Как устроено машинное обучение: задачи, алгоритмы и виды machine learning
Об этом все говорят, но мало кто знает, что это такое.


Содержание:
- что такое машинное обучение;
- какие задачи оно решает;
- какие разновидности машинного обучения бывают;
- как оно устроено;
- какие алгоритмы можно использовать;
- где его применяют.
Что такое машинное обучение
Машинное обучение (machine learning, ML) — это совокупность методов искусственного интеллекта, с помощью которых можно создавать самообучающиеся компьютерные системы (в частности, нейросети). Для таких систем разработчики не прописывают конкретные алгоритмы решения задач, а предоставляют подготовленные данные и описывают критерии успешного решения, по которым учатся нейросети.
В традиционном программировании для решения некой задачи разработчику необходимо определить алгоритм и «объяснить» его компьютеру с помощью кода на языке программирования. У специалистов по машинному обучению другой подход: они пытаются научить машину «думать», подобно человеку, и самой находить решения.
ML применяется для создания беспилотных автомобилей и рекомендательных систем, в генерации изображений по текстовому описанию, распознавании речи и других областях науки. Вы наверняка слышали о ChatGPT, Bard или YaGPT, а может, и пользовались ими. Всё это — результат машинного обучения.

Читайте также:
Важно не путать термины «машинное обучение» и «искусственный интеллект». Искусственный интеллект ― это более общий термин. Можно сказать, что это способность компьютера обучаться, принимать решения и выполнять действия, свойственные человеческому интеллекту. Машинное обучение — это направление искусственного интеллекта, реализующее его с помощью алгоритмов.
Задачи машинного обучения
Глобальная задача машинного обучения ― создать искусственный интеллект, который по своим аналитическим способностям будет равен или даже превосходить человеческий. Это очень сложная задача, которую тем не менее наука вполне может решить в ближайшие 5–10 лет.
ИИ, который способен соперничать с человеком и решать задачи разного типа, называют сильным, или общим (artificial general intelligence).

Что касается более узких задач машинного обучения, то их можно разделить на четыре группы: классификация, регрессия, кластеризация и уменьшение размерности. Разберём каждую из них.
Классификация
Используется для решения тех задач, где на основании признаков объектов требуется распределить их по заданным категориям. Например, на производстве могут отделять детали с браком от хороших с помощью компьютерного зрения.
Регрессия
Регрессия в теории вероятностей и математической статистике ― это зависимость среднего значения какой-либо величины от некоторой другой величины или от нескольких величин. Компьютеры могут анализировать огромные массивы данных и делать предсказания на их основе. Например, можно загрузить в компьютер данные о движении курса акций за последние 10 лет и попросить предсказать их цену в текущем году.
Кластеризация
Кластеризация ― это распределение объектов по категориям, когда неизвестно, сколько категорий получится в итоге. Распределение происходит по заданному критерию. Например, компания может использовать кластеризацию для определения типов клиентов по паттернам их покупок и делать на основании этого персонализированные предложения товаров.
Уменьшение размерности
Уменьшение размерности помогает сократить количество признаков в данных без потери информации. Это упрощает их обработку и ускоряет алгоритмы машинного обучения, так как количество данных, с которыми им предстоит работать, уменьшается.
При распознавании изображений снижение размерности позволяет не анализировать каждый пиксель, а использовать только важные признаки. Например, чтобы распознать зебру среди животных, главное — научиться видеть белые и чёрные полосы.
Вы читаете эту статью, потому что задумываетесь о карьере специалиста по машинному обучению? Присмотритесь к курсу Skillbox — он подойдёт вам, если вы хотите стартовать в этой сфере.
Типы машинного обучения
Чтобы обучить искусственный интеллект, можно использовать разные методы. Они отличаются друг от друга степенью вовлечённости человека в процесс.
Обучение с учителем (supervised learning)
Компьютер может учиться под присмотром учителя, то есть дата-сайентиста или аналитика данных, который предоставляет ему размеченные данные.
