Deep learning: что это такое и зачем нужно
Расскажем, как работают нейросети на низком уровне, и покажем слоёный пирог глубоких моделей.

Если боитесь, что нейросети скоро захватят мир и всех уволят, сначала посмотрите, как один из самых умных ИИ на сегодня пытается смешно пошутить:
Промпт: Придумай шутку про глубокое обучение.
Ответ ChatGPT: Почему нейронные сети никогда не ходят на пляж?
Потому что они боятся глубокого обучения, но не могут перенести глубокое погружение!
Не у всех получается с первого раза — простим ему это. Попробуем ещё раз:
Промпт: Ещё одну.
Ответ ChatGPT: Какой алгоритм deep learning самый любимый у программистов?
НейрОТПЕЧАТКА! Ведь защищать свой код лучше всего с помощью глубокой сети!
Чтобы понять, почему у ChatGPT нет чувства юмора и остальных эмоций, в этой статье мы решили разобраться, как нейросети имитируют человеческий мозг, почему они работают так, как работают, и зачем им нужны скрытые слои.
Подготовили полный и понятный обзор на глубокое обучение, чтобы оставаться в тренде. Статья подойдёт как новичкам, так и профи.
Вы узнаете:
Что такое deep learning
Deep learning (глубокое обучение) — это способ научить компьютер делать сложные вещи: распознавать лица, определять объекты на фотографии или писать статьи по программированию.
Самый простой способ обучения — дать компьютеру много примеров и надеяться, что он их запомнит. Например, если хотим научить компьютер отличать яблоки от бананов, показываем ему сначала яблоко и говорим: «Это яблоко». Затем показываем банан и говорим: «Это банан». Повторяем это много-много раз.
Хорошо, логика понятна — показали примеры, а компьютер запомнил их. А если компьютеру попадётся новое изображение, которого не было в датасете? Что нужно сделать, чтобы он не растерялся? Создать нейронную сеть!
Нейросеть — это программа, которая притворяется человеческим мозгом. Она состоит из нейронов, которые общаются между собой. Вместе они создают сеть «мозговых клеток», чтобы запоминать информацию и принимать решения.
Если копнуть чуть глубже, то нейросеть — это сложная математическая модель. В ней нет никакой магии — только непонятные формулы из матанализа и теории вероятностей. Но всё это магическим и математическим образом помогает компьютеру думать.
Именно поэтому нейронные сети не умеют шутить — они всего лишь горстка математических функций. У ChatGPT ответ примерно такой же:
Промпт: Почему нейросети не умеют шутить?
Ответ ChatGPT: Нейросети не умеют шутить, потому что шутки требуют высокого уровня культурной и социальной осведомлённости, а нейросети сконцентрированы на статистических вычислениях, а не на творческом процессе создания юмора.
Когда нейронка видит фотографию, она начинает искать признаки яблока: смотрит на форму, цвет, текстуру и так далее. Затем сравнивает найденные особенности с тем, что видела раньше, и принимает решение: яблоко это или банан.
Чтобы нейронная сеть увереннее распознавала объекты, ей нужно дать больше примеров. «Больше» — значит тысячи или даже миллионы.
Давайте спустимся в операционную и посмотрим, из чего же состоят нейросети.
Как устроена простая нейронная сеть
Начнём с простой нейронной сети, а затем будем двигаться дальше — к многослойным сетям и современным моделям deep learning. Всё здесь подчиняется базовым правилам.
Нейросеть состоит из нейронов и связей между ними:
- Нейрон — это на самом деле небольшая программа, которая умеет делать три вещи: получать данные, обрабатывать и передавать дальше.
- Нейроны скрепляются связями, которые характеризуются весом. Вес — это число, показывающее, насколько крепко воспоминание.
