JOIN в SQL: что это такое и как её использовать
Объединяем и властвуем.


В реляционных базах данных информация обычно не хранится в одной таблице, а распределена между несколькими. Например, в одной могут быть пользователи, а в другой — их заказы. Чтобы работать с такими данными как с единой системой, используется операция SQL JOIN.
JOIN связывает строки из разных таблиц по заданному условию и формирует новую результирующую таблицу. Благодаря этому можно получить, например, список пользователей вместе с датами их заказов и суммами покупок. Без соединения таблиц такие данные пришлось бы извлекать и объединять несколькими запросами.
В статье разберём, что такое SQL JOIN, рассмотрим основные виды соединения таблиц и покажем, как применять этот инструмент на практике.
Содержание
Что такое SQL JOIN
SQL JOIN — это операция объединения таблиц по заданному условию. В результате запроса формируется новая виртуальная таблица, в которой строки из разных источников сопоставляются по связанным полям.
Чаще всего таким полем выступает ключ. Например, в таблице пользователей хранится user_id, а в таблице заказов — тот же user_id, указывающий, кто сделал покупку. JOIN сопоставляет эти значения и объединяет строки, относящиеся к одному и тому же пользователю.

С точки зрения логики работы JOIN перебирает строки двух таблиц и оставляет те комбинации, которые удовлетворяют условию соединения (ON). При этом результат зависит от типа соединения: иногда в итоговую таблицу попадают только совпадающие строки, а иногда — ещё и те, для которых пары не нашлось.
В SQL существует несколько видов JOIN: INNER, LEFT, RIGHT, FULL и другие. Они определяют, какие строки из исходных таблиц попадут в итоговый набор данных. Разбеём каждый вариант JOIN с примерами SQL-запросов.
Типы операции JOIN
Для объяснения теории будем использовать базу данных онлайн-кинотеатра. Она состоит из четырёх таблиц: movies, directors, reviews и showtimes.
Скачайте базу данных и откройте её в любом SQL-редакторе. Мы советуем использовать онлайн-сервис Sandbox SQL, который не требует регистрации и установки на компьютер.
Чтобы открыть БД в Sandbox SQL, нажмите New → Upload file и в открывшемся окне выберите скачанный файл.
Перед вами откроется основной интерфейс приложения, состоящий из трёх частей:
- Слева расположен список таблиц нашей БД. Вы должны увидеть там четыре строки: movies, directors, reviews и showtimes.
- Правая часть интерфейса разделена на ещё две части. Сверху располагается окно вывода результата запроса. Внизу — окно ввода SQL-запросов.
Работать с Sandbox SQL просто — вставляйте запросы из статьи в окно ввода и кликайте на кнопку Execute. В окне вывода получите таблицу — ответ на запрос.
INNER JOIN
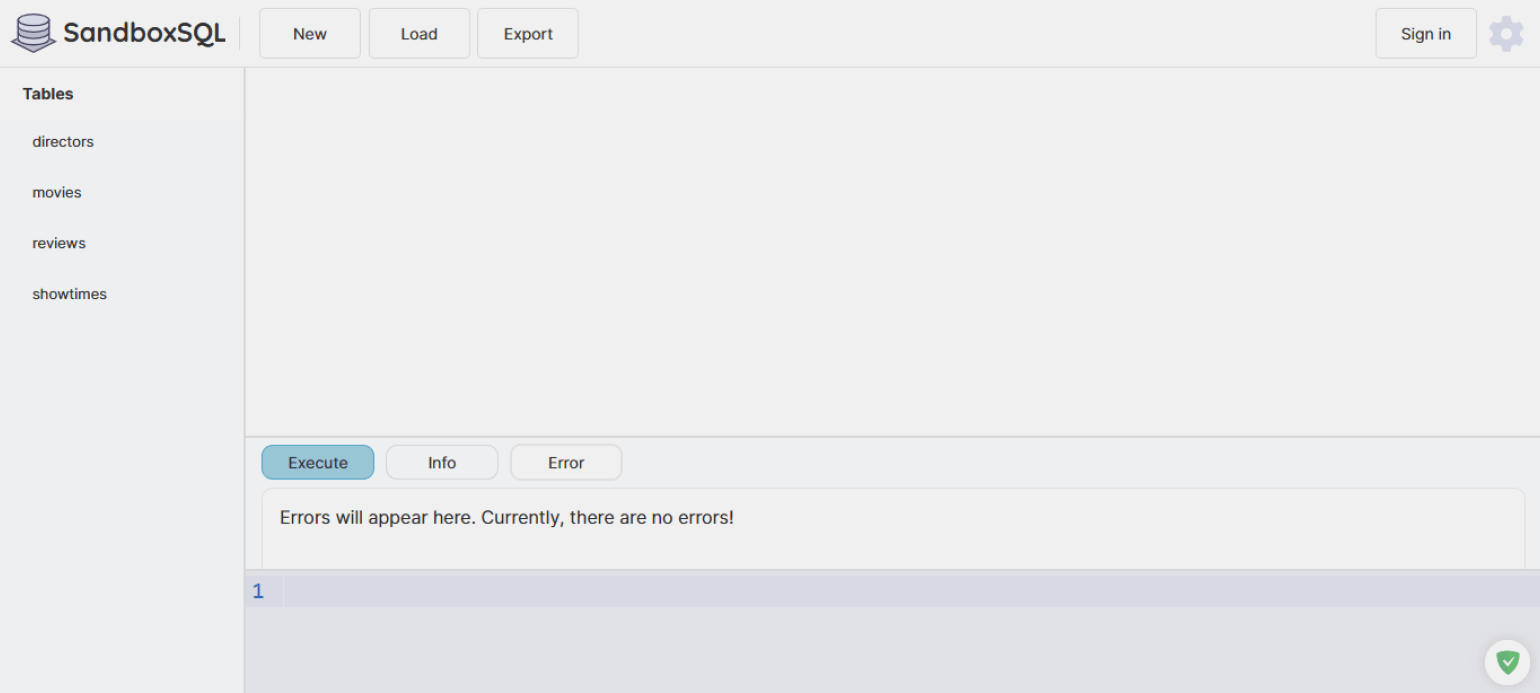
INNER JOIN при соединении таблиц выбирает только те строки, для которых найдено совпадение по заданному условию.
Попробуем получить список фильмов с именами режиссёров из базы данных кинотеатра. Для этого потребуется проанализировать две таблицы: movies и directors.
В результате запроса получится пересечение множеств фильмов и режиссёров. В выборку попадут только те строки, где связь между таблицами действительно существует.
Если в movies у фильма не указан режиссёр или указанный director_id отсутствует в таблице directors, такой фильм не попадёт в выборку. И наоборот: режиссёр из таблицы directors, для которого в movies нет фильмов, также не будет показан.
SQL-запрос:
SELECT
m.title,
d.name,
d.country
FROM movies m
INNER JOIN directors d ON m.director_id = d.director_id;В ответе получим четыре фильма.
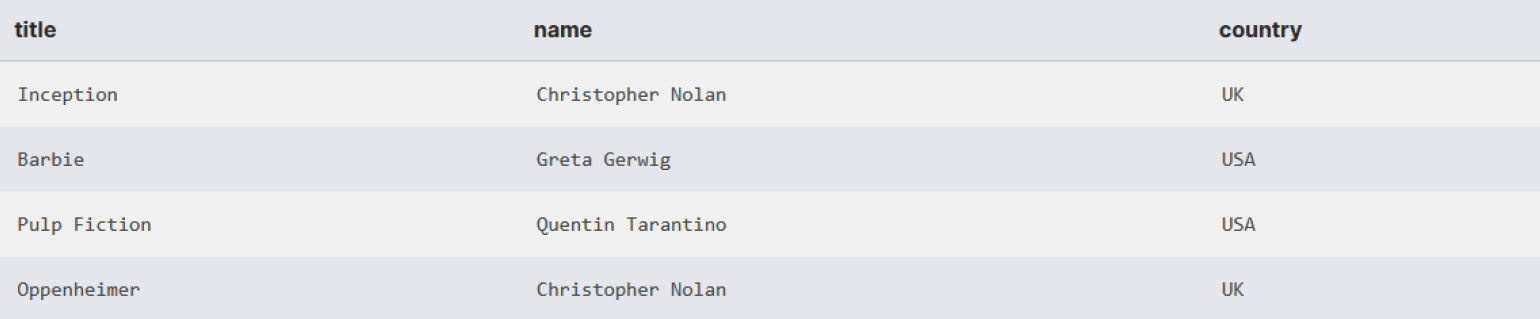
Визуально INNER JOIN работает как пересечение двух множеств на диаграмме Венна — в результат запроса попадают только те строки, которые имеют совпадение в обеих таблицах по условию соединения.
LEFT JOIN
LEFT JOIN и RIGHT JOIN позволяют сохранить данные из одной таблицы, даже если во второй нет совпадений.
