Регулярные выражения в JavaScript: как они устроены и для чего нужны
Один разработчик выучил все регулярки и был причислен к лику святых.


Каждый день в интернете появляются гигабайты нового текста: статей, постов, комментариев, сообщений в чатах. Чтобы со всем этим можно было работать с помощью кода, используют регулярные выражения — о них сегодня и поговорим.
Что такое регулярные выражения
Регулярные выражения — это специальные комбинации символов для поиска и обработки текста. Механика у них простая: вы составляете шаблон слова, которое вам нужно, а программа находит все строки с этим словом. Чтобы искать точнее, для шаблонов можно задавать команды — например, найти все слова без учёта регистра.
Регулярные выражения в JavaScript обычно пишут между двумя наклонными чертами. А сразу за ними идут команды — их называют «флагами».
/регулярное выражение/флаги
Внимательный читатель спросит: а чем это отличается от обычной функции «найти и заменить», которая есть в любом «Ворде»? Фишка в том, что можно сочетать регулярки с обычным кодом и обрабатывать любой текст по правилам, менять строки местами, извлекать отдельные слова, передавать информацию на сервер — что угодно.
Например, можно написать простую форму для оформления рассылки по email — чтобы отклоняла неправильные адреса, а правильные сохраняла в базу.
Работать будет так:
- Пользователь заходит на сайт и вводит свой email: dartanyan2mail.ru.
- JavaScript сравнивает адрес с регулярным выражением.
- Выясняется, что адрес не совпадает с шаблоном — не хватает знака @.
- Пользователь получает ошибку и ставит недостающий символ.
Звучит просто, но смотрите, как будет выглядеть регулярное выражение для валидации email-адреса:
/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igmКогда начинающий программист видит такое, он впадает в ступор, хмурится и уходит дальше писать код, делая вид, что ничего не произошло. Если у вас тоже такая реакция — не переживайте, сейчас будем во всём разбираться.

Изображение: Telegram-канал «Программисты шутят»
Специальные символы
Настало время разобраться, зачем нужны все эти фигурные скобки, доллары, слэши и прочие эльфийские руны.
Представьте: вы пришли в букинистический магазин, чтобы купить редкое издание «Войны и мира» Льва Толстого 1886 года. Чтобы не копаться в стеллажах самому, скорее всего, вы обратитесь за помощью к продавцу. Продавец знает, где в магазине что лежит, и в два счёта отыщет нужную книгу.
В случае с регулярками принцип тот же: вы говорите компьютеру, что нужно найти, задаёте условия, и он ищет. Но загвоздка в том, что машина не понимает слова и предложения: ей подавай простые формальные команды, и чем короче их можно записать, тем меньше памяти всё это будет потреблять.
Один специальный символ означает одно условие поиска. Чем больше условий, тем сложнее будут комбинации символов.
Допустим, у вас есть большая база резюме разработчиков и вы хотите достать оттуда все Telegram-никнеймы. Как это сделать?
Шаг 1. Найдём все никнеймы формата @username, состоящие из латинских букв. Выражение внутри квадратных скобок означает «любая строчная латинская буква».
/@[a-z]/
Шаг 2. Добавим в шаблон дефисы, проценты и нижние подчёркивания.
/@[a-z0-9_-%]/Шаг 3. Зададим размер слова в символах — если этого не сделать, машина будет выдавать юзернеймы по слогам или отдельным буквам. В нашем случае интервал будет от 5 до 32 символов (такого размера все никнеймы в Telegram).
/@[a-z0-9_-]{5, 32}/Шаг 4. Зададим начало и конец фразы, чтобы в выдачу не попали адреса электронной почты. Сделать это можно с помощью символов ^ и $.
/^@[a-z0-9_-%]{5,32}$/gФинальный штрих — флаги. У регулярок есть странная особенность: по умолчанию алгоритм находит в строке не все совпадения, а только первое. Чтобы это исправить, добавим нашему выражению флаг g, который включает глобальный поиск.
В JavaScript есть и другие флаги: например, m — многострочный поиск, i — поиск без учёта регистра, а флаг u ищет по символам Юникода — например, эмодзи или иероглифам. Как правило, этого набора хватает.
