7 базовых статистических понятий, необходимых дата-сайентисту
Даже если вы хорошо программируете, но слабо ориентируетесь в статистике, вероятность выжить в Data Science очень низка.

У статистики есть несколько различных определений. Одно из самых простых и точных — это «наука о сборе и классификации цифровых данных». А если добавить к нему немного о программировании и машинном обучении, то получится неплохое описание основ Data Science.

В самом деле, в Data Science трудно найти область, где нет статистики в том или ином виде. Она нужна для:
- анализа, преобразования и очистки данных;
- оценки и оптимизации моделей машинного обучения;
- понимания данных и презентации результатов.
Мы выбрали семь базовых концепций, без которых в Data Science точно не обойтись. К счастью, они не слишком сложны.
1. Меры описательной статистики
Задача описательной статистики, как следует из названия, — дать хорошее описание данных. Она не для предсказаний, выводов или преобразований — только внешняя форма данных, измеренная в показателях.
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, мерами центральной тенденции), — это:
- Среднее: чаще всего вычисляется как среднее арифметическое. Просто складываем все значения, делим на их количество — и вуаля, средняя температура по больнице готова.
- Медиана: если выстроить все данные по возрастанию и найти середину этого ряда, это как раз и будет медиана. Одна половина из значений данных будет больше медианы, а другая — меньше.
- Мода: значение в наборе данных, которое встречается чаще всего. Запомнить очень легко: мода — самое популярное из значений, то, что «носят все».

Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, меры рассеяния. Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
2. Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.

Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.

Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и другие распределения, в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
3. Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Но тут сразу же возникают вопросы:
- Сколько и каких котов отобрать для замера?
- Почему именно этих, а не других?
- Какие есть гарантии, что вычисленное значение действительно будет средней шириной морды всех котов России?
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
4. Смещение
Аналогично тому, как производится выборка из генеральной совокупности, дата-сайентисты из готового датасета выделяют тренировочный набор. Именно на этой «выборке второго порядка» модель учится делать предсказания.
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».

Чаще всего причиной смещения являются:
- неправильный сбор данных в датасет: например, в него попали только краснодарцы — любители Парижа;
- неправильное формирование тренировочного набора из датасета;
- неправильное измерение ошибок.
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.

Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
- Эффект низкой/высокой базы. Если в финансовом отчёте найти самый низкий показатель прибыли, то на его фоне любой другой результат будет выглядеть как достижение. И наоборот: если хотите показать, что ученик перестал прогрессировать, сравнивайте текущие оценки с его лучшими результатами за все годы обучения.
- Сокращение рассматриваемого периода. Если хочется доказать, что рекламная кампания не приносит результатов, надо просто найти период, когда деньги уже потрачены, а эффекта ещё нет. И рассматривать только его.
- Исключение из выборки. Если вы измеряете результативность методики снижения веса, то можно выкидывать из выборки участников, которые отказались от методики, не дойдя до конца. Это существенно «повысит» эффективность методики.
- Ну и, конечно же, классика: «Интернет-опрос населения показал, что 100% населения пользуются интернетом».
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
5. Дисперсия
Дисперсия — это величина, показывающая, как именно и насколько сильно разбросаны значения — например, предсказания модели машинного обучения или доход за рассматриваемый период. За точку, относительно которой эти значения разбросаны, берут истинное значение, целевую переменную или математическое ожидание, которое вычисляется теоретически и заранее.
Часто в качестве матожидания выступает обычное среднее арифметическое. Например, математическое ожидание количества очков при броске игрального кубика равно среднему арифметическому очков на всех гранях:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5
Представьте себе тир, стрелка и мишень. Снайпер стреляет в стандартный круг, где попадание в центр даёт 10 баллов, в зависимости от удаления от центра количество баллов снижается, а крайние области дают всего 1 балл. Каждый выстрел стрелка — это случайное целое значение от 1 до 10.

Изрешечённая пулями мишень — отличная иллюстрация распределения. Дисперсия здесь — величина, обратная кучности попаданий: хорошая кучность означает низкую дисперсию, и наоборот.
6. Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо». Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени.

