Парсинг сайта вместе с Python и библиотекой Beautiful Soup: простая инструкция в три шага
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.


Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Что такое парсинг и зачем он нужен?
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP-запросы, XML и JSON
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
({
<font color="#069">"firstName"</font> : <font color="#069">"Антон"</font>,
<font color="#069">"lastName"</font> : <font color="#069">"Яценко"</font>
});Для того чтобы получить информацию в формате JSON, необходимо подготовить правильный HTTP-запрос:
var requestURL = 'test.json';
var request = new XMLHttpRequest();
request.open('GET', requestURL);
request.responseType = 'json';
request.send();
В его структуре можно выделить пять логических частей:
- var requestURL — переменная с указанием на URL-адреса с необходимой информацией;
- var request = new XMLHttpRequest () — создание нового экземпляра объекта запроса из конструктора XMLHttpRequest с помощью ключевого слова new;
- request.open ('GET', requestURL) — открытие нового запроса с использованием метода GET. Обязательно указываем нашу переменную с URL-адресом;
- request.responseType = 'json' — явно обозначаем получаемый формат данных как JSON;
- request.send () — отправляем запрос на получение информации.
XML — язык разметки, который определяет набор правил для кодирования документов, записанных в текстовом формате. От JSON отличается большей сложностью — проще всего увидеть это на примере:
<font color="#069"><person></font>
<font color="#069"><firstname></font>Антон<font color="#069"></firstname></font>
<font color="#069"><lastname></font>Яценко<font color="#069"></lastname></font>
<font color="#069"></person></font>Чтобы получить информацию, хранящуюся на сервере как XML или HTML, потребуется воспользоваться той же библиотекой, как и в случае с JSON, но в качестве responseType следует указать Document.
var requestURL = 'test.txt';
var request = new XMLHttpRequest();
request.open('GET', requestURL);
request.responseType = 'document';
request.send();Какой из форматов лучше выбрать? Кажется, что JSON легче для восприятия. Но выбор между определённым форматом HTTP-запроса зависит и от решаемой задачи. Подробно обсудим это в будущих материалах.
А сегодня разберёмся с основами веб-скрейпинга — используем стандартные библиотеки Python и научимся работать с различными полезными инструментами.
Три этапа парсинга
Самый простой способ разобраться в парсинге — что-то спарсить. Создадим программу, которая будет показывать информацию о погоде в вашем городе.
Для этого пройдём через три последовательных шага:
- Подключим библиотеки, которые помогут нам спарсить информацию с помощью Python (как установить Python на Windows, macOS и Linux — смотрите в нашей статье).
- Зайдём на сайт, с которого мы планируем парсить информацию, и изучим его исходный код. Важно будет найти те элементы, которые содержат нужную информацию.
- Напишем код и спарсим данные.
Шаг 1
Подключаем библиотеки
Подключаем библиотеки
В разных языках программирования есть свои библиотеки для парсинга информации с сайтов. Например, в JavaScript используется библиотека Puppeteer, а на Python популярна библиотека Beautiful Soup. Принципы их работы похожи. Но сначала нужно разобраться с запуском Python на компьютере.
Просто так написать код в текстовом документе не получится. Можно воспользоваться одним из способов:
- Использовать терминал на macOS или Linux, или воспользоваться командной строкой в Windows. Для этого предварительно потребуется установить Python в систему. Мы подробно писали об этом в отдельном материале.
- Воспользоваться одним из онлайн-редакторов, позволяющих работать с кодом на Python без его установки: Google Colab, python.org, onlineGDB или другим.
После установки на свой компьютер Python или запуска онлайн-редактора кода можно переходить к импорту библиотек.
BeautifulSoup — библиотека, которая позволяет работать с HTML- и XML-кодом. Подключить её очень просто:
from bs import BeautifulSoupДополнительно потребуется библиотека requests, которая помогает сделать запрос на нужный нам адрес сайта. Импортируется она в одну строку:
import requestsВсё. Все библиотеки готовы к работе — они помогут получить исходный код сайта и найти в нём нужную информацию.
Важно! Библиотека Beautiful Soup чаще всего предустановлена в используемой среде разработке или в Jupyter Notebook, но иногда её нет. Если при попытке её импорта вы получаете ошибку, то выполните команду для её установки, а потом повторите запросы на импорт:
pip3 install bs4
Шаг 2
Изучаем исходный код сайта
В качестве источника прогнозы погоды будем использовать сайт «Яндекс.Погода». Перейдём на него и в строке поиска найдём свой город. В нашем случае это будет Москва.
