Pandas DataFrame: как упоительно работать с данными
Исчерпывающий гайд по самому популярному фреймворку в ML от эксперта по data science и машинному обучению.



Мирко Стоилькович
Об авторе
Ph. d. в области машиностроения, доцент Нишского университета. Основная специализация: гибридные методы оптимизации и машинное обучение в энергетике. Владеет несколькими языками программирования, среди которых Python, C#, C и JavaScript.
Pandas DataFrame активно применяют в data science, машинном обучении, научных вычислениях и многих других областях, связанных с активным использованием данных.
Эти структуры во многом похожи на SQL, таблицы Excel и Calc. Однако зачастую DataFrame быстрее, проще в использовании и мощнее — ведь это неотъемлемая часть экосистемы Python и NumPy.
Из этой статьи вы узнаете:
- Что такое DataFrame в Pandas и как его создать.
- Как получить доступ, изменить, добавить, отсортировать, отфильтровать и удалить данные.
- Как обрабатывать пропущенные значения.
- Как работать с временными рядами.
- Как быстро визуализировать данные.
Содержание:
- Применение арифметических операций
- Применение функций NumPy и SciPy
- Сортировка в Pandas DataFrame
- Фильтрация данных
- Работа со статистическими данными
- Обработка отсутствующих данных
Что такое Pandas DataFrame
Pandas DataFrame (или просто дата фреймы) — это структуры, которые состоят из:
- данных, организованных в двух измерениях — строках и столбцах;
- и соответствующих этим строкам и столбцам меток.
Мы будем писать код в интерактивной консоли Python. Чтобы начать работу с Pandas, нужно импортировать её модуль:
>>> import pandas as pdЕсли в вашем окружении нет библиотеки Pandas, установите её с помощью пакетного менеджера PIP.
Сразу приступим к практике. Представьте такую ситуацию: наша компания ищет Python-разработчиков в новую команду. Кандидатов так много, что отбирать их вручную, было бы слишком долго, поэтому нас попросили написать программу для анализа результатов тестирования.
Нас интересуют имена кандидатов (name), города проживания (city), возраст (age) и количество баллов, которое они получили в тесте по программированию (py-score):
| name | city | age | py-score | |
|---|---|---|---|---|
| 101 | Xavier | Mexico City | 41 | 88.0 |
| 102 | Ann | Toronto | 28 | 79.0 |
| 103 | Jana | Prague | 33 | 81.0 |
| 104 | Yi | Shanghai | 34 | 80.0 |
| 105 | Robin | Manchester | 38 | 68.0 |
| 106 | Amal | Cairo | 31 | 61.0 |
| 107 | Nori | Osaka | 37 | 84.0 |
В этой таблице первая строка содержит метки столбцов (name, city и так далее). Первый столбец содержит метки строк (101, 102 и так далее). Все остальные ячейки заполняются значениями данных.
Есть несколько способов создать data frame. В большинстве случаев используют конструктор и передают данные в виде двумерного списка, кортежа или массива NumPy. Также их можно переформатировать в словарь, Pandas Series или другие типы данных, которые в этой статье не рассматриваются.
Предположим, нам нужен словарь:
>>> data = {
... 'name': ['Xavier', 'Ann', 'Jana', 'Yi', 'Robin', 'Amal', 'Nori'],
... 'city': ['Mexico City', 'Toronto', 'Prague', 'Shanghai',
... 'Manchester', 'Cairo', 'Osaka'],
... 'age': [41, 28, 33, 34, 38, 31, 37],
... 'py-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
... }
>>> row_labels = [101, 102, 103, 104, 105, 106, 107]
В данном случае data— это переменная Python, которая ссылается на словарь, содержащий данные кандидатов. Она содержит метки столбцов:
- 'name'
- 'city'
- 'age'
- 'py-score'
А row_labels ссылается на список, содержащий метки строк, представляющих собой числа в диапазоне от 101 до 107.
Создадим Pandas DataFrame:
>>> df = pd.DataFrame(data=data, index=row_labels)
>>> df
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0Здесь df — это переменная, содержащая ссылку на наш объект DataFrame. Он выглядит точно так же, как и приведённая выше таблица кандидатов, и имеет следующие функции:
- Метки строк от 101 до 107;
- Метки столбцов 'name', 'city', 'age' и 'py-score';
- Данные: имена кандидатов, города, возраст и результаты тестов Python.
В таблице представлены метки и данные из df: красные — метки столбцов, синие — метки строк, зелёные — данные.
| 0 | name | city | age | py-score |
|---|---|---|---|---|
| 101 | Xavier | Mexico City | 41 | 88.0 |
| 102 | Ann | Toronto | 28 | 79.0 |
| 103 | Jana | Prague | 33 | 81.0 |
| 104 | Yi | Shanghai | 34 | 80.0 |
| 105 | Robin | Manchester | 38 | 68.0 |
| 106 | Amal | Cairo | 31 | 61.0 |
| 107 | Nori | Osaka | 37 | 84.0 |
Иногда объекты Pandas DataFrames настолько большие, что просматривать все строки одновременно становится неудобно. Чтобы увидеть первые несколько элементов, воспользуйтесь методом head(), а для показа последних — tail(). С помощью необязательного параметра n в скобках можно регулировать количество строк, которое вы хотите отобразить:
>>> df.head(n=2)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0>>> df.tail(n=2)
name city age py-score
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0Примечание. В зависимости от ситуации Pandas DataFrame можно рассматривать как словарь столбцов или как Pandas Series с дополнительными функциями.
Доступ к столбцам в Pandas DataFrame можно получить так же, как к значениям из словаря, — это самый удобный способ:
>>> cities = df['city']
>>> cities
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: objectЕсли имя столбца — строка, представленная в виде действительного идентификатора Python, для доступа к нему можно также использовать запись через точку, то есть тем же путём, как и для атрибута экземпляра класса. Попробуем извлечь таким способом всё тот же столбец с меткой 'city', содержащей данные о местонахождении наших кандидатов:
>>> df.city
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: objectОбратите внимание: мы извлекли как данные, так и соответствующие метки строк:
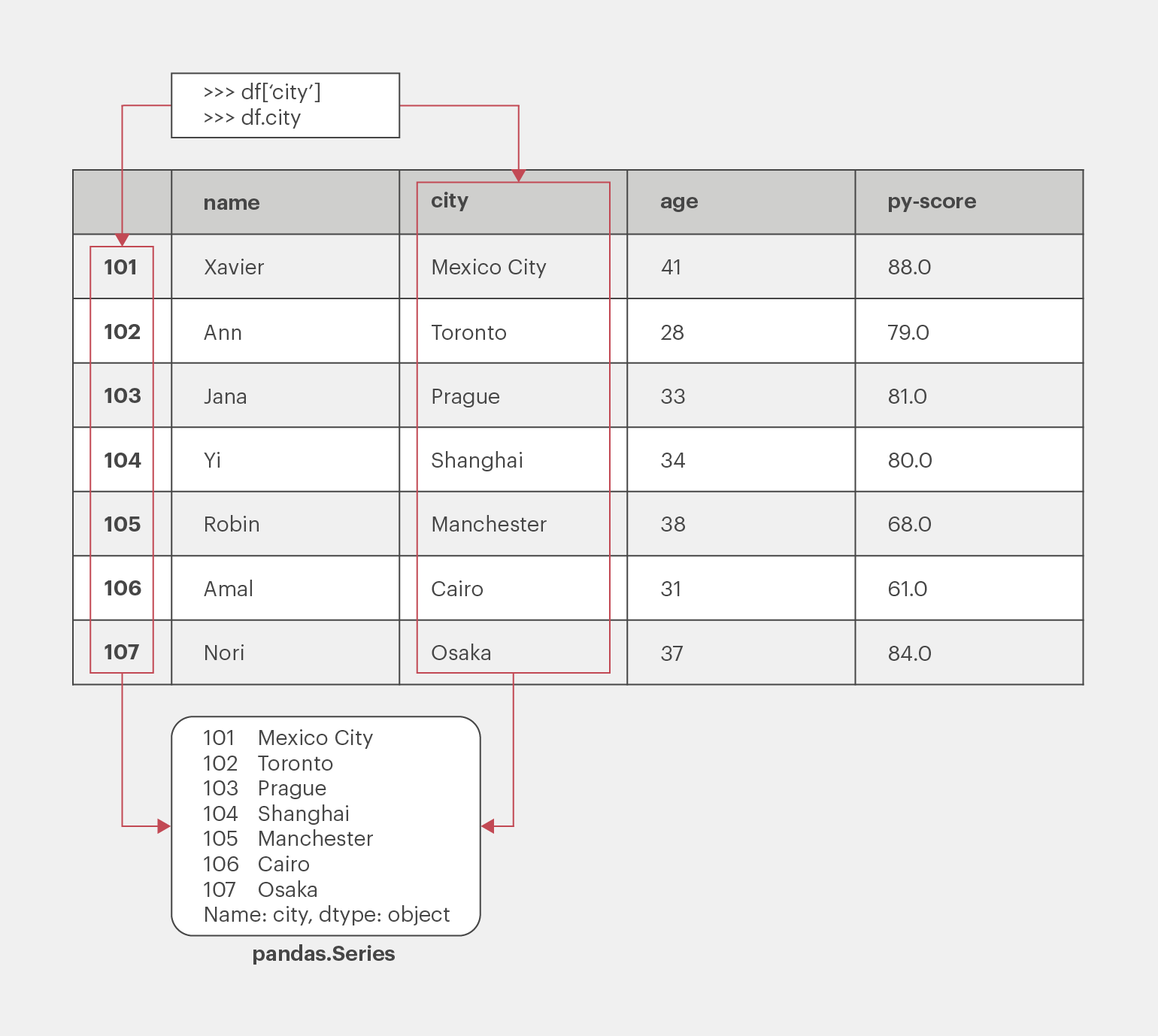
Каждый столбец Pandas DataFrame — это экземпляр класса Pandas.Series — структуры, которая содержит одномерные данные и их метки. Вызвать любой элемент из объектов Series можно так же, как из словаря, то есть используя его метку в качестве ключа:
>>> cities[102]
'Toronto'В данном случае 'Toronto' — это значение данных, а 102 — соответствующая метка. В следующем разделе приведены другие способы вызвать элемент Pandas DataFrame.
