Библиотека Pandas Profiling: делаем первичный анализ данных в одну строку
Профиль ваших данных — быстро, компактно, наглядно.


Python-библиотека pandas — незаменимый инструмент для работы с табличными данными. Команды и функции из этой библиотеки — практически всегда первое, что исполняет дата-сайентист в своём Jupyter-блокноте.
Мы будем запускать наш блокнот в среде Google Colab, которая работает прямо в браузере. Прочитайте небольшую статью об этом популярном сервисе.
Мы будем запускать наш блокнот в среде Google Colab, которая работает прямо в браузере. Прочитайте небольшую статью об этом популярном сервисе.
Выглядит это так:
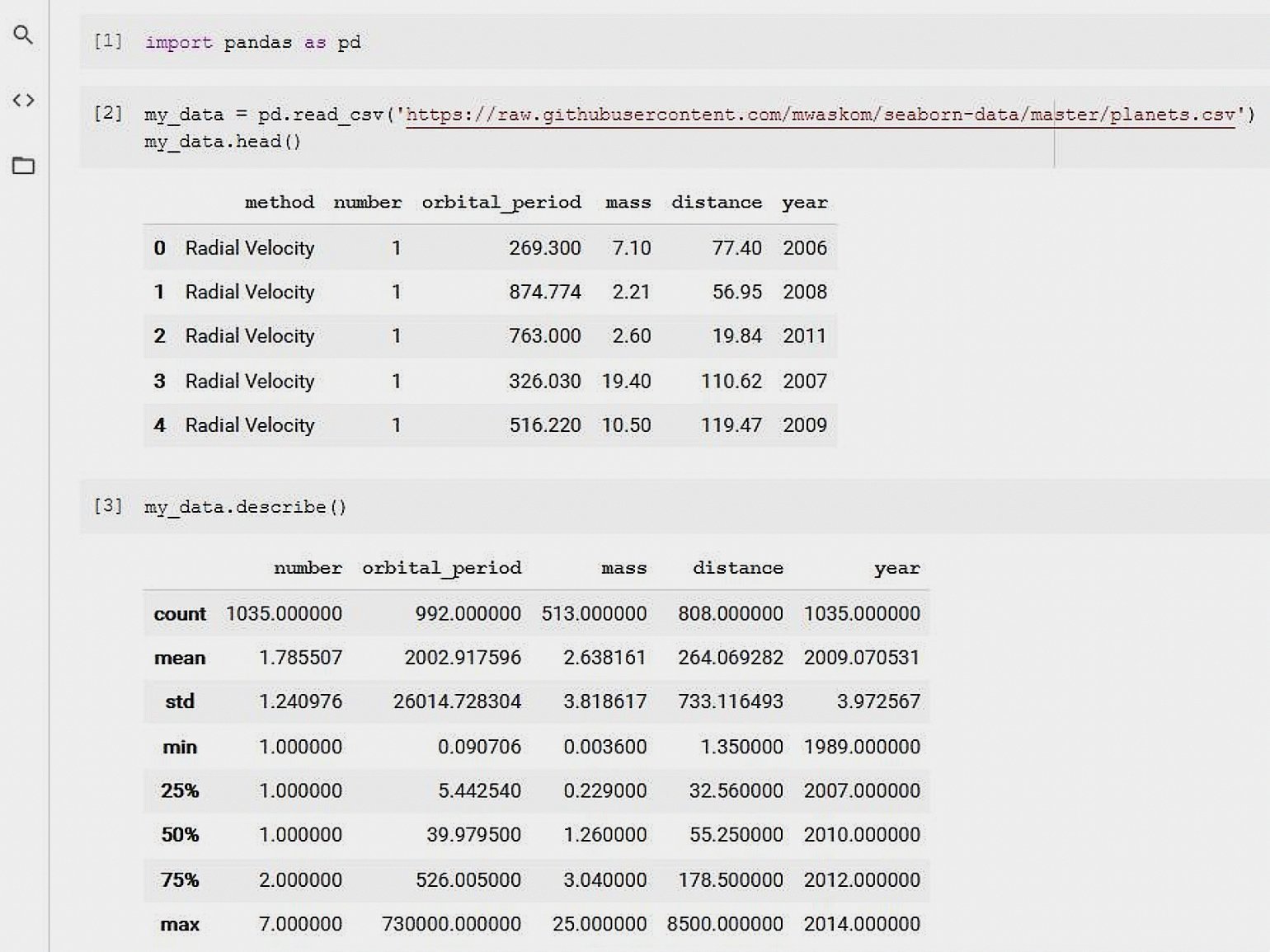
В первой ячейке мы импортировали библиотеку pandas. Во второй:
- прочитали таблицу planets.csv из коллекции seaborn-data, содержащую данные наблюдений за экзопланетами;
- сохранили её в переменную my_data;
- а также посмотрели первые пять строк датасета с помощью метода .head(), чтобы убедиться, что данные прочитались корректно.
