Hadoop: что это, для чего она нужна и как работает
Как устроена платформа для работы с большими данными: основные компоненты и преимущества.


Работать с большими данными на одном компьютере не получится — необходима распределённая инфраструктура для их хранения и параллельной обработки. Иначе анализ может занять несколько дней или даже недель.
Одним из подобных инструментов является Apache Hadoop — платформа с открытым исходным кодом, позволяющая распределять данные для анализа по кластеру компьютеров.

Валерий Линьков
Эксперт Skillbox. Дипломированный специалист Cisco, автор статей о машинном зрении и математической обработке изображений. Более семи лет обучает студентов по всему миру. Ведёт телеграм-канал «Кудрявый микрофон».
В статье подробно расскажем о Hadoop.
- Как появилась экосистема
- Что она собой представляет
- Основные компоненты платформы
- Как она работает
- Для чего её используют
- Почему её выбирают
- Перспективы экосистемы
Как появилась Hadoop
Дуг Каттинг сделал первые шаги к созданию Hadoop в 2005 году, когда начал работать над созданием программной инфраструктуры распределённых вычислений для проекта Nutch. Это была поисковая машина на Java, работающая на основе вычислительной концепции MapReduce. Позднее MapReduce легла в фундамент Hadoop.
В 2006 году компания Yahoo предложила Каттингу стать руководителем выделенной команды разработки инфраструктуры распределённых вычислений. Именно в этот момент Hadoop получила название — в честь игрушечного слоника основателя проекта.
Уже в 2008 году на базе технологии Hadoop в Yahoo запустили поисковую машину. Так новый инструмент стал верхнеуровневым проектом системы Apache Software Foundation. Почти сразу им заинтересовались крупные компании — «Фейсбук»*, Last.fm, The New York Times и другие. Случилось это после того, как Hadoop побила мировой рекорд производительности в стандартизированном бенчмарке сортировки данных — 1 терабайт был обработан за 209 секунд. Рекорд был поставлен на кластере из 910 узлов.
После этого Hadoop продолжила развиваться. Для неё появлялись новые модули и технологии, дополняющие функциональность и повышающие скорость работы с данными. При этом разработкой новых инструментов занимались и сторонние разработчики. В итоге получилась современная Hadoop — целая экосистема, включающая несколько десятков подходов для управления и работы с данными.
Что такое Hadoop
Apache Hadoop — написанная на языке Java платформа с открытым исходным кодом для распределённого хранения и обработки больших и не связанных между собой данных. Звучит сложно, но сейчас разберёмся.
Под большими данными подразумеваются те, что отличаются разнообразием, высокой скоростью поступления и постоянно растущим объёмом, который не позволяет разместить их и обработать на одном компьютере. Важно сказать, что в само определение «большие данные» входит не только информация, но и методы работы с ней — от хранения до анализа.
Hadoop позволяет разделить данные объёмом в несколько терабайт или петабайт на небольшие фрагменты и распределить их по вычислительному кластеру — группе компьютеров, которые представляют собой аппаратный ресурс, выполняющий работу как единое целое.
Таким образом, задача аналитической обработки данных разделяется между несколькими рабочими машинами, параллельно выполняющими свои небольшие части общей работы. Таких машин может быть от одной до нескольких тысяч.
Основные компоненты Hadoop
Экосистема состоит из четырёх ключевых компонентов: HDFS, YARN, MapReduce и Common. В дополнение к ним выпущено несколько десятков инструментов, используемых для расширения функциональности платформы. Подробнее с ними можно познакомиться в документации к платформе.
HDFS — распределённая файловая система
HDFS (Hadoop Distributed File System) обрабатывает, хранит данные и управляет доступом к ним. Она обеспечивает лучшую пропускную способность, чем традиционные файловые системы, а также высокую отказоустойчивость и встроенную поддержку больших данных. Как и любая файловая система, HDFS представляет собой иерархию каталогов с вложенными в них подкаталогами и файлами.