Самая простая нейросеть состоит всего из одного нейрона:
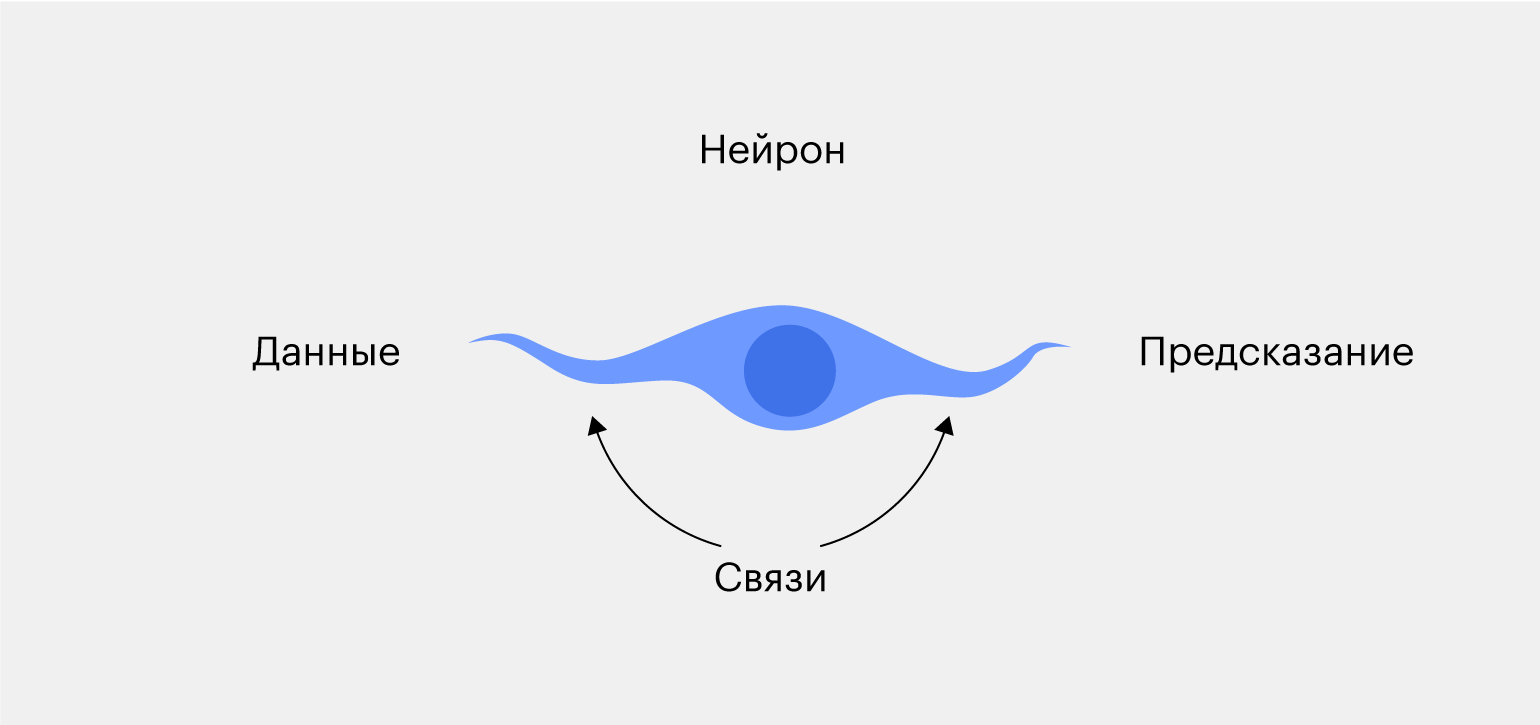
Иллюстрация: Оля Ежак для Skillbox Media
На вход нейрон получает данные — например, фотографию яблока или банана. Он обрабатывает её — скажем, проверяет цвет всех пикселей. Затем нейрон делает вывод: если зелёных пикселей больше, чем остальных, то это, вероятнее всего, яблоко. А если больше всего жёлтых, то это банан.
Алгоритм несложный и неточный. Представьте, что будет, если дать нейросети незрелый банан зелёного цвета или просто жёлтое яблоко. Получается, делать выводы только по цвету фрукта — недостаточно.
Чтобы повысить точность, можем добавить ещё два нейрона. Пусть один из них смотрит на форму объекта, а второй — на хвостик фрукта.
