3 причины, по которым модели машинного обучения не попадают в продакшен
Мнение и советы эксперта Анастасии Никулиной.



Консалтинговые компании Gartner и McKinsey провели исследования и выяснили, что 50–80% моделей машинного обучения не попадают в продакшен. Это означает, что более половины проектов каждый дата-сайентист отправит в стол — разработает, но нигде не использует. Мы пообщались с Анастасией Никулиной и выяснили три частые причины, по которым так происходит, и как можно повлиять на ситуацию.
Для справки: что такое модель машинного обучения и продакшен
Модель машинного обучения — это программа, которая проводит вычисления и превращает доступные данные в полезную информацию.
Представьте сталелитейный завод, где плавят металл для космических кораблей. Чтобы наладить производственный цикл, технологи много лет экспериментировали с добавками, записывали результаты и учились добывать сплав нужного качества.
Теперь производственный цикл можно улучшить, если разработать под него модель машинного обучения. Например, программа сама находит сочетания более дешёвых добавок и прогнозирует их совместимость. Получится удешевить производство хотя бы на 1% — завод сэкономит миллионы.
Если вместо моделирования смешивать новые добавки вручную, то нарушение пропорций приведёт к отклонению от стандарта — и вместо космических кораблей эта партия металла уйдёт на выплавку лопат. Завод сработает себе в убыток.
Дата-сайентист не может взять случайные данные и слепить из них рабочую модель машинного обучения. Это сложный цикл, о котором мы поговорим в другой раз.
Просто запомните: пока модель не будет обучена на большом количестве статистически значимых данных — она не попадёт в продакшен (production), поскольку не сможет выполнять поставленную задачу. В нашем примере — не сможет оптимизировать производство металла на заводе. Программа будет что-то подсчитывать, выдавать бессмысленный результат, и сэкономить на этом не выйдет.
Дальше мы поговорим о причинах, которые мешают моделям машинного обучения пройти полный цикл и превратиться в бизнес-инструмент (попасть в продакшен).
Причина 1