В третьей ячейке с помощью .describe() были получены основные количественные характеристики нашего датасета: количество строк (наблюдений) count, среднее mean, величина стандартного отклонения std и так далее. На вид всё вполне солидно, но:
- результат — сплошные цифры, надо разбираться и вникать в каждую строчку;
- куда-то делась колонка method, содержащая категориальные (не числовые) переменные.
Неужели характеристики датасета (часто говорят «профиль данных») нельзя представить полнее и нагляднее? Оказывается, можно.

Pandas Profiling спешит на помощь
Создатели библиотеки пишут прямо: функция .describe() в Pandas отличная, но не покрывает современных требований к первичному исследовательскому (разведочному) анализу данных.
Pandas Profiling выдаёт в своём отчёте следующие параметры датасета:
- тип данных в каждой колонке;
- пропущенные и уникальные значения (количество и процент);
- описательную статистику: квартили, медиану, межквартильный размах, среднее, моду, абсолютное и относительное стандартное отклонение, медианное абсолютное отклонение, коэффициенты асимметрии и эксцесса;
Уфф! А ведь это только середина неполного списка. Пора сделать перерыв на статью о базовых статистических понятиях, необходимых для дата-сайентиста.
- график в виде гистограммы;
- корреляции между значениями (Пирсона, Спирмена и Кендалла);
- матрицу пропущенных значений;
- анализ текста в категориальных значениях;
