, что данные и результат операции у компании и вендора полностью совпадают. Всё это будет происходить в процессе, который мы назвали задачей (task) сверки, а для управления запуском этого процесса будем использовать календарь сверок.
Посмотрим на схему со всеми базовыми сущностями и их атрибутами:
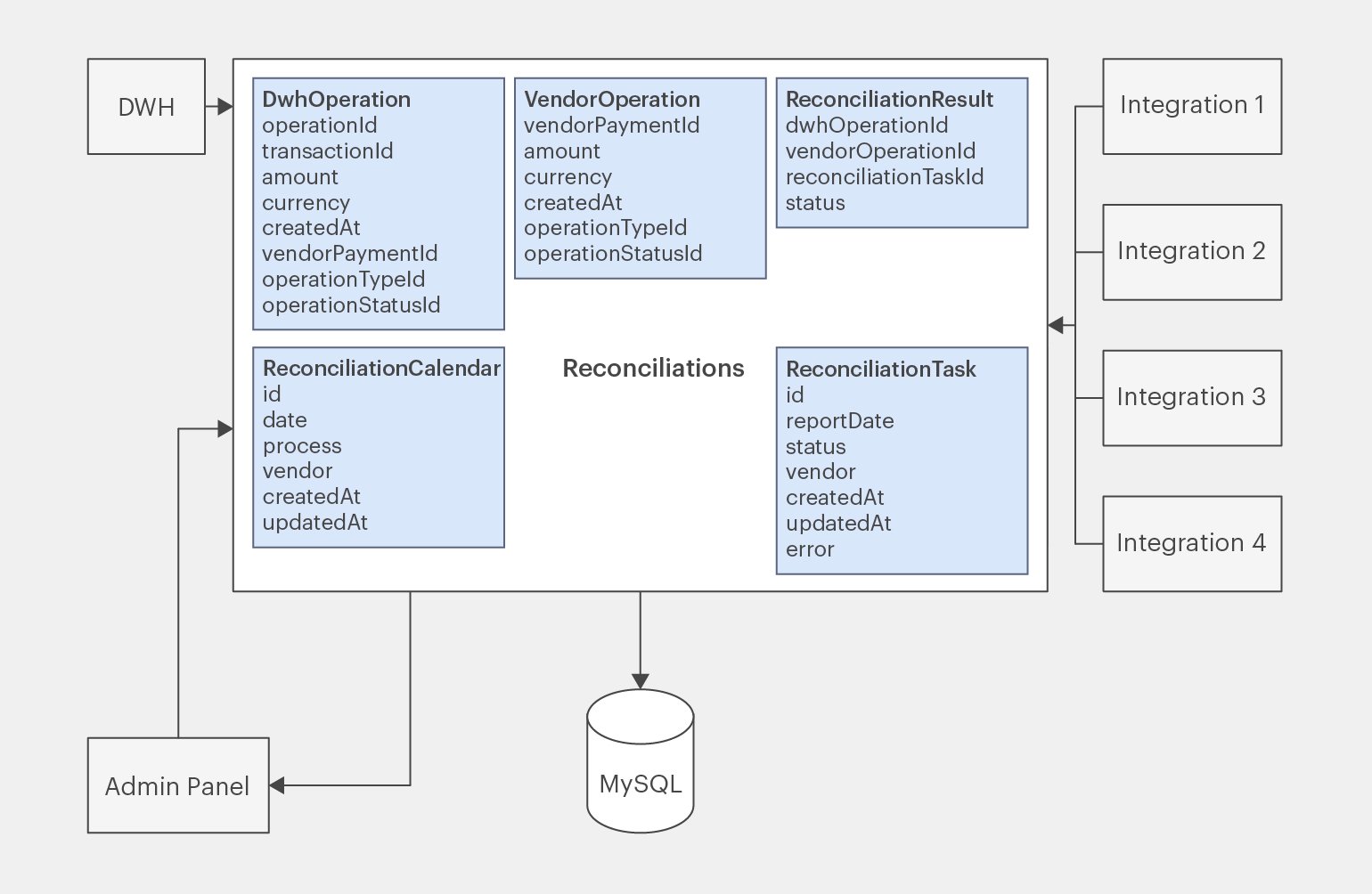
Инфографика: Майя Мальгина для Skillbox Media
Пока что картина далека от готового продукта, так как разработчик обозначил только основные понятия навскидку. Теперь пришло время добавить детализации и продумать, как будет происходить сверка.
Анализ данных и определение стадии работы продукта
Следующий шаг — подумать, как будет проходить процесс сверки с технической точки зрения. Сейчас известна только отправная и конечная точка, а что и как происходит между ними — неясно. Чтобы сервис работал, это нужно прописать.
Анализ данных и выбор ключей сопоставления
Разобраться в том, как проходит процесс сверки, помогут правильные вопросы:
- Как он будет запускаться?
- По какому алгоритму будет проходить процесс сверки?
- Как нужно делать выборки данных для сверки?
- Каков объём этих данных?
- Можно ли запустить параллельную обработку данных или их нужно обрабатывать в один поток?
- Как технически будет проходить передача данных?
- Как будет работать схема для вендоров, которые не прислали отчёт вовремя?