Доступ ко всей строке можно получить с помощью аксессора .loc[]:
>>> df.loc[103]
name Jana
city Prague
age 33
py-score 81.0
Name: 103, dtype: objectНа этот раз мы извлекли строку, соответствующую метке 103, содержащую данные кандидатки по имени Jana. Кроме самих значений данных мы видим и метки соответствующих столбцов:
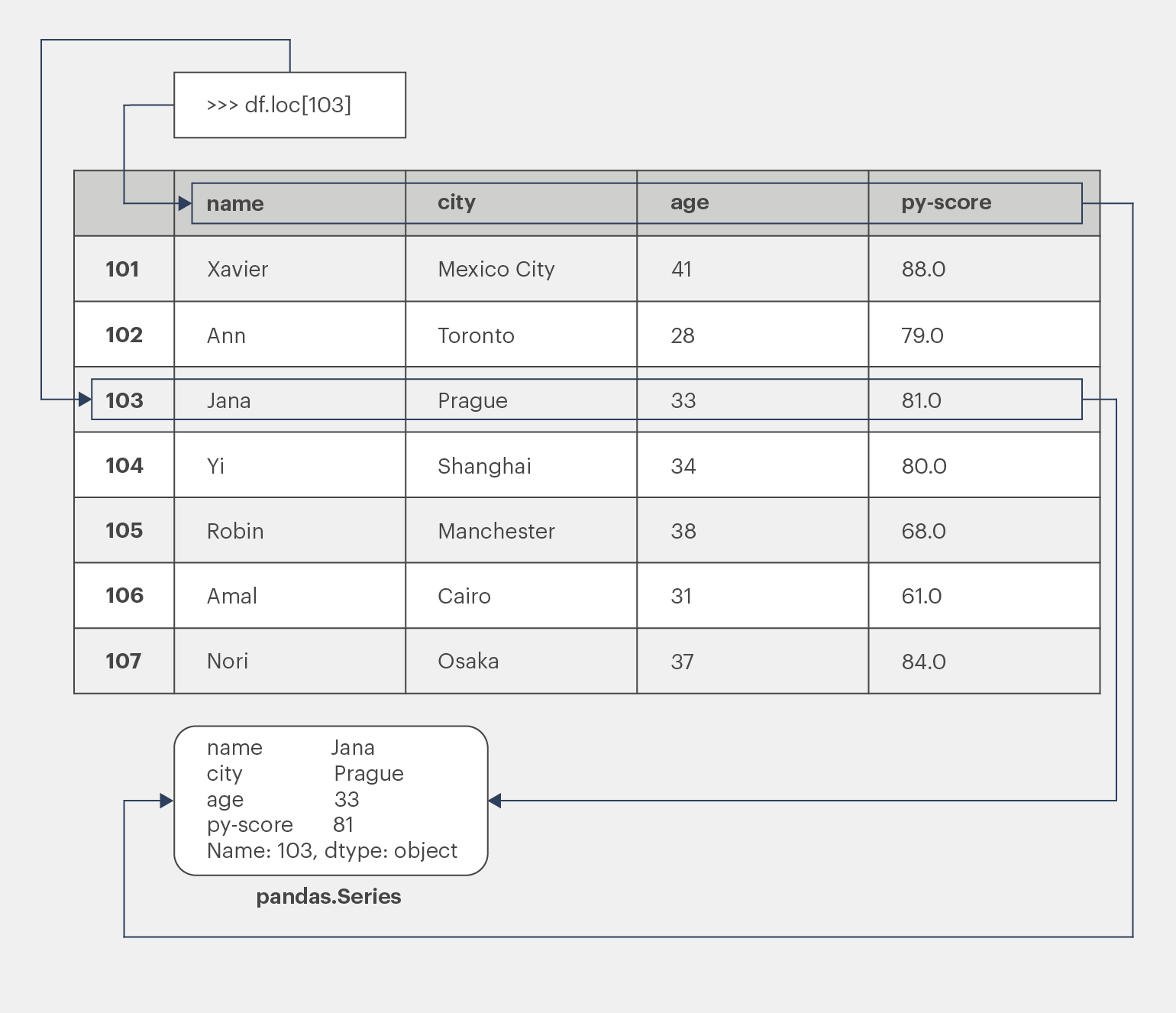
Возвращаемая строка — тоже экземпляр Pandas.Series.
Создание Pandas DataFrame
Как уже упоминалось, существует несколько способов создать дата фрейм. В этом разделе вы научитесь делать это с помощью конструктора DataFrame, используя:
- словари Python;
- списки Python;
- двумерные массивы NumPy;
- файлы.
Есть и другие методы, о которых вы можете узнать из официальной документации.
Начнём с импорта NumPy, который пригодится нам дальше:
>>> import numpy as np
>>> import Pandas as pdВот и всё. Теперь создадим несколько видов DataFrame.
Создание из словарей
Как вы уже знаете, Pandas DataFrame можно создать из словаря Python:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100Ключи словаря — это метки столбцов DataFrame, а значения словаря — это значения данных в соответствующих столбцах DataFrame. Они могут содержаться в кортеже, списке, одномерном массиве NumPy, объекте Pandas Series или в одном из нескольких других типов данных. Можно также указать значение, которое будет скопировано по всему столбцу.
Можно менять порядок столбцов с помощью параметра columns, а меток строк — с помощью index:
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 3Как видите, мы указали метки строк 100, 200 и 300, при этом изменив порядок столбцов: z, y, x.
Создание из списков
Другой способ создать Pandas DataFrame — использовать список словарей:
>>> l = [{'x': 1, 'y': 2, 'z': 100},
... {'x': 2, 'y': 4, 'z': 100},
... {'x': 3, 'y': 8, 'z': 100}]
>>> pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100Опять же, ключи словаря — это метки столбцов, а значения словаря — это значения данных в DataFrame.
В качестве значений данных можно также использовать вложенные списки и даже списки списков. В этих случаях лучше явно указывать метки столбцов, строк или и того и другого:
>>> l = [[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]]
>>> pd.DataFrame(l, columns=['x', 'y', 'z'])
x y z
0 1 2 100
1 2 4 100
2 3 8 100Аналогично можно использовать список кортежей — просто замените ими вложенные списки в приведённом выше примере.
Создание из массивов NumPy
Вы можете передать двумерный массив NumPy в DataFrame так же, как и в вышеприведённом случае с вложенным списком:
>>> arr = np.array([[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]])
>>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
>>> df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100Хотя этот пример выглядит похожим на предыдущий, у него есть одно преимущество: вы можете указать необязательный параметр copy. Когда для copy установлено значение False (настройка по умолчанию), данные из массива NumPy не копируются. Это означает, что исходные данные из массива назначаются DataFrame Pandas. Если вы измените массив, ваш DataFrame тоже изменится:
>>> arr[0, 0] = 1000
>>> df_
x y z
0 1000 2 100
1 2 4 100
2 3 8 100Как видите, когда вы изменяете первый элемент arr, вы также изменяете df_.
Примечание. Отсутствие копирования значений данных может значительно сэкономить время и вычислительную мощность при работе с большими объёмами данных.
Если же указать copy=True, вместо фактических значений в df_ будет создана копия значений arr.
Создание из файлов
Вы можете сохранять и загружать данные и метки из Pandas DataFrame в различные типы файлов, включая CSV, Excel, SQL, JSON и другие, и наоборот. Это очень мощная функция.
Сохраним DataFrame кандидатов в файл CSV с помощью метода to_csv():
>>> df.to_csv('data.csv')Приведённый выше оператор создаст CSV-файл, вызываемый с помощью data.csv из рабочего каталога:
,name,city,age,py-score
101,Xavier,Mexico City,41,88.0
102,Ann,Toronto,28,79.0
103,Jana,Prague,33,81.0
104,Yi,Shanghai,34,80.0
105,Robin,Manchester,38,68.0
106,Amal,Cairo,31,61.0
107,Nori,Osaka,37,84.0
Загрузим его с помощью read_csv():
>>> pd.read_csv('data.csv', index_col=0)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0index_col=0 указывает на то, что метки строк должны быть расположены в первом столбце CSV-файла.
Получение меток и данных
Теперь, когда мы создали DataFrame, можно извлекать из него информацию. Для этого типа объектов в Pandas доступны следующие действия:
- получение и изменение меток строк и столбцов в виде последовательностей;
- представление данных в виде массивов NumPy;
- проверка и настройке типов данных;
- анализ размеров объектов DataFrame.
Метки Pandas DataFrame как последовательность
Можно получить метки строк DataFrame с помощью атрибутов index и метки столбцов с помощью columns:
>>> df.index
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64')
>>> df.columns
Index(['name', 'city', 'age', 'py-score'], dtype='object')Как и в любой другой последовательности в Python, вы можете получить любой элемент объекта df.columns:
>>> df.columns[1]
'city'Помимо этих доступны другие операции последовательности, включая итерацию по меткам строк или столбцов. Однако в них редко возникает необходимость, так как Pandas предлагает другие виды итераций в DataFrames, которые вы увидите далее.
Этот подход можно использовать и для изменения меток:
>>> df.index = np.arange(10, 17)
>>> df.index
Int64Index([10, 11, 12, 13, 14, 15, 16], dtype='int64')
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0В этом примере numpy.arange() используется для создания новой последовательности меток строк, которая содержит целые числа от 10 до 16. Имейте в виду: если вы попытаетесь изменить определённый элемент index или columns, вы получите ошибку TypeError.
Узнать больше о методе arange() можно в статье NumPy arange(): How to Use np.arange()
Данные в виде массивов NumPy
Иногда вам может понадобиться извлечь данные из Pandas DataFrame без меток. Чтобы получить массив NumPy с немаркированными данными, используйте метод to_numpy() или свойство values:
>>> df.to_numpy()
array([['Xavier', 'Mexico City', 41, 88.0],
['Ann', 'Toronto', 28, 79.0],
['Jana', 'Prague', 33, 81.0],
['Yi', 'Shanghai', 34, 80.0],
['Robin', 'Manchester', 38, 68.0],
['Amal', 'Cairo', 31, 61.0],
['Nori', 'Osaka', 37, 84.0]], dtype=object)И to_numpy(), и values дают один и тот же результат: они возвращают массив NumPy с данными из DataFrame Pandas:
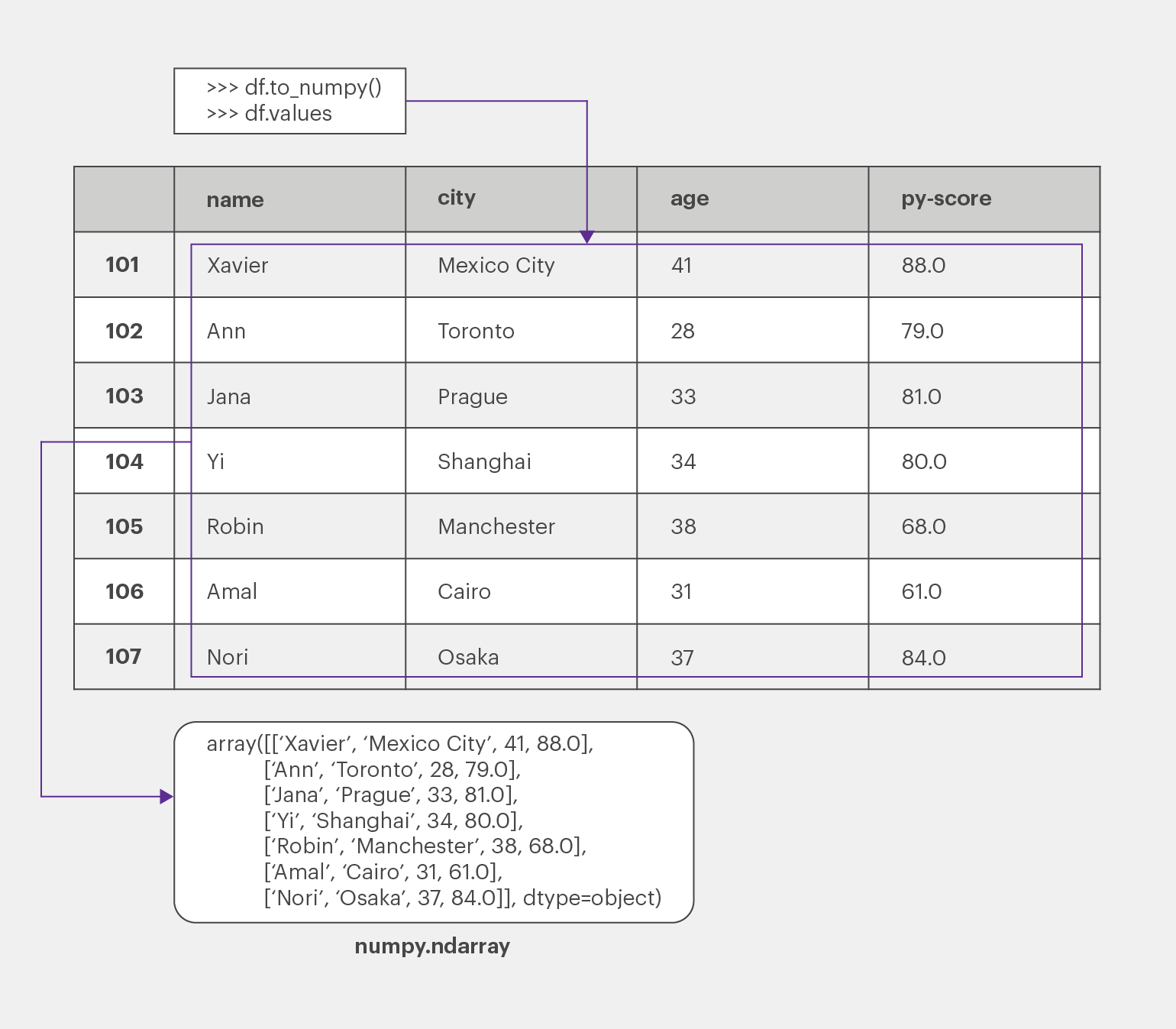
Однако в официальной документации Pandas рекомендуется использовать to_numpy(), потому что это более гибкий инструмент с полезными параметрами:
- dtype — используется, когда нужно указать тип данных результирующего массива. Значение умолчанию — None;
- copy — если хотите использовать исходные данные из DataFrame, установите этот параметр в False. Если хотите скопировать данные, установите True.
Тем не менее вам, скорее всего, чаще будет встречаться values, особенно в старых программах, потому что to_numpy() впервые был представлен только в Pandas 0.24.0.
Типы данных
Типы данных, или dtypes, важны, поскольку определяют объём памяти, который использует ваш DataFrame, скорость вычислений и уровень точности расчётов.
Pandas в основном построен на типах данных NumPy. Однако в Pandas 1.0 появились собственные дополнительные типы:
- BooleanDtype и BooleanArray — для поддержки отсутствующих логических значений и трёхзначной логики Клини.
- StringDtype и StringArray — специальные строковые типы.
Типы данных для каждого столбца Pandas DataFrame можно получить с помощью dtypes:
>>> df.dtypes
name object
city object
age int64
py-score float64
dtype: objectКак видите, dtypes возвращает объект Series с именами столбцов в качестве меток и соответствующими типами данных в качестве значений.
Если вы хотите изменить тип данных одного или нескольких столбцов, используйте astype():
>>> df_ = df.astype(dtype={'age': np.int32, 'py-score': np.float32})
>>> df_.dtypes
name object
city object
age int32
py-score float32
dtype: objectСамый важный и единственный обязательный параметр для astype() — dtype. Его можно задавать как тип данных или словарь. В случае со словарём ключи будут именами столбцов, а значения — типами данных.