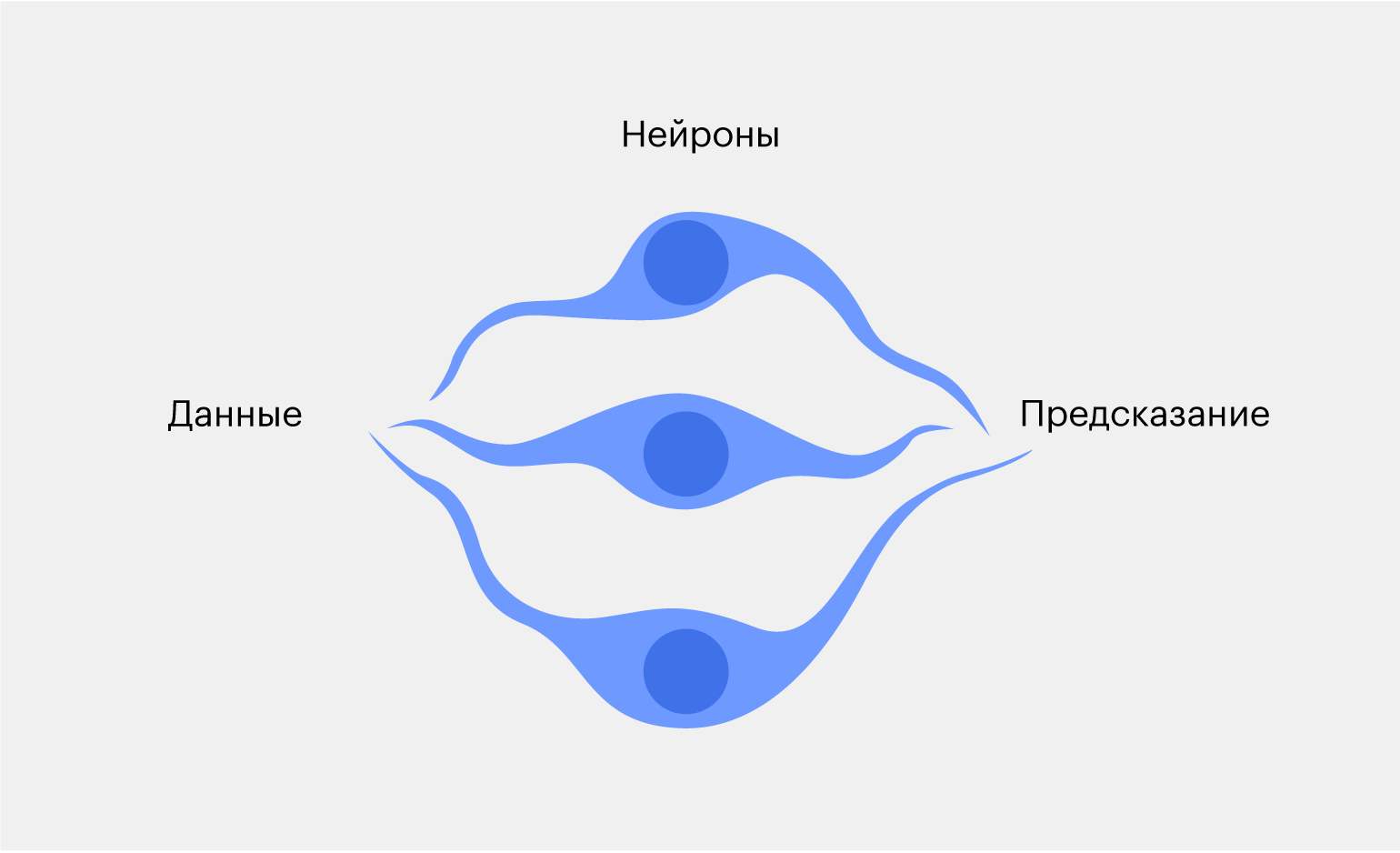
Иллюстрация: Оля Ежак для Skillbox Media
Теперь фотография банана передаётся сразу в три нейрона, затем каждый из них обрабатывает картинку по своим правилам и передаёт предположение на выход.
Когда три нейрона отработают, получится три результата — например, первый и третий скажут, что это банан, а второй будет утверждать, что яблоко. В конце нейросеть подсчитает, каких голосов было больше и выдаст этот вариант за окончательный результат.
? Но что делать, если нейросеть выдала неправильный результат?
Наказывать! Причём буквально. Хотя ладно, не буквально, а механически ослабить связь.
Связи показывают, насколько сильно нейрон влияет на принятие решений. Если связь слабая — значит, его голос будет учитываться последним. А если крепкая — он может перекрыть своим решением голоса других нейронов. Настоящая демократия.
Когда нейросеть выдаёт неправильный результат, мы снижаем влияние нейронов, которые привели к этому результату. Так и проходит deep learning.