- Как выделить интерфейс для вендоров так, чтобы реализовать простые интеграции с каждым из них?
- Как реализовать систему расписания сверок?
- Как реализовать кастомизированные процессы сверок для компаний, у которых есть транзакционная сверка?
Начать стоит с глубокого изучения данных. Можно попробовать сверить небольшой кусок вручную или написать простейший скрипт, который сделает это автоматически. Такой подход поможет выявить довольно большое количество интересных деталей, которые потребуется учесть для построения правильной архитектуры нового приложения.
После анализа архитектору стало понятно, что нужно сопоставлять операции друг с другом по какому-то свойству. В текущей версии событий есть всего одно свойство, по которому это можно сделать, — vendorPaymentId, так как этот ключ есть и в операции DWH, и в отчётах вендора. Поэтому оно будет ключом для сопоставления операций.
Но известно, что у многих вендоров это поле не является уникальным и может содержать под собой несколько различных операций, например продажу и возврат. Поэтому ключ сопоставления следует сделать составным — он будет включать в себя vendorPaymentId и тип операции.
Определение вариантов сценариев сверки
Вопрос с ключами решён. Теперь можно рассмотреть сценарии сверки, которые будут возникать в процессе сопоставления операций.
Какие сценарии могут быть:
- мы смогли подобрать операции, и все их параметры полностью сошлись;
- мы смогли подобрать операции, но разошлась сумма;
- мы смогли подобрать операции, но разошлась валюта;
- мы смогли подобрать операции, но разошлась как сумма, так и валюта;
- мы нашли операцию на стороне DWH, но не нашли на стороне вендора данных;
- мы нашли операцию на стороне вендора данных, но не нашли на стороне DWH.
Отправной точкой сверки является отчёт, так как в нём данные уже каким-то образом привязаны к временному интервалу. Так как данных может быть очень много, то проводить поиск поштучно не лучший вариант. Это приведёт к повышенной нагрузке на DWH и всю сеть в целом.
Значит, необходимо сначала получить данные от вендора и только затем из DWH, выбрав те, которые присутствуют в отчёте управляющей компании. Это можно сделать запросом по ключам сопоставления. Но если ограничиться только такой выборкой, то не получится закрыть сценарий, когда операция нашлась на стороне DWH, но не нашлась на стороне вендора.
Возникает вопрос: как это учесть? Самый очевидный способ — делать выборку по времени, например с даты и времени создания операции, сверенной последней в предыдущем таске сверки, и до даты и времени создания операции, сверенной последней в текущем таске сверки. Таким образом мы сможем выбрать все операции из DWH, которые подпадают под интервал операций в отчёте вендора данных.
Но как это реализовать? Необходима стадийность сверки, так как некоторые процессы внутри неё не могут идти параллельно, а значит, их нужно запускать последовательно друг за другом. При этом каждая стадия будет опираться на данные, полученные на предыдущей стадии.
Таким образом, у разработчика-архитектора появляется понимание того, что у сверки должны быть стадии и результат работы получается только по итогу прохождения через каждую из них.
Сразу возникают новые вопросы:
- Какие это будут стадии?
- Сколько их будет?
- Как они будут взаимодействовать друг с другом?
- Какой транспорт данных будет между стадиями?
Без ответов на эти вопросы идти дальше не стоит. Надо вновь подумать и представить логику всего процесса.
У нашего архитектора получится такой список стадий сверки:
1. initiated — стартовая стадия. Запускается, когда становится понятно, что необходимо что-то сверить. На этой стадии создаётся таск сверки, в который передаются необходимые для этого параметры: название вендора, дата сверки и так далее.
2. get_vendor_operations — на этой стадии сервис получает и сохраняет ответ от вендора. Здесь появляется хороший вопрос — куда мы всё это сохраняем? Вернёмся к нему позже.
3. get_dwh_operations — стадия получения данных из DWH для сверки по ключам сопоставления.
Стадии 2 и 3 можно было бы объединить. Но в этом случае стадия будет перегружена из-за выполнения двух логических действий — одновременного получения данных от вендора и из DWH. Так как стоит придерживаться принципов SOLID, то её лучше разделить на две.

4. reconciliation_by_keys — сверка по ключам сопоставления. В этот момент сервис получает список первых результатов сверки, а также дату и время последней, сверенной в текущем таске сверки, операции.
5. get_dwh_operations_by_interval — получение данных из DWH по интервалу. Интервал, как мы помним, определяется датой и временем операции, сверенной последней в предыдущем таске сверки и датой и временем операции, сверенной последней в текущем таске сверки. Эту дату сервис выявил на предыдущей стадии.
6. reconciliation_by_interval — сверка операций по интервалу.
7. reconciliation_results_saving — сохранение результатов сверки. Для упрощения будем считать, что результат сверки сохраняется в DWH, а не в отдельное хранилище.
8. finish_reconciliation — закрываем все процессы, формируем данные для админки и завершаем процесс сверки.
Так как нам точно потребуется API для работы с админкой, то сразу запланируем его наличие.