Hadoop YARN (Yet Another Resource Negotiator)
Yet Another Resource Negotiator (диспетчер ресурсов) — платформа, которая управляет узлами кластера, планирует их работу и распределяет вычислительные ресурсы в системе Hadoop.
YARN мониторит динамическое выделение ресурсов кластера приложениям Hadoop и отслеживает выполнение заданий обработки. Она поддерживает несколько подходов к планированию задач — например, FIFO: «первым пришёл — первым ушёл», то есть обработку задач в порядке их поступления.
Hadoop MapReduce
Это фреймворк, который используется для обработки данных, хранящихся в HDFS. MapReduce упрощает и ускоряет процесс за счёт простых действий — разбивает данные на небольшие части и обрабатывает их параллельно. Затем он объединяет итоги расчётов для получения общего результата. Про MapReduce подробнее поговорим позже.
Hadoop Common
Это набор библиотек и утилит для работы с различными компонентами Hadoop: настройки, управления и обеспечения безопасности.
Вот некоторые из утилит:
- Common Configuration позволяет настраивать приложения Hadoop с помощью XML-файлов.
- Common IO обеспечивает работу с различными файловыми системами — например, HDFS и Amazon S3.
- Common Security включает утилиты, связанные с безопасностью, такие как системы аутентификация и авторизация.
Прочие компоненты экосистемы Hadoop
В экосистему входит множество других инструментов и решений. Большинство из них используется для дополнения или поддержки четырёх основных компонентов. Вот некоторые из них:
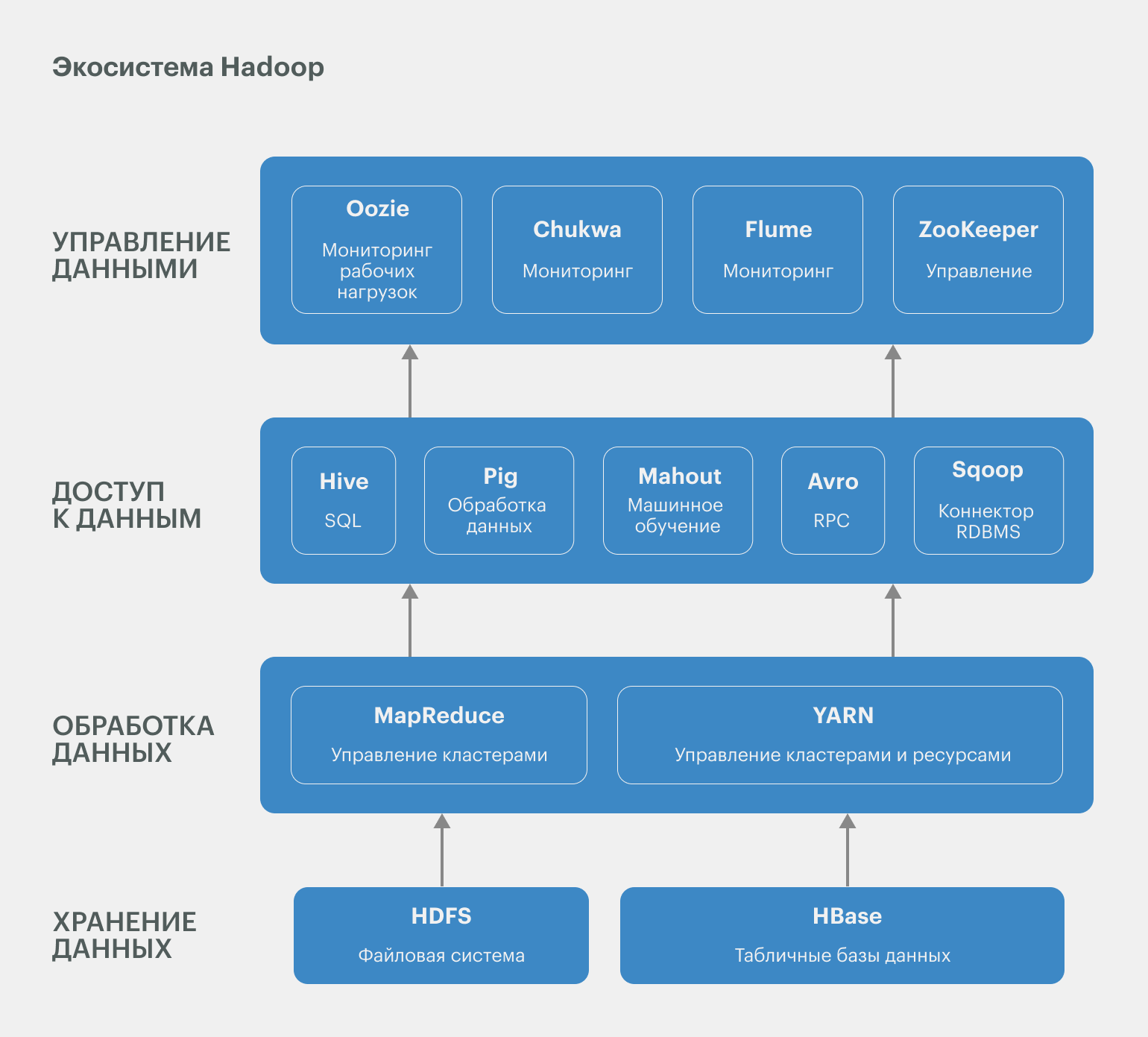
Pig — платформа, которая используется для анализа больших данных: она представляет их в виде потоков данных.
Hive — система управления базами данных, позволяющая читать и записывать массивы данных, управлять массивами, размещёнными в распределённом хранилище. Можно сказать, что это инструмент для SQL-подобных запросов к большим данным, который преобразует запросы в серию MapReduce-задач. Именно Hive чаще всего используется как точка входа в экосистему, так как с чистым Hadoop работают только дата-инженеры.