- а также метаданные файлов и изображений: размеры файлов, даты создания, высоту и ширину.
Это практически исчерпывающее описание имеющихся данных. Причём оформленное в наглядный отчёт прямо в вашем блокноте.
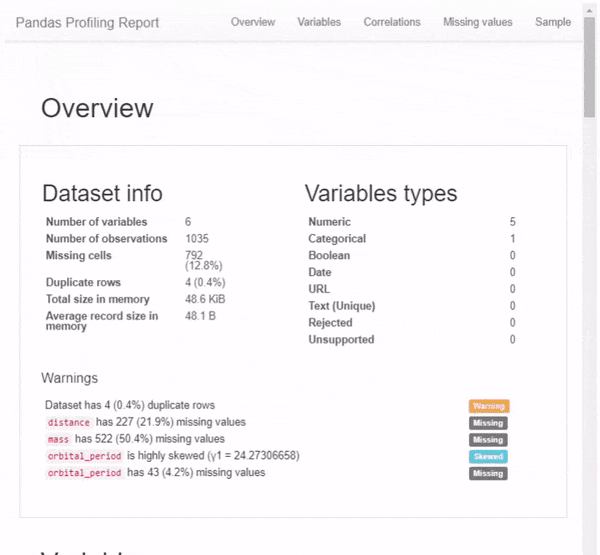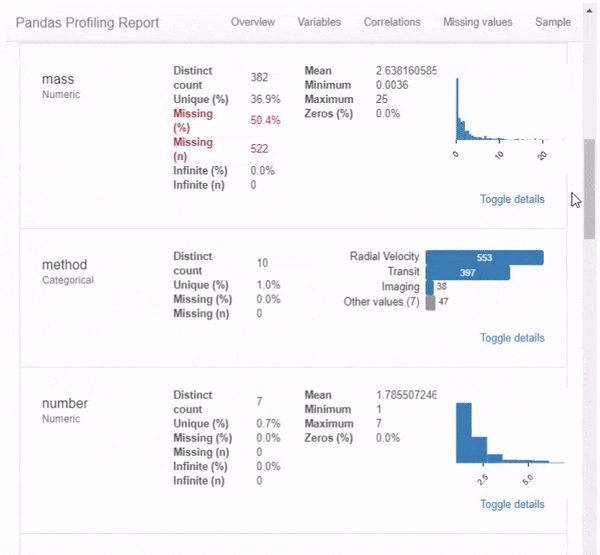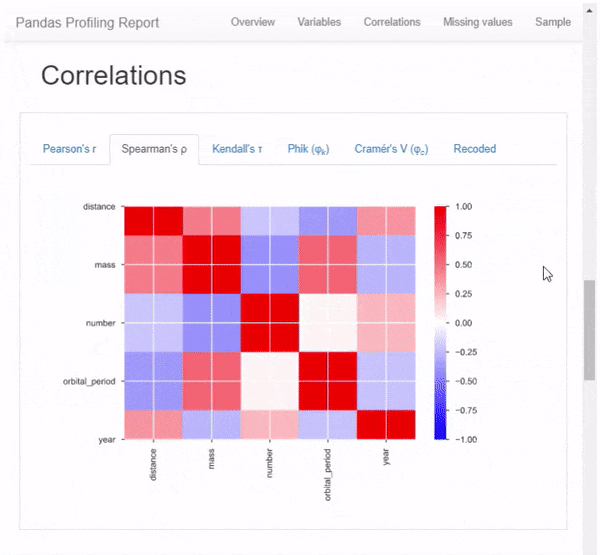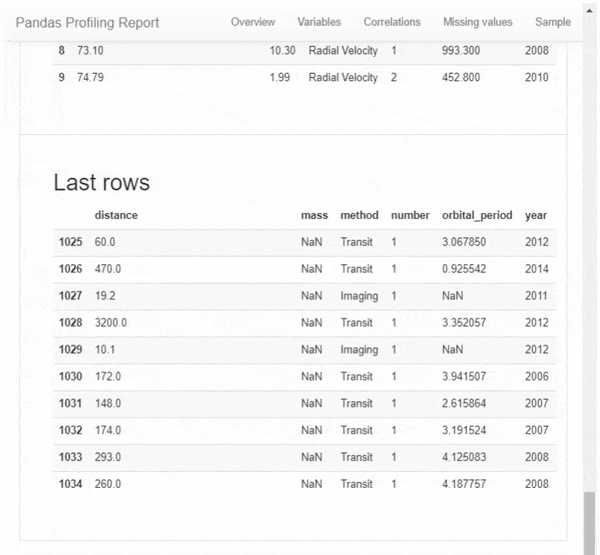
Давайте разбираться, как заполучить себе такую красоту.
Отчёт о данных в одну (почти) строчку
Для установки библиотеки в Colab запускаем в отдельной ячейке одну из двух команд:
# стандартный способ установки
!pip install pandas-profiling[notebook]
# альтернативный способ установки
!pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zipАльтернативный способ установки помогает, если в какой-либо из следующих команд будут ошибки. В этом случае не забудьте перезапустить среду выполнения колаба: «Среда выполнения» → «Перезапустить среду выполнения». Заново установку делать после этого, конечно, не требуется — просто запустите предыдущие ячейки (1–3) с датасетом my_data.
Импортируем в блокнот нужную нам функцию ProfileReport, составляем профиль наших данных, то есть my_data, и сохраняем его в переменную profile:
from pandas_profiling import ProfileReport
profile = ProfileReport(my_data, title="Pandas Profiling Report")
# запускаем показ профиля
profileВы получите обширный и подробный отчёт о данных, содержащихся в my_data. Причём правда в одну строчку — конечно, не считая импорта самой библиотеки и команды для показа.