Посмотрим на схему с внесёнными дополнениями:
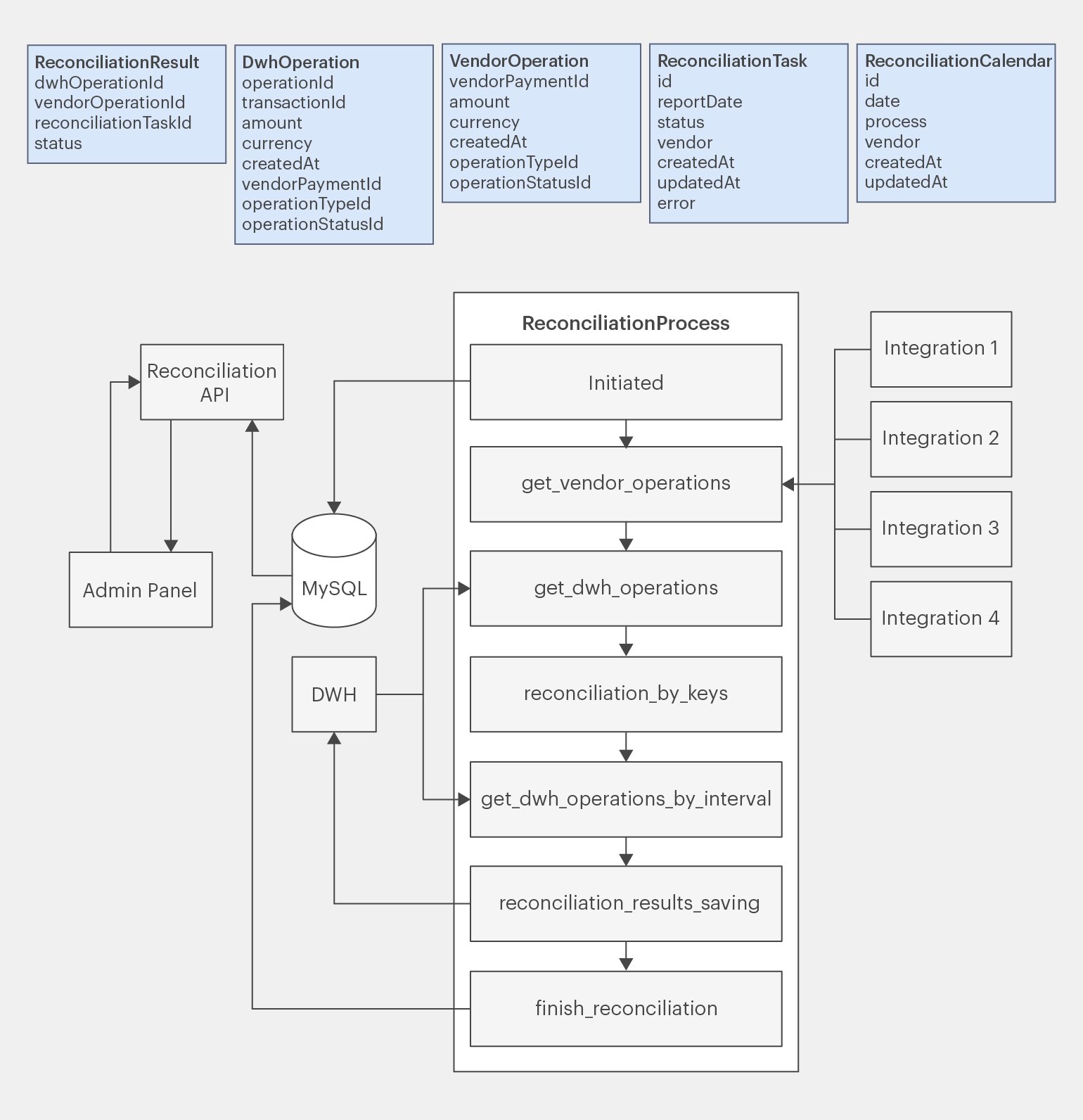
Инфографика: Майя Мальгина для Skillbox Media
Схема стала более полной, но пока остаются открытые вопросы. Например, непонятно, как сверка будет запускаться, как будет осуществляться транспорт данных, взаимодействие классов и так далее.
Построение системы сверки
Первый вопрос, который должен задать архитектор: как будет запускаться каждая сверка? Пока что неизвестно, что будет для неё триггером и как это будет работать в деталях.
Прежде чем найти решение, стоит подумать о том, каким образом будет построена работа приложения в целом. Прояснить это помогут следующие вопросы:
- Запуск будет происходить командой из интерфейса командной строки?
- Можно ли будет управлять запуском из интерфейса?
- Каждая стадия должна запускаться автоматически?
- Что будет переключать стадии?
- На чём будет работать стадийность — на кронах или на очередях или, возможно, каким-то другим способом?
Допустим, в нашем примере разработчик отказался от ручного запуска и хочет, чтобы всё происходило автоматически. То есть возможности управлять стадиями через интерфейс не будет.
Значит, остаётся выбрать, на каком подходе будет построена система стадий и вся сверочная линия в целом. Архитектор решает рассмотреть три возможных варианта реализации.
Вариант 1
Сделать приложение линейным и запускаемым по крону в одном процессе
Преимущества:
- простая реализация;
- кратчайшие сроки разработки.
