LM Studio: что это такое и как локально запустить языковую модель
Личный ChatGPT без подписок, кода и возни с терминалом.


LM Studio — кросс-платформенное приложение для запуска языковых моделей прямо на компьютере. Внешне оно похоже на ChatGPT: тот же чат, где вы можете общаться с ИИ и загружать файлы для анализа. Разница лишь в том, что в LM Studio запросы обрабатываются локально и Сэм Альтман никогда не узнает, над чем вы работаете.
В этой статье мы установим LM Studio и расскажем, где скачивать и как запускать локальные нейросети. А ещё мы протестируем одну модель в разных сценариях и посмотрим несколько альтернативных сервисов.
Содержание
- Разбираем особенности локальных моделей
- Устанавливаем LM Studio и проверяем систему
- Подключаем первую нейросеть
- Ищем лучшие языковые модели для LM Studio
- Проверяем LM Studio в повседневных задачах
- Смотрим на альтернативы LM Studio
Разбираем особенности локальных моделей
Главное преимущество локальных языковых моделей связано с приватностью. Все данные остаются на вашем устройстве и никуда не передаются. Это важно при работе с конфиденциальной информацией — например, при анализе финансовых отчётов компании, обработке карт пациентов или подготовке юридических документов, подпадающих под NDA.
Среди других преимуществ можно выделить следующие:
- Настройка под задачи. Можно адаптировать локальную модель под конкретные нужды: подключить базу знаний, загрузить корпоративные документы или обучить её специализированной терминологии. Так вы получите ассистента, который лучше понимает контекст вашей работы и даёт более точные ответы.
- Свобода общения. У всех облачных нейросетей есть темы, которые нельзя обсуждать. Например, DeepSeek аккуратно обходит вопросы о Тайване и событиях на площади Тяньаньмэнь в 1989 году, а ChatGPT часто отказывается давать медицинские, психологические и финансовые советы. В большинстве локальных моделей такие ограничения можно легко отключить.
- Работа без интернета. Локальные нейросети выручают в удалённых местах или при нестабильном соединении — в самолёте, на даче без Wi-Fi или в зонах с плохим покрытием.
- Экономия средств. Локальные модели не требуют платной подписки и позволяют обрабатывать неограниченное количество запросов. При этом всё работает без очередей, которые возникают в бесплатных версиях облачных сервисов.
Из основных недостатков мы бы выделили сильную зависимость от ресурсов компьютера. Например, для работы с моделями на 70 миллиардов параметров вам нужно не менее 64 ГБ оперативной памяти и видеокарта с большим объёмом VRAM. Даже 32 ГБ ОЗУ может быть недостаточно для локального запуска нейросетей уровня ChatGPT — такие модели будут тормозить или вообще не запустятся.
Кроме того, локальные нейросети не подключены к интернету. Поэтому они не могут искать актуальную информацию и без обновлений будут выдумывать данные или ссылаться на устаревшие.
Устанавливаем LM Studio и проверяем систему
Перейдите на сайт lmstudio.ai и нажмите на кнопку Download. Мы установим LM Studio на MacBook Pro с чипом M1 Pro и 16 ГБ ОЗУ.
Если на главной странице сайта ваша операционная система не определилась автоматически, то перейдите в раздел Download. В нём выберите ОС, укажите архитектуру процессора и скачайте программу.
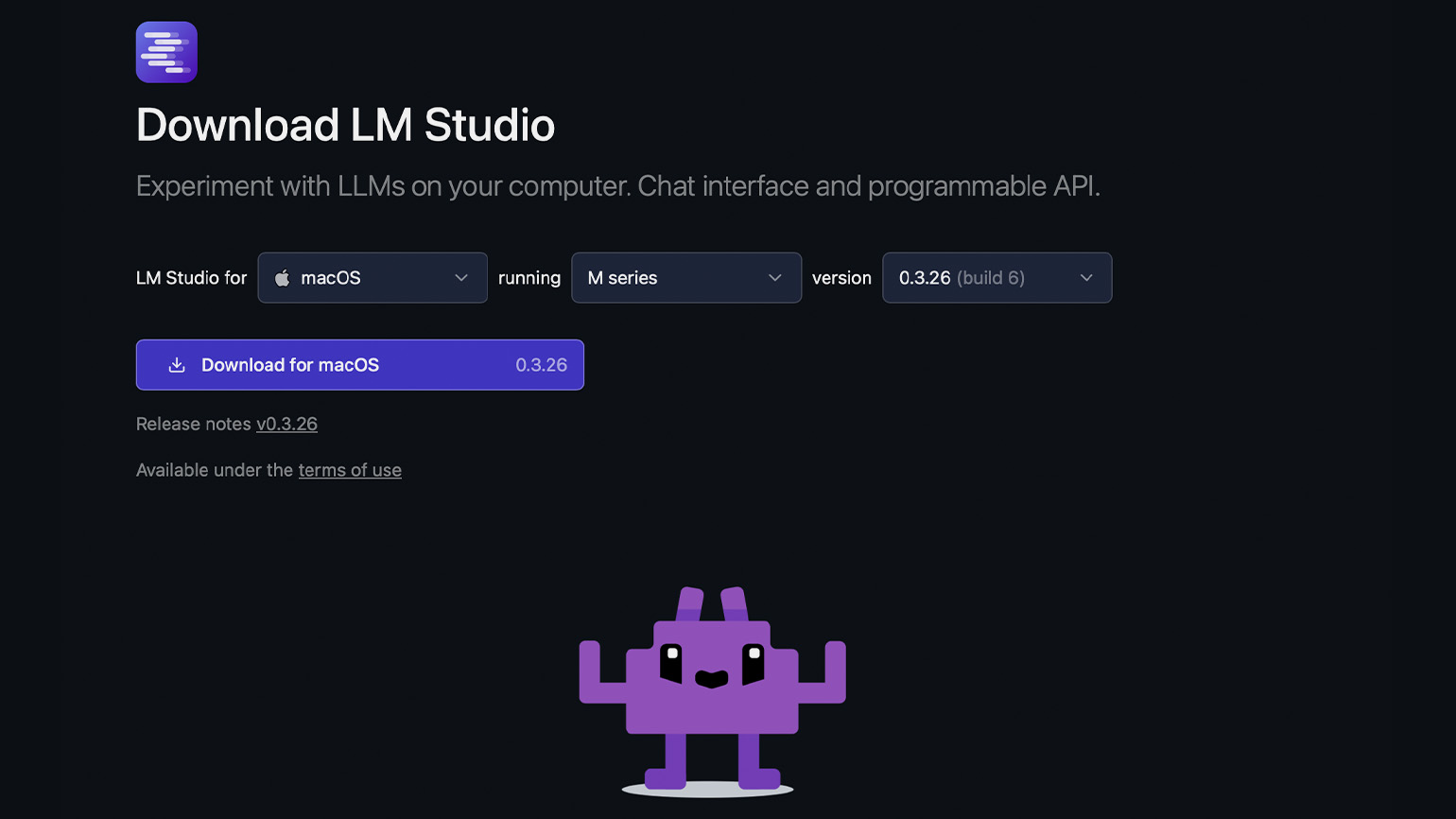
После запустите скачанный файл и установите его как обычную программу. Например, на macOS нужно перенести иконку LM Studio в папку Applications, а на Windows — пройти шаги, которые предложит мастер установки.
Если всё получилось, то после запуска вы увидите главный экран приложения — он напоминает интерфейсы ChatGPT, DeepSeek, Grok и других сервисов. В центре появится маленький фиолетовый робот с надписью LM STUDIO, а ниже — пустое окно с полем Send a message to the model…. Именно сюда вы будете вводить свои запросы к модели.
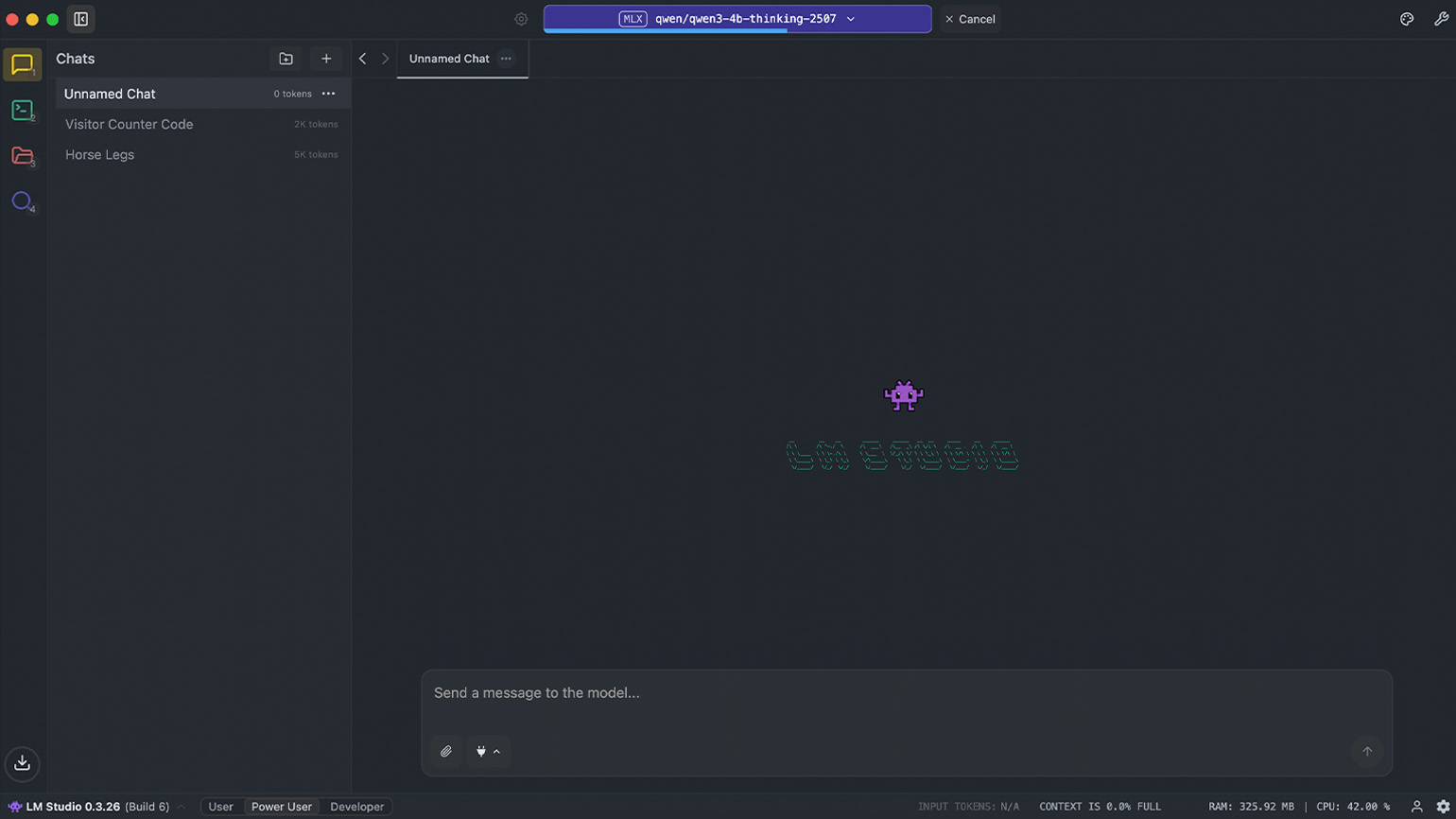
Однако, если LM Studio не запускается, скорее всего, ваше устройство не соответствует рекомендованным системным требованиям:
|
|
macOS | Windows | Linux |
|---|---|---|---|
| Процессор |
Чипы Apple Silicon (M1–M4) |
Любой современный процессор — Intel, AMD или ARM (например, Snapdragon X Elite) | 64-битный Intel, AMD или ARM |
| Система | macOS 13.4 и новее, для MLX — с версии 14.0 | Windows 10 / 11 | Ubuntu 20.04 и новее |
| Оперативная память | От 16 ГБ, на 8 ГБ пойдут только лёгкие модели | От 16 ГБ | От 16 ГБ |
| Видеокарта | Используется общая память чипа | Желательна видеокарта с 4 ГБ VRAM | Зависит от конфигурации |
| Особенности | Не поддерживаются старые Mac с Intel | Без видеокарты всё работает медленно | Запускается в формате AppImage, без установки в систему |
Пара слов о системных требованиях. Недавно мы готовили статью о локальных нейросетях и попробовали установить LM Studio на MacBook с чипом Intel и на Linux Mint. На MacBook программа работала, хотя официально не поддерживается. А вот на Linux она без проблем установилась, но так и не запустилась. С чем это связано — непонятно.
Подключаем первую нейросеть
Из коробки LM Studio — это просто оболочка без встроенных нейросетей. Поэтому если сразу после установки вы введёте запрос в чат, то ничего не произойдёт. Чтобы начать работу, на левой панели нажмите на значок поиска — вы попадёте в раздел Discover. В нём вы можете просмотреть список моделей с открытым исходным кодом и загрузить подходящую. Проще говоря, это маркетплейс нейросетей.
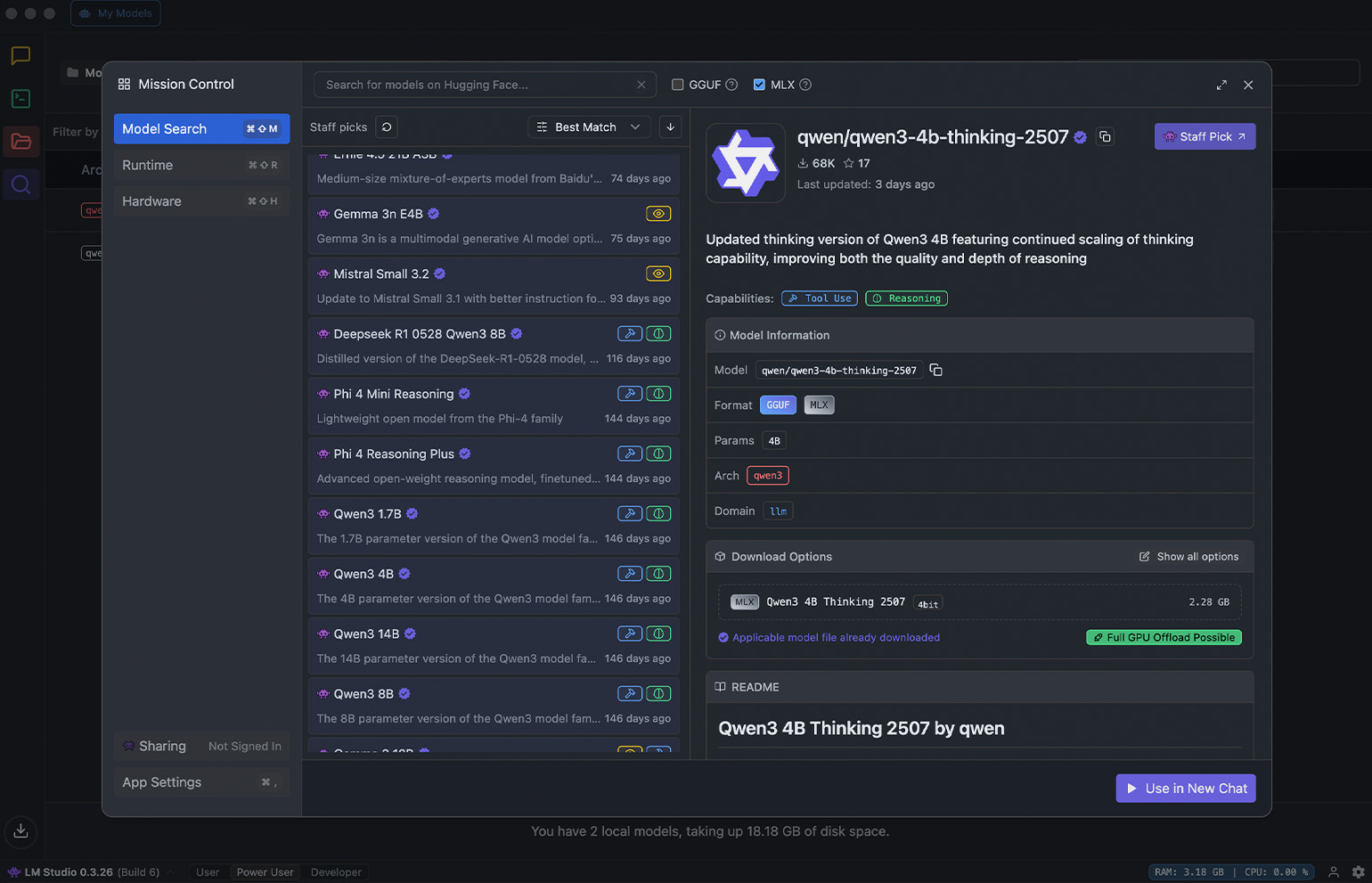
Скриншот: LM Studio / Skillbox Media
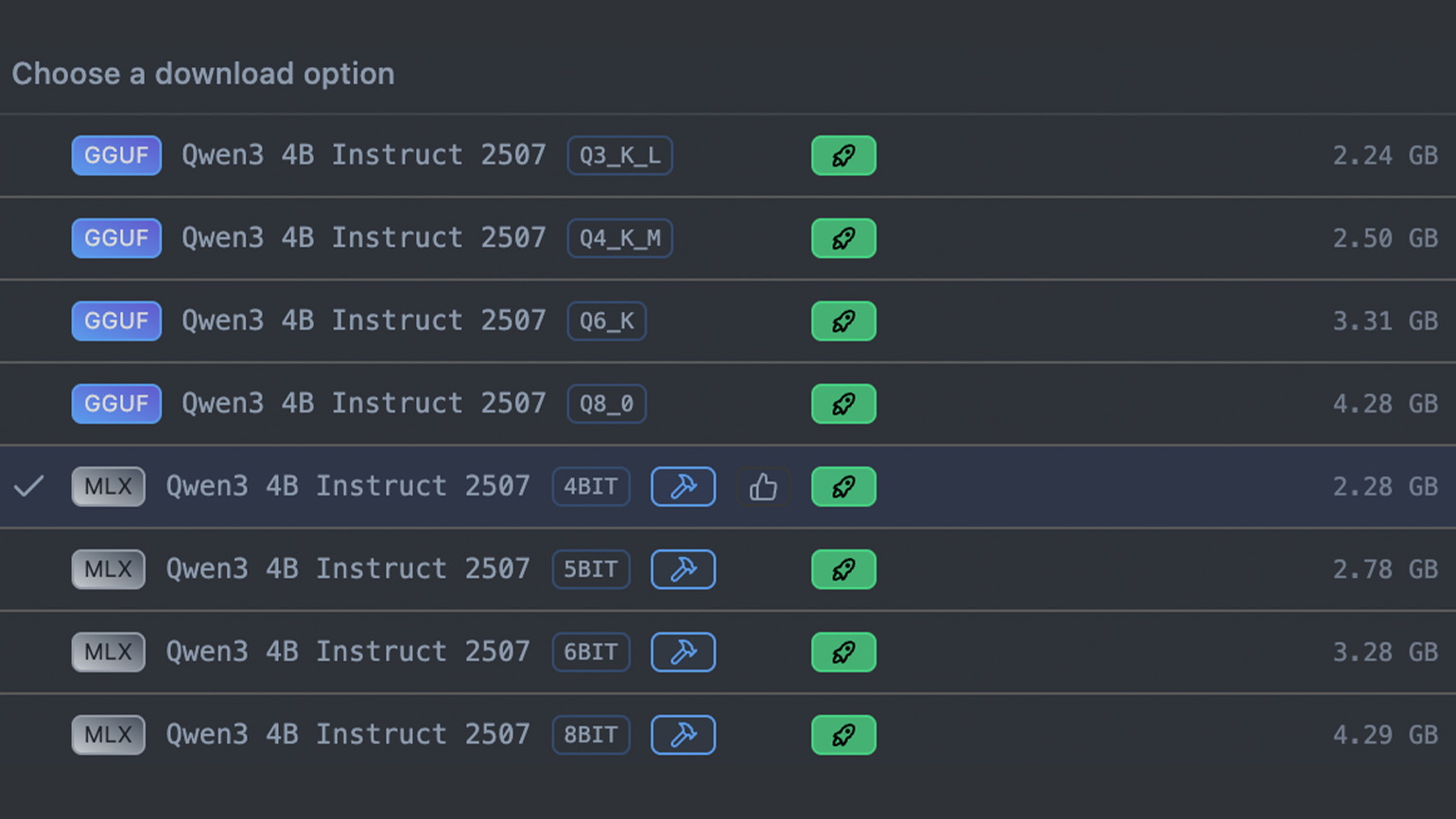
Для примера установим Qwen3 4B Thinking 2507 — компактную рассуждающую языковую модель от команды Qwen. Она поддерживает расширенный контекст до 256 000 токенов и подходит для многих повседневных задач: генерации и редактирования текста, написания кода, объяснения решений и ответов на вопросы. Для запуска нам понадобится 4 ГБ оперативной памяти и 3 ГБ места на диске.
Введите в поиске Qwen3-4b-thinking-2507. Если у вас macOS, то в списке версий выберите формат MLX, для других ОС — GGUF. Затем нажмите Download, дождитесь загрузки и кликните на Use in New Chat.
Скриншот: LM Studio / Skillbox Media
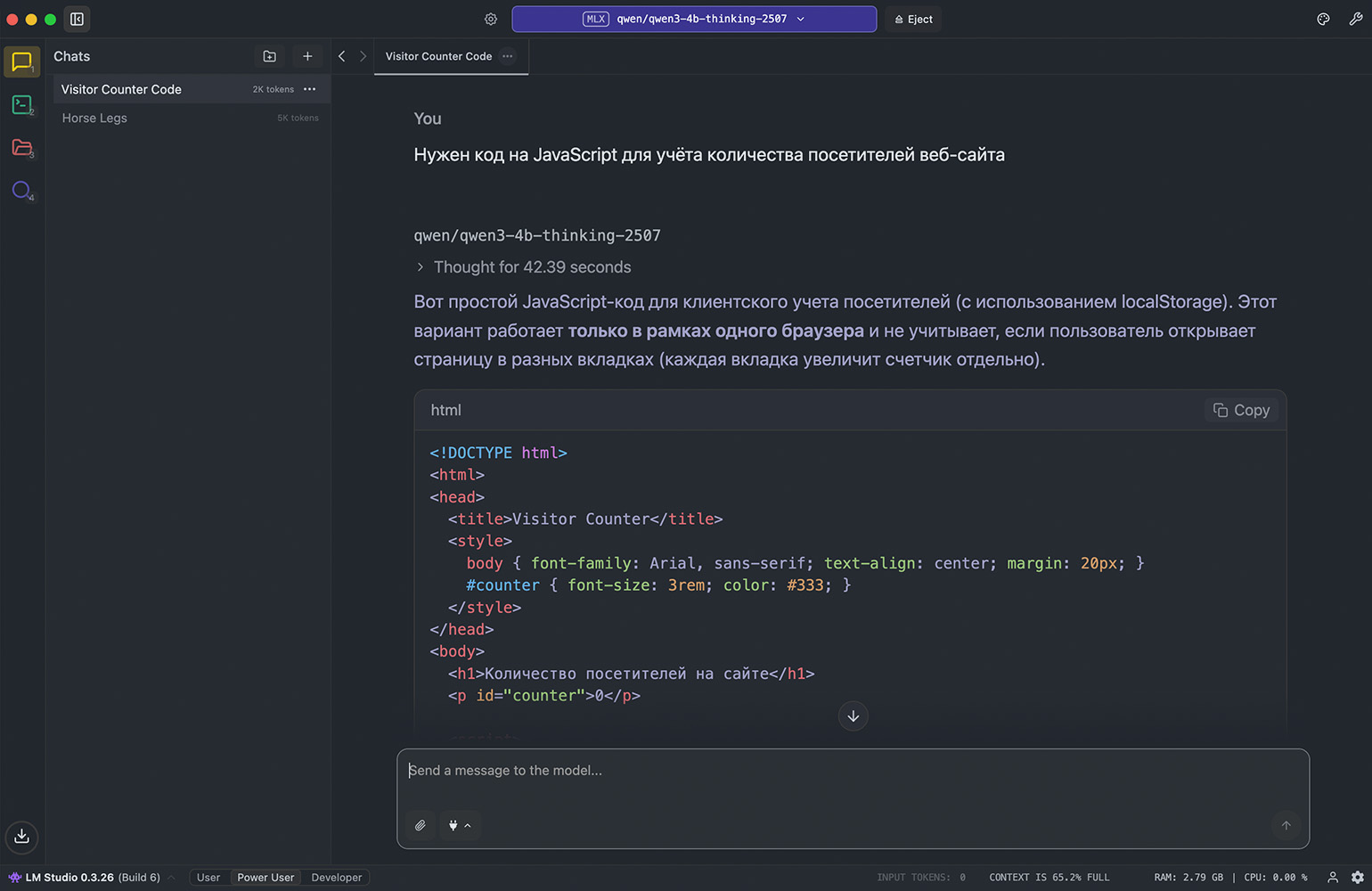
После этого откроется окно чата, где вы сможете ввести запрос для нейросети. Мы установили рассуждающую модель, поэтому перед генерацией ответа она некоторое время будет анализировать ваш запрос и подбирать оптимальный вариант. Также в чате будет отображаться цепочка рассуждений, и по ней вы сможете понять, почему нейросеть выбрала такое решение или где могла ошибиться.
Имейте в виду, что скорость ответов зависит от производительности компьютера. Например, на Windows, помимо достаточного объёма оперативной памяти, вам желательно использовать производительную видеокарту — LM Studio выгрузит в неё часть слоёв модели, чтобы ускорить генерацию. Если видеокарты нет или у неё недостаточно памяти, то вся нагрузка ляжет на процессор, и это замедлит процесс.
Скриншот: LM Studio / Skillbox Media
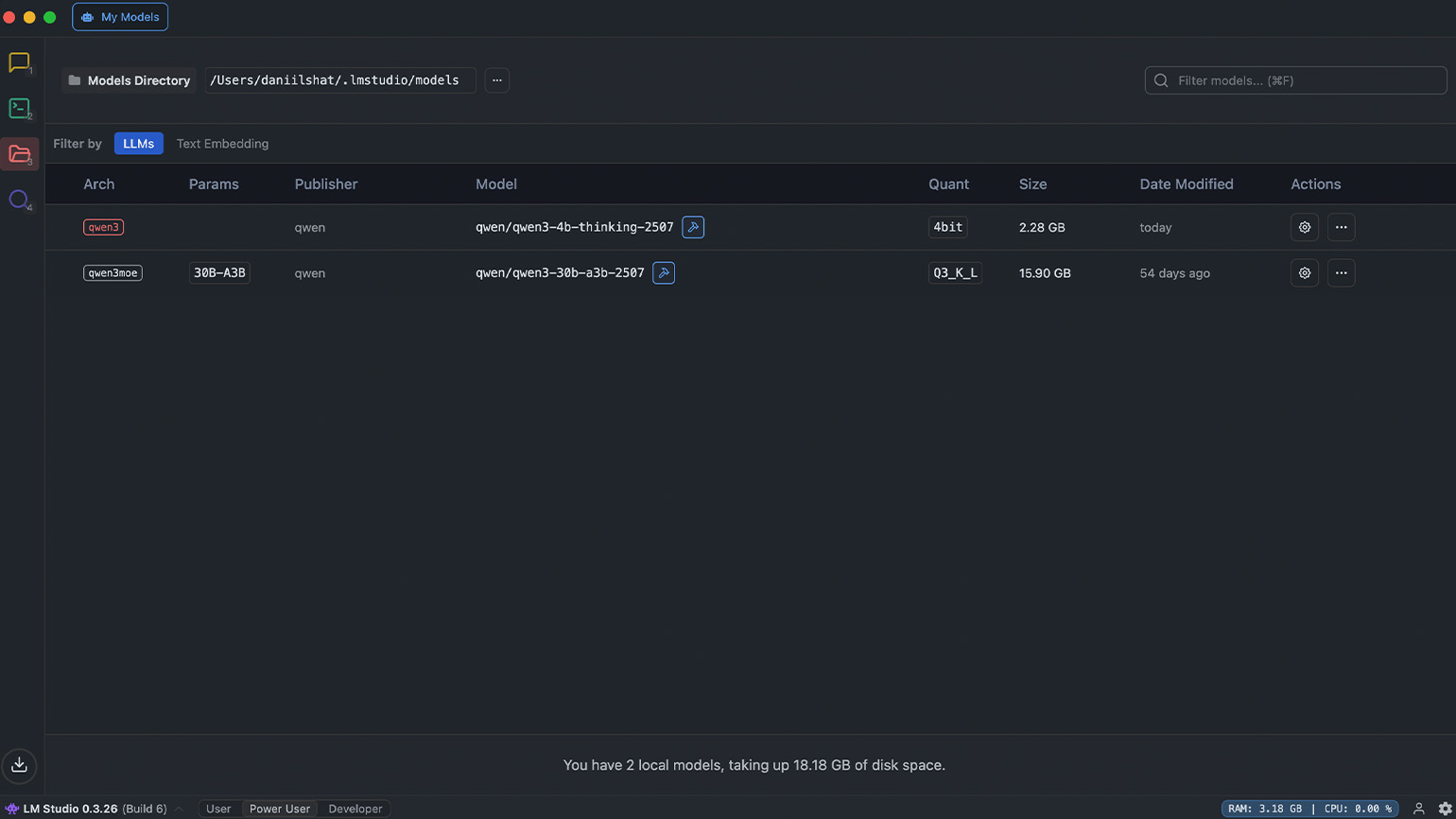
Помимо поиска, на левой боковой панели находятся значки папки и терминала. Значок с папкой открывает раздел My Models — здесь отображаются все языковые модели, которые сохранены на компьютере. Если вы выберете любую из них, то увидите имя разработчика, количество параметров, тип квантизации и размер файла. А если модель больше не нужна, то отсюда её можно удалить.
Скриншот: LM Studio / Skillbox Media
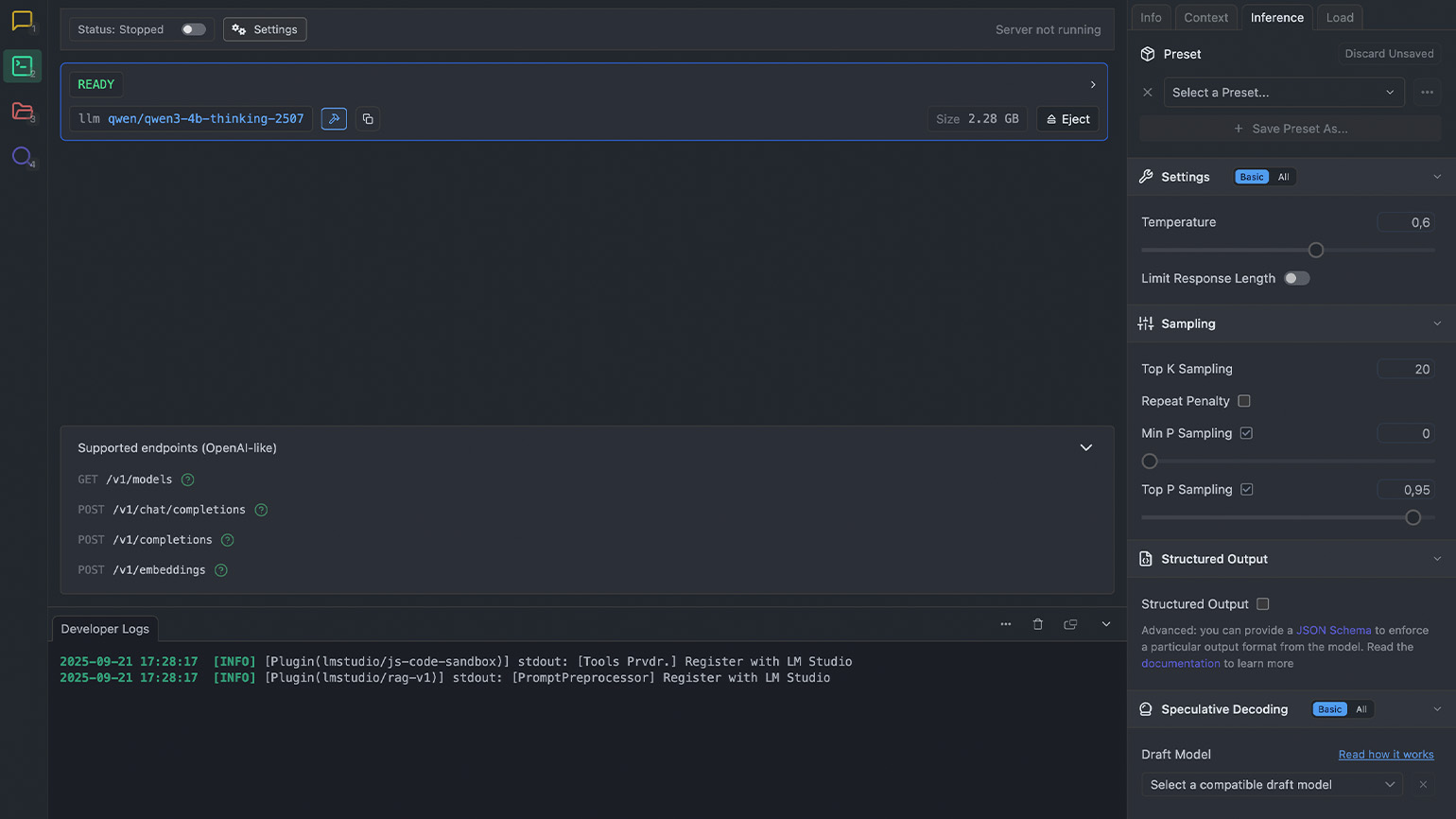
Значок с терминалом открывает раздел Developer. В нём вы можете просмотреть параметры запущенной модели, изучить логи и запустить сервер для подключения нейросети к другим приложениям. Также в этом разделе доступны настройки моделей: вы можете задать системный промпт, управлять инференсом и менять длину контекста.
Скриншот: LM Studio / Skillbox Media
Ищем лучшие языковые модели для LM Studio
В LM Studio вы можете запускать десятки языковых моделей, и ниже мы добавим несколько популярных вариантов для разных сценариев:
- gpt-oss-20b — открытая модель от OpenAI с 20 миллиардами параметров. Будет работать на обычных ПК с 16 ГБ оперативной памяти и подойдёт тем, кто привык к стилю ответов ChatGPT.
- gpt-oss-120b — более мощная версия со 120 миллиардами параметров, которая справляется со сложными задачами, рассуждениями и анализом больших объёмов информации. Для полноценного запуска нужна видеокарта с 80 ГБ VRAM.
- qwen2.5-coder-14b — модель для генерации кода и подготовки технической документации. Запускается на видеокартах с 8–12 ГБ видеопамяти и на компьютерах с 16 ГБ оперативной памяти.
- gemma-3-12b — умеет генерировать текст и код, распознавать изображения и отвечать на вопросы. Для версии с 12 миллиардами параметров потребуется около 32 ГБ оперативной памяти. Есть и другие варианты: gemma-3-1b (4 ГБ), gemma-3-4b (8 ГБ) и gemma-3-27b (64 ГБ). Если вы будете использовать сжатые версии, то последнюю модель можно запустить на 16 ГБ ОЗУ.
- phi-4-mini-reasoning — это компактная рассуждающая модель от Microsoft с 3,8 миллиарда параметров и расширенным контекстным окном. Она хорошо справляется с логическими рассуждениями и задачами, где нужно что-то спланировать. Для запуска вам потребуется не менее 16 ГБ оперативной памяти.
Локальные модели удобнее всего искать не через поиск в LM Studio, а на портале Hugging Face — это своеобразный нейросетевой GitHub, где собраны тысячи моделей с открытым исходным кодом. В каждом репозитории есть сама нейросеть, описание её возможностей, инструкции по запуску, дообучению и настройке под разные задачи.
На сайте добавлены фильтры, через которые удобно искать модели. В них вы можете выбрать число параметров, задачи, поддерживаемые языки, адаптацию под конкретные приложения для запуска и оптимизацию под требования провайдеров. А дальше вы просто заходите в LM Studio и через поиск находите подходящую нейросеть.
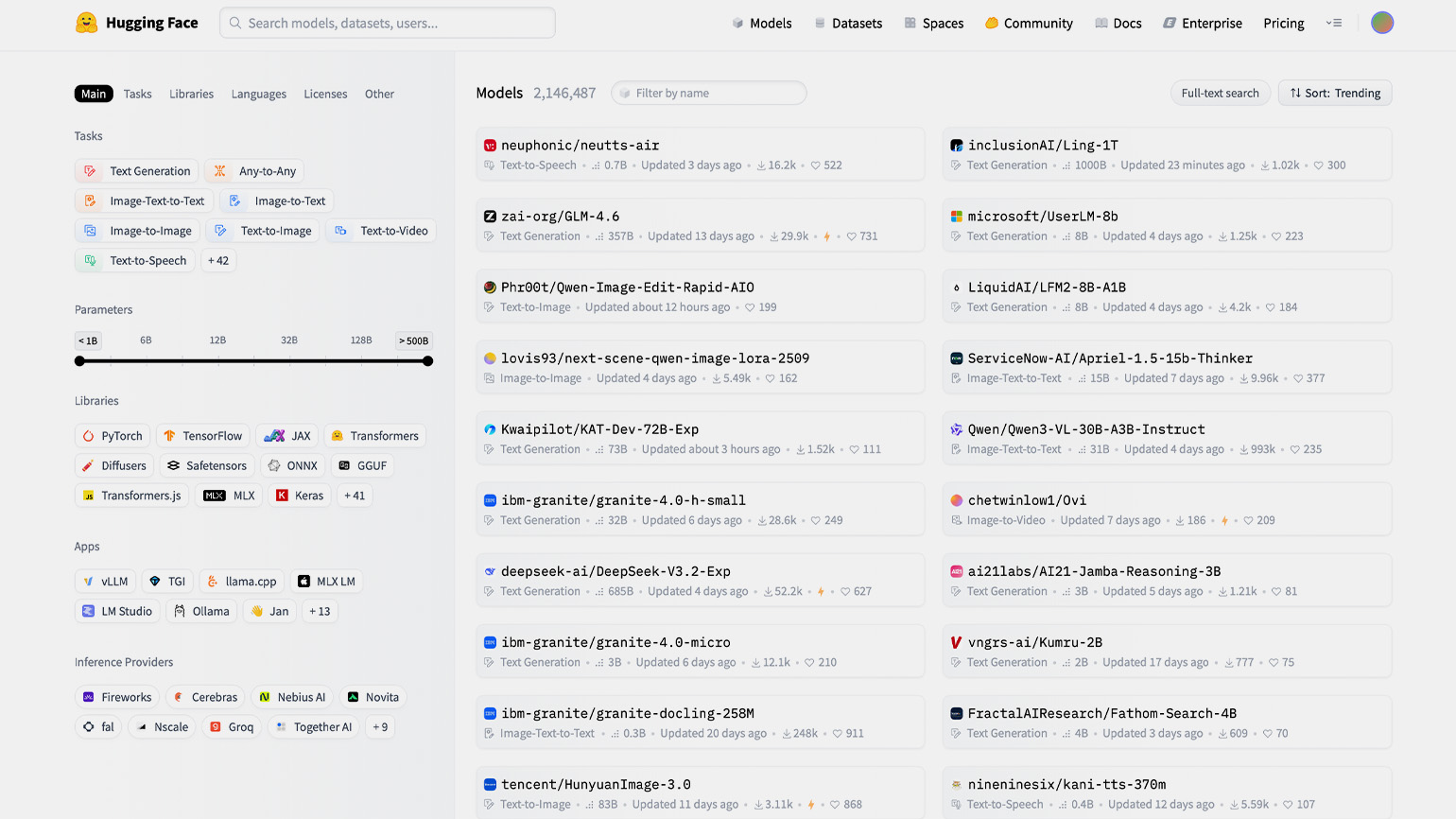
Скриншот: Hugging Face / Skillbox Media
Проверяем LM Studio в повседневных задачах
Качество ответов локальных моделей сильно зависит от количества параметров нейросети — чем их больше, тем точнее и лучше сгенерированный результат. В примерах ниже мы протестируем установленную нейросеть Qwen 3 с 4 миллиардами параметров. Посмотрим, что выйдет и как она справится с программированием, поиском фактов, созданием текста и решением математических задач.
Программирование
Сначала мы попросили нейросеть создать скрипт на Python, который выводит на экран английский алфавит в формате Aa, Bb, Cc, Dd и так далее. Получился вполне рабочий код, который справляется с задачей:
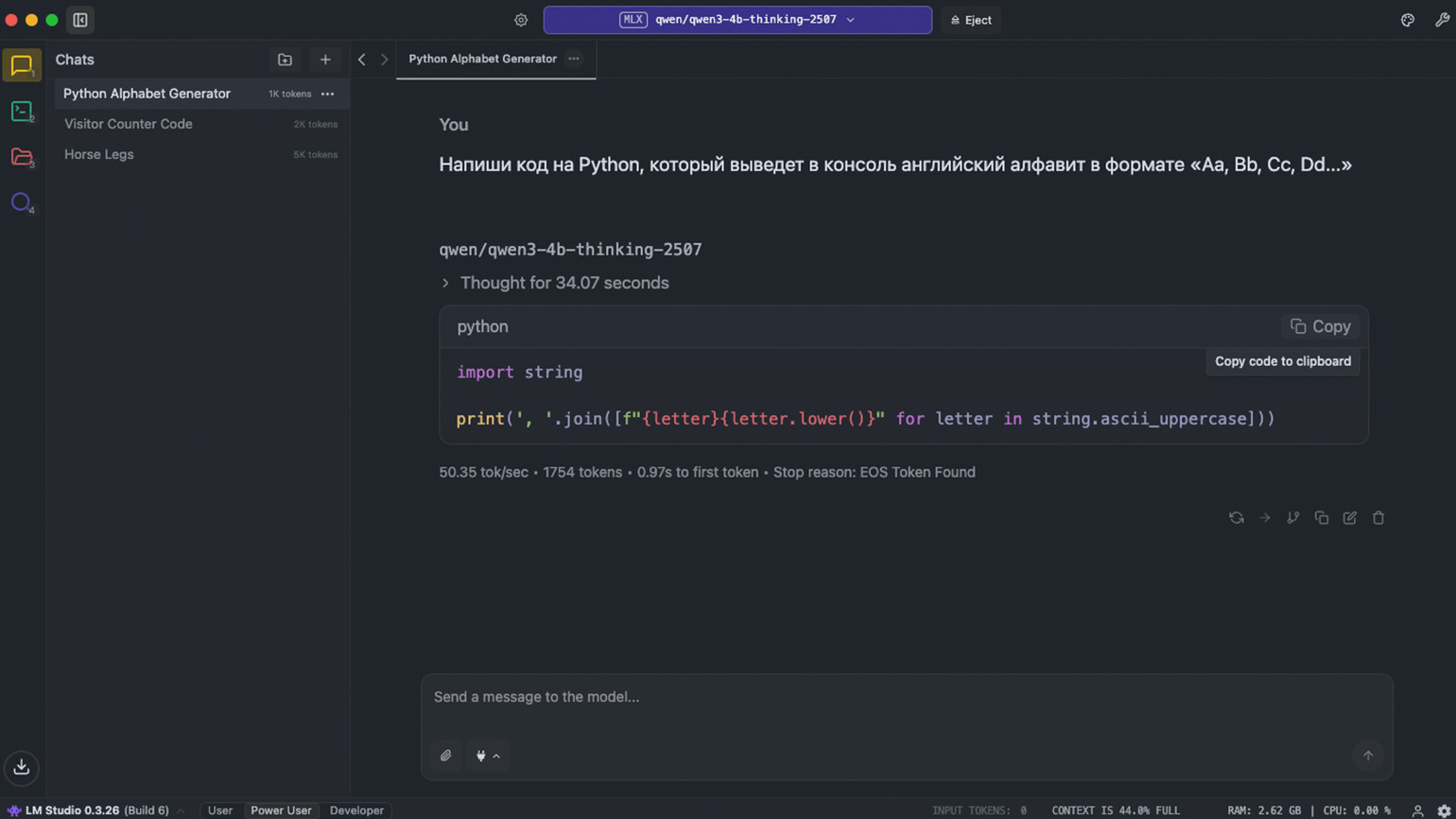
Мы усложнили задачу и попросили Qwen исправить ошибку в коде. Нейросеть проанализировала проблему, предложила исправленный вариант и объяснила, почему функция не работала. Вот наш промпт:
Функция должна возвращать новый список с добавленным элементом. Почему же при нескольких вызовах элементы накапливаются? Найди и исправь ошибку.
def append_item(item, items=[]):
items.append(item)
return items
print(append_item("a")) # ожидаешь: ["a"]
print(append_item("b")) # ожидаешь: ["b"], а что получится?
print(append_item("c")) # ожидаешь: ["c"], а что получится?Ниже публикуем ответ локалочки:
Исходная ошибка в том, что список items=[] используется как ссылка по умолчанию. Это означает, что при каждом вызове функции происходит изменение одного и того же списка, а не создания нового. В результате при последующих вызовах элементы накапливаются.
Исправленный код:
def append_item(item, items=None):
if items is None:
items = []
items.append(item)
return itemsОбъяснение:
- При первом вызове append_item («a») создаётся новый пустой список [], затем добавляется «a», возвращается [«a»].
- При втором вызове append_item («b») параметр items по умолчанию None проверяется, и создаётся новый пустой список [], затем добавляется «b», возвращается [«b»].
- При третьем вызове append_item («c») аналогично создаётся новый список [] и добавляется «c».
Таким образом, функция теперь возвращает новый список с каждым вызовом, а не накапливает элементы.
Пример работы:
print(append_item("a")) # ["a"]
print(append_item("b")) # ["b"]
print(append_item("c")) # ["c"]Поиск фактов
У нашей Qwen 3 нет доступа к веб-поиску, поэтому она способна выдумывать события и искажать информацию. Мы спросили, в каких цветах Apple выпустила iPhone 17 Pro Max. В ответ нейросеть заявила, что это будущая модель, поэтому данных о дизайне у неё пока нет.
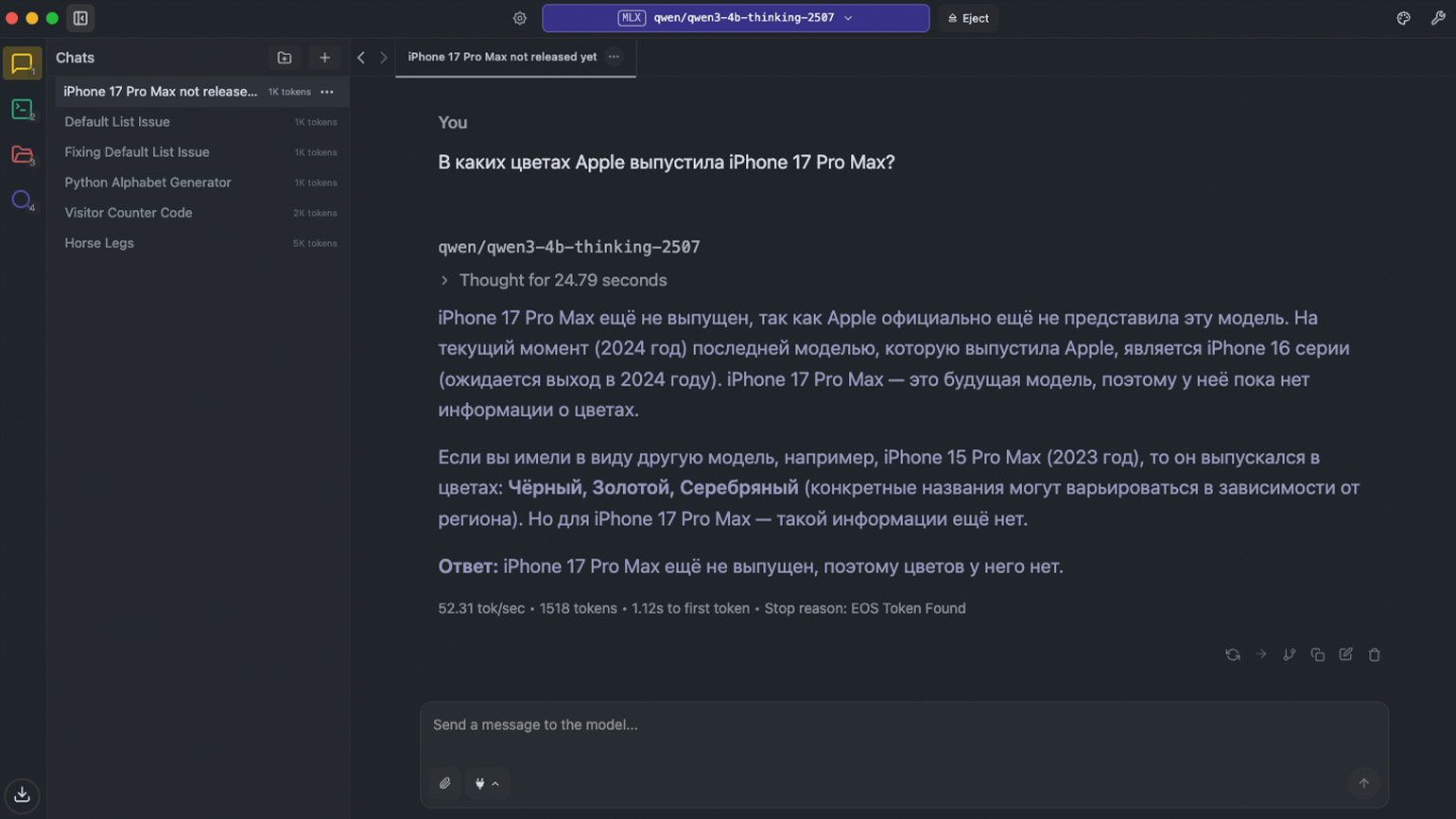
ChatGPT без проблем отвечает на этот вопрос и приводит в качестве источника официальный сайт Apple. Не спорим — веб-поиск важен.
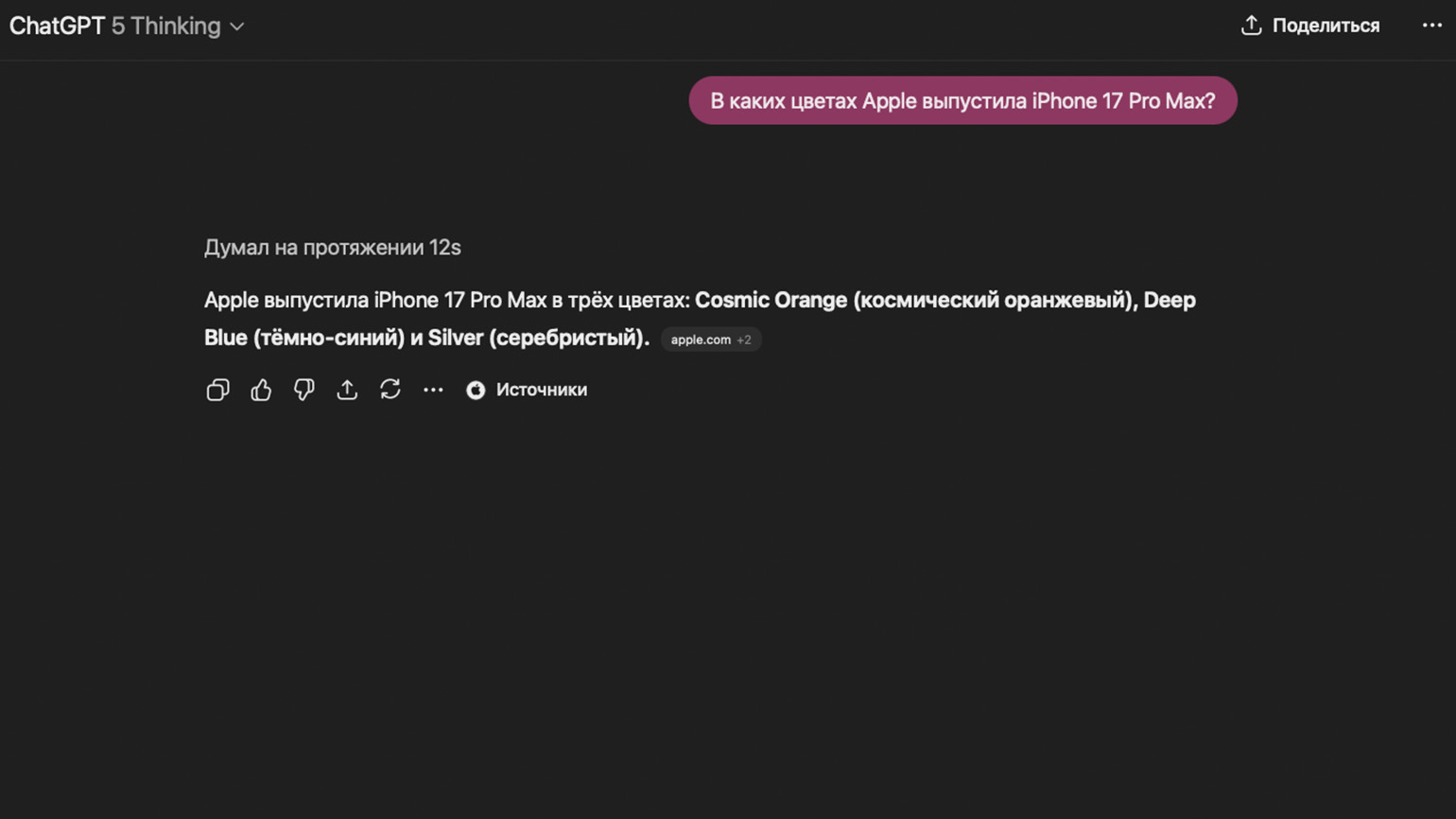
Генерация текста
Для теста мы попросили Qwen 3 сгенерировать поздравление с днём рождения для вымышленного друга Артёма. Чтобы усложнить задачу, мы указали, что в тексте должны быть креативные упоминания «Формулы-1» и программирования — увлечений именинника. Текст вы видите ниже, а нам остаётся лишь вручить его какому-нибудь Артёму:
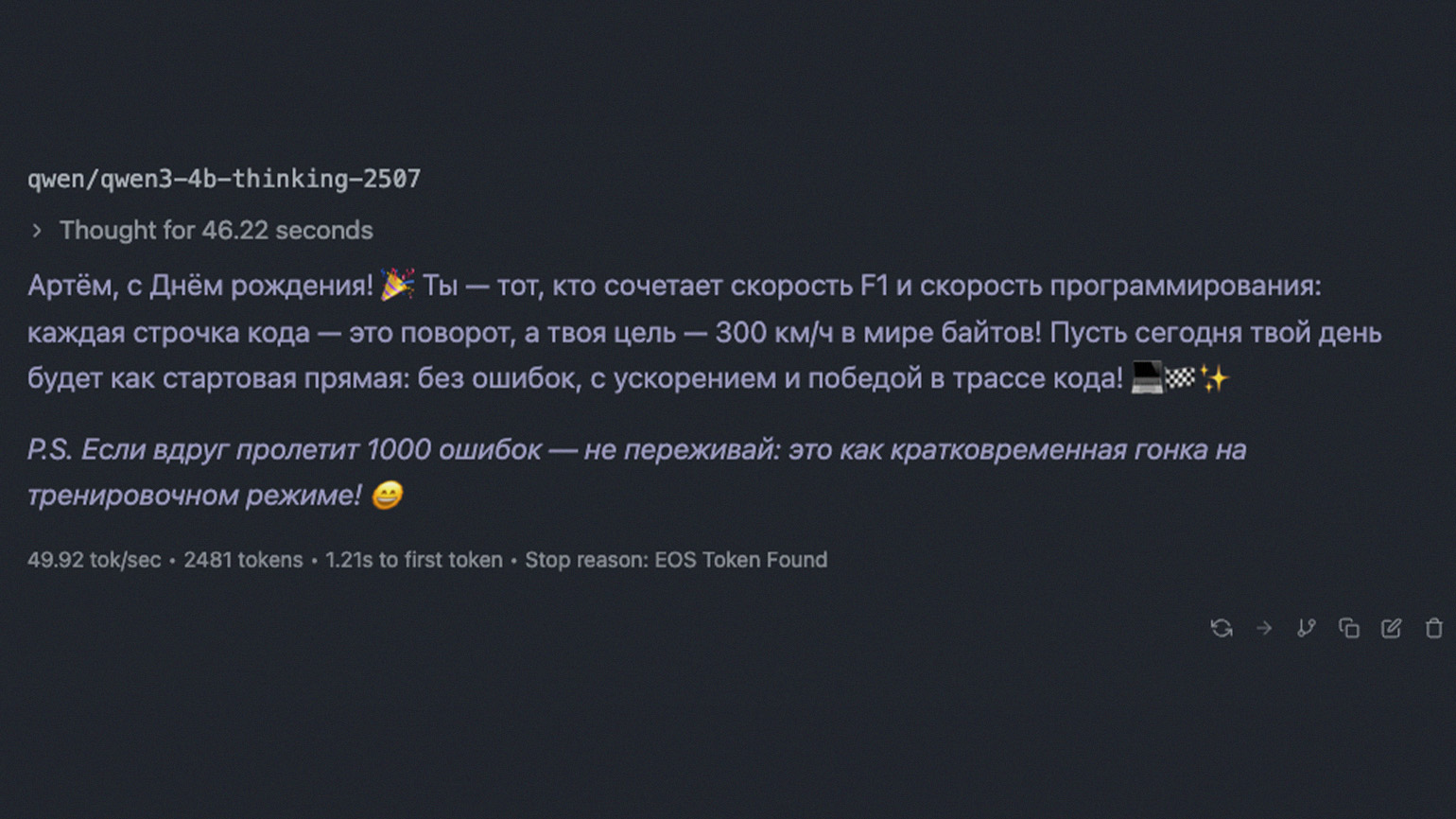
Задания по математике
Возьмём сложное выражение и попросим нейросеть его упростить:

К сожалению, Qwen 3 не умеет распознавать изображения. Поэтому мы конвертировали запись в LaTeX-формат и отправили её в таком виде: \sqrt{(2\sqrt{11}-3\sqrt{5})^{2}}+\frac{2}{4\sqrt{5}+9}+\sqrt{44}-18.
Языковая модель обработала запрос за 36 секунд, подробно расписала решение и получила правильный ответ. Посмотрите результат:
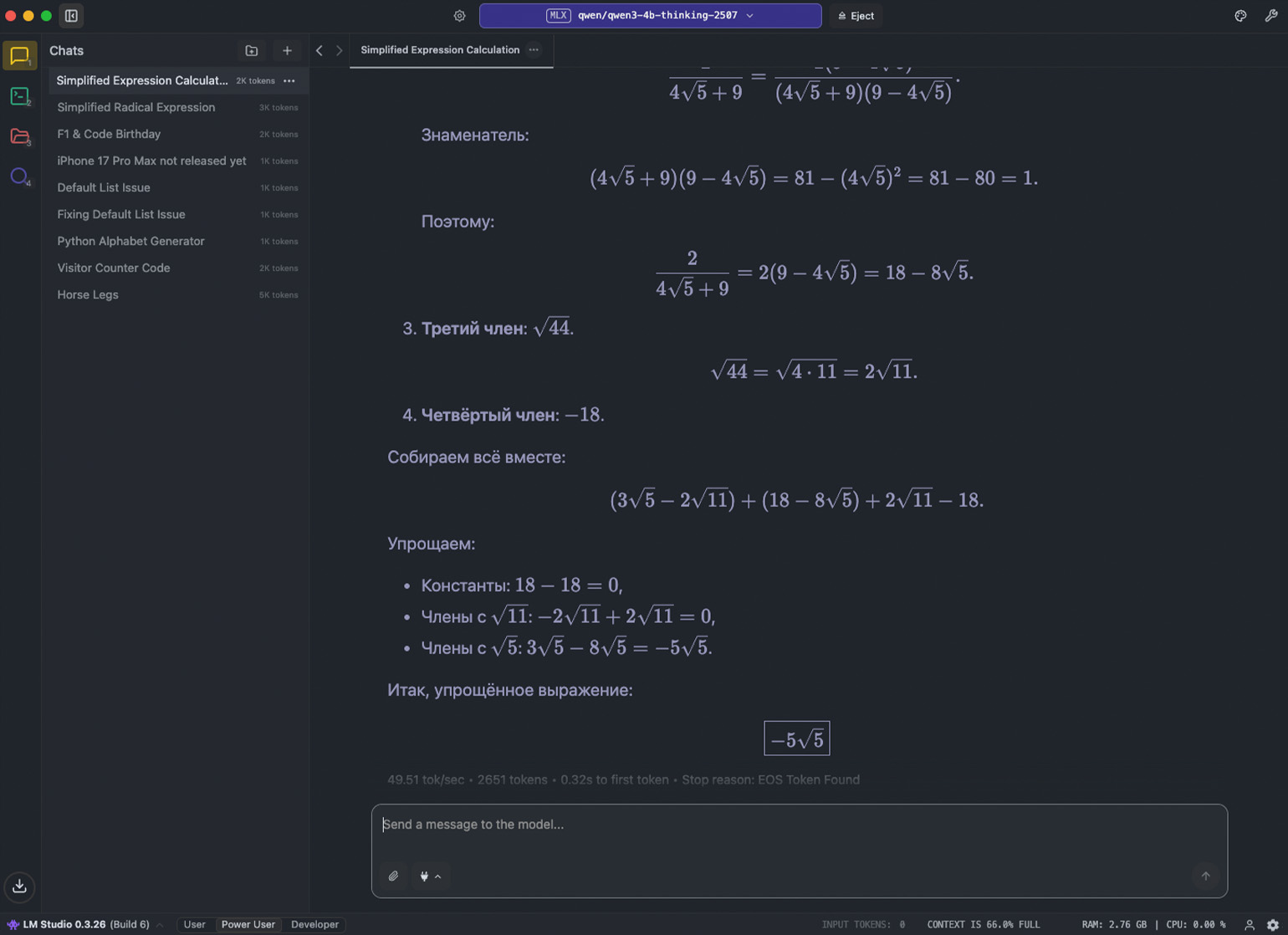
Смотрим на альтернативы LM Studio
В этом разделе мы хотели сделать краткий обзор нескольких бесплатных кросс-платформенных приложений, которые по функциям похожи на LM Studio. По описанию нам подошли Ollama, GPT4All и Jan.
Мы установили эти программы и планировали загрузить в каждую из них модель Qwen3 4B Thinking 2507. Затем мы задали бы всем один вопрос: «Расскажи, чем ты лучше LM Studio?» — и показали результаты.
Однако ничего не вышло. Мы без проблем установили Qwen 3 в GPT4All и Jan, но обе программы выдавали ошибку при попытке получить ответ. В каталоге Ollama нужной модели не оказалось, поэтому мы скачали базовую gemma3:4b, которая зависла при первом запуске.
Никаких выводов из этого мы не делаем. Возможно, стоит глубже разобраться в настройках каждого сервиса, перезапустить их или попробовать другие модели. Если у вас будет желание — обязательно поэкспериментируйте. Но, если хочется начать без лишних сложностей, — в конце 2025 года мы можем порекомендовать только LM Studio.
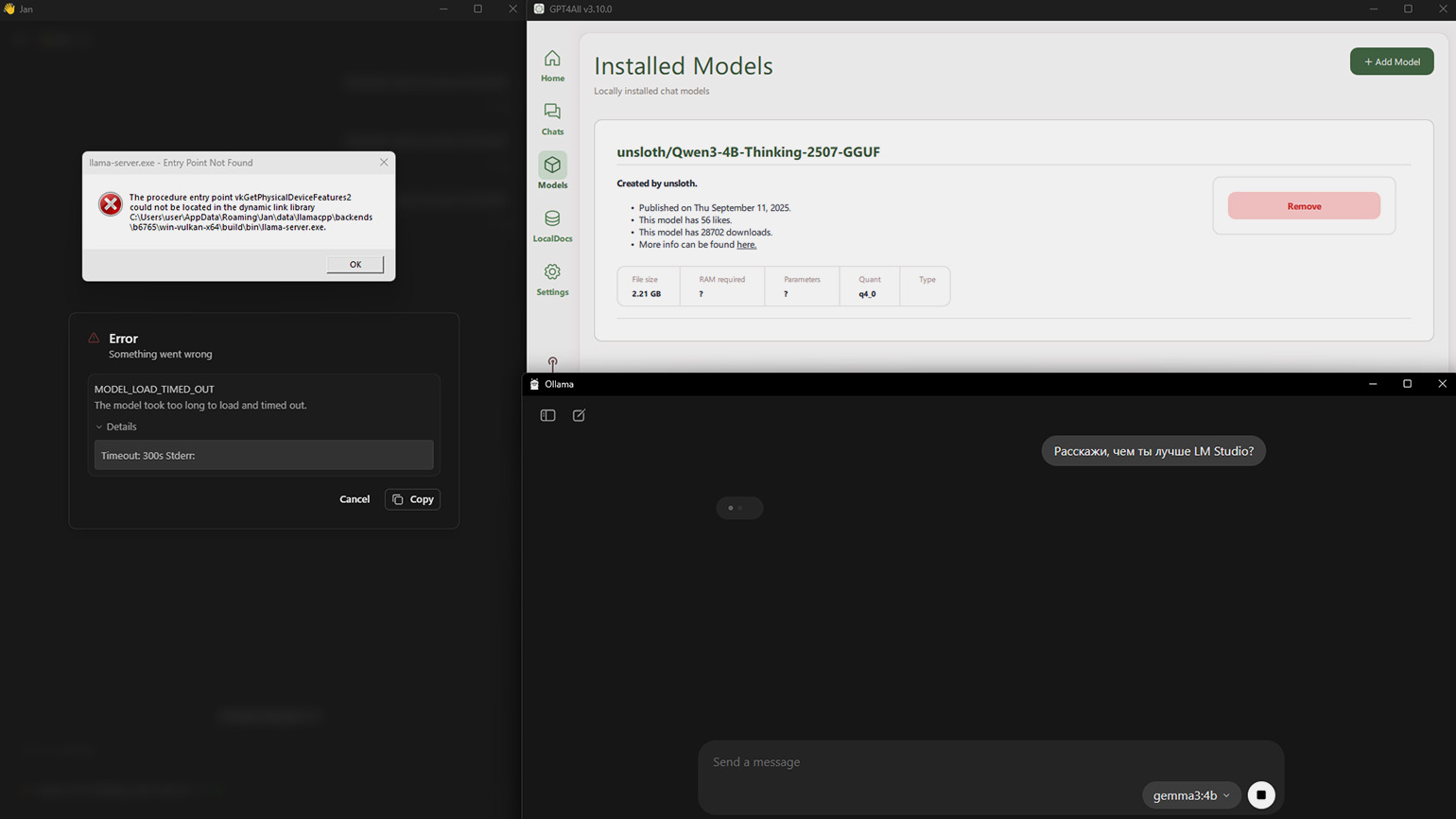
Скриншот: Jan / GPT4All / Ollama / Skillbox Media
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!









