Исчерпывающий гайд по опенсорсным языковым моделям
Рассказываем, как сориентироваться в запутанном мире сотен LLM с открытым исходным кодом.


Если пару лет назад появление новой LLM с открытым исходным кодом было важным событием в IT-мире, то сегодня этим уже никого не удивишь. Каждый месяц появляются десятки опенсорсных языковых моделей, а каждый год — сотни.
Чтобы сориентироваться в этом многообразии, мы собрали гайд с актуальными открытыми нейронками.
Содержание
- Откуда берутся опенсорсные модели
- Как они развиваются
- Какие у них есть преимущества и недостатки
- Какими бывают открытые LLM
- С какими видами open-source-лицензий их публикуют
- Как определить лучшие LLM
- На какие популярные опенсорсные модели стоит обратить внимание
- Что ещё почитать про открытые и проприетарные LLM
Откуда берутся открытые модели
Существуют сотни опенсорсных нейронок. Но это не самостоятельные проекты — большинство из них разработаны на базе нескольких LLM, называемых базовыми моделями (foundation models).
Создание и обучение такой модели требует больших финансовых затрат и вычислительных мощностей. Поэтому работа над ними доступна только крупным научным коллективам и IT-компаниям: Google, OpenAI и другим. Например, обучение GPT-3 обошлось разработчикам почти в 5 млн долларов.
Базовая модель — это искусственная нейросеть, обученная на большом объёме данных, которую можно настроить для решения каких-либо задач.
После разработки новая модель выпускается под закрытой (проприетарной) или открытой лицензией (опенсорсной). В последнем случае другие компании и отдельные энтузиасты могут доработать и настроить её для решения своих задач.
Это не требует больших затрат и вычислительных ресурсов. Поэтому именно с опенсорсными LLM часто работают стартапы. Такие модифицированные модели называют форками (от англ. fork — развилка).