Недостатки:
- низкая производительность;
- если в системе что-то упадёт, то упадёт и весь процесс без возможности восстановления;
- тяжёлая поддержка — долгие процессы сложнее мониторить;
- отсутствие масштабируемости;
- отсутствие возможности перезапуска конкретной стадии;
- расписание запусков придётся хранить в операционной системе. Это плохо, так как расписание относится к бизнес-логике самого приложения;
- аллокация большого количества ресурсов сервера на долгий срок.
Вариант 2
Сделать приложение на очередях с запуском из-под супервизора
Преимущества:
- аллокация ресурсов сервера на короткие промежутки времени;
- масштабируемость;
- возможность перезапуска стадий;
- организовать мониторинг проще, чем в предыдущем варианте.
Недостатки:
- более сложная реализация по сравнению с вариантом с кронами;
- срок разработки больше.
Вариант 3
Сделать приложение на очередях с параллельно запускаемыми стадиями
Преимущество: можем потенциально выиграть время и повысить скорость обработки данных. Но это не точно!
Недостатки:
- очень сложная реализация;
- долгая разработка;
- есть вопросы к целесообразности решения для этой задачи.
Исходя из предложенных вариантов, архитектор делает вывод, что лучший вариант второй — очереди с супервизором.

Важно! Мы описываем абстрактный пример, и этот вариант архитектуры, возможо, не самый оптимальный. Но для понимания общего подхода к созданию архитектуры приложений его будет достаточно.
Теперь важно решить, как будет запускаться приложение и кто будет управлять переключением стадий.
Определяем порядок запуска приложения и подход к управлению переключением стадий
Предположим, что время запуска не нужно указывать с точностью до секунды, а значит, в настройках каждой интеграции можно использовать cron-подобное расписание, то есть выполняющее задачи в определённое время. Поэтому в приложении пригодится какой-то класс, консольная команда, которая будет запускаться раз в минуту, сверять часы и анализировать, исходя из настроек интеграций и календаря ReconciliationCalendar, какие сверки стоит запустить в конкретную минуту.
Проще всего это сделать консольной командой, внутри которой будет логика запуска с последующим вызовом функции sleep, которую впоследствии поставим под супервизор. Назовём этот класс ReconciliationStarter. Он будет создавать таски в очередь на обработку и таски для сущности ReconciliationTask.
Как будет устроено управление процессами стадий? Для этого создаётся класс ReconciliationManager. Это демон, обрабатывающий свою собственную очередь и переключающий стадии сверок по их завершении.
Если архитектор посмотрит на схему, то поймёт, что предусмотрел не все поля сущностей. Необходимо добавить новые:
ReconciliationResult.additionalInfo — п оле для хранения детализированной информации о найденных расхождениях между операциями.
ReconciliationTask.attempts — счётчик количества попыток свериться. Он необходим, так как ряд вендоров может присылать отчёты не по расписанию, а с опозданием. В этом случае нужнам механика перезапуска отдельной стадии по отложенному таймеру. Это как раз позволяет реализовать выбранный вариант реализации стадийности.
ReconciliationTask.duration — будет хранить среднее значение времени работы одной сверки.
ReconciliationTask.lastOperationDt — поле для сохранения даты и времени последней сверенной операции в таске сверки в таймзоне UTC.
ReconciliationTask.comment — необязательное поле с комментарием от саппорта к таскам сверки.
Детализация процессов
Остаётся несколько важных технических и архитектурных вопросов:
- Как будет происходить передача данных между стадиями?
- На чём должны быть реализованы очереди?
- Как обрабатывать разные форматы отчётов?
- Как обрабатывать специфические случаи?
Разберём вопросы по порядку, начав с транспорта данных. Какие технологии доступны команде разработки? Что принято использовать в компании? С чем разработчики из команды имеют опыт работы?
Представим, что после ответа на эти вопросы остаётся два кандидата — это Memcached и Redis. Обе технологии доступны и используются в компании, и с обеими из них у команды есть опыт работы. Так какую же выбрать, если обе такие хорошие?
В таких случаях полезно смотреть на исходное предназначение инструментов и их различия.
Memcached — высокопроизводительный сервис, работает быстро вне зависимости от количества хранимых данных. Быстрее, чем Redis. Можно сказать, что это хранилище «ключ — значение», поддерживающее атомарные операции. Длина ключей может достигать 250 байт, а объём данных под одним ключом — 1 МБ.
Redis поддерживает большое количество типов данных. Он умеет периодически сохранять информацию на жёсткий диск и позволяет хранить до 512 МБ данных в значениях. Redis поддерживает master-slave-репликацию, и его можно использовать в качестве постоянного хранилища данных. Он однопоточный.
Возможно, выбор здесь будет не совсем очевиден, но для этого приложения Redis избыточен, так как данные нужно не хранить на постоянной основе, а только передавать между стадиями сверки. Поэтому архитектор выбирает Memcached.
Следующий вопрос — очереди. Здесь тоже есть несколько вариантов — Kafka, Gearman и RabbitMQ.
Предположим, что с Gearman в команде никто не работал и под него нужно писать клиент с нуля, а это займёт много времени — поэтому он отпадает.