Не все сотрудники рады внедрению технологий
Что не так
Модели машинного обучения лучше человека справляются со многими задачами, где нужно работать с большим количеством данных и повторяющимися процессами — когда нужно что-то рассчитать, спрогнозировать или классифицировать. Многим сотрудникам это не нравится, и поэтому они переживают за свои рабочие места.
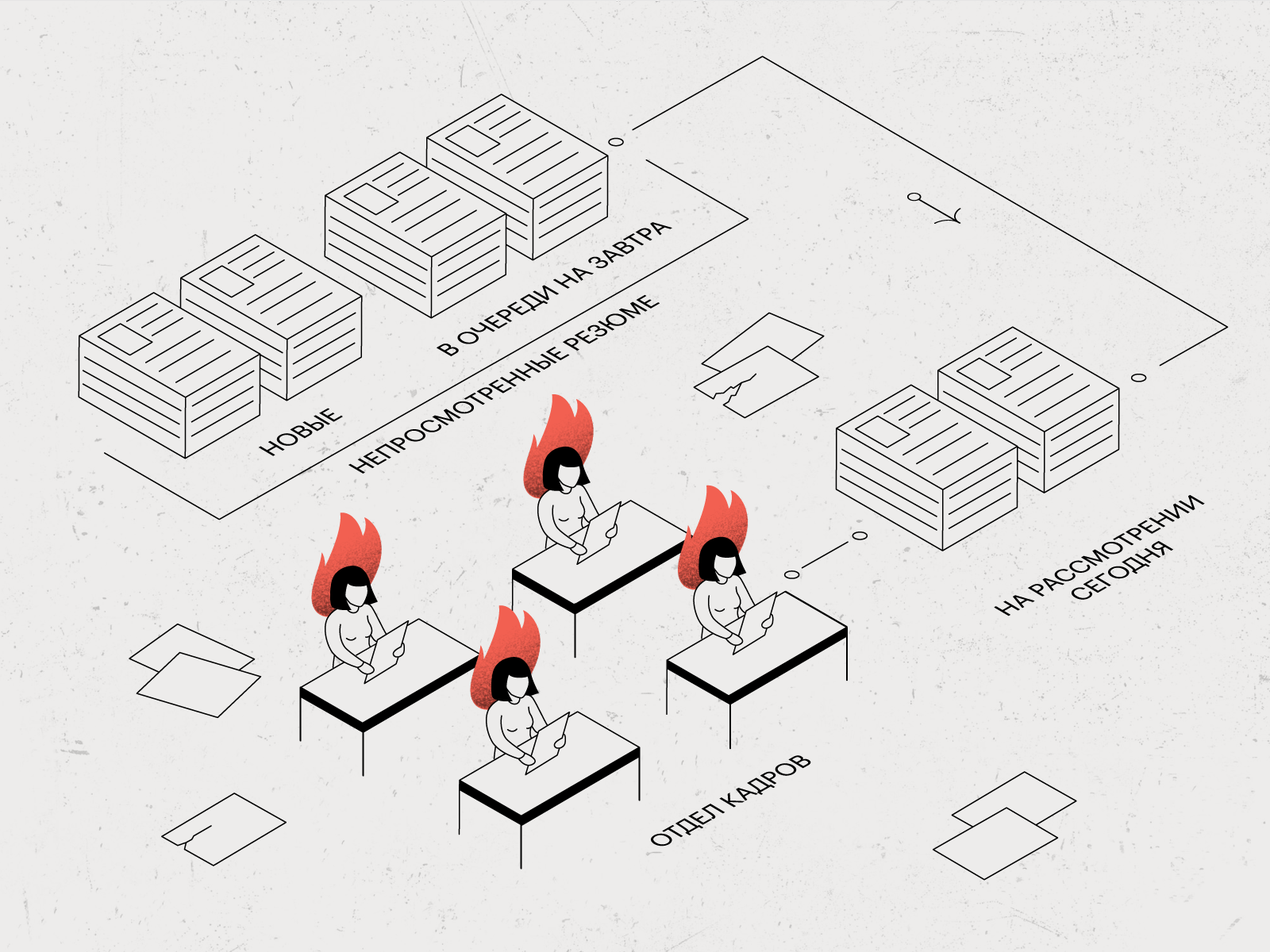
Возьмём отдел кадров, где все привыкли неспешно готовить отчёты в Excel. В какой-то момент на пороге их кабинета появляется дата-сайентист с алгоритмом для проверки резюме и отсева неподходящих кандидатов — технологией, которая может сэкономить отделу кадров 80% времени.
Кадровики не захотят изменений. Они будут видеть в алгоритме угрозу, из-за которой их могут уволить, понизить в должности или нагрузить обязанностями. Иногда это заканчивается саботажем: дата-сайентист получит неполную базу резюме, искажённые требования к кандидатам на вакансии и так далее. С недостоверными данными модель машинного обучения не сможет давать корректный результат и такая модель не принесёт пользы в продакшене.
Как попробовать исправить
Саботаж нужно гасить переговорами. Дата-сайентисту важно объяснить, зачем сотрудникам модель машинного обучения и почему им важно ей пользоваться. Для убедительности полезно изучать опыт компаний, которые пользуются похожими технологиями. Например, чтобы автоматизировать процессы противодействия отмыванию доходов и финансирования терроризма, банки могут взять кейс Росбанка.
После внедрения системы специалисты финансового мониторинга стали быстрее искать и сопоставлять нужную информацию, готовить отчёты и принимать решения по сомнительным операциям, подлежащим обязательному банковскому контролю.
👉 Другие кейсы Росбанка: как модели машинного обучения помогают управлять банковскими отделениями и розничными сетями.
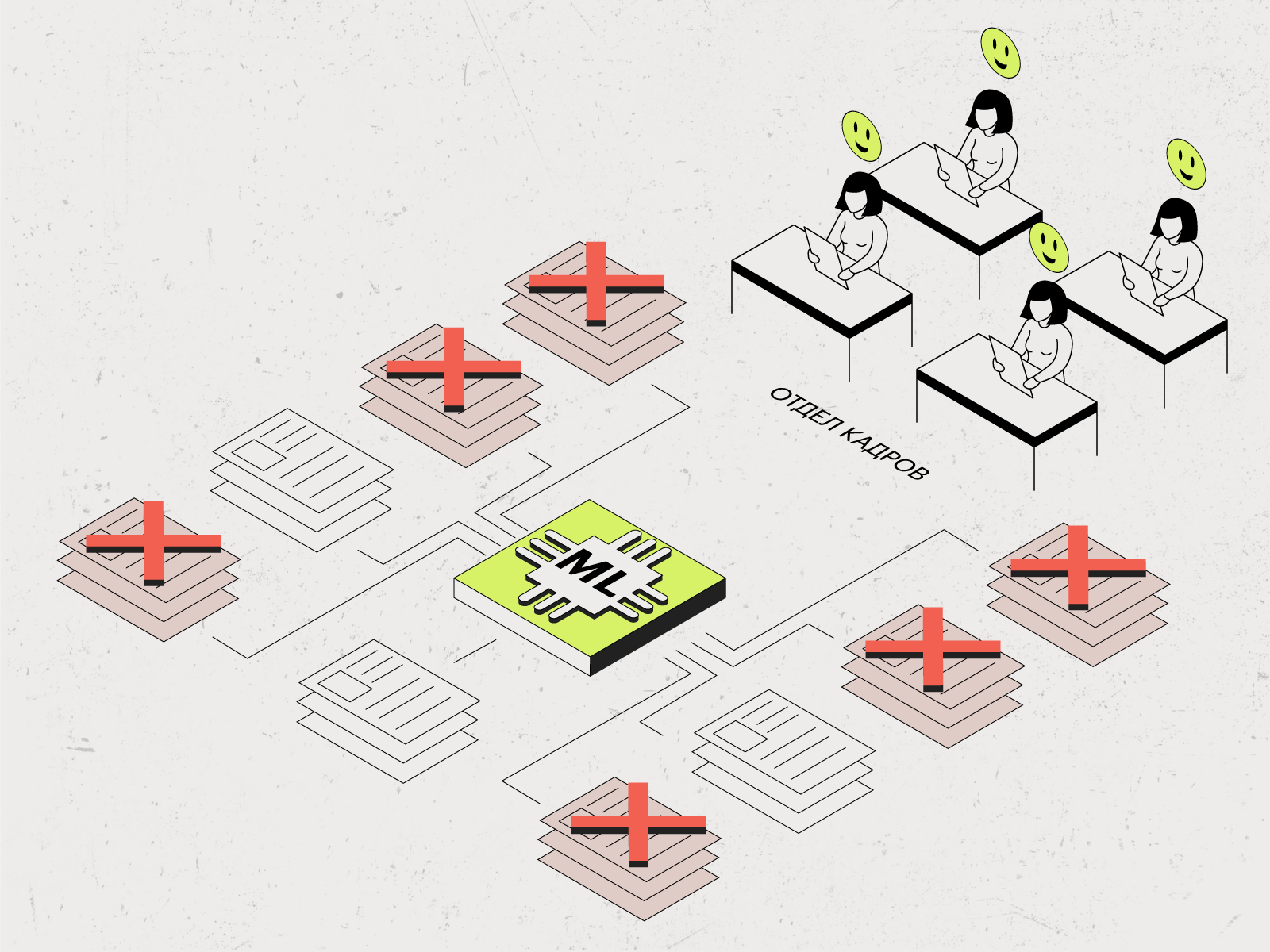
Сначала дайте понять, что внедрение технологии не повлияет на численность штата. Переговоры бесполезны, пока сотрудники боятся потерять работу и воспринимают алгоритм как угрозу. Например, в случае с отделом кадров можно организовать встречу и сравнить модель машинного обучения с Excel — рассказать, что это просто инструменты, которые не заменят человека и предназначены для разных задач.