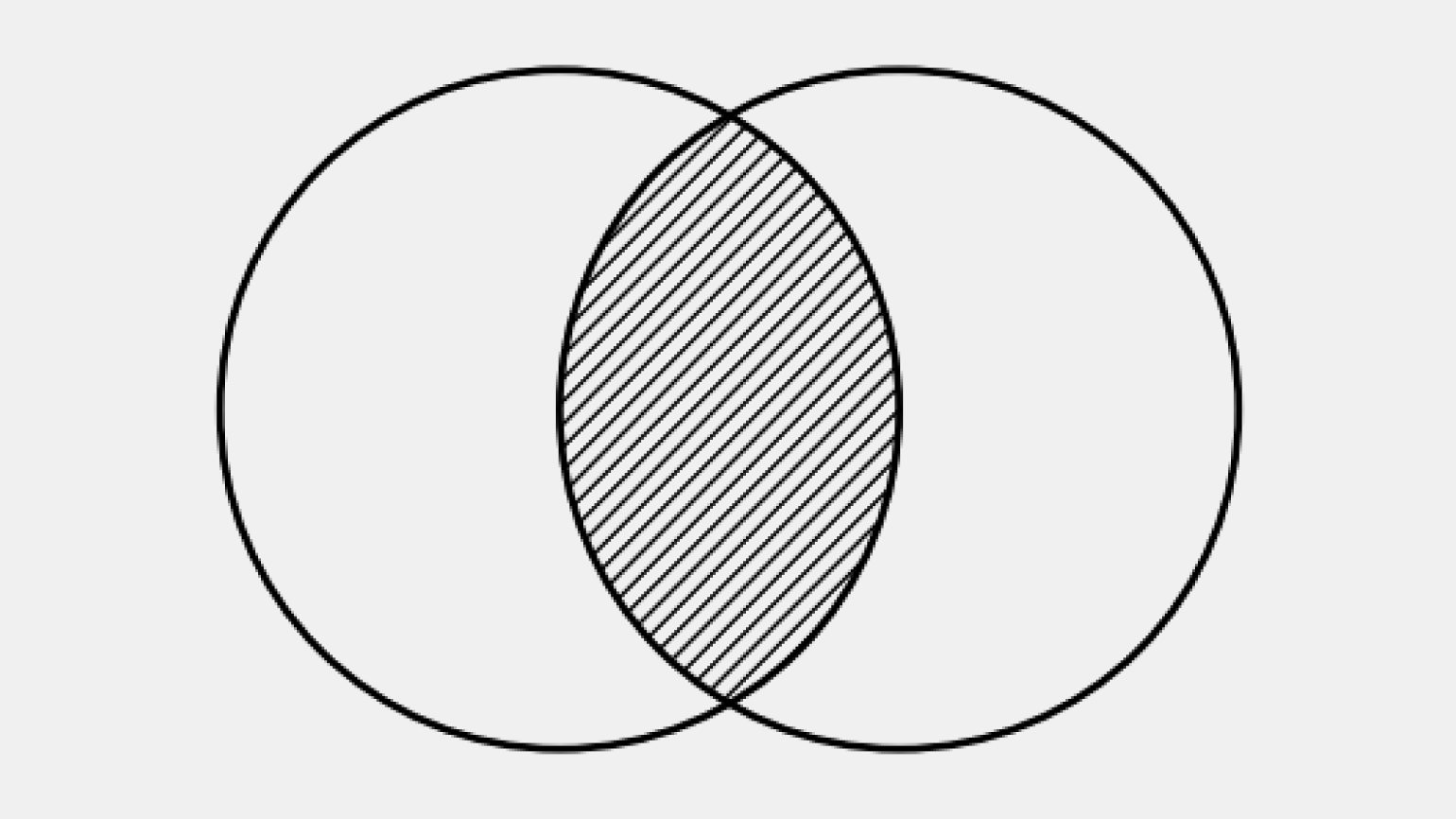
Попробуем на практической задаче: выведем список всех режиссёров и их фильмов. Важное условие: если у режиссёра в базе нет ни одного фильма, он всё равно должен попасть в итоговый список.
Логика запроса такая: мы берём все строки из таблицы directors и присоединяем к ним подходящие строки из movies. Если для конкретного режиссёра совпадений во второй таблице нет, поля из movies будут заполнены NULL.
SQL-запрос:
SELECT
m.title,
d.name
FROM directors d
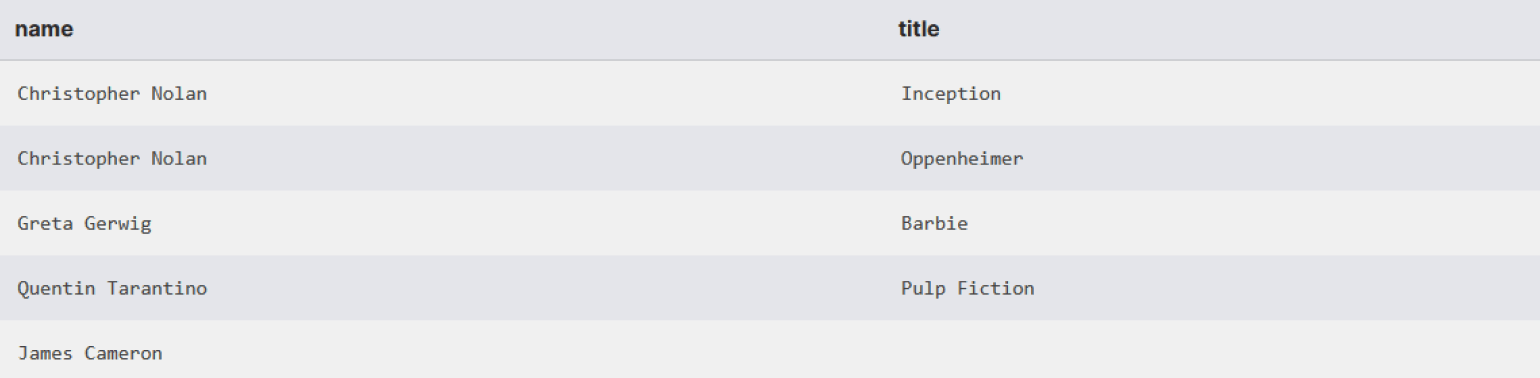
LEFT JOIN movies m ON m.director_id = d.director_id;Из-за того, что ни одного фильма Джеймса Кэмерона в базе данных нет, напротив его имени в колонке title будет пусто.
