Работаем с Pandas: основные понятия и реальные данные
Разбираемся в том, как работает библиотека Pandas, и проводим первый анализ данных.


Python используют для анализа данных и машинного обучения, подключая к нему различные библиотеки: Pandas, Matplotlib, NumPy, TensorFlow и другие. Каждая из них используется для решения конкретных задач.
Сегодня мы поговорим про Pandas: узнаем, для чего нужна эта библиотека, как импортировать её в Python, а также проанализируем свой первый датасет и выясним, в каких странах самый быстрый и самый медленный интернет.
Для чего нужна библиотека Pandas в Python
Pandas — главная библиотека в Python для работы с данными. Её активно используют аналитики данных и дата-сайентисты. Библиотека была создана в 2008 году компанией AQR Capital, а в 2009 году она стала проектом с открытым исходным кодом с поддержкой большого комьюнити.
Вот для каких задач используют библиотеку.
Аналитика данных: продуктовая, маркетинговая и другая. Работа с любыми данными требует анализа и подготовки: необходимо удалить или заполнить пропуски, отфильтровать, отсортировать или каким-то образом изменить данные. Pandas в Python позволяет быстро выполнить все эти действия, а в большинстве случаев ещё и автоматизировать их.
Data science и работа с большими данными. Pandas помогает подготовить и провести первичный анализ данных, чтобы потом использовать их в машинном или глубоком обучении.
Статистика. Библиотека поддерживает основные статистические методы, которые необходимы для работы с данными. Например, расчёт средних значений, их распределение по квантилям и другие.
Работа с Pandas
Для анализа данных и машинного обучения обычно используются особые инструменты: Google Colab или Jupyter Notebook. Это специализированные IDE, позволяющие работать с данными пошагово и итеративно, без необходимости создавать полноценное приложение.
В этой статье мы посмотрим на Google Colab, облачное решение для работы с данными, которое можно запустить в браузере на любом устройстве: десктопе, ноутбуке, планшете или даже смартфоне.
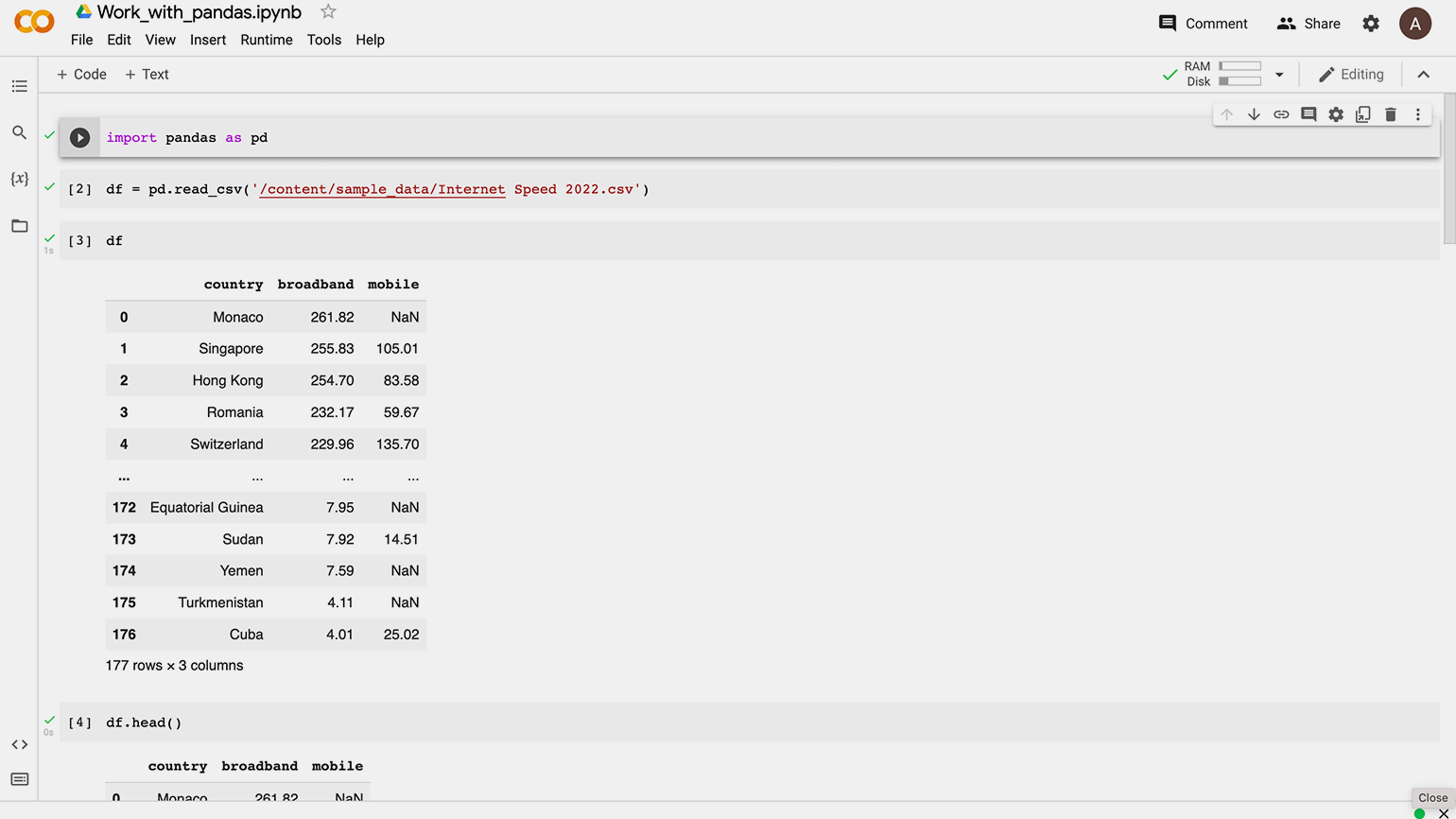
Каждая строчка кода на скриншоте — это одно действие, результат которого Google Colab и Jupyter Notebook сразу демонстрируют пользователю. Это удобно в задачах, связанных с аналитикой и data science.
Устанавливать Pandas при работе с Jupyter Notebook или Google Colab не требуется. Это стандартная библиотека, которая будет доступна сразу после их запуска. Останется только импортировать её в ваш код.
import pandas as pdpd — общепринятое сокращение для Pandas в коде. Оно встречается в книгах, статьях и учебных курсах. Используйте его и в своих программах, чтобы не писать длинное pandas.
Series и DataFrame
Данные в Pandas представлены в двух видах: Series и DataFrame. Разберёмся с каждым из них.
Series — это объект, который похож на одномерный массив и может содержать любые типы данных. Проще всего представить его как столбец таблицы с последовательностью каких-либо значений, у каждого из которых есть индекс — номер строки.
Создадим простой Series:
import pandas as pd # Импортируем библиотеку Pandas.
series_example = pd.Series([4, 7, -5, 3]) # Создаём объект Series, содержащий числа.
series_example # Выводим объект на экран.Теперь выведем его на экран:
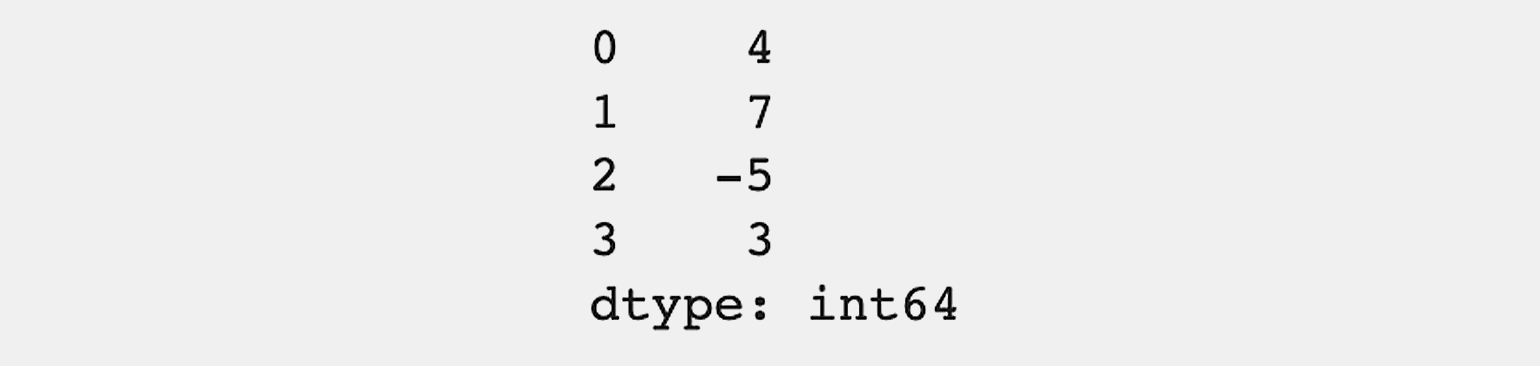
Series отображается в виде таблицы с индексами элементов в первом столбце и значениями во втором.
