Big O Notation: что это такое и как её посчитать
Software Engineer Валерий Жила подробно рассказал, что такое O(n), и показал, как её считать на примере бинарного поиска и других алгоритмов.

Валерий Жила

об эксперте
Software Engineer, разрабатывает системы управления городской инфраструктурой для мегаполисов. Основная деятельность: backend, database engineering. Ведёт твиттер @ValeriiZhyla и пишет научные работы по DevOps.
Сегодня я расскажу о сложности алгоритмов, или, как её часто называют, Big O Notation. Статья рассчитана на новичков, поэтому постараюсь изложить идеи и концепции просто, не теряя важных деталей.
Время и память — основные характеристики алгоритмов
Алгоритмы описывают с помощью двух характеристик — времени и памяти.
Время — это… время, которое нужно алгоритму для обработки данных. Например, для маленького массива — 10 секунд, а для массива побольше — 100 секунд. Интуитивно понятно, что время выполнения алгоритма зависит от размера массива.
Но есть проблема: секунды, минуты и часы — это не очень показательные единицы измерения. Кроме того, время работы алгоритма зависит от железа, на котором он выполняется, и других внешних факторов. Поэтому время считают не в секундах и часах, а в количестве операций, которые алгоритм совершит. Это надёжная и, главное, независимая от железа метрика.
Когда говорят о Time Complexity или просто Time, то речь идёт именно о количестве операций. Для простоты расчётов разница в скорости между операциями обычно опускается. Поэтому, несмотря на то, что деление чисел с плавающей точкой требует от процессора больше действий, чем сложение целых чисел, обе операции в теории алгоритмов считаются равными по сложности.
Запомните: в О-нотации на операции с одной или двумя переменными вроде i++, a * b, a / 1024, max(a,b) уходит всего одна единица времени.
Память, или место, — это объём оперативной памяти, который потребуется алгоритму для работы. Одна переменная — это одна ячейка памяти, а массив с тысячей ячеек — тысяча ячеек памяти.
В теории алгоритмов все ячейки считаются равноценными. Например, int a на 4 байта и double b на 8 байт имеют один вес. Потребление памяти обычно называется Space Complexity или просто Space, редко — Memory.
Алгоритмы, которые используют исходный массив как рабочее пространство, называют in-place. Они потребляют мало памяти и создают одиночные переменные — без копий исходного массива и промежуточных структур данных. Алгоритмы, требующие дополнительной памяти, называют out-of-place. Прежде чем использовать алгоритм, надо понять, хватит ли на него памяти, и если нет — поискать менее прожорливые альтернативы.
Что такое O(n)
Давайте вспомним 8-й класс и разберёмся: что значит запись O(n) с математической точки зрения. При расчёте Big O Notation используют два правила:
Константы откидываются. Нас интересует только часть формулы, которая зависит от размера входных данных. Проще говоря, это само число n, его степени, логарифмы, факториалы и экспоненты, где число находится в степени n.
Примеры:
O(3n) = O(n)
O(10000 n^2) = O(n^2)
O(2n * log n) = O(n * log n)
Если в O есть сумма, нас интересует самое быстрорастущее слагаемое. Это называется асимптотической оценкой сложности.
Примеры:
O(n^2 + n) = O(n^2)
O(n^3 + 100n * log n) = O(n^3)
O(n! + 999) = O(n!)
O(1,1^n + n^100) = O(1,1^n)
Хороший, плохой, средний
У каждого алгоритма есть худший, средний и лучший сценарии работы — в зависимости от того, насколько удачно выбраны входные данные. Часто их называют случаями.
Худший случай (worst case) — это когда входные данные требуют максимальных затрат времени и памяти.
Например, если мы хотим отсортировать массив по возрастанию (Ascending Order, коротко ASC), то для простых алгоритмов сортировки худшим случаем будет массив, отсортированный по убыванию (Descending Order, коротко DESC).
Для алгоритма поиска элемента в неотсортированном массиве worst case — это когда искомый элемент находится в конце массива или если элемента нет вообще.
Лучший случай (best case) — полная противоположность worst case, самые удачные входные данные. Правильно отсортированный массив, с которым алгоритму сортировки вообще ничего делать не нужно. В случае поиска — когда алгоритм находит нужный элемент с первого раза.
Средний случай (average case) — самый хитрый из тройки. Интуитивно понятно, что он сидит между best case и worst case, но далеко не всегда понятно, где именно. Часто он совпадает с worst case и всегда хуже best case, если best case не совпадает с worst case. Да, иногда они совпадают.
Как определяют средний случай? Считают статистически усреднённый результат: берут алгоритм, прокручивают его с разными данными, составляют сводку результатов и смотрят, вокруг какой функции распределились результаты. В общем, расчёт average case — дело сложное. А мы приступаем к конкретным алгоритмам.
Линейный поиск
Начнём с самого простого алгоритма — линейного поиска, он же linear search. Дальнейшее объяснение подразумевает, что вы знаете, что такое числа и как устроены массивы. Напомню, это всего лишь набор проиндексированных ячеек.