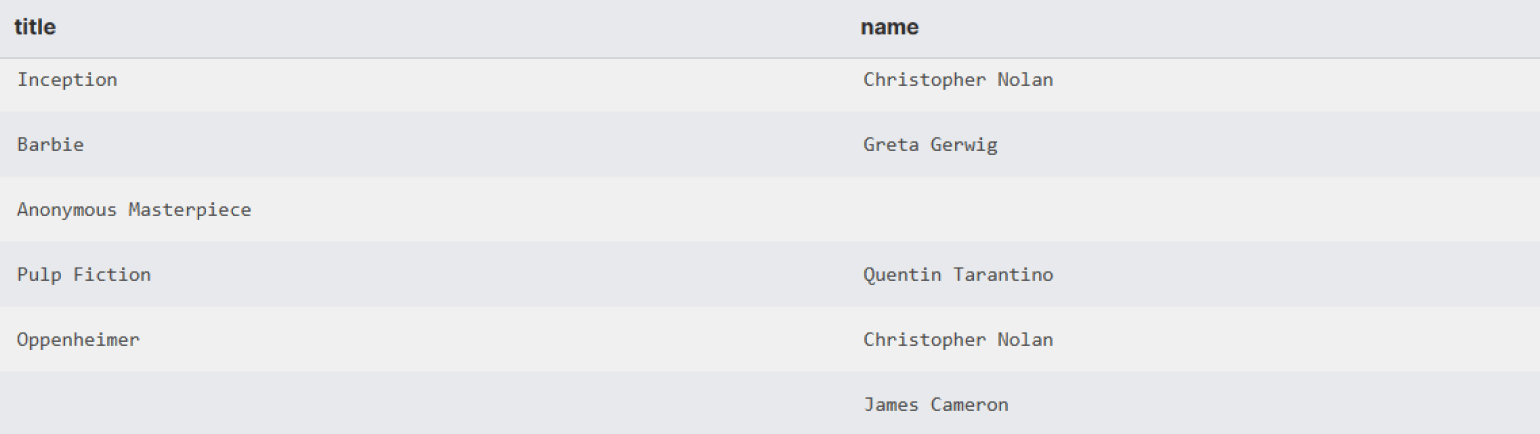
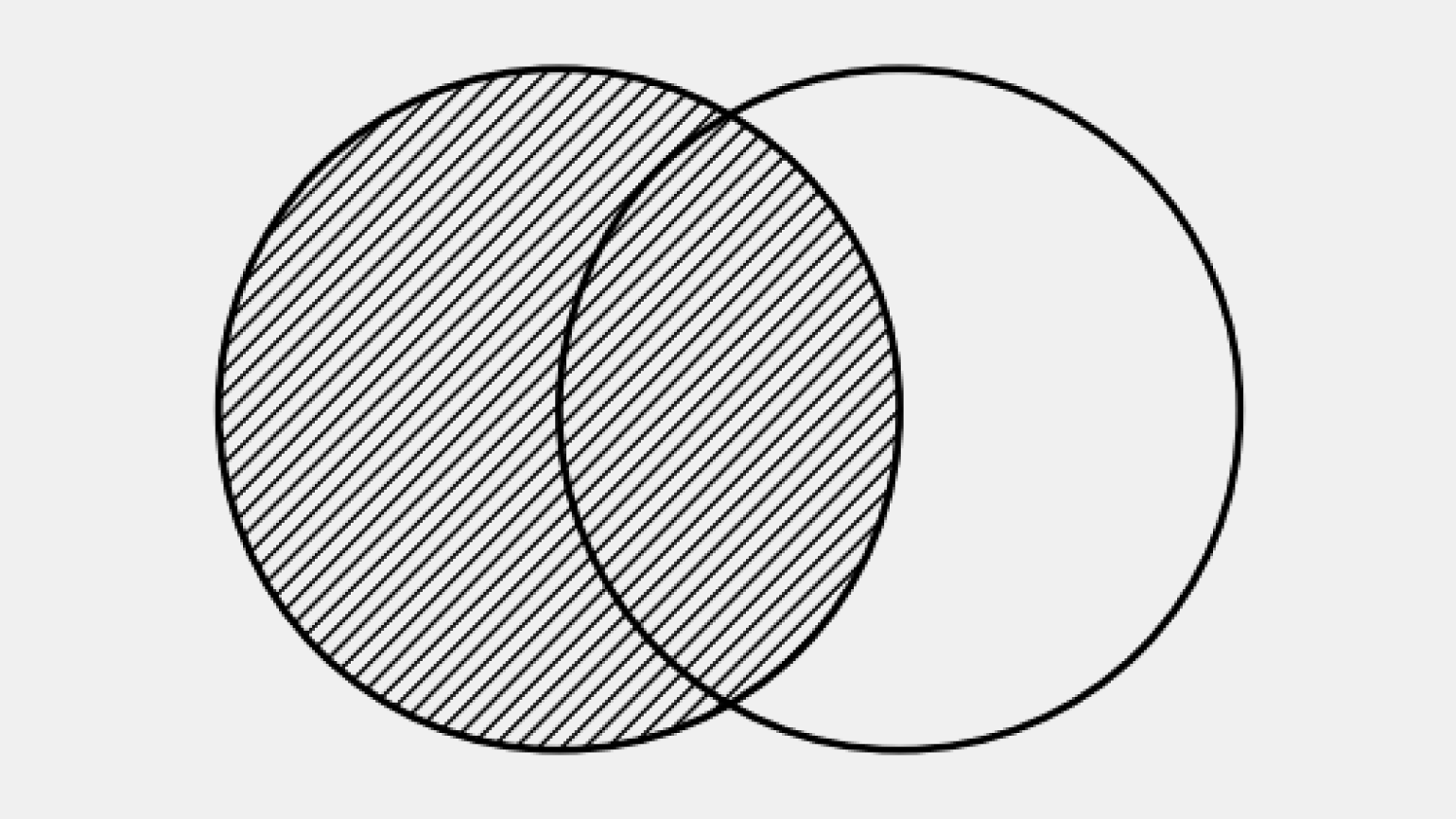
Визуально LEFT JOIN на диаграмме Венна — это вся левая таблица целиком, включая её пересечение с правой.
То есть результат содержит все строки из левой таблицы: — и те, которые совпадают с правой; — и те, для которых соответствий не найдено (в этом случае поля правой таблицы будут NULL).
RIGHT JOIN
RIGHT JOIN абсолютно зеркален LEFT JOIN. Он сохраняет все строки из правой таблицы.
Напишем SQL-запрос, чтобы решить задачу из раздела про LEFT JOIN — вывести всех режиссёров, даже если у них нет фильмов в базе данных:
SELECT
d.name,
m.title
FROM movies m
RIGHT JOIN directors d ON d.director_id = m.director_id;В результате получим тот же список, где у Джеймса Кэмерона нет фильмов, но столбцы меняются местами.
Использование RIGHT JOIN часто считают неудачным с точки зрения читаемости. Мы воспринимаем код слева направо, поэтому логика «взять таблицу A (левую) и присоединить к ней B (правую)» выглядит естественнее, чем обратная конструкция.
При этом RIGHT JOIN не даёт каких-либо преимуществ: его всегда можно переписать через LEFT JOIN, поменяв таблицы местами.
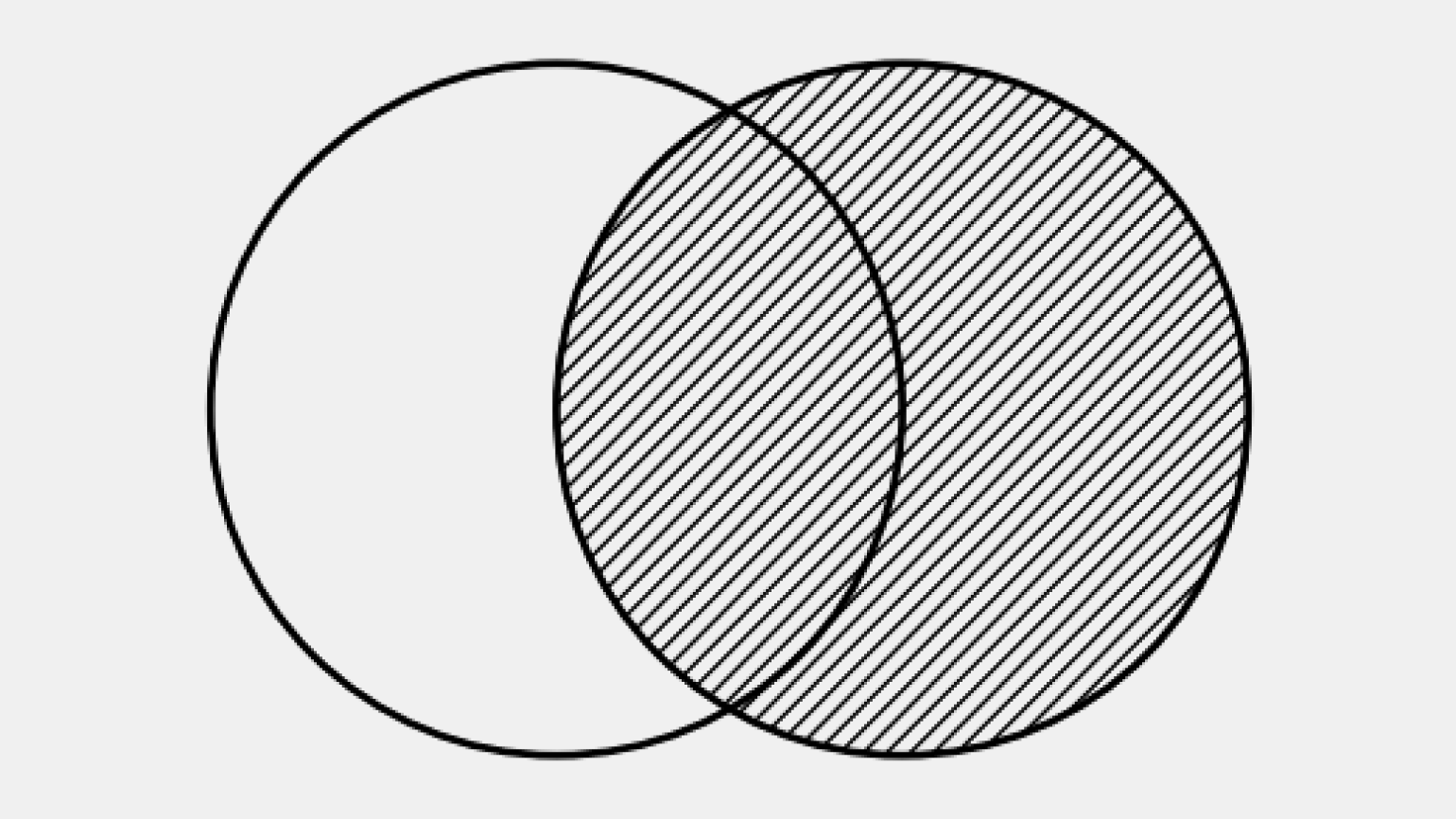
Визуально RIGHT JOIN на диаграмме Венна — это вся правая таблица целиком, включая её пересечение с левой.
Результат содержит все строки из правой таблицы:
- и те, которые совпадают с левой;
- и те, для которых соответствий не найдено (в этом случае поля левой таблицы будут NULL).
FULL JOIN
FULL JOIN возвращает все строки из обеих таблиц.
В результате будут:
- совпадающие записи;
- строки из левой таблицы без пары;
- строки из правой таблицы без пары.