DataFrame — основной тип данных в Pandas, вокруг которого строится вся работа. Его можно представить в виде обычной таблицы с любым количеством столбцов и строк. Внутри ячеек такой «таблицы» могут быть данные самого разного типа: числовые, булевы, строковые и так далее.
У DataFrame есть и индексы строк, и индексы столбцов. Это позволяет удобно сортировать и фильтровать данные, а также быстро находить нужные ячейки.
Создадим простой DataFrame с помощью словаря и посмотрим на его отображение:
import pandas as pd # Импортируем библиотеку Pandas.
city = {'Город': ['Москва', 'Санкт-Петербург', 'Новосибирск', 'Екатеринбург'],
'Год основания': [1147, 1703, 1893, 1723],
'Население': [11.9, 4.9, 1.5, 1.4]} # Создаём словарь с нужной информацией о городах.
df = pd.DataFrame(city) # Превращаем словарь в DataFrame, используя стандартный метод библиотеки.
df # Выводим DataFrame на экран.Посмотрим на результат:
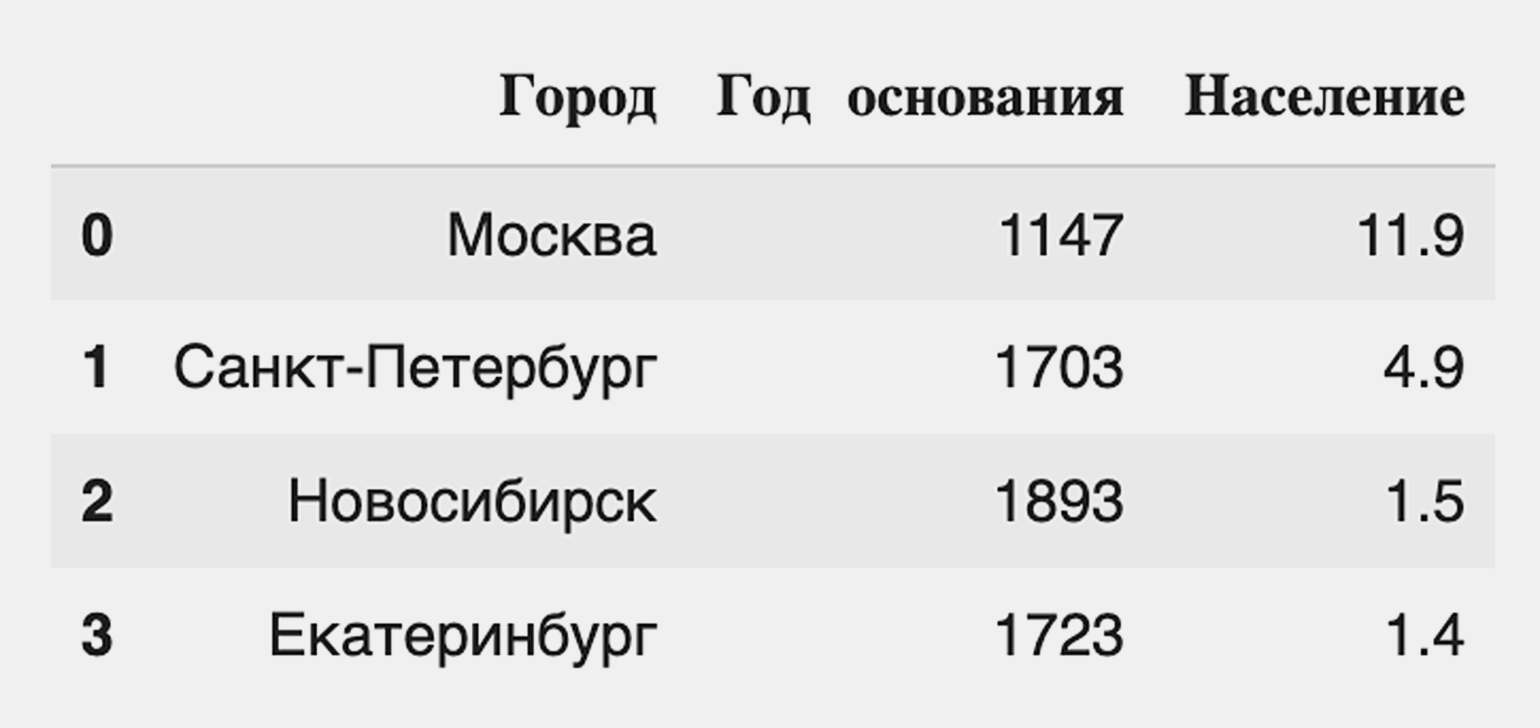
Мы видим таблицу, строки которой имеют индексы от 0 до 3, а «индексы» столбцов соответствуют их названиям. Легко заметить, что датафрейм состоит из трёх Series: Город, Год основания и Население. Оба типа индексов можно использовать для навигации по данным.
Импорт данных
Pandas позволяет импортировать данные разными способами. Например, прочесть их из словаря, списка или кортежа. Самый популярный способ — это работа с файлами .csv, которые часто применяются в анализе данных. Для импорта используют команду pd.read_csv().
read_csv имеет несколько параметров для управления импортом:
- sep позволяет явно указать разделитель, который используется в импортируемом файле. По умолчанию значение равно ,, что соответствует разделителю данных в файлах формата .csv. Этот параметр полезен при использовании нестандартных разделителей в исходном файле, например табуляции или точки с запятой;
- dtype позволяет указать тип данных в столбцах после загрузки файла формата .csv. Полезно в тех случаях, когда формат данных автоматически определился неверно. Например, даты часто импортируются в виде строковых переменных, хотя для них существует отдельный тип.
Подробно параметры, позволяющие настроить импорт csv, описаны в документации.
Давайте импортируем датасет с информацией о скорости мобильного и стационарного интернета в отдельных странах. Готовый датасет скачиваем с Kaggle. Это файл в формате .csv. Параметры для read_csv не указываем, так как наши данные уже подготовлены для анализа.
df = pd.read_csv('/content/Internet Speed 2022.csv')Теперь посмотрим на получившийся датафрейм:
df
Важно!
При работе в Google Colab или Jupyter Notebook для вывода DataFrame или Series на экран не используется команда print. Pandas умеет показывать данные и без неё. Если же написать print (df), то табличная вёрстка потеряется. Попробуйте вывести данные двумя способами и посмотрите на результат.