Допустим, у нас есть массив целых чисел arr, содержащий n элементов. Вообще, количество элементов, размер строк, массивов, списков и графов в алгоритмах всегда обозначают буквой n или N. Ещё дано целое число x. Для удобства обусловимся, что arr точно содержит x.
Задача: найти, на каком месте в массиве arr находится элемент 3, и вернуть его индекс.
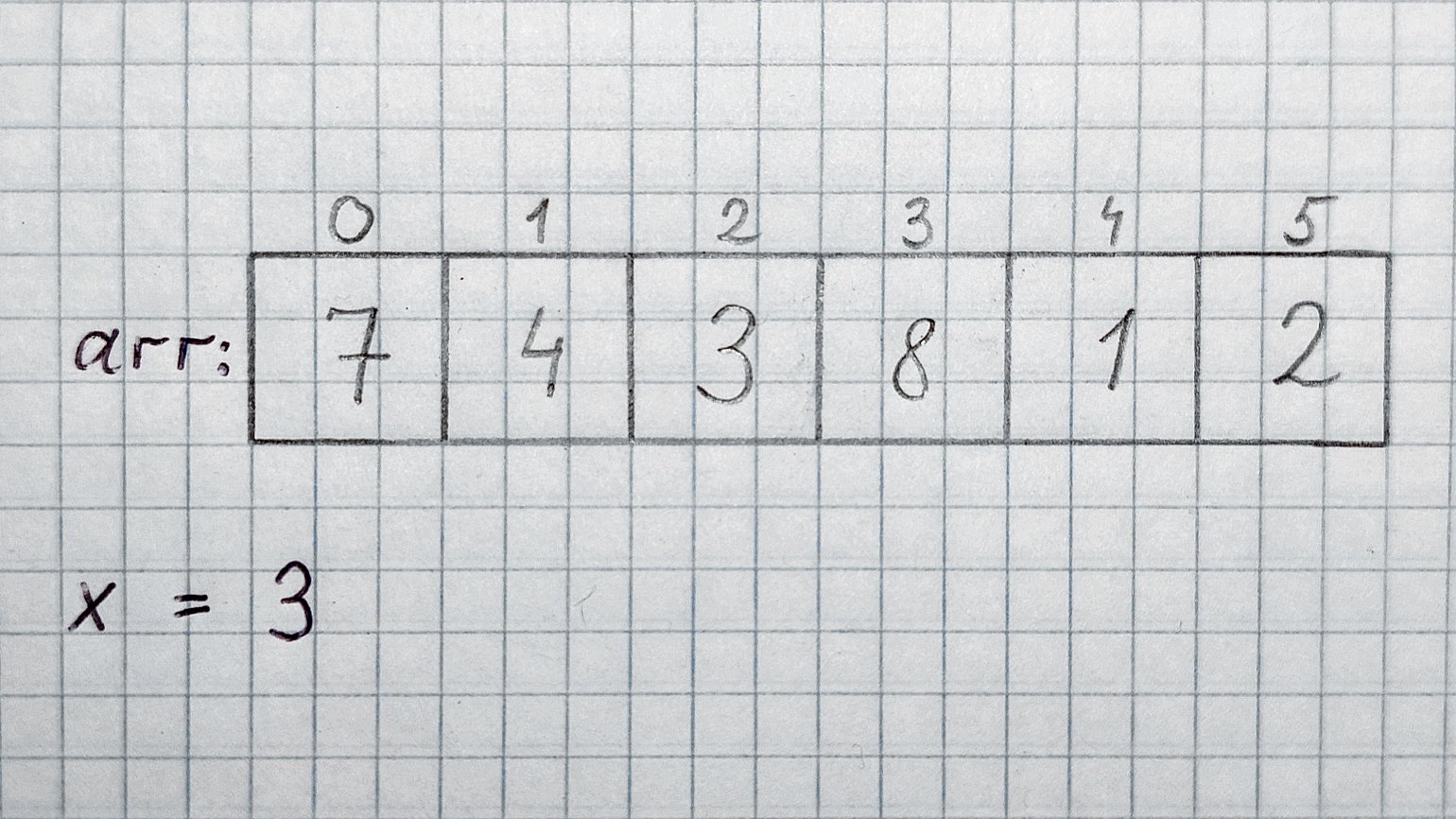
Меткий человеческий глаз сразу видит, что искомый элемент содержится в ячейке с индексом 2, то есть в arr[2]. А менее зоркий компьютер будет перебирать ячейки друг за другом: arr[0], arr[1]… и так далее, пока не встретит тройку или конец массива, если тройки в нём нет.
Теперь разберём случаи:
Worst case. Больше всего шагов потребуется, если искомое число стоит в конце массива. В этом случае придётся перебрать все n ячеек, прочитать их содержимое и сравнить с искомым числом. Получается, worst case равен O(n). В нашем массиве худшему случаю соответствует x = 2.
Best case. Если бы искомое число стояло в самом начале массива, то мы бы получили ответ уже в первой ячейке. Best case линейного поиска — O(1). Именно так обозначается константное время в Big O Notation. В нашем массиве best case наблюдается при x = 7.