Напишем SQL-запрос для вывода всех фильмов и режиссёров, даже если среди них нет совпадений:
SELECT
m.title,
d.name
FROM movies m
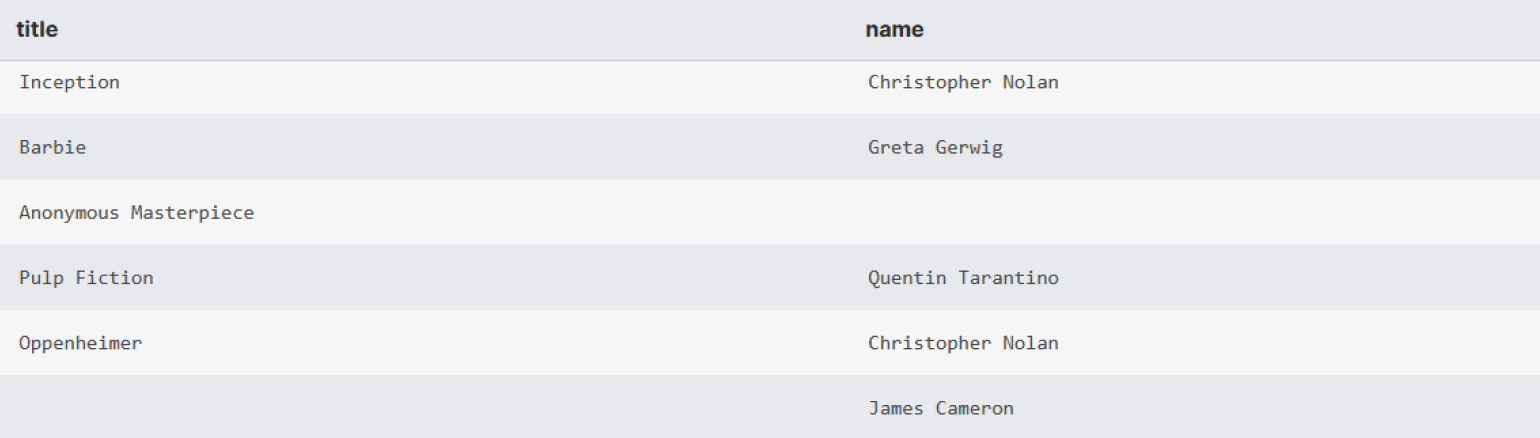
FULL JOIN directors d ON m.director_id = d.director_id;В результат попали:
- пары, где есть совпадение;
- фильмы без указания режиссёров;
- режиссёры без фильмов.
MySQL исторически не поддерживает оператор FULL JOIN. Чтобы реализовать эту логику, придётся использовать объединение UNION для двух запросов LEFT JOIN и RIGHT JOIN:
SELECT m.title, d.name
FROM movies m
LEFT JOIN directors d ON m.director_id = d.director_id
UNION
SELECT m.title, d.name
FROM movies m
RIGHT JOIN directors d ON m.director_id = d.director_id;Визуально FULL JOIN на диаграмме Венна — это оба круга целиком.
В результат попадает:
- пересечение таблиц (совпадающие строки);
- уникальная часть левой таблицы;
- уникальная часть правой таблицы.
То есть это объединение двух множеств без потерь элементов с любой стороны.
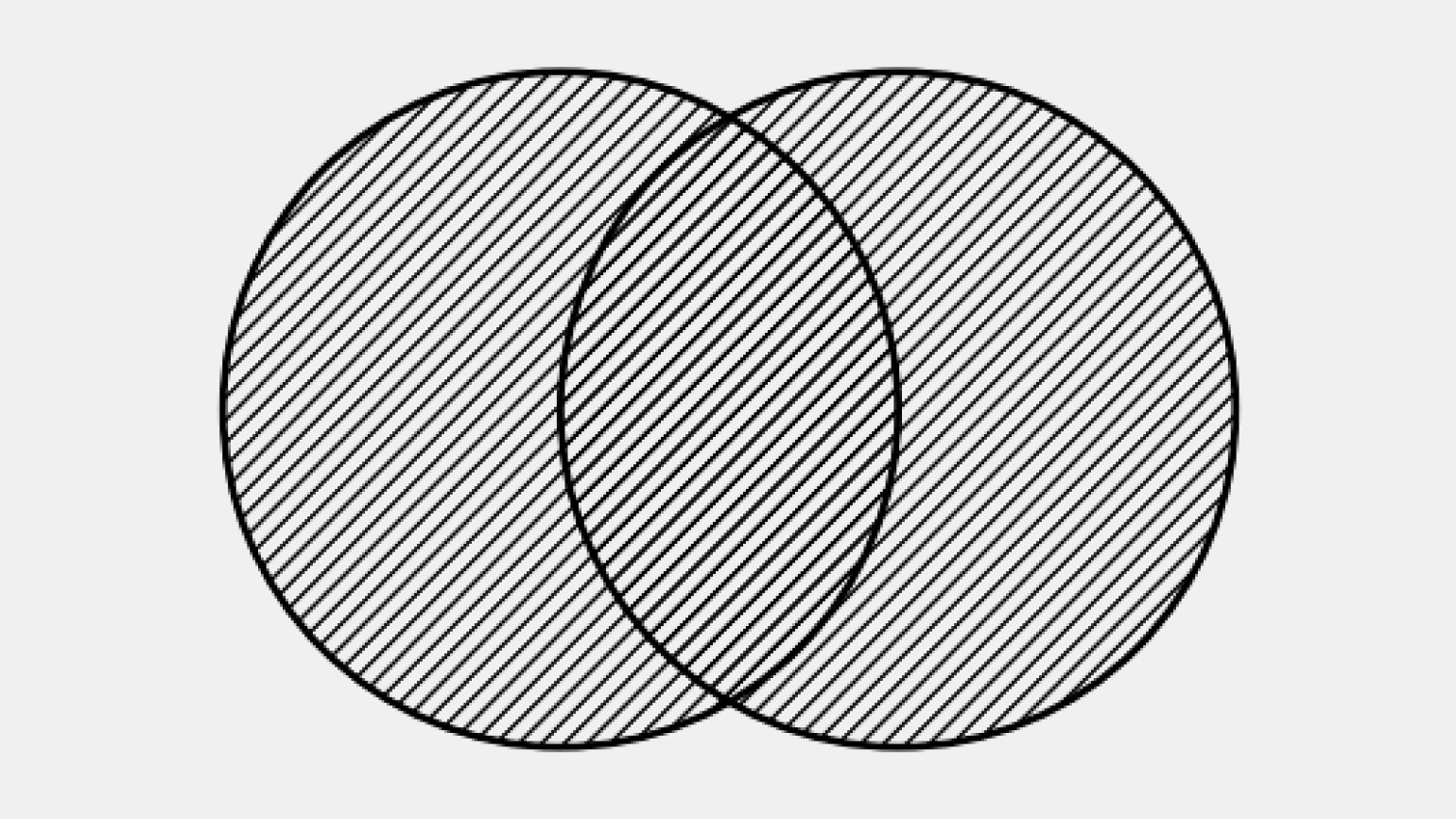
CROSS JOIN
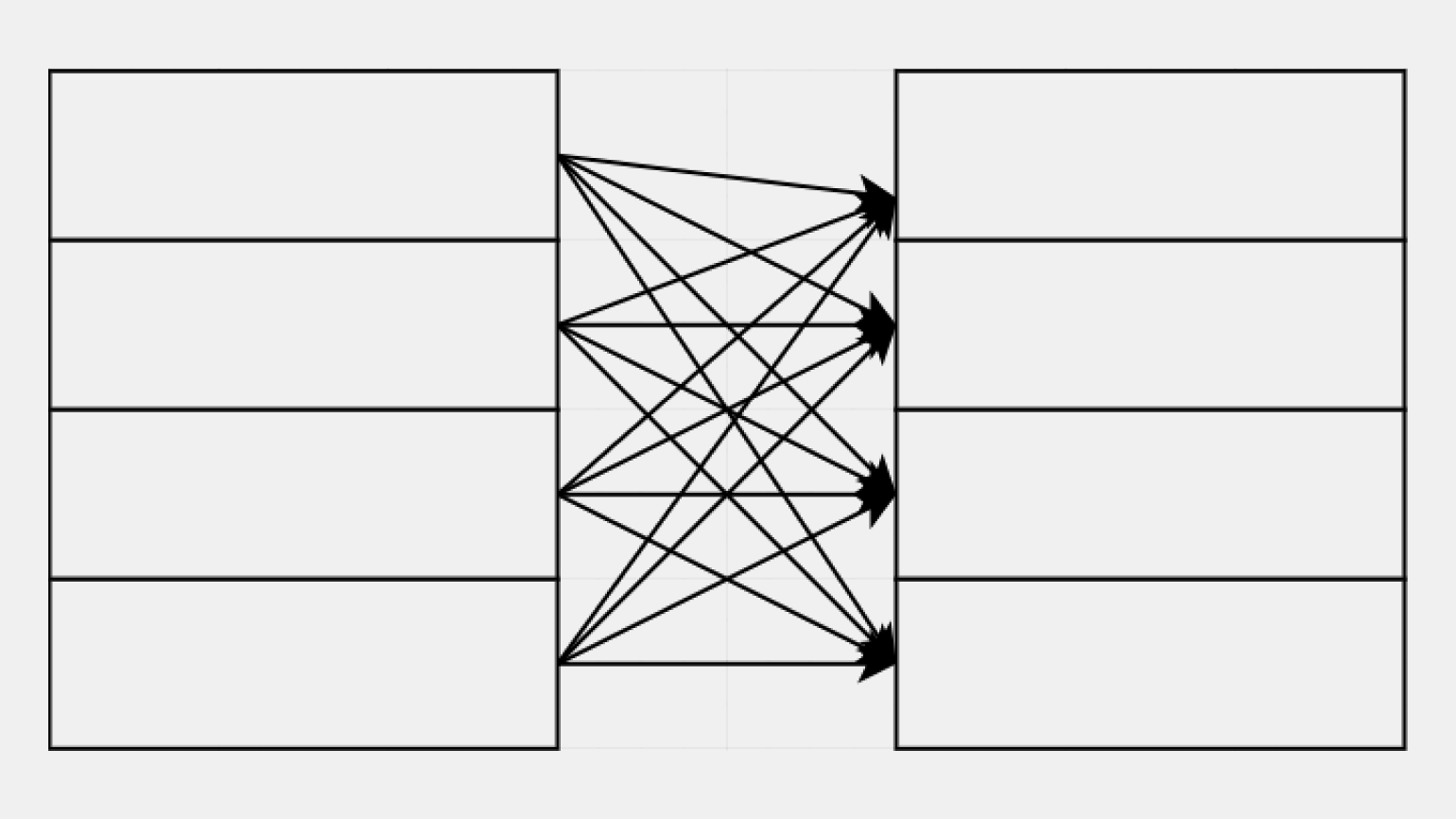
CROSS JOIN — тип соединения таблиц, не требующий условия ON. Каждая строка первой таблицы соединяется с каждой строкой второй. Мы говорили о таком варианте соединения в начале статьи — это декартово произведение.