На экране появилась вот такая таблица:
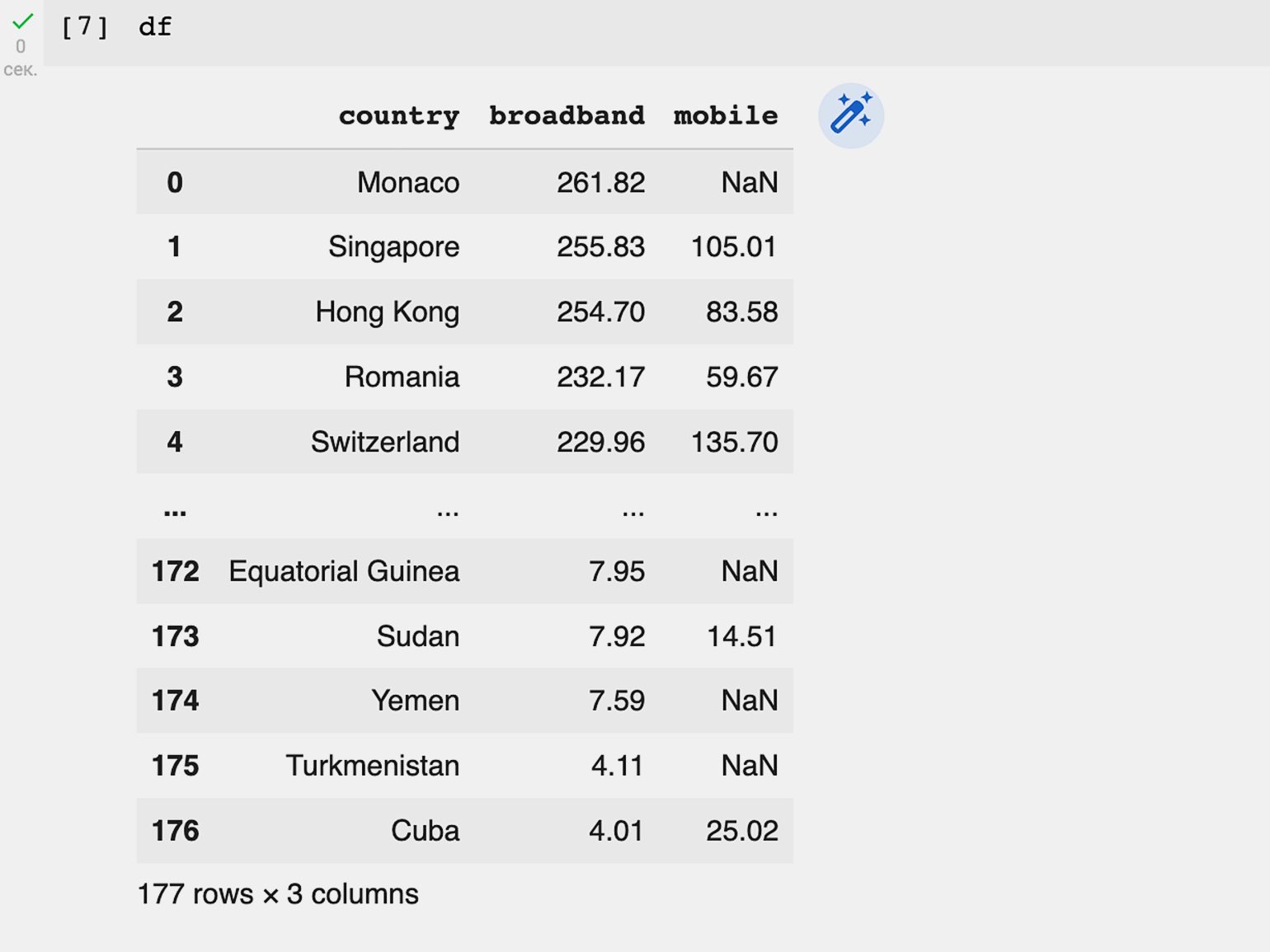
В верхней части датафрейма мы видим названия столбцов: country (страна), broadband (средняя скорость интернета) и mobile (средняя скорость мобильного интернета). Слева указаны индексы — от 0 до 176. То есть всего у нас 177 строк. В нижней части таблицы Pandas отображает и эту информацию.
Выводить таблицу полностью не обязательно. Для знакомства с данными достаточно показать пять первых или пять последних строк. Сделать это можно с помощью df.head() или df.tail() соответственно. В скобках можно указать число строк, которое которые будут выведены. По умолчанию параметр равен 5.
df.head()
Результат:

Так намного удобнее. Мы можем сразу увидеть названия столбцов и тип данных в столбцах. Также в некоторых ячейках мы видим значение NaN — к нему мы вернёмся позже.
Изучаем данные и описываем их
Теперь нам надо изучить импортированные данные. Действовать будем пошагово.
Шаг 1. Проверяем тип данных в таблице. Это поможет понять, в каком виде представлена информация в датасете — а иногда и найти аномалии. Например, даты могут быть сохранены в виде строк, что неудобно для последующего анализа. Проверить это можно с помощью стандартного метода:
df.dtypes
На экране появится таблица с обозначением типа данных в каждом столбце датафрейма:

Что мы видим:
- столбец country представляет собой тип object. Это тип данных для строковых и смешанных значений;
- столбцы broadband и mobile имеют тип данных float, то есть относятся к числам с плавающей точкой.
Шаг 2. Быстро оцениваем данные и делаем предварительные выводы. Сделать это можно очень просто: для этого в Pandas существует специальный метод describe(). Он показывает среднее со стандартным отклонением, максимальные, минимальные значения переменных и их разделение по квантилям.
Посмотрим на этот метод в деле:
df.describe()
Результат:

Пройдёмся по каждой строчке:
- count — это количество заполненных строк в каждом столбце. Мы видим, что в столбце с данными о скорости мобильного интернета есть пропуски.
- mean — среднее значение скорости обычного и мобильного интернета. Уже можно сделать вывод, что мобильный интернет в большинстве стран медленнее, чем кабельный.
- std — стандартное отклонение. Важный статистический показатель, показывающий разброс значений.
- min и max — минимальное и максимальное значения.
- 25%, 50% и 75% — значения скорости интернета по процентилям. Если не углубляться в статистику, то процентиль — это число, которое показывает распределение значений в выборке. Например, в выборке с мобильным интернетом 25-й процентиль показывает, что 25% от всех значений скорости интернета меньше, чем 24,4.
Обратите внимание, что этот метод работает только для чисел. Информация для столбца с названием стран отсутствует.
Какой вывод делаем? Проводной интернет в большинстве стран работает быстрее, чем мобильный. При этом скорость проводного интернета в 75% случаев не превышает 110 Мбит/с, а мобильного — 69 Мбит/сек.
Шаг 3. Сортируем и фильтруем записи. В нашем датафрейме данные уже отсортированы от большего к меньшему по скорости проводного интернета. Попробуем найти страну с наилучшим мобильным интернетом. Для этого используем стандартный метод sort_values, который принимает два параметра:
- Название столбца, по которому происходит сортировка, обязательно должно быть заключено в одинарные или двойные кавычки.
- Параметр ascending= указывает на тип сортировки. Если мы хотим отсортировать значения от большего к меньшему, то параметру присваиваем False. Для сортировки от меньшего к большему используем True.