HBase — база данных NoSQL, работающая поверх Hadoop и в реальном времени обеспечивающая доступ к большим массивам данных в режиме чтения и записи.
Spark MLlib — библиотека машинного обучения для Apache Spark, предоставляющая масштабируемые алгоритмы машинного обучения.
ZooKeeper — сервис для координации распределённых систем и управления ими.
Oozie — система планирования рабочих процессов для управления заданиями Hadoop.
Apache Spark
Spark — фреймворк, постепенно вытесняющий MapReduce. Эксперты выделяют несколько причин этого.
Высокая скорость работы. Apache Spark может обрабатывать данные в 10–100 раз быстрее, чем MapReduce. Это связано с тем, что он работает с информацией в оперативной памяти, в то время как MapReduce после каждого действия сохраняет данные на диске. Поэтому Spark чаще используется в задачах, требующих обработки больших данных в реальном времени.
Простота использования. Spark предоставляет высокоуровневые API на языках Java, Scala, Python и R. MapReduce работает с низкоуровневыми API на Java, что затрудняет работу.
Потоковая передача данных в реальном времени. Spark предоставляет возможности потоковой обработки в реальном времени, позволяя пользователям обрабатывать данные по мере их появления.
Возможности для машинного обучения. Spark содержит библиотеки машинного обучения, позволяющие пользователям создавать модели и обучать их на больших наборах данных.
Как работает Hadoop
Если коротко, то Hadoop распределяет большие данные по кластеру общедоступного оборудования и обрабатывает их на нескольких рабочих машинах. Таких машин может быть две, а может — несколько тысяч.
Теперь подробный ответ. Для этого разберёмся в работе MapReduce. Она состоит из двух основных функций.
Map — предварительная обработка входных данных. Главный узел кластера получает данные, делит их на части и передаёт рабочим узлам. Последние вновь применяют функцию Map к своим локальным данным и записывают результат в формате «ключ — значение» во временное хранилище. Именно на этом этапе распределённые фрагменты данных проходят необходимую обработку: фильтрацию, сортировку, анализ и так далее.