Посмотрите внимательно на адресную строку — она ещё пригодится нам в дальнейшем: https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526.
Обычно в адресной строке там нет названия города, а есть географические координаты точки, для которой показана текущая погода (у нас это центр Москвы).
Теперь посмотрим на исходный код страницы и найдём место, где хранится текущая температура. Нас интересует обведённый на скриншоте сайта блок:
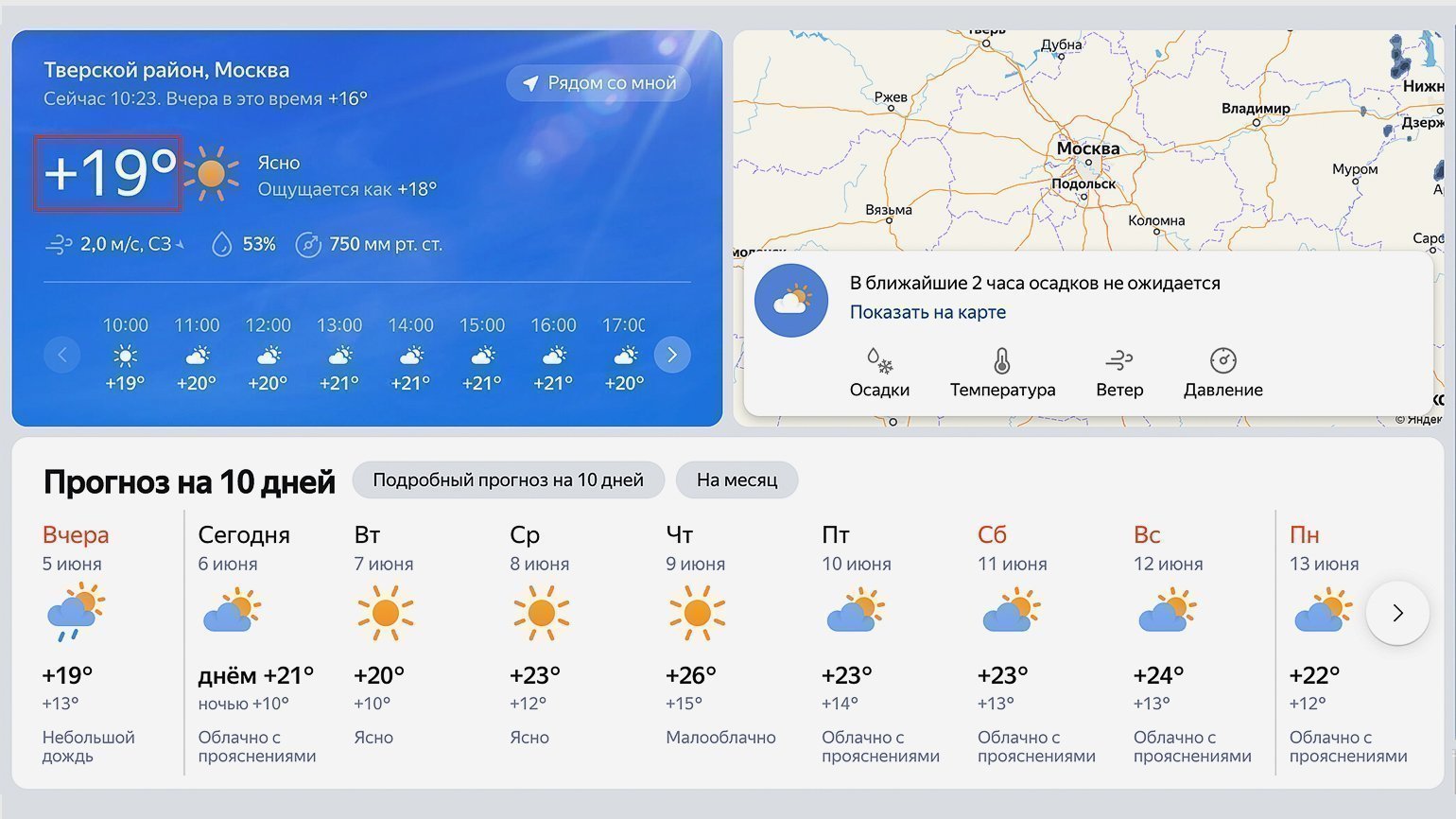
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
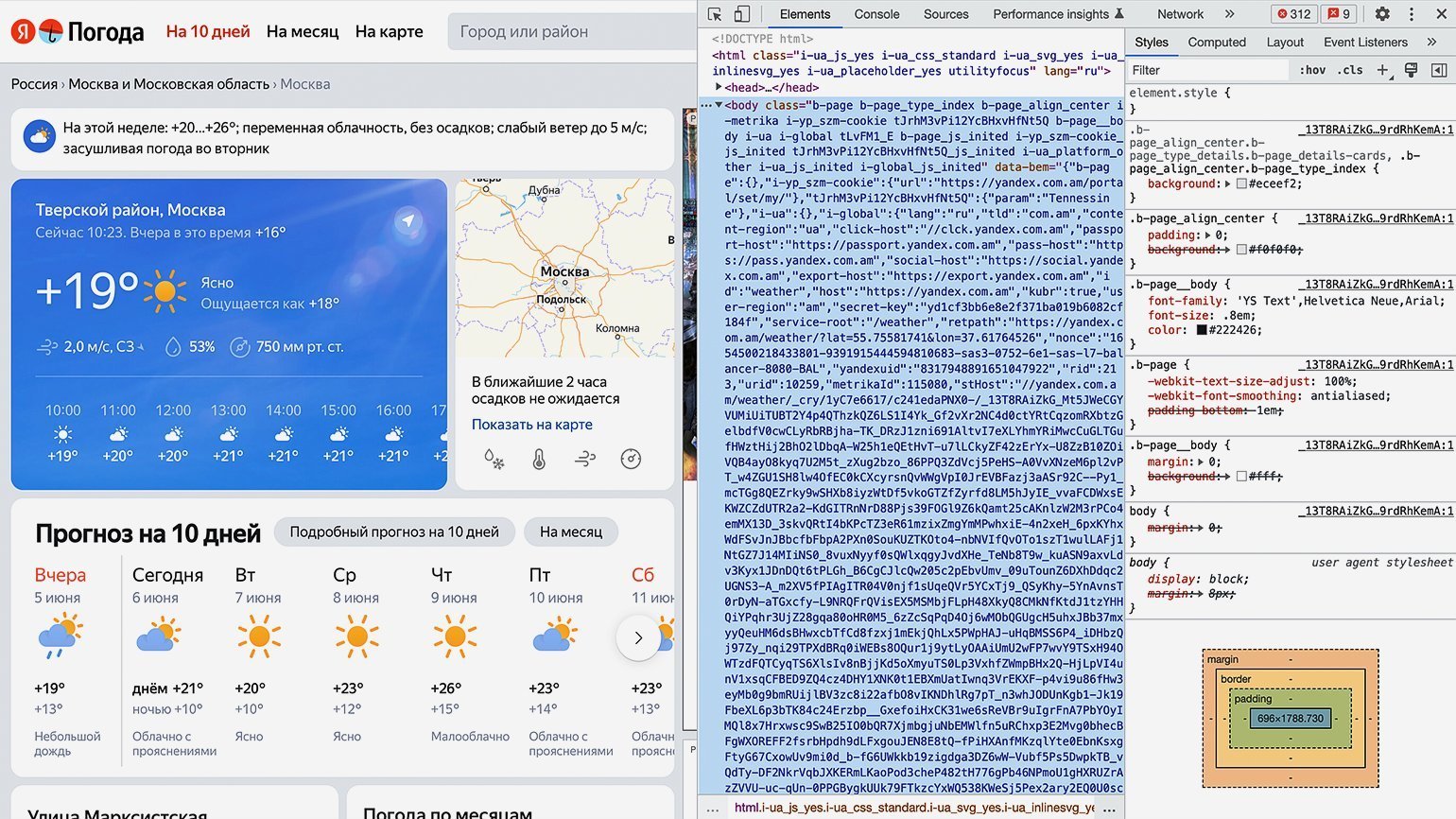
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега <body>. Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
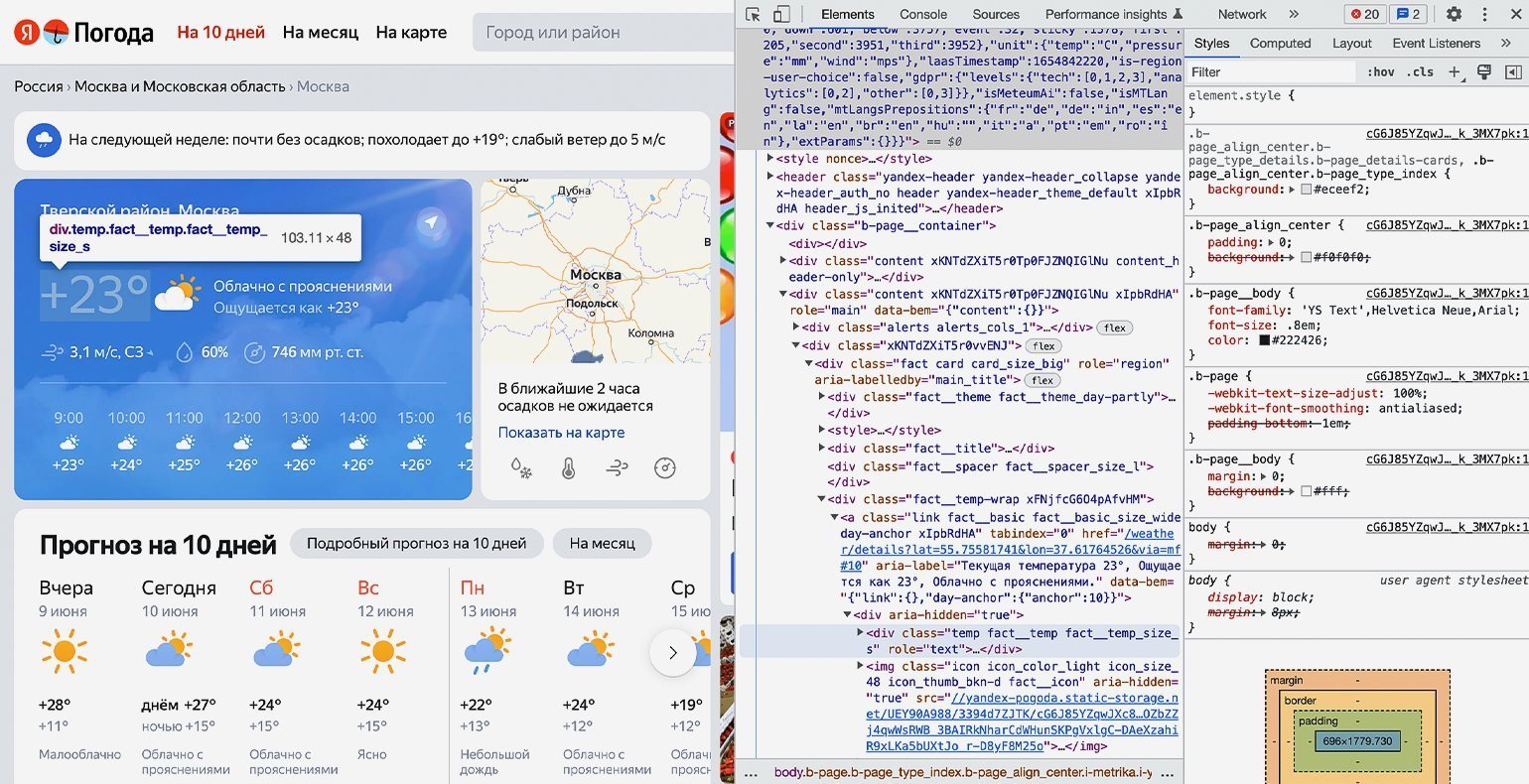
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
Шаг 3
Пишем код и получаем необходимую информацию
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента <span="temp fact__temp fact__temp_size_s">. Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:
url = 'https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526'Создадим к ней запрос и посмотрим, что вернёт сервер:
response = requests.get(url)
print(response)В нашем случае получаем ответ:
<Response [200]>Отлично. Ответ «200» значит, что библиотека requests работает правильно и сервер отдаёт нам информацию со страницы.
Теперь получим исходный код, используя библиотеку Beautiful Soup и сразу выведем результат на экран:
bs = BeautifulSoup(response.text,"lxml")
print(bs)После выполнения на экране виден код всей страницы полностью:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это <span="temp fact__temp fact__temp_size_s">. Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')И сразу выведем результат на экран с помощью print:
print(temp)Получаем:
<span class="temp__value temp__value_with-unit">+17</span> Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)Результат:
+17Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Скрапинг веб-сайтов с помощью Python — мастер-класс для новичков
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Парсинг динамических сайтов c помощью Python и библиотеки Selenium
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Резюме
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.
Python для всех
Вы освоите Python на практике и создадите проекты для портфолио — телеграм-бот, веб-парсер и сайт с нуля. А ещё получите готовый план выхода на удалёнку и фриланс. Спикер — руководитель отдела разработки в «Сбере».
Пройти бесплатно