Перейдём к коду:
df.sort_values('mobile', ascending=False).head()Результат:
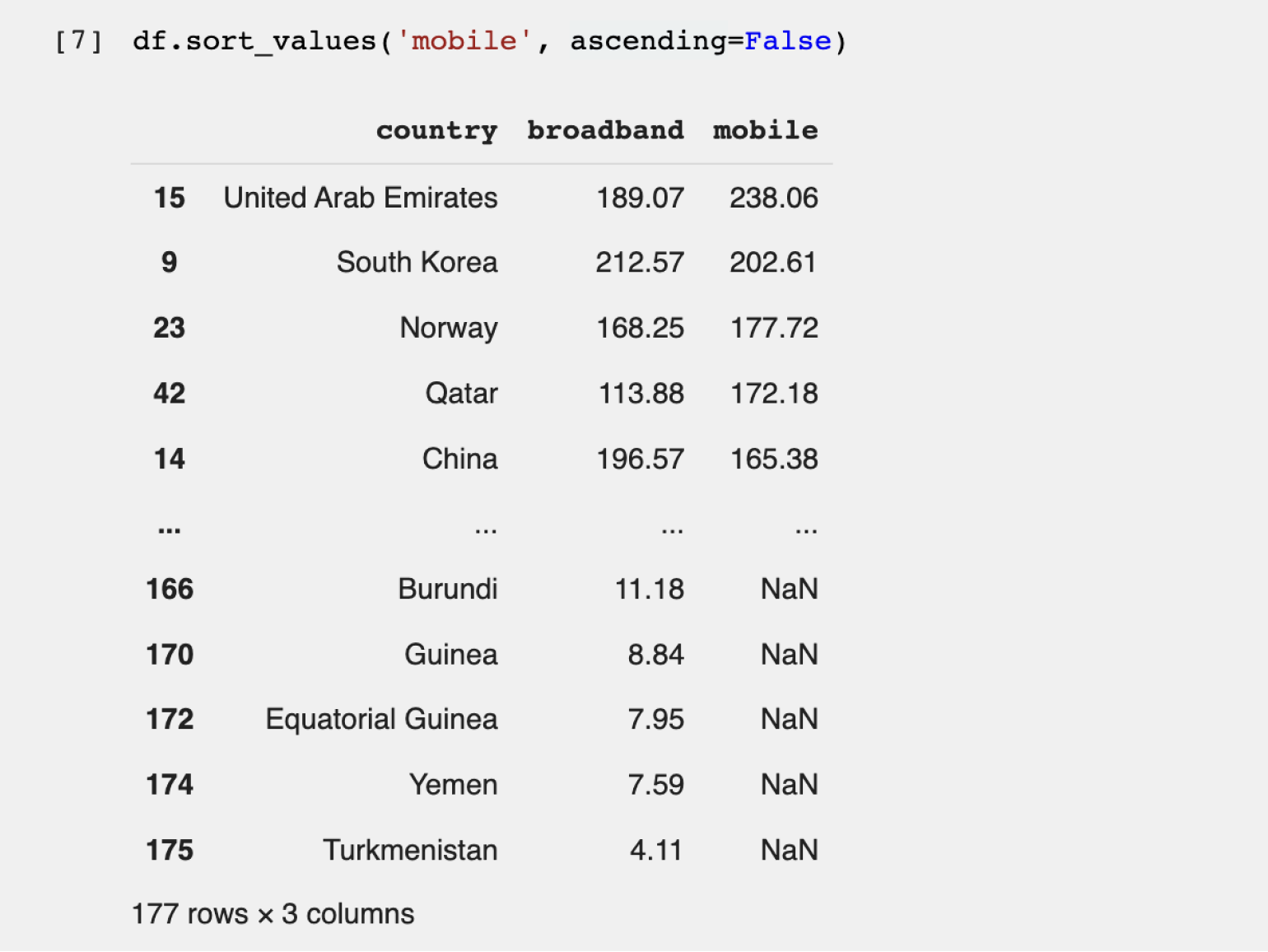
Теперь рейтинг стран другой — пятёрка лидеров поменялась (потому что мы отсортировали данные по другому значению). Мы выяснили, что самый быстрый мобильный интернет в ОАЭ.
Но есть нюанс. Если вернуться к первоначальной таблице, отсортированной по скорости проводного интернета, можно заметить, что у лидера — Монако — во втором столбце написано NaN.
NaN в Python указывает на отсутствие данных. Поэтому мы не знаем скорость мобильного интернета в Монако из этого датасета и не можем сделать однозначный вывод о лидерах в мире мобильной связи.
Попробуем отфильтровать значения, убрав из датафрейма страны с неизвестной скоростью мобильного интернета, и посмотрим на худшие по показателю страны (если оставить NaN, он будет засорять «дно» таблицы и увидеть реальные значения по самому медленному мобильному интернету будет сложновато).
В Pandas существуют различные способы фильтрации для удаления NaN. Мы воспользуемся методом dropna(), который удаляет все строки с пропусками. Важно, что удаляется полностью строка, содержащая NaN, а не только ячейки с пропущенными значениями в столбце с пропусками.
df.dropna()
Результат:
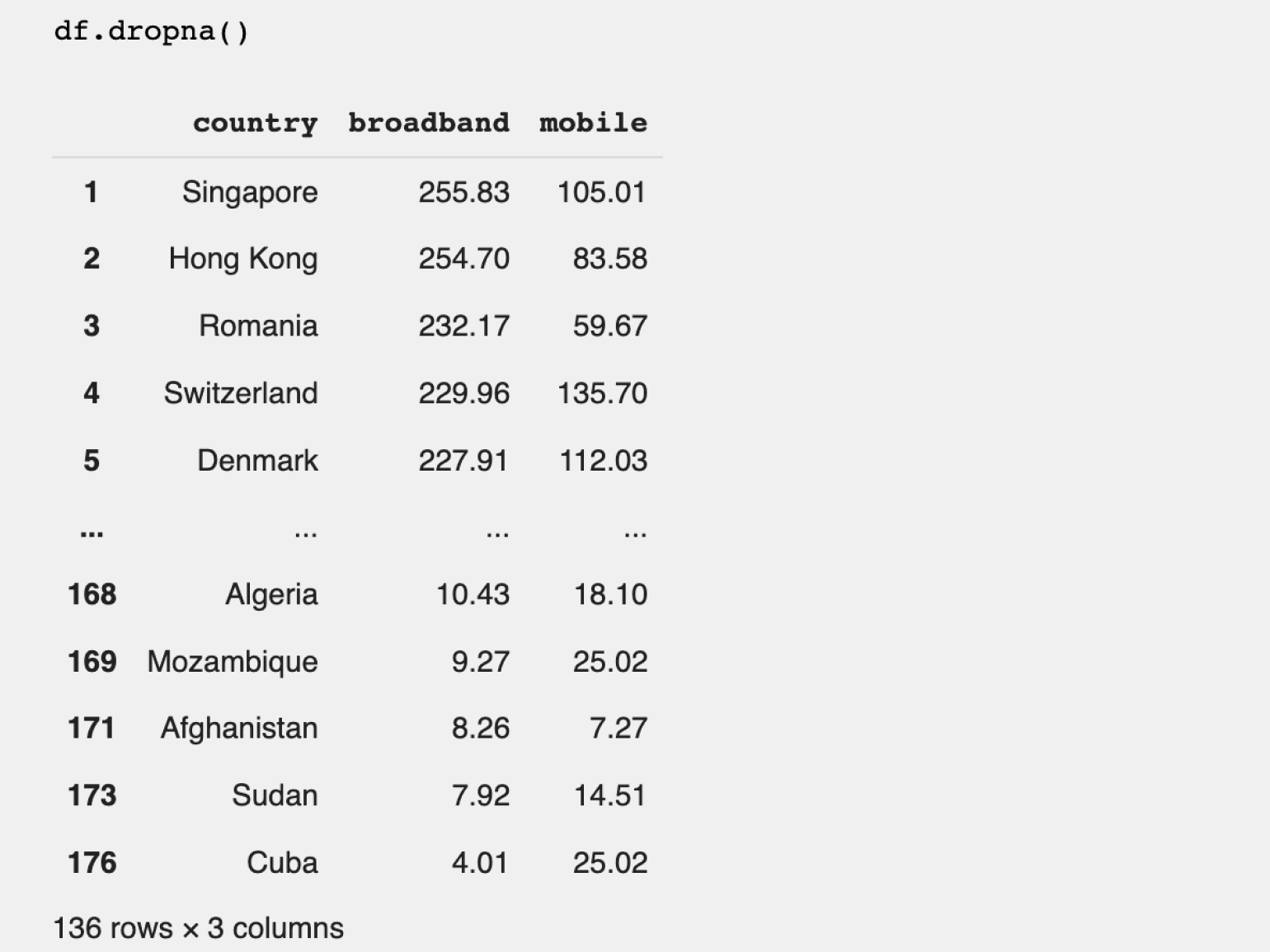
Количество строк в датафрейме при удалении пустых данных уменьшилось до 136. Если вернуться ко второму шагу, то можно увидеть, что это соответствует количеству заполненных строк в столбце mobile в начальном датафрейме.