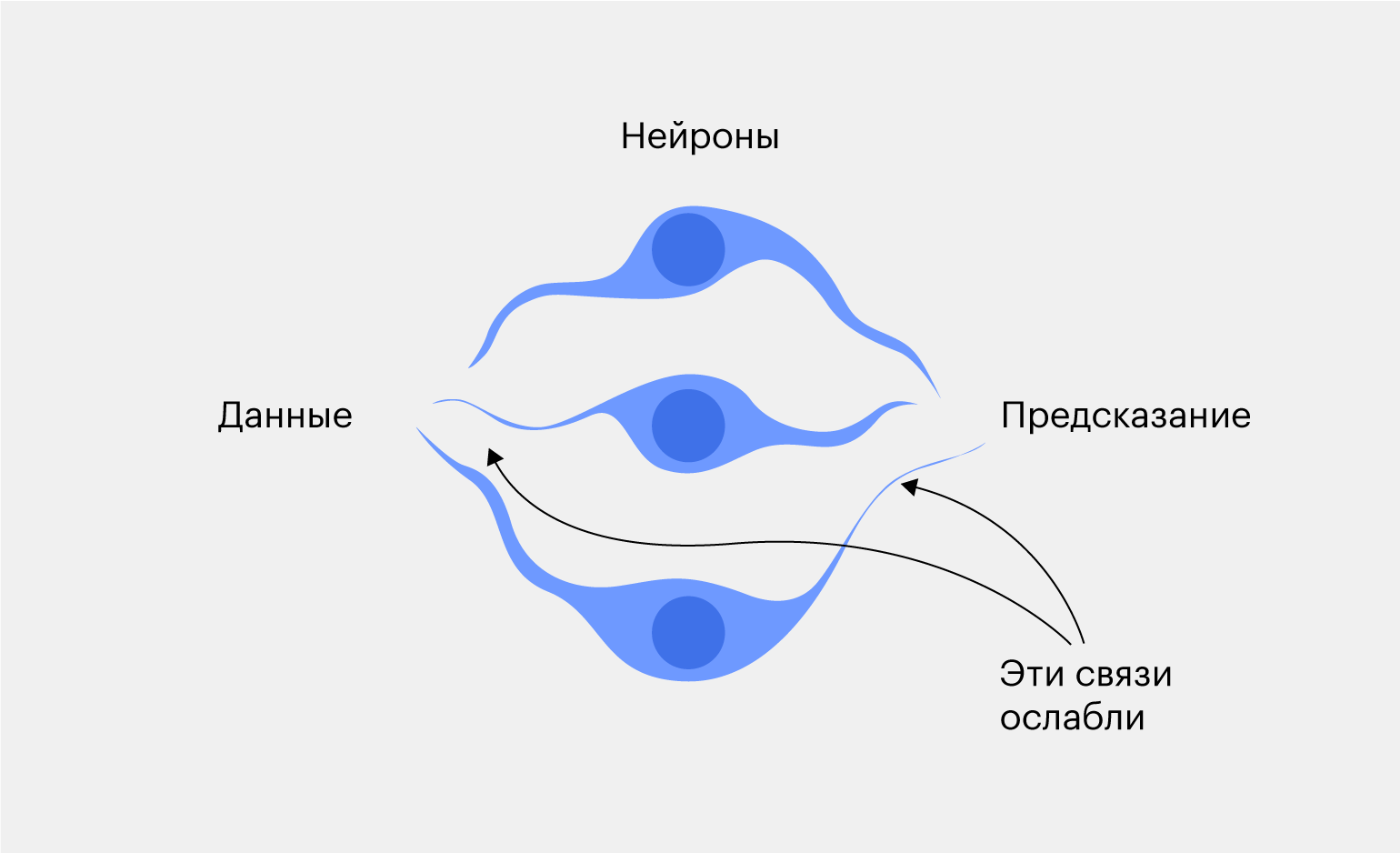
Иллюстрация: Оля Ежак для Skillbox Media
Нейроны, связи, программы… Получается, мы сами программируем нейросеть? В чём тогда искусственный интеллект? А вот в чём:
? Программы, зашитые в нейроны, не прописываются вручную. Они находятся путём проб и ошибок во время обучения самой нейронной сетью. Структура нейронки, например количество слоёв и нейронов, задаётся разработчиком с помощью языков программирования. Например, на Python это можно сделать с помощью специальной библиотеки TensorFlow.
Мы рассказали, что нейроны могут считать цвета в пикселях, смотреть на форму объектов и хвостики фруктов. Но в реальности никто не знает, почему нейросеть работает так, как она работает. Нейроны сами создают алгоритм, по которому учатся отличать яблоки от бананов. Мы им никак не помогаем — только вознаграждаем за правильные ответы и наказываем за неправильные.
Нейрон может даже полагаться на необычные явления — например, на отбрасываемую тень от фрукта или его отражение в зеркале. Этим нейросеть действительно похожа на человеческий мозг, потому что люди тоже не до конца понимают, как он работает.
А теперь перейдём от простых нейронок к сложным, или многослойным.
Как устроена многослойная нейронная сеть
Добавим нашей нейросети пару новых слоёв, чтобы она стала многослойной. Ещё такую нейронку называют глубокой нейронной сетью. У каждого её слоя есть особое название и назначение.
Первый слой называется входным, потому что он получает входные данные — например, изображения, числа и строки. Последний слой называется выходным, потому что (вы уже догадались) здесь получаются выходные значения. Все слои, которые находятся между ними, называются скрытыми.