У Kafka большая пропускная способность в сравнении с RabbitMQ, и он легко масштабируется. RabbitMQ умеет в сложную маршрутизацию и поддержку различных протоколов — это его основные преимущества, но в нашем приложении они не нужны. Поэтому выбираем Kafka.
Остаётся два открытых архитектурных вопроса и уже ощутимо разросшаяся диаграмма продукта, которая теперь выглядит так:
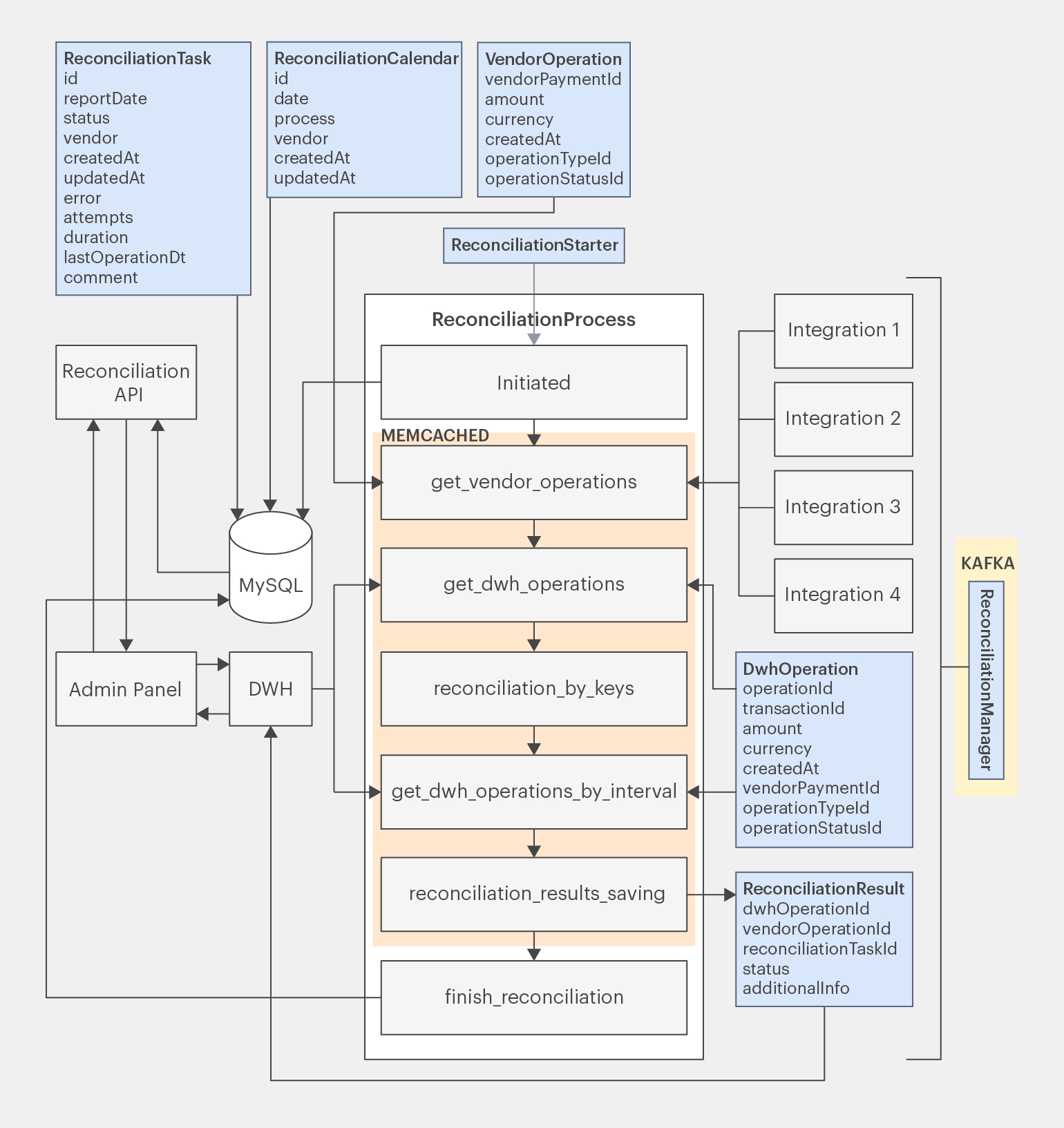
Инфографика: Майя Мальгина для Skillbox Media
На схеме обновлены сущности, добавлены связи между админкой и DWH, указано, какие сущности хранятся и взаимодействуют с БД, размещены Kafka и Memcached.
Завершение работы над системой
Необходимо решить вопросы настраиваемой обработки отчётов и работы с различными форматами данных, поступающих от вендоров. Напомним, что эти данные предоставили саппорты на первом этапе сбора информации.
В поиске ответов помогут паттерны проектирования и ООП.

Читайте также:
Первым делом предстоит решить вопрос с различными форматами и другими различиями между вендорами. При этом процесс сверки будет одинаковым почти для всех них и для большинства операций. Различаются лишь форматы данных и некоторые аспекты реализации интеграций с вендорами.