Reduce — процесс свёртки предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует решение задачи, то есть итоговый результат.
Вот и всё. Всего две функции, которые выполняются одновременно на нескольких сотнях или тысячах рабочих узлов.
Для чего используют Hadoop
Платформу используют для хранения и обработки больших объёмов данных. Они могут содержать информацию о банковских транзакциях, сведения о посещённых сайтах, журналы веб-серверов и мобильных приложений, сообщения в социальных сетях, электронные письма клиентов, данные датчиков из интернета вещей (IoT) и многое другое. Посмотрим на примеры практического применения Hadoop.
Ретейл
В ретейле Hadoop используется для оптимизации уровня текущих складских запасов, повышения точности прогнозирования спроса и сокращения времени выполнения заказов.
Финансы
Банки и инвестиционные компании применяют Hadoop для моделирования и оценки финансовых рисков, а также для управления рисками при работе с клиентскими портфелями.
Здравоохранение
Государственные и частные медицинские учреждения обрабатывают большие объёмы данных о клиентах. Hadoop может быть полезна:
- при обработке данных для оценки заболеваемости населения;
- для выявления мошенничества с медицинскими страховками.
Наука
Научные институты используют Hadoop в различных областях:
- Геномика. Анализ больших наборов геномных данных для выявления генетических вариаций, которые могут быть связаны с заболеваниями.
- Астрономия. Обработка данных с телескопов для идентификации небесных тел и изучения их свойств.
- Социология. Анализ данных из социальных сетей для определения тенденций и разработки моделей поведения пользователей.
- Климатология. Работа с климатическими данными для изучения влияния изменения климата на окружающую среду.
Преимущества Hadoop
Основные достоинства Hadoop — масштабируемость, универсальность, экономичность и отказоустойчивость.
Масштабируемость. Платформа не ограничивает ёмкость хранилища данных: пользователи могут быстро добавлять новые узлы, масштабируя кластер от нескольких компьютеров до тысяч рабочих машин.