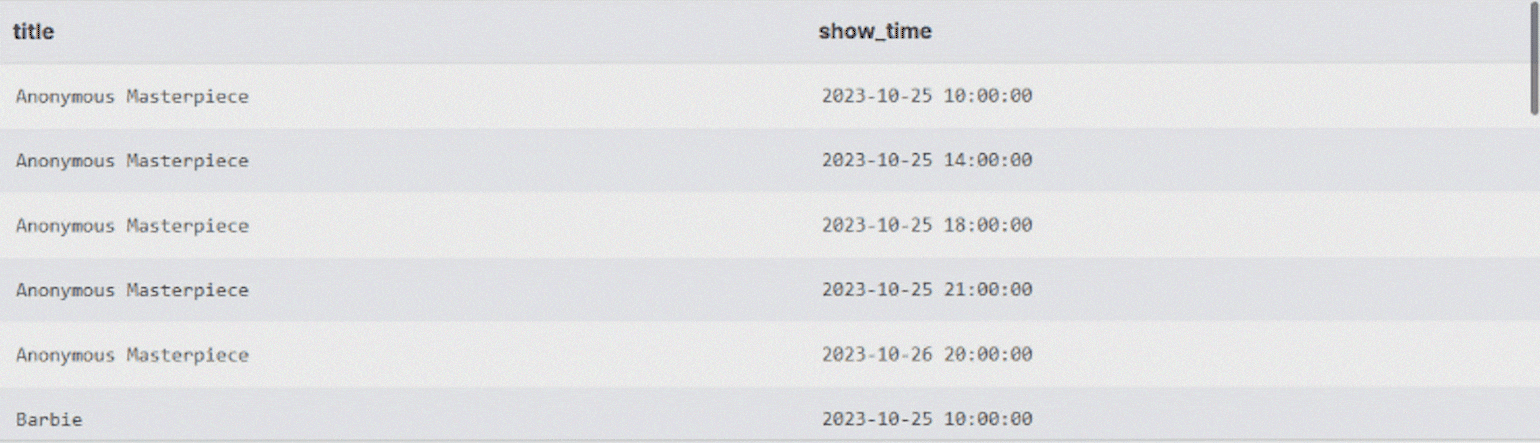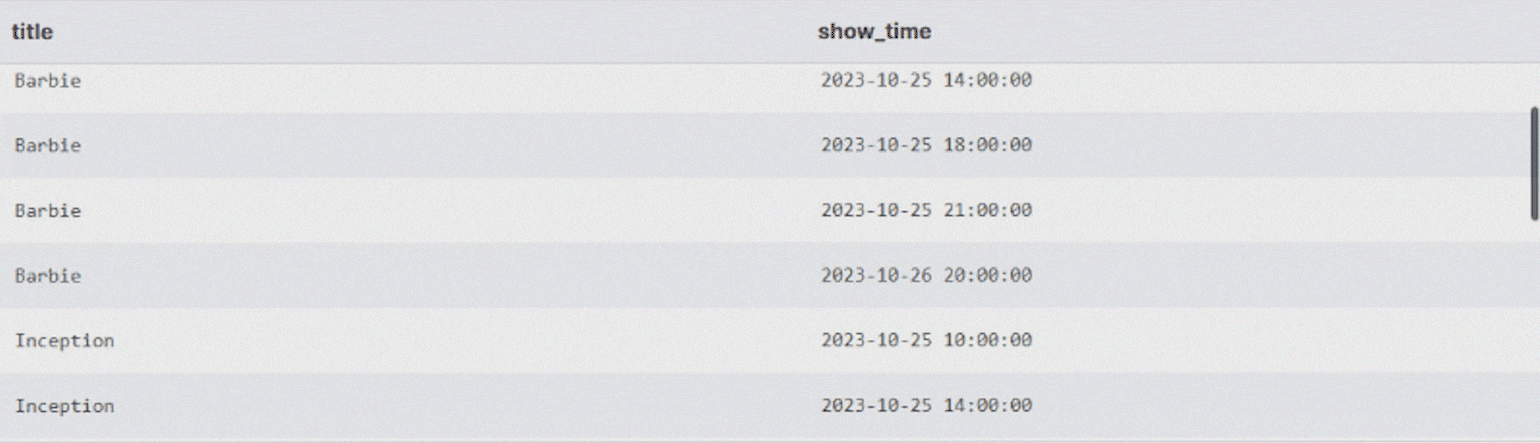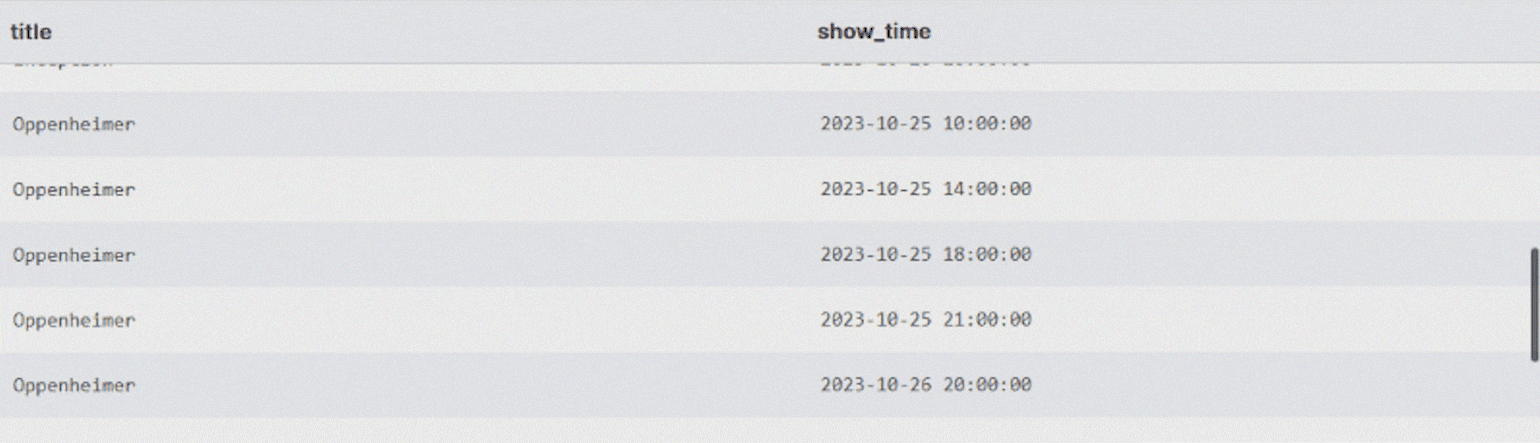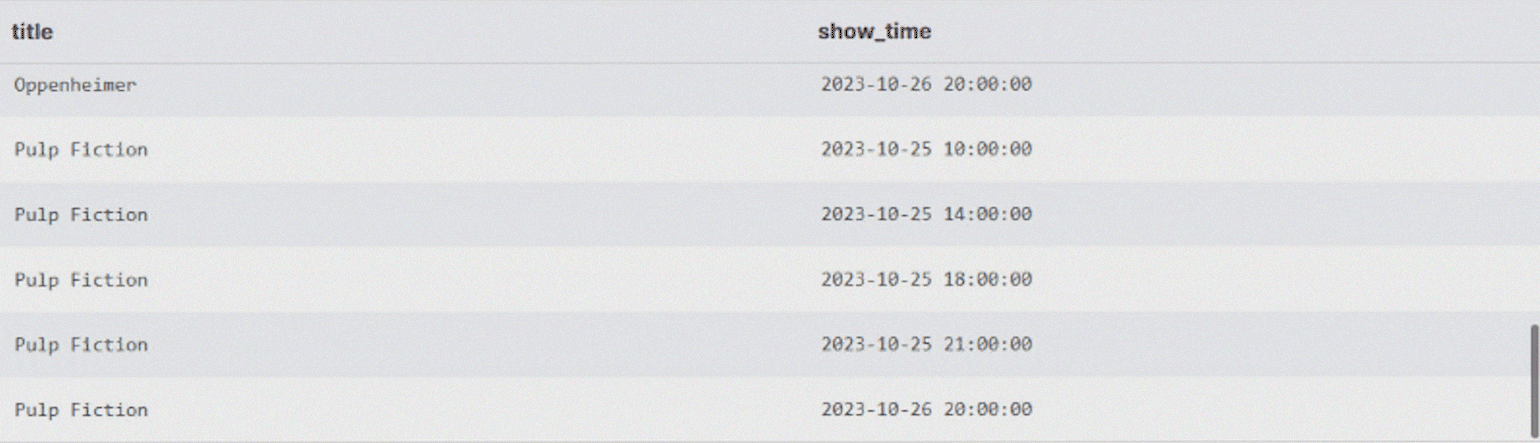
Напишем SQL-запрос, чтобы получить расписание киносеансов. Все данные для этого есть: список фильмов хранится в таблице movies, а время начала сеансов — в showtimes.