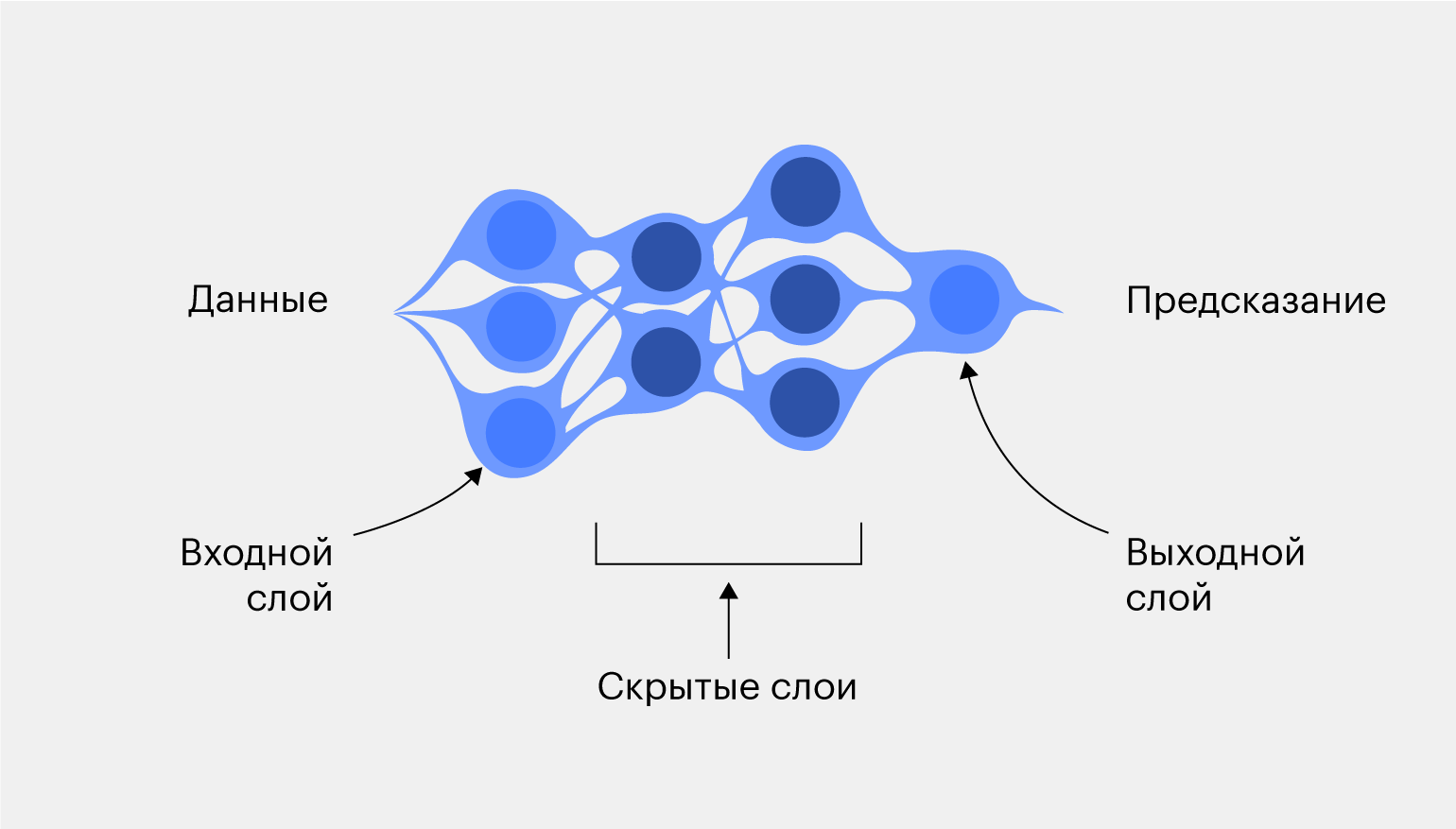
Иллюстрация: Оля Ежак для Skillbox Media
Работает многослойная нейросеть по тем же принципам, что и простая, но вместо того, чтобы сразу выдать результат, данные обрабатываются и передаются на скрытые слои. Там проходит дополнительная обработка, и после этого выводится результат.
Правда, теперь весь процесс сильно запутан: вы только посмотрите на количество связей между нейронами.
Давайте сразу ответим на вопрос: зачем нужны скрытые слои?
? Скрытые слои нужны, чтобы тщательнее обрабатывать входные данные и находить больше деталей. Например, давайте подробнее разберём пример с яблоками и бананами:
- На вход нейросеть получает картинку определённого размера — пусть 200 на 400 пикселей. Всего пикселей — 80 000. Каждый пиксель передаётся во все входные нейроны. Получаем очень много связей.
- Входной слой делает предварительную обработку картинки — например, определяет общую форму объекта на изображении. Затем передаёт обработанные данные на следующий слой — скрытый.
- Скрытый слой проводит дополнительную обработку — например, определяет цвет объекта. А дальше опять передаёт результаты к следующему слою.
