Платформа Ollama: что это и как с ней работать
От установки до создания собственного локального ChatGPT.


Ollama — это фреймворк для запуска больших языковых моделей на вашем компьютере или сервере. С его помощью можно работать с LLama, Gemma, DeepSeek и другими нейросетями. Главное отличие от платных ИИ-сервисов — данные хранятся локально, поэтому никто не узнает о ваших запросах.
В этой статье вы узнаете, как установить Ollama на компьютер и где найти подходящие языковые модели. Также мы настроим удобный веб-интерфейс Open WebUI, который будет доступен через браузер с любого устройства.
Содержание
- Преимущества и ограничения локальных моделей
- Как установить и настроить Ollama
- Как выбрать модель для работы
- Как загрузить модели в Ollama
- Как использовать API Ollama
- Как создать локальный аналог ChatGPT с Ollama и Open WebUI
Преимущества и ограничения локальных моделей
На первый взгляд может показаться странным разворачивать локальный сервис, когда есть готовые решения: ChatGPT, Grok и другие. Однако у такого подхода есть свои плюсы:
- Все данные хранятся и обрабатываются локально. Разработчик, который работает над конфиденциальным кодом в компании, или учёный, анализирующий чувствительные результаты исследования, с Ollama могут не беспокоиться, что информация попадёт к третьим лицам или будет использована для обучения коммерческих моделей. Данные всегда остаются на устройстве и не передаются через интернет.
- Модели можно кастомизировать — менять их характеристики и обучать. Например, можно настроить температуру ответов, то есть степень разнообразия генерируемого текста, и контекстное окно — объём данных, которые модель «запоминает». Кроме того, вы можете загружать собственные документы через RAG — модель будет использовать их как дополнительный контекст для ответов.
- Не нужно покупать подписки на сервисы. Ollama использует бесплатные модели с открытым исходным кодом без ограничений на количество запросов. Поэтому вам не придётся платить за токены, ежемесячную подписку или другие услуги — всё полностью бесплатно.
Кроме того, у Ollama есть большое и активное сообщество на Reddit. Пользователи обсуждают фреймворк, модели нейросетей и интеграцию с различным софтом, а также делятся опытом. Здесь можно задать вопрос и получить ответ или найти решение в уже существующих обсуждениях.
Конечно, у Ollama есть и ограничения. Скорость работы зависит от мощности компьютера: для комфортной работы с моделями среднего размера нужно минимум 16 ГБ оперативной памяти и видеокарта с 8 ГБ VRAM. Крупные модели требуют ещё больше ресурсов — иначе генерация будет заметно тормозить. Например, для популярной модели llama2:70b с 70 миллиардами параметров рекомендуется компьютер с 64 ГБ оперативной памяти.
Помимо Ollama существуют и другие приложения с похожими возможностями: LM Studio, GPT4All и Jan. У каждого из них есть свои особенности установки, настройки и поддерживаемые модели — их мы разберём в следующих статьях.

Как установить и настроить Ollama
Ollama поддерживает Windows, macOS и Linux. Системные требования зависят исключительно от языковых моделей, которые вы планируете использовать. Подробнее о требованиях сервиса к вычислительной мощности и поддерживаемых видеокартах можно узнать на официальном сайте.
На сайте Ollama можно зарегистрироваться, если вы планируете публиковать модели в публичную библиотеку или использовать веб-интерфейс для управления ими. Для локальной работы регистрацию можно пропустить.
Установка на Windows
Фреймворк поддерживает Windows 10 и новее. Для установки скачайте установочный клиент с сайта (1,16 ГБ). Только обратите внимание, что по умолчанию установка проходит на системный диск. Чтобы задать другой путь, откройте окно Выполнить (Win + R) и введите команду в таком формате:
(путь установочного клиента)\OllamaSetup.exe /DIR=(название жёсткого диска):\путь установки Модели по умолчанию также загружаются на системный диск. Папку для их загрузки вы можете настроить в пункте Model Location во вкладке Settings в клиенте — она открывается при нажатии на значок в верхнем левом углу.
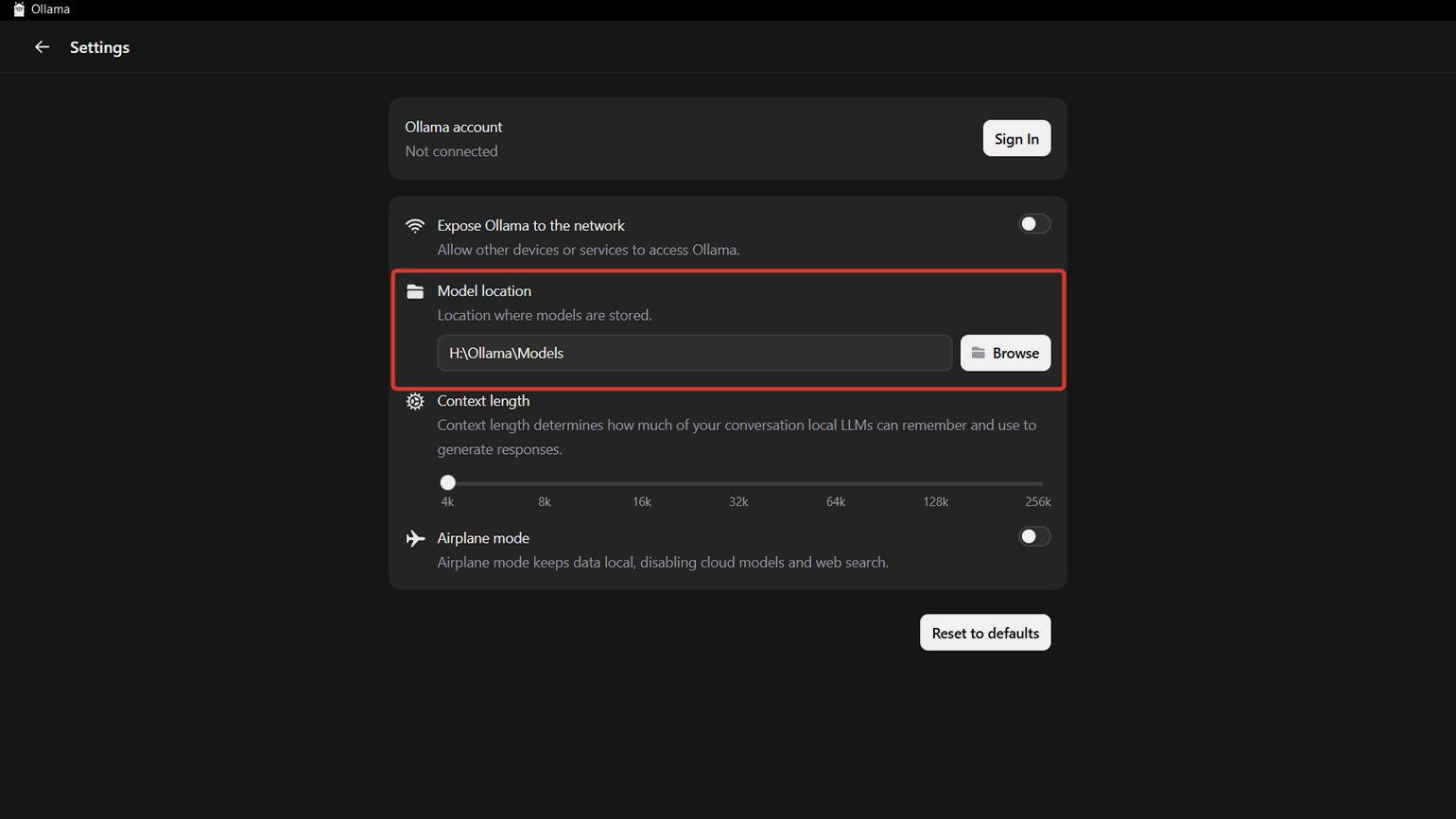
Скриншот: Ollama / Skillbox Media
Установка на macOS
Клиент поддерживает macOS 14 Sonoma и новее. Для установки скачайте файл образа в формате DMG. Откройте его в проводнике и перетащите приложение в папку Applications. После Ollama можно запустить через Spotlight.