Average case. В среднем случае результаты будут равномерно распределены по массиву. Средний элемент можно рассчитать по формуле (n + 1) / 2, но так как мы отбрасываем константы, то получаем просто n. Значит, average case равен O(n). Хотя иногда в среднем случае константы оставляют, потому что запись O(n / 2) даёт чуть больше информации.
Псевдокод
Хорошо, мы уже три минуты обсуждаем linear search, но до сих пор не видели кода. Потерпите, скоро всё будет. Но сперва познакомимся с очень полезным инструментом — псевдокодом.
Разработчики пишут на разных языках программирования. Одни похожи друг на друга, а другие — сильно различаются. Часто мы точно знаем, какую операцию хотим выполнить, но не уверены в том, как она выглядит в конкретном языке.
Возьмём хотя бы получение длины массива. По историческим причинам практически во всех языках эта операция называется по-разному: .length, length(), len(), size(), .size — попробуй угадай! Как же объяснить свой код коллегам, которые пишут на другом языке? Написать программу на псевдокоде.
Псевдокод — достаточно формальный, но не слишком требовательный к мелочам инструмент для изложения мыслей, не связанный с конкретным языком программирования.
Прелесть псевдокода в том, что конкретных правил для его написания нет. Я, например, предпочитаю использовать смесь синтаксиса Python и C: обозначаю вложенность с помощью отступов и называю методы в стиле Python.
А вот и пример псевдокода для нашей задачи, со всеми допущениями и упрощениями. Метод должен возвращать -1, если arr пуст или не содержит x:
int linear_search(int[] arr, int x):
if arr is empty:
return -1
for i in 0..n:
if (arr[i] == x):
return i
return -1 //x was not foundВ псевдокоде часто используют -1 в качестве invalid index, а если алгоритм возвращает объекты — null, nil (то же самое, что и null) или специальный символ «ничего», похожий на перевёрнутую букву «т». Также встречаются конструкции для исключений, вроде throw error ("Very Bad").
Уметь писать псевдокод полезно. Например, с его помощью можно решать задачи на доске на технических собеседованиях. Я пишу код на бумаге и доске почти так же, как в компьютере, но ещё явно выделяю отступы — иначе строчки кода разъезжаются куда глаза глядят:

Бинарный поиск
Следующая остановка — binary search, он же бинарный, или двоичный, поиск.
В чём отличие бинарного поиска от уже знакомого линейного? Чтобы его применить, массив arr должен быть отсортирован. В нашем случае — по возрастанию.
Часто binary search объясняют на примере с телефонным справочником. Возможно, многие читатели никогда не видели такую приблуду — это большая книга со списками телефонных номеров, отсортированных по фамилиям и именам жителей. Для простоты забудем об именах.
Итак, есть огромный справочник на тысячу страниц с десятками тысяч пар «фамилия — номер», отсортированных по фамилиям. Допустим, мы хотим найти номер человека по фамилии Жила. Как бы мы действовали в случае с линейным поиском? Открыли бы книгу и начали её перебирать, строчку за строчкой, страницу за страницей: Астафьев… Безье… Варнава… Ги… До товарища Жилы он дошёл бы за пару часов, а вот господин Янтарный заставил бы алгоритм попотеть ещё дольше.
Бинарный поиск мудрее и хитрее. Он открывает книгу ровно посередине и смотрит на фамилию, например Мельник — буква «М». Книга отсортирована по фамилиям, и алгоритм знает, что буква «Ж» идёт перед «М».
Алгоритм «разрывает» книгу пополам и выкидывает часть с буквами, которые идут после «М»: «Н», «О», «П»… «Я». Затем открывает оставшуюся половинку посередине — на этот раз на фамилии Ежов. Уже близко, но Ежов не Жила, а ещё буква «Ж» идёт после буквы «Е». Разрываем книгу пополам, а левую половину с буквами от «А» до «Е» выбрасываем. Алгоритм продолжает рвать книгу пополам до тех пор, пока не останется единственная измятая страничка с заветной фамилией и номером.
Перенесём этот принцип на массивы. У нас есть отсортированный массив arr и число 7, которое нужно найти. Почему поиск называется бинарным? Дело в том, что алгоритм на каждом шаге уменьшает проблему в два раза. Он буквально отрезает на каждом шаге половину arr, в которой гарантированно нет искомого числа.

На каждом шаге мы проверяем только середину. При этом есть три варианта развития событий:
- попадаем в 7 — тогда проблема решена;
- нашли число меньше 7 — отрезаем левую половину и ищем в правой половине;
- нашли число больше 7 — отрезаем правую половину и ищем в левой половине.
Почему это работает? Вспомните про требование к отсортированности массива, и всё встанет на свои места.
Итак, смотрим в середину. Карандаш будет служить нам указателем.