Была белиберда, а получилась чуть более понятная белиберда. Едем дальше.
Как создать регулярное выражение в JavaScript
Сделать это можно двумя способами.
Классический. Составляем регулярку, оборачиваем её двумя косыми чертами и помещаем в переменную или константу. Потом, если нужно, добавляем флаги. Способ простой, работает почти во всех языках: Java, Python, PHP. C# и так далее. Для большинства задач вам хватит именно его.
var regexp = /шаблон/флагиЧерез конструктор. Тут немного посложнее: сначала нужно создать объект RegExp(), а уже в него положить регулярное выражение. Причём шаблон и флаги прописывают через запятую, в одинарных кавычках — никаких слэшей.
var regexp = new RegExp('шаблон', 'флаги')Второй способ хорош тем, что позволяет менять выражение на лету, прямо во время исполнения программы. Это удобно, если вы загружаете шаблон из стороннего источника — например, из базы данных.
Что можно делать с регулярками в JavaScript: основные функции
Сами по себе регулярные выражения — это просто шаблоны для поиска текста. Чтобы они могли совершать в программе какое-то действие, их надо поместить в функцию. В JavaScript есть два типа функций, которые работают с регулярками:
- строковые — базовый набор для обработки любого текста;
- RegExp-функции — заточенные конкретно под регулярные выражения.
Строковые функции
1. search — простой поиск. Показывает, в каком месте строки есть совпадение с шаблоном. Например, код ниже ищет слово world во фразе «Hello, world!». А так как оно начинается с седьмой буквы, результатом будет «7».
var str = "Hello, world!";
var regexp = str.search(/world/i);2. match — найти и показать в виде текста. Тут уже поинтереснее: если функция search просто ищет место в строке, то match находит все слова по шаблону и выдаёт их списком.
Допустим, у вас есть какой-то список имён и нужно достать оттуда только те, что написаны на латинице:
var names = 'Саша, Carl, Лена, Оля, Sam, Peter, Лев';
console.log(names.match(/[a-zA-Z]{1,10}/gi));Результат будет такой: ['Carl', 'Sam', 'Peter'].
3. replace — найти и заменить. Позволяет заменить слово целиком или по буквам и слогам. Если копнуть чуть глубже, можно даже менять слова местами в пределах одной фразы:
const a = 'Роняет лес багряный свой убор';
const b = str.replace(/(\W+)\s(\W+)\s(\W+)\s(\W+)\s(\W+)/, '$2 $1 $4 $3 $5');
console.log(b);Было:
«Роняет лес багряный свой убор».
Стало:
«Лес роняет свой багряный убор».
4. split — разбить одну строку на несколько частей. Разделять можно как угодно: хоть по слогам, хоть по буквам, хоть по знакам препинания. Для примера давайте разберём на части какую-нибудь строку из Шекспира:
let message = 'Что есть любовь? Безумье от угара, игра с огнём, ведущая к пожару!';
let sentences = message.split(/[.,!,?]/);
console.log(sentences);В итоге получим вот такой набор фраз: ['Что есть любовь', ' Безумье от угара', ' игра с огнём', ' ведущая к пожару', '']. Может, это и бесполезно, зато красиво :)
Функции объекта RegExp
Новичкам стоит обратить внимание на два метода RegExp:
1. test — проверяет, совпадает ли строка с шаблоном. Если совпадение есть, вернёт true, если нет — вернёт false. Звучит примитивно, но на этой функции работает львиная доля всех форм авторизации в интернете.
Возьмём, например, нашу регулярку для проверки электронной почты. Сама по себе она ничего не проверяет — но если завернуть её в функцию test, получится надёжная система авторизации — бери и используй.
var str = "media@skillbox.ru";
var email = (/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igm.test(str));
console.log(email);2. exec — найти и показать в виде текста. Работает точно так же, как и match, но возвращает только первую найденную строку.
Ещё несколько примеров
Разберём ещё несколько жизненных ситуаций, в которых могут пригодиться регулярные выражения.