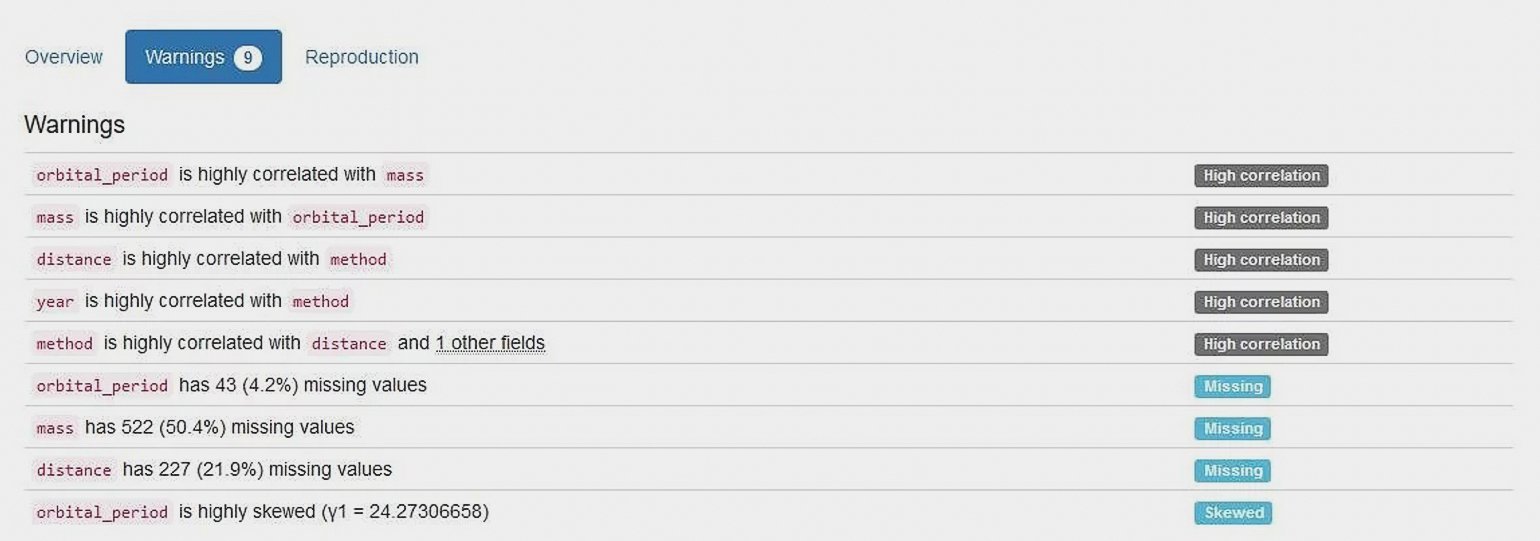
Отдельно обратите внимание на вкладку Warnings сразу же на первом экране отчёта. Там Pandas Profiling собирает наиболее подозрительные с точки зрения статистики свойства датасета: корреляции, асимметрию и колонки с большим процентом пропущенных значений.
Чтобы сохранить отчёт в html-файл, воспользуйтесь командой .to_file():
profile.to_file("my_report.html")Файл my_report.html появится в меню колаба слева, и оттуда его можно будет скачать себе на компьютер.
Посмотрите, как выглядят отчёты по разным датасетам на странице библиотеки на GitHub:
- отчёт по классическому датасету про пассажиров «Титаника»;
- отчёт по данным NASA о падениях метеоритов;
- отчёт по данным о 1000 самых употребительных слов русского языка;
- ну, и, конечно, куда без котиков и собачек.
Что дальше
Библиотека Pandas Profiling поможет как начинающим, так и опытным дата-сайентистам быстро понять, что за данные перед ними, оценить их качество и полноту. Скопируйте наш колаб-ноутбук себе с помощью команды меню «Файл» → «Сохранить копию на диске» и испытайте её в деле.
На курсе «Профессия Data Scientist» вы познакомитесь со множеством других, не менее мощных, быстрых и полезных инструментов специалиста по данным. Приходите, чтобы получить модную, интересную и востребованную профессию!