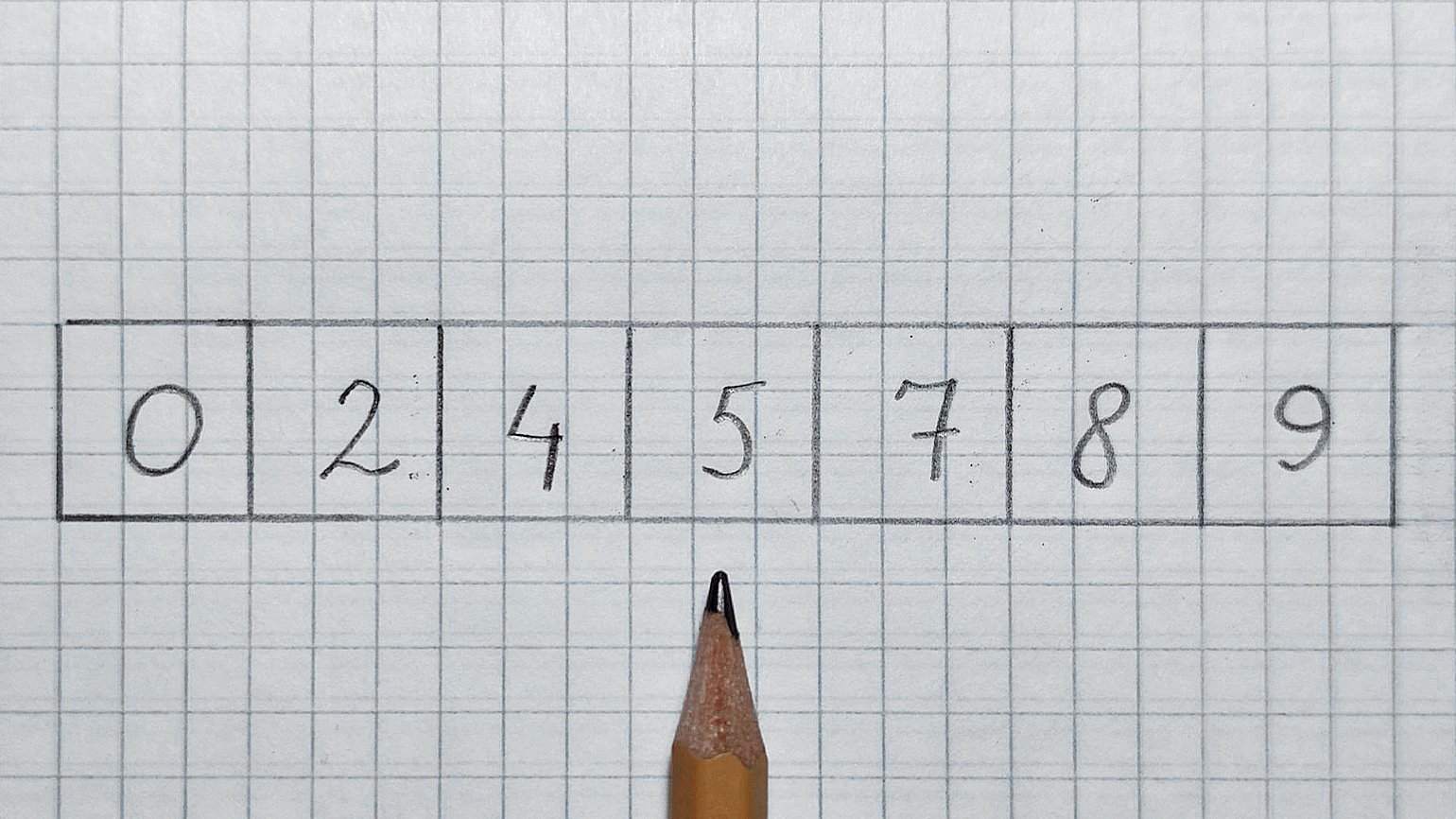
В середине находится число 5, оно меньше 7. Значит, отрезаем левую половину и проверенное число. Смотрим в середину оставшегося массива:
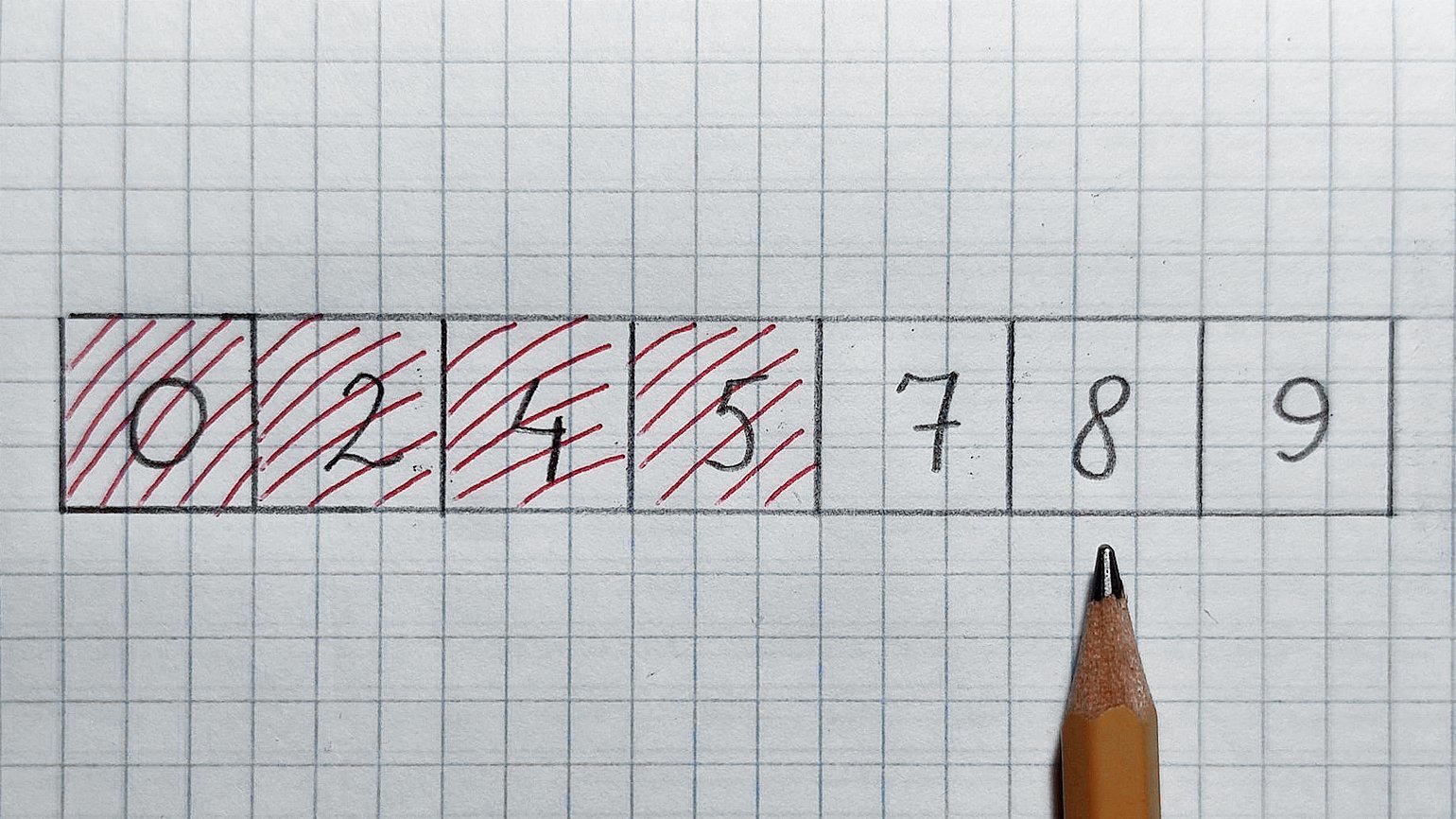
В середине число 8, оно больше 7. Значит, отрезаем правую половинку и проверенное число. Остаётся число 7 — как раз его мы и искали. Поздравляю!

Теперь давайте попробуем записать это в виде красивого псевдокода. Как обычно, назовём середину mid и будем перемещать «окно наблюдения», ограниченное двумя индексами — low (левая граница) и high (правая граница).
int binary_search(int [] arr, int low, int high, int x):
if high >= low:
mid = round_down((low + high)/2)
if arr[mid] == x: // check middle element
return mid
else if arr[mid] > x: // recursive check left hals
return binary_search(arr, low, mid-1, x)
else: // recursive check right half
return binary_search(arr, mid+1, high, x)
else:
return -1 // x was not foundАлгоритм организован рекурсивно, то есть вызывает сам себя на строках 7 и 9. Есть итеративный вариант с циклом, без рекурсии, но он кажется мне уродливым. Если не находим искомый элемент, возвращаем -1. В начале работы алгоритма значение low совпадает с началом массива, а high — с его концом. И они бегут навстречу друг другу…
Чтобы запускать алгоритм, не задумываясь о начальных значениях индексов low и high, можно написать такую функцию-обёртку:
int binary_search(int [] arr, int x):