В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
7. Корреляция
Когда изменения одной величины сопутствуют изменениям другой, говорят о корреляции. Главное, что необходимо о ней знать: корреляция не означает причинно-следственную связь.
Линейная корреляция — это когда изменения одной величины пропорциональны изменениям другой. Она может быть:
- положительной — обе величины растут в одну сторону;
- отрицательной — одна величина растёт, другая уменьшается;
- а также сильной или слабой, независимо от направления.
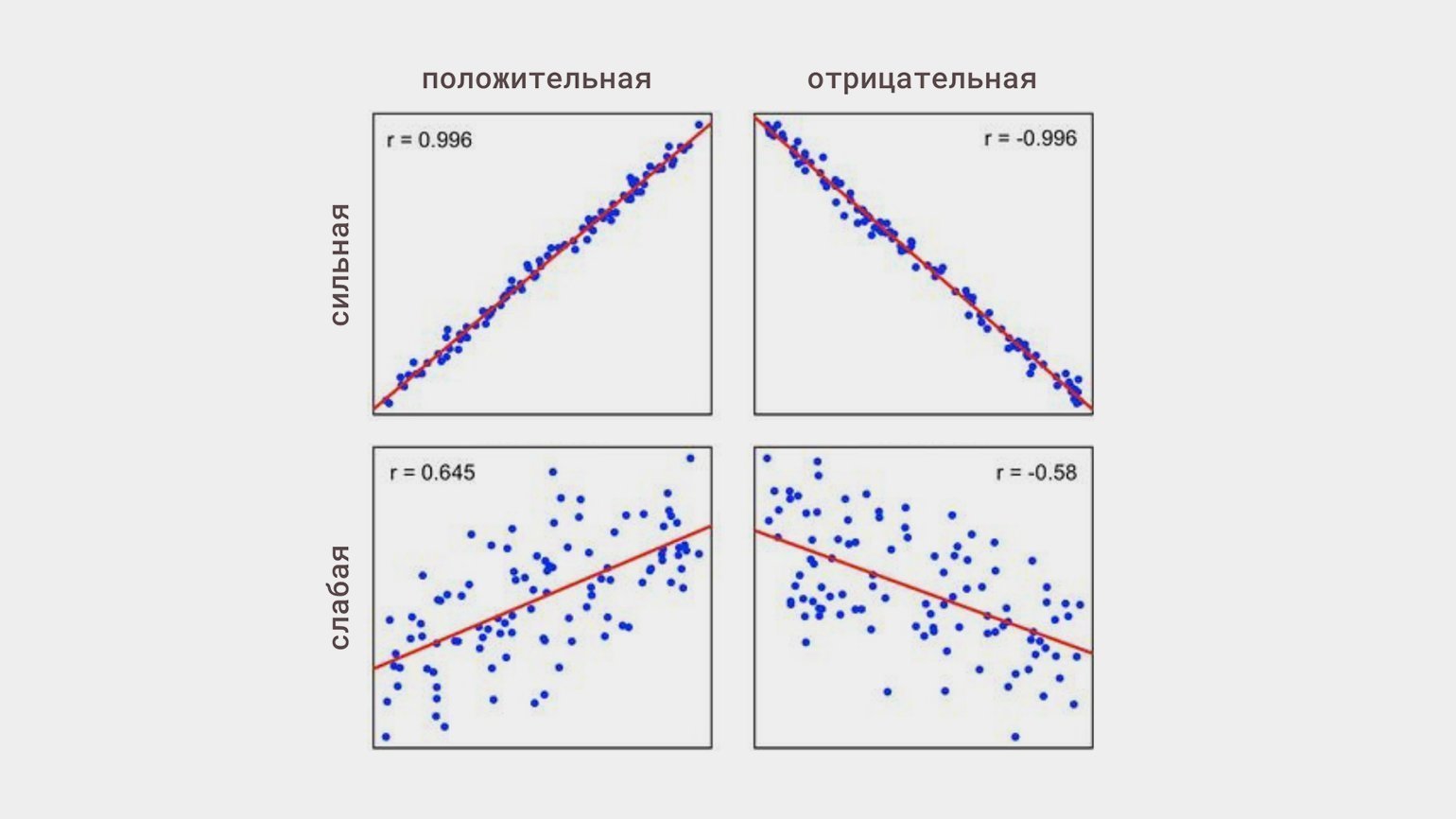
Статистическую связь между переменными исследуют с помощью корреляционного анализа. Его основная задача — оценить тесноту связи (это термин) между переменными, чтобы понять, какие переменные учитывать в модели, а какие нет.
И ещё раз, потому что действительно важно: корреляция ни в коем случае не означает причинно-следственную связь. Если два показателя скоррелированы, то далеко не факт, что они хоть как-то связаны.
Кстати, проект Spurious Correlations («Ложные корреляции») публикует графики корреляций между совершенно неожиданными статистическими показателями — например, количеством людей, утонувших в домашних бассейнах, и числом фильмов с участием Николаса Кейджа.

Имеет смысл время от времени заходить по этой ссылке с целью профилактики СПГС — синдрома поиска глубинной связи.
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании. Приходите!

Курс с помощью в трудоустройстве

Профессия Data scientist + ИИ
- Реальные задачи от «СберАвтоподписки» и «СберМаркета»
- 8 сильных проектов в портфолио
- Спикеры из VK, ВТБ, «Сбера», Wildberries