С помощью CROSS JOIN можно получить все возможные комбинации строк из этих таблиц — то есть таблицу вида «каждый фильм в каждое время».
SQL-запрос:
SELECT
m.title,
s.show_time
FROM movies m
CROSS JOIN showtimes s
ORDER BY m.title, s.show_time; -- Отсортируем, чтобы было удобнее читатьВ результате получим большую таблицу с расписанием киносеансов для каждого фильма.
Иногда можно встретить старый синтаксис соединения таблиц из стандарта SQL-89:
SELECT * FROM movies, directors;
Технически такая запись эквивалентна CROSS JOIN. Однако она ухудшает читаемость запроса и может вводить в заблуждение.
Дело в том, что эту конструкцию легко перепутать с обычным INNER JOIN, для которого забыли написать условие в WHERE. СУБД не станет проверять намерения аналитика и проведёт декартово произведение таблиц. Если таблицы большие, результат может содержать миллионы лишних строк и серьёзно нагрузить сервер.
Когда же CROSS JOIN указан явно, запрос читается однозначно: разработчик сознательно хочет получить декартово произведение таблиц.
В виде диаграмм Венна CROSS JOIN представить нельзя. Логика работы будет выглядеть, как соединение каждой строки первой таблицы с каждой строкой второй таблицы.
В некоторых источниках вместо LEFT JOIN, RIGHT JOIN и FULL JOIN встречается запись LEFT OUTER JOIN, RIGHT OUTER JOIN и FULL OUTER JOIN.
Это одно и то же: слово OUTER необязательно и не меняет смысл операции. Оно лишь подчёркивает, что в результат попадают не только совпадающие строки из обеих таблиц, но и строки без соответствия — с NULL на стороне, где пара не найдена.
ANTI-JOIN: продвинутый уровень
Иногда в таблицах требуется найти не совпавшие значения, а те, у которых нет пары. В теории множеств это называется вычитанием или симметрической разностью. В SQL задача решается просто — с помощью добавления условия WHERE… IS NULL.
FULL ANTI-JOIN
Представьте, что нам нужно найти в базе данных фильмы без режиссёров и режиссёров без фильмов. То есть все значения без пар в таблицах movies и directors.
Получится FULL JOIN, из которого вырезали середину с помощью добавления условия:
SELECT
m.title,
d.name
FROM movies m
FULL JOIN directors d ON m.director_id = d.director_id
WHERE m.movie_id IS NULL OR d.director_id IS NULL;В результате получим список, включающий фильм без режиссёра и режиссёра без фильмов.
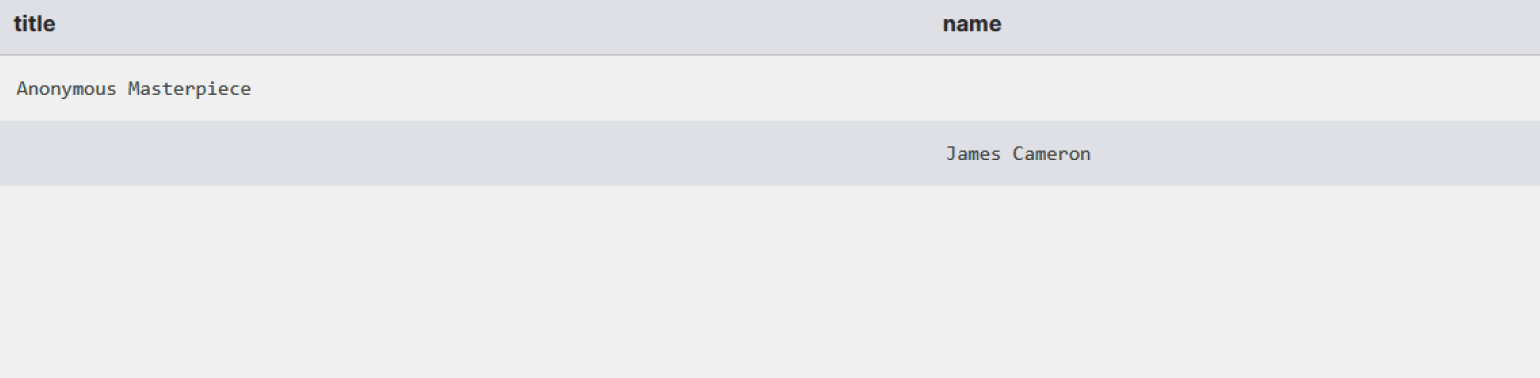
В MySQL такой код не сработает из-за ограничений СУБД на использование FULL JOIN. Поэтому используем UNION:
-- Берём фильмы без режиссёров
SELECT
m.title,
NULL AS name
FROM movies m
LEFT JOIN directors d ON m.director_id = d.director_id
WHERE d.director_id IS NULL
UNION ALL
-- Объединяем с режиссёрами без фильмов
SELECT
NULL AS title,
d.name
FROM directors d
LEFT JOIN movies m ON d.director_id = m.director_id
WHERE m.movie_id IS NULL;Визуально FULL ANTI-JOIN на диаграмме Венна — это обе не пересекающиеся части кругов.
В результат попадают:
- строки из левой таблицы без совпадений в правой;
- строки из правой таблицы без совпадений в левой.
Общая зона пересечения исключается.