if arr_is_empty:
return -1
lower_bound == 0
upper_bound == arr.length -1
return binary_search(arr, lower_bound, upper_bound, x)Посчитаем сложность бинарного поиска:
Best case. Как и у линейного поиска, лучший случай равен O(1), ведь искомое число может находиться в середине массива, и тогда мы найдём его с первой попытки.
Worst case. Чтобы найти худший случай, нужно ответить на вопрос: «Сколько раз нужно разделить массив на 2, чтобы в нём остался один элемент?» Или найти минимальное число k, при котором справедливо 2^k ≥ n.
Надеюсь, что большинство читателей смогут вычислить k. Но на всякий случай подскажу решение: k = log n по основанию 2 (в алгоритмах практически все логарифмы двоичные). Поэтому worst case бинарного поиска — O(log n).
Average case. Он тоже равен O(log n). И если для линейного поиска average case в два раза лучше, чем worst case, то тут они обычно отличаются всего на несколько шагов.
Ок, бинарный поиск лучше, но зачем тогда нужен линейный?
Часто студенты спрашивают: «Зачем нужен линейный поиск, если бинарный обходит его по всем позициям?» Отвечаю: линейный поиск работает с любыми массивами, а бинарный — только с отсортированными.
Мы дошли до важного принципа: чем сложнее структура данных, тем более быстрые алгоритмы к ней можно применять. Отсортированный массив — более сложная структура, чем неотсортированный. Забегу вперёд и скажу, что сортировка в общем случае требует от O(n * log(n)) до O(n^2) времени.