На следующем шаге покажите пользу от работы с данными.
- Как сейчас: ручная обработка резюме, кадровая текучка, дефицит квалифицированных специалистов.
- Как может быть: алгоритм будет сопоставлять умения кандидатов с требованиями вакансий и убирать неподходящие резюме. Кадровики смогут проводить больше интервью, тщательнее тестировать кандидатов и хантить ценных сотрудников у конкурентов.
Когда сотрудники правильно поняли идею машинного обучения, можно завершать переговоры и запрашивать данные. Дальше всё зависит от навыков дата-сайентиста.
Причина 2
В команде недостаточно людей
Что не так
Коллективная работа дата-сайентистов напоминает действия футбольной команды — есть разные исполнители, которые поэтапно готовят модель машинного обучения в продакшен: собирают данные, проводят тестирование, настраивают инфраструктуру, пишут код, отслеживают метрики и выполняют множество других операций.
Ни один футболист не умеет одинаково хорошо стоять на воротах, играть в защите и нападении — это разные навыки, для которых нужна специальная подготовка. С дата-сайентистами так же — у каждого исполнителя есть специализация, которая подходит только для определённой части проекта. Поэтому если компания не привлекает в проект достаточное количество квалифицированных исполнителей с разной специализацией, то модель машинного обучения не попадёт в продакшен или выйдет позже срока.

Как попробовать исправить
Data Scientist — это гибридная профессия, которая связана со статистикой, машинным обучением, математикой, аналитикой, визуализацией данных и бизнес-процессами. Да, в теории существуют дата-сайентисты, которые одинаково хорошо во всём разбираются. Но на практике такие редко встречаются. Вот примерный перечень специалистов, чьи услуги понадобятся более-менее крупному проекту:
- Data Architect. Отвечает за стандарты качества — устанавливает правила, по которым нужно собирать, хранить, обрабатывать и использовать данные.