Специалист показывает программе разные примеры и объясняет: вот кот, а вот собака. После обучения предлагает ей по тому же принципу проанализировать незнакомые данные. Если модель ошибается, то учитель исправляет её. Так программа учится, пока не достигнет нужной точности ответов.
Этот тип обучения подходит для решения задач классификации и регрессии. Примеры алгоритмов: наивный Байес, метод опорных векторов, дерево решений, k-ближайшие соседи, логистическая регрессия и линейная и полиномиальная регрессия.
Используется для фильтрации спама, компьютерного зрения, поиска и классификации документов.
Обучение без учителя (unsupervised learning)
Здесь программа не получает от специалиста никаких подсказок. Есть большой массив данных, и модели машинного обучения нужно самой найти закономерности.
Часто обучение без учителя используется для глубокого анализа больших данных, когда информации так много, что классифицировать всё вручную для обучения алгоритмов невозможно. Также этот тип обучения применяется в тех случаях, когда дата-сайентист не знает, что он может найти, но предполагает, что какие-то паттерны в данных присутствуют.
С помощью обучения без учителя тренируют алгоритмы по кластеризации данных и выявлению аномалий. Примеры алгоритмов: метод k-средних, DBSCAN, сингулярное разложение (SVD), анализ главных компонент (PCA) и латентное размещение Дирихле (LDA).
Метод используется для сегментации данных, обнаружения аномалий, составления рекомендаций, управления рисками и обнаружения фейковых изображений.
Обучение с частичным участием учителя (semi-supervised learning)
Как понятно из названия, этот метод обучения что-то среднее между полностью самостоятельным обучением и обучением с учителем. Например, специалист может разметить только небольшую часть данных, чтобы повысить точность предсказаний модели на старте её обучения.
Такой способ используется в тех сферах, где требуется работать с большим количеством однотипных по форме, но разнообразных по содержанию данных. Например, при распознавании изображений и речи.
Обучение с подкреплением (reinforcement learning)
Некоторым навыкам можно обучиться только на практике: ходить, танцевать, плавать или водить машину. Людям не нужен постоянный контроль, чтобы эффективно учиться. Получая в ответ на свои действия положительные либо отрицательные сигналы, мы учимся очень эффективно. Например, ребёнок учится избегать острых углов стола, если хотя бы раз о них ударился.
Компьютер тоже способен учиться в динамичной среде: игровом или реальном мире. Например, с помощью обучения с подкреплением обучают беспилотные автомобили. Описать абсолютно все ситуации на дороге в виде правил нереально. Нельзя предсказать, в какой момент на дорогу выбежит ребёнок или как ориентироваться на дороге в густом тумане. Поэтому беспилотные автомобили учатся водить при помощи симуляции реальной среды.
Примеры алгоритмов: Q-обучение, генетический алгоритм, SARSA, DQN и DDPG. Используется для обучения беспилотных автомобилей и роботов.
Глубинное обучение (deep learning)
Глубинное обучение — это класс алгоритмов машинного обучения, созданный по аналогии со структурой человеческого мозга. Они работают благодаря многослойным нейронным сетям.

Читайте также:
Как устроено машинное обучение
Для того чтобы обучить машину, нужны три компонента:
Наборы данных, или датасеты. ML-системы обучаются на специальных коллекциях образцов, называемых наборами данных, или датасетами. Они могут включать числа, изображения, тексты или любые другие типы данных в зависимости от задачи. Хороший датасет — это один из факторов успешного обучения модели, поэтому его сбору и предварительной подготовке уделяется много времени.
Функции. Функции показывают машине, на что следует обратить внимание. Допустим, вы хотите спрогнозировать цену квартиры. Можно попытаться предсказать стоимость с помощью линейной регрессии и, например, оценить, сколько может стоить это место исходя из площади. Но гораздо проще найти корреляцию между ценой и районом, где расположено здание. Поэтому важно подбирать правильные функции, учитывающие наиболее подходящие параметры.