Поэтому можно выделить базовую и интеграционную части. Для интеграционной части потребуется оформить какой-то интерфейс, с которым будет работать базовая часть. А в ней будут расположены операции сверки DwhOperation и VendorOperation.
Давайте попробуем определить интерфейс для интеграции — ReconciliationInterface:
public function getVendorData(): VendorOperationCollection — метод предполагает, что интеграция с вендором вернёт коллекцию объектов VendorOperation. Он будет вызываться на стадии get_vendor_operations.
public function getVendorReconciliationKey(VendorOperation): string — этот метод позволит доставать ключ сопоставления из любого поля VendorOperation.
public function canOperationsBeMatched(DwhOperation, VendorOperation): bool — метод определяет, можем ли мы сравнивать операции, например, по типу, если они совпали по ключу сопоставления.
public function compareOperations(DwhOperation, VendorOperation): ReconciliationResult — метод, который будет сверять данные из двух операций по их свойствам.
Такой интерфейс позволяет парсить отчёты в разных форматах и даже обращаться за данными в API. Кроме этого, можно использовать различные ключи сопоставления для операций и проводить дополнительные проверки для определения фактической возможности сверки двух операций.
Отдельно стоит упомянуть о возможности сверять операции в разных интеграциях. Например, в одной сверке мы сверяем у операций сумму, номер кошелька и фамилию пользователя, а в другой — номер карты и валюту. Всё это реализуется за счёт архитектуры в одном контуре с подменной только части кода.
Посмотрим на схему с добавленным интерфейсом:
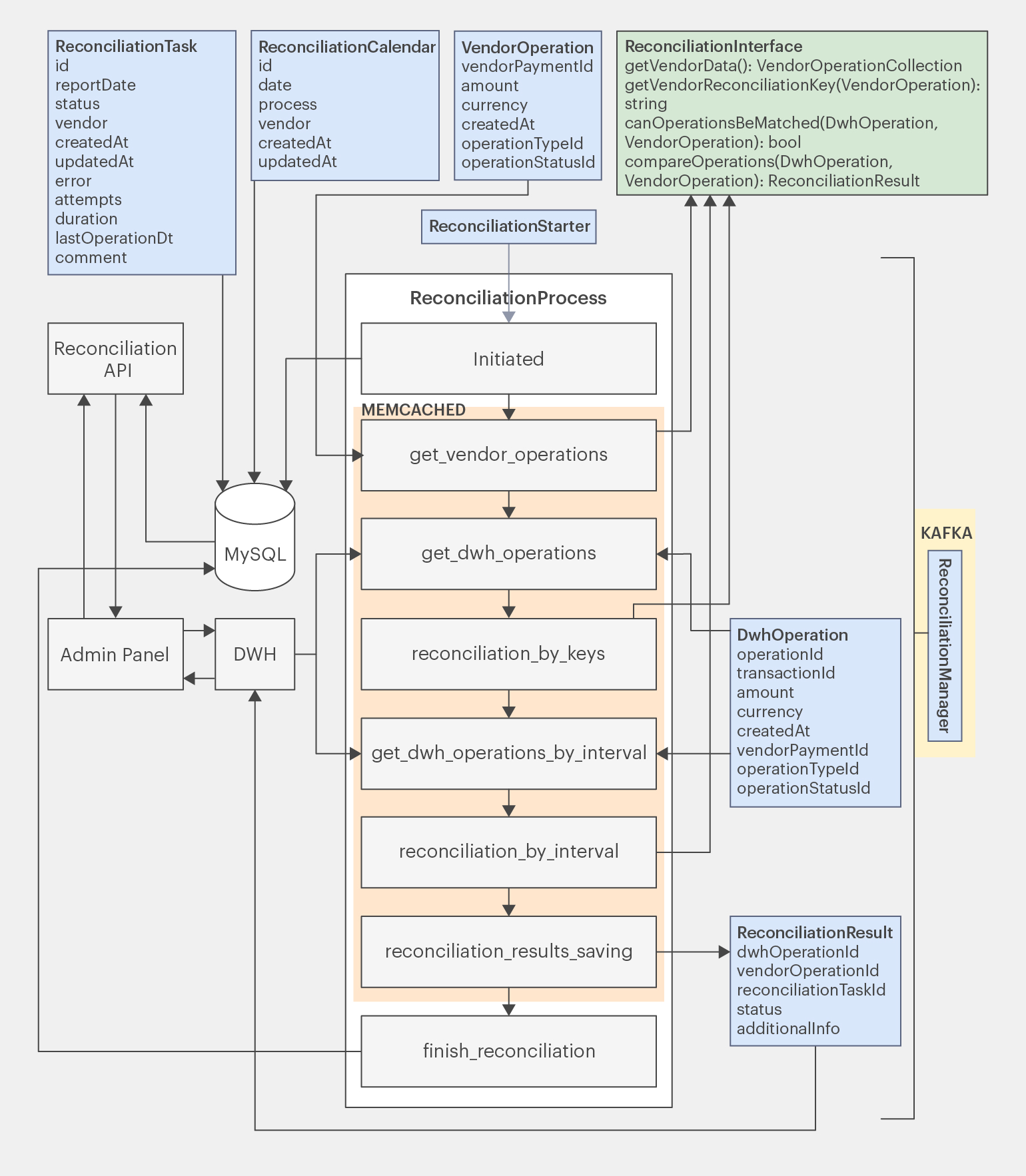
Итак, на схеме появился ReconciliationInterface и одна новая стадия, которую архитектор забыл отобразить ранее — это reconciliation_by_interval. Забыть что-то добавить на диаграмму очень просто, поэтому полезно повторно проходить по ней, повторяя логику приложения.
