Библиотека Scikit-learn: как создать свой первый ML‑проект
Изучаем возможности Python-библиотеки для machine learning и пишем модель классификации цветов с помощью Scikit-learn.


Python-библиотеку Scikit-learn используют в data science для создания моделей машинного обучения. С помощью «Сайкит-лёрн» (именно так произносится название этой либы) автомобили ездят по городу на автопилоте, а ваш почтовый ящик фильтрует спам.
В этой статье мы собрали всё необходимое для старта работы с этой библиотекой: базовые теоретические понятия, примеры кода для основных алгоритмов и теоретические основы. Так что запускайте Google Colab или другую IDE и присоединяйтесь к нам.
Что такое Scikit-learn
Scikit-learn — популярная Python-библиотека для машинного обучения, которая была разработана в рамках проекта Google Summer of Code в 2007 году. Её цель — взаимодействие с числовыми и научными библиотеками Python: NumPy и SciPy. В библиотеке представлены различные алгоритмы классификации, регрессии и кластеризации, включая support vector machines, random forests, gradient boosting, k-means и DBSCAN.
Scikit-learn быстро набрала популярность и сегодня является одним из лучших вариантов для ML-разработки, что подтверждает статистика её использования в Kaggle-соревнованиях:
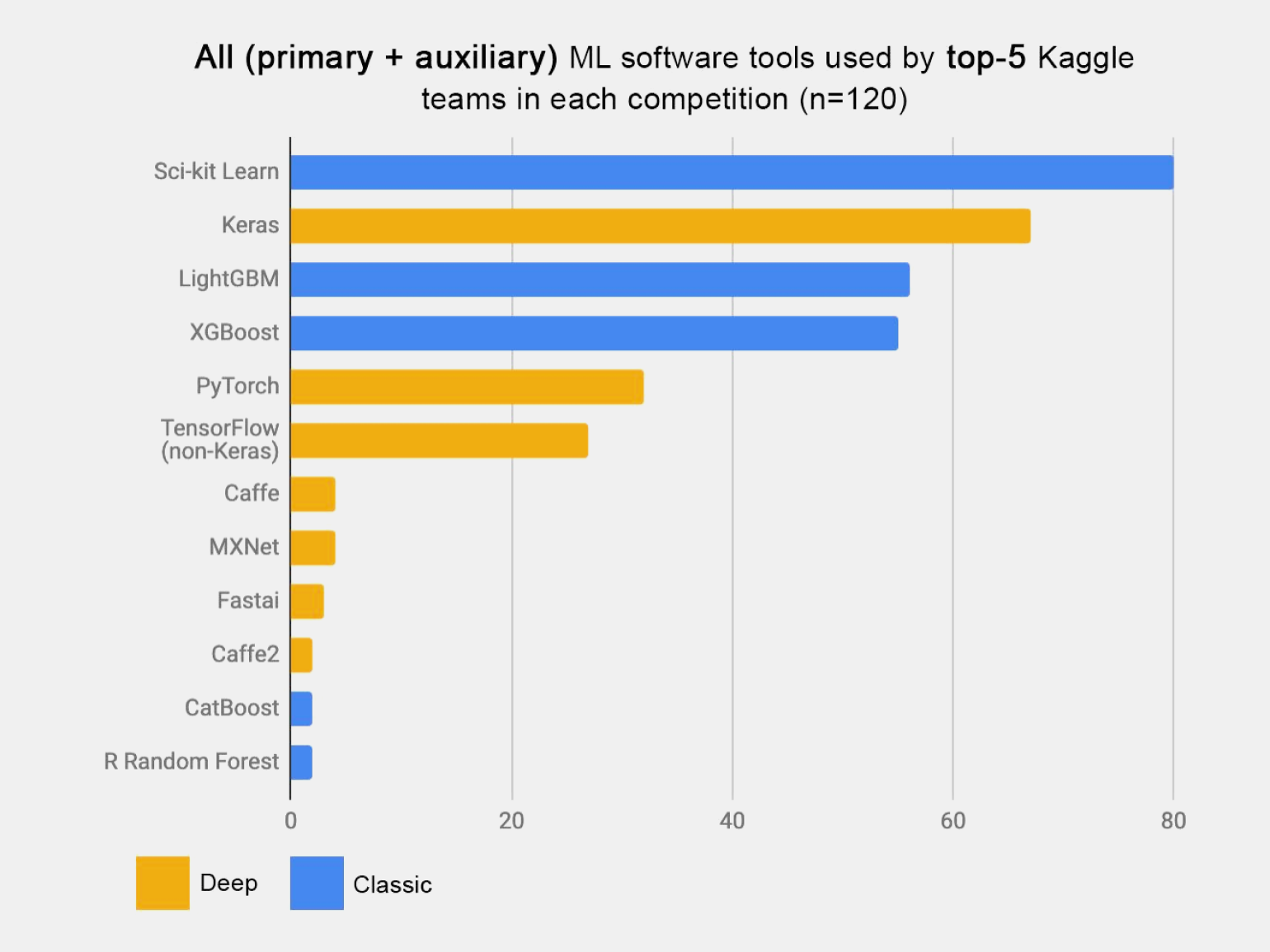
Скриншот: Kaggle / Skillbox Media
Почему она так популярна:
- большое комьюнити и подробная документация, облегчающая обучение и использование библиотеки на практике;
- самостоятельность для машинного обучения за счёт возможности работать с основными алгоритмами ML: регрессия, кластеризация, random forest и другими;
- лёгкая интеграция с другими библиотеками, используемыми в машинном обучении и data science в целом: Matplotlib и Plotly для построения графиков, NumPy для векторизации массивов, Pandas DataFrame, SciPy и другими;
- open-source-код и возможность использования в коммерческих проектах.
Как установить Scikit-learn
В машинном обучении для работы с кодом обычно используются специальные инструменты: Google Colab или Jupyter Notebook. Это IDE, специально созданные для работы с данными, позволяющие не писать отдельные приложения, а обрабатывать информацию пошагово.
В этой статье мы будем использовать Google Colab — облачное решение для работы с данными. Оно работает в браузере и доступно хоть на ноутбуке, хоть на планшете и даже на смартфоне.
При работе с Google Colab или Jupyter Notebook устанавливать Python и Scikit-learn не понадобится — язык программирования и библиотека уже доступны «из коробки». Но если вы решили писать код в другой IDE, например в Visual Studio Code, то сначала установите Python, а затем Scikit-learn через терминал:
pip install -U scikit-learn
Установка на Windows, macOS и Linux происходит одинаково. Если вы столкнулись с ошибками в процессе установки, то почитайте документацию к библиотеке.
Библиотека Scikit-learn умеет работать с самыми разными данными: массивы numpy.array (формат библиотеки NymPy), матрицы SciPy Sparse (из библиотеки SciPy) и классические DataFrame из библиотеки Pandas. Можно создавать наборы данных с нуля или импортировать уже готовые в CSV, JSON и других стандартных форматах.
Но, прежде чем начать работать с данными, нам нужно их откуда-то получить: воспользоваться готовым набором данных, скачать их из открытых репозиториев, взять данные из систем аналитики вашей компании и так далее. В этой статье мы воспользуемся датасетом, который уже установлен в библиотеку Scikit-learn.
Датасеты Scikit-learn
Библиотека Scikit-learn предлагает несколько готовых датасетов, которые можно использовать в процессе обучения. Всего их шесть:
| load_iris | Содержит информацию о 150 образцах ирисов с несколькими признаками | Подходит для задач классификации |
| load_diabetes | Данные 442 пациентов с сахарным диабетом и 10 признаками, связанными со здоровьем | Подходит для задач регрессии |
| load_digits | Набор из 1800 изображений рукописных букв | Подходит для задач классификации |
| load_linnerud | Набор данных о результатах выполнения 3 физических упражнений 20 людьми в динамике | Подходит для задач регрессии |
| load_wine | Набор данных о результатах химического анализа разных видов вина | Подходит для задач классификации |
| load_breast_cancer | Набор данных о гистологических параметрах опухолей молочной железы | Подходит для задач классификации |
Для загрузки стандартных датасетов существует модуль sklearn.datasets. Давайте импортируем его и загрузим данные из набора данных load_iris:
from sklearn import datasets
data = datasets.load_iris()Если сейчас вывести содержимое объекта data на экран, то мы увидим что-то непонятное:

Датасеты хранятся в Scikit-learn не в привычных для аналитиков данных DataFrame, а в Bunch — специальном словаре с расширением .data. В нашем случае это массивы setosa, versicolor, virginica и другие.
Для удобства работы можно импортировать Pandas и сохранить информацию в табличном виде:
import pandas as pd
# Создадим DataFrame.
df = pd.DataFrame(data.data, columns=data.feature_names)
# Добавим столбец "target" и заполним его данными.
df['target'] = data.target
# Выведем на экран первые пять строк.
df.head()Теперь данные отображаются в удобном виде и с ними можно работать:
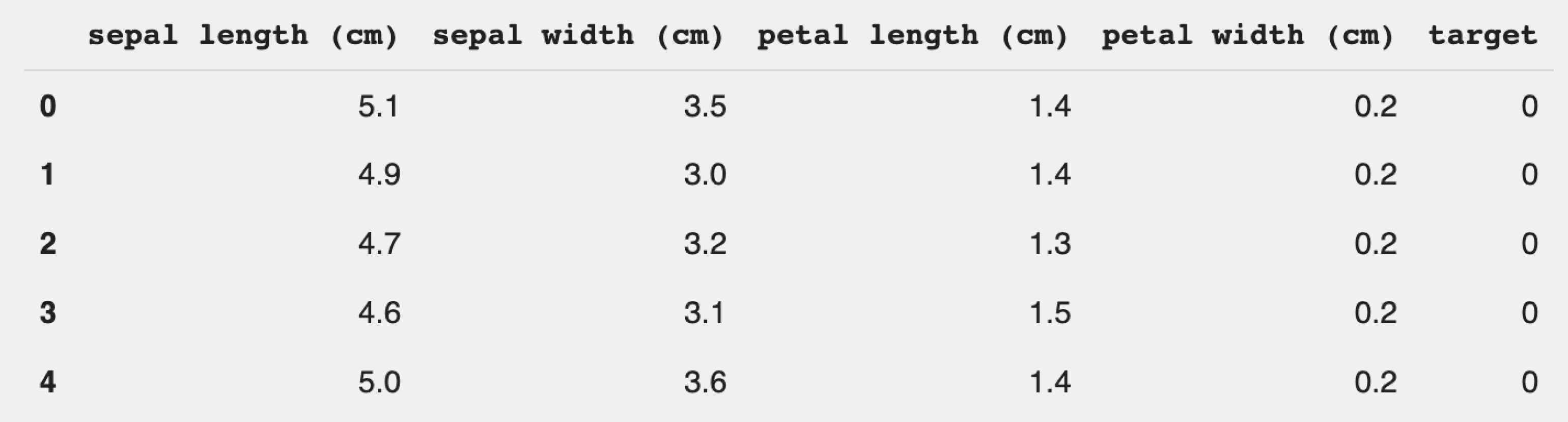
Используем этот датасет для классической задачи машинного обучения — классификации. Для начала разберёмся в самих данных и поймём, что содержится в этом наборе данных.
Что содержится в датасете с ирисами?
Данные включают в себя информацию о 150 образцах трёх видов ирисов. В первом столбце представлена длина чашелистика, во втором — ширина чашелистика, в третьем — длина лепестка, в четвёртом — ширина лепестка. В зависимости от этих значений мы можем разделить цветки на три разных вида: setosa, versicolor, virginica, различающиеся шириной и высотой лепестков и чашелистиков.
Этот набор данных отлично подходит для классических задач контролируемого обучения, то есть обучения на размеченных данных. Входными переменными являются длина и ширина чашелистика и длина и ширина лепестка; каждая строка представляет собой один экземпляр или наблюдение. Выходной переменной является Iris setosa, Iris versicolor или Iris virginica, то есть название вида.
Посмотрим ещё раз на наш датасет:
В столбце target указан вид, к которому относится цветок: setosa (0), versicolor (1), virginica (2). Но работать с ним неудобно, так как нам проще работать с названиями видов. Поэтому добавим столбец с указанием вида растения:
import pandas as pd
species = []
for i in range(len(df['target'])):
if df['target'][i] == 0:
species.append("setosa")
elif df['target'][i] == 1:
species.append('versicolor')
else:
species.append('virginica')
df['species'] = speciesТеперь выведем датафрейм и посмотрим, всё ли получилось:
df.head()
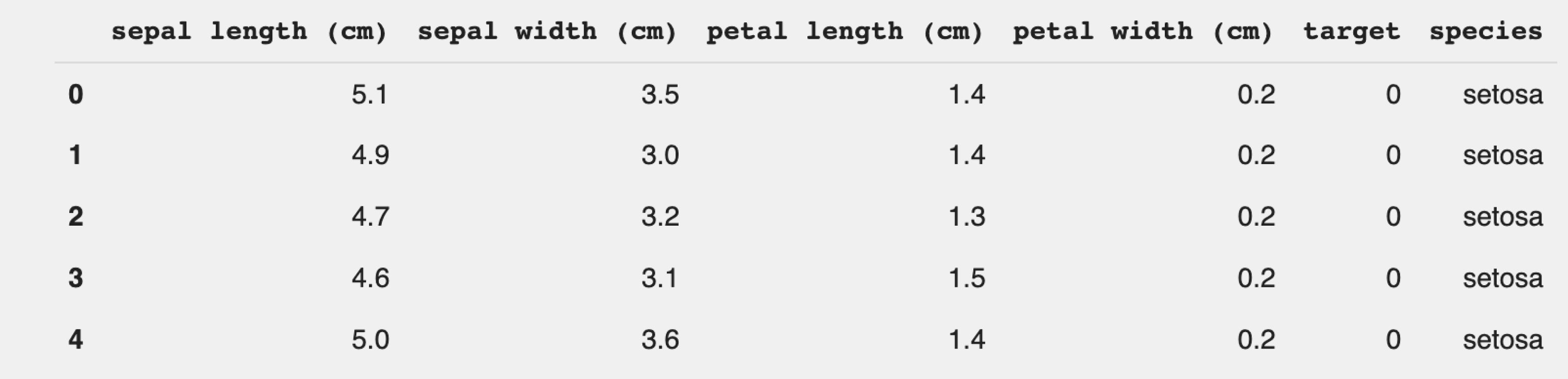
Отлично. Всё получилось.
Классификация в машинном обучении
Классификация используется для разделения переменных или каких-то объектов по категориям. Как правило, это всегда обучение с учителем, то есть на выходе должны быть размеченные данные с признаками и сами категории, которые будут использоваться для разделения. Один из примеров работы классификации — спам-фильтры в почтовом ящике.
Посмотрим, как классификация работает на практике, — приготовьтесь, часть терминологии из сферы работы с данными довольно сложна для понимания, и мы предполагаем, что с ней вы уже немного знакомы.
Шаг 1. Смотрим на распределение данных
Прежде чем приступать к написанию алгоритма классификации, посмотрим на то, как сейчас распределены образцы по своим параметрам — воспользуемся библиотекой Matplotlib и построим график распределения образцов по размерам чашелистика:
import matplotlib.pyplot as plt
setosa = df[df.species == 'setosa']
versicolor = df[df.species == 'versicolor']
virginica = df[df.species == 'virginica']
fig, ax = plt.subplots()
fig.set_size_inches(13, 7) # Задаём размеры графика.
# Подписываем и отрисовываем точки.
ax.scatter(setosa['petal length (cm)'], setosa['petal width (cm)'], label="Setosa", facecolor="blue")
ax.scatter(versicolor['petal length (cm)'], versicolor['petal width
(cm)'], label="Versicolor", facecolor="green")
ax.scatter(virginica['petal length (cm)'], virginica['petal width (cm)'], label="Virginica", facecolor="red")
ax.set_xlabel("длина чашелистика (см)")
ax.set_ylabel("ширина чашелистика (см)")
ax.grid()
ax.set_title("Чашелистики у ирисов")
ax.legend()
Смотрим на результат:
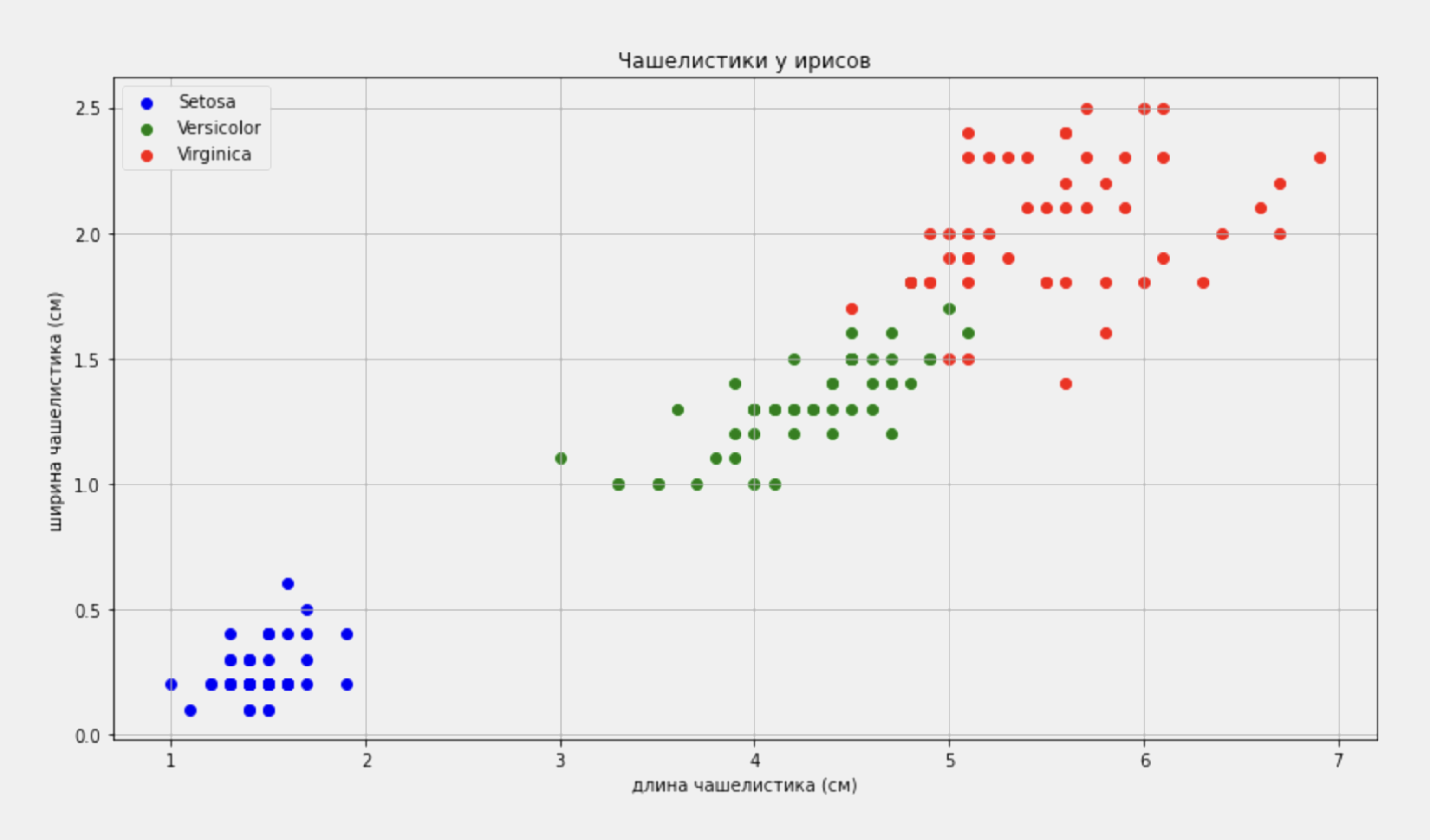
Хорошо заметно, что виды отличаются друг от друга размером чашелистиков. Например, у ирисов virginica они крупнее, чем у ирисов versicolor и setosa. То есть эти характеристики можно использовать для различения видов между собой. Попробуем научить этому компьютер.
Шаг 2. Используем правильные модули для классификации
Нам не придётся писать алгоритм классификации с нуля. В библиотеке Scikit-learn есть множество готовых алгоритмов — надо только выбрать правильный.
В случае с ирисами воспользуемся логистической регрессией. Прежде чем приступить к этому, разделим датасет на два набора данных: тренировочный, который будем использовать для обучения алгоритма, и тестовый — для проверки точности его работы. Для этого воспользуемся стандартным методом train_test_split.
Важно, что логистическая регрессия не работает с датафреймами Pandas. Поэтому дополнительно импортируем NumPy и преобразуем датафрейм в NumPy-массивы.
from sklearn.model_selection import train_test_split
# Удалим из датасета два столбца, которые не нужны нам для обучения.
X = df.drop(['target','species'], axis=1)
# Переведём значения длины и ширины чашелистика в массив NumPy.
X = X.to_numpy()[:, (2,3)]
y = df['target']
# Разделим данные на тестовую и тренировочную выборку.
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.5, random_state=42)Отлично — теперь у нас есть два отдельных набора данных для обучения и тренировки. Параметр test_size задаёт размер тестовой выборки в процентах, а random_state делает разбивку не случайной. Если его не указать, то при каждом перезапуске кода мы будем получать различные значения в тренировочной и тестовой выборке.
Остаётся импортировать алгоритм логистической регрессии и обучить его. Сделать это можно с помощью трёх строк:
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train) # Обучаем наш алгоритм на тренировочной выборке.Запускаем! Отлично, теперь можно прогнать через наш алгоритм обе выборки — тестовую и тренировочную. В зависимости от значений переменных логистическая регрессия присвоит образцу значение 0, 1 или 2, то есть конкретный вид ириса.
training_prediction = log_reg.predict(X_train)
training_prediction
Результат:

Мы видим, что на выходе получили массив, содержащий значения от 0 до 2, которые соответствуют видам ирисов. Повторим для тестовой выборки:
test_prediction = log_reg.predict(X_test)
test_prediction
Шаг 3. Измеряем производительность алгоритма
Показатели производительности используются для оценки эффективности классификаторов. Для задач классификации существуют три основные метрики оценки модели: точность, полнота и матрица ошибок.
Точность (precision) — это соотношение объектов, названных классификатором положительными и при этом действительно являющихся положительными, а полнота (recall) отвечает на вопрос, какую долю положительных объектов действительно нашёл алгоритм. Именно две эти метрики используем для оценки нашей модели.
Для проверки производительности алгоритма в Scikit-learn существует специальный метод metrics, рассчитывающий основные метрики:
from sklearn import metrics
print("Precision, Recall в тренировочной выборке\n")
# Считаем Recall.
print(metrics.classification_report(y_train, training_prediction, digits=3))Результат:
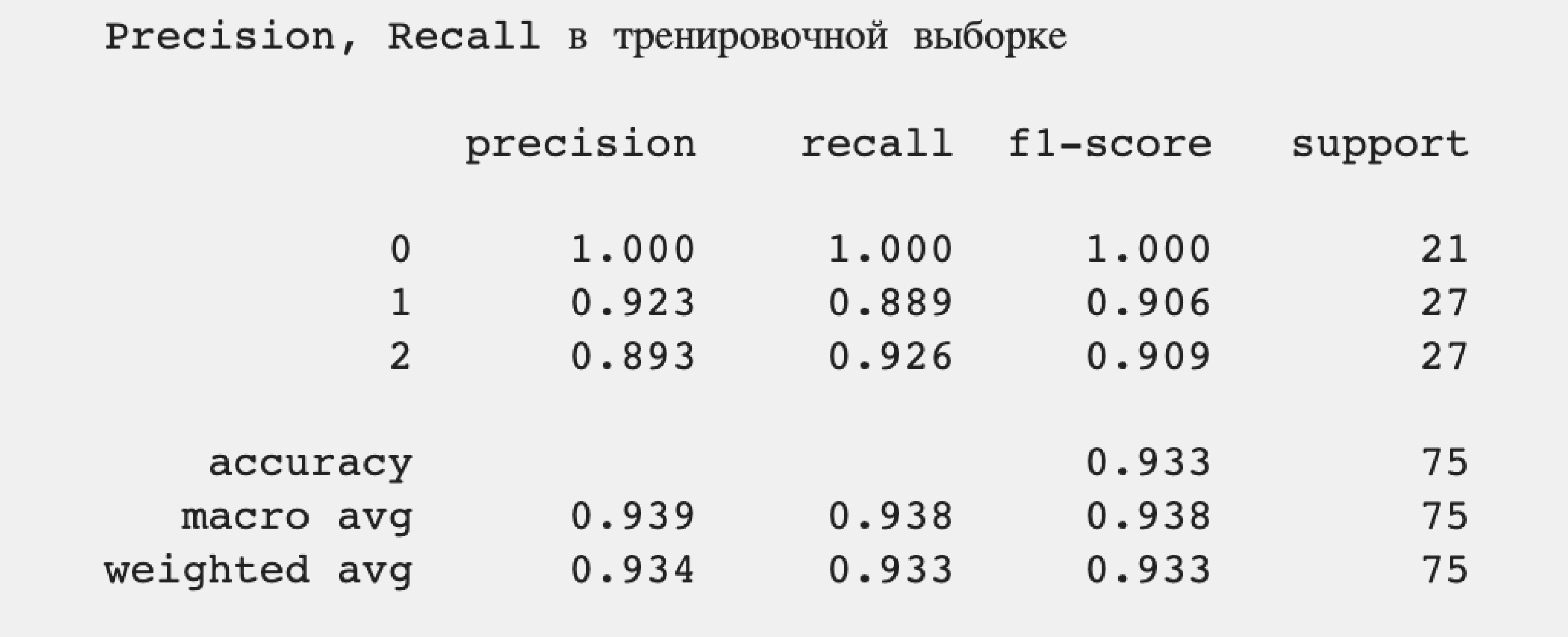
Что мы видим?
Точность (precision) в среднем равна 0,939, то есть 93,9%, что довольно хорошо для небольшого количества образцов. Полнота (recall) также равна 0,938, то есть алгоритм в 93,8% случаев правильно понимает принадлежность конкретного образца, пропуская их в оставшихся 6,2% случаев.
Проверим теперь алгоритм на тестовой выборке:
print("Precision, Recall в тестовой выборке")
# Считаем Recall.
print(metrics.classification_report(y_test, test_prediction, digits=3))Результат:
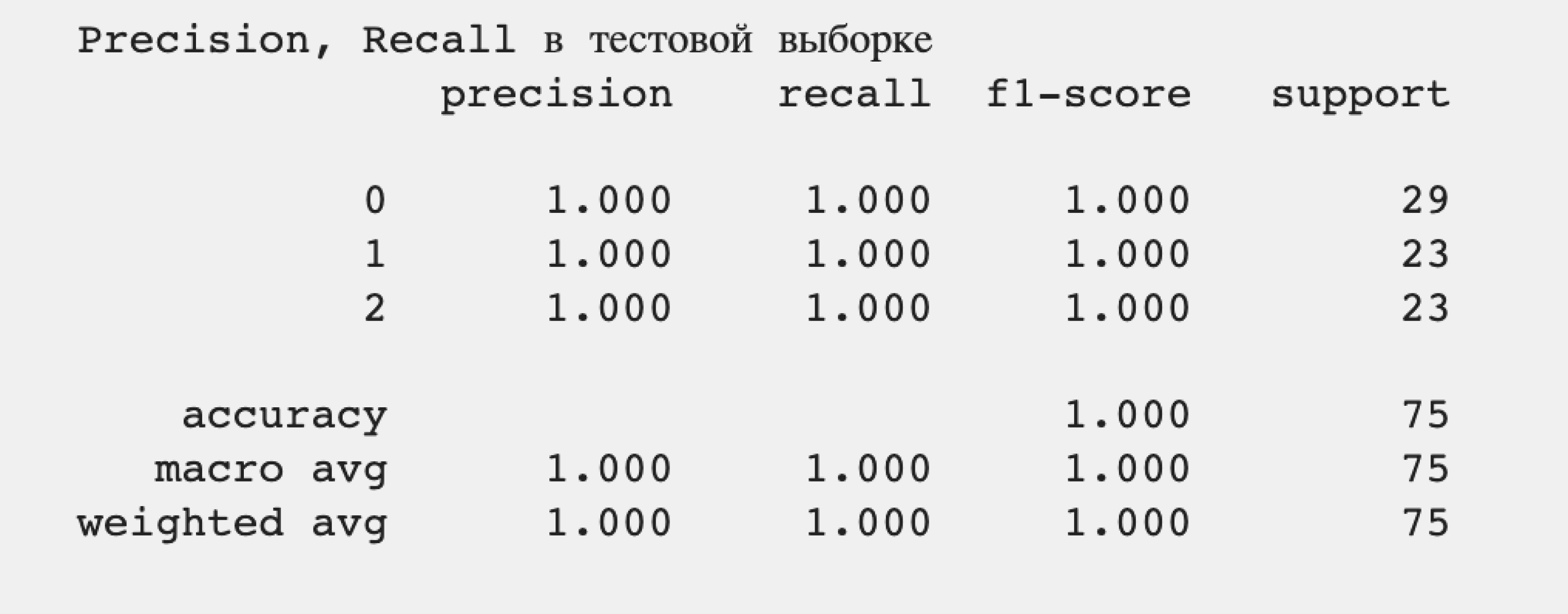
100% точность определения. Наша модель классификации правильно определяет все подвиды ирисов на основе длины и ширины чашелистиков, не допуская ложноположительных и ложноотрицательных результатов.
Что дальше?
Библиотека Scikit-learn имеет подробную официальную документацию, которая содержит подробную информацию об особенностях работы с ней и примеры кода для различных вариантов алгоритмов машинного обучения. Для глубокого погружения в работу с библиотекой лучше подойдут специализированные книги:
- «Прикладное машинное обучение с помощью Scikit-Learn, Keras и TensorFlow. Концепции, инструменты и техники для создания интеллектуальных систем» Жерона Орельена;
- Learning scikit-learn. Machine Learning in Python Рауля Гарреты;
- Scikit-learn Cookbook Трента Хаука.

Курс с помощью в трудоустройстве

Профессия Data scientist + ИИ
- Реальные задачи от «СберАвтоподписки» и «СберМаркета»
- 8 сильных проектов в портфолио
- Спикеры из VK, ВТБ, «Сбера», Wildberries