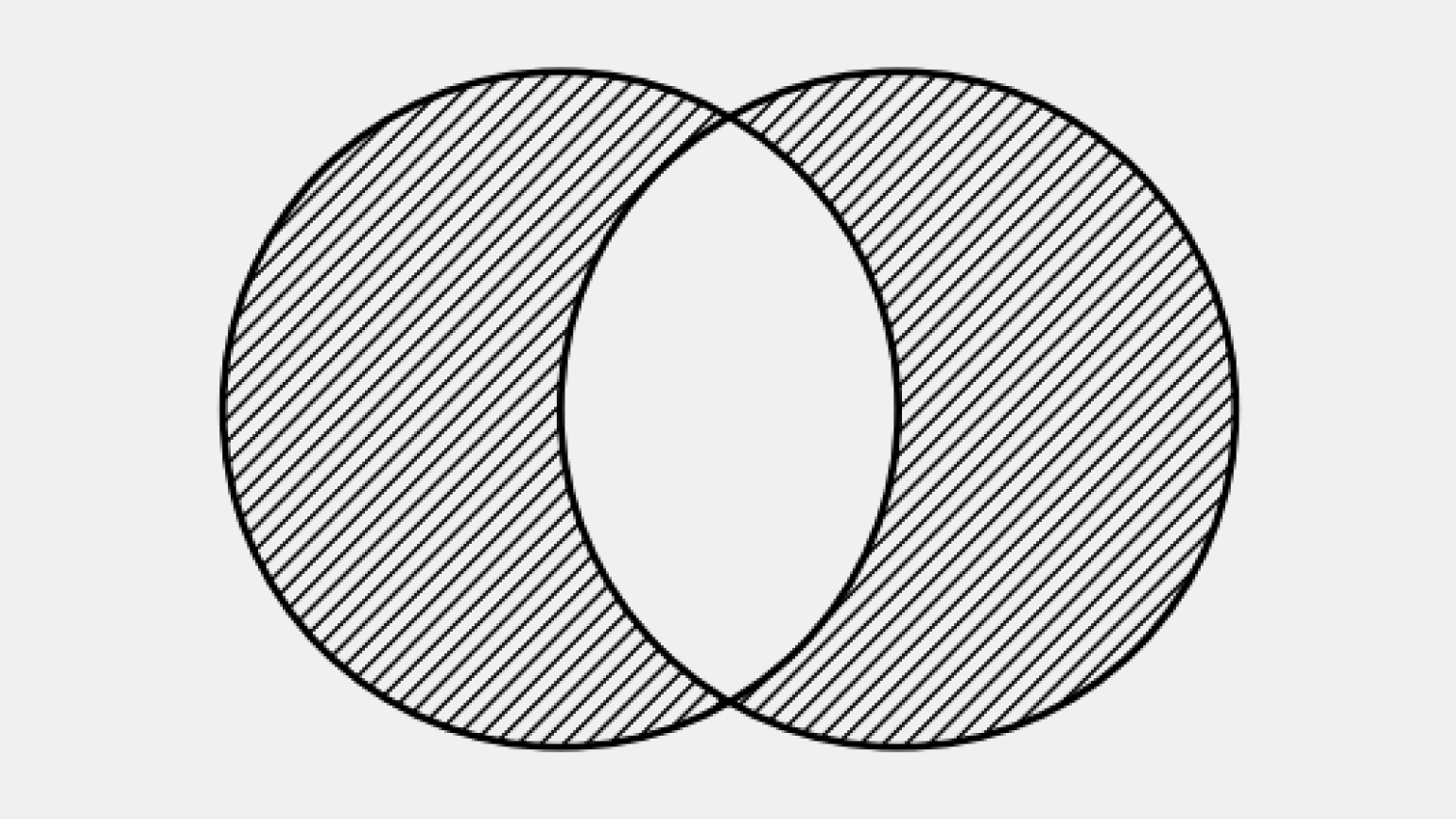
LEFT ANTI-JOIN
Чтобы найти фильмы, у которых нет режиссёра, мы берём все фильмы с помощью LEFT JOIN, а затем оставляем только те строки, где в колонке режиссёра NULL, то есть пусто.
SQL-запрос:
SELECT m.title
FROM movies m
LEFT JOIN directors d ON m.director_id = d.director_id
WHERE d.director_id IS NULL;В результате получим таблицу с одним фильмом — Anonymous Masterpiece.
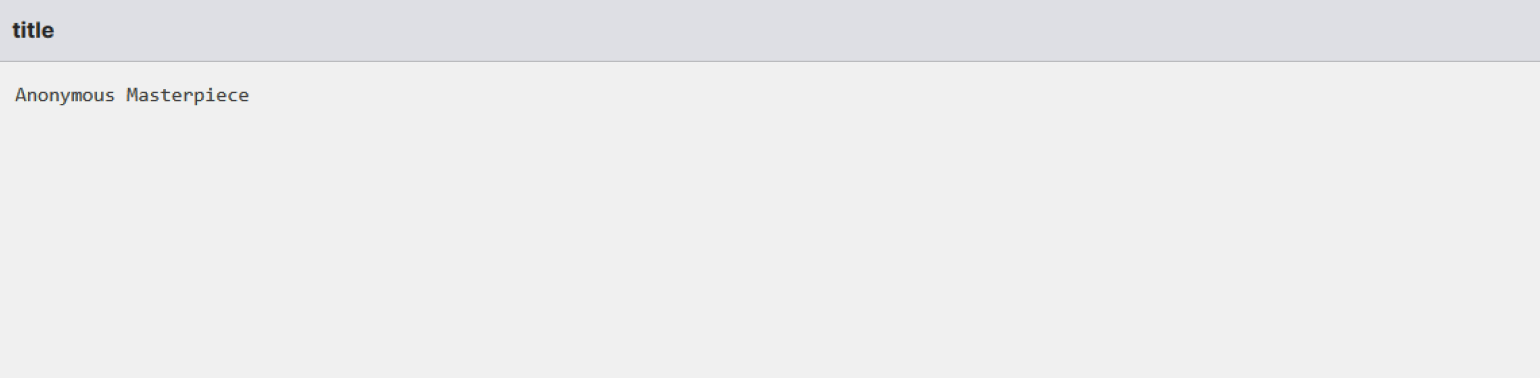
Визуально LEFT ANTI-JOIN на диаграмме Венна — это левая часть круга без зоны пересечения. В результат попадают только те строки из левой таблицы, для которых не найдено совпадений в правой.
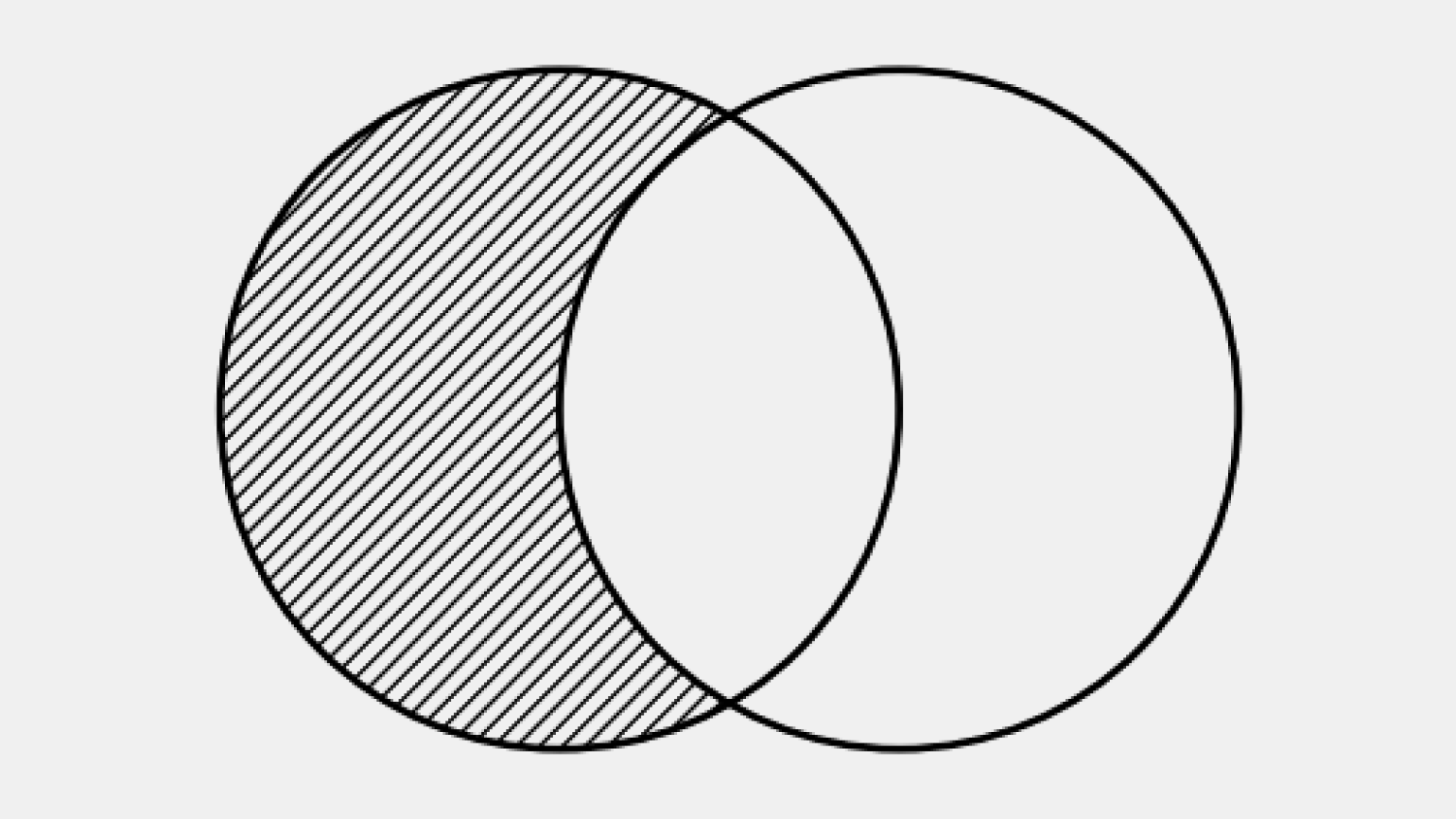
RIGHT ANTI-JOIN
Зеркальный предыдущему вариант симметрической разности.
Найдём режиссёров, которые не сняли ни одного фильма из нашего списка. SQL-запрос будет таким:
SELECT d.name
FROM movies m
RIGHT JOIN directors d ON d.director_id = m.director_id
WHERE m.movie_id IS NULL;В результате получим таблицу с Джеймсом Кэмероном.