- Второй скрытый слой смотрит на другие детали объекта. Здесь можете подставить что-то своё.
- Когда данные доходят до выходного слоя, нейросеть делает предположение на основе работы всех слоёв и возвращает итоговый результат.
Механизм работы стал сложнее, но и нейросеть стала умнее. Такая модель уже может решать задачи поинтереснее — например, распознавать образы, классифицировать объекты и писать текст.
? Чтобы нейросети стать ещё умнее, нельзя просто взять и добавить больше слоёв. Это поможет, но не сильно. Даже если мы добавим тысячу слоёв, ошибок в предположениях станет меньше, хотя совсем они не исчезнут.
Для перехода на следующий уровень «разумности» нужно использовать алгоритмы глубокого обучения, о которых мы поговорим дальше, а сейчас узнаем, как соотносятся друг с другом глубокое обучение и нейросети.
Что собой представляют deep learning и нейронные сети?
Короткий ответ: нейросеть — это программа, которая имитирует работу мозга, а глубокое обучение — это способы её обучения.
Длинный ответ: эти понятия связаны, но имеют серьёзные различия.
Нейросеть — это набор нейронов, которые передают данные друг другу. Это помогает нейронке принимать решения и делать предположения, например, различая объекты.
Deep learning — это когда мы делаем нейросеть сложной, добавляем много новых слоёв и используем один из алгоритмов глубокого обучения. Это позволяет решать сложные задачи — например, задачи классификации объектов, распознавания речи и создания текстов.
Без нейросетей не было бы глубокого обучения, потому что нейросеть — это основа всего машинного обучения. О нём у нас есть отдельная статья.
Как нейронные сети обучаются
Давайте разберём ещё на одном примере, как работают нейронные сети, чтобы плавно перейти к методам глубокого обучения. Допустим, мы хотим научить нейросеть предсказывать цену на авиабилеты.
- Входные данные: дата полёта, место вылета и место прибытия.
- Выходные данные: цена авиабилета.
У нас уже есть реальные цены, чтобы сравнить их с предсказаниями — и обучить нейросеть на них.
Пусть нейронка состоит из двух скрытых слоёв. В каждом скрытом слое по четыре нейрона, во входном слое — три нейрона, а в выходном — один.
Теперь будем передавать данные в нейросеть и смотреть на её предположения. Если результат близок к реальному, поощряем нейросеть и укрепляем те связи нейронов, которые к нему привели. А если результат оказался далёк от реального, то наказываем нейросеть и ослабляем те связи, которые на это повлияли.
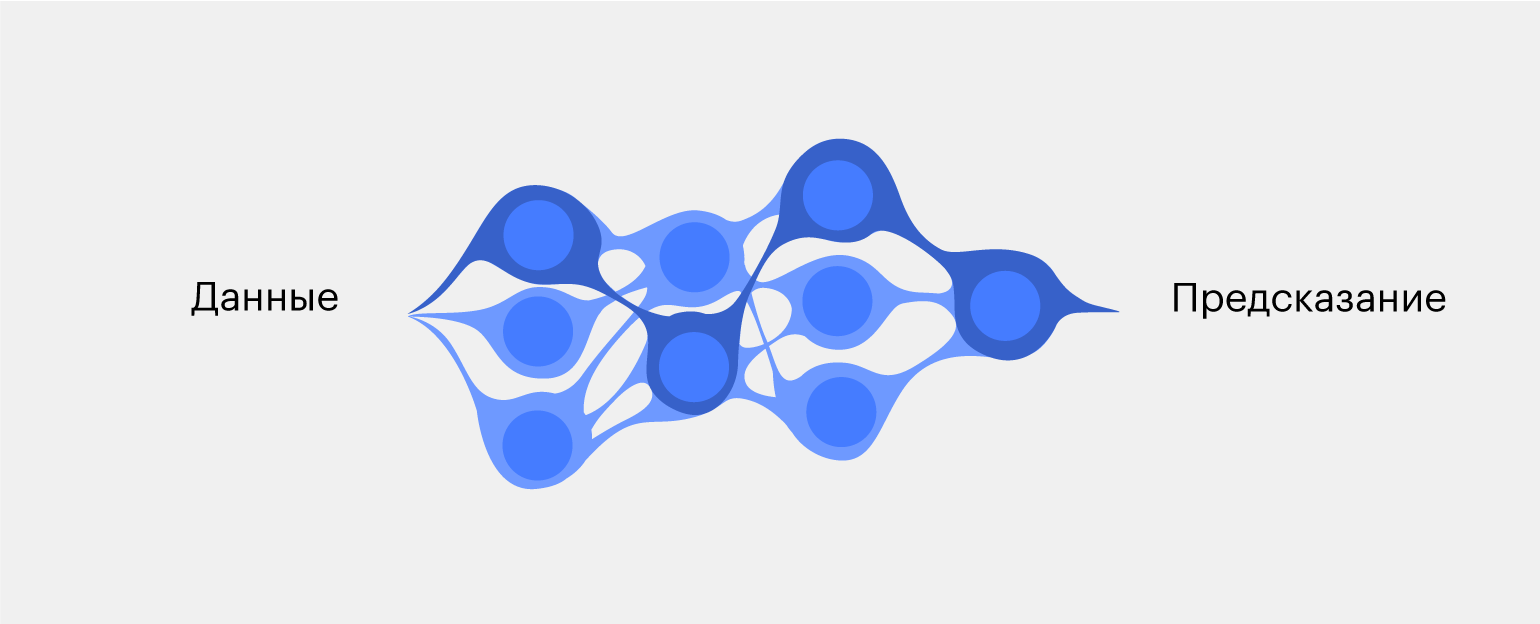
Иллюстрация: Оля Ежак для Skillbox Media
? Что значит «укрепляем» или «ослабляем» связи?
У каждой связи есть собственный вес — обычное число, например 2, 5 или 19,3. Если результат неправильный, вес уменьшаем, скажем, на 0,5. А если правильный — увеличиваем на 0,5. Изначально веса устанавливаются случайным образом, а затем подбираются в процессе обучения.
Примерно через тысячу повторений нейросеть начнёт выдавать правдивые результаты. А через миллион — станет настоящим турагентом с многолетним стажем.
Поздравляем, нейросеть обучена. Теперь можно дать ей любую дату и город для путешествия, а она назовёт стоимость билета — с небольшой погрешностью, но никто не идеален.
У такого процесса обучения есть название — обучение с учителем. Получается, что учитель — это правдивые результаты, а ученик — нейросеть.
Обучение с учителем имеет большой недостаток: что делать, если у нас нет результатов, но задачу решить нужно. Например, нейронку надо научить играть в игру «Тетрис». Здесь придётся придумать что-то новое.
Противоположность обучения с учителем — обучение без учителя, при котором нейросеть сама определяет, какой результат её устроит. Кажется, немного странным, но это очень полезно.
Представим, что мы хотим распределить всех пользователей видеохостинга на разные группы, чтобы рекомендовать им интересные видео. Самим справиться с такой задачей очень сложно, так как мы не можем предположить количество и особенности этих групп. Но задачу можно доверить нейросети.
Входными данными для неё могут быть просмотренные видео пользователя, его лайки под видео и подписки. По этим критериям юзера можно объединить с другими пользователями — например, теми, кто подписан на похожие каналы и кто лайкал похожие видео. Только что мы придумали рекомендательную систему.
Обучение с учителем и без — это два базовых способа обучения нейросети. Но если мы хотим сделать что-то похожее на ChatGPT, придётся использовать современные алгоритмы deep learning.
Какие есть алгоритмы глубокого обучения
Их много — и с каждым днём становится всё больше. Но, к сожалению, ещё не придумали универсальный способ заставить нейросеть решать любые задачи. Поэтому пока обходятся разными алгоритмами: для работы с изображениями используют свёрточные нейросети, а чтобы писать текст — рекуррентные.
Давайте разберёмся, как работают популярные алгоритмы.
Свёрточные нейронные сети (convolutional neural networks, CNN)
Зачем нужны: помогают обрабатывать картинки и лучше понимать, что на них изображено.
Как работают: добавляют в нейросеть дополнительные слои — свёрточные. Они нужны, чтобы анализировать изображение тщательнее.
В свёрточных слоях на картинку накладывают фильтры — например, делают чёрно-белой, выделяют все углы или обрезают. Так нейросеть находит новые детали, которые помогут ей лучше определять объекты на изображении.
Первый свёрточный слой обычно нужен, чтобы находить все края и углы у объектов. Следующие слои — чтобы видеть более сложные элементы, например форму или текстуру. А последний слой собирает все детали вместе и делает предсказание.
Рекуррентные нейронные сети (recurrent neural networks, RNN)
Зачем нужны: помогают понять и обработать элементы, которые идут последовательно и связаны друг с другом, — например, текст.
Как работают: запоминают всё, что происходило раньше, чтобы понимать, что произойдёт дальше.
Рекуррентные нейросети состоят из звеньев, которые похожи на бусы. Каждая бусинка — это кусок информации, такой как слово. Вместе бусы образуют цепочку отдельных бусинок, которые связаны друг с другом.
Эта концепция может показаться запутанной, потому что здесь есть слово «рекурсия», но главный смысл рекуррентных нейросетей в том, что они умеют проводить ассоциации между разными объектами.
Когда рекуррентная нейронная сеть получает предложение на вход, она анализирует каждое слово по отдельности. Новые слова соединяются с уже изученными — так нейросеть понимает контекст и значение каждого слова в связке с окружающими.
Разновидность архитектуры RNN — сети с долговременной и кратковременной памятью (long short-term memory, LSTM). Они сохраняют в памяти информацию, пока её не попросят удалить. LSTM-сети обычно используют в связке с другими видами deep learning. Например, ChatGPT работает по такой схеме: чат-бот запоминает, что пользователь писал раньше, чтобы выдавать ему более релевантные ответы.
Генеративно-состязательные сети (generative adversarial networks, GAN)
Зачем нужны: рисовать, сочинять музыку и писать стихи — или просто творить.
Как работают: используют связь из двух нейросетей — художника и критика. Художник создаёт что-то новое, а критик пытается понять, создано это реальными художниками или нейросетью.
С каждым новым творением нейросеть-художник становится всё лучше — в умении подражать художникам-людям и умении обманывать нейросеть-критика. А нейросеть-критик учится внимательнее анализировать творения художника.
Такое «состязание» помогает нейронной сети быстро обучаться. И для этого человеку даже не нужно прикладывать усилия, достаточно алгоритма для проведения машинного обучения.
? Главная фишка алгоритмов глубокого обучения в том, что их можно объединять.
Например, если совместить генеративно-состязательную и рекуррентную нейросети, получим что-то похожее на ChatGPT. Такая нейронная сеть сможет творить, запоминать, что она делала и даже сочинять стихи.
Где применяется глубокое обучение
Deep learning проникло повсюду, но оно ещё слабовато, чтобы полностью заменить все профессии. И этому есть объяснение — компьютерам не хватает вычислительных мощностей.
И всё же есть несколько сфер, в которых алгоритмы deep learning уже находят применение.
Чипы для гаджетов. Всё больше компаний говорят, что они встраивают алгоритмы глубокого обучения в свои устройства. NVIDIA показала всем, что нейросети могут прибавить пару десятков кадров в играх на видеокартах. А Apple утверждает, что их процессоры повсюду напичканы нейросетями, которые улучшают работу смартфонов. Возможно, это маркетинговый приём, но хотелось бы верить, что нет.
Игры. Представьте, что вы играете в свою любимую игру, где общаетесь с NPC, как с живым человеком. И это уже не просто мечты, а вполне реальность. После выхода ChatGPT разработчики игр всерьёз задумались над тем, чтобы создать реалистичные диалоги в играх. Для этого всего лишь нужно придумать способ добавить нейросеть внутрь игрового процесса.
Медицина. Нейросети ещё не ставят окончательные диагнозы пациентам, но очень хорошо помогают врачам делать предположения о возможных заболеваниях. Некоторые компании даже делают своих карманных психологов — о них у нас есть отдельная статья, в которой мы поговорили с основателем стартапа для психологической самопомощи.
Цифровые помощники. Нейросети могут помочь с подготовкой презентации, записью видеоурока для образовательных курсов или даже с ответом на звонки спамеров. Такой автоответчик несколько лет назад реализовал банк «Тинькофф».
Что запомнить
Давайте подведём итоги и повторим то, что мы сегодня узнали:
- Глубокое обучение — это способ научить компьютер делать сложные вещи. Например, отличать яблоки от бананов.
- Deep learning построено на нейросетях. Это такие программы, которые «притворяются» человеческим мозгом.
- Нейросеть состоит из нейронов и связей между ними. Нейроны обрабатывают данные и передают результат по связям к другим нейронам.
- Чтобы обучить нейросеть, нужно вознаградить те нейроны, которые привели к правильному результату. Это делается с помощью усиления или ослабления нейронных связей.
- Нейросети бывают простыми, то есть состоящими из одного слоя нейронов. А ещё они бывают многослойными — тогда слоёв несколько.
- Многослойная нейросеть состоит из слоёв трёх типов: входного, скрытого и выходного. Входной слой получает начальные данные и проводит первичную обработку. Скрытые слои проводят дополнительную обработку данных. А выходной слой возвращает предсказание, то есть результат.
- Два главных способа обучить нейросеть — это обучение с учителем и без. В процессе обучения с учителем происходит сравнение предсказаний нейронной сети с правильными результатами. А при обучении без учителя — нейросети предоставляют возможность самой решить задачу и понять, какие ответы верные.
- Чтобы решать сложные задачи, используют алгоритмы deep learning. Самые популярные алгоритмы — это свёрточные нейронные сети, рекуррентные и генеративно-состязательные.
- Нейросети применяют практически везде — в играх, голосовых помощниках и медицине.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!