Например, к популярным базовым моделям, ставших основой для открытых LLM, относят:
- Цукерберговскую LLaMA и LLaMA 2, последняя из которых разработана совместно с Microsoft.
- BLOOM (BigScience large open-science open-access multilingual language model) от проекта BigScience, созданного при участии компании Hugging Face.
- GPT-2, выложенная OpenAI несколько лет назад, когда компания планировала разрабатывать только open-source-решения.
- Falcon — новейшая разработка от Института технологических инноваций (TII) из Абу-Даби (ОАЭ).
- Семейство моделей Т5 от компании Google.
Современные LLM-модели можно представить в виде генеалогического дерева, отследив их эволюцию и взаимосвязи:
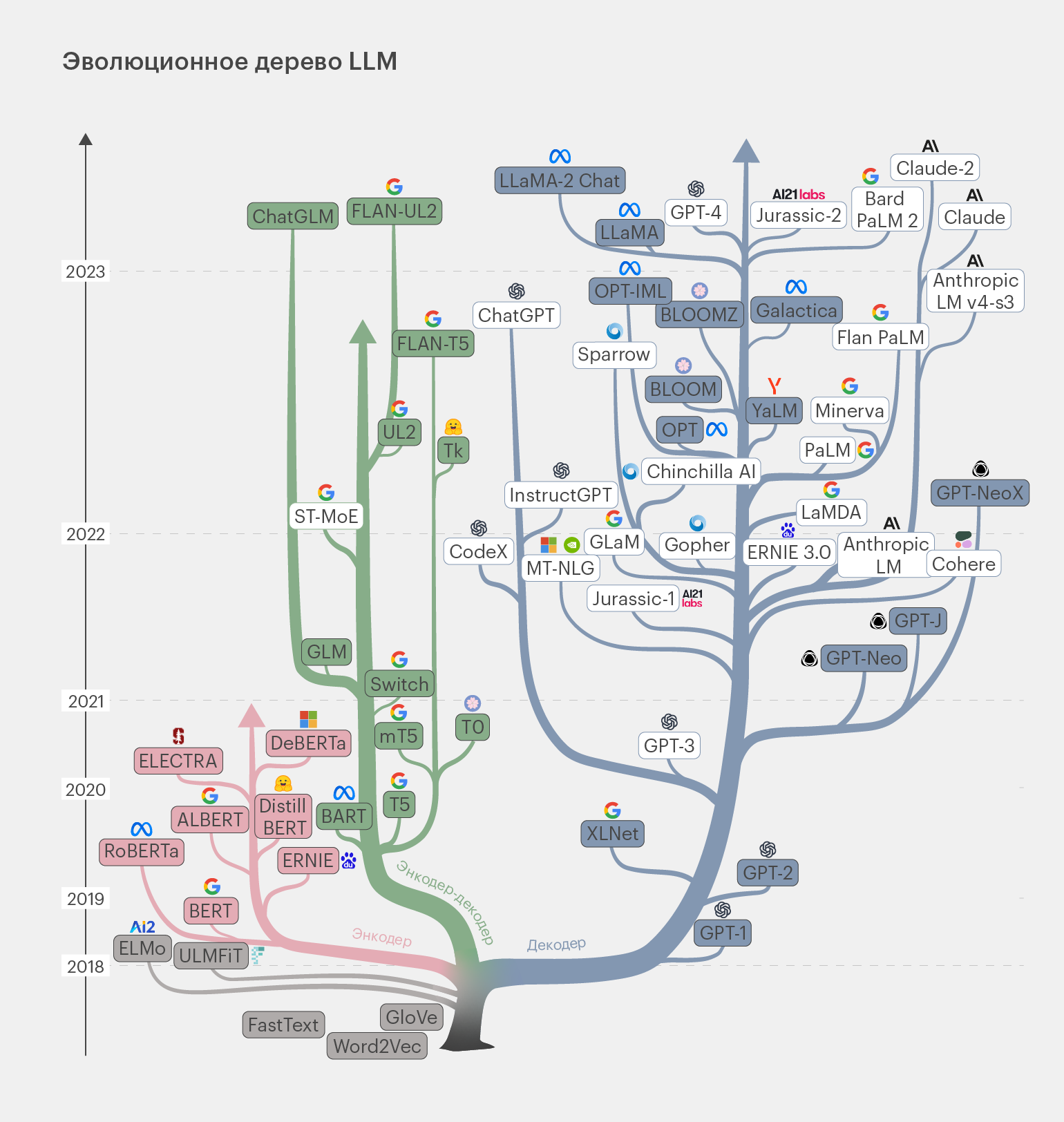
Инфографика: Майя Мальгина для Skillbox Media
На этой схеме нас интересуют модели в закрашенных прямоугольниках. Это опенсорсные решения, о которых мы сегодня и будем говорить. Можно проследить их базовые модели и эволюцию до 2023 года.
Как развиваются опенсорсные модели
У LLM с открытой лицензией те же проблемы, что и у проприетарных нейронок: частые галлюцинации, ограничения длины контекстного окна, необходимость восприятия информации разной модальности и так далее. Поэтому направления их развития совпадают.
Снижение количества галлюцинаций. LLM могут выдавать ошибочные данные, которые выглядят правдоподобно. Их называют галлюцинациями. Полностью избавиться от таких ответов нейросетей не удаётся до сих пор.
Лидер по борьбе с галлюцинациями — закрытая модель GPT-4, которая ошибается в 3% случаев. Однако от неё не сильно отстаёт опенсорсная LLaMA 2 70B, находящаяся по уровню точности на уровне разрекламированной проприетарной Gemini от Google DeepMind.