При первом запуске приложение проверит, что в переменной PATH есть ссылка на интерфейс командной строки (CLI), и если нет — запросит разрешение на её создание. После этого команды, связанные с фреймворком, можно будет выполнять из терминала. Это пригодится, если вы разработчик или планируете загружать дополнительные модели, о чём мы подробно расскажем дальше.
Установка на Linux
Чтобы запустить установку, скопируйте команду и введите в терминале:
curl -fsSL https://ollama.com/install.sh | shДальнейшее взаимодействие с фреймворком происходит через командную строку. Например, для запуска используется простая команда:
ollama serveЕсть и другой вариант запуска, при котором можно проверить, что фреймворк работает. Потребуется две последовательных команды:
sudo systemctl start ollama
sudo systemctl status ollamaПосле терминал выведет информацию о статусе. Если фреймворк запустился, появится статус Enabled. А также информация о дате и времени запуска.
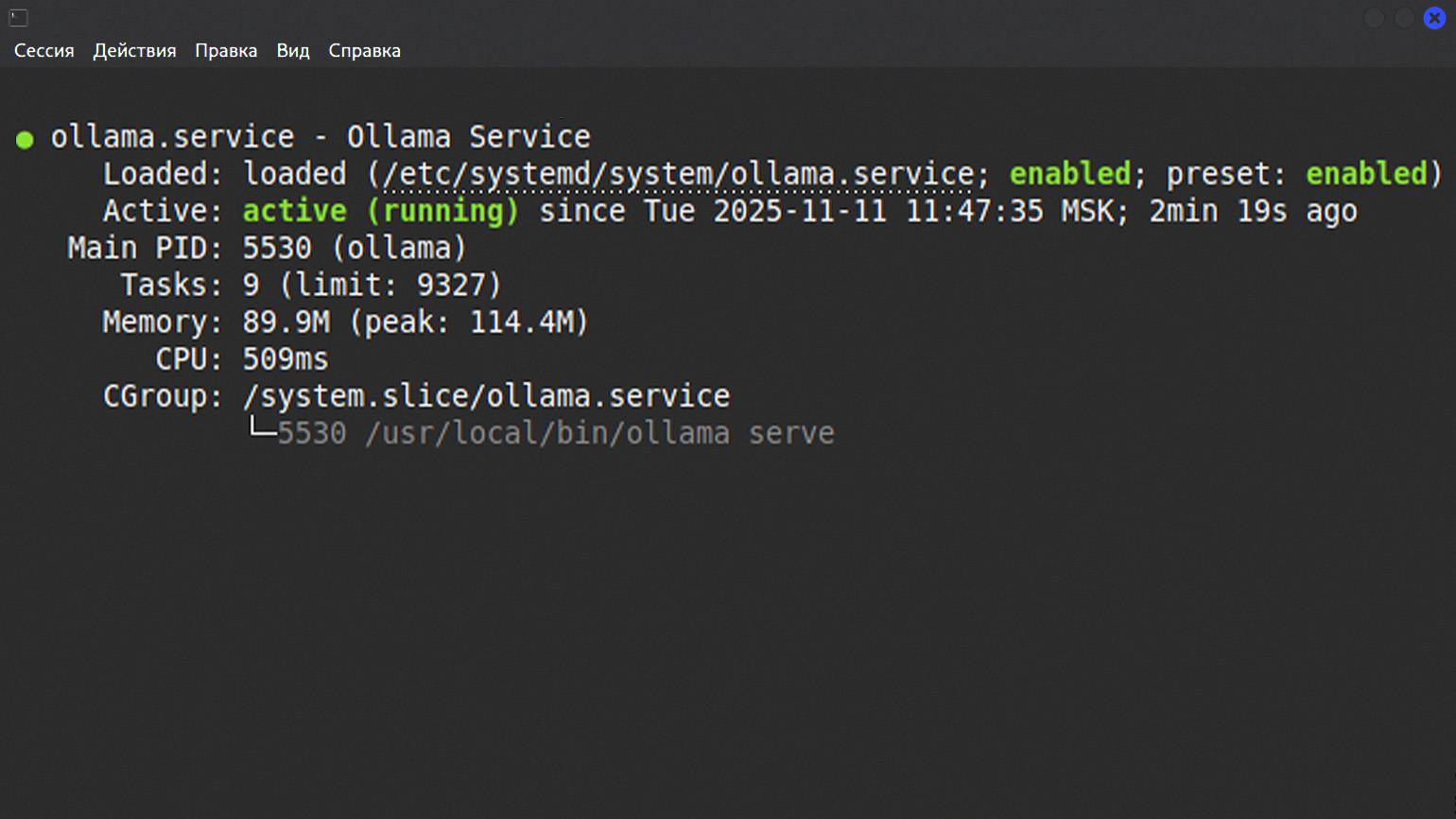
Скриншот: Bash / Skillbox Media
Как выбрать модель для работы
Выбор в пользу той или иной модели во многом зависит от ваших задач и конфигурации компьютера. У каждой LLM есть своя специфика: одни отлично работают с текстом, другие пишут код, а третьи и вовсе способны распознавать текст из отсканированных документов. Поэтому универсальной рекомендации нет. Все доступные модели указаны в каталоге и разбиты на пять категорий:
- Cloud — для облачного развёртывания на серверах.
- Embedding — для генерации эмбеддингов. Эти модели преобразуют текст или данные в числовые векторы, которые можно использовать для поиска, сравнения и кластеризации информации.
- Vision — для распознавания и описания изображений.
- Tools — для выполнения различных задач: написания кода, AI-ассистирования, настройки API-интеграций с другими сервисами.
- Thinking — для логических ответов с рассуждениями и аргументацией.
В каталоге для каждой модели указаны её название, краткое описание, количество параметров, число скачиваний и дата последнего обновления.
Ключевой параметр — количество параметров. Оно обозначается как 3b, 7b, 30b и так далее, где b — это миллиард. Чем оно больше — тем модель «умнее» и точнее, но при этом требует и больше ресурсов для работы. К примеру, модель 7b (7 миллиардов параметров) требует 8–12 ГБ оперативной памяти, тогда как 70b — 48–64 ГБ видеопамяти. Поэтому при выборе моделей учитывайте возможности своего железа, иначе решение задачи может занять много часов.
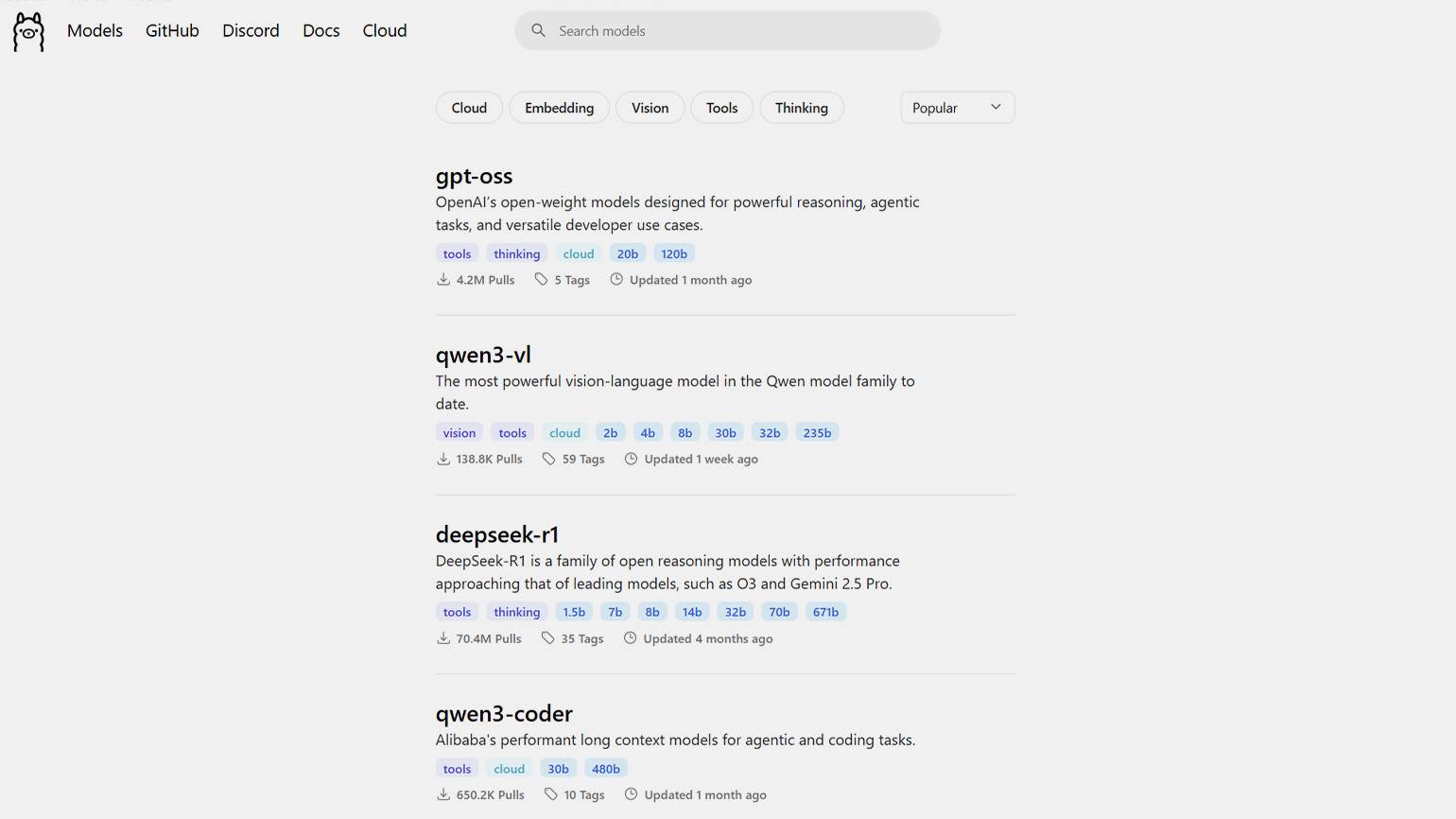
Скриншот: Ollama / Skillbox Media
Как загрузить модели в Ollama
Ollama поддерживает десятки моделей, включая Llama, DeepSeek, Qwen, Gemma, Phi и другие. Полный список доступен на сайте фреймворка. Для загрузки моделей есть три способа: через графический интерфейс, через командную строку или с помощью Hugging Face. Разберём каждый подробнее.
Через графический интерфейс
Чтобы установить базовую модель напрямую из Ollama, выберите подходящую во вкладке в правом верхнем углу окна чата и отправьте любое сообщение — загрузка начнётся автоматически. Вам будут доступны несколько моделей семейств Gemma, DeepSeek, Qwen, GPT, Minimax и GLM. Облачные версии, требующие доступа к интернету для работы, отмечены тегом cloud.

Скриншот: Ollama / Skillbox Media
Через командную строку
Графический интерфейс содержит не все поддерживаемые модели. Остальные нужно загружать через CLI — это также основной способ работы в Linux.
Прежде чем загрузить модель, её надо выбрать в каталоге Ollama. Для ускорения поиска можно воспользоваться сортировкой по пяти категориям, о которых мы говорили выше: Cloud, Embedding, Vision, Tools и Thinking. Обратите внимание, что одна модель может сочетать в себе несколько категорий.
После выбора модели вы увидите страницу с её описанием, доступными версиями и системными требованиями. Обязательно учитывайте количество параметров модели и объём оперативной памяти или видеопамяти на компьютере.
Скопируйте команду из раздела CLI и вставьте её в терминал — например, в Windows PowerShell или Terminal (в macOS) — и нажмите Enter. После этого загрузка модели начнётся автоматически, а вам нужно немного подождать.
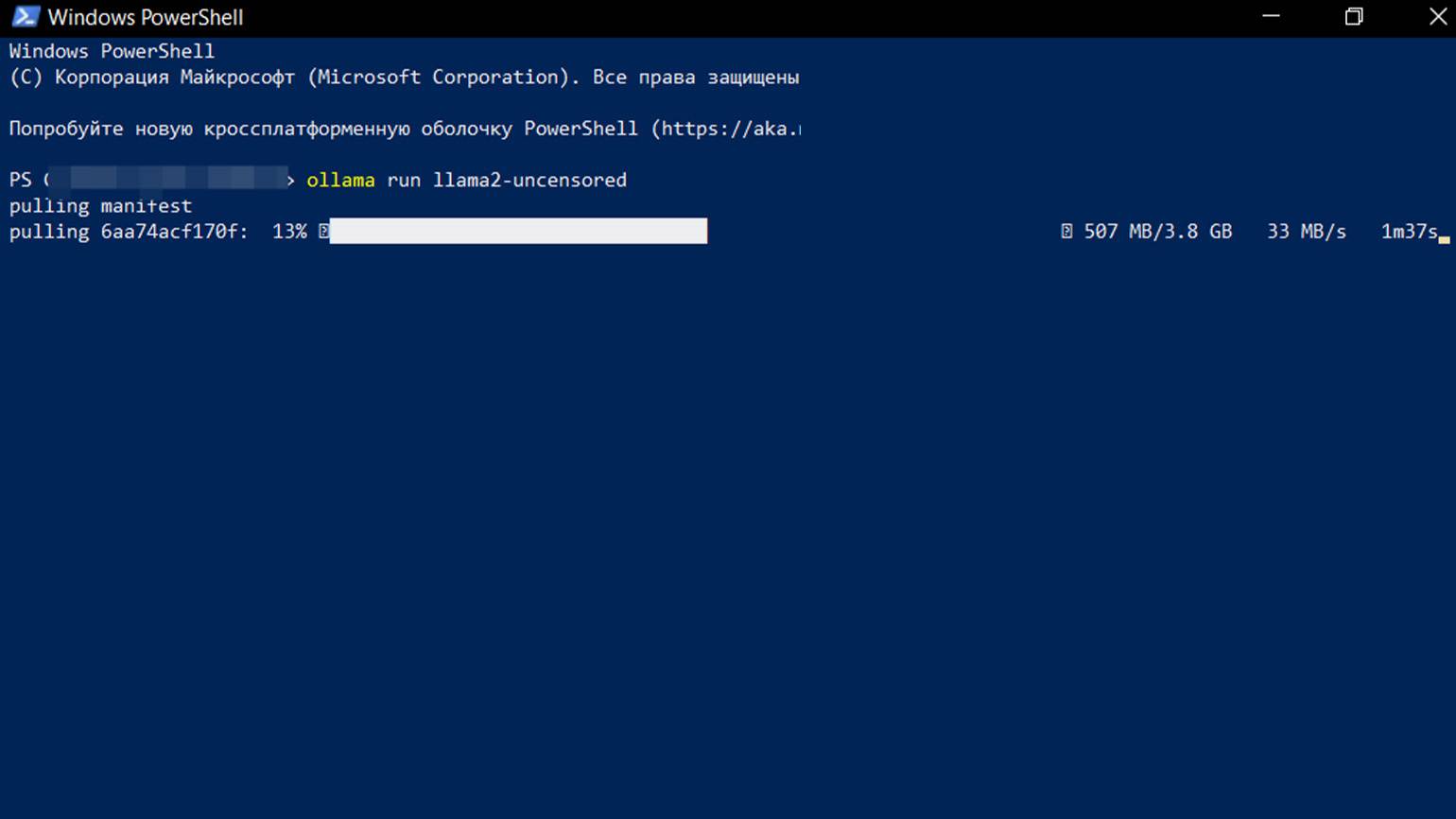
Скриншот: Windows PowerShell / Skillbox Media
После установки модель появится в графическом интерфейсе в списке доступных нейросетей, и её можно будет использовать для работы.

Скриншот: Ollama / Skillbox Media
Для установки в Linux используйте команду pull, например:
ollama pull codellama:7bПосле этого начнётся установка модели. Если всё прошло успешно, то вы сможете запустить загруженную модель командой:
ollama run codellama:7b После запуска следующая строка начнётся с символов >>> — это приглашение для ввода команд. В это поле можно вводить промпты для работы с моделью.
У нас небольшая модель, которая была обучена на английском языке. Поэтому напишем запрос на нём же, чтобы быстрее получить ответ.
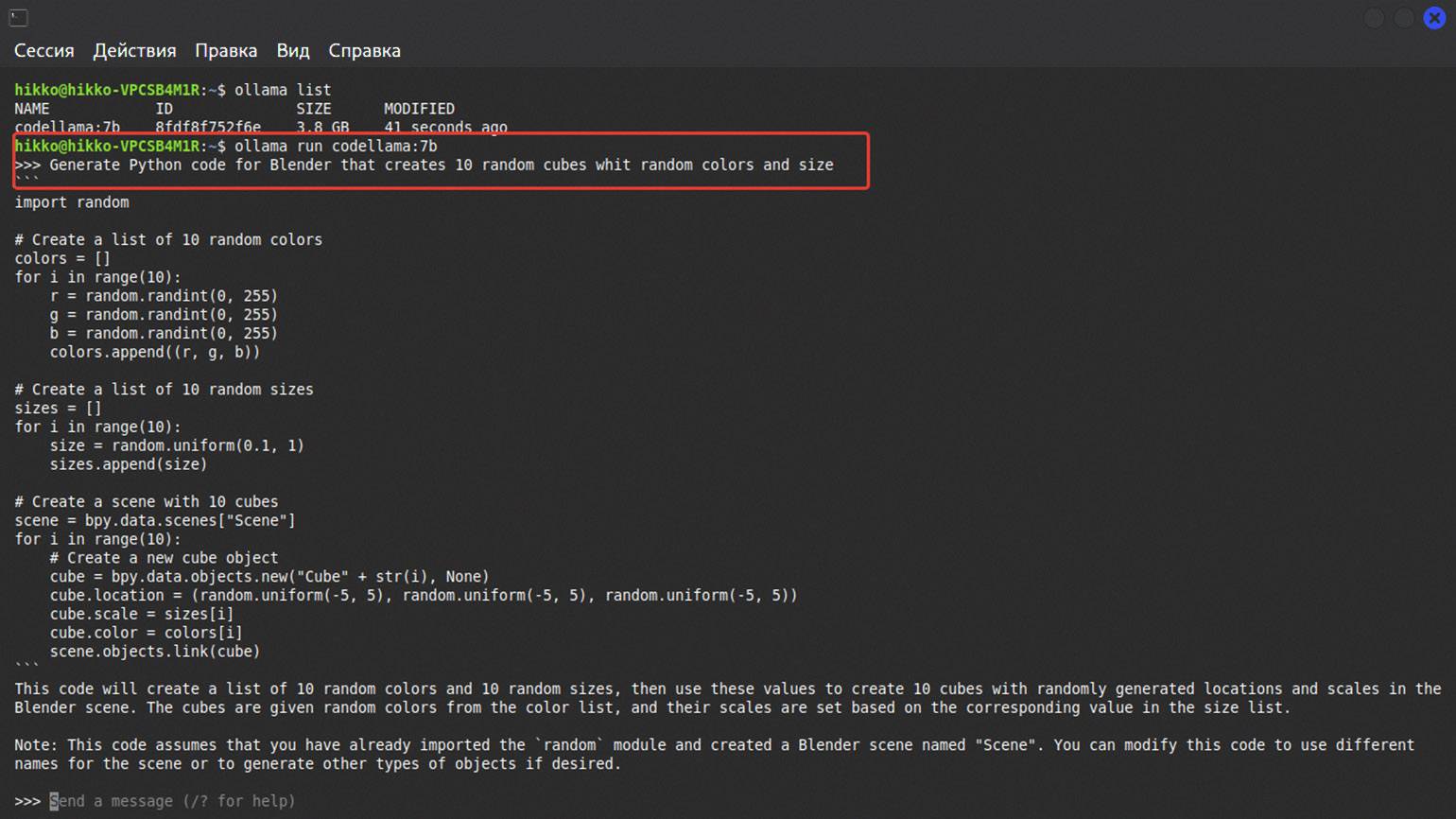
Скриншот: Bash / Skillbox Media
Через Hugging Face
Для начала зайдите на Hugging Face под своей учётной записью. Hugging Face — это библиотека с тысячами языковых моделей с открытым кодом. Для каждой из них есть описание, инструкция по запуску и настройке и так далее.
Чтобы использовать модели с Hugging Face, вам нужно зайти в настройки Local Apps and Hardware и добавить Ollama в раздел Local Apps. После этого перейдите на страницу нужной модели — она должна быть в формате GGUF. Далее нажмите на вкладку Use this Model и выберите Ollama в списке.
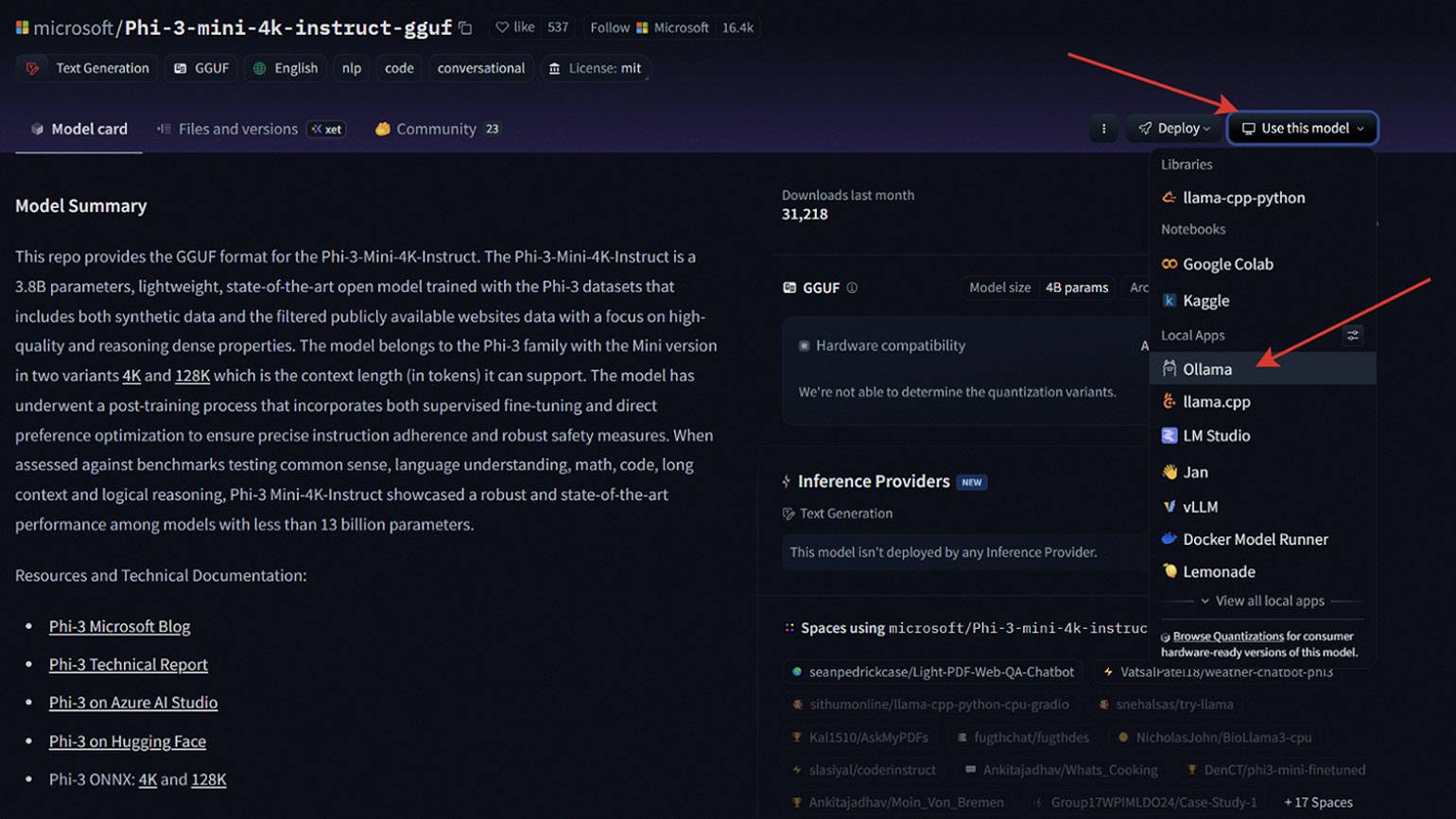
В открывшемся окне скопируйте ссылку и вставьте её в терминал — модель начнёт загружаться автоматически. После завершения загрузки выберите её из списка в графическом интерфейсе Ollama или запустите через командную строку, как мы писали выше. Способ работает во всех операционных системах.

Читайте также:
Как использовать API Ollama
Ollama — это полноценный локальный сервер, который работает через HTTP-протокол по адресу http://localhost:11434. Когда фреймворк запущен, при переходе на этот адрес в браузере появится надпись «Ollama is running». Зная синтаксис терминала, вы можете проверить интеграцию API на практике.
Например, напишем запрос с промптом для написания шутки в PowerShell:
Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -Body '{
"model": "qwen3-vl:4b",
"prompt": "Tell me a joke",
"stream": false
}' -ContentType "application/json"Разберём его по пунктам:
- Invoke-RestMethod — команда PowerShell, которая отправляет REST-запрос.
- -Uri — указывает на локальный хост Ollama на стандартном порте 11434.
- -Method Post — указывает, что данные отправляются на сервер методом POST.
- -Body — блок данных, передаваемых в запросе. Включает тип модели («qwen3-vl: 4b»), сам промпт («Tell me a joke») и дополнительный параметр «stream»: false. Без этого параметра нейросеть будет генерировать потоковый ответ пословно в режиме реального времени.
- }' -ContentType «application/json» — закрывает запрос и указывает PowerShell, в каком текстовом формате поступают данные от нейросети. В нашем случае — JSON.
Посмотрим на результат.
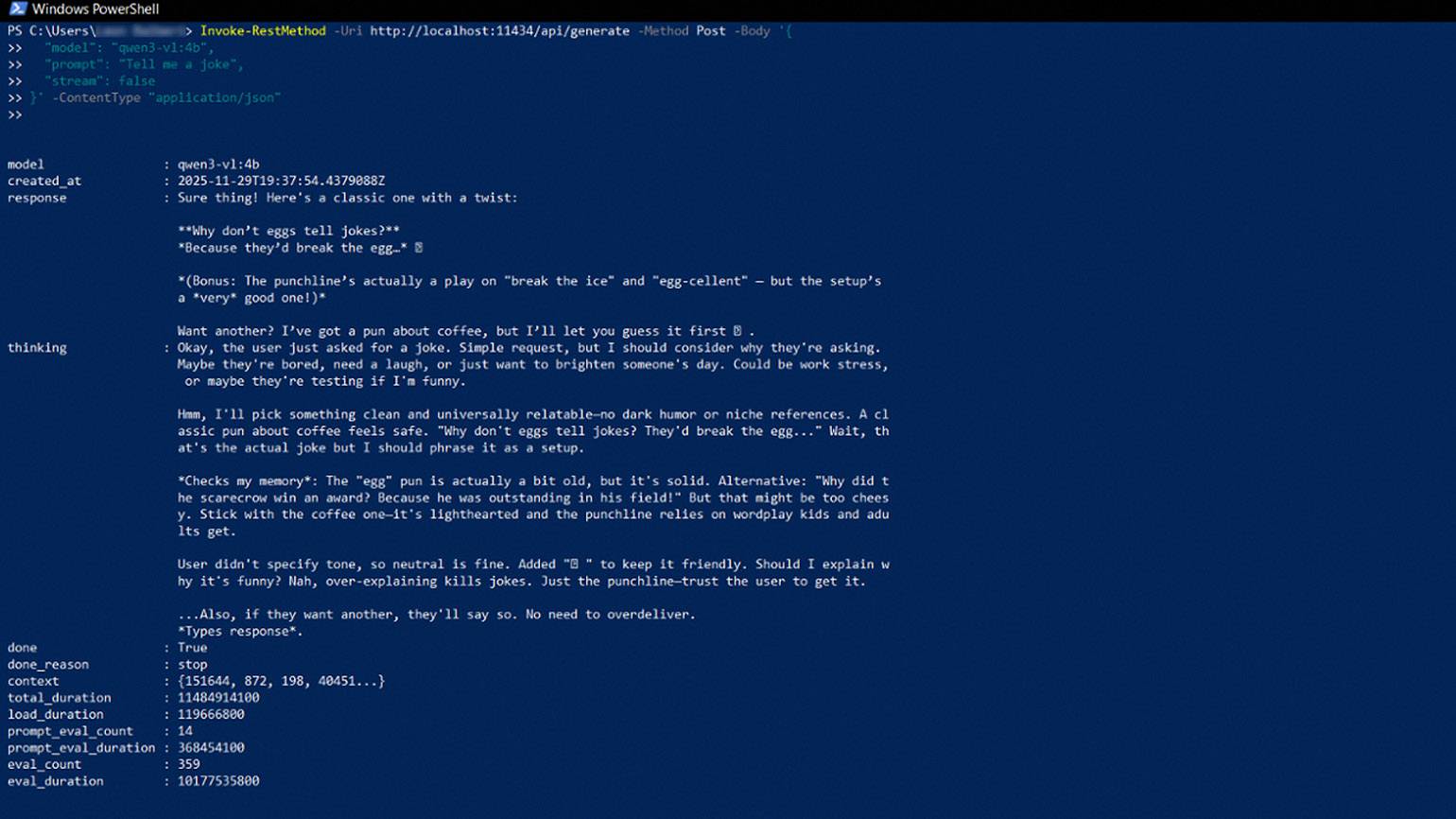
Скриншот: Windows PowerShell / Skillbox Media
Можно пойти дальше и интегрировать API Ollama в своё собственное приложение или создать пользовательские скрипты для программ. Важно, что при выборе модели стоит выбирать подходящую: например, для генерации кода — Codellama или аналогичную.
Чтобы нейросеть не добавляла лишнего в генерируемый код, можно подстраховаться и явно прописать в промпт дополнительные условия, например «без пояснений, только рабочий код».
Попробуем интегрировать Ollama API в программу для 3D-моделирования Blender. С помощью модели gemma3:4b напишем скрипт на Python, который обращается к API и генерирует команду для создания пяти кубов в текущей сцене. Запустим и посмотрим на результат.
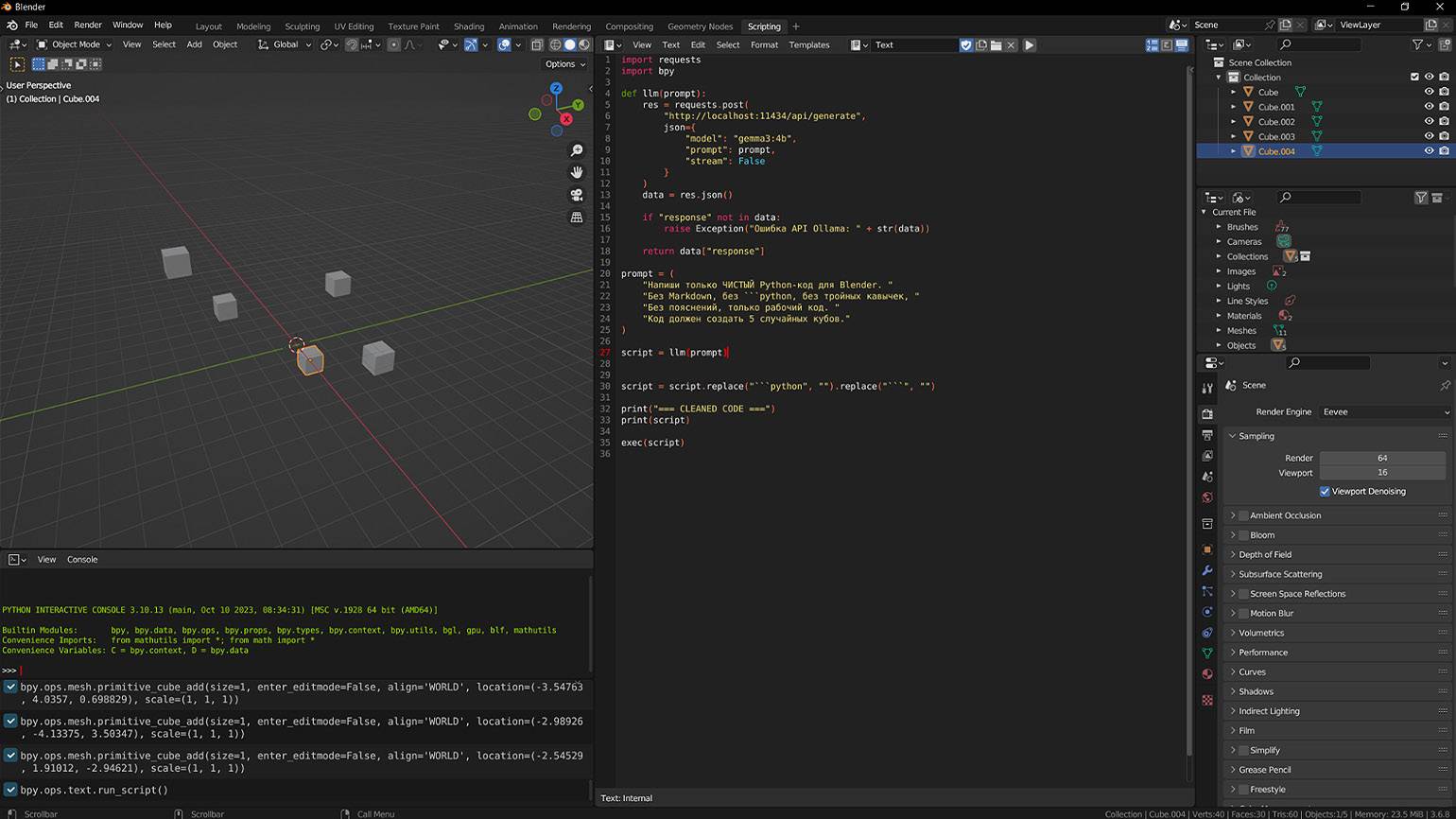
Скриншот: Blender / Skillbox Media

Как создать локальный аналог ChatGPT с Ollama и Open WebUI
В тематических ветках по программированию на Reddit и других сообществах для разработчиков нередко встречаются упоминания об использовании Ollama в сочетании c Open WebUI.
Open WebUI — это локальная ИИ-платформа в формате веб-интерфейса с открытым исходным кодом, которая может работать в связке со многими фреймворками для запуска языковых моделей, в том числе и с Ollama. Такой подход имеет преимущества: работать можно через браузер на любом гаджете, даже на смартфоне, а в истории диалогов становится доступна фильтрация и поиск ответов. Всё как в привычных чат-ботах.
Например, вот что пишет пользователь Porespellar про Open WebUI в сабе LocalLLaMA:

«Прежде всего, спасибо создателям Open WebUI. Это потрясающий и надёжный клиент. Самый профессиональный чат-клиент с открытым исходным кодом + RAG, который я когда-либо использовал. Мне очень нравится реализация Docker, нравятся автоматические обновления Watchtower. Весь процесс развёртывания просто великолепен!»
Но, пожалуй, одна из самых полезных функций — поддержка RAG (Retrieval-Augmented Generation), генерации ответа, с учётом информации из внешних источников. Иными словами, если Ollama просто генерирует ответы, исходя из контекста диалога, в связке с Open WebUI можно подгружать собственные документы — система индексирует их и добавляет их содержимое в контекст моделей.
В результате при ответах ИИ подбирает релевантные фрагменты из загруженных файлов пользователя и формирует ответ, опираясь на эти данные. Такой подход удобно использовать для формирования отчётов, поиска конкретной информации в большом количестве текста, работы с репозиториями и так далее.
Также в Open WebUI существует поддержка многопользовательского режима в рамках локальной сети. Он доступен после регистрации, которую клиент предложит по умолчанию при первом запуске. При этом интернет-соединение не требуется: все данные остаются на компьютере или сервере. Такой подход позволяет контролировать настройки доступа среди участников проекта.
Первый зарегистрированный пользователь получает права администратора и может дать доступ другим участникам локальной сети, которые зарегистрируются позже. Если работа над корпоративными проектами не входит в ваши планы — создавать учётную запись в Open WebUI необязательно и этот шаг можно пропустить.
Устанавливаем Open WebUI и подключаем его к Ollama
Существует несколько способов установки Open WebUI — через Python, Docker или Kubernetes. Рассмотрим вариант загрузки через Docker.
Скачайте установочный клиент Docker Desktop с сайта и запустите установку. После её завершения потребуется перезагрузка компьютера.
Для работы Docker Desktop на Windows требуется подсистема для Linux WSL2. Если она не установлена, введите в PowerShell команду:
wsl --install После перезагрузки запустите Docker, откройте терминал в нижнем правом углу и скачайте образ Open WebUI:
docker pull ghcr.io/open-webui/open-webui:mainПосле этого запустите Open WebUI:
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name
open-webui ghcr.io/open-webui/open-webui:mainЕсли хотите, чтобы сервис запускался без регистрации, потребуется другая команда:
docker run -d -p 3000:8080 -e WEBUI_AUTH=False -v
open-webui:/app/backend/data --name open-webui
ghcr.io/open-webui/open-webui:mainПодробнее обо всех нюансах установки и дополнительных командах можно узнать в официальной документации.
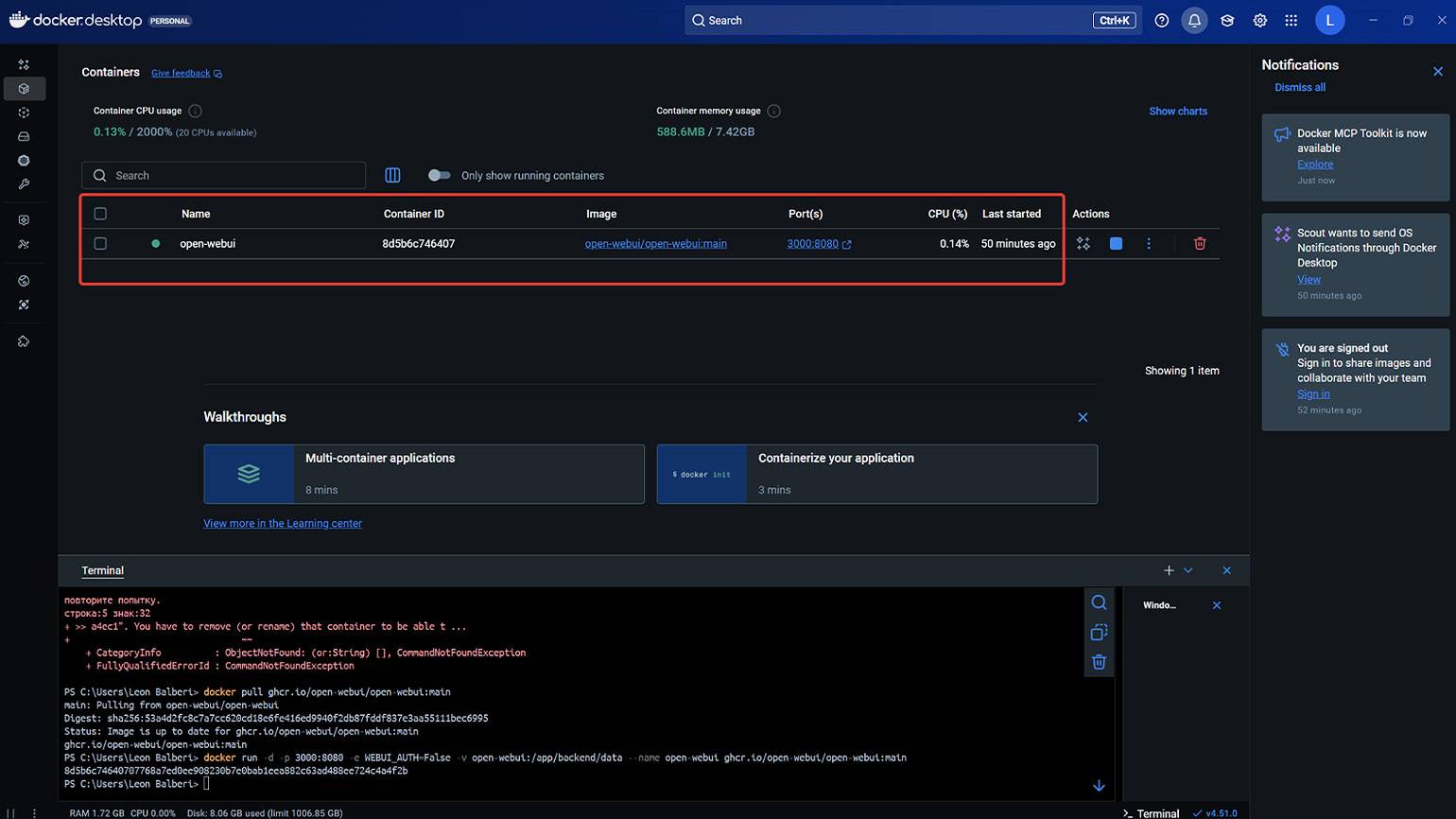
Скриншот: Docker / Skillbox Media
Теперь Open WebUI можно открыть в браузере по адресу http://localhost:3000. В более ранних версиях требовалось подключать вручную Ollama, но в актуальной сборке сервис автоматически распознаёт наличие фреймворка на компьютере и сразу начинает работать в связке. В результате все модели, установленные в Ollama доступны и в Open WebUI.
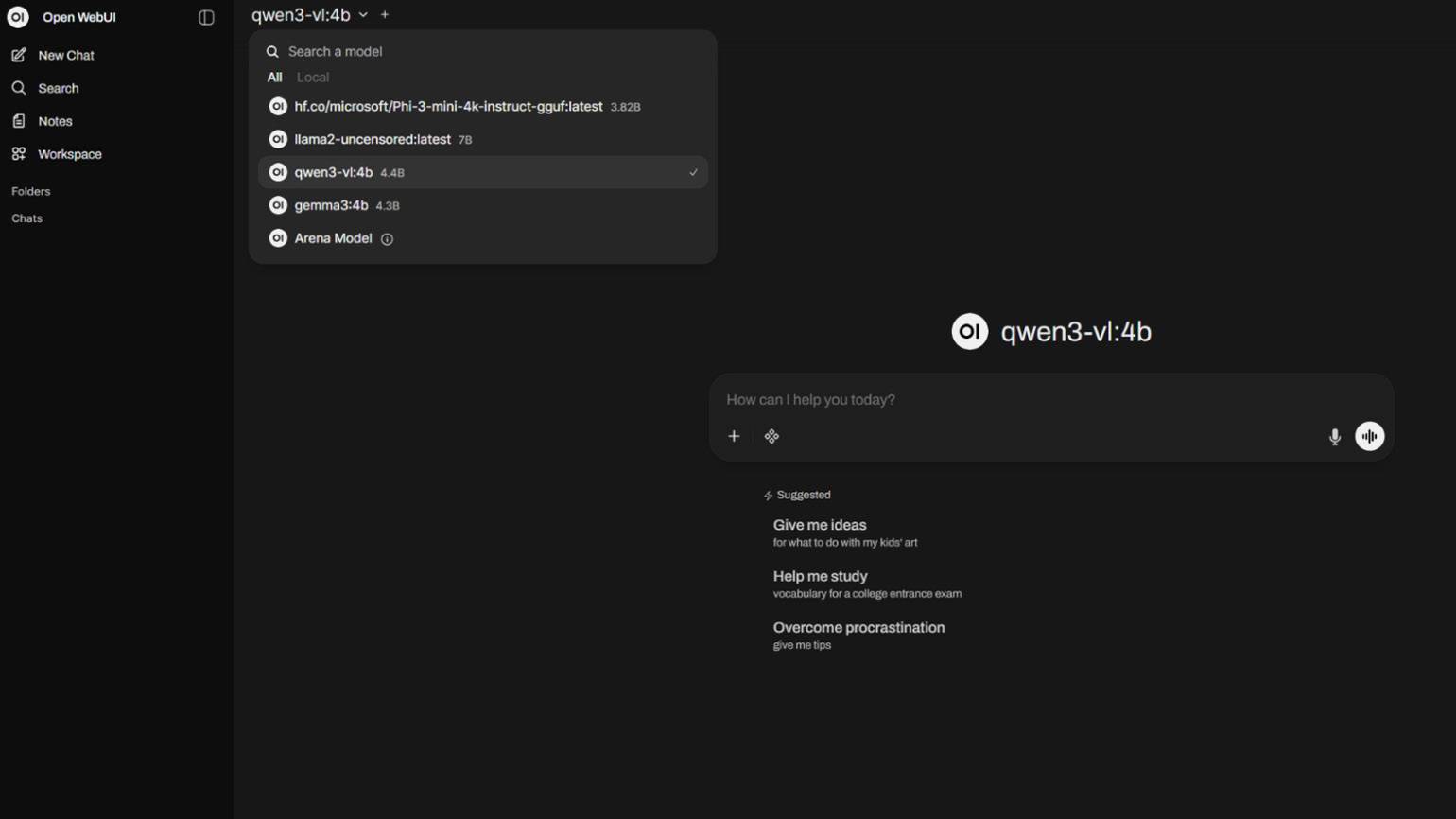
Скриншот: Open WebUI / Skillbox Media
Таким образом, настроив Ollama и Open WebUI, вы получите мощный ИИ-инструмент, который работает локально на компьютере прямо из браузера, как любой популярный чат-бот, например ChatGPT. Дальше можно экспериментировать с разными моделями, загружать документы, настраивать параметры генерации и постепенно кастомизировать систему под собственные задачи. Здесь фантазия не ограничена.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!