- Data Engineer. Занимается хранением, обработкой и получением собранных данных — реализует то, что описано в проекте дата-архитектора.
- Data Analyst. Работает со статистикой: находит в цифрах закономерности, визуализирует информацию и подготавливает всевозможные отчёты.
- Machine Learning Engineer. Проводит тесты, настраивает автоматизацию и выполняет техобслуживание моделей машинного обучения после продакшена.
- Business Intelligence Developer. Собирает полученные командой данные, переводит их на понятный язык и демонстрирует менеджменту компании.
- Database Administrator. Следит за базой данных, в которой дата-сайентисты хранят информацию по каждому проекту: исправляет ошибки, проводит резервное копирование, настраивает безопасный доступ и обеспечивает совместимость разных версий программного обеспечения.
Сколько специалистов понадобится — зависит от задачи и сроков. Поэтому, чтобы не сорвать проект, ответственный сотрудник вместе с коллегами-дата-сайентистами должен заранее подготовить план запуска модели в продакшен с учётом ресурсов компании. В плане нужно указать, каких исполнителей не хватает и почему. После этого руководитель решит, стоит ли расширять штат или лучше отложить разработку.
Причина 3
Компания не готова к запуску
Что не так
Оцените ситуацию: вы смотрите рекламу, кликаете по объявлению и попадаете в пустой интернет-магазин. Согласитесь, нелогично — предприниматели не будут тратить бюджет, пока не наладят поставку товаров и не настроят продажи через сайт.
Другой пример: владелец интернет-магазина недоволен сотрудниками склада, поскольку из-за них компания несёт убытки. Многие воруют, готовят фиктивные отчёты, несвоевременно утилизируют просрочку, пропускают сроки отправки товаров, подбирают недобросовестных поставщиков и так далее.
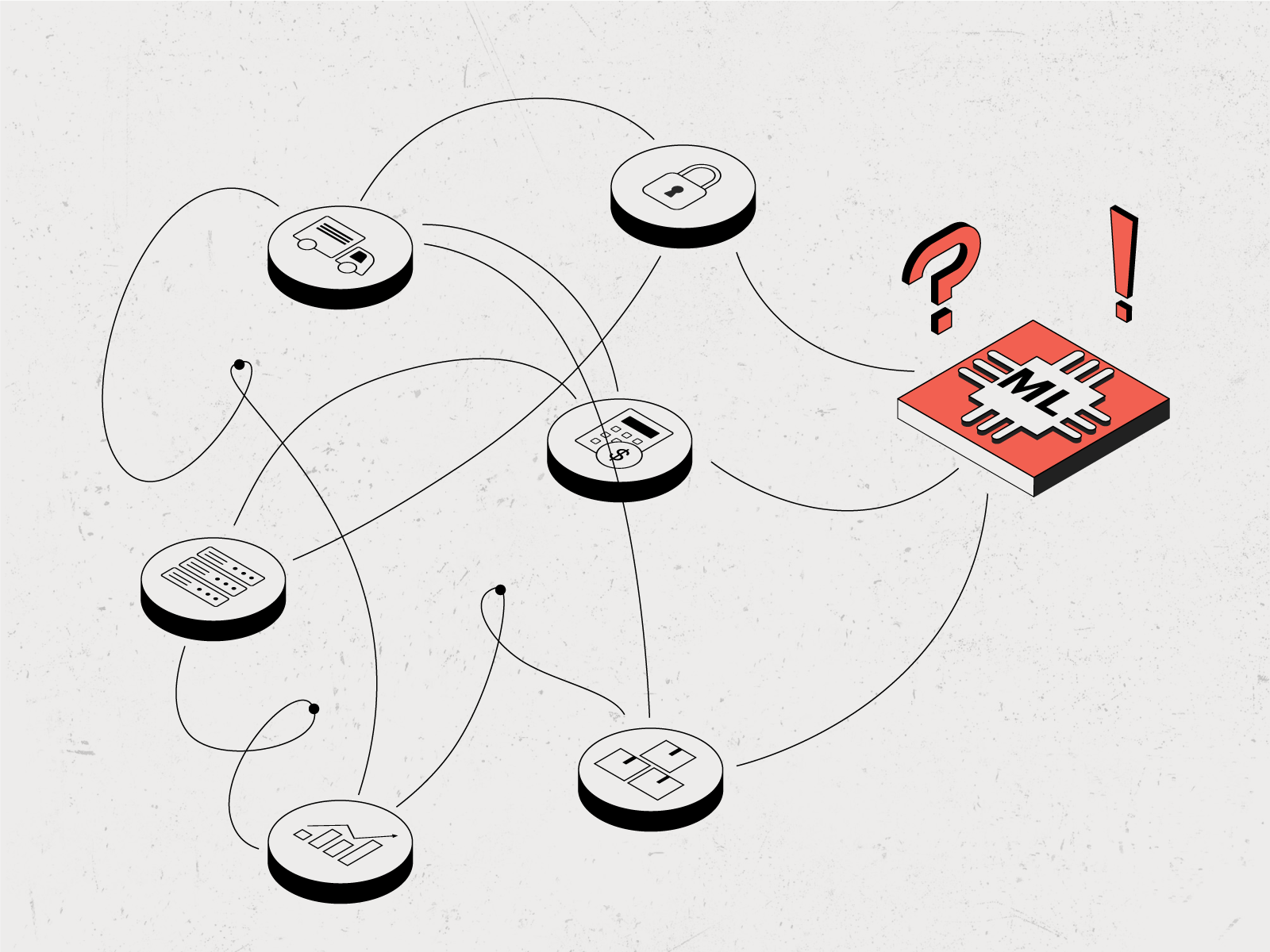
Предприниматель не хочет традиционным способом разбираться с проблемами, поскольку для этого нужно проделать много работы: обновить персонал и набрать ответственных работников, установить стандарты качества для бизнес-процессов и разработать механизмы контроля исполнения обязательств. Вместо этого он собирается нанять группу дата-сайентистов и оптимизировать логистику с помощью алгоритма — разработать программу, которая сможет сама управлять сетью складов.
Владелец интернет-магазина ожидает, что модель машинного обучения наведёт порядок в бизнесе и избавит его от проблем, которые возникали с сотрудниками.
Технически всё реально: программу можно обучить делать отчёты, прогнозировать запасы товаров на складе и выполнять прочие логистические процедуры. Для этого дата-сайентисты должны получить точные и полные данные по бизнес-процессам, которые нужно оптимизировать. Если таких данных нет, то алгоритм не сработает.
Как попробовать исправить
Модели машинного обучения подходят не каждому бизнесу, и не все компании могут подготовиться к их запуску. Поэтому, чтобы не терять впустую время и бюджет, перед общением с дата-сайентистами руководителю важно понять: какой процесс он хочет улучшить, как это можно сделать с помощью алгоритма и что после этого изменится.
Идеальный вариант — когда идею о запуске модели машинного обучения предлагают сотрудники на рабочих местах, внутренние эксперты, которые отлично знакомы с локальными бизнес-процессами и лучше всех понимают, что и как можно улучшить.
Для примера возьмём заведующего складом, который заявляет о такой проблеме: большинство сотрудников ежедневно вручную проверяют просроченные товары и из-за этого часто перерабатывают и не успевают выполнять остальные обязанности. Тут же заведующий просит разработать систему, которая сможет контролировать просрочку и позволит сотрудникам справляться со всеми задачами за смену.
Если руководитель прислушается к заведующему складом, то это повод задуматься о модели машинного обучения — посоветоваться с дата-сайентистами и аналитиками, посчитать, сколько будет стоить разработка, и понять, принесёт ли это пользу компании.
Дальше всё зависит от прогноза: компания может перейти к разработке или отказаться от идеи, поскольку для её реализации не хватит бюджета. Возможен и альтернативный вариант: руководитель просто повысит зарплату сотрудникам склада, поскольку это окажется дешевле, чем нанимать команду дата-сайентистов.
Когда руководитель знает о реальных потребностях и проблемах компании, то он может подобрать оптимальные инструменты для исправления ситуации. Всё зависит от планирования, и иногда модели машинного обучения являются лучшим решением. Планирование — это залог осмысленной работы и попадания алгоритма в продакшен.

Что делать, если ничего не помогло и проект попал в стол
Если вы участвовали в разработке модели машинного обучения и по каким-то причинам она не попала в продакшен — не расстраивайтесь и относитесь к этому как к части рабочего процесса. Вы получили опыт, не остались без зарплаты и теперь можете переключиться на что-то новое.
Если на проект не распространяется коммерческая тайна — напишите о проделанной работе в блоге и пополните портфолио. Ещё вариант — подготовьте доклад для IT-конференции и расскажите о своём кейсе другим дата-сайентистам. Выступления на конференциях помогают систематизировать накопленные знания, завести полезные знакомства и выйти из зоны комфорта — преодолеть боязнь публики, что в будущем может поспособствовать карьерному продвижению.