Сохраним результат в новый датафрейм и назовём его df_without_nan. Изначальный DataFrame стараемся не менять, так как он ещё может нам понадобиться.
df_without_nan = df.dropna()
Теперь отсортируем полученные результаты по столбцу mobile — от меньшего к большему — и посмотрим на страну с самым медленным мобильным интернетом:
df_without_nan.sort_values('mobile', ascending=True)Результат:
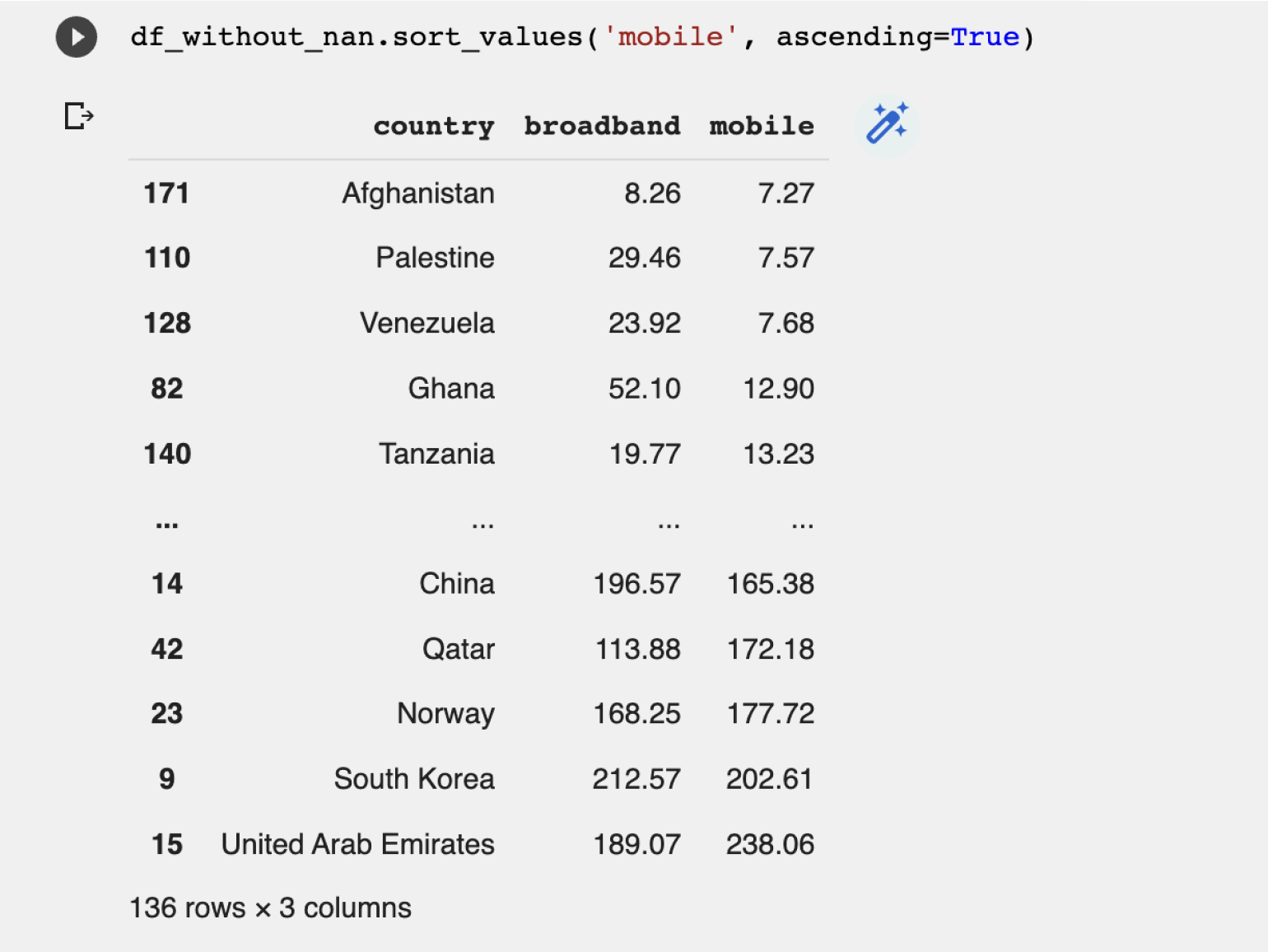
Худший мобильный интернет в Афганистане, далее с небольшим отставанием идут Палестина и Венесуэла.
Как можно редактировать датафрейм
Кроме как работать с существующим датафреймом, мы можем менять готовый датафрейм в зависимости от своих задач: добавлять новые строки, удалять существующие, агрегировать данные и так далее.
Вернём нашему df первоначальный вид. Загрузим csv с датасетом повторно:
df = pd.read_csv('/content/Internet Speed 2022.csv')Посмотрим на датафрейм:
df
Убедимся, что все данные на месте:
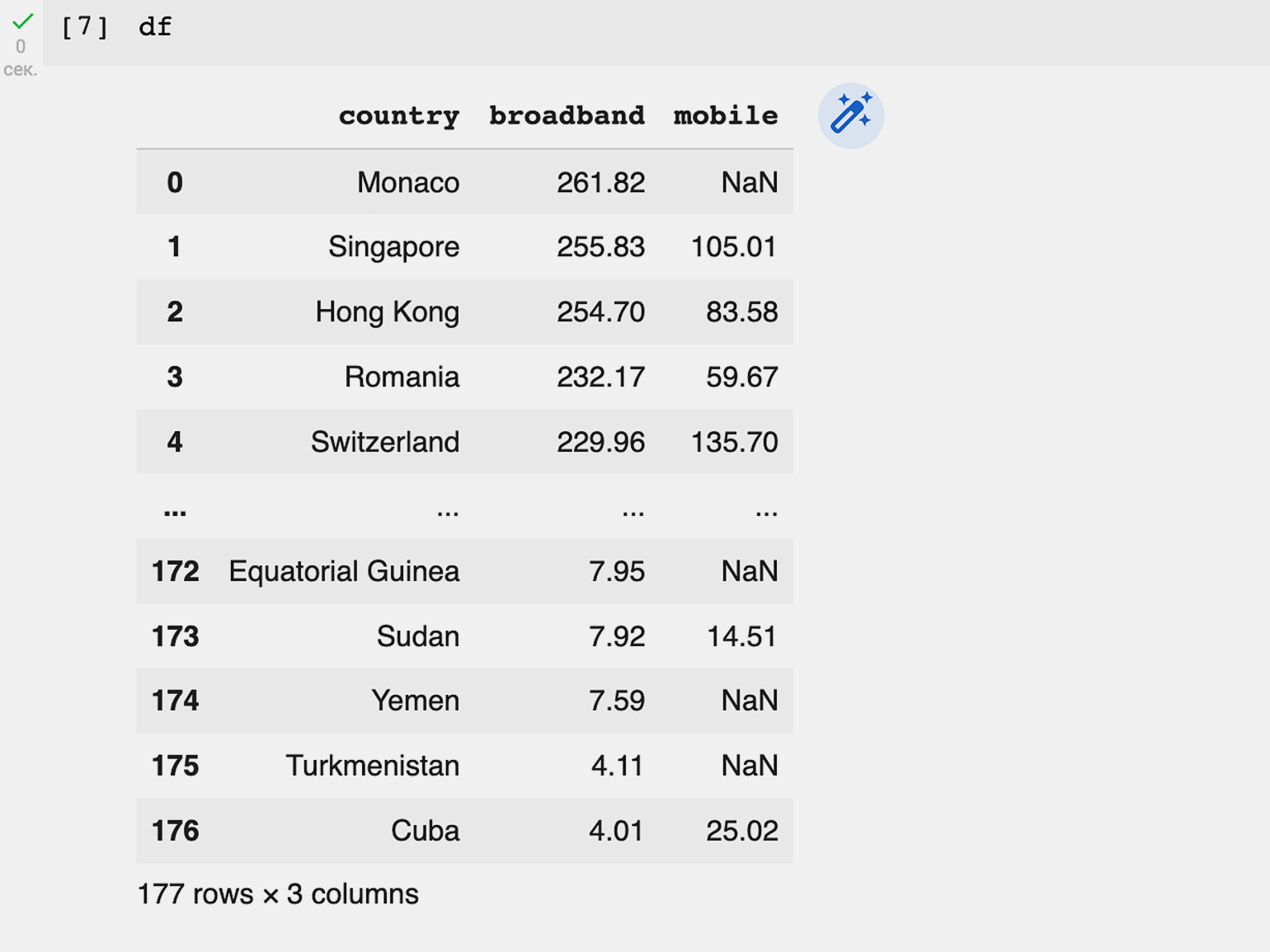
177 строк — все страны, в том числе те, данные о скорости интернета которых отсутствуют, в списке есть.