Как видите, типы данных для столбцов age и py-score в DataFrame df — int64 и float64 соответственно, то есть 64-битные (или 8-байтовые) целые числа и числа плавающей точкой. А в df_ для тех же столбцов устанавливаются 32-битные (4-байтовые) типы.
Размер Pandas DataFrame
Атрибуты ndim, size и shape отображают, соответственно, количество измерений, количество значений данных по каждому измерению и общее количество значений данных:
>>> df_.ndim
2
>>> df_.shape
(7, 4)
>>> df_.size
28Экземпляры DataFrame имеют два измерения (строки и столбцы), поэтому ndim имеет значение 2. С другой стороны, у объекта Series только одно измерение, поэтому для него ndim будет отображаться как 1.
В атрибуте shape хранится кортеж с количеством строк (в данном случае 7) и столбцов (4). Наконец, size отображает целое число, равное количеству значений в DataFrame (28).
С помощью memory_usage() можно узнать, сколько памяти занимает каждый столбец:
>>> df_.memory_usage()
Index 56
name 56
city 56
age 28
py-score 28
dtype: int64Как видите, memory_usage() возвращает объект Series с именами столбцов в качестве меток и памяти в байтах в качестве данных. Если вы хотите исключить использование памяти столбцом, содержащим метки строк, установите необязательный аргумент index=False.
В приведённом выше примере последние два столбца age и py-score используют по 28 байтов памяти: столбцы имеют семь значений, каждое из которых представляет собой целое число, занимающее 32 бита, или 4 байта. 7 целых чисел, умноженных на 4 байта, дают в общей сложности 28 байтов.
Получение доступа и изменение данных
Вы уже знаете, как вызвать определённую строку или столбец Pandas DataFrame в виде объекта Series:
>>> df['name']
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
>>> df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: objectВ первом примере доступ к столбцу осуществляется с помощью name — так же, как к элементу из словаря, с использованием его метки в качестве ключа. Аналогично, если метка столбца — допустимый идентификатор Python, вы можете использовать для доступа к нему оператор точку. Во втором примере получаем строку по метке с помощью loc[].
Получение данных с помощью аксессоров
В дополнение к loc[], Pandas предлагает метод iloc[], который извлекает строку или столбец по их целочисленному индексу. В большинстве случаев можно использовать любой из них:
>>> df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: object
>>> df.iloc[0]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: objectdf.loc[10] возвращает строку с меткой 10. Точно так же df.iloc[0] возвращает строку с отсчитываемым от нуля индексом 0, то есть первую строку. Как видите, оба оператора возвращают одну и ту же строку в качестве объекта Series.
Всего у Pandas четыре аксессора:
- loc[] — принимает метки строк и столбцов, выдаёт Series или DataFrames. Можно использовать как для получения целых строк или столбцов, так и для их частей.
- iloc[] — принимает отсчитываемые от нуля индексы строк и столбцов, выдает Series или DataFrames.Также годится и для целых строк (столбцов), и для их частей.
- at[] — принимает метки строк и столбцов, выдаёт одно значение данных.
- iat[] — принимает отсчитываемые от нуля индексы строк и столбцов, выдаёт одно значение данных.
loc[] и iloc[] более эффективные: они поддерживают срезы и индексирование в стиле NumPy. Получим с их помощью доступ к столбцу:
>>> df.loc[:, 'city']
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
>>> df.iloc[:, 1]
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: objectdf.loc[:, 'city'] выдаёт столбец city. Конструкция среза [ :] в месте метки строки означает, что должны быть включены все строки. df.iloc[:, 1] выдаёт тот же столбец, поскольку отсчитываемый от нуля индекс 1 относится ко второму столбцу city.
Как и в случае с NumPy, вы можете использовать срезы вместе со списками или массивами вместо индексов, чтобы получить несколько строк или столбцов:
>>> df.loc[11:15, ['name', 'city']]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal Cairo
>>> df.iloc[1:6, [0, 1]]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal CairoСовет. Не используйте кортежи вместо списков или массивов целых чисел для получения обычных строк или столбцов. Они предназначены для представления нескольких измерений в NumPy и Pandas, а также для иерархической или многоуровневой индексации в Pandas.
Как видно из представленных выше примеров, можно использовать:
- срезы для получения строк с метками от 11 до 15, которые эквивалентны индексам от 1 до 5;
- списки для получения столбцов name и city, которые эквивалентны индексам 0 и 1.
Оба оператора возвращают пересечение из искомых пяти строк и двух столбцов.
Следует отметить важное различие между loc[] и iloc[]. Когда мы задали в loc[] метки строк 11:15, то получили строки 11–15. А когда в iloc[] задали индексы 1:6, то получили строки с индексами от 1 до 5.
Причина в том, что в iloc[] остановка среза исключительная, то есть второй индекс не показывается в выдаваемых значениях. Это похоже на срезы в Python и массивы NumPy. А в loc[] индексы инклюзивны, то есть оба включаются в выдаваемые значения.
Вы можете пропускать строки и столбцы в iloc[] так же, как и при нарезке кортежей, списков и массивов NumPy:
>>> df.iloc[1:6:2, 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: objectВ этом примере мы указываем нужные индексы строк с помощью среза 1:6:2. Это означает, что выборка элементов начинается со строки с индексом 1 (вторая строка), останавливается перед строкой с индексом 6 (седьмая строка) и пропускает каждую вторую строку.
Вместо среза вы можете использовать встроенный класс Python slice(), а также numpy.s[] или pd.IndexSlice[]:
>>> df.iloc[slice(1, 6, 2), 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
>>> df.iloc[np.s_[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
>>> df.iloc[pd.IndexSlice[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: objectИспользуя loc[] и iloc[], можно также получать определённые значения данных. Однако, когда вам нужно только одно значение, Pandas рекомендует использовать специализированные методы доступа at[] и iat[]:
>>> df.at[12, 'name']
'Jana'
>>> df.iat[2, 0]
'Jana'Здесь at[] используется для получения имени одного кандидата, с помощью соответствующих меток столбца и строки, а iat[] для получения того же имени с помощью индексов.
Установка данных с помощью аксессоров
Чтобы изменить DataFrame через аксессор, нужно задать последовательность Python, массив NumPy или число:
>>> df.loc[:, 'py-score']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
>>> df.loc[:13, 'py-score'] = [40, 50, 60, 70]
>>> df.loc[14:, 'py-score'] = 0
>>> df['py-score']
10 40.0
11 50.0
12 60.0
13 70.0
14 0.0
15 0.0
16 0.0
Name: py-score, dtype: float64Оператор df.loc[:13, 'py-score'] = [40, 50, 60, 70] изменяет первые четыре элемента в строках от 10 до 13 столбца py-score, используя значения из предоставленного списка. df.loc[14:, 'py-score'] = 0 устанавливает остальные значения в этом столбце в 0.
В следующем примере показано, как получить доступ к элементам через iloc[], используя отрицательные индексы:
>>> df.iloc[:, -1] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0])
>>> df['py-score']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64Здесь мы изменили последний столбец ('py-score'), который соответствует целочисленному индексу столбца -1.
Вставка и удаление данных
Pandas предоставляет несколько удобных методов для вставки и удаления строк и столбцов.
Вставка и удаление строк
Допустим, нам нужно добавить нового человека в свой список кандидатов на работу. Для этого создадим новый объект Series:
>>> john = pd.Series(data=['John', 'Boston', 34, 79],
... index=df.columns, name=17)
>>> john
name John
city Boston
age 34
py-score 79
Name: 17, dtype: object
>>> john.name
17Объект john хранит метки, соответствующие меткам столбцов из df, поэтому нам понадобится index=df.columns.
Поместим новую строку john в конец df с помощью append():
>>> df = df.append(john)
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
17 John Boston 34 79.0Обратите внимание, как Pandas использует атрибут john.name со значением 17, чтобы указать метку для новой строки.
Мы добавили новую строку с помощью append(). Удалить её можно с помощью метода drop(), указав параметр labels:
>>> df = df.drop(labels=[17])
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0Если вы зададите inplace=True, исходный DataFrame будет изменён, а метод вернёт None.
Вставка и удаление столбцов
Самый простой способ вставить столбец в DataFrame — следовать той же процедуре, которую используют при добавлении элемента в словарь. Например, вот как можно добавить столбец, содержащий баллы кандидатов по тесту JavaScript:
>>> df['js-score'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0])
>>> df
name city age py-score js-score
10 Xavier Mexico City 41 88.0 71.0
11 Ann Toronto 28 79.0 95.0
12 Jana Prague 33 81.0 88.0
13 Yi Shanghai 34 80.0 79.0
14 Robin Manchester 38 68.0 91.0
15 Amal Cairo 31 61.0 91.0
16 Nori Osaka 37 84.0 80.0Вы можете также добавить новый столбец с одним значением:
>>> df['total-score'] = 0.0
>>> df
name city age py-score js-score total-score
10 Xavier Mexico City 41 88.0 71.0 0.0
11 Ann Toronto 28 79.0 95.0 0.0
12 Jana Prague 33 81.0 88.0 0.0
13 Yi Shanghai 34 80.0 79.0 0.0
14 Robin Manchester 38 68.0 91.0 0.0
15 Amal Cairo 31 61.0 91.0 0.0
16 Nori Osaka 37 84.0 80.0 0.0В DataFrame df теперь есть дополнительный столбец, заполненный нулями. Однако такой способ не позволяет указать расположение нового столбца. Если это важно, можно использовать insert(). Попробуем вставить ещё один столбец с результатами теста Django:
>>> df.insert(loc=4, column='django-score',
... value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0]))
>>> df
name city age py-score django-score js-score total-score
10 Xavier Mexico City 41 88.0 86.0 71.0 0.0
11 Ann Toronto 28 79.0 81.0 95.0 0.0
12 Jana Prague 33 81.0 78.0 88.0 0.0
13 Yi Shanghai 34 80.0 88.0 79.0 0.0
14 Robin Manchester 38 68.0 74.0 91.0 0.0
15 Amal Cairo 31 61.0 70.0 91.0 0.0
16 Nori Osaka 37 84.0 81.0 80.0 0.0Параметр loc определяет расположение, или отсчитываемый от нуля индекс нового столбца в дата-фрейме. column устанавливает метку нового столбца, а value указывает значения данных для вставки.
Можно удалить один или несколько столбцов так же, как и в обычном словаре Python, используя оператор del:
>>> del df['total-score']
>>> df
name city age py-score django-score js-score
10 Xavier Mexico City 41 88.0 86.0 71.0
11 Ann Toronto 28 79.0 81.0 95.0
12 Jana Prague 33 81.0 78.0 88.0
13 Yi Shanghai 34 80.0 88.0 79.0
14 Robin Manchester 38 68.0 74.0 91.0
15 Amal Cairo 31 61.0 70.0 91.0
16 Nori Osaka 37 84.0 81.0 80.0Теперь в df нет колонки total-score. Ещё одно сходство со словарями заключается в том, что можно использовать метод pop(), который удаляет указанный столбец и возвращает его. Это означает, что вы могли бы написать что-то вроде df.pop('total-score') вместо del.
Также можно удалить один или несколько столбцов с помощью drop(). Нужно лишь указать метки нужных столбцов с помощью параметра labels и выставить аргумент axis=1:
>>> df = df.drop(labels='age', axis=1)
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0Например, сейчас мы удалили столбец age.
По умолчанию, drop() выдаёт дата-фрейм без указанных столбцов, если вы не передадите inplace=True.
Применение арифметических операций
Основные арифметические операции вроде сложения, вычитания, умножения и деления в Pandas Series и объектах DataFrame производятся так же, как и в массивах NumPy:
>>> df['py-score'] + df['js-score']
10 159.0
11 174.0
12 169.0
13 159.0
14 159.0
15 152.0
16 164.0
dtype: float64
>>> df['py-score'] / 100
10 0.88
11 0.79
12 0.81
13 0.80
14 0.68
15 0.61
16 0.84
Name: py-score, dtype: float64Кроме того, можно вставлять новые столбцы с более сложными арифметическими действиями. Например, попробуем рассчитать total (общий балл) наших кандидатов в виде линейной комбинации их баллов по Python, Django и JavaScript:
>>> df['total'] =\
... 0.4 * df['py-score'] + 0.3 * df['django-score'] + 0.3 * df['js-score']
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9Применение функций NumPy и SciPy
В большинстве программ с NumPy и SciPy в качестве аргументов можно передавать Pandas Series и объекты DataFrame, вместо массивов NumPy. Чтобы проиллюстрировать это, попробуем рассчитать результаты тестов кандидатов, используя процедуру NumPy numpy.average().
Вместо того чтобы передавать массив NumPy в numpy.average(), передадим часть DataFrame:
>>> import numpy as np
>>> score = df.iloc[:, 2:5]
>>> score
py-score django-score js-score
10 88.0 86.0 71.0
11 79.0 81.0 95.0
12 81.0 78.0 88.0
13 80.0 88.0 79.0
14 68.0 74.0 91.0
15 61.0 70.0 91.0
16 84.0 81.0 80.0
>>> np.average(score, axis=1,
... weights=[0.4, 0.3, 0.3])
array([82.3, 84.4, 82.2, 82.1, 76.7, 72.7, 81.9])Переменная score ссылается на DataFrame с оценками по Python, Django и JavaScript. Используем score в качестве аргумента numpy.average() и получим линейную комбинацию столбцов с указанными весами.
Но это ещё не всё! Вы можете использовать массив NumPy, возвращаемый average() как новый столбец df. Сначала удалите существующий столбец total из df, а затем добавьте новый:
>>> del df['total']
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
>>> df['total'] = np.average(df.iloc[:, 2:5], axis=1,
... weights=[0.4, 0.3, 0.3])
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9Результат такой же, как и в предыдущем примере, но здесь вместо того, чтобы писать собственный код, мы использовали готовую функцию NumPy.
Сортировка в Pandas DataFrame
Сортировать Pandas DataFrame можно с помощью sort_values():
>>> df.sort_values(by='js-score', ascending=False)
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9
13 Yi Shanghai 80.0 88.0 79.0 82.1
10 Xavier Mexico City 88.0 86.0 71.0 82.3В этом примере дата-фрейм сортируется по значениям в столбце js-score. Параметр by задает метку строки или столбца для сортировки, ascending указывает сортировать элементы по возрастанию (True) или по убыванию (False). По умолчанию элементы сортируются по убыванию. Параметр axis определяет, что будет сортироваться: строки (axis=0) или столбцы (axis=1).
Если вы хотите отсортировать по нескольким столбцам, просто передайте списки в качестве аргументов для by и ascending:
>>> df.sort_values(by=['total', 'py-score'], ascending=[False, False])
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
10 Xavier Mexico City 88.0 86.0 71.0 82.3
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7В этом случае DataFrame сортируется по столбцу total, но если два значения совпадают, их порядок определяется значениями из столбца py-score.
Необязательный параметр inplace также можно использовать с sort_values(). По умолчанию оно установлено в False, что обеспечивает выдачу нового DataFrame. Когда вы установите inplace=True, существующий DataFrame изменится и sort_values() вернёт None.
Если вы когда-нибудь пробовали сортировать значения в Excel, то подход Pandas может показаться вам более эффективным и удобным. Когда у вас есть большие объёмы данных, Pandas значительно превосходит Excel.
Узнать больше о сортировке в Pandas можно в гайде Pandas Sort: Your Guide to Sorting Data in Python.
Фильтрация данных
Фильтрация данных — ещё одна суперспособность Pandas. Она работает аналогично индексации логических массивов в NumPy.
Если применить какую-либо логическую операцию к объекту Series, получится ещё одна серия с логическими значениями True и False:
>>> filter_ = df['django-score'] >= 80
>>> filter_
10 True
11 True
12 False
13 True
14 False
15 False
16 True
Name: django-score, dtype: boolВ данном случае df['django-score'] >= 80. То есть True присваивается строкам, в которых оценка по Django больше или равна 80, а False —для строк с оценкой Django меньше 80.
Теперь у вас есть серия filter_, заполненная булевыми значениями. Выражение df[filter_] выдаёт Pandas DataFrame со строками df, где в filter_ стоит True:
>>> df[filter_]
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9Как видите, в filter_[10], filter_[11], filter_[13] и filter_[16] стоит True, а в filter_[12], filter_[14] и filter_[15] — False, поэтому соответствующие строки не появляются в df[filter_].
Вы можете создавать сложные выражения, комбинируя логические операции со следующими операторами:
- NOT( ~)
- AND( &)
- OR( |)
- XOR( ^)
Например, попробуем получить DataFrame с кандидатами, чьи результаты py-score и js-score больше или равны 80:
>>> df[(df['py-score'] >= 80) & (df['js-score'] >= 80)]
name city py-score django-score js-score total
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9Выражение (df['py-score'] >= 80) & (df['js-score'] >= 80) задаёт True в строках, где py-score и js-score больше или равны 80, и False — в остальных. В этом случае только строки с метками 12 и 16 удовлетворяют обоим условиям.
Для некоторых операций, требующих фильтрации данных, удобнее использовать where():
>>> df['django-score'].where(cond=df['django-score'] >= 80, other=0.0)
10 86.0
11 81.0
12 0.0
13 88.0
14 0.0
15 0.0
16 81.0
Name: django-score, dtype: float64В данном примере условие — df['django-score'] >= 80. Значения DataFrame или Series, которые вызываются, при использовании where() останутся True и будут заменены значением в параметре other (в данном случае 0.0), если условие не выполняется.
Работа со статистическими данными
Pandas предоставляет множество статистических методов для DataFrames. Базовую статистику для числовых столбцов в DataFrame можно получить с помощью метода describe():
>>> df.describe()
py-score django-score js-score total
count 7.000000 7.000000 7.000000 7.000000
mean 77.285714 79.714286 85.000000 80.328571
std 9.446592 6.343350 8.544004 4.101510
min 61.000000 70.000000 71.000000 72.700000
25% 73.500000 76.000000 79.500000 79.300000
50% 80.000000 81.000000 88.000000 82.100000
75% 82.500000 83.500000 91.000000 82.250000
max 88.000000 88.000000 95.000000 84.400000В этом примере describe() возвращает новый DataFrame с количеством строк, указанным в count, а также средним значением, стандартным отклонением, минимумом, максимумом и квартилями столбцов.
Если вы хотите получить конкретную статистику для некоторых или всех ваших столбцов, можно вызвать такие методы, как mean() или std():
>>> df.mean()
py-score 77.285714
django-score 79.714286
js-score 85.000000
total 80.328571
dtype: float64
>>> df['py-score'].mean()
77.28571428571429
>>> df.std()
py-score 9.446592
django-score 6.343350
js-score 8.544004
total 4.101510
dtype: float64
>>> df['py-score'].std()
9.446591726019244При применении к Pandas DataFrame эти методы позволяют выдать Series с результатами для каждого столбца. При применении к объекту Series или одному столбцу будут выданы скаляры.
Узнать больше о статистических вычислениях в Pandas, и ознакомиться с описательной статистикой в Python можно в этой статье. А изучить работу с корреляцией в NumPy, SciPy и Pandas — в этой.
Обработка отсутствующих данных
Отсутствующие данные очень распространены в науке о данных и машинном обучении. К счасть, у Pandas есть очень мощные функции для работы с ними. Более того, в его документации есть целый раздел, посвящённый работе с отсутствующими данными.
Pandas обычно представляет отсутствующие данные значениями NaN (не число). В Python вы можете получить NaN с помощью float('nan'), math.nan или numpy.nan. Начиная с Pandas 1.0, используются также BooleanDtype, Int8Dtype, Int16Dtype, Int32Dtype и Int64Dtype. Вот пример работы с отсутствующим значением:
>>> df_ = pd.DataFrame({'x': [1, 2, np.nan, 4]})
>>> df_
x
0 1.0
1 2.0
2 NaN
3 4.0Переменная df_ относится к DataFrame с одним столбцом x и четырьмя значениями. Третье значение NaN по умолчанию считается отсутствующим.
Расчёт с отсутствующими данными
Многие методы Pandas опускают значения NaN при выполнении вычислений, если только они явно не указаны:
>>> df_.mean()
x 2.333333
dtype: float64
>>> df_.mean(skipna=False)
x NaN
dtype: float64В первом примере df_.mean() вычисляет среднее значение без учёта NaN (третьего значения). Он просто принимает 1.0, 2.0 и 4.0 и выдаёт их среднее значение, равное 2.33.
Однако, если вы с помощью skipna=False прикажете mean() не пропускать NaN, то он будет возвращать их там, где отсутствует значение.
Заполнение недостающих данных
В Pandas есть несколько способов заполнения или замены отсутствующих значений другими значениями. Один из самых удобных — fillna(). Он позволяет заменять NaN на:
- указанные значения,
- значение выше пропущенного значения,
- значение ниже пропущенного значения.
Вот как вы можете применить параметры, упомянутые выше:
>>> df_.fillna(value=0)
x
0 1.0
1 2.0
2 0.0
3 4.0
>>> df_.fillna(method='ffill')
x
0 1.0
1 2.0
2 2.0
3 4.0
>>> df_.fillna(method='bfill')
x
0 1.0
1 2.0
2 4.0
3 4.0В первом примере fillna(value=0) вставляет число 0.0, которое указано в value. Во втором fillna(method='ffill') заменяет отсутствующее значение тем, что расположено над ним, то есть 2.0. А в третьем fillna(method='bfill') вставляет то, что расположено ниже отсутствующего значения, то есть 4.0.
Другой популярный вариант — применить интерполяцию и заменить отсутствующие значения интерполированными с помощью interpolate():
>>> df_.interpolate()
x
0 1.0
1 2.0
2 3.0
3 4.0Также можно использовать необязательный параметр inplace с fillna(). Это позволит:
- Создавать и возвращать новый DataFrame, когда inplace=False;
- Изменять существующий DataFrame на None когда inplace=True.
По умолчанию параметр inplace равен False. Однако его полезно устанавливать в True, во время работы с большими объёмами данных для предотвращения ненужного и неэффективного копирования.
Удаление строк и столбцов с отсутствующими данными
В некоторых ситуациях может потребоваться удалить строки или даже столбцы, в которых отсутствуют значения. Сделать это можно с помощью dropna():
>>> df_.dropna()
x
0 1.0
1 2.0
3 4.0В приведённом выше примере метод dropna() удаляет строку с NaN, вместе с её меткой. Он также имеет необязательный параметр inplace, который ведёт себя так же, как .fillna() и .interpolate().
Итерации в Pandas DataFrame
Как мы уже знаем, метки строк и столбцов DataFrame можно получить в виде последовательностей с помощью атрибутов index и columns. Их можно использовать также для перебора меток и получения или установки значений данных. Однако Pandas предоставляет несколько более удобных методов итерации:
- items() — перебирать столбцы;
- iteritems() — перебирать столбцы;
- iterrows() — перебирать строки;
- itertuples() — перебирать строки и получать именованные кортежи.
Каждая итерация items() и iteritems() возвращает кортеж с именем и данными столбца в виде объекта Series:
>>> for col_label, col in df.iteritems():
... print(col_label, col, sep='\n', end='\n\n')
...
name
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
city
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
py-score
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
django-score
10 86.0
11 81.0
12 78.0
13 88.0
14 74.0
15 70.0
16 81.0
Name: django-score, dtype: float64
js-score
10 71.0
11 95.0
12 88.0
13 79.0
14 91.0
15 91.0
16 80.0
Name: js-score, dtype: float64
total
10 82.3
11 84.4
12 82.2
13 82.1
14 76.7
15 72.7
16 81.9
Name: total, dtype: float64Каждая итерация с помощью iterrows() даёт кортеж с именем строки и данными строки в виде серии:
>>> for row_label, row in df.iterrows():
... print(row_label, row, sep='\n', end='\n\n')
...
10
name Xavier
city Mexico City
py-score 88
django-score 86
js-score 71
total 82.3
Name: 10, dtype: object
11
name Ann
city Toronto
py-score 79
django-score 81
js-score 95
total 84.4
Name: 11, dtype: object
12
name Jana
city Prague
py-score 81
django-score 78
js-score 88
total 82.2
Name: 12, dtype: object
13
name Yi
city Shanghai
py-score 80
django-score 88
js-score 79
total 82.1
Name: 13, dtype: object
14
name Robin
city Manchester
py-score 68
django-score 74
js-score 91
total 76.7
Name: 14, dtype: object
15
name Amal
city Cairo
py-score 61
django-score 70
js-score 91
total 72.7
Name: 15, dtype: object
16
name Nori
city Osaka
py-score 84
django-score 81
js-score 80
total 81.9
Name: 16, dtype: objectТочно так же itertuples() перебирает строки и на каждой итерации (опционально) даёт именованный кортеж с индексом и данными:
>>> for row in df.loc[:, ['name', 'city', 'total']].itertuples():
... print(row)
...
Pandas(Index=10, name='Xavier', city='Mexico City', total=82.3)
Pandas(Index=11, name='Ann', city='Toronto', total=84.4)
Pandas(Index=12, name='Jana', city='Prague', total=82.19999999999999)
Pandas(Index=13, name='Yi', city='Shanghai', total=82.1)
Pandas(Index=14, name='Robin', city='Manchester', total=76.7)
Pandas(Index=15, name='Amal', city='Cairo', total=72.7)
Pandas(Index=16, name='Nori', city='Osaka', total=81.9)Имя кортежа устанавливается параметром name. Дополнительно можно указать, включать ли метки строк в index (по умолчанию установлен в True).
Работа с временными рядами
Pandas отлично справляется с временными рядами. Хотя эта функция частично основана на datetimes и timedeltas, Pandas обеспечивает гораздо большую гибкость.
Создание DataFrame с метками временных рядов
Попробуем создать дата-фрейм, используя почасовые данные о температуре за день.
Начнём со списка (кортежа, массива NumPy или другого типа данных) со значениями данных, которые будут представлять собой почасовую температуру, указанную в градусах Цельсия:
>>> temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0,
... 9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1,
... 21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]Переменная temp_c ссылается на список значений температуры.
Следующий шаг — создание последовательности дат и времени. Для этого в Pandas есть очень удобная функция date_range(), ранжирующая аргументы, которые вы используете для указания начала или конца диапазона, количества периодов, частоты, часового пояса и так далее:
>>> dt = pd.date_range(start='2019-10-27 00:00:00.0', periods=24,
... freq='H')
>>> dt
DatetimeIndex(['2019-10-27 00:00:00', '2019-10-27 01:00:00',
'2019-10-27 02:00:00', '2019-10-27 03:00:00',
'2019-10-27 04:00:00', '2019-10-27 05:00:00',
'2019-10-27 06:00:00', '2019-10-27 07:00:00',
'2019-10-27 08:00:00', '2019-10-27 09:00:00',
'2019-10-27 10:00:00', '2019-10-27 11:00:00',
'2019-10-27 12:00:00', '2019-10-27 13:00:00',
'2019-10-27 14:00:00', '2019-10-27 15:00:00',
'2019-10-27 16:00:00', '2019-10-27 17:00:00',
'2019-10-27 18:00:00', '2019-10-27 19:00:00',
'2019-10-27 20:00:00', '2019-10-27 21:00:00',
'2019-10-27 22:00:00', '2019-10-27 23:00:00'],
dtype='datetime64[ns]', freq='H')Примечание. Хотя доступны и другие параметры, по умолчанию в Pandas в основном используют формат даты и времени ISO 8601.
Теперь создадим DataFrame. Во многих случаях удобно использовать значения даты и времени в качестве меток строк:
>>> temp = pd.DataFrame(data={'temp_c': temp_c}, index=dt)
>>> temp
temp_c
2019-10-27 00:00:00 8.0
2019-10-27 01:00:00 7.1
2019-10-27 02:00:00 6.8
2019-10-27 03:00:00 6.4
2019-10-27 04:00:00 6.0
2019-10-27 05:00:00 5.4
2019-10-27 06:00:00 4.8
2019-10-27 07:00:00 5.0
2019-10-27 08:00:00 9.1
2019-10-27 09:00:00 12.8
2019-10-27 10:00:00 15.3
2019-10-27 11:00:00 19.1
2019-10-27 12:00:00 21.2
2019-10-27 13:00:00 22.1
2019-10-27 14:00:00 22.4
2019-10-27 15:00:00 23.1
2019-10-27 16:00:00 21.0
2019-10-27 17:00:00 17.9
2019-10-27 18:00:00 15.5
2019-10-27 19:00:00 14.4
2019-10-27 20:00:00 11.9
2019-10-27 21:00:00 11.0
2019-10-27 22:00:00 10.2
2019-10-27 23:00:00 9.1Индексирование и нарезка
К DataFrame с данными временных рядов можно применить срезы, чтобы получить только часть информации:
>>> temp['2019-10-27 05':'2019-10-27 14']
temp_c
2019-10-27 05:00:00 5.4
2019-10-27 06:00:00 4.8
2019-10-27 07:00:00 5.0
2019-10-27 08:00:00 9.1
2019-10-27 09:00:00 12.8
2019-10-27 10:00:00 15.3
2019-10-27 11:00:00 19.1
2019-10-27 12:00:00 21.2
2019-10-27 13:00:00 22.1
2019-10-27 14:00:00 22.4В этом примере показано, как извлечь значения температуры между 05:00 и 14:00. Pandas понимает, что метки строк — это значения даты и времени, и соответственно их интерпретирует.
Ресемплинг и роллинг
Если вы хотите разбить день на четыре шестичасовых интервала и получить среднюю температуру для каждого из них, в Pandas есть метод resample(), который можно комбинировать с другими, например с mean():
>>> temp.resample(rule='6h').mean()
temp_c
2019-10-27 00:00:00 6.616667
2019-10-27 06:00:00 11.016667
2019-10-27 12:00:00 21.283333
2019-10-27 18:00:00 12.016667Каждая строка соответствует одному шестичасовому интервалу. Например, значение 6.616667 представляет собой среднее значение первых шести температур из дата-фрейма temp, тогда как 12.016667 — среднее значение последних шести значений температуры.
Вместо mean() можно применить min() или max(). Аналогично можно использовать sum() для получения сумм значений данных. Вы можете свернуть окно, выбрав другой набор смежных строк для вычислений.
Первое окно начинается с первой строки в DataFrame и включает столько смежных строк, сколько вы укажете. Затем можно переместить окно вниз на одну строку, опуская первую строку и добавляя ту, которая идёт сразу после последней, и снова вычислить ту же статистику. Процесс нужно повторять, пока вы не дойдёте до последней строки DataFrame. Для этого в Pandas есть метод rolling():
>>> temp.rolling(window=3).mean()
temp_c
2019-10-27 00:00:00 NaN
2019-10-27 01:00:00 NaN
2019-10-27 02:00:00 7.300000
2019-10-27 03:00:00 6.766667
2019-10-27 04:00:00 6.400000
2019-10-27 05:00:00 5.933333
2019-10-27 06:00:00 5.400000
2019-10-27 07:00:00 5.066667
2019-10-27 08:00:00 6.300000
2019-10-27 09:00:00 8.966667
2019-10-27 10:00:00 12.400000
2019-10-27 11:00:00 15.733333
2019-10-27 12:00:00 18.533333
2019-10-27 13:00:00 20.800000
2019-10-27 14:00:00 21.900000
2019-10-27 15:00:00 22.533333
2019-10-27 16:00:00 22.166667
2019-10-27 17:00:00 20.666667
2019-10-27 18:00:00 18.133333
2019-10-27 19:00:00 15.933333
2019-10-27 20:00:00 13.933333
2019-10-27 21:00:00 12.433333
2019-10-27 22:00:00 11.033333
2019-10-27 23:00:00 10.100000Параметр window определяет размер скользящего временного окна.
В приведённом выше примере третье значение (7.3) представляет собой среднюю температуру за первые три часа (00:00:00, 01:00:00 и 02:00:00). Четвёртое — среднюю температуру за часы 02:00:00, 03:00:00 и 04:00:00. Последнее — среднюю температуру за последние три часа, 21:00:00, 22:00:00 и 23:00:00. Первые два значения отсутствуют, так как для их вычисления не хватило данных.
Графика в Pandas DataFrame
Pandas позволяет визуализировать данные или создавать графики на основе DataFrames с использованием Matplotlib в фоновом режиме, поэтому построение графиков в Pandas очень похоже на работу с Matplotlib.
Для работы с графиками сначала нужно импортировать модуль matplotlib.pyplot:
>>> import matplotlib.pyplot as pltТеперь вы можете создавать графики с Pandas.DataFrame.plot() и визуализировать их с plt.show():
>>> temp.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070cd9d950>
>>> plt.show()Команда plot() отображает объект plot, который выглядит так:
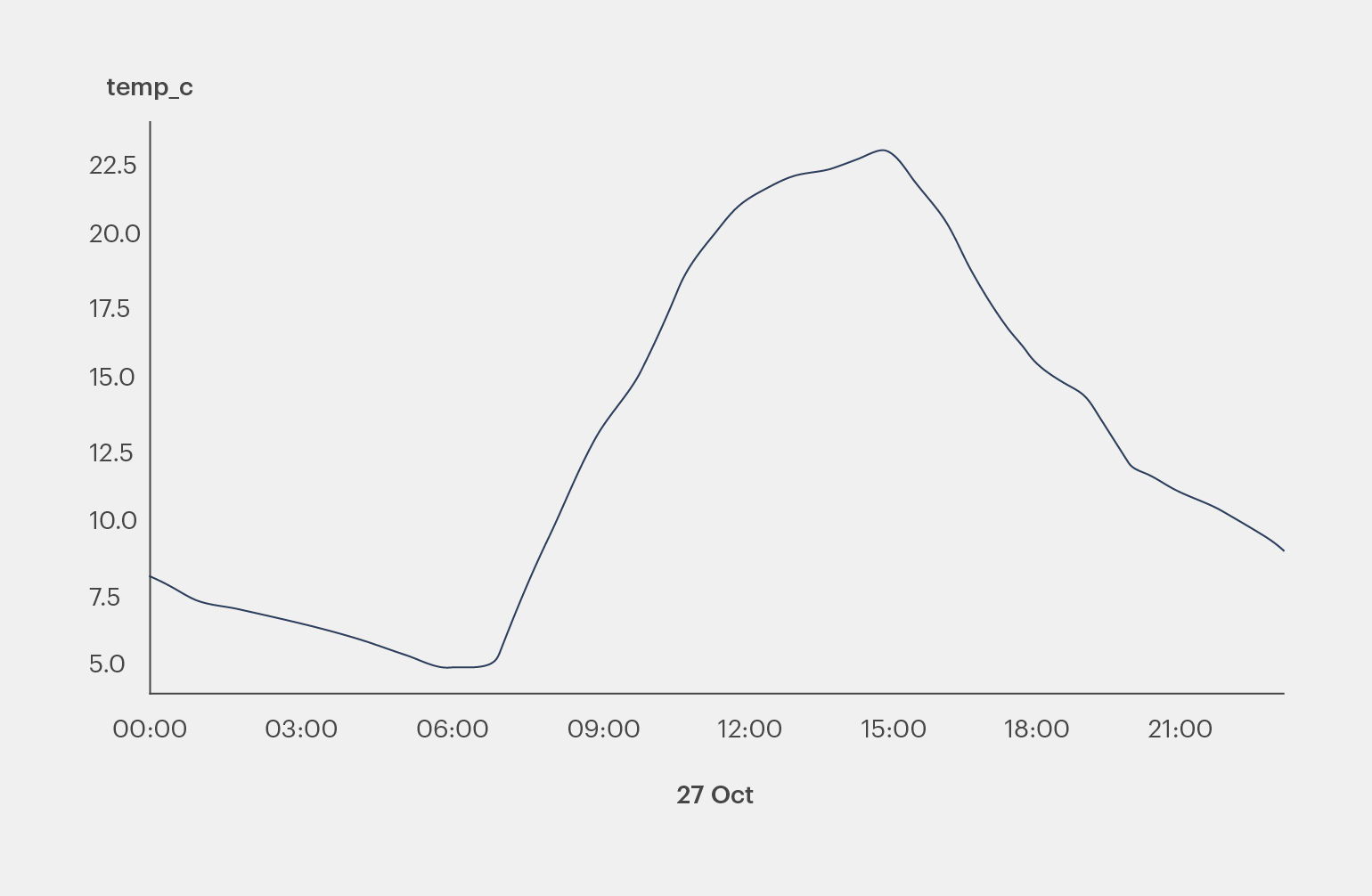
Тот же результат можно получить, применив plot.line(). У plot() и plot.line() есть много необязательных параметров, которые позволяют указать внешний вид графика.
Для сохранения изображения используется объединённая команда get_figure().savefig():
>>> temp.plot().get_figure().savefig('temperatures.png')В результате график сохраняется в рабочем каталоге как файл temperatures.png.
Pandas DataFrame позволяет создавать разные типы графиков. Например, с помощью plot.hist() можно визуализировать данные кандидатов в виде гистограммы:
>>> df.loc[:, ['py-score', 'total']].plot.hist(bins=5, alpha=0.4)
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070c69edd0>
>>> plt.show()Выглядит это так:
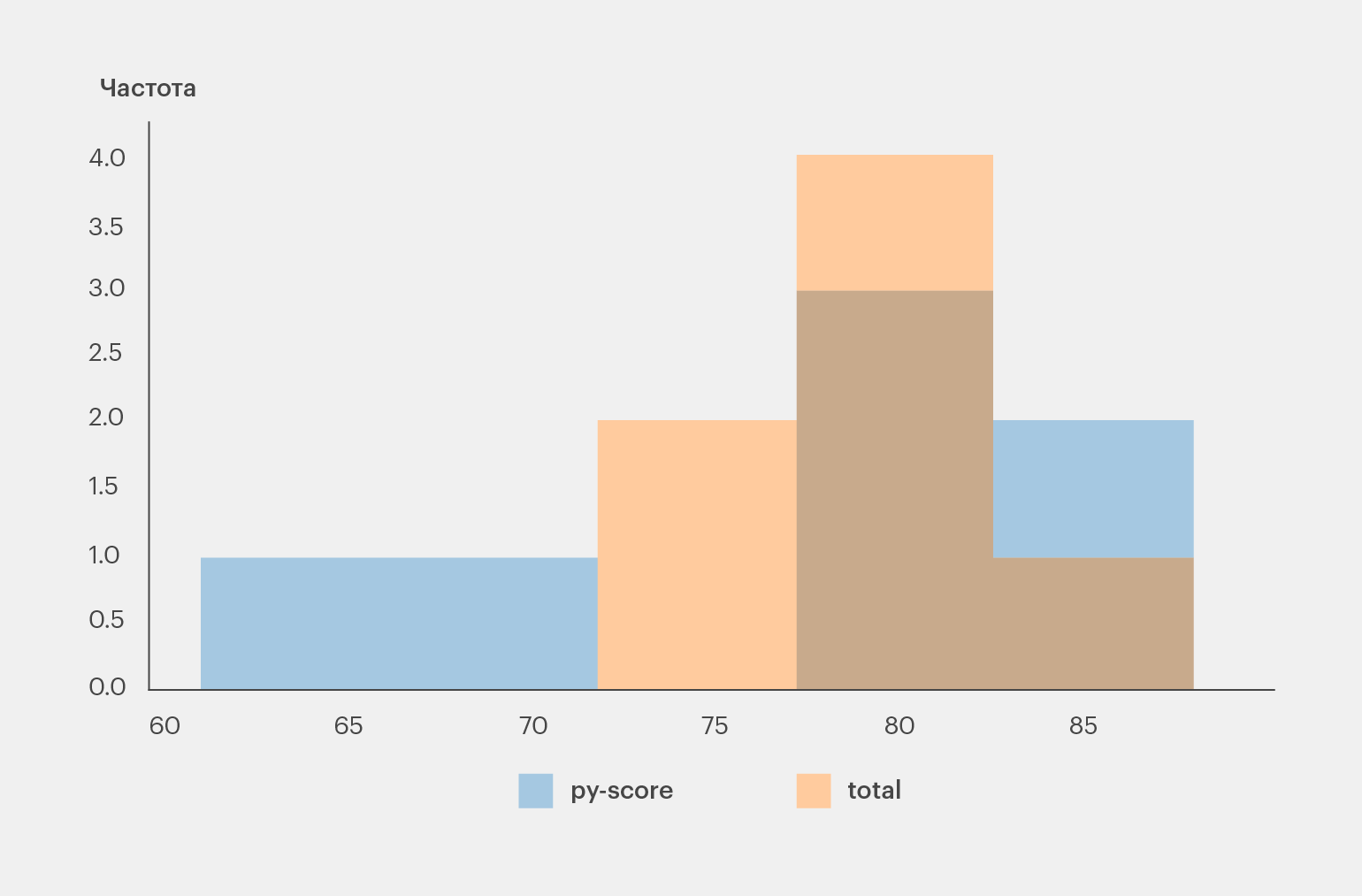
Настроить детали можно с помощью дополнительных методов и параметров: plot.hist(), plt.rcParams и многих других. Более подробную информацию вы найдёте в бесплатном учебнике Anatomy of Matplotlib.
Рекомендуемая литература
Pandas DataFrames — это очень многофункциональные объекты, которые поддерживают многие операции, не упомянутые в этой статье:
- Иерархическую (многоуровневую) индексацию;
- Группировку;
- Слияние, объединение и конкатенацию;
- Работу с категориальными данными.
Большинство доступных опций хорошо описано в официальном учебнике по Pandas. Если вы хотите узнать больше, можно ознакомиться со следующими руководствами (все они написаны на английском языке):
- Очистка данных в Pandas и NumPy;
- Pandas DataFrames 101;
- Знакомство с Pandas и Vincent;
- Python Pandas: приёмы и возможности, о которых вы могли не знать;
- Идиоматические Pandas: приёмы и возможности, о которых вы могли не знать;
- Чтение CSV в Pandas;
- Написание CSV в Pandas;
- Чтение и запись файлов CSV в Python;
- Чтение и запись файлов CSV;
- Использование Pandas для чтения больших файлов Excel в Python;
- Быстро, гибко, просто и интуитивно понятно: как ускорить ваши проекты в Pandas.
Если вам нужно работать данными более чем в двух измерениях, можно использовать Xarray — ещё одну мощную библиотеку Python, очень похожую на Pandas.
Для работы с большими объёмами данных есть также DataFrame API в Dask.
Заключение
Из этого гайда вы узнали:
- Что такое Pandas DataFrame и как его создать.
- Как получить доступ, изменить, добавить, отсортировать, отфильтровать и удалить данные.
- Как использовать подпрограммы NumPy с DataFrames.
- Как обрабатывать пропущенные значения.
- Как работать с данными временных рядов.
- Как визуализировать данные, содержащиеся в DataFrames.
Если хотите глубже изучить работу с данными в Python, ознакомьтесь с другими руководствами по Pandas на сайте Real Python.

