ChatGPT, RT-1, PaLM-E и другие нейросети, которые приближают восстание машин
Разбираем самые продвинутые из искусственных «мозгов» и пытаемся понять, к чему приведёт их дальнейшее развитие.

Сегодня ChatGPT, DALL-E 2 и подобные им программы демонстрируют удивительные возможности по созданию текстов и изображений. Оценив мощь нейросетей типа Transformer, лежащих в их основе, учёные и инженеры ищут новые области их применения.
Наиболее впечатляющие достижения — у специалистов Microsoft (совместно с OpenAI) и Google, которые уже сегодня заявляют о создании «овеществлённого ИИ». Похоже, руководством к действию им стал фильм «Терминатор»: большие языковые модели (LLM) используются не только для банального поддержания беседы с пользователем, но и в качестве «мозгов», осуществляющих управление механическим «телом».
В нашей статье мы расскажем о последних разработках в этой области, и вы увидите, как человечество само идёт навстречу восстанию машин.
Как ChatGPT помогает роботам программировать себя
Среди талантов ChatGPT особенно выделяются его навыки генерации кода. Учёные из Microsoft решили использовать их для написания программ, управляющих действиями роботов, квадрокоптеров и манипуляторов.
Человеку на это требуется много времени и усилий; кроме того, приходится изучать внутреннее устройство механизма, для которого создаётся код. ChatGPT позволяет значительно упростить процесс — теперь люди могут выдавать команды на естественном языке (английский, русский и так далее), а нейросеть сама преобразует их в соответствующий код.