Добавление строки
Добавим в наш датафрейм новую страну. Так как в списке их уже 177, пусть это будет Галактическая Республика из «Звёздных войн».
Для добавления информации в датафрейм используется метод concat:
new_country = {'country': 'Галактическая Республика', 'broadband': 1342, 'mobile': 295.45}
df1 = pd.DataFrame([new_country])
new_list1 = pd.concat([df1,df], ignore_index=True)Разберём код построчно:
- Сначала мы создаём словарь, который будет содержать название страны, информацию о средней скорости интернета и средней скорости мобильного интернета.
- В конструкторе pd.DataFrame конвертируем словарь в датафрейм.
- С помощью метода concat объединяем изначальный датафрейм с новым в new_list. Не забываем указать ignore_index=True, чтобы новая строка появилась первой.
Проверим результат:
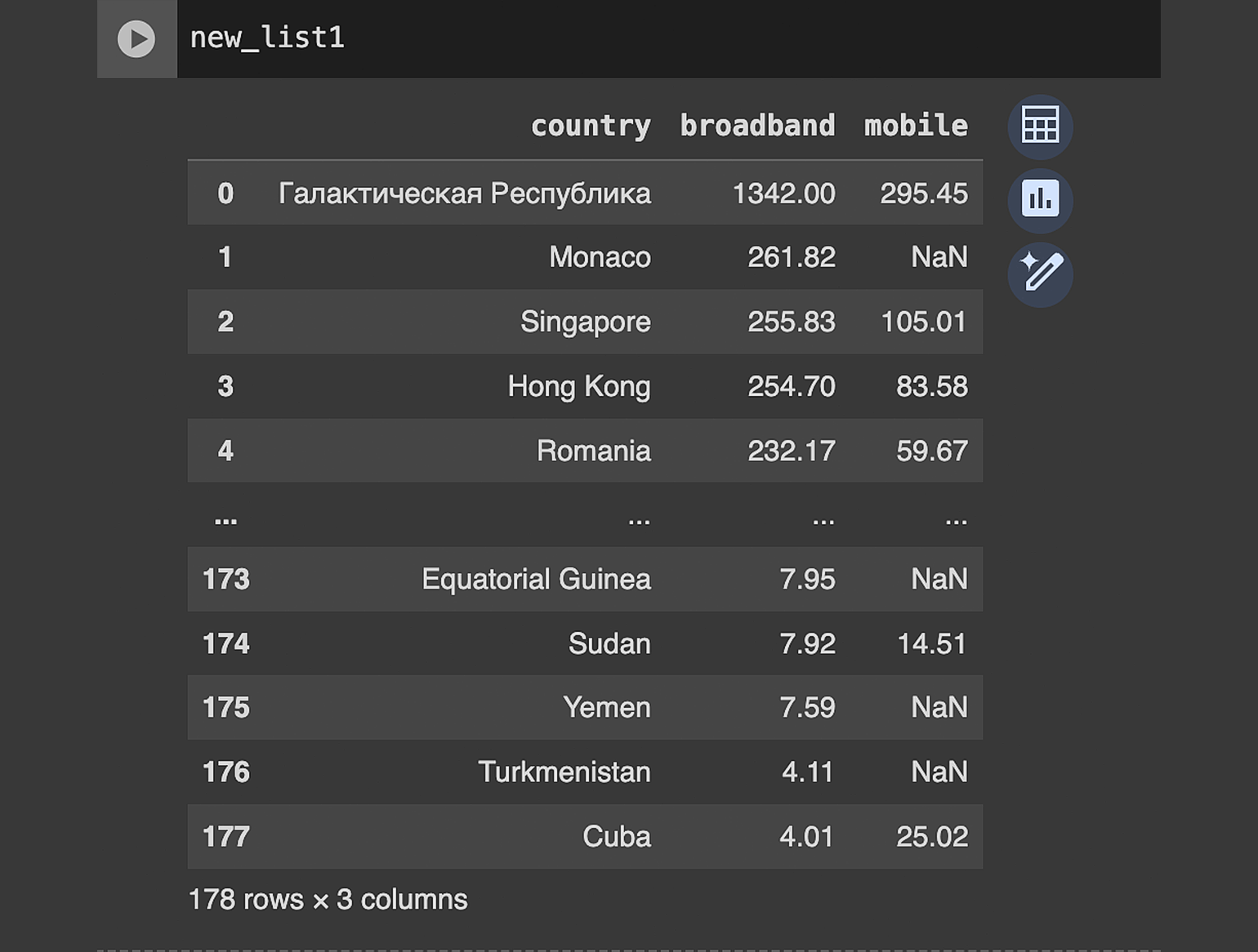
Всё получилось. Галактическая Республика в нашей таблице.
Удаление строк
Строки в Pandas удаляются методом drop. Давайте теперь с его помощью удалим несуществующую страну, которую мы добавили ранее в наш датафрейм:
new_list1.drop(0, inplace=True)В метод передаётся два параметра:
- Индекс строк, которые необходимо удалить, — в нашем случае это строка с индексом 0. Чтобы удалить несколько строк, нужно передать индексы списком. Например, [0, 1, 2].
- inplace=True — обнуляет индексы, чтобы у первой строки после удаления он стал равен 0.
Запустим код и выведем датафрейм:
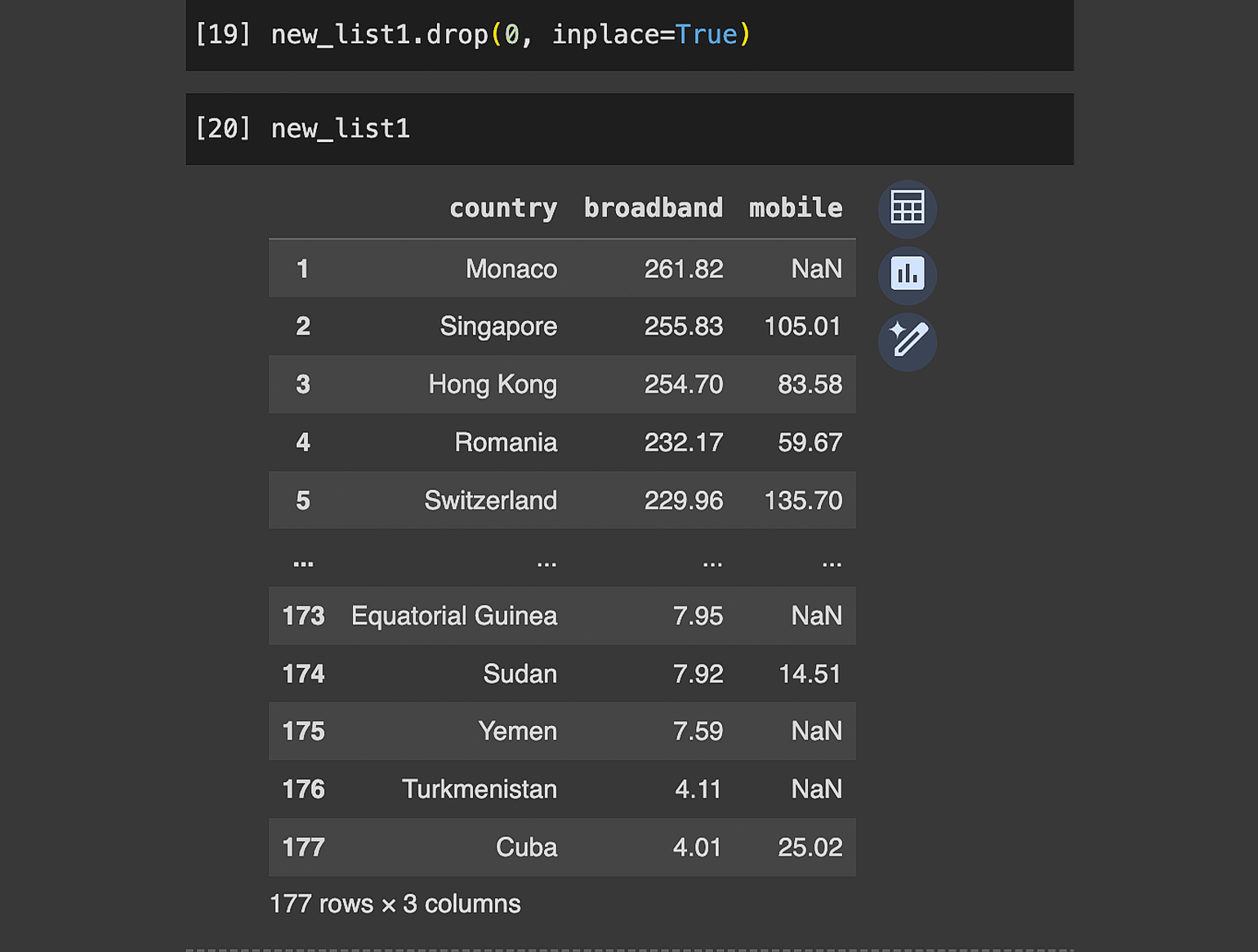
Галактической Республики больше нет. Датафрейм вернулся в изначальный вид.