Универсальность. Экосистема может хранить и обрабатывать неограниченное количество структурированных, частично структурированных и неструктурированных данных в любых форматах.
Экономичность. Платформа работает на любом стандартном оборудовании, не требуя больших затрат на организацию хранения больших данных и управления ими.
Отказоустойчивость. Hadoop защищает приложения и обработку данных от аппаратных сбоёв. Если один узел в кластере выходит из строя, система автоматически перенаправляет задания по обработке на другие узлы, чтобы приложения продолжили работу, восстановив фрагмент потерянных данных из первичного источника.
Перспективы Hadoop
Hadoop появилась в 2005 году и за почти два десятка лет превратилась в огромную экосистему с десятками приложений. За это время появились и другие платформы для работы с большими данными, однако Hadoop всё ещё удерживает лидерство:
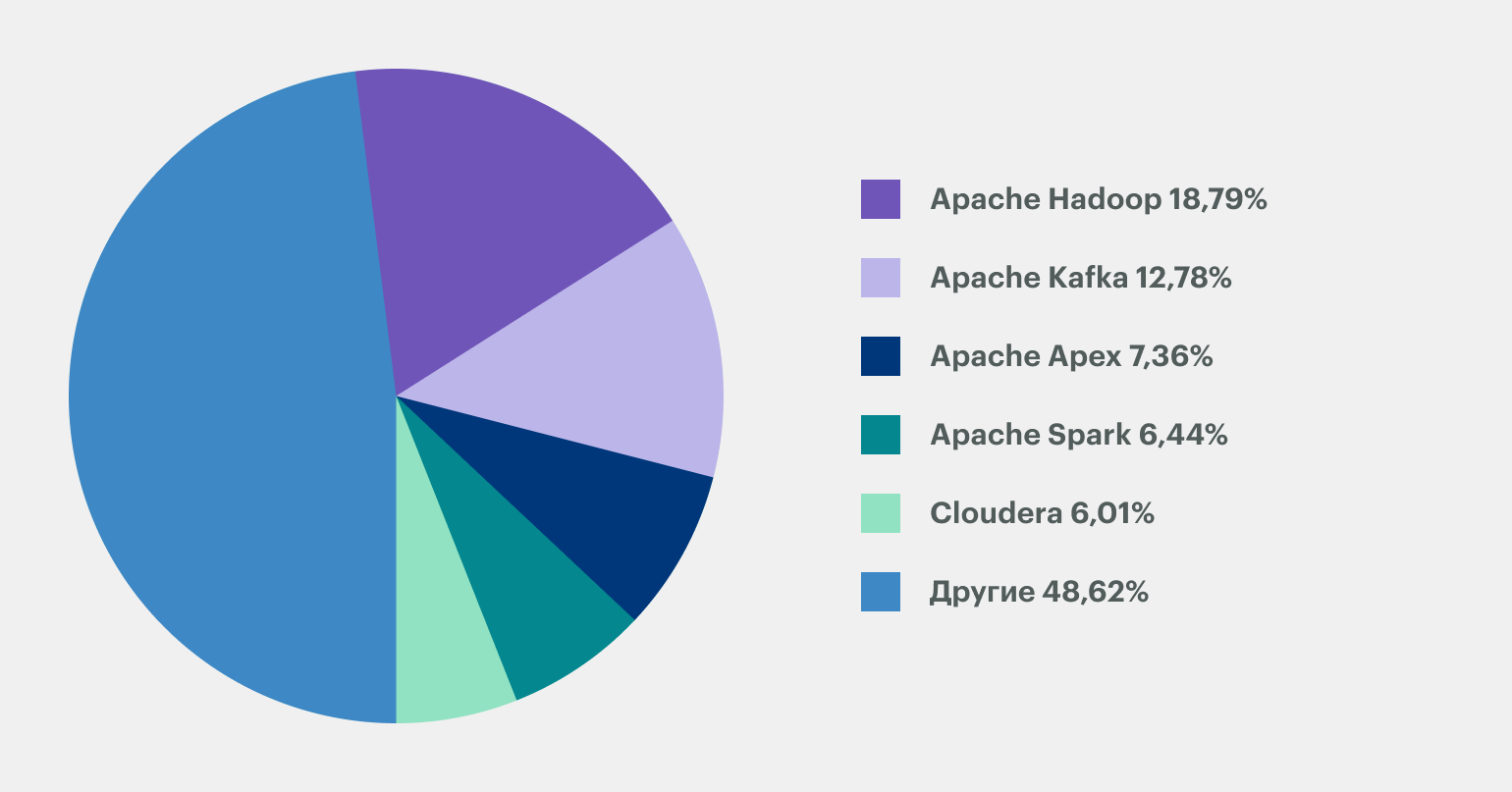
Hadoop продолжает развиваться и регулярно обновляться. Например, последняя стабильная версия 3.3.6 вышла 23 июня 2023 года. Кроме того, у экосистемы большое сообщество и подробная документация, что делает её платформой №1 для работы с большими данными.
Что запомнить
Давайте резюмируем то, что мы узнали о Hadoop.
- Hadoop — экосистема приложений для работы с большими данными.
- Она состоит из четырёх ключевых компонентов: HDFS, YARN, MapReduce и Common. Есть ещё несколько десятков дополнительных инструментов, в том числе от сторонних разработчиков.
- Основа работы Hadoop — парадигма MapReduce, позволяющая разделить данные по отдельным кластерам, то есть рабочим машинам, и обрабатывать их параллельно друг другу.
- Apache Spark — логичное развитие MapReduce, позволяющее увеличить скорость обработки данных.
- Hadoop используется в сферах, где необходимо работать с большими данными: в ретейле, здравоохранении, банковском деле и так далее.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».
Data Science с нуля: пробуем профессии на практике за 5 дней
Вы разберётесь в трёх главных направлениях data science: машинном обучении, разработке на Python и визуализации данных. Решите, какая сфера вам ближе, и выполните 4 реальные задачи с данными.
Пройти бесплатно