Остаётся один нерешённый вопрос — как разрешить проведение кастомизированных транзакционных сверок при условии необходимости сверки нескольких операций?
Тут нам поможет дополнительный интерфейс, который будет опционален для реализации, в отличие от ReconciliationInterface, под названием CustomReconciliationInterface. У него будет всего один метод:
public function reconcileOperations(DwhOperations, VendorOperations): ReconciliationResultCollection. Этот метод позволит сверять те операции, которые имеют полностью кастомную функциональность сверки. В него будут передаваться оставшиеся несверенные операции вендора и DWH, а на выходе будет ожидаться коллекция объектов ReconciliationResult.
Теперь нужно определиться с местом его вызова. Лучше всего предусмотреть для этого отдельную стадию custom_reconciliation.
Обновлённая схема:
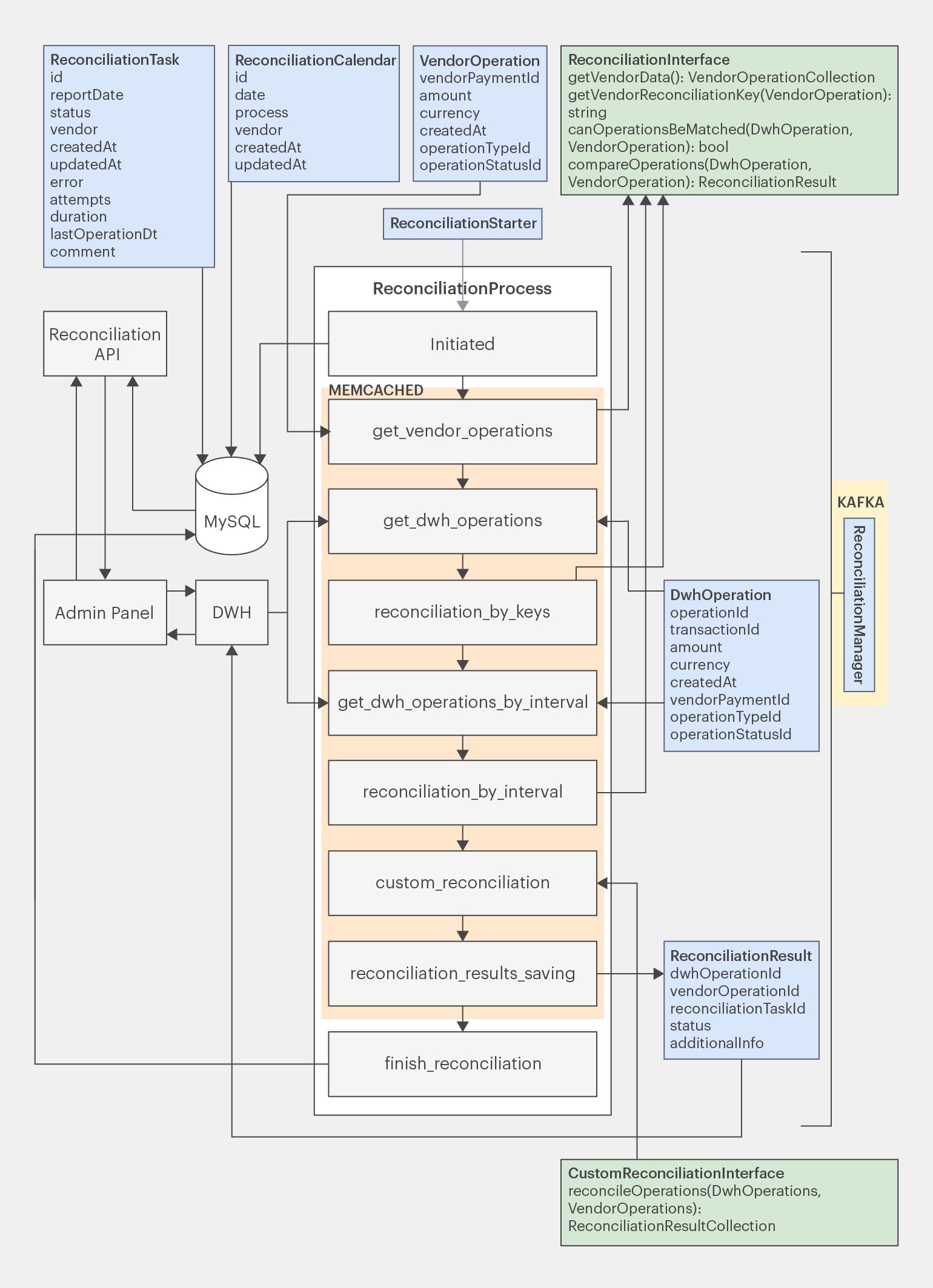
Проверяем полноценность архитектуры
Теперь схема завершена и отображает всю архитектуру приложения. Но нужно проверить исходный список задач, которые сформулировал архитектор.
Необходимо настроить взаимосвязь с DWH посредством интеграции по API. Внутри приложения будет создан клиент или сервис для связи с DWH по API. Нюансы его реализации в этой статье указывать не будем, так как без конкретных параметров продукта и инфраструктуры это невозможно сделать.
Необходимо уметь обрабатывать различные отчёты в различных форматах. Реализовано за счёт ReconciliationInterface.
Сверки должны запускаться в разное время в течение дня. Реализовано за счёт ReconciliationStarter и ReconciliationCalendar.
Расчётные нагрузки на систему на одну сверку от 1000 до 500 000 операций. Стоит провести нагрузочное тестирование, но в целом такие цифры не выглядят проблемой в текущей архитектуре.
Количество сверок по текущим данным — до 40 в один день. Стоит провести нагрузочное тестирование, но это небольшие цифры, чтобы переживать из-за них.
Обработка отчётов от управляющих компаний, которые не присылают их по выходным и праздничным дням. Для этого предусмотрен ReconciliationCalendar, который позволяет управлять днями сверки из админки или принудительно включать или выключать их в определённые дни.
Обработка специальных финансовых операций, которые существуют у ряда управляющих компаний, требующих обработки вместе с другими операциями из одной транзакции. Для этого предусмотрен CustomReconciliationInterface.
Обработка отчётов, которые поставляются посуточно с данными за предыдущий день. Это учтено в архитектуре, так как она строилась на основе этой информации.
Учесть обработку данных в отчётах, которые формируются не строго посуточно в интервале с 00:00:00 до 23:59:59. Это учтено в сверке по интервалу даты и времени, который рассчитывается в процессе самой сверки, а не строго задан в конфигурации.
Обрабатывать данные от управляющих компаний, которые не присылают отчёты в выходные и праздничные дни. Отчёт в понедельник может содержать данные за несколько дней. Данный вариант обрабатывается процессом интервальной сверкой, так как интервал формируется в процессе самой сверки.
Обрабатывать данные от управляющих компаний, которые не присылают отчёт вовремя. Для этого в процессе сверки предусмотрены стадии, которые можно перезапускать при необходимости. Вариантов технической реализации тут довольно много, и это можно оставить на усмотрение разработчика.
Автотестами должно быть покрыто не менее 98% кода. Поскольку в технологическом стеке есть Symfony, можно использовать отличный фреймворк для автотестов Codeception с подробной документацией. В нём также предусмотрены инструменты для замера процента покрытия с подсветкой не закрытого автотестами кода, что удобно для разработчиков.
Создание системы мониторинга. В качестве инструментов мониторинга можно использовать Grafana или любой аналогичный инструмент, принятый внутри компании. Обычно этот вопрос уточняют у группы эксплуатации или администраторов.
Создание системы логирования. Как и в любом фреймворке, в Symfony есть логгер, который можно использовать в разработке. Главное — определить ключевые места кода, где необходимо логирование, и добавить его туда. Для просмотра логов подойдёт Kibana или её аналоги.
Что дальше?
Итак, мы рассмотрели пример создания архитектуры нового приложения с нуля. Прошли путь от идеи до готового концепта, который можно описать в документе, а затем на основе этого описания составить техническое задание и нарезать задачи.
В завершение хотел бы дать рекомендации начинающим архитекторам:
Не стесняйтесь спрашивать мнения коллег и не игнорируйте их советы. Обмен идеями позволяет по-новому взглянуть на логику работы приложения и не упустить важные детали на старте работы.
После завершения проектирования проводите презентацию архитектуры саппортам, разработчикам и другим коллегам, которые будут работать с приложением. Они могут задать важные вопросы, которые по какой-то причине не возникли на первых этапах работы.
Детализируйте схему системы и подробно описывайте назначение каждого компонента. Если у нас есть класс, то пропишите его в деталях: как будет работать каждый метод, какие будут свойства и так далее. Это позволяет увидеть систему в целом и подготовить описание для технических заданий разработчикам.
Согласуйте список используемого технологического стека с отделом информационной безопасности. Некоторые ваши решения могут противоречить внутренним правилам ИБ. Специалисты по информационной безопасности смогут предложить аналоги, разрешённые в компании.
При сравнении технологий и выборе инструментов рассматривайте минимум три их разновидности, стараясь соблюдать объективность. Не стоит делать выбор только на основе привычек.
Старайтесь не проецировать удачный опыт предыдущих проектов на текущий, потому что он может быть нерелевантен в данной ситуации. Предыдущие решения можно рассмотреть, но не стоит их приоритизировать.
Если хотите погрузиться в тему глубже, вот список ресурсов, с которых я рекомендую начать:
- серия постов про паттерны проектирования в моём блоге;
- «Фундаментальный подход к программной архитектуре: паттерны, свойства, проверенные методы» Марка Ричардса и Нила Форда;
- «Современный подход к программной архитектуре: сложные компромиссы» Нила Форда и Марка Ричардса.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!