Фильтрация строк
Иногда в датафрейме нужно найти определённую строку. Сделать это можно двумя способами: по индексному значению и индексу. Попробуем оба метода.
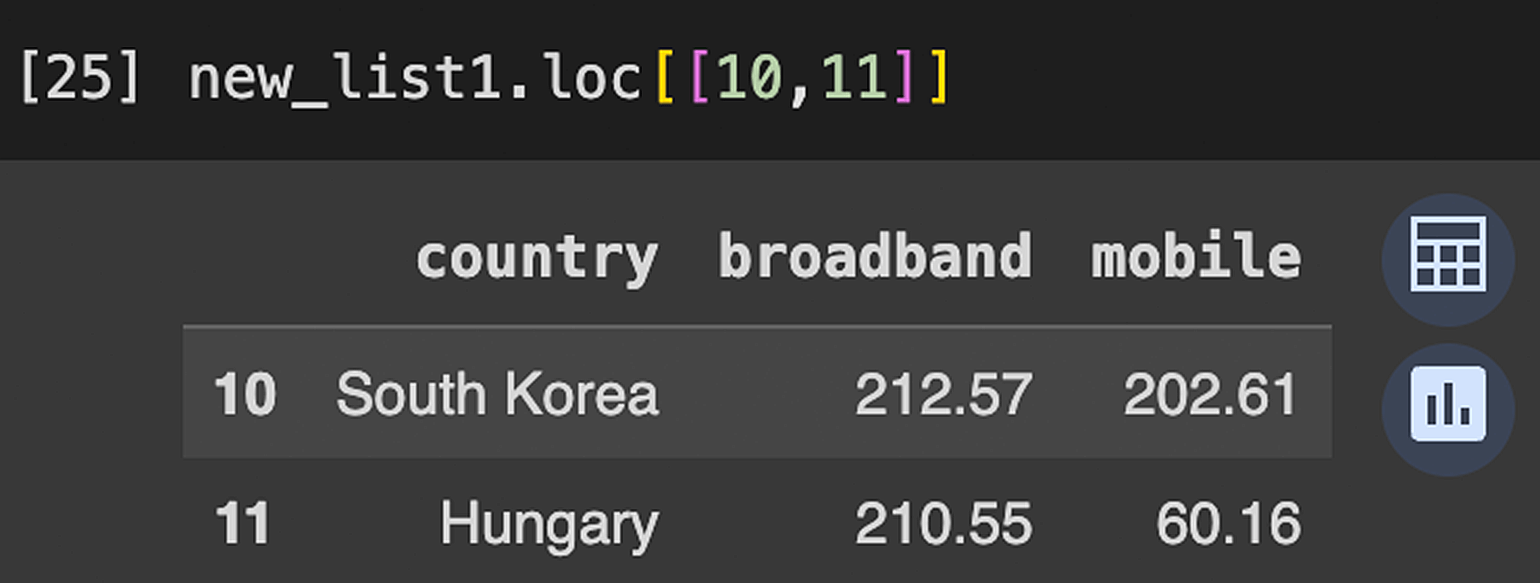
Фильтрация по индексному значению. Оно соответствует первому столбцу в датафрейме. В нашем случае индексные значения — это числа от 0 до 177.
Выведем на экран страны с индексными значениями 10 и 11:
new_list1.loc[[10,11]]Смотрим на результат:
Фильтрация по индексу. Он в датафрейме всегда начинается с 0. Сделаем срез стран с индексами 5–8. Для этого используется метод iloc.
new_list1.iloc[5:8]Смотрим на результат:
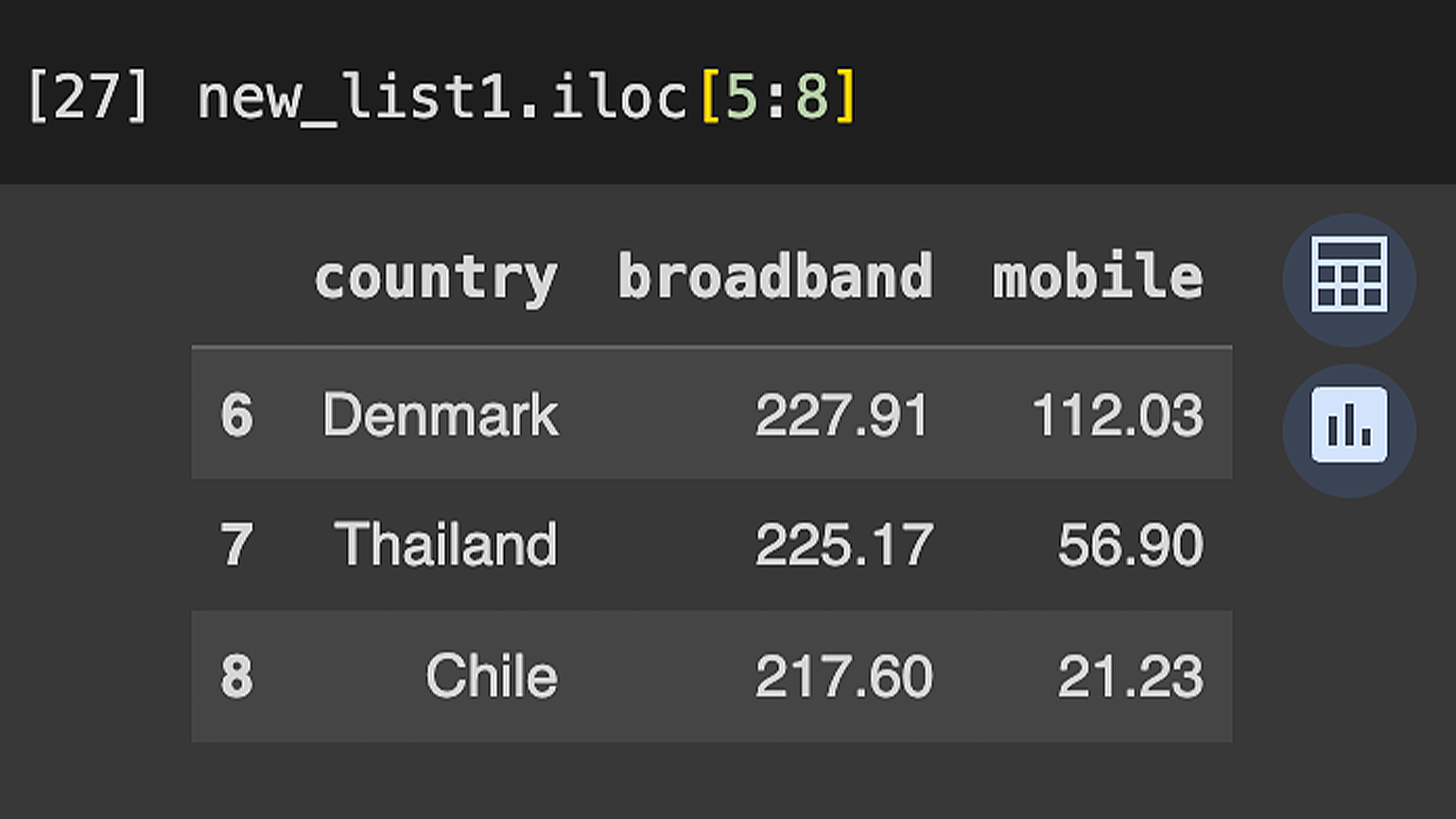
Получили срез списка с 6-го по 8-й объект. Обратите внимание, что индекс и индексные значения строк различаются.
