База данных MS SQL Server: что это, зачем нужна, как появилась и чем хороша
Изучаем, что под капотом у классической СУБД от Microsoft, постигаем азы реляционности и закрепляем нюансы хранения данных в вебе.


MS SQL Server появилась ещё в конце 1980-х и с тех пор держится в топе самых популярных СУБД в мире. Она быстрая, удобная и подходит почти для всего: от небольших сайтов до высоконагруженных веб-приложений. Да и вообще, база данных от Microsoft — должна же быть хорошая? Будем разбираться.
Это четвёртая статья в цикле о СУБД. Ранее мы рассказывали, что это такое, как они устроены, и даже разобрали пару известных решений — от Oracle и MongoDB. Сегодня на очереди MS SQL Server.
Из этой статьи вы узнаете:
- БД и СУБД: в чём разница
- Что такое MS SQL Server
- Как Билл Гейтс базу данных создавал
- Как устроен язык запросов T-SQL
- Как работает SQL Server
- Ещё несколько фишек системы
- Выводы: кому и для чего нужен SQL Server
Коротко о базах данных и СУБД
Для начала — повторим основные моменты из предыдущих статей:
- Повсюду в интернете нас окружают данные: текст, картинки, посты, товары, нейронные арты с енотами, новые серии «Короля и Шута» и так далее. Чтобы как-то упорядочить весь этот хаос, придумали базы данных.
- Но сама по себе база — это просто способ организовать данные, и она мало что умеет: например, она может знать, что в магазине есть белые «найки», но не способна сама обновить остатки, если их кто-то купит.
- Чтобы проводить сложные манипуляции с данными, используют системы управления базами данных — СУБД.
- Они заточены на то, чтобы искать, добавлять и менять данные по запросу, защищать их от кражи и взлома. Это такая софтовая обёртка для данных, чтобы люди могли использовать их для своих нужд, не мешая друг другу.
- Можно сравнить СУБД со школьным библиотекарем Зинаидой, которая следит за состоянием книг, обновляет их когда нужно и выдаёт только приличным детям, а тем, кто рисует ручкой в учебниках, кричит в библиотеке и вообще задолжал кучу литературы, — не выдаёт.
А теперь перейдём непосредственно к детищу Microsoft.
Что такое MS SQL Server
MS SQL Server — это система управления реляционными базами данных, работающая по клиент-серверной модели. Прозвучало много новых слов — сейчас разберём по порядку, что это всё значит.
Реляционные базы — это такие базы, где все данные хранятся в виде таблиц, и эти таблицы связаны между собой: одна с другой, другая — с третьей и так далее. Вот упрощённый пример такой базы данных в онлайн-кинотеатре — у нас есть три таблицы, которые отвечают за фильмы, пользователей и отзывы:
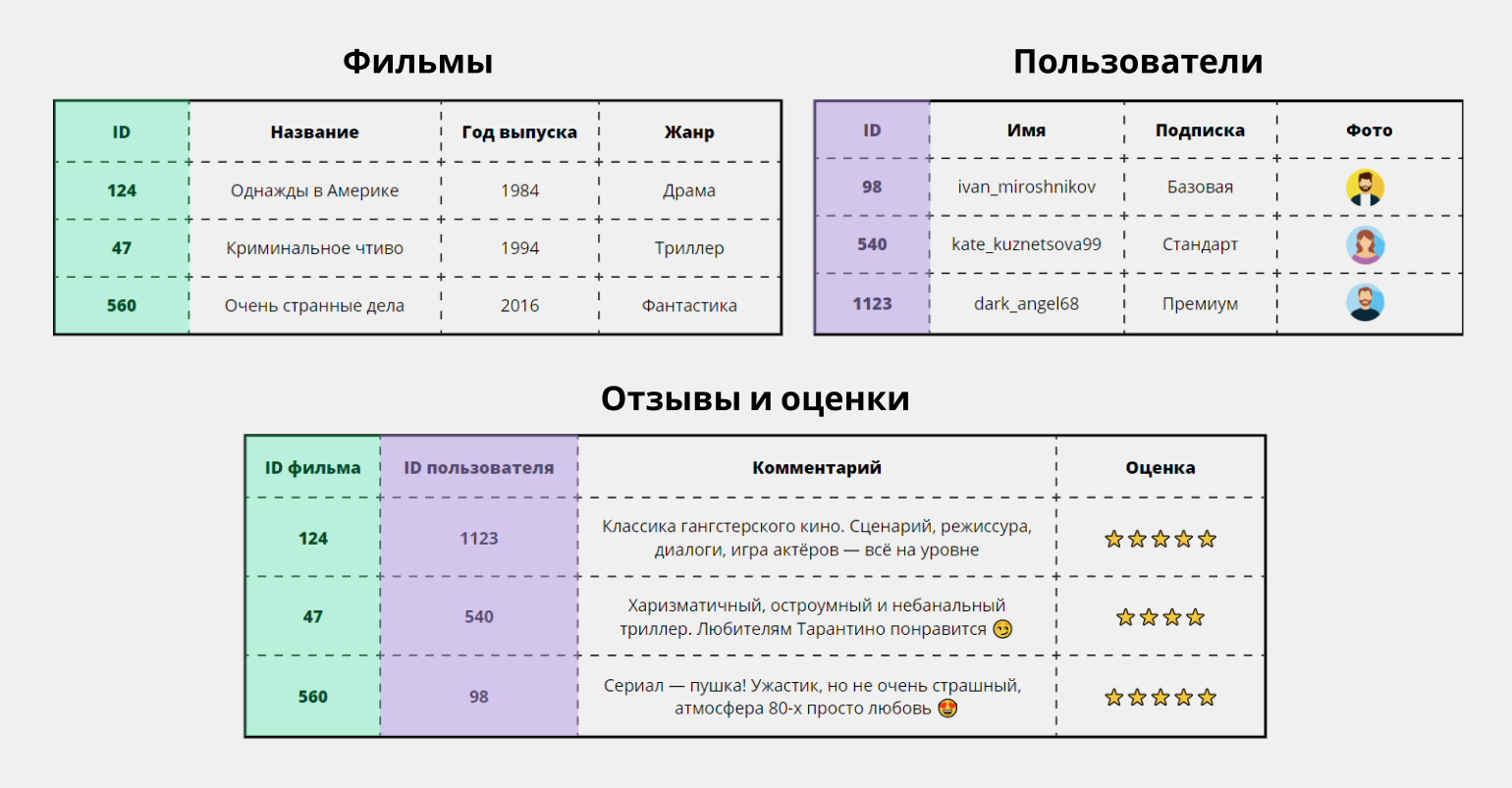
Реляционный подход хорош тем, что позволяет СУБД избежать массы лишней работы. Например, если какой-то пользователь решит обновить, скажем, фото или никнейм, системе будет достаточно поменять это только в одной таблице — «Пользователи». А остальные базы сами подтянут эти данные по запросу.
Читайте также:
«Клиент-серверная» означает, что вся логика работы с данными вынесена на сервер, а пользователи подключаются к нему через приложения-клиенты. Идея в том, что нам не надо хранить полную версию базы данных у себя на компьютере — достаточно просто иметь хороший интернет.
Более того, экосистему SQL Server можно развернуть и в облаке: в этом случае обслуживание базы данных берут на себя дата-центры Microsoft, а вы можете сосредоточиться на разработке клиентских приложений. Версия SQL Server, которая позволяет так делать, называется Azure SQL.
? Так как SQL Server — это СУБД от Microsoft, она заточена в основном на работу с Windows, хотя частично поддерживает и Linux. Частично — потому что в версии для этой системы нет некоторых важных функций. Поэтому, если ищете СУБД для Linux-машины, лучше дополнительно поизучать конкурентов.
Как Билл Гейтс базу данных создавал
К началу 1980-х реляционные базы уже вовсю правили бал в энтерпрайзе. На этом рынке выросло сразу много крупных игроков, включая Oracle, Sybase, IBM и Ashton-Tate. И, конечно, Microsoft не могла не подвизаться на этой ниве:
- с одной стороны, потому, что тогда, как и сейчас, пылесосила рынок в поиске перспективных технологий (привет, Bing AI);
- с другой — потому, что делала совместную с IBM операционку OS/2, которая нуждалась во встроенной базе данных.
Основная задача была в том, чтобы создать СУБД, которая может запускаться на маломощных домашних и рабочих станциях — что неудивительно, ведь «майки» на то и «майки», чтобы пилить софт для компактных машин. В то время же большинство СУБД работали на «тучных» серваках и мейнфреймах.
Чтобы реализовать такой подход, Microsoft выбрали набирающую тогда популярность клиент-серверную технологию. Идея в том, чтобы перенести все сложные вычисления на сервер, а пользователям дать доступ к «плодам» этих вычислений через клиентские приложения, запущенные на рабочих станциях.
Тут важно отметить, что сама Microsoft ещё не умела делать такие системы, поэтому обратилась за помощью к компании Sybase, автору платформы DataServer, код которой и лёг в основу первых версий SQL Server. Ещё один партнёр по разработке — компания Ashton-Tate — помог Microsoft по части дистрибуции и создания клиентских приложений.
Сохранился даже рекламный ролик из махровых 1980-х, где Билл Гейтс вместе с главой Ashton-Tate Эдом Эсбером рассуждает о возможностях SQL Server:
Эд Эсбер: Главное преимущество SQL Server в том, что она позволяет пользователям dBase IV и обмениваться данными по сети.
Билл Гейтс: Извини, Эд, но ты не совсем прав. Главная фишка SQL Server в том, что она позволяет пользователям Excel анализировать и визуализировать данные рабочей группы.
Эд Эсбер: О чём ты говоришь, Билл? SQL Server отлично работает с dBase IV! Вот, смотри.
Билл Гейтс: О, это же мои данные!
Эд Эсбер: Это мои данные!
Вместе: Это одни и те же данные — в одно и то же время!
Сейчас эта реклама выглядит наивно, но она демонстрирует прорывные фишки в обработке данных для своего времени: например, возможность работать с одной и той же базой с разных ПК. А ещё — совместно визуализировать «дату», создавая на её основе красочные графики. И это в 1988 году!
То есть уже тогда юзеры Microsoft могли работать с разными офисными приложениями, системами учёта, банковскими программами в режиме реального времени — SQL Server делала так, чтобы запросы не мешали друг другу, а данные не перезаписывались и ложились на диск по очереди.
Скриншот: SQL Server
Стоит отметить, что совместный бизнес «майков» с Ashton-Tate и Sybase закончился ещё в конце 1990-х. Первая обанкротилась, а вторая вышла из предприятия и стала пилить собственный форк SQL Server под названием Adaptive Server Enterprise. Ну а сама Microsoft сосредоточилась на выпуске SQL Server под Windows — и по сей день она многими воспринимается именно как часть «оконной» экосистемы.
Язык запросов Transact-SQL
С «сервером» вроде разобрались, теперь поговорим об SQL. Многие из вас знают, что это специальный язык запросов к базе данных. И что он умеет делать с данными по запросу что угодно: извлекать, загружать, группировать, настраивать права доступа и так далее.
Но мало кто говорит о Transact-SQL — диалекте SQL, который Microsoft и Sybase создали специально для SQL Server. Главная его фишка в том, что это не только язык запросов, но и полноценный язык программирования — то есть в нём есть переменные, циклы, условные конструкции if-else и другие атрибуты.

С помощью T-SQL можно создавать небольшие программки для обработки данных и запускать их прямо на сервере — называются хранимые процедуры. Это удобно, если у вас есть набор повторяющихся действий к базе и вам нужно его автоматизировать — например, добавление товара в корзину.
-- Хранимая процедура для добавления товара в корзину
CREATE PROCEDURE AddToCart
@UserID int,
@ProductID int,
@Quantity int
AS
BEGIN
-- Добавляем новый товар в корзину или обновляем количество, если он уже есть
MERGE INTO Cart AS C
USING (SELECT @UserID AS UserID, @ProductID AS ProductID) AS P
ON C.UserID = P.UserID AND C.ProductID = P.ProductID
WHEN MATCHED THEN UPDATE SET C.Quantity = C.Quantity + @Quantity
WHEN NOT MATCHED THEN INSERT (UserID, ProductID, Quantity) VALUES (P.UserID, P.ProductID, @Quantity);
END;Смотрите, в примере выше мы создали хранимую процедуру AddToCart и добавили в неё универсальный запрос для добавления товара в корзину. Теперь, вместо того чтобы выполнять запрос для каждого товара и покупателя, серверу нужно будет всего лишь вызвать эту функцию:
-- Вызов хранимой процедуры для добавления товара с ID = 1 в корзину пользователя с ID = 101
EXEC AddToCart @UserID = 101, @ProductID = 1, @Quantity = 2;
Как работает SQL Server
Под капотом у SQL Server лежит движок Database Engine — это ядро СУБД, которое и отвечает за всю работу с данными. Именно движок принимает SQL-запросы от пользователей и распределяет их между ресурсами сервера. Технически он выглядит как служба в операционной системе — sqlservr.exe.
А ещё на один сервер можно установить несколько экземпляров SQL Server, и тогда движков тоже будет несколько — и каждый будет работать с каким-то своим набором баз данных. Например, на сервере Skillbox один движок может заниматься базой статей в Skillbox Media, а другой — онлайн-курсами.
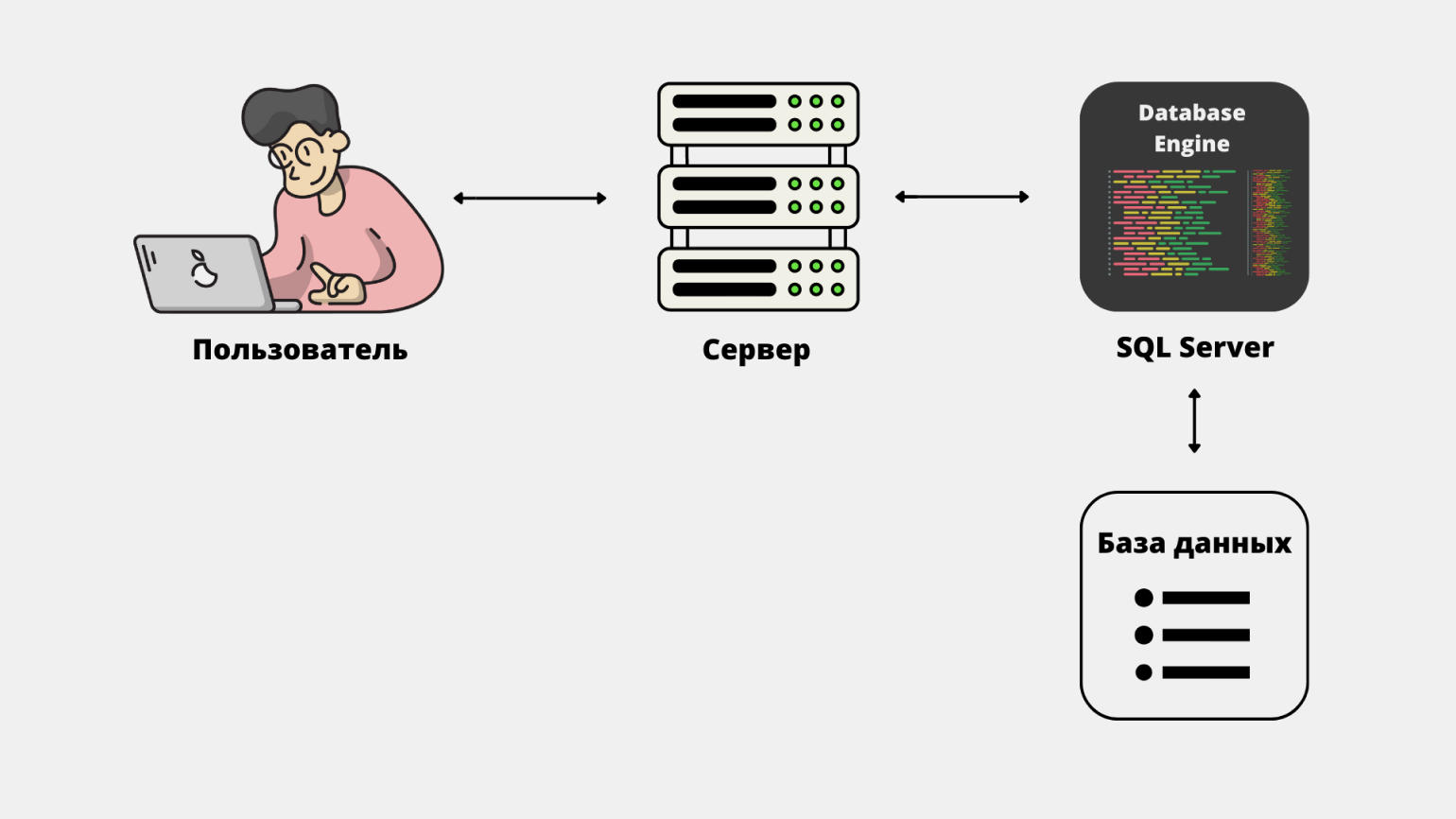
Иллюстрация: Skillbox Media
Теперь заберёмся чуть поглубже и посмотрим, как именно SQL Server работает с клиентскими запросами. Допустим, мы зашли на маркетплейс, чтобы купить футболку — но не простую, а поло 48 размера бренда «Школьный вальс». Выставляем фильтры, нажимаем «Применить», а дальше — следим за руками:
- Браузер превращает наши фильтры в запрос и отправляет на сервер.
- Там наш запрос встречает движок SQL Server, создаёт на его основе новую задачу (task) и переводит её в режим ожидания.
- Далее задачу подхватывает рабочий поток (worker), анализирует содержимое запроса и составляет план: как его выполнить максимально быстро и не затратно по ресурсам.
- Потом в игру вступает планировщик задач (task scheduler) — он следит за тем, чтобы рабочие потоки эффективно расходовали ресурсы процессора и не мешали друг другу.
- Только на этом этапе запрос начинает по-настоящему выполняться — операторы SQL работают с базой данных и извлекают из неё нужные данные.
- Сервер пуляет данные обратно в браузер, и вот мы видим список нужных футболок — прошла всего секунда, а сколько всего случилось :)
Конечно, это очень упрощённая схема — она не учитывает, например, обработку HTTP-запросов на веб-сервере и некоторые аспекты архитектуры SQL Server. Если хотите лучше в этом разобраться, можете почитать хорошую статью по этой теме на «Хабре» или документацию по SQL Server от Microsoft.
Ещё несколько киллер-фич SQL Server
Разберём несколько приятных фишек, за которые SQL Server ценят компании и разработчики:
Отказоустойчивость. Например, в SQL Server можно создавать кластеры серверов, которые будут работать с одним экземпляром СУБД. Если какая-то машина вдруг выйдет из строя, её работу сразу перехватит другая, и всё это случится абсолютно бесшовно и незаметно для пользователя. Эта технология называется кластеризацией.
А ещё SQL Server постоянно создаёт контрольные точки, из которых можно восстановить базу данных в случае сбоя или повреждения данных.
Совместимость с Microsoft. Естественно, SQL Server тесно интегрирован в экосистему «оконных» приложений — например, с помощью расширения mssql можно управлять базами данных из IDE Visual Studio.
Машинное обучение. С помощью SQL Server можно обучать ML-модели прямо внутри базы данных. Для этого там есть специальная служба, которая умеет выполнять скрипты для работы с big data на Python и R. А если к этому делу подключить какой-нибудь TensorFlow, то там и до своего ChatGPT недалеко :)

Бизнес-аналитика. Можно делать интерактивные дашборды на основе данных с помощью встроенной службы отчётов, а можно выгрузить начинку базы данных в сторонний сервис — тот же майкрософтовский PowerBI.
Удобная студия управления. Считается, что SQL Server Management Studio — это одна из лучших сред разработки баз данных из существующих. Мы не будем спорить, просто добавим, что скоро про неё у нас выйдет отдельная статья.
Скриншот: Database by Doug / YouTube
Большое сообщество. SQL Server — вторая по популярности СУБД в мире, и в интернете по ней море учебных материалов, блогов и сообществ. Энтузиасты даже собрали все обучающие ресурсы в один большой гайд. Похожий, кстати, есть на «Хабре» — довольно старый, но с основами разобраться поможет.
Кому и для чего нужен SQL Server
SQL Server можно использовать в любых проектах, где нужно управлять данными: контентом на сайтах, отчётностью, ресурсами предприятия, зарплатами сотрудников, цепочками поставок, проектами, торговлей, документами — да в целом чем угодно.
Так как это продукт Microsoft, стоит он недёшево — около 4000 долларов в год за стандартную лицензию на два ядра. И это не считая затрат на поддержку обслуживание и серверную версию Windows, ибо только с ней SQL Server работает нормально — вариант для Linux сильно урезан по функциям.
Подводя итог, можно сказать, что SQL Server — это хороший вариант для больших или средних проектов с прицелом на рост в будущем. Во всех остальных случаях лучше присмотреться к open-source-решениям вроде PostgreSQL — для большинства задач их возможностей вполне хватит.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!