Создать дополнительные структуры данных несложно, вот только это не бесплатное удовольствие. Они едят много памяти. Как правило, O(n). Отсюда вытекает довольно логичный, но обидный вывод: время и память — «взаимообмениваемые» ресурсы. Алгоритм можно ускорить, пожертвовав памятью, или решать задачу медленно, зато in-place. Кроме того, почти всегда есть промежуточный вариант.
Решить одну и ту же проблему зачастую можно тремя способами. Задача разработчика — выбрать самый подходящий.
Как определить сложность алгоритма
Мы рассмотрели два алгоритма и увидели примеры их сложности. Но так и не поговорили о том, как эту сложность определять. Есть три основных способа.
Оценка «на глаз»
Первый и наиболее часто используемый способ. Именно так мы определяли сложность linear search и binary search. Обобщим эти примеры.
Первый случай. Есть алгоритм some_function, который выполняет действие А, а после него — действие В. На А и В нужно K и J операций соответственно.
int some_function():
action_A() // K operations
action_B() // J operationsВ случае последовательного выполнения действий сложность алгоритма будет равна O(K + J), а значит, O(max (K, J)). Например, если А равно n^2, а В — n, то сложность алгоритма будет равна O(n^2 + n). Но мы уже знаем, что нас интересует только самая быстрорастущая часть. Значит, ответ будет O(n^2).
Второй случай. Посчитаем сложность действий или вызова методов в циклах. Размер массива равен n, а над каждым элементом будет выполнено действие А (n раз). А дальше всё зависит от «содержимого» A.
Посчитаем сложность бинарного поиска:
int some_function(int [] arr):
n = arr.length
for i in 0..n:
action_A() // K operationsЕсли на каждом шаге A работает с одним элементом, то, независимо от количества операций, получим сложность O(n). Если же A обрабатывает arr целиком, то алгоритм совершит n операций n раз. Тогда получим O(n * n) = O(n^2). По такой же логике можно получить O(n * log n), O(n^3) и так далее.
Третий случай — комбо. Для закрепления соединим оба случая. Допустим, действие А требует log(n) операций, а действие В — n операций. На всякий случай напомню: в алгоритмах всегда идёт речь о двоичных логарифмах.
Добавим действие С с пятью операциями и вот что получим:
int some_function(int [] arr):
n = arr.length
for i in 0..n:
for j in 0..n:
action_A(arr) // log(n) operations
action_B(arr) // n operations
action_C() // 5 operationsO(n * (n * log(n) + n) + 5) = O(n^2 * log(n) + n^2 + 5) = O(n^2 * log(n)).
Мы видим, что самая дорогая часть алгоритма — действие А, которое выполняется во вложенном цикле. Поэтому именно оно доминирует в функции.
Есть разновидность определения на глаз — амортизационный анализ. Это относительно редкий, но достойный упоминания гость. В двух словах его можно объяснить так: если на X «дешёвых» операций (например, с O(1)) приходится одна «дорогая» (например, с O(n)), то на большом количестве операций суммарная сложность получится неотличимой от O(1).
Частый пациент амортизационного анализа — динамический массив. Это массив, который при переполнении создаёт новый, больше оригинального в два раза. При этом элементы старого массива копируются в новый.
Практически всегда добавление элементов в такой массив «дёшево» — требует лишь одной операции. Но когда он заполняется, приходится тратить силы: создавать новый массив и копировать N старых элементов в новый. Но так как массив каждый раз увеличивается в два раза, переполнения случаются всё реже и реже, поэтому average case добавления элемента равен O(1).
Мастер-теорема
Слабое место прикидывания на глаз — рекурсия. С ней и правда приходится тяжко. Поэтому для оценки сложности рекурсивных алгоритмов широко используют мастер-теорему.
По сути, это набор правил по оценке сложности. Он учитывает, сколько новых ветвей рекурсии создаётся на каждом шаге и на сколько частей дробятся данные в каждом шаге рекурсии. Это если вкратце.
Метод Монте-Карло
Метод Монте-Карло применяют довольно редко — только если первые два применить невозможно. Особенно часто с его помощью описывают производительность систем, состоящих из множества алгоритмов.
Суть метода: берём алгоритм и гоняем его на случайных данных разного размера, замеряем время и память. Полученные измерения выкладываем на отдельные графики для памяти и времени. А затем автоматически вычисляется функция, которая лучше всего описывает полученное облако точек.
Как ещё оценивают сложность алгоритмов
На протяжении всей статьи мы говорили про Big O Notation. А теперь сюрприз: это только одна из пяти существующих нотаций. Вот они слева направо: Намджун, Чонгук, Чингачгук… простите, не удержался. Сверху вниз: Small o, Big O, Big Theta, Big Omega, Small omega. f — это реальная функция сложности нашего алгоритма, а g — асимптотическая.

Несколько слов об этой весёлой компании:
- Big O обозначает верхнюю границу сложности алгоритма. Это идеальный инструмент для поиска worst case.
- Big Omega (которая пишется как подкова) обозначает нижнюю границу сложности, и её правильнее использовать для поиска best case.
- Big Theta (пишется как О с чёрточкой) располагается между О и омегой и показывает точную функцию сложности алгоритма. С её помощью правильнее искать average case.