| Модель | Частота галлюцинаций | Коэффициент согласованности фактов | Частота правильных ответов | Средняя длина ответа, в словах |
|---|---|---|---|---|
| GPT 4 | 3,0% | 97,0% | 100,0% | 81,1 |
| GPT 4 Turbo | 3,0% | 97,0% | 100,0% | 94,3 |
| GPT 3.5 Turbo | 3,5% | 96,5% | 99,6% | 84,1 |
| Gemini Pro (Google) | 4,8% | 95,2% | 98,4% | 89,5 |
| LLaMa 2 70B | 5,1% | 94,9% | 99,9% | 84,9 |
| LLaMa 2 7B | 5,6% | 94,4% | 99,6% | 119,9 |
| LLaMa 2 13B | 5,9% | 94,1% | 99,8% | 82,1 |
| Cohere-Chat | 7,5% | 92,5% | 98,0% | 74,4 |
| Cohere | 8,5% | 91,5% | 99,8% | 59,8 |
| Claude 2 (Anthropic) | 8,5% | 91,5% | 99,3% | 87,5 |
| Phi-2 (Microsoft) | 8,5% | 91,5% | 91,5% | 80,8 |
| PaLM 2 (beta, Google) | 8,6% | 91,4% | 99,8% | 86,6 |
| Mixtral 8x7B | 9,3% | 90,7% | 99,99% | 90,7 |
| Titan Express (Amazon) | 9,4% | 90,6% | 99,5% | 98,4 |
| Mistral 7B | 9,4% | 90,6% | 98,7% | 96,1 |
| PaLM 2 Chat (beta) | 10,0% | 90,0% | 100% | 66,2 |
| PaLM 2 (Google) | 12,1% | 87,9% | 92,4% | 36,2 |
| PaLM 2 Chat (Google) | 27,2% | 72,8% | 88,8% | 221,1 |
Увеличение длины контекстного окна. Чем больше размер текста, который LLM способна обработать, тем выше её производительность и качество генерируемых ответов. Это связано со значительным увеличением объёма данных, которые может проанализировать модель.
Лучшие закрытые модели GPT-4 и Claude 100K могут воспринимать более 100 тысяч токенов за раз. Нейросети с открытым кодом пытаются догнать конкурентов по этому показателю.
Например, базовый Mistral 7B способен работать с 8000 токенов, а его новейший форк Nous-Yarn-Mistral-7B-128k от компании Nous Research поддерживает контекстное окно в 128 тысяч.
Обработка данных разных модальностей. Современные нейросети умеют работать не только с текстом, но и с изображениями, видео и аудио. Это уже реализовано в нескольких опенсорсных LLM:
- зрительно-языковой модели Nous-Hermes-2-Vision-Alpha;
- мультимодальной нейросети Qwen-VL от китайской компании Alibaba Cloud;
- мультимодальной версии LLaMA с названием LLaVA-13B.

Скриншот: Teknium (e/λ)/X
Уменьшение стоимости LLM. Одна из проблем нейросетей — высокая стоимость разработки базовых моделей. Благодаря тому, что некоторые из них выпущены под открытой лицензией, затраты на их дообучение и внедрение снижаются. Например, доработка и запуск опенсорсных Alpaca и Vicuna-13B, основанных на модели LLaMA, обошлись разработчикам всего лишь в 600 и 300 долларов соответственно.
Один из механизмов снижения стоимости — использование нейросетей как для генерации «синтетических» обучающих данных, так и для оценки качества работы новой модели. Такой подход называют RLAIF (reinforcement learning with AI feedback) — обучение с подкреплением от ИИ.
Возможность запуска языковых моделей на слабом железе. В большинстве LLM с открытым исходным кодом меньше параметров по сравнению со своими закрытыми конкурентами. Благодаря этому такие нейронки запускаются на слабом железе, даже на домашнем компьютере.
Например, та же Mistral 7B имеет в 25 раз меньше параметров по сравнению с GPT-3.5, лежавшей в основе базовой версии ChatGPT. Поэтому её использование требует меньше вычислительных мощностей — примерно в 187 раз меньше, чем GPT-4, и в девять раз меньше, чем GPT-3.5.

Михаил Сальников
научный сотрудник группы «Вычислительная семантика» Института искусственного интеллекта AIRI
— Опенсорсные модели позволили бизнесу использовать LLM практически без ограничений. Так, например, открытые решения позволяют компаниям контролировать весь процесс работы с данными пользователей, адаптировать их под свои нужды и в целом снизить риски, используя собственную инфраструктуру.
Кроме того, появление опенсорсных моделей стало причиной роста компетенций академического сообщества в работе с LLM. Сейчас уже никого не удивишь чат-ботом, сравнимым с ChatGPT, который запущен на ноутбуке каким-то энтузиастом, хотя ещё два года назад это казалось фантастикой.
Улучшение существующих и создание новых архитектур нейросетей. Одна из главных проблем LLM, определяющая их недостатки, — это особенности архитектуры трансформер. Решение ждут от стартапов, работающих с опенсорсными моделями, и экспериментирующими с их внутренним устройством.
Возможно, проблему решит архитектура Mixture of Experts (MoE, «модель смешанных экспертов»), копирующая предполагаемое устройство GPT-4. Такая модель состоит из восьми нейросетей-экспертов, каждая из которых отвечает за свой набор задач. Опенсорсная Mixtral 8x7B от французской компании Mistral AI, использующая такой подход, имеет в шесть раз большую скорость генерации ответов по сравнению с исходной LLaMA 2 70B.
Построение мультиагентных систем на базе LLM. Менять архитектуру полезно, но существует другой подход к повышению качества работы языковых моделей. В его основе — построение систем, состоящих из нескольких нейросетей-агентов, которые могут договариваться и взаимодействовать между собой для решения пользовательских задач.
Идеальный кандидат для таких систем — именно открытые LLM, не требующие большого количества ресурсов для вычислений. И такие проекты уже есть: AutoGPT, GPT-Engineer, LangChain и GPTeam.
Создание LLM для языков, отличных от английского. Нейросети предпочитают его для взаимодействия, так как на нём написана большая часть обучающих данных, использованных для их создания. Остальные языки, на которых в мире говорят десятки и сотни миллионов людей, считаются вторичными. Обучение для работы с ними требует поиска и составления качественных датасетов, а значит, и дополнительных ресурсов.
Даже лучшие нейронки вроде GPT-4 охватывают лишь сотню языков из более чем 7000 известных. Эксперты ждут решения этой проблемы от опенсорсных LLM.
Например, в 2023 году была анонсирована разработанная в ОАЭ модель Jais, способная общаться на арабском, и вариант LLaMA для португальского языка. В России «Яндекс» и «Сбер» публиковали нейронки YaLM 100B и ruGPT-3.5 13B, специализирующиеся на русском.
Работа продолжается и для более редких языков. В 2023 году был запущен проект Massively Multilingual Speech (MMS). Его задача — сформировать наборы данных для 1100 не охваченных ранее языков.

Преимущества и недостатки открытых LLM
Почему компании выбирают опенсорсные нейросетки? У них есть преимущества над проприетарными моделями по нескольким пунктам:
- Безопасность и конфиденциальность данных. LLM с открытым исходным кодом можно развернуть на собственной инфраструктуре без пересылки информации на сторонние серверы. Благодаря этому пользователи получают полный контроль над данными, которые обрабатывает нейросеть.
- Экономия средств. Опенсорсные LLM можно использовать без оплаты подписки или регулярных выплат разработчикам по контрактам. Поэтому они популярны у стартапов и компаний с ограниченным бюджетом.
- Снижение зависимости от поставщиков IT-услуг. Пользователи могут выбрать наиболее подходящий для себя вариант нейронок из сотен опенсорсных LLM. Таким образом, компания не привязывается к одному поставщику ИИ-решений и может выбирать лучшие модели или даже сочетать их между собой.
- Прозрачность используемых LLM. Модели с открытым исходным кодом можно изучить изнутри и понять, как именно они работают с данными. Это позволяет выявить и предотвратить отправку информации на сторонние серверы.
- Проекты с открытым исходным кодом поддерживаются группами разработчиков и экспертов. Благодаря этому возникшие баги и проблемы быстро устраняются, а документация подробно описывает нюансы использования нейросети. Это характерно для большинства опенсорсных моделей, но есть и неприятные исключения.
- Нестандартные решения и подходы. Открытые LLM позволяют экспериментировать с ИИ, опираясь на новые базовые модели. Даже небольшие стартапы могут творчески перерабатывать такие нейросети и использовать их в качестве основы для собственных уникальных разработок.

Виктор Носко
генеральный директор компании «Аватар Машина», создатель чат-бота-психолога «Сабина Ai», соавтор проекта FractalGPT
— Массовое появление и распространение больших языковых моделей с открытой лицензией является следствием развития глобального тренда на повышение производительности и снижение стоимости LLM. Потребители сегодня стараются уйти от закрытых проприетарных решений, в которых они зависимы от зарубежных поставщиков и политической турбулентности. Эти причины подталкивают к отказу от использования популярных решений таких иностранных IT-гигантов, как, например, компания OpenAI.
Однако у опенсорсных LLM есть недостатки:
- Их внедрение и обслуживание может потребовать больше времени и технических знаний от специалистов, чем при использовании проприетарных моделей. Последние обычно готовы к работе «из коробки».
- Разработки от малоизвестных коллективов могут быть обучены на неполных или некачественных данных. Это снижает точность ответов нейросети и повышает частоту галлюцинаций.
- У опенсорсных моделей возможны недокументированные проблемы в работе. Например, отсутствие совместимости между разными версиями LLM.

Роман Душкин
генеральный директор ООО «А-Я эксперт», компании — разработчика систем искусственного интеллекта
— Опенсорсные LLM должны быть открытыми не только с точки зрения исходного кода самих моделей, но и с точки зрения данных, на которых они обучаются. Это очень важно, потому что проблема „отравления данных“ продолжает оставаться актуальной. И я думаю, что сейчас упор будет сделан именно на это — на чистоту и прозрачность.
У инженеров, учёных и государства при использовании решений на базе открытых моделей ИИ всегда будут возникать вопросы доверия к данным. Поэтому только открытость и высокое качество датасетов, на которых тренируются нейросети, позволят опенсорсным моделям занять свой рыночный сегмент.

Какими бывают открытые LLM
Модели с открытым кодом делятся на различные категории по ряду параметров: степени обученности, размеру и наличию поддержки тех или иных языков. Разберём каждый из них.
Степень обученности
Разработчики часто выкладывают в открытый доступ лишь предобученные версии своих нейронок — «претрейны». Например, так поступили специалисты «Сбера» с отечественной ruGPT-3.5 и Цукерберг с исходной LLaMA.
Такие языковые модели перед публикацией проходят длительный процесс тренировки на огромном количестве неразмеченных текстовых данных. Это требует больших вычислительных мощностей и финансовых затрат. В результате у нейронок формируется только общее понимание языка.
Но использовать «претрейн» для решения каких-либо задач проблематично. Он может лишь генерировать продолжение текстовых последовательностей, вводимых пользователем. Например, без труда продолжит фразу с определением «Машинное обучение — это…».
Если же пользователь попытается вести с ним диалог или отправит инструкцию для действий, то нейросеть начнёт выдавать чепуху вместо полезных ответов.
Поэтому популярностью пользуются не претрейны, а варианты базовых моделей, прошедших дополнительную тонкую настройку, которую называют «файн-тюнинг» (fine tuning). Как правило, в названиях таких LLM присутствует слово Chat, если нейронку дообучили для ведения диалога, или Instruct, если она умеет выполнять инструкции с помощью метода, аналогичного RLHF, использованного при обучении ChatGPT.
Встречаются и более специфичные варианты дообучения. Например, у модели MPT-7B есть версия StoryWriter, которая специализируется на написании вымышленных историй с очень длинным контекстом. Стоит упомянуть и большое количество LLM, генерирующих программный код. В названиях таких нейронок обычно есть слово Code: StableCode, CodeGeneX и так далее.
Поддержка разных языков
По этому показателю LLM делят на три категории:
- англоязычные;
- с поддержкой одного местного языка, например русского;
- мультиязычные, которые справляются сразу с несколькими языками, отличными от английского.
Например, при работе с нейросетью в России для пользователей будет важна поддержка русского языка. Но базовый язык для большинства моделей — английский.
Связано это с тем, что именно на нём доступно наибольшее количество данных, используемых в обучении нейронок. Другие языки они осваивают за счёт дополнительных тренировок и внесения изменений в архитектуру.

«В целом практически все опенсорсные модели могут понимать русский язык. Проблема заключается в том, что в большинстве известных LLM токенизатор разрабатывался в первую очередь для английского языка или как минимум для латиницы. В итоге тексты на кириллице занимают много места в токенах и контекст использования существенно сокращается».
Михаил Сальников
Размер модели
Времена, когда считалось, что чем больше нейросеть — тем лучше, постепенно уходят в прошлое. Современные опенсорсные модели при очень скромных размерах работают не хуже гигантских проприетарных аналогов. Поэтому сегодня стоит выбирать LLM по принципу золотой середины — нейронка должна иметь наименьший размер, способный справиться с поставленной задачей.
«Уровень каждой модели можно оценить с помощью регулярно обновляющихся метрик качества (бенчмарков). По этому показателю все LLM можно разделить на две категории:
- Модели, которые демонстрируют результаты, близкие к некому «качеству отсечения». Как правило, базовым уровнем считается ChatGPT (GPT-3.5-Turbo).
- Модели, которые не удовлетворяют соотношению цена — качество. Это либо слишком большие LLM, стоимость которых зашкаливает, либо очень маленькие, содержащие менее 7 миллиардов параметров. Последние обычно имеют провалы в качестве работы, обнаруживаемые с помощью отдельных бенчмарков, связанных с пониманием языка».
Виктор Носко
Второй важный параметр, который относится к размеру модели, — тип LLM: полная или квантованная. Квантование нейросети уменьшает требования к вычислительным мощностям, например минимальному объёму оперативной памяти. Но точность работы самой языковой модели при этом снижается.
«Часто снижение стоимости хостинга модели достигается путём квантования. В результате её удаётся запустить даже на обычных домашних видеокартах типа GTX, RTX 3070–3090 от NVIDIA. Но при этом наблюдается падение качества её работы на 5–15% от исходного варианта (впрочем, в ряде случаев, это оказывается приемлемым)».
Виктор Носко
Основные виды open-source-лицензий
Не все опенсорсные модели являются одинаково открытыми. Это зависит от типа лицензии, который выбирает разработчик.
Модели, применение которых возможно с рядом существенных ограничений, относят к частично открытым. Например, создатели LLaMA 2 предлагают пользователю перед скачиванием принять соглашение с обширным списком требований и запретов. Один из пунктов запрещает использовать нейросеть при количестве пользователей в проекте, превышающем 700 миллионов человек в месяц. И это не всё. Результаты работы LLaMA 2 нельзя использовать для обучения других LLM, кроме самой LLaMA и её производных.
Основное число LLM распространяется под типовыми лицензиями свободного ПО, среди которых можно выделить базовые:
- Apache 2.0 позволяет использовать модели для любых целей, модифицировать их и распространять в соответствии с условиями лицензии, без отчисления платежей разработчику. Под этой лицензией создано подавляющее большинство открытых LLM: T5, Mistral 7B и другие.
- MIT License разработана Массачусетским технологическим институтом (MIT). Во многом совпадает с Apache 2.0, но допускает повторное использование опенсорсного кода в составе проприетарного ПО. Например, эта лицензия используется для модели Phi-2 от Microsoft.
- Open RAIL-M v1 поддерживается сообществом BigCode, созданным компанией Hugging Face. Лицензия предполагает свободный доступ к моделям, возможность модификации их исходного кода, и совместное использование LLM и их вариантов. Содержит ряд ограничений, связанных с запретом на использование в неэтичной или противоправной деятельности. Под этой лицензией распространяется модель BLOOM.
- CC BY-SA 4.0 поддерживается международной некоммерческой организацией Creative Commons. Позволяет копировать и распространять LLM, модифицировать и дополнять их для любых целей, включая коммерческое использование. Но в последнем случае распространять новые модели следует по той же лицензии, что и оригинал. Под этой лицензией находится модель MPT-7B-Chat.
- BSD-3-Clause. Лицензия свободного ПО с минимальными ограничениями на использование и распространение нейросеток. Допускает неограниченное копирование для любых целей при условии указания дисклеймеров об авторских правах и отказа от гарантийных обязательств. Используется редко. Нам удалось найти одну популярную LLM с подобной лицензией — CodeT5+.

Как найти лучшую LLM
Чтобы разобраться в том, какая опенсорсная LLM лучше, специалисты создали виртуальные тестовые арены, называемые лидербордами. В них языковые модели сражаются между собой.
На таких сайтах каждая нейросеть оценивается по ряду метрик качества (бенчмарков). При этом стоит понимать, что идеальной во всех смыслах LLM не существует. Модель может демонстрировать выдающиеся результаты по одному показателю, но при этом быть аутсайдером по другим бенчмаркам.
Поэтому при выборе стоит ориентироваться на метрики, наиболее соответствующие задаче, для решения которой мы выбираем LLM. Большинство тестовых арен снабжены удобным интерфейсом, позволяющим сортировать списки доступных моделей в соответствии с интересующими параметрами.
Мы можем посоветовать несколько лидербордов:
- Open LLM Leaderboard. Платформа компании Hugging Face, предназначенная для отслеживания, ранжирования и автоматической оценки новейших LLM и чат-ботов, представленных на одноимённом сайте. Использует оригинальную систему оценки языковых моделей EleutherAI, основанную на расчёте семи бенчмарков.
- Chatbot Arena Leaderboard. Ещё одна открытая платформа для оценки LLM на сайте Hugging Face. Работает по краудсорсинговой схеме. Здесь собраны более 200 тысяч отзывов реальных пользователей, позволяющих оценить языковые модели с помощью системы ранжирования Elo, подобной рейтингу, применяемому для расчёта уровня игры шахматистов.
«Основная идея Chatbot Arena Leaderboard — это попарное сравнение качества ответов моделей людьми-асессорами с помощью рейтинга Elo. Дело в том, что существуют „мошеннические“ способы обучить модели показывать высокие результаты в бенчмарках, которые при этом не коррелируют с их реальными показателями качества. В таком случае ручная человеческая оценка простым сравнением отчасти решает эту проблему».
Виктор Носко
- AlpacaEval Leaderboard. Автоматическая система оценки языковых моделей, относящихся к классу Instruct. Основана на методике AlpacaFarm, которая проверяет способность LLM следовать общим инструкциям пользователя. В качестве «судьи» и источника эталонных ответов в ней используется ИИ на основе модели GPT-4.
- Chatbot Arena. Разработка LMSYS Org (Large Model Systems Organization), создавшей модель Vicuna-13B. Важно, что лидерборд не обновлялся с мая 2023 года.
- Big Code Models Leaderboard. Система оценки LLM, предназначенных для генерации программного кода. Очередная разработка Hugging Face. Лидерборд не обновлялся с ноября 2023 года, поэтому может содержать неактуальные данные.
Легко заметить, что лидером в сравнении является платформа Hugging Face. На ней доступен десяток бенчмарков под названием The Big Benchmarks Collection. Здесь легко настроить рейтинг для выбора наилучшей модели под конкретную задачу, например написание кода.
Но в этом направлении работают не только конкретные компании. Отдельные open-source-сообщества пытаются создать единую систему оценки, способную объединить преимущества всех существующих лидербордов. Так был создан LLM-Leaderboard, проект Людвига Штумппа из Германии.
«В большинстве задач открытые модели незначительно уступают проприетарным по сухим метрикам. Так, например, в задаче ответов на вопросы или упрощения текстов пользователь далеко не сразу заметит разницу между LLaMA 2 70B и ChatGPT. Кроме того, разрыв в рейтингах между закрытыми и открытыми моделями постоянно сокращается».
Михаил Сальников

Читайте также:
Примеры популярных опенсорсных моделей
В основе большинства LLM с открытой лицензией лежат несколько базовых моделей. Разберём ключевые из них.