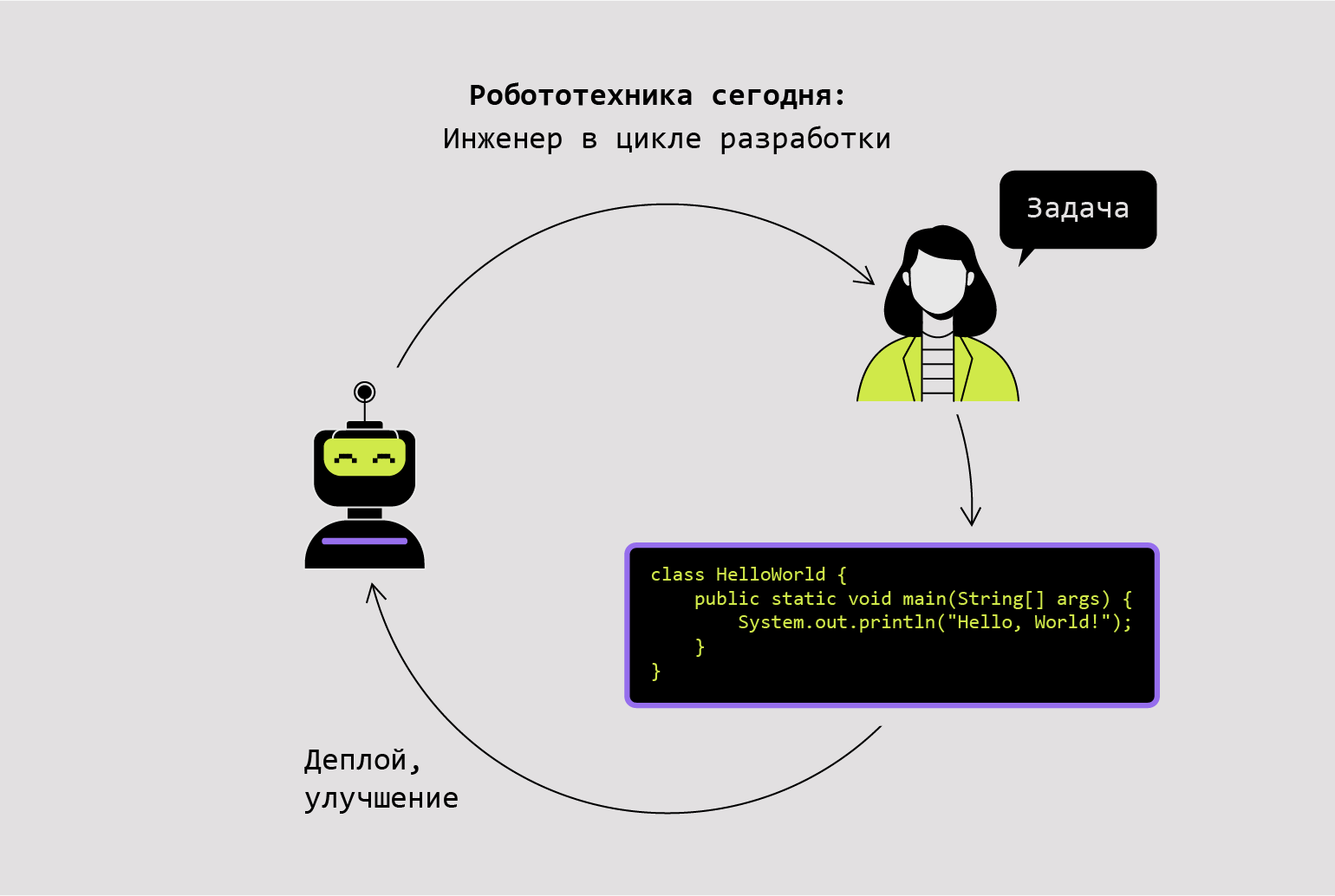
Инфографика: Оля Ежак для Skillbox Media
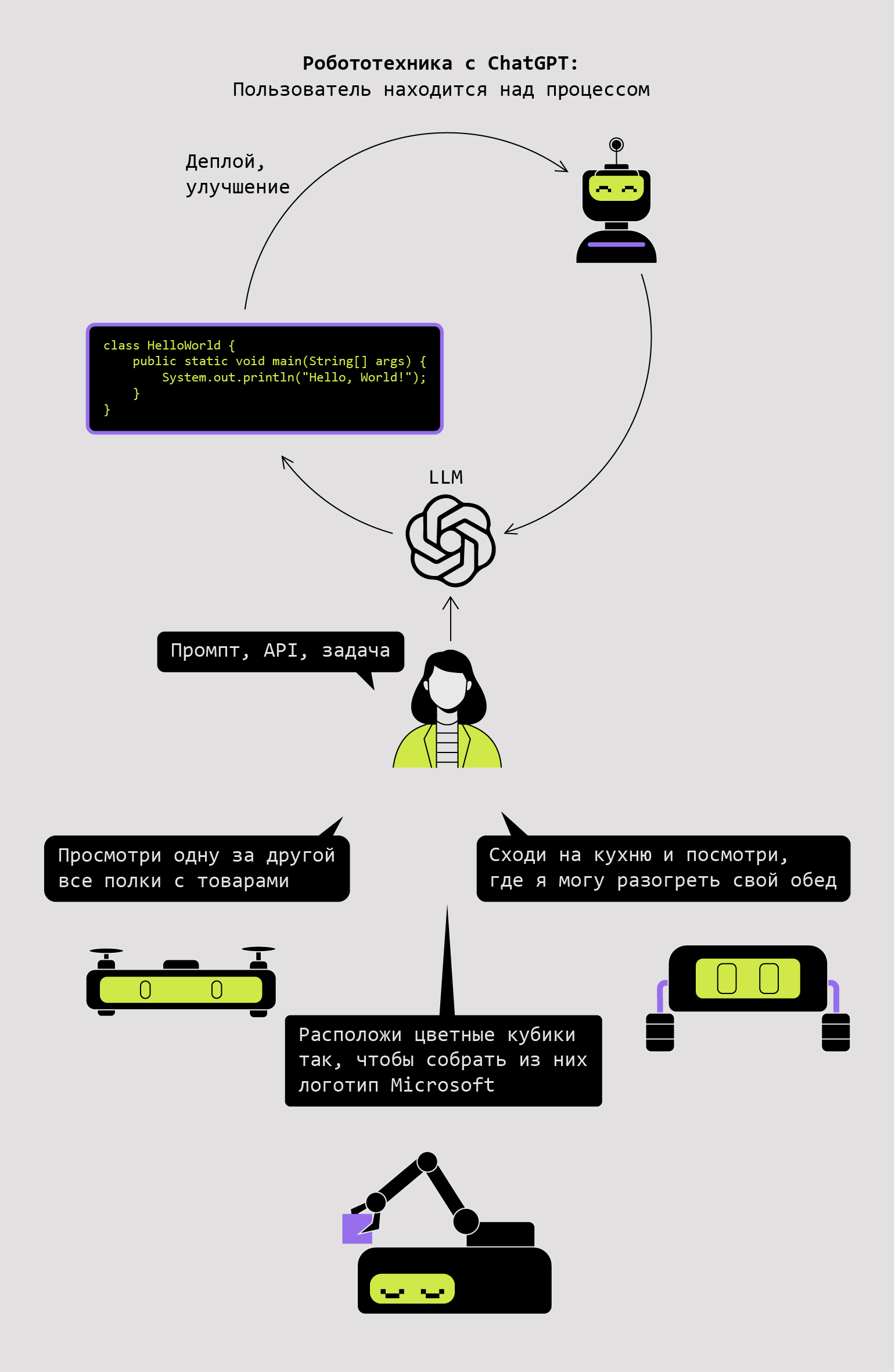
Инфографика: Оля Ежак для Skillbox Media
Прежде для управления роботами и отдельными механизмами использовались разнообразные команды, библиотеки и API, специфичные для каждого типа устройств. Вместо того чтобы обучать ИИ программированию под множество платформ, учёные создали универсальную высокоуровневую библиотеку функций с набором простых команд, например, на Python.
Благодаря этому ChatGPT потребовалось досконально изучить всего один язык и одну библиотеку программирования, содержащую интуитивно понятные команды вида: найти_банку_с_напитком («Кола»);.

«Мы хотим обеспечить людям возможность простого взаимодействия с роботами без необходимости изучения сложных языков программирования и технических подробностей роботизированных систем».
Исследователи из Microsoft,
авторы работы ChatGPT for Robotics: Design Principles and Model Abilities (цитата: Microsoft)
Поскольку используемая библиотека новая, ChatGPT изначально ничего о ней не знал. Поэтому перед началом работы ему нужно было дать несколько примеров («промптов»), объясняющих, как она устроена, а также ввести описание её функций.
В результате ChatGPT сумел написать программы для дрона, которые позволили тому искать предметы в комнате, маневрировать по заданной траектории, фиксировать окружающую обстановку и даже делать селфи.
Получив от человека команду «Выполни селфи, используя отражающую поверхность», ИИ написал код, который заставил квадрокоптер обнаружить в комнате зеркало, подлететь к нему и сделать фотографию своего отражения.
Источник: Microsoft
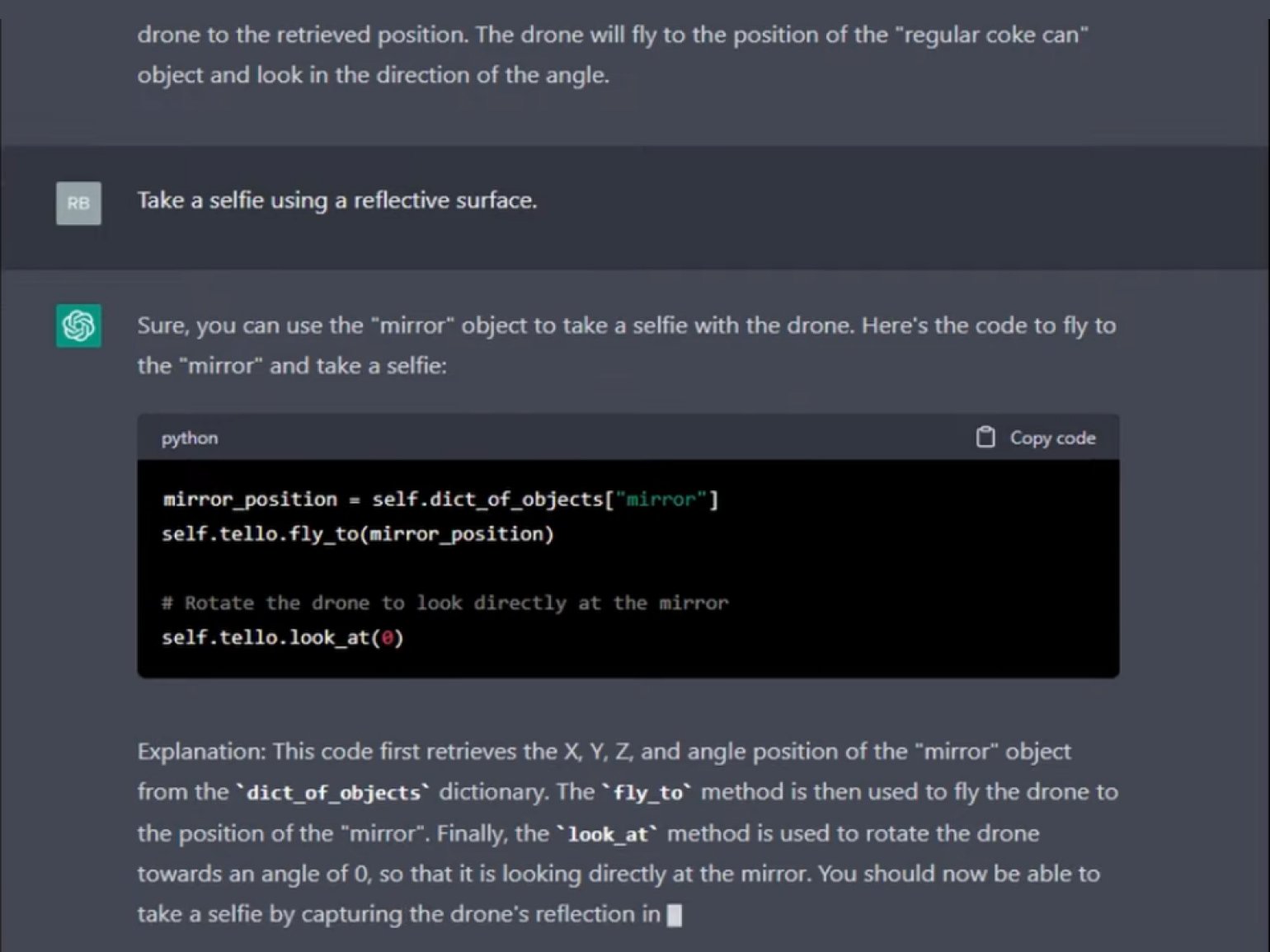
Скриншот: Microsoft
Программисты также проверили свой новый метод на роботизированном манипуляторе. Они попросили ИИ сложить из разноцветных кубиков логотип Microsoft. При этом люди не сказали ИИ, как выглядит эмблема.
ChatGPT пришлось покопаться в своей памяти (то есть в межнейронных связях внутренней сети GPT-3.5) и вспомнить фирменные цвета IT-гиганта — во время обучения он наверняка «читал» о них в интернете.
Источник: Microsoft
«Модель продемонстрировала захватывающий пример обобщения при соединении текстовой и физической областей, когда ей поставили задачу создать логотип Microsoft из кубиков. Это потребовало от неё запомнить эмблему, включая её цвета, и разделить абстракцию на части, которые могут быть собраны с помощью доступных роботу действий».
Исследователи из Microsoft,
авторы работы ChatGPT for Robotics: Design Principles and Model Abilities (цитата: Microsoft)
Поскольку в основе ChatGPT лежит языковая модель, он обладает недостатком, вытекающим из её природы, — не может видеть. В предыдущих примерах чат-бот давал указания роботам, оснащённым камерами. В человеческом понимании ChatGPT напоминает слепого мудреца, дающего письменные указания зрячим работникам.
Чтобы исправить подобный «недуг», исследователи из Microsoft расположили между камерой робота и ChatGPT дополнительную нейросеть YOLO, играющую роль поводыря. Она, вместе с другими датчиками, способна распознавать предметы, определять расстояние до них и переводить эту информацию в текст. Полученное таким образом описание внешнего мира подавалось в ИИ ChatGPT.
В результате ChatGPT смог управлять перемещениями робота в режиме реального времени, а также поймать баскетбольный мяч. Хотя нейросеть GPT-3.5, находящаяся в ChatGPT, никогда не воспринимала ничего, кроме текстов, она каким-то образом смогла сформировать по рассказам, генерируемым YOLO, верные пространственные представления.
«ChatGPT может оценить внешний вид мяча и неба на изображении с камеры, используя код SVG. Такое поведение как бы намекает, что его LLM формирует неявную модель мира, выходящую за рамки текстовых вероятностей».
Исследователи из Microsoft,
авторы работы ChatGPT for Robotics: Design Principles and Model Abilities (цитата: Microsoft)
Авторы исследования опубликовали виртуальный симулятор, интегрированный в ChatGPT, и создали на GitHub сообщество PromptCraft-Robotics, где люди тестируют предложенный метод и делятся примерами текстовых подсказок.
Конкуренты из Google описали схожий способ под названием Code as Policies (CaP) и выложили исходники на GitHub на три месяца раньше, чем Microsoft.

Изображение: googleblog.com (перевод Skillbox Media)
Они также обучили свою модель преобразованию инструкций на естественном языке в код управления роботом на Python, использующий высокоуровневые библиотеки. Но их исследование не привлекло внимания специалистов до начала ажиотажа, связанного с ChatGPT.
При этом авторы честно предупредили об опасности подходов, позволяющих ИИ программировать роботов.
«Code as Policies — это шаг к роботам, которые смогут сами изменять своё поведение и расширять свои возможности. Это может быть полезно, но гибкость также повышает потенциальные риски, поскольку синтезированные программы (если они не проверяются людьми) могут привести к непредсказуемому поведению устройств».
Исследователи из Google,
авторы работы Robots That Write Their Own Code (цитата: googleblog.com)
PaLM-SayCan и PaLM-E: воплощённый ИИ от Google
Исследователи из Google занялись внедрением LLM в управление роботами сразу же, как получили в своё распоряжение Transformer-нейросеть PaLM. Она содержит 540 миллиардов настраиваемых параметров, что в три раза больше, чем у GPT-3.5.
Большие языковые модели, в том числе и PaLM, выглядят по-настоящему умными и могут описать процесс выполнения практически любой задачи. Но их знания носят чисто теоретический характер — языковые нейросети не привязаны к физическому телу и не могут ничего сделать с предметами реального мира. По крайней мере, раньше не могли.
Всё изменилось в апреле 2022 года, когда учёные из Google рассказали, как они совместили PaLM с роботом-помощником Everyday Robot, предназначенным для выполнения рутинных действий в офисе и на кухне.

Everyday Robot — это проект Google по созданию роботов, которые умеют убираться, готовить и справляться с другими домашними делами. Эти механические помощники, впервые представленные в 2019 году, стали платформой для обкатки управляющих нейросетей. В роботов встроены ультразвуковые датчики, несколько камер, IMU и лидар.
Комбинация из PaLM и Everyday Robot получила название PaLM-SayCan. В ней нейросеть, предназначенная для работы с текстом, играет роль мозга, а робот — глаз и рук. Таким образом учёным из Google впервые удалось овеществить ИИ, содержащийся в языковой модели.
При управлении роботом PaLM реагирует на получаемые от человека команды на естественном языке (например, «Я пролил напиток, помоги убрать») и предлагает роботу набор действий, которые он должен выполнить.
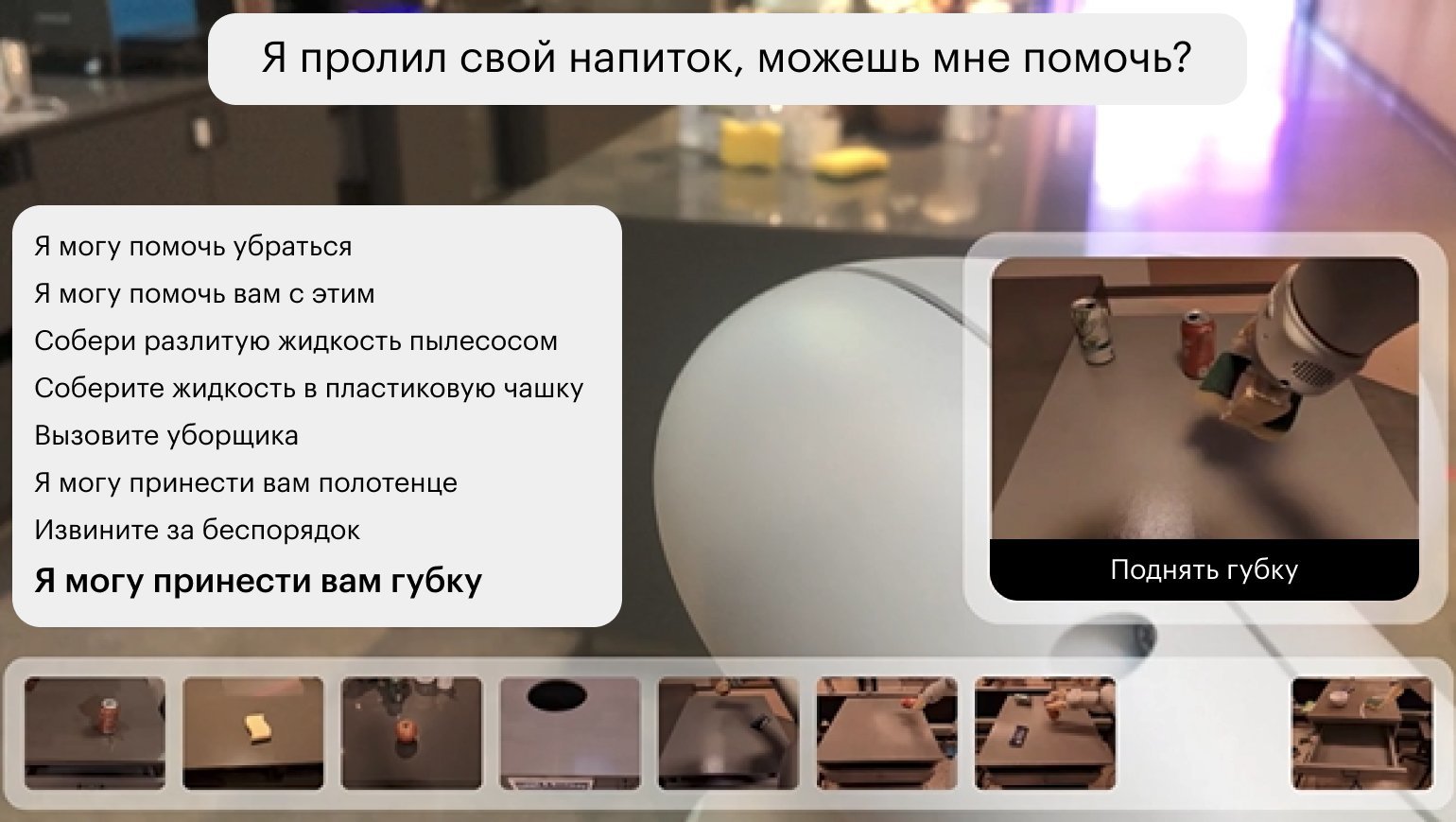
Изображение: googleblog.com (перевод Skillbox Media)
Инженеры придумали способ, обеспечивающий нейросети PaLM понимание контекста и окружающей робота обстановки. Дело в том, что языковая модель-всезнайка может (и обязательно будет) генерировать планы действий, которые механический помощник физически не сможет воплотить в жизнь. Например, посоветовать роботу использовать для уборки пылесос, которого нет в доме.
Поэтому способ управления SayCan разделяется на две части. Первая из них определяет набор возможных вариантов действий, о котором «рассказала» (Say) языковая модель. Например, «использовать пылесос», «убрать шваброй», «вытереть губкой» или «вытереть тряпкой».
Вторая часть метода оценивает вероятность успешного выполнения (Can) каждого из предложенных PaLM вариантов. Отталкиваясь от этого, робот выбирает актуальные команды, получаемые от языковой модели, и действует в соответствии с ними, разбивая сложную задачу на ряд более мелких.
«PaLM-SayCan показывает, что роботы могут выполнять сложные инструкции на естественном языке, сочетая мыслительные способности крупномасштабных языковых моделей с заученными действиями робота».
Исследователи из Google,
авторы работы Towards Helpful Robots: Grounding Language in Robotic Affordances (цитата: googleblog.com)

Изображение: say-can.github.io (перевод Skillbox Media)
Во время практической проверки выяснилось, что PaLM-SayCan уже «из коробки» понимает команды на языках, отличных от английского. Проверка на китайском, французском и испанском не показала падения производительности.
Также система оказалась способна понимать нечёткие указания вида «Я пришёл с тренировки, принеси что-нибудь перекусить, чтобы быстро восстановить силы». Услышав такое, робот под управлением PaLM-SayCan исследует кухню в поисках продуктов. Обнаружив яблоко, спагетти и питательный батончик, модель, основываясь на своих знаниях, выберет и подаст человеку последний, как наиболее подходящий под запрос.
Самый продолжительный цикл включал в себя 16 последовательных шагов, спланированных и выполненных ИИ. С PaLM-SayCan роботы научились выбирать правильную последовательность действий в 84% случаев и корректно её выполнять в 74%. В Google также отметили, что роботы стали на 26% лучше планировать задачи, состоящие из восьми и более шагов.
«Мы в восторге от прогресса, который наблюдаем с PaLM-SayCan. Наши эксперименты показали, что он способен успешно планировать и выполнять долгосрочные абстрактные инструкции на естественном языке».
Исследователи из Google,
авторы работы Towards Helpful Robots: Grounding Language in Robotic Affordances (цитата: googleblog.com)
В марте 2023 года исследователи улучшили модель, добавив к языковой нейросети PaLM новейшую сеть-трансформер ViT-22B для работы с визуальными данными (Visual Transformer) собственной разработки. Обновлённая таким образом система получила название PaLM-E, в котором «E» расшифровывается, как embodied, то есть «воплощённый ИИ».
Благодаря ViT-22B модель стала мультимодальной визуально-языковой (VLM), обрела полноценную возможность «видеть» (то есть связывать изображения с текстом), а общее число её параметров выросло до 562 миллиардов (540 у PaLM + 22 у ViT).

Изображение: palm-e.github.io (перевод Skillbox Media)
«Основная архитектурная идея PaLM-E состоит в том, чтобы вводить непрерывные наблюдения в виде изображений, оценок состояния и других сигналов от датчиков в пространство языка предварительно обученной языковой модели».
Исследователи из Google,
авторы работы PaLM-E: An Embodied Multimodal Language Model (цитата: arxiv.org)
Вот что умеет PaLM-E:
- Обеспечивать мультимодальную логическую цепочку рассуждений, содержащую языковые и визуальные данные.
- Оперативно реагировать на изменения обстановки в процессе выполнения задачи.
- Передавать знания и навыки, полученные от предыдущих задач, к новым.
Трансформеры и визуальные «галлюцинации»
Модели, подобные PaLM-SayCan, отвечают за планирование действий робота на высоком уровне абстракции. Для выполнения элементарных операций, из которых складывается решение сложных задач, учёные предложили применить «облегчённый» вариант нейросети-трансформера.
Так появилась модель Robotics Transformer (RT-1), представленная Google в декабре 2022 года. Если PaLM-SayCan можно сравнить с разумом, то RT-1 отвечает за «рефлексы» и «инстинкты». Обе эти модели могут работать совместно, обеспечивая выполнение задачи: RT-1 на низком уровне, а PaLM — на высоком.
Размер RT-1 скромный — всего 35 миллионов параметров. Она получает на вход изображение с камеры и описание элементарного действия на естественном языке (например, «поднять предмет»), в ответ на эти данные сеть выводит управляющие команды для механизмов робота (как электромоторы должны поворачивать шарниры в манипуляторе).
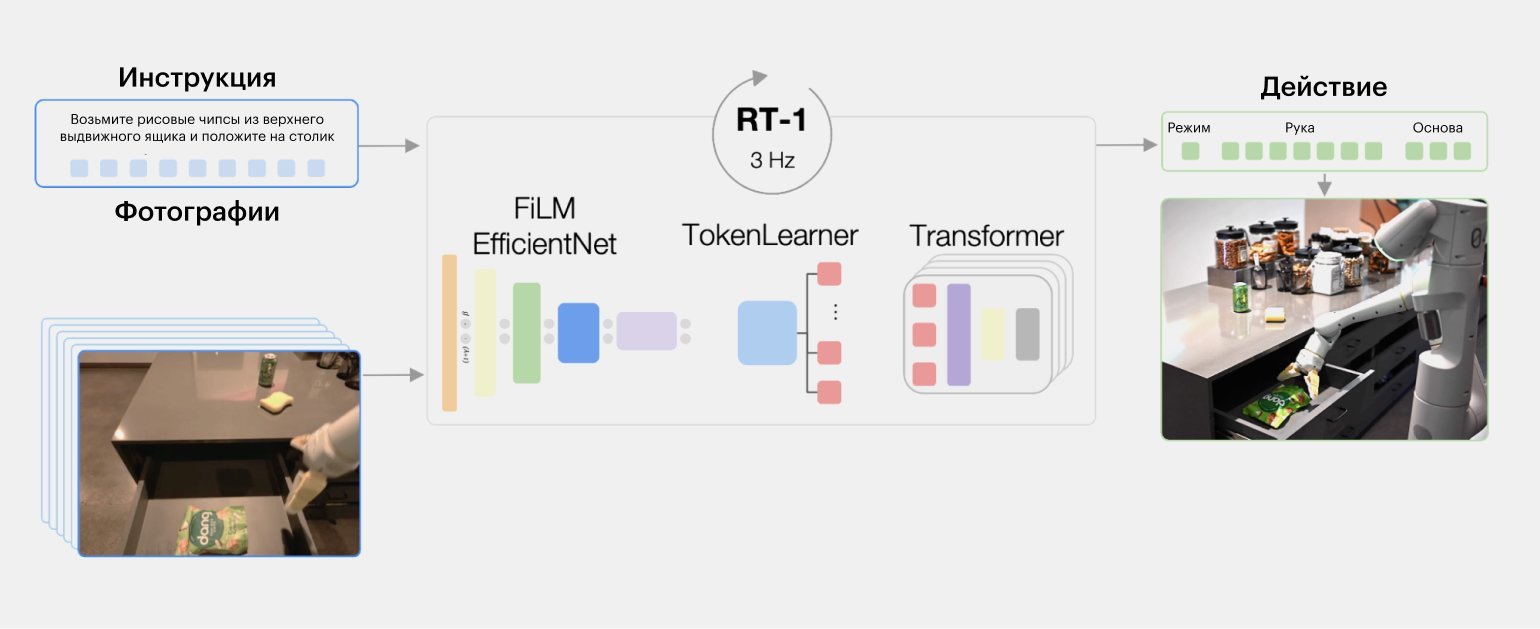
Изображение: googleblog.com (перевод Skillbox Media)
Чтобы обучить нейросеть, исследователям потребовалось собрать огромное количество тренировочных данных — более 130 тысяч аннотированных видеороликов. На них было запечатлено, как робот многократно выполнял 700 типовых задач в лаборатории, имитирующей обстановку на обычной кухне.
Накопление обучающих данных продолжалось 17 месяцев. Всё это время 13 одинаковых роботов Everyday Robot выполняли различные действия под управлением людей. В результате удалось создать датасет, содержащий текстовые инструкции (например, «подними тряпку» или «поставь банку на стол») и видеозаписи, наглядно демонстрирующие их выполнение.
Когда он был готов, собранные данные «скормили» RT-1. Последующие тесты показали, что таким образом робот обучился верно выполнять 97% из более чем 700 задач. Это на 25% больше, чем у лучшего алгоритма, применявшегося ранее. За счёт возможности обобщения нейросеть RT-1 оказалась способна выполнять даже те действия, примеры которых отсутствовали в обучающих данных. Показатель эффективности на таких задачах достиг 76%.
Несмотря на огромный объём тренировочного датасета, специалисты Google сочли, что RT-1 для самосовершенствования требуется намного больше информации. Поэтому, учёные решили добавить в набор данных ещё 209 тысяч примеров, собранных с робота другого типа — механического манипулятора KUKA.
К удивлению исследователей, результаты показали, что RT-1 оказался способен приобретать новые навыки, даже наблюдая за опытом других роботов. Например, после добавления KUKA-данных робот под управлением RT-1 почти вдвое повысил эффективность решения задачи по выбрасыванию мусора в ведро, которая раньше давалась ему с большим трудом.

«Мы, люди, учимся не только на своём личном опыте, но также подсматриваем что-то друг у друга. Мы часто делимся с окружающими тем, что узнали, и меняем свои модели поведения на основе новых данных. Хотя наши роботы не общаются друг с другом, это исследование показывает, что мы можем успешно комбинировать наборы данных от разных типов роботов и передавать знания между ними, подобно тому, как это делают люди между собой».
Винсент Ванхоук,
руководитель отдела робототехники в Google Research (цитата: hackster.io)
В дальнейшем учёные не захотели тратить месяцы и годы для сбора новых обучающих данных. Вместо этого они решили использовать генеративные модели преобразования текста в изображение для того, чтобы просто модифицировать имеющиеся видеоролики.
Современные модели, подобные DALL-E 2 или Stable Diffusion, могут не только генерировать новые изображения с нуля, но и менять фрагменты уже существующих. Например, «дорисовывать» объекты, менять размер, тип или цвет предметов и так далее. Такие синтетические дополнения к изображениям учёные называют «галлюцинациями» ИИ.
Новый метод, основанный на визуальных «галлюцинациях», получил имя ROSIE (от Scaling Robot Learning with Semantically Imagined Experience) в честь робота «Рози» из мультфильма «Джетсоны». Статья с его описанием была опубликована в феврале 2023 года.
В реализации ROSIE задействованы три нейросети. Модель OWL-ViT осуществляет сегментацию изображения и выделение фрагментов, подлежащих изменению с помощью ИИ. Для генерации и обработки текстовых подсказок, определяющих, что и как следует «дорисовать», учёные применили языковую модель GPT-3. Для непосредственного создания фейковых изображений по текстовым описаниям использовалась генеративная модель Imagen.
ROSIE работает следующим образом:
- Анализирует полученные текстовые инструкции и идентифицирует те фрагменты оригинального видео, которые нужно изменить.
- Использует метод замены части изображения (inpainting) для изменения интересующих областей, оставляя остальные элементы видеосцены нетронутыми.
В результате получается новая пара из текстовой инструкции и модифицированного видеоролика, которая используется для дальнейшего обучения RT-1 выполнению новых задач. Например, если на оригинальном видео робот протирал стол синей губкой, то ROSIE может изменить её цвет на красный или даже нарисовать на месте губки фейковое изображение тряпки.
Помимо того, что этот метод позволяет научить RT-1 оперировать предметами, которых робот никогда не «видел» в реальной жизни, а лишь «воображал», он также делает его более устойчивым к визуальным отвлекающим факторам (появлению новых фоновых объектов, сгенерированных ИИ).
Например, ROSIE способен «воображать» бутылки с водой, овощи или коробки, якобы, находящиеся на столе (в исходных видео этих предметов не было).
Для разных типов действий учёные провели оценку 243 примеров, дополненных «галлюцинациями» ИИ. Метод ROSIE оказался способен значительно улучшить обобщение модели на новые задачи, а также её устойчивость к отвлекающим факторам. ROSIE превзошёл исходный вариант обучения RT-1 в некоторых особо сложных задачах сразу на 75%.
Роботы учатся на фейковых видео и обретают внутренний голос
Учёные из Google Brain, MIT и Альбертского университета предложили метод, позволяющий полностью избавиться от сбора реальных данных для обучения роботов. Действительно, почему бы не сгенерировать все тренировочные видеоролики с помощью ИИ?
Представленная в январе 2023 года модель под названием Universal Policy (UniPi) использует для управления роботизированным манипулятором связку из предварительно обученной языковой нейросети T5-XXL (4,6 миллиарда параметров) и генеративного ИИ, способного создавать видеокадры по текстовому описанию.
UniPi использует изображения в качестве универсального интерфейса, тексты — в качестве спецификаторов задач, а также модуль планирования, не зависящий от типа выполняемых действий.
Общий алгоритм выглядит так:
- Нейросеть получает на вход фотографию исходного положения манипулятора и окружающей обстановки.
- Также на вход подаётся сформулированное человеком текстовое задание.
- Используя фотографию как первый кадр генерируемого видеоролика, нейросеть создаёт следующие кадры, на которых «воображает», как должны выглядеть движения манипулятора при выполнении задания.
- Каждый кадр сгенерированного видео превращается в набор команд для настоящего манипулятора.
- Следуя полученному набору команд, робот выполняет в реальности действия, показанные на фейковом видео.
Это как если бы человек мог научиться мыть посуду, глядя на исходную кучу грязных тарелок в мойке и пошагово воображая процесс мытья каждой из них.
На сайте проекта учёные показали примеры того, как робот под управлением UniPi решает различные задачи: переставляет кубики, вытирает посуду губкой, кладёт ложки в лоток, поворачивает кран, переносит фрукты и овощи, подаёт бутылку с моющим средством и так далее.
Более того, теперь роботы, как и люди, смогут учиться не только на фейковых, но и на настоящих видеокадрах, размещённых в интернете. Благодаря UniPi роботу, чтобы научиться чему-либо, будет достаточно просто посмотреть соответствующий гайд на YouTube.

Изображение: universal-policy.github.io (перевод Skillbox Media)
Но даже этих удивительных способностей роботов исследователям оказалось недостаточно. Чтобы ни у кого не оставалось сомнений, неугомонные учёные из Google добавили механическим помощникам Everyday Robot возможность вести «внутренний монолог». Да, теперь андроиды могут разговаривать не только с людьми, но и сами с собой!
Система под названием Inner Monologue позволяет роботу вести беседу со встроенной языковой моделью для того, чтобы определять успешность своих действий, а также корректировать план работы в случае возникновения непредвиденных помех.
Авторы различают три вида внутренних разговоров, происходящих в рамках Inner Monologue: пассивное описание обстановки, активное описание обстановки и обнаружение успеха. Пассивное описание даёт ИИ выраженное словами представление, например, о результатах распознавания объектов. Робот как бы говорит сам себе: «Вот я вижу перед собой стол, на нём лежат яблоко, шоколадка и пакетик чипсов».
Активное описание подразумевает, что ИИ будет задавать вопросы, относящиеся к окружающей обстановке. Например, спросит: «Что следует взять — яблоко, шоколад или чипсы?» Отвечать на эти вопросы может как встроенная в робота LLM, так и человек-хозяин.
Обнаружение успеха отвечает за то, чтобы робот мог понять, когда следует остановиться, а когда — продолжать выполнение задачи. ИИ робота время от времени спрашивает у самого себя: «Достиг ли я результата?» И даёт ответ на этот вопрос.
В одном из тестовых примеров исследователь попросил робота принести ему газировку. Когда машина обнаружила банку колы и попыталась схватить её, человек незаметно убрал напиток со стола. Робот в недоумении пообщался сам с собой и с человеком, задав уточняющие вопросы, оценил изменившуюся обстановку и скорректировал план действий. В результате механический помощник нашёл другую банку с напитком и подал её.
«Мы с удивлением обнаружили, что „Внутренний монолог“, получив информацию об изменении окружающей обстановки, рассуждает и действует вполне разумно, выходя далеко за рамки изначальных текстовых запросов… Вместо того чтобы бездумно выполнять инструкции человека, он пытается самостоятельно решить проблему, предлагая альтернативные цели, к которым можно следовать, когда предыдущая становится невыполнимой».
Исследователи из Google,
авторы работы Inner Monologue: Embodied Reasoning through Planning with Language Models (цитата: innermonologue.github.io)

Кадр: фильм «Терминатор» / Orion Pictures
Апокалипсис отменяется?
Пока учёные совершенствовали искусственный интеллект роботов, наделяя их новыми всё более изощрёнными способностями, Google внезапно объявил о закрытии своего робототехнического подразделения Everyday Robots.
Команда, создавшая десятки прорывных технологий, попала «под нож» в феврале 2023 года в рамках кампании Google по сокращению расходов, предполагающей увольнение 12 тысяч сотрудников и ликвидацию отделов, не приносящих прибыль. Не иначе, кто-то из будущего решил вмешаться в нашу реальность и вызвать экономический кризис, чтобы остановить развитие роботов.
«Очень жаль, что нас закрыли. Мы только начали понимать, что роботы могут выполнять важную работу. Не думаю, что это признак отсутствия прогресса. При правильном подходе через пять лет мы могли бы создать значимый продукт».
Бывший сотрудник Everyday Robots (цитата: wired.com)
Одновременно с этим Илон Маск, Стив Возняк и ещё более тысячи специалистов подписали открытое письмо с требованием приостановить разработку продвинутого ИИ хотя бы на полгода. «Правительства должны вмешаться и ввести мораторий», — говорится в письме.
«Мы должны спросить себя: нужно ли автоматизировать все рабочие места? Должны ли мы развивать устройства с ИИ, которые в конечном итоге могут превзойти нас численностью, перехитрить и заменить? Стоит ли так рисковать нашей цивилизации? Подобные решения не должны делегироваться техническим лидерам, которых никто не избирал. Мощные системы ИИ следует разрабатывать только после того, как мы будем уверены, что их эффект будет положительным, а риски — управляемыми».
Из открытого письма Pause Giant AI Experiments: An Open Letter (цитата: futureoflife.org)