Фильтрация датафрейма по значениям
Выведем на экран только те страны, где скорость мобильного интернета более 100 Мбит/с:
new_list1[new_list1['mobile'] > 100]В результате получили таблицу с 18 странами:
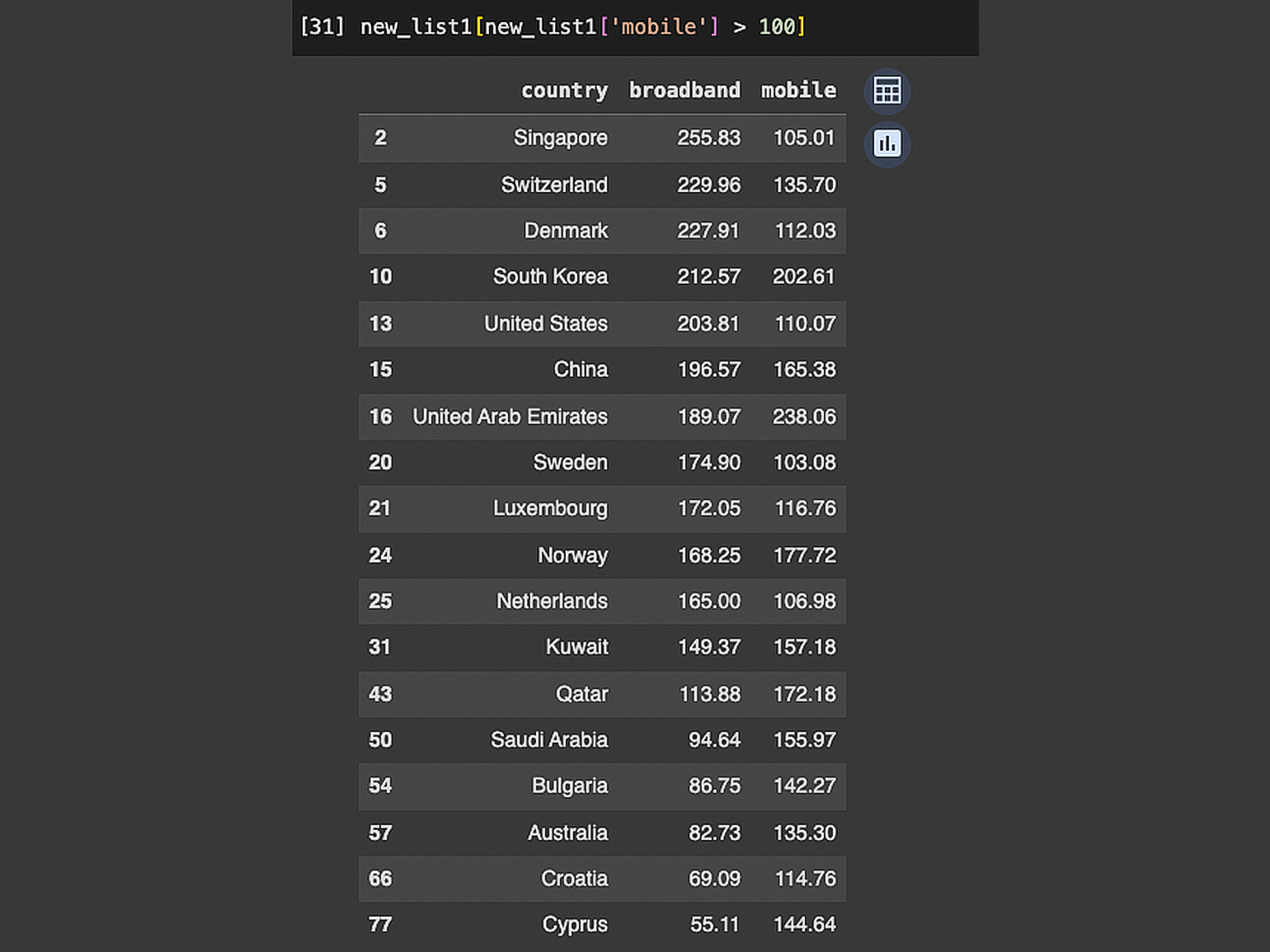
Важно!
При использовании этого метода сохраняются индексные значения анализируемого датафрейма.
Агрегирование данных
Агрегирование данных — это функция, которая принимает несколько отдельных значений и возвращает сводные данные.
Рассчитаем среднее значение скорости интернета для всех стран с помощью функции agg, передав туда поле mean:
new_list1['broadband'].agg(['mean'])Результат:
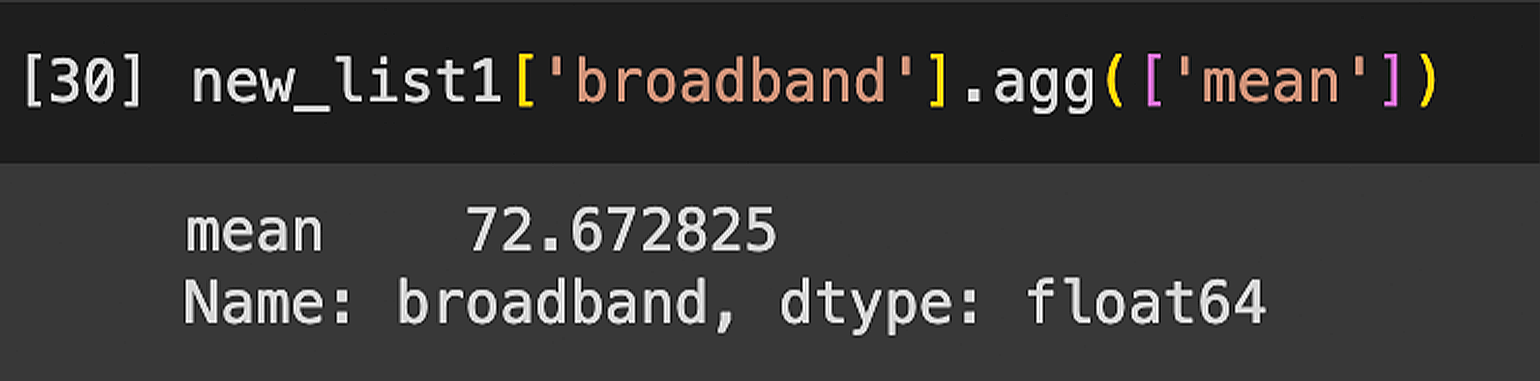
Среднее значение скорости интернета по всем странам — 72,67.
После завершения редактирования датафрейма его можно сохранить в CSV или другом формате:
new_list1.to_csv (r' C:\Users\Skillbox\Desktop\country.csv')Сохранённый файл появится по указанному пути.
Что дальше?
Pandas в Python — мощная библиотека для анализа данных. В этой статье мы прошли по базовым операциям. Подробнее про работу библиотеки можно узнать в документации. Углубиться в работу с библиотекой можно благодаря специализированным книгам:
- «Изучаем pandas» Майкла Хейдта и Артёма Груздева;
- «Thinking in Pandas: How to Use the Python Data Analysis Library the Right Way», Hannah Stepanek;
- «Hands-On Data Analysis with Pandas: Efficiently perform data collection, wrangling, analysis, and visualization using Python», Stefanie Molin.