- Small o и Small omega находятся по краям этой иерархии и используются в основном для сравнения алгоритмов между собой.
«Правильнее» в данном контексте означает — с точки зрения математических пейперов по алгоритмам. А в статьях и рабочей документации, как правило, во всех случаях используют «Большое „О“».
Если хотите подробнее узнать об остальных нотациях, посмотрите интересный видос на эту тему. Также полезно понимать, как сильно отличаются скорости возрастания различных функций. Вот хороший cheat sheet по сложности алгоритмов и наглядная картинка с графиками оттуда:
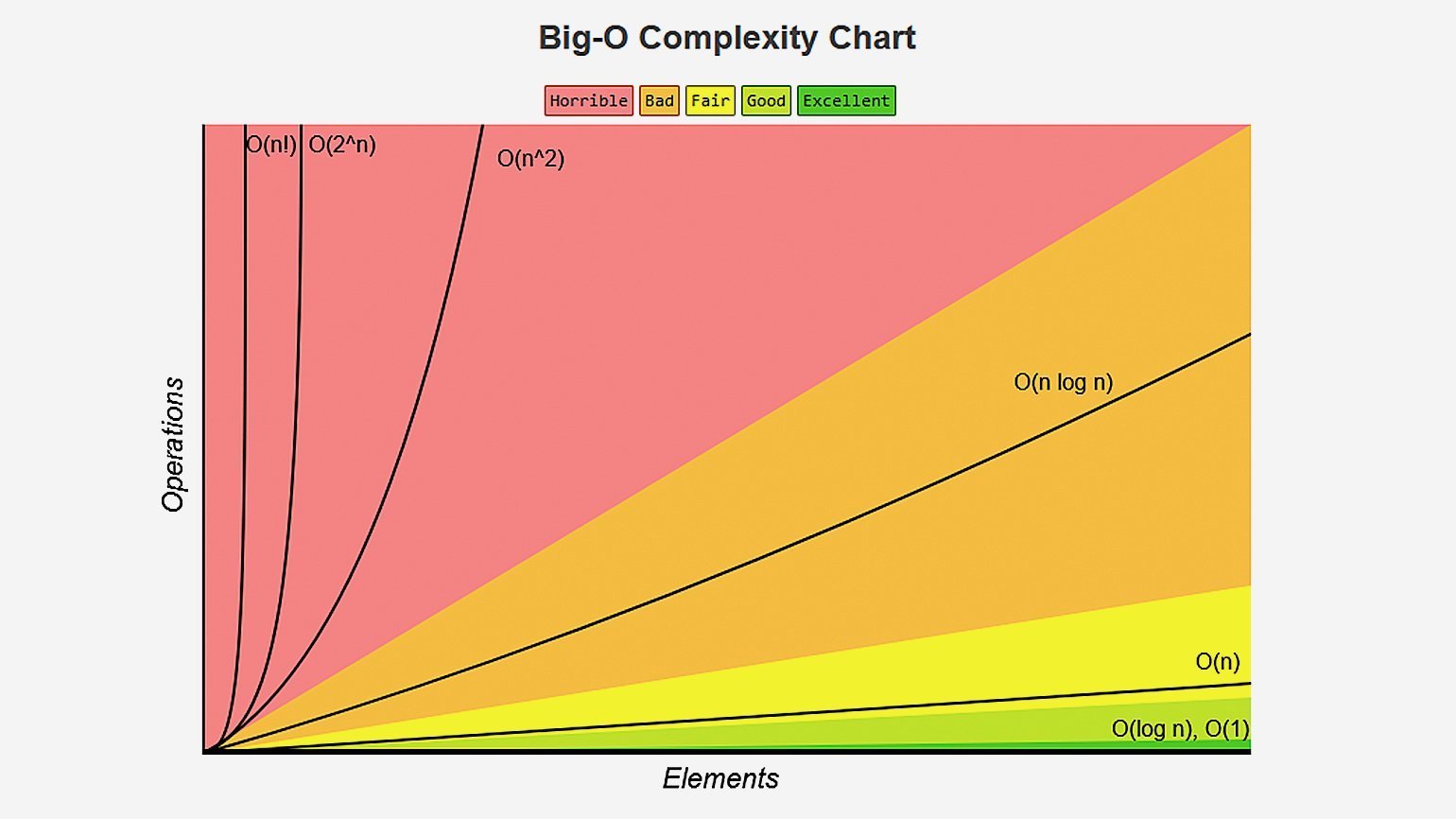
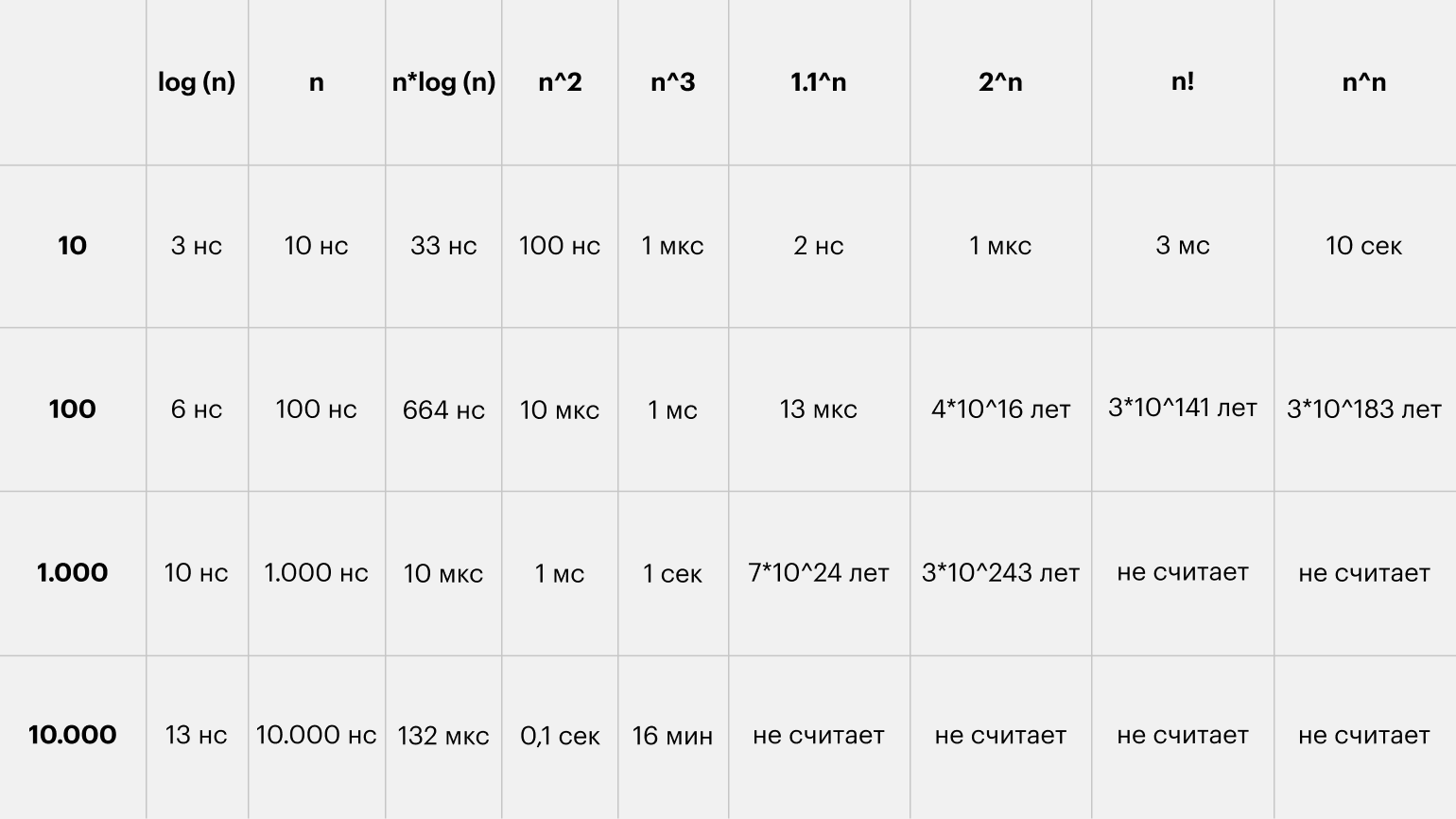
Хоть картинка и наглядная, она плохо передаёт всю бездну, лежащую между функциями. Поэтому я склепал таблицу со значениями времени для разных функций и N. За время одной операции взял 1 наносекунду:
Скрытые константы
В последнем разделе поговорим о скрытых константах. Это хитрая штука, там собака зарыта.
Возьмём умножение матриц. При размерности матрицы n * n наивный алгоритм, который многие знают с начальных курсов универа, «строчка на столбик» имеет кубическую временную сложность O(n^3). Кубическая, зато честная. Без констант и O(10000 * n^3) под капотом. И памяти не ест — только время.
У Валерия есть отдельный тред об умножении матриц.
В некоторых алгоритмах умножения матриц степень n сильно «порезана». Самые «быстрые» из них выдают время около O(n^2,37). Какой персик, правда? Почему бы нам не забыть про «наивный» алгоритм?
Проблема в том, что у таких алгоритмов огромные константы. В пейперах гонятся за более компактной экспонентой, а степени отбрасываются. Я не нашёл внятных значений констант. Даже авторы оригинальных пейперов называют их просто «очень большими».
Давайте от балды возьмём не очень большую константу 100 и сравним n^3 c 100 * n^2,37. Правая функция даёт выигрыш по сравнению с левой для n, начинающихся с 1495. А ведь мы взяли довольно скромную константу. Подозреваю, что на практике они не в пример больше…
В то же время умножение матриц 1495 × 1495 — очень редкий случай. А матрицы миллиард на миллиард точно нигде не встретишь. Да простит меня Император Душнил с «Хабра» за вольное допущение :)
Такие алгоритмы называются галактическими, потому что дают выигрыш только на масштабах, нерелевантных для нас. А в программном умножении матриц, если я правильно помню курс алгоритмов и умею читать «Википедию», очень любят алгоритм Штрассена с его O(2,807) и маленькими константами. Но и те, к сожалению, жрут слишком много памяти.