Алгоритм. В математическом смысле алгоритм ― это совокупность функций. Он берёт данные на входе и выдаёт результат на выходе. Одну и ту же задачу можно решить, используя разные алгоритмы.
В зависимости от их выбора точность или скорость получения результатов может быть разной. Иногда для достижения большей производительности нужно комбинировать разные алгоритмы. Такие конструкции называются ансамблями (ensemble learning).
Если качество набора данных было высоким, целевые параметры выбраны правильно и использованы подходящие алгоритмы, то машинное обучение может справляться со специализированными задачами даже лучше, чем люди. Например, такие модели используются в диагностике опухолей и они дают на 20% больше верных диагностических ответов в сравнении с врачами-людьми.
Алгоритмы моделей машинного обучения
Кратко поговорим о популярных алгоритмах машинного обучения: наивном Байесе, логистической регрессии, деревьях решений и методе опорных векторов.
Наивный Байес
Байесовские алгоритмы — это семейство вероятностных классификаторов, основанных на применении теоремы Байеса. С её помощью можно предсказать, как возникновение одного события влияет на вероятность другого события.
Наивный классификатор Байеса был одним из первых алгоритмов, использованных для машинного обучения. Например, алгоритм использовали для фильтрации спама до 2010 года. Механизм фильтрации с применением классификатора Байеса очень простой ― инженеры посчитали, какие слова чаще всего встречаются в подобных письмах: «срочно», «скидка», «бесплатно» и другие. А потом научили алгоритм автоматически сортировать письма, где такие слова встречаются часто, в отдельную папку.