Проверить почтовый трек-номер. Допустим, вы делаете чат-бот для отслеживания посылок с AliExpress — чтобы пользователь мог ввести свой трек-номер и узнать, где едет его чехол или браслет. Если брать за основу трек-коды Почты России, регулярное выражение будет выглядеть так:
/^[0-9]{14}$/Удалить все HTML-теги. Ситуация: вы спарсили из интернета какой-то текст и хотите очистить его от лишней разметки. Чтобы найти в документе все HTML-теги, используют выражение <.*?>. А для комментариев — <!--(.*?)-->.
Проверить биткоин-кошелёк. Допустим, вы настраиваете на сайте оплату в криптовалюте. Чтобы форма принимала только правильные биткоин-адреса, можно использовать вот такой шаблон:
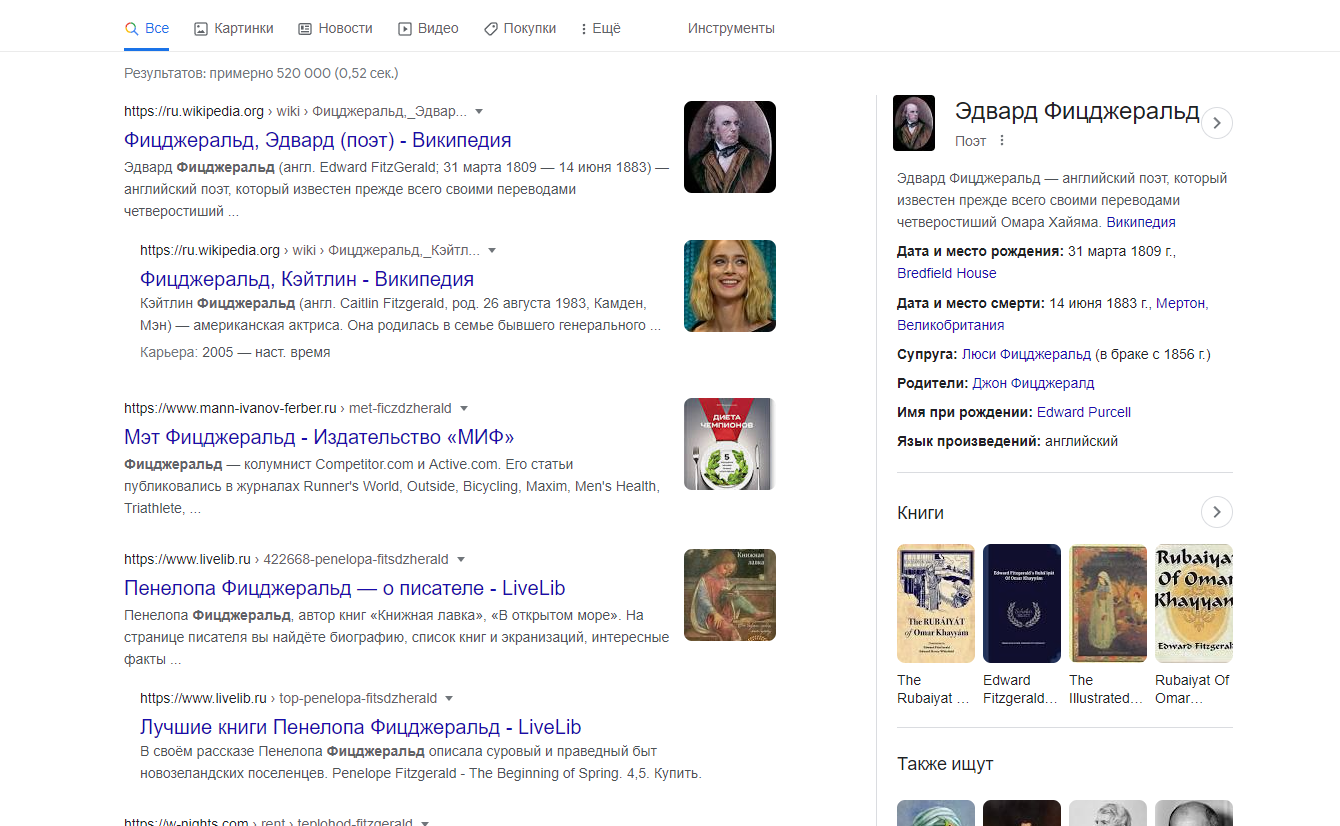
^[13][a-km-zA-HJ-NP-Z1-9]{25,34}$Искать в Google. Знаменитый поисковик поддерживает некоторые возможности регулярок. Например, фраза -Фрэнсис Фицджеральд найдёт всех Фицджеральдов, которых зовут не Фрэнсис. А выражение (gray|red) (wolf|fox) отыщет всех серых волков и рыжих лисиц — и наоборот. Попробуйте сами.
Что дальше
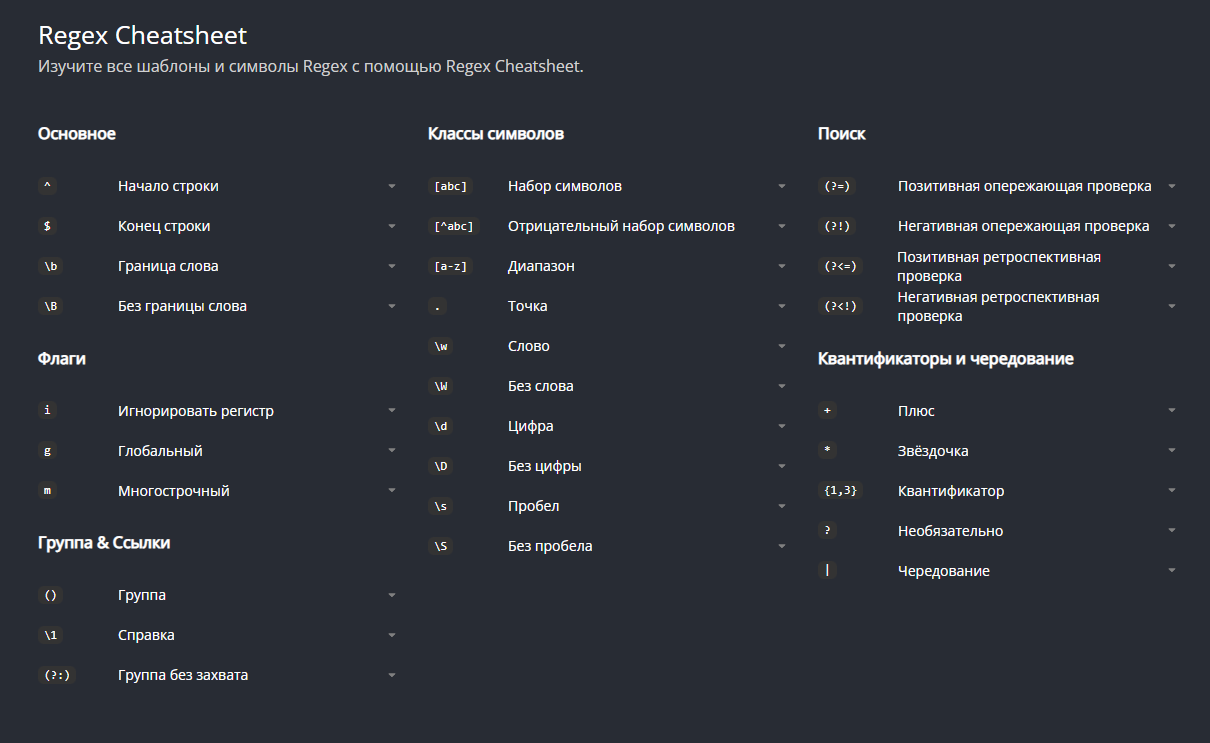
Чтобы изучить все возможности регулярок, никаких статей не хватит. Если хотите лучше в этом разбираться, почитайте книгу «Регулярные выражения» Джеффри Фридла — это хороший гайд для новичков с понятной теорией и примерами. Или попробуйте бесплатные тренажёры на сайте regexlearn.com — чтобы сразу практиковаться в изученном. Вот хорошая шпаргалка оттуда: