Регулярные выражения в Python: синтаксис, полезные функции и задачи
Исчерпывающий гайд по работе с мощным инструментом для анализа и обработки строк.


Само словосочетание «регулярные выражения» звучит непонятно и выглядит страшно, но на самом деле ничего сложного в работе с ними нет. В этой статье мы познакомим вас с их логикой и основными принципами и научим разговаривать на языке шаблонов. В хорошем смысле слова.
Содержание:
- Что такое регулярные выражения
- Синтаксис регулярок
- Как ведётся поиск
- Квантификаторы и логическое ИЛИ при группировке
- Регулярные выражения в Python: модуль re и Match-объекты
- Жадный и ленивый пропуск
- Примеры и задачи
Что такое регулярные выражения
Представьте, что вы снова в школе, на уроке истории. Вам нужно решить итоговую контрольную работу по всем датам, которые проходили в четверти.
Но тут вас поджидает препятствие: все даты разбросаны по нескольким главам учебника по десятку страниц каждая. Читать полкниги в поисках нужных вам крупиц информации — такое себе удовольствие. Тем более когда каждая минута на счету.
К счастью, вы — человек неглупый (не зря же пошли в IT), тренированный и быстро соображающий. Поэтому моментально замечаете основные закономерности:
- даты обозначаются цифрами: арабскими, если это год и месяц, и римскими, если век;
- учебник — по истории позднего Средневековья и Нового времени, поэтому все даты, написанные арабскими цифрами, — четырёхсимвольные;
- после римских цифр всегда идёт слово «век».
Теперь у вас есть шаблон нужной информации. Остаётся лишь пролистать страницу за страницей и записать даты в смартфон (или себе на подкорку). Вуаля: пятёрка за четверть у вас в дневнике, а премия от родителей за отличную учёбу — в кармане.
По такому же принципу работают и регулярные выражения: они ведут поиск фрагментов текста по определённому шаблону. Если фрагмент совпадает с шаблоном — с ним можно работать.
Запишем логику поиска исторических дат в виде регулярных выражений (они ещё называются Regular Expressions, сокращённо regex или regexp). Выглядеть он будет так:
(?:\d{4})|(?:[IVX]+ век)Приятные новости: regex — настолько полезный и мощный инструмент, что поддерживается почти всеми современными языками программирования, в том числе и Python. Причём соответствующий синтаксис в разных языках очень схож. Так что, выучив его в одном языке, можно пользоваться им в других, практически не переучиваясь. Поехали.
Синтаксис регулярок
С помощью regex можно искать как вполне конкретные выражения (например, слово «век» — последовательность букв «в», «е» и «к»), так и что-то более общее (например, любую букву или цифру).
Для обозначения второй категории существуют специальные символы. Вот некоторые из них:
| Символ | Что означает | Пример использования шаблона | Пример вывода |
|---|---|---|---|
| . | Любой символ, кроме новой строки (\n) | H.llo, .orld 20.. год | Hello, world; Hallo, 2orld 2022 год, 2010 год |
| […] | Любой символ из указанных в скобках. Символы можно задавать как перечислением, так и указывая диапазон через дефис | [abc123] [A-Z] [A-Za-z0-9] [А-ЯЁа-яё] | а; 1 B; T A; s; 1 А; ё |
| [^…] | Любой символ, кроме указанных в скобках | [^A-Za-z] | з, 4 |
| ^ | Начало строки | ^Добрый день, | 0 |
| $ | Конец строки | До свидания!$ | 0 |
| | | Логическое ИЛИ. Регулярное выражение будет искать один из нескольких вариантов | [0-9]|[IVXLCDM] — регулярное выражение будет находить совпадение, если цифра является либо арабской, либо римской | 5; V |
| \ | Экранирование. Помогает регулярным выражениям ориентироваться, является ли следующий за \ символ обычным или специальным | \A\d\w\Z — экранирование превращает буквы алфавита в спецсимволы. \[\.\] — экранирование превращает спецсимволы в обычные | 0 |
Важное замечание 1. Регулярные выражения зависимы от регистра, то есть «А» и «а» при поиске будут считаться разными символами.
Важное замечание 2. Буквы «Ё» и «ё» не входят в диапазон «А — Я» и «а — я». Так что, задавая русский алфавит, их нужно выписывать отдельно.
На экранировании остановимся подробнее. По умолчанию символы .^$*+? {}[]\|() являются спецсимволами — то есть они выполняют определённые функции. Чтобы сделать спецсимволы обычными, их нужно экранировать \.
Таким образом, . будет обозначать любой символ, а \. — знак точки. Чтобы написать обратный слеш, его тоже нужно экранировать, то есть в регулярных выражениях он будет выглядеть так: \\.
Обратная ситуация с некоторыми алфавитными символами. По умолчанию они считаются просто буквами, но при экранировании начинают играть роль спецсимволов.
| Символ | Что означает |
|---|---|
| \d | Любая цифра. То же самое, что [0-9] |
| \D | Любой символ, кроме цифры. То же самое, что [^0-9] |
| \w | Любая буква, цифра и нижнее подчёркивание |
| \W | Любой символ, кроме буквы, цифры и нижнего подчёркивания |
| \s | Любой пробельный символ (пробел, новая строка, табуляция, возврат каретки и тому подобное) |
| \S | Любой символ, кроме пробельного |
| \A | Начало строки. То же самое, что ^ |
| \Z | Конец строки. То же самое, что $ |
| \b | Начало или конец слова |
| \B | Середина слова |
| \n, \t\, \r | Стандартные строковые обозначения: новая строка, табуляция, возврат каретки |
Важное замечание. \A, \Z, \b и \B указывают не на конкретный символ, а на положение других символов относительно друг друга. Можно сказать, что они указывают на пространство между символами.
Например, регулярное выражение \b[А-ЯЁаяё]\b будет искать только те буквы, которые отделены друг от друга пробелами или знаками препинания.
Часто при записи регулярного выражения какая-то часть шаблона должна повторяться определённое количество раз. Число вхождений в синтаксисе regex задают с помощью квантификаторов. Они всегда помещаются после той части шаблона, которую нужно повторить.
| Символ | Что означает | Примеры шаблона | Примеры вывода |
|---|---|---|---|
| {} | Указывает количество вхождений, можно задавать единичным числом или диапазоном | \d{4} — цифра, четыре подряд \d{1,4} — цифра, от одного до четырёх раз подряд \d{2,} — цифра, от двух раз подряд \d{,4} — цифра, от 0 до 4 раз подряд | 1243, 1876 1, 12, 176, 1589 22, 456, 988888 5, 15, 987, 1234 |
| ? | От нуля до одного вхождения. То же самое, что {0,1} | \d? | 0 |
| * | От нуля вхождений. То же самое, что {0,} | \d* | 0 |
| + | От одного вхождения. То же самое, что {1,} | \d+ | 0 |
Теперь давайте ещё раз посмотрим на наше регулярное выражение для поиска дат по учебнику истории:
(?:\d{4})|(?:[IVX]+ век)В нём есть несколько дополнительных символов, о которых рассказано ниже, но начинка этого выражения уже понятна.
- \d{4} — цифра, четыре подряд
- | — логическое ИЛИ
- [IVX]+ век — символ I, V или X, одно или более вхождений, пробел, слово «век»
Попрактиковаться в составлении регулярных выражений можно на сайте regex101.com. А мы разберём основные приёмы их использования и решим несколько задач.
Как ведётся поиск
Уточним ещё несколько терминов regex.
Регулярные выражения — это инструмент для работы со строками, которые и являются основной их единицей.
Строка представляет собой как само регулярное выражение, так и текст, по которому ведётся поиск.
Найденные в тексте совпадения с шаблоном называются подстроками. Например, у нас есть регулярное выражение м. (буква «м», затем любой символ) и текст «Мама мыла раму». Применяя регулярное выражение к тексту, мы найдём подстроки «ма», «мы» и «му». Подстроку «Ма» наше выражение пропустит из-за разницы в регистре.
Есть и более мелкая единица, чем подстрока, — группа. Она представляет собой часть подстроки, которую мы попросили выделить специально. Группы выделяются круглыми скобками (…).
Возьмём ту же строку «Мама мыла раму» и применим к ней следующее регулярное выражение:
(\w)(\w{3})Оно значит: буквенный символ, выделенный группой, и за ним ещё три буквенных символа, также выделенных группой. Итого весь шаблон представляет собой четыре буквенных символа.
В нашем тексте это выражение найдёт три совпадения, в каждом из которых выделит две группы:
| Подстрока | Группа 1 | Группа 2 |
|---|---|---|
| Мама | М | ама |
| мыла | м | ыла |
| раму | р | аму |
Это помогает извлечь из найденной подстроки конкретную информацию, отбросив всё остальное. Например, мы нашли адрес, состоящий из названия улицы, номера дома и номера квартиры. Подстрока будет представлять собой адрес целиком, а в группы можно поместить отдельно каждый его структурный элемент — и потом обращаться к нему напрямую.
Группам можно давать имена с помощью такой формы: (? P<name>…)
Вот так будет выглядеть наш шаблон, ищущий четырёхбуквенные слова, если мы дадим имена группам:
?P<first_letter>\w)(?P<rest_letters>\w{3})Уберём группы и упростим регулярное выражение, чтобы оно искало только подстроку:
\w{4}Немного изменим текст, по которому ищем совпадения: «Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке».
Регулярное выражение ищет четыре буквенных символа подряд, поэтому в качестве отдельных подстрок находит также «пило», «раме», «рабо», «тает», «лесо» и «пилк».
Задача 0. Пересечение подстрок и граница слова
Исправьте регулярное выражение так, чтобы оно находило только четырёхбуквенные слова. То есть оно должно найти подстроки «мама», «мыла», «раму» и «папа» — и ничего больше.
Подсказка, если не можете решить задачу
Используйте символ \b.
Важное замечание. При написании regex нужно помнить, что они ищут только непересекающиеся подстроки. Под шаблон \w{4} в слове «работает» подходят не только подстроки «рабо» и «тает», но и «абот», «бота», «отае». Их регулярное выражение не находит, потому что тогда бы эти подстроки пересеклись с другими — а в regex так нельзя.
Квантификаторы и логическое ИЛИ при группировке
Нередко при использовании регулярных выражений требуется применить квантификатор либо логическое ИЛИ не к отдельному символу, а к целой группе. Именно так мы поступили в нашем шаблоне для поиска дат по учебнику истории:
(?:\d{4})|(?:[IVX]+ век)С помощью скобок мы сказали: выдайте совпадение, если в тексте присутствует хотя бы один из двух вариантов — либо год, либо век.
Важное замечание.? : в начале группы означает, что мы просим regex не запоминать эту группу. Если все группы открываются символами? :, то регулярные выражения вернут только подстроку и ни одной группы.
В Python это может быть полезно, потому что некоторые re-функции возвращают разные результаты в зависимости от того, запомнили ли регулярные выражения какие-то группы или нет.
Также к группам удобно применять квантификаторы. Например, имена многих дроидов в «Звёздных войнах» построены по принципу: буква — цифра — буква — цифра.
Вот так это выглядит без групп:
[A-Z]\d[A-Z]\d
И вот так с ними:
(?:[A-Z]\d){2}Особенно полезно использовать незапоминаемые группы со сложными шаблонами.
Регулярные выражения в Python: модуль re и Match-объекты
Чтобы работать с регулярными выражениями в Python, необходимо импортировать модуль re:
import reЭто даёт доступ к нескольким функциям. Вот их краткое описание.
| Функция | Что делает | Если находит совпадение | Если не находит совпадение |
|---|---|---|---|
| re.match (pattern, string) | Ищет pattern в начале строки string | Возвращает Match-объект | Возвращает None |
| re.search (pattern, string) | Ищет pattern по всей строке string | Возвращает Match-объект с первым совпадением, остальные не находит | Возвращает None |
| re.finditer (pattern, string) | Ищет pattern по всей строке string | Возвращает итератор, содержащий Match-объекты для каждого найденного совпадения | Возвращает пустой итератор |
| re.findall (pattern, string) | Ищет pattern по всей строке string | Возвращает список со всеми найденными совпадениями | Возвращает None |
| re.split (pattern, string, [maxsplit=0]) | Разделяет строку string по подстрокам, соответствующим pattern | Возвращает список строк, на которые разделила исходную строку | Возвращает список строк, единственный элемент которого — неразделённая исходная строка |
| re.sub (pattern, repl, string) | Заменяет в строке string все pattern на repl | Возвращает строку в изменённом виде | Возвращает строку в исходном виде |
| re.compile (pattern) | Собирает регулярное выражение в объект для будущего использования в других re-функциях | Ничего не ищет, всегда возвращает Pattern-объект | 0 |
Важное замечание. Напоминаем, что регулярные выражения по умолчанию ищут только непересекающиеся подстроки.
Для написания регулярных выражений в Python используют r-строки (их называют сырыми, или необработанными). Это связано с тем, что написание знака \ требует экранирования не только в регулярных выражениях, но и в самом Python тоже.
Чтобы программистам не приходилось экранировать экранирование и писать нагромождения обратных слешей, и придумали r-строки. Синтаксически они обозначаются так:
r'...'re-функции с возвратом Match-объекта
Перечислим самые популярные из них.
re.match (pattern, string)
Находит совпадение только в том случае, если соответствующая шаблону подстрока находится в начале строки, по которой ведётся поиск:
print (re.match (r'Мама', 'Мама мыла раму'))
>>> <re.Match object; span=(0, 4), match='Мама'>
print (re.match (r'мыла', 'Мама мыла раму'))
>>> None
Как видим, поиск по шаблону «Мама» нашёл совпадение и вернул Match-объект. Слово же «мыла», хотя и есть в строке, находится не в начале. Поэтому регулярное выражение ничего не находит и возвращается None.
re.search (pattern, string)
Ищет совпадения по всему тексту:
print (re.search (r'Мама', 'Мама мыла раму'))
>>> <re.Match object; span=(0, 4), match='Мама'>
print (re.search (r'мыла', 'Мама мыла раму'))
>>> <re.Match object; span=(5, 9), match='мыла'>При этом re.search возвращает только первое совпадение, даже если в строке, по которой ведётся поиск, их больше. Проверим это:
print (re.search (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла'))
>>> <re.Match object; span=(5, 9), match='мыла'>re.finditer (pattern, string)
Возвращает итератор с объектами, к которым можно обратиться через цикл:
results = re.finditer (r'мыла', 'Мама мыла раму, а потом ещё раз мыла, потому что не домыла')
print (results)
>>> <callable_iterator object at 0x000001C4CDE446D0>
for match in results:
print (match)
>>> <re.Match object; span=(5, 9), match='мыла'>
>>> <re.Match object; span=(32, 36), match='мыла'>
>>> <re.Match object; span=(54, 58), match='мыла'>Эта функция очень полезна, если вы хотите получить Match-объект для каждого совпадения.
Как работать с Match-объектами
В Match-объектах хранится много всего интересного. Посмотрим внимательнее на объект с подстрокой «Мама», который нашла функция re.match:
<re.Match object; span=(0, 4), match='Мама'>span — это индекс начала и конца найденной подстроки в тексте, по которому мы искали совпадение. Обратите внимание, что второй индекс не включается в подстроку.
match — это собственно найденная подстрока. Если подстрока длинная, то она будет отображаться не целиком.
Это, конечно же, не всё, что можно получить от Match-объекта. Рассмотрим ещё несколько методов.
group
Возвращает найденную подстроку, если ему не передавать аргумент или передать аргумент 0. То же самое делает обращение к объекту по индексу 0:
match = re.match (r'Мама', 'Мама мыла раму')
print (match.group())
>>> Мама
print (match.group(0))
>>> Мама
print (match[0])
>>> МамаЕсли регулярное выражение поделено на группы, то, начиная с единицы, можно вызвать группу отдельно от строки:
match = re.match (r'(М)(ама)', 'Мама мыла раму')
print (match.group(1))
print (match.group(2))
>>> М
>>> ама
print (match[1])
print (match[2])
>>> М
>>> ама
#Методом group также можно получить кортеж из нужных групп.
print (match.group(1,2))
>>> ('М', 'ама')Если группы поименованы, то в качестве аргумента метода group можно передавать их название:
match = re.match (r'(?P<first_letter>М)(?P<rest_letters>ама)', 'Мама мыла раму')
print (match.group('first_letter'))
print (match.group('rest_letters'))
>>> М
>>> амаЕсли одна и та же группа соответствует шаблону несколько раз, то в группу запишется только последнее совпадение:
#Помещаем в группу один буквенный символ, при этом шаблон представляет собой четыре таких символа.
match = re.match (r'(\w){4}', 'Мама мыла раму')
print (match.group(0))
>>> Мама
print (match.group(1))
>>> аgroups
Возвращает кортеж с группами:
match = re.match (r'(М)(ама)', 'Мама мыла раму')
print (match.groups())
>>> ('М', 'ама')span
Возвращает кортеж с индексом начала и конца подстроки в исходном тексте. Если мы хотим получить только первый индекс, можно использовать метод start, только последний — end:
match = re.search (r'мыла', 'Мама мыла раму')
print (match.span())
>>> (5, 9)
print (match.start())
>>> 5
print (match.end())
>>> 9re-функции без возврата Match-объекта
re.findall (pattern, string)
Возвращает просто список совпадений. Никаких Match-объектов, к которым нужно дополнительно обращаться:
#В этом примере в качестве регулярного выражения мы используем правильный ответ на задание 0.
match_list = re.findall (r'\b\w{4}\b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (match_list)
>>> ['Мама', 'мыла', 'раму', 'папа']Функция ведёт себя по-другому, если в регулярном выражении есть деление на группы. Тогда функция возвращает список кортежей с группами:
match_list = re.findall (r'\b(\w{1})(\w{3})\b', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (match_list)
>>> [('М', 'ама'), ('м', 'ыла'), ('р', 'аму'), ('п', 'апа')]re.split (pattern, string, [maxsplit=0])
Аналог метода str.split. Делит исходную строку по шаблону, а сам шаблон исключает из результата:
#Поделим строку по запятой и пробелу после неё.
split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (split_string)
>>> ['Мама мыла раму', 'а папа был на пилораме', 'потому что работает на лесопилке.']re.split также имеет дополнительный аргумент maxsplit — это максимальное количество частей, на которые функция может поделить строку. По умолчанию maxsplit равен нулю, то есть не устанавливает никаких ограничений:
#Приравняем аргумент maxsplit к единице.
split_string = re.split (r', ', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.', maxsplit=1)
print (split_string)
>>> ['Мама мыла раму', 'а папа был на пилораме, потому что работает на лесопилке.']Если в re.split мы указываем группы, то они попадают в список строк в качестве отдельных элементов. Для наглядности поделим исходную строку на слог «па»:
#Помещаем буквы «п» и «а» в одну группу.
split_string = re.split (r'(па)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (split_string)
>>> ['Мама мыла раму, а ', 'па', '', 'па', ' был на пилораме, потому что работает на лесопилке.']
#Помещаем буквы «п» и «а» в разные группы.
split_string = re.split (r'(п)(а)', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (split_string)
>>> ['Мама мыла раму, а ', 'п', 'а', '', 'п', 'а', ' был на пилораме, потому что работает на лесопилке.']re.sub (pattern, repl, string)
Требует указания дополнительного аргумента в виде строки, на которую и будет заменять найденные совпадения:
new_string = re.sub (r'Мама', 'Дочка', 'Мама мыла раму, а папа был на пилораме, потому что работает на лесопилке.')
print (new_string)
>>> Дочка мыла раму, а папа был на пилораме, потому что работает на лесопилке.Дополнительные возможности у функции появляются при применении групп. В качестве аргумента замены ему можно передать не строку, а ссылку на номер группы в виде \n. Тогда он подставит на нужное место соответствующую группу из шаблона. Это очень удобно, когда нужно поменять местами структурные элементы в тексте:
new_string = re.sub (r'(\w+) (\w+) (\w+),', r'\2 \3 \1 –', 'Бендер Остап Ибрагимович, директор ООО "Рога и копыта"')
print (new_string)
>>> Остап Ибрагимович Бендер — директор ООО "Рога и копыта"re.compile (pattern)
Используется для ускорения и упрощения кода, когда одно и то же регулярное выражение применяется в нём несколько раз. Её синтаксис выглядит так:
pattern = re.compile (r'Мама')
print (pattern.search ('Мама мыла раму'))
>>> <re.Match object; span=(0, 4), match='Мама'>
print (pattern.sub ('Дочка', 'Мама мыла раму'))
>>> Дочка мыла рамуДеление r-строк
Нередко в регулярных выражениях нужно учесть сразу много вариантов и опций, из-за чего их структура усложняется. А regex даже простые и короткие читать нелегко, что уж говорить о длинных.
Чтобы хоть как-то облегчить чтение регулярок, в Python r-строки можно делить точно так же, как и обычные. Возьмём наше выражение для поиска дат по учебнику истории:
re.findall (r'(?:\d{4})|(?:[IVX]+ век)', text)Его же можно написать вот в таком виде:
re.findall (r'(?:\d{4})'
r'|'
r'(?:[IVX]+ век)', text)Жадный и ленивый пропуск
Часто при написании регулярных выражений приходится использовать квантификаторы, охватывающие диапазон значений. Например, \d{1,4}. Как регулярные выражения решают, сколько цифр им захватить, одну или четыре? Это определяется пропуском квантификаторов.
По умолчанию все квантификаторы являются жадными, то есть стараются захватить столько подходящих под шаблон символов, сколько смогут.
В некоторых случаях это может стать проблемой. Например, возьмём часть оглавления поэмы Венедикта Ерофеева «Москва — Петушки», записанную в одну строку:
Фрязево — 61-й километр..........64 61-й километр — 65-й километр…68 65-й километр — Павлово-Посад…71 Павлово-Посад — Назарьево........73 Назарьево — Дрезна...............77 Дрезна — 85-й километр...........80
Нужно написать регулярное выражение, которое выделит каждый пункт оглавления. Для этого определим признаки, по которым мы будем это делать:
- Каждый пункт начинается с буквы или цифры (для этого используем шаблон \w).
- Он может содержать внутри себя любой набор символов: буквы, цифры, знаки препинания (для этого используем шаблон .+).
- Он заканчивается на точку, после которой следует от одной до трёх цифр (для этого используем шаблон \.\d{1,3}).
Посмотрим в конструкторе, как работает наше выражение:
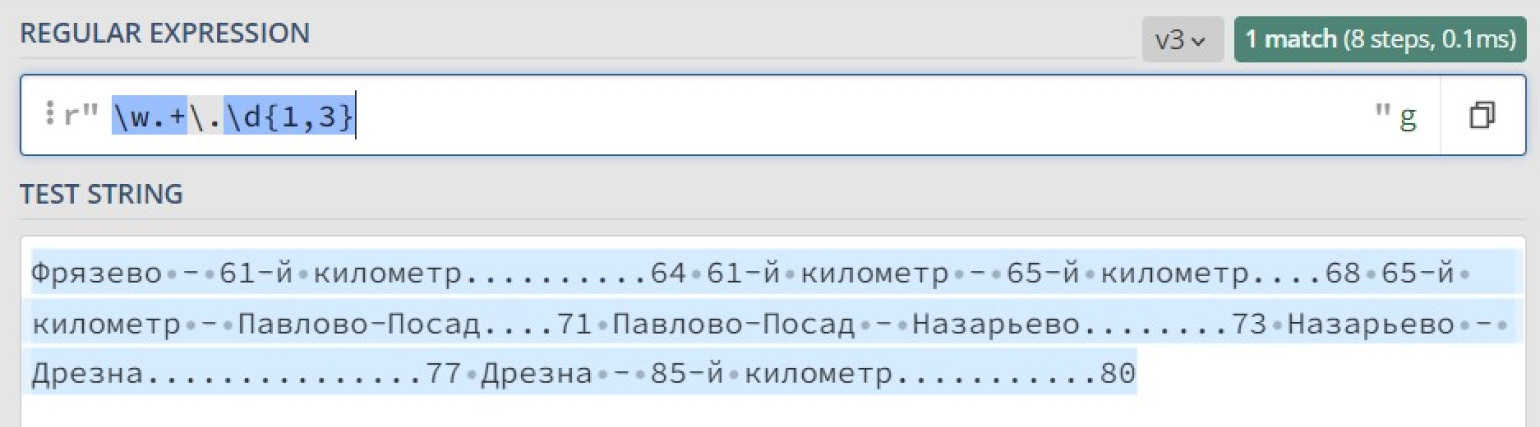
Что же произошло? Почему найдено только одно совпадение, причем за него посчитали весь текст сразу? Всё дело в жадности квантификатора +, который старается захватить максимально возможное количество подходящих символов.
В итоге шаблон \w находит совпадение с буквой «Ф» в начале текста, шаблон \.\d{1,3} находит совпадение с «.80» в конце текста, а всё, что между ними, покрывается шаблоном .+.
Чтобы квантификатор захватывал минимально возможное количество символов, его нужно сделать ленивым. В таком случае каждый раз, находя совпадение с шаблоном ., регулярное выражение будет спрашивать: «Подходят ли следующие символы в строке под оставшуюся часть шаблона?»
Если нет, то функция будет искать следующее совпадение с .. А если да, то . закончит свою работу и следующие символы строки будут сравниваться со следующей частью регулярного выражения: \.\d{1,3}.
Чтобы объявить квантификатор ленивым, после него надо поставить символ ?. Сделаем ленивым квантификатор + в нашем регулярном выражении для поиска строк в оглавлении:
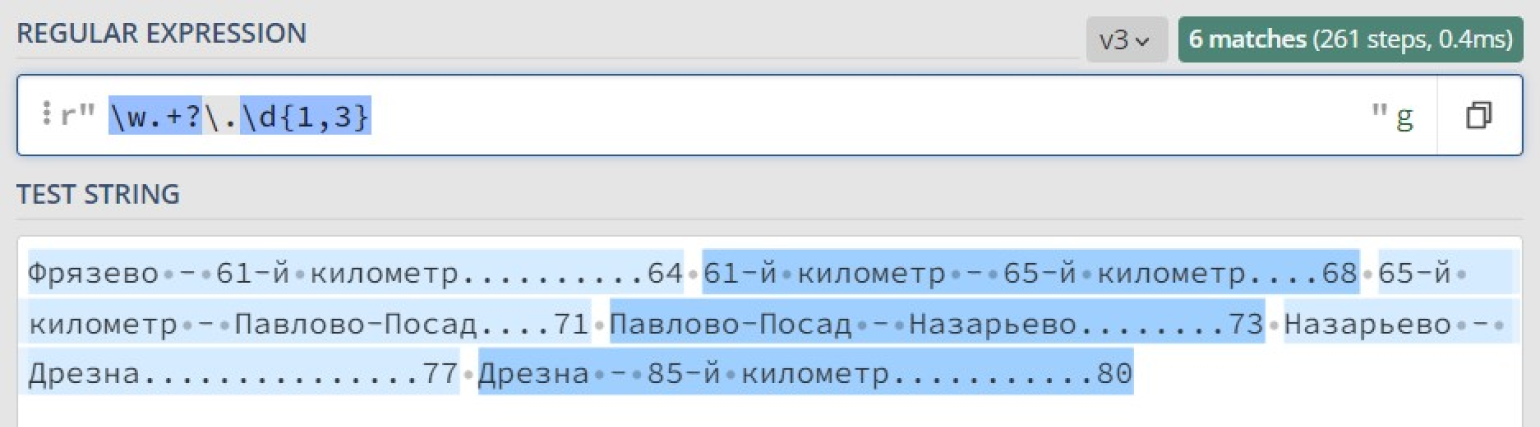
Теперь, когда мы уверены в правильности работы нашего регулярного выражения, используем функцию re.findall, чтобы выписать оглавление построчно:
content = 'Фрязево — 61-й километр..........64 61-й километр — 65-й километр....68 65-й километр — Павлово-Посад....71 Павлово-Посад — Назарьево........73 Назарьево — Дрезна...............77 Дрезна — 85-й километр...........80'
strings = re.findall (r'\w.+?\.\d{1,3}', content)
for string in strings:
print (string)
#Результат на экране.
>>> Фрязево — 61-й километр..........64
>>> 61-й километр — 65-й километр....68
>>> 65-й километр — Павлово-Посад....71
>>> Павлово-Посад — Назарьево........73
>>> Назарьево — Дрезна...............77
>>> Дрезна — 85-й километр...........80Примеры и задачи
В некоторых случаях одну и ту же задачу можно решить разными способами, используя разные возможности регулярок. Попробуйте решить следующие задачи самостоятельно. Возможно, у вас даже получится сделать это более эффективно.
Задача 1. Замена имён в судебном решении
При обнародовании судебных решений из них извлекают персональные данные участников процесса — фамилии, имена и отчества. Каждое слово в Ф. И. О. начинается с заглавной буквы, при этом фамилия может быть двойная.
Напишите программу, которая заменит в тексте Ф. И. О. подсудимого на N.
Ввод
Подсудимая Эверт-Колокольцева Елизавета Александровна в судебном заседании вину инкриминируемого правонарушения признала в полном объёме и суду показала, что 14 сентября 1876 года, будучи в состоянии алкогольного опьянения от безысходности, в связи с состоянием здоровья позвонила со своего стационарного телефона в полицию, сообщив о том, что у неё в квартире якобы заложена бомба. После чего приехали сотрудники полиции, скорая и пожарные, которым она сообщила, что бомба — это она.
Вывод
«Подсудимая N в судебном заседании» и далее по тексту.
Подсказка
Используйте незапоминаемую опциональную группу вида (? : …)? , чтобы обозначить вторую часть фамилии после дефиса.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
print (re.sub (r'[А-ЯЁ]\w*'
r'(?:-[А-ЯЁ]\w*)?'
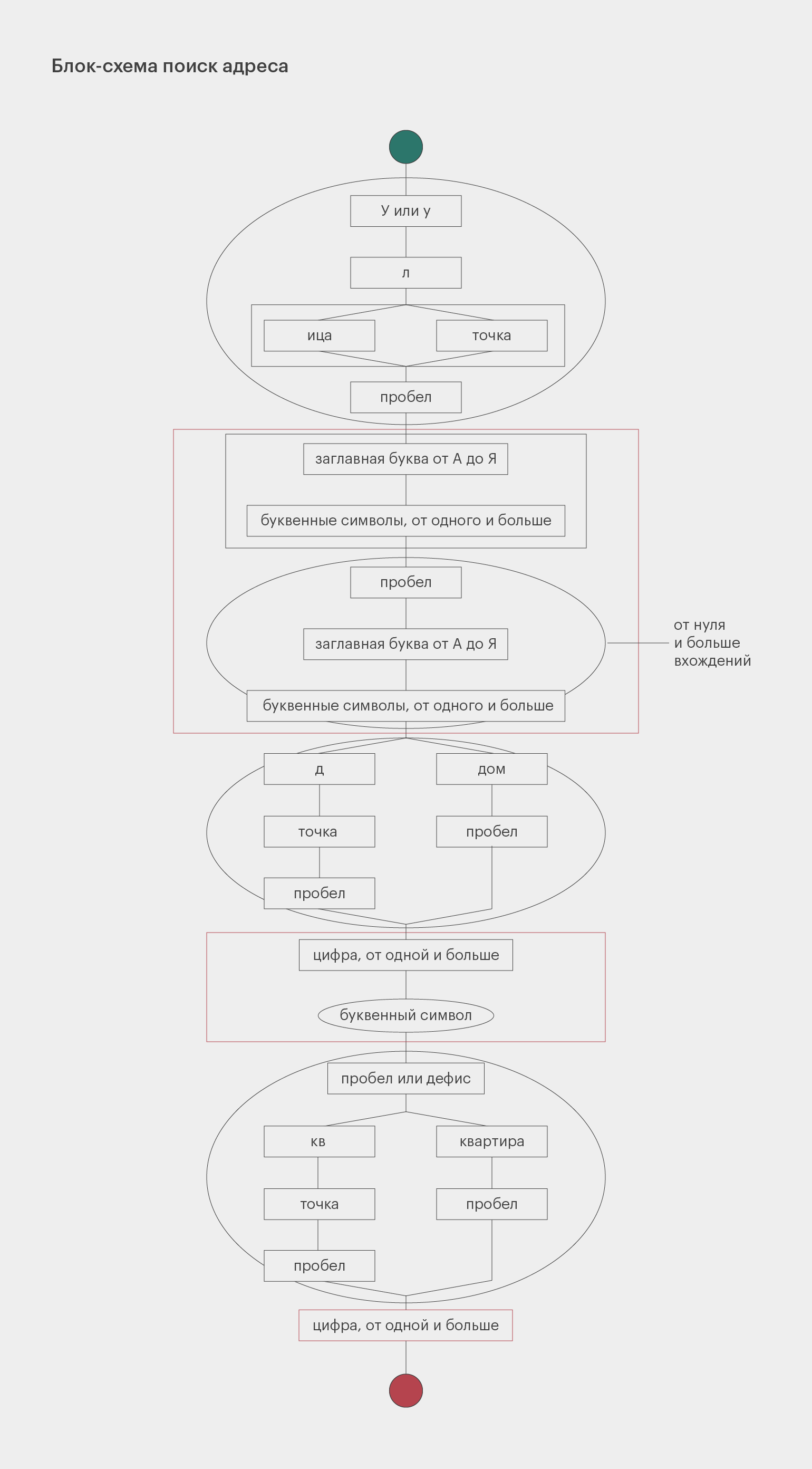
r'(?: [А-ЯЁ]\w*){2}', 'N', string))Задача 2. Поиск адресов
Большинство адресов состоит из трёх частей: название улицы, номер дома и номер квартиры. Название улицы может состоять из нескольких слов, каждое из которых пишется с заглавной буквы. Номер дома может содержать после себя букву.
Перед названием улицы может быть написано «Улица», «улица», «Ул.» или «ул.», перед номером дома — «дом» или «д.», перед номером квартиры — «квартира» или «кв.». Также номер дома и номер квартиры могут быть разделены дефисом без пробелов.
Дан текст, в нём нужно найти все адреса и вывести их в виде «Пушкина 32-135».
Для упрощения мы не будем учитывать дома, которые находятся не на улицах, а на площадях, набережных, бульварах и так далее.
Ввод:
Добрый день!
Сегодня на выезды потребуется отправить трёх-четырёх специалистов, остальных держите в офисе. Некоторые заявки пришли на конкретных людей, но можно вызвать и других, смотрите по ситуации, как лучше их отправить, чтобы всех объездить сегодня.
Петрову П. П. попросили выехать по адресам ул. Культуры 78 кв. 6, улица Мира дом 12Б квартира 144. Смирнова С. С. просят подъехать только по адресу: Восьмого Марта 106-19. Без предпочтений по специалистам пришли запросы с адресов: улица Свободы 54 6, Улица Шишкина дом 9 кв. 15, ул. Лермонтова 18 кв. 93.
Все адреса скопированы из заявок, корректность подтверждена.
Вывод
Культуры 78-6
Мира 12Б-144
Восьмого Марта 106-19
Свободы 54-6
Шишкина 9-15
Лермонтова 18-93
Подсказка
Используйте деление на группы, чтобы удобно выстроить структуру выражения. Попросите regex запоминать только нужные вам части адреса, чтобы функция не возвращала вам лишние подгруппы.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:[Уу]л(?:\.|ица) )?'
r'((?:[А-ЯЁ]\w+)(?: [А-ЯЁ]\w+)*)'
r' (?:дом |д\. )?'
r'(\d+\w?)'
r'[ -](?:квартира |кв\. )?'
r'(\d+)')
addresses = pattern.findall (text)
for address in addresses:
print (f'{address[0]} {address[1]}-{address[2]}')Структура этого регулярного выражения довольно сложная. Чтобы в нём разобраться, посмотрите на схему. Прямоугольники обозначают обязательные элементы, овалы — опциональные. Развилки символизируют разные варианты, которые допускает наш шаблон. Красным цветом очерчены группы, которые мы запоминаем.
Задача 3. Метод Довлатова
Писатели в поиске собственного неповторимого стиля нередко изобретают оригинальные творческие приёмы и неукоснительно им следуют. Например, Сергей Довлатов следил за тем, чтобы слова в предложении не начинались с одной и той же буквы.
Даны несколько предложений. Программа должна проверить, встречаются ли в каждом из них слова на одинаковую букву. Если таких нет, она печатает: «Метод Довлатова соблюдён». А если есть: «Вы расстроили Сергея Донатовича».
Важно. Чтобы регулярные выражения не рассматривали заглавные и прописные буквы как разные символы, передайте re-функции дополнительный аргумент flags=re.I или flags=re.IGNORECASE.
Ввод
Здесь все слова начинаются с разных букв.
А в этом предложении есть слова, которые всё-таки начинаются на одну и ту же букву.
А здесь совсем интересно: символ «а» однобуквенный.
Вывод
Метод Довлатова соблюдён
Вы расстроили Сергея Донатовича
Вы расстроили Сергея Донатовича
Подсказка
Чтобы указать на начало слова, используйте символ \b.
Чтобы в каждом совпадении regex не старалось захватить максимум, используйте ленивый пропуск.
Чтобы найти повторяющийся символ, используйте ссылку на группу в виде \1.
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = r'\b(\w)\w*.*?\b\1'
match = re.search (pattern, string, flags=re.I)
if match is None:
print ('Метод Довлатова соблюдён')
else:
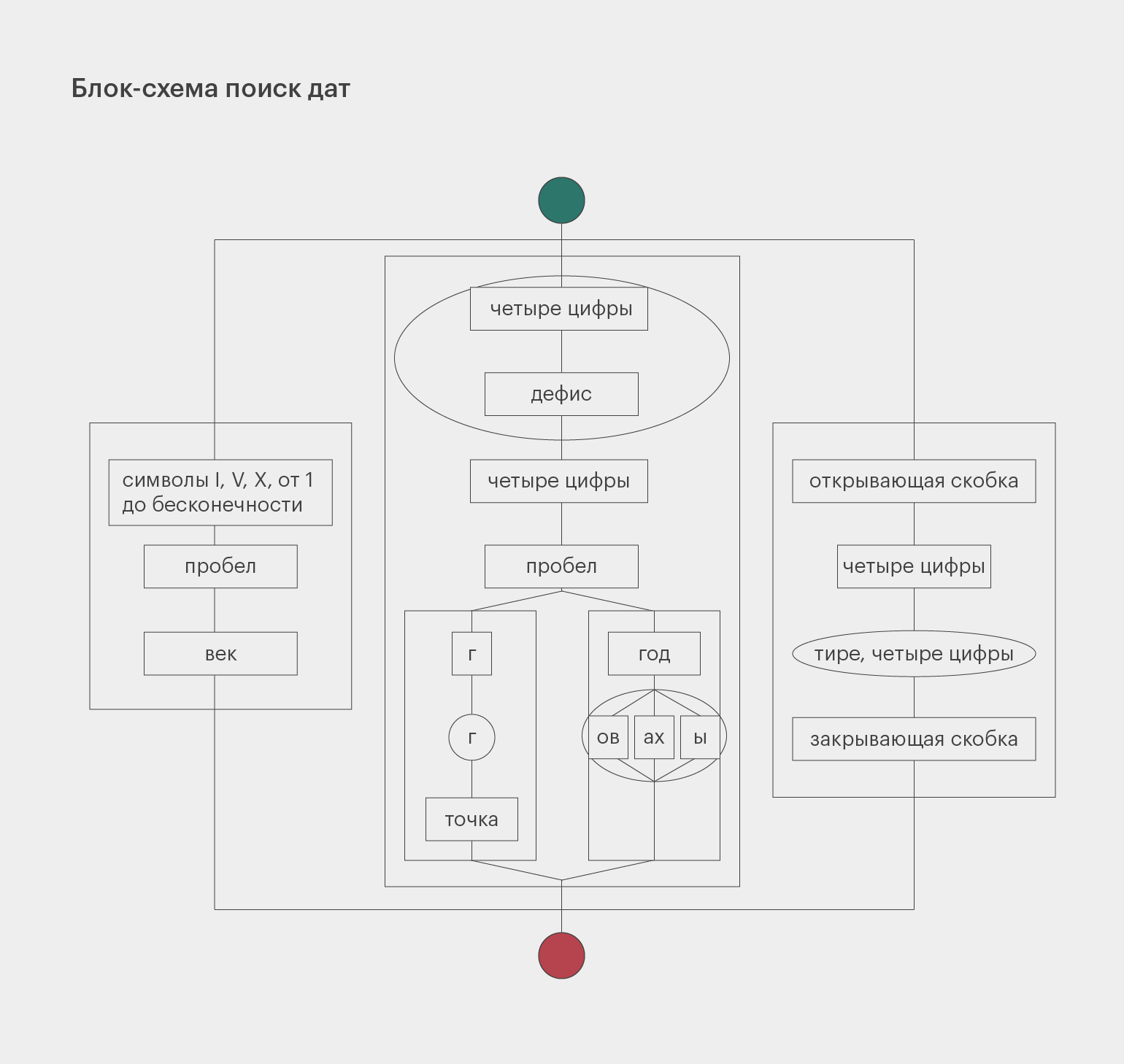
print ('Вы расстроили Сергея Донатовича')Задача 4. Улучшенный поиск дат в учебнике
Вернёмся к регулярному выражению, которое ищет даты в учебнике истории: (? :\d{4})|(? : [IVX]+ век).
Оно в целом справляется со своей задачей, но также находит много ненужных чисел. Например, количество человек, которые участвовали в битве, тоже может быть описано четырьмя цифрами подряд.
Чтобы не получать лишние результаты, обратим внимание на то, как именно могут быть записаны годы. Есть несколько вариантов записи: 1400 год, 1400 г., 1400–1500 годы, 1400–1500 гг., (1400), (1400–1500).
Чтобы немного упростить задачу и не раздувать регулярное выражение, мы не будем искать конструкции «с такого-то по такой-то год» и «между таким-то и таким-то годом».
Важное замечание. Не забывайте про экранирование, если хотите использовать точки и скобки в качестве обычных, а не специальных символов. Так программа правильно поймёт, что вы имеете в виду.
Ввод
Началом Реформации принято считать 31 октября 1517 г. — день, когда Мартин Лютер (1483–1546) прибил к дверям виттенбергской Замковой церкви свои «95 тезисов», в которых выступил против злоупотреблений Католической церкви. Реформация охватила практически всю Европу и продолжалась в течение всего XVI века и первой половины XVII века. Одно из самых известных и кровавых событий Реформации — Варфоломеевская ночь во Франции, произошедшая в ночь на 24 августа 1572 года.
Точное число жертв так и не удалось установить достоверно. Погибли по меньшей мере 2000 гугенотов в Париже и 3000 — в провинциях. Герцог де Сюлли, сам едва избежавший смерти во время резни, говорил о 70 000 жертв. Для Парижа единственным точным числом остаётся 1100 погибших во время Варфоломеевской ночи.
Этому событию предшествовали три других, произошедшие в 1570–1572 годах: Сен-Жерменский мирный договор (1570), свадьба гугенота Генриха Наваррского и Маргариты Валуа (1572) и неудавшееся покушение на убийство адмирала Колиньи (1572).
Вывод
['1517 г.', '(1483–1546)', 'XVI век', 'XVII век', '1572 год', '1570–1572 годах', '(1570)', '(1572)', '(1572)']
Решение
#Сначала кладём в переменную string текст строки, по которой ведём поиск.
pattern = re.compile (r'(?:\(\d{4}(?:-\d{4})?\))'
r'|'
r'(?:'
r'(?:\d{4}-)?\d{4} '
r'(?:'
r'(?:год(?:ы|ах|ов)?)'
r'|'
r'(?:гг?\.)'
r')'
r')'
r'|'
r'(?:[IVX]+ век)')
print (pattern.findall (string))Если вам сложно разобраться в структуре этого выражения, то вот его схема: