Вышла новая библиотека для Python — Lingua: она определяет язык написанного текста
Она точнее остальных библиотек, а ещё её можно запустить в офлайн-режиме.

Задача Lingua проста: с её помощью можно определить, на каком языке написан входной текст, причём для анализа хватает одного слова. Это может быть полезно для классификации текста или проверки на орфографию.
Обычно определение языка происходит при помощи фреймворков машинного обучения или NLP-приложений. Чтобы не разбираться в специфике системы и её функционировании, разработчики предлагают уже готовые решения, такие как библиотека Lingua.
Сейчас она поддерживает 75 языков, и их количество постепенно растёт. Среди них есть и популярные — английский, испанский и русский, — и те, что используются гораздо реже, — коса, урду и тамил.
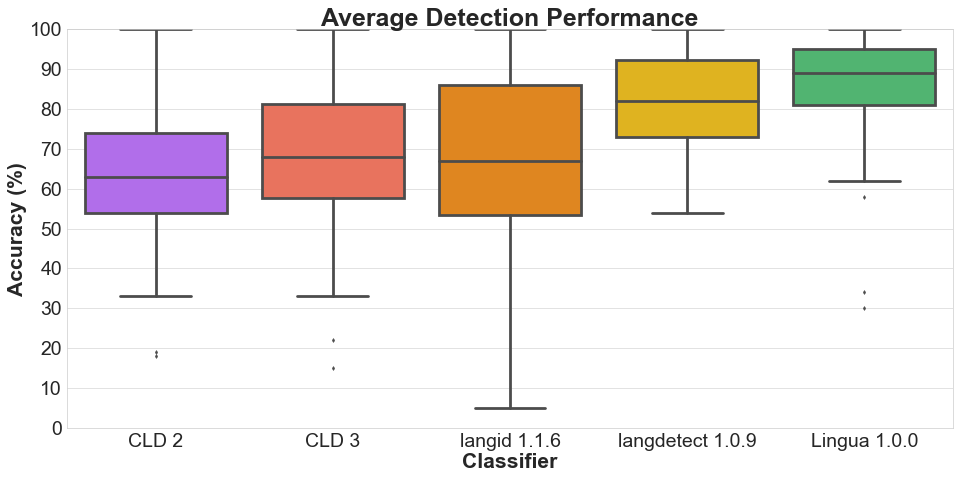
Разработчик Lingua смог решить серьёзные недостатки таких библиотек, как CLD 2, CLD 3, langid и langdetect. Все они, за исключением двух последних, имели следующие проблемы:
- они работали только на больших фрагментах текста, а для коротких (например, пост в Twitter) они не выдавали адекватных результатов;
- чем больше языков присутствовало в тексте, тем менее точным был результат.
Lingua направлена на решение этих проблем. Она почти не требует предварительной настройки и выдаёт относительно точные результаты при работе с текстами любого объёма — от отдельных слов до длинных статей. Кроме того, библиотеке не нужны дополнительные словари или внешние API. Lingua можно использовать сразу же после загрузки — причём даже без интернета.
Подробнее с библиотекой можно познакомиться на Github-странице разработчика.
Вот как на это отреагировали пользователи Reddit:

“Звучит очень изящно”.

“Мне это нравится”.

“Она, наверное, будет хорошо работать вместе с argos-translate”.