Но потом изобрели байесовское отравление. Спамеры научились прятать свои сообщения в большом количестве безобидного текста, например отрывков литературных произведений. Это помогало им обмануть фильтр. Поэтому появились другие способы фильтрации писем, более точные, например с помощью нейронных сетей.
Логистическая регрессия
Регрессия разбивает все данные на две группы — верные и неверные показатели. Она получила своё название благодаря тому, что использует логистическую функцию для прогнозирования вероятности принадлежности объекта к одному из классов.
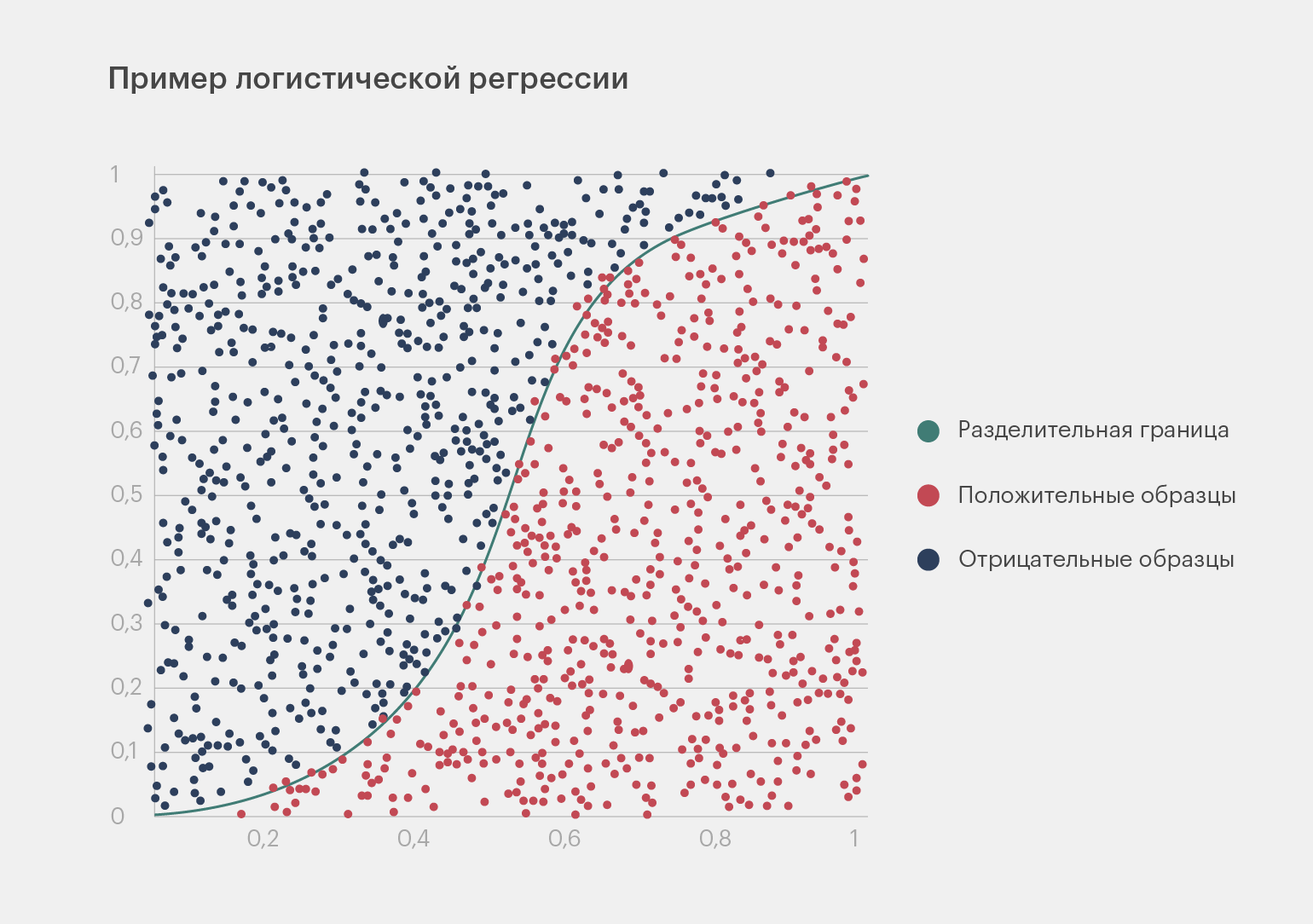
Инфографика: Майя Мальгина для Skillbox Media
С помощью алгоритма можно предсказать зависимость между двумя переменными. Регрессия даёт ответ, насколько вероятно, что произойдёт то или иное событие. По своему смыслу это простая статистическая модель, которая со временем перекочевала в машинное обучение.
Например, с помощью логистической регрессии можно рассчитать, с какой вероятностью лишний вес и отсутствие физической активности спровоцируют у пациента сердечный приступ.
Деревья решений
Дерево решений — это алгоритм машинного обучения, который используют для классификации, регрессии и выявления аномалий. Деревья решений часто применяют для анализа больших данных. Предсказания модели довольно точные и их легко визуализировать.
Чтобы дать предсказание, алгоритм полагается на систему правил «Если… то…». У правил есть иерархия. Например, если продавец решает, давать клиенту скидку или нет, то он может использовать такое дерево решений:
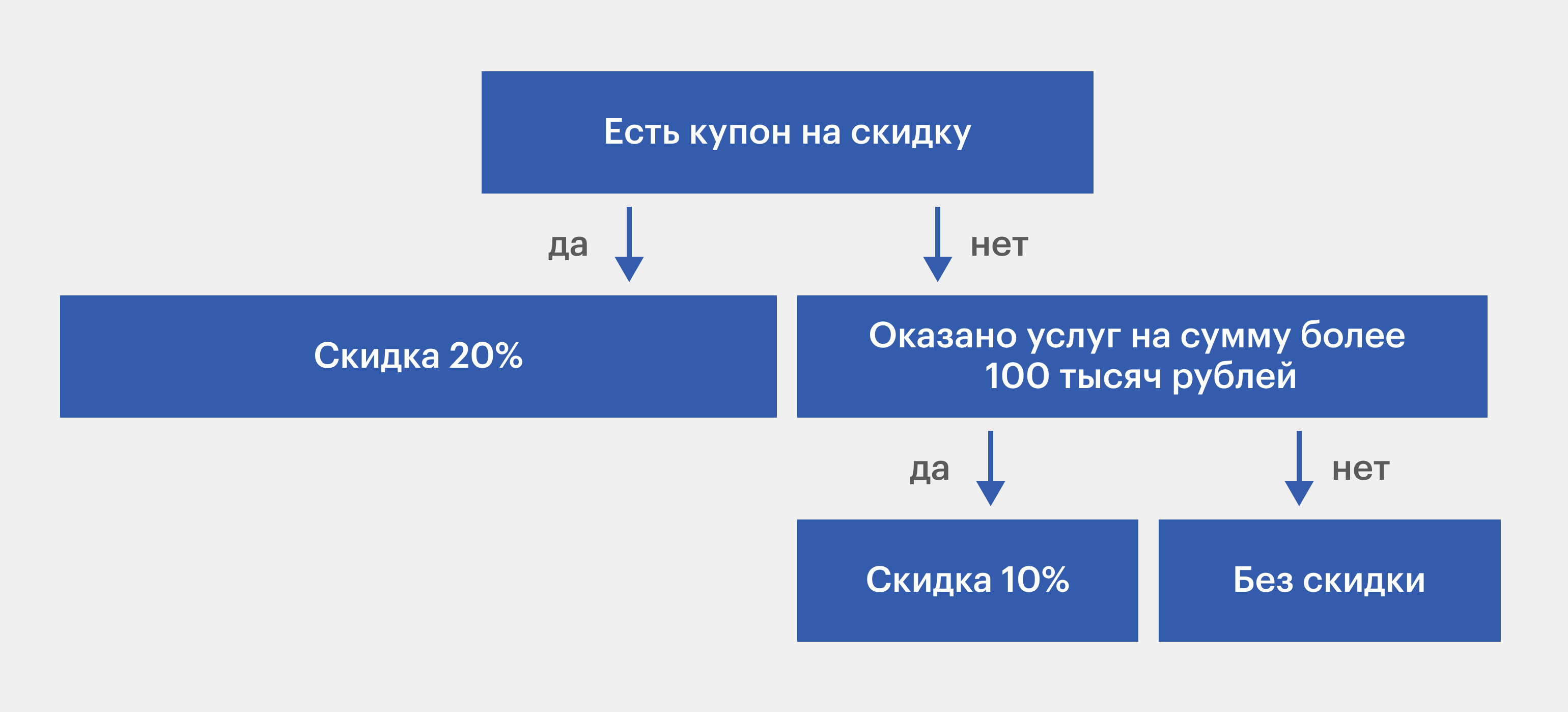
Инфографика: Майя Мальгина для Skillbox Media
Алгоритм сам генерирует правила в процессе обучения. Правила ― это обобщения множества отдельных наблюдений, описывающих предметную область. Дерево решений анализирует выборку входящих данных, а затем группирует их, чтобы объекты одного класса оказались вместе.
Например, в метеорологии они могут использоваться для прогнозирования погоды на основе данных о температуре, давлении и влажности воздуха.

SVM (машина опорных векторов)
Машины опорных векторов применяют для задач регрессии и классификации.
Цель SVM — построить в N-мерном пространстве гиперплоскость, которая однозначно разделяет данные на классы. N соответствует количеству признаков, а гиперплоскость ― это прямая, которая разделяет объекты на эти классы. Расстояние от неё до каждого класса должно быть максимальным, так как от этого зависит точность.
Логика SVM такая: чем больше расстояние между гиперплоскостью и объектами, то есть зазор, тем точнее предсказание. Гиперплоскость графически изображается в виде линии. Точки данных по разным сторонам от линии относятся к разным классам. Сложность заключается в том, чтобы найти правильную линию, которая будет разделять объекты на классы.
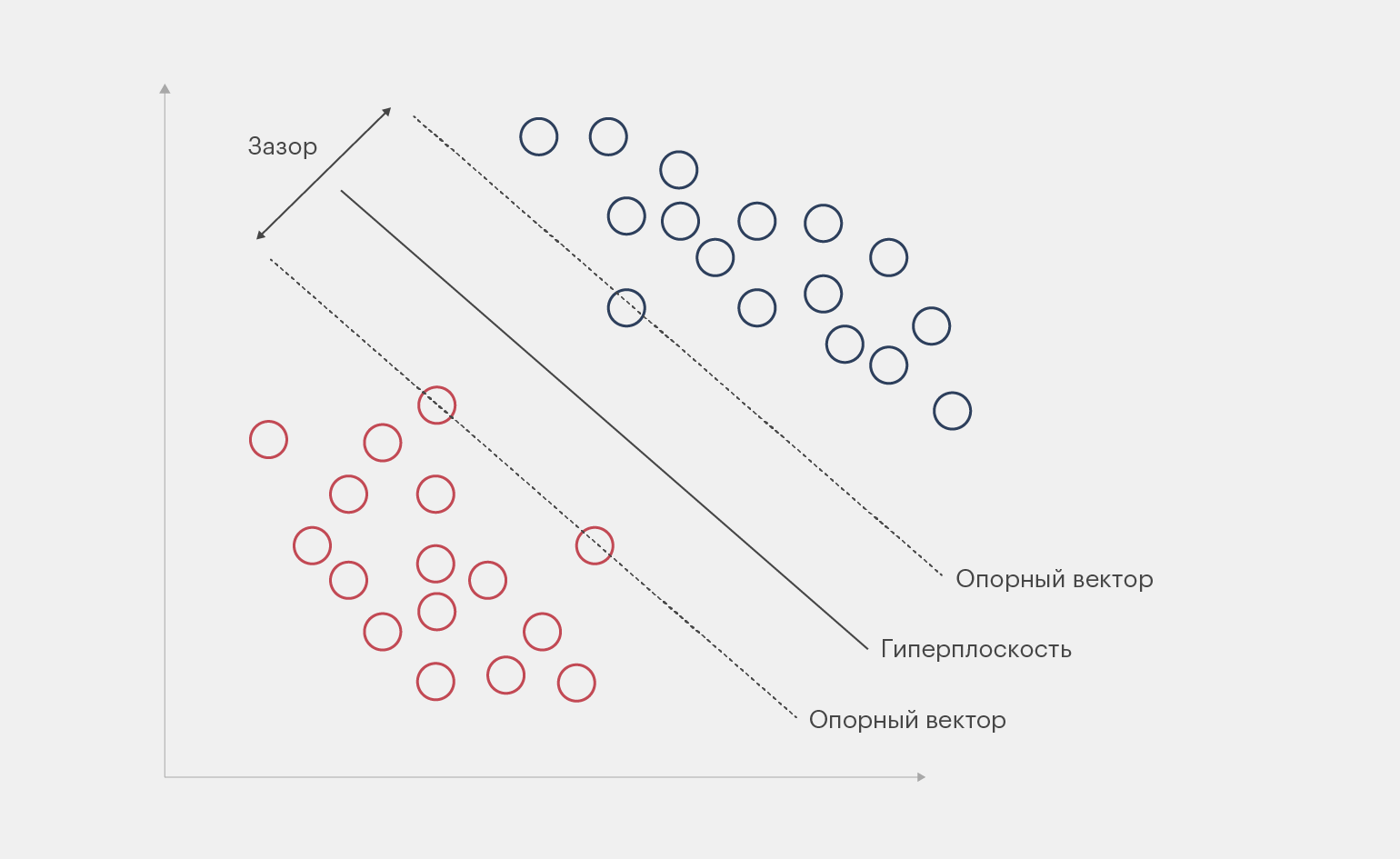
Инфографика: Майя Мальгина для Skillbox Media
SVM один из самых универсальных алгоритмов. Он используется и для распознавания лиц, и для извлечения содержания текстов при их анализе.
Нейронные сети
Нейронная сеть — это математическая модель, которая состоит из нейронов ― узлов, объединённых в слои. Между собой слои связаны синапсами. Всё вместе, хоть и очень упрощённо, напоминает устройство нашего мозга.
Когда данные подаются на вход модели, они проходят через множество слоёв нейросети и переживают трансформацию. Например, нерелевантные данные могут быть отсортированы, а более важные переданы на следующие слои. У каждого нейрона есть вес, который автоматически меняется в процессе обучения сети. Чем больше вес, тем сильнее связь между нейронами.
Нейросети сегодня превосходят большинство других моделей, независимо от задачи. А потому используются во многих областях и сферах деятельности человека.
Примеры использования машинного обучения
Рассмотрим, как умные компьютерные системы делают нашу жизнь проще в разных областях.
Рекомендация товаров в интернет-магазинах
Многие интернет-магазины используют машинное обучение для предоставления персонализированных рекомендаций своим клиентам.
Алгоритмы анализируют данные о покупках клиентов, исследуют их поведение на сайте, а также информацию о товарах, которые они просматривают. На основе этих данных можно сделать предсказания о том, какие товары могут заинтересовать клиента, и предлагать их в ленте или даже на странице с корзиной.
Рекомендательные системы также используют сайты, куда пользователи заходят, чтобы потреблять контент: соцсети, видеохостинги и новостные сайты.
Читайте также:
Обнаружение мошенничества в банковских операциях
Большинство банков используют инструменты машинного обучения для защиты средств своих клиентов, например для обнаружения мошенничества в банковских операциях.
«Умные» системы анализируют большие данные и выявляют аномальные транзакции, например перевод средств с незнакомого устройства или непривычный паттерн покупок. Это позволяет банкам быстро реагировать на подозрительные операции и предотвращать финансовые потери.
Прогнозирование погоды
Алгоритмы машинного обучения могут анализировать данные о температуре, влажности, давлении и других показателях, чтобы делать прогнозы о том, каких погодных условий можно ожидать в ближайшее время. Например, у «Яндекса» есть система предсказания погоды на основе машинного обучения «Метеум».
Постановка диагнозов в медицине
Машинное обучение применяют в анализе медицинских данных, например для анализа результата рентгенологических снимков, анализов и истории болезни. Это помогает врачам поставить правильный диагноз и подобрать наиболее эффективное лечение. Например, такой подход реализован в компании Oncora из США, использующей ML-подходы для выявления онкозаболеваний.
Распознавание речи
Машинное обучение может использоваться для распознавания речи. Алгоритмы анализируют звуковые данные и преобразовывают их в текстовую форму. Именно так работают голосовые помощники, такие как Siri и Alexa, а также переводчики текста в реальном времени.
Например, сейчас Spotify тестирует новую функцию ― дубляж подкастов в реальном времени. Причём текст на другом языке воспроизводится голосами авторов. Это было бы невозможно без машинного обучения.
Здесь мы напомним про курс Skillbox «Профессия Machine Learning Engineer». Курс даёт навыки, достаточные, чтобы стартовать в машинном обучении с нуля.
Что запомнить
Давайте повторим то, что мы сегодня узнали о машинном обучении:
- Машинное обучение — это набор методов, с помощью которых создают системы, способные самостоятельно (без жёстко заданных алгоритмов) решать поставленные задачи.
- Компьютер может учиться под присмотром учителя, который помогает программе находить решения с помощью размеченного датасета или проверки результатов. Такой метод называется обучением с учителем.
- Если программа не получает от специалиста никаких подсказок и учится только на данных― это обучение без учителя.
- Обучение с частичным привлечением учителя ― что-то среднее между самообучением машины и методом с привлечением учителя. ML-инженер может разметить только небольшую часть данных, чтобы повысить точность предсказаний модели.
- Некоторым навыкам, таким как вождение, компьютер может научиться только методом проб и ошибок в реальной среде. Так работает обучение с подкреплением.
- Машинное обучение применяют в разных областях: для рекомендации товаров в интернет-магазинах, постановки диагнозов в медицине, обнаружения мошенничества в банках и в других сферах.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!



Профессия Machine Learning Engineer
- Все необходимые для ML-инженера навыки
- Практика на реальных данных от компаний
- Практика в Kaggle — сможете работать с реальными дата-сетами