Визуально RIGHT ANTI-JOIN на диаграмме Венна — это правая часть круга без зоны пересечения с левым кругом. В результат попадают только те строки из правой таблицы, для которых не найдено совпадений в левой.
Шпаргалка по использованию JOIN
Мы собрали компактную шпаргалку, которая поможет быстро вспомнить, какой результат возвращает каждый вариант JOIN и как он используется в SQL-запросах.
| Операция | Логика работы | Результат | SQL-паттерн |
|---|---|---|---|
| INNER JOIN | Пересечение двух таблиц | Только те строки, у которых есть пара в обеих таблицах | JOIN ... ON ... |
| LEFT JOIN | Приоритет левой таблицы | Все строки из левой таблицы и совпадения из правой (или NULL) | LEFT JOIN ... ON ... |
| RIGHT JOIN | Приоритет правой таблицы | Все строки из правой таблицы и совпадения из левой (или NULL) | RIGHT JOIN ... ON ... |
| FULL JOIN | Объединение таблиц | Полный список всего, что есть в обеих таблицах | FULL JOIN ... ON ... |
| LEFT ANTI-JOIN | Вычитание (A − B) | Только те строки левой таблицы, для которых не нашлось пары | LEFT JOIN ... WHERE b.id IS NULL |
| RIGHT ANTI-JOIN | Вычитание (B − A) | Только те строки правой таблицы, для которых не нашлось пары | RIGHT JOIN ... WHERE a.id IS NULL |
| FULL ANTI-JOIN | Исключение общего из таблиц | Всё уникальное из обеих таблиц (без пересечения) | FULL JOIN ... WHERE ... IS NULL |
| CROSS JOIN | Перемножение таблиц | Все возможные комбинации (каждое с каждым) | CROSS JOIN ... |
Частые ошибки
При работе с JOIN можно совершить несколько типичных ошибок, которые приводят к некорректным результатам. Разберём наиболее частых из них.
Неправильное использование фильтрации
Частая ошибка при работе с LEFT JOIN — фильтрация по столбцам правой таблицы в блоке WHERE.
Разработчик ожидает получить все строки из левой таблицы, включая те, для которых совпадений нет. Но условие в WHERE меняет поведение запроса: строки без совпадений отсекаются, и внешнее соединение фактически начинает работать как INNER JOIN.
Причина в порядке выполнения запроса. Сначала формируется результат LEFT JOIN, где для строк без совпадений в столбцах правой таблицы подставляются значения NULL. Затем применяется фильтрация WHERE. Если условие проверяет столбцы правой таблицы, сравнение с NULL возвращает значение UNKNOWN, а такие строки не проходят фильтр.
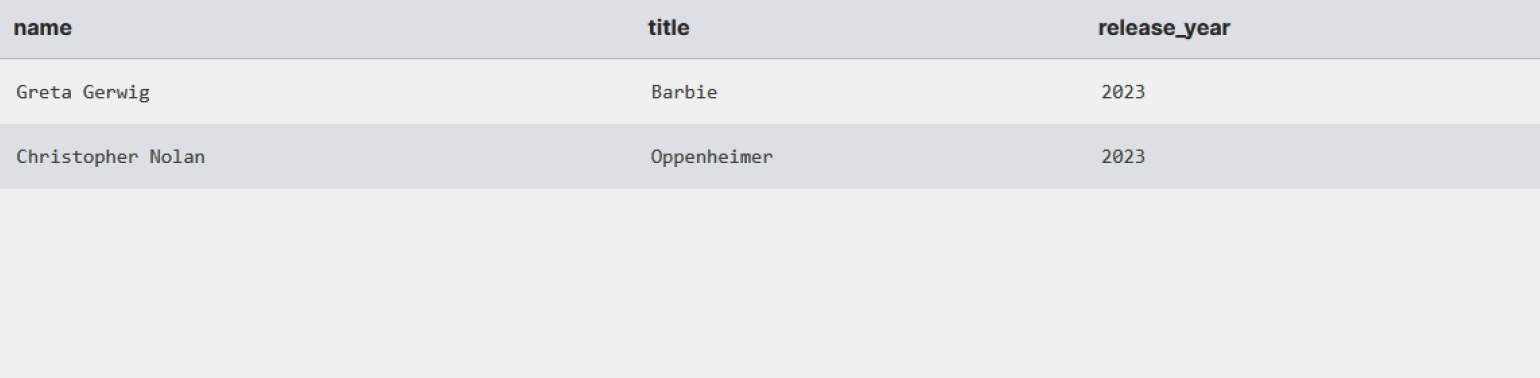
Напишем запрос для нашей базы данных, чтобы получить список режиссёров и их фильмы, вышедшие после 2020 года. При этом режиссёр должен остаться в выводе даже в том случае, если за этот период он не выпускал фильмов.
Если не задумываться про порядок выполнения запросов, то можно написать такой код:
SELECT d.name, m.title, m.release_year
FROM directors d
LEFT JOIN movies m ON d.director_id = m.director_id
WHERE m.release_year > 2020;
-- Ошибка: Режиссёры без фильмов или со старыми фильмами исчезнут,
-- так как NULL > 2020 вернёт FalseВ результате мы увидим только новые фильмы и их режиссёров, а режиссёры без фильмов или со старыми картинами не появятся в таблице.
То есть задача решена неправильно. Чтобы её выполнить, необходимо перенести условие в секцию ON:
SELECT d.name, m.title, m.release_year
FROM directors d
LEFT JOIN movies m ON d.director_id = m.director_id
AND m.release_year > 2020; -- Условие стало частью логики склейкиВ результате мы увидим всех режиссёров. Если они не выпускали новые фильмы в этот период, то напротив имени будет пусто.
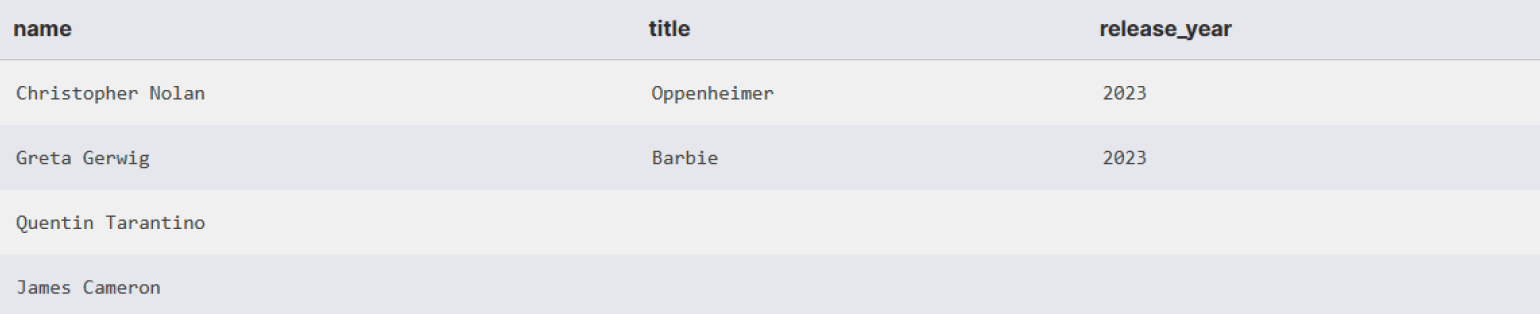
Поиск отсутствующих записей
Пытаясь найти режиссёров, которые не сняли ни одного фильма, джуниор-аналитик мог бы написать такой запрос:
SELECT * FROM directors WHERE director_id NOT IN (SELECT director_id FROM movies);На первый взгляд логика понятна: взять всех режиссёров, чьих director_id нет в таблице фильмов.
Но в таблице movies могут быть фильмы со значением NULL в director_id. Например, у фильма Anonymous Masterpiece режиссёр не указан.
Если подзапрос вернёт хотя бы одно значение NULL, логика сравнения меняется. В выражении NOT IN любое сравнение с NULL даёт результат UNKNOWN. В итоге всё условие перестаёт быть истинным для любой строки.
Поскольку оператор WHERE оставляет только строки, где условие равно TRUE, итоговый результат окажется пустым. Вместо ожидаемого списка режиссёров без фильмов запрос вернёт пустую выборку.
Для решения проблемы есть два решения: использовать конструкцию LEFT JOIN… WHERE id IS NULL или NOT EXISTS.
Первый вариант мы уже использовали раньше. Он подойдёт, если нам требуется вывести какие-то поля из «несуществующей» таблицы — они будут NULL:
SELECT d.name
FROM directors d
LEFT JOIN movies m ON d.director_id = m.director_id
WHERE m.movie_id IS NULL; -- Оставляем только те строки, где соединение не удалосьНаиболее правильный вариант — добавить условие NOT EXISTS. Его логику легче понять при чтении запросов.
Напишем SQL-запрос:
SELECT d.name
FROM directors d
WHERE NOT EXISTS (
SELECT 1
FROM movies m
WHERE m.director_id = d.director_id
);Оба варианта SQL-запроса выведут только Кэмерона. Это правильный результат.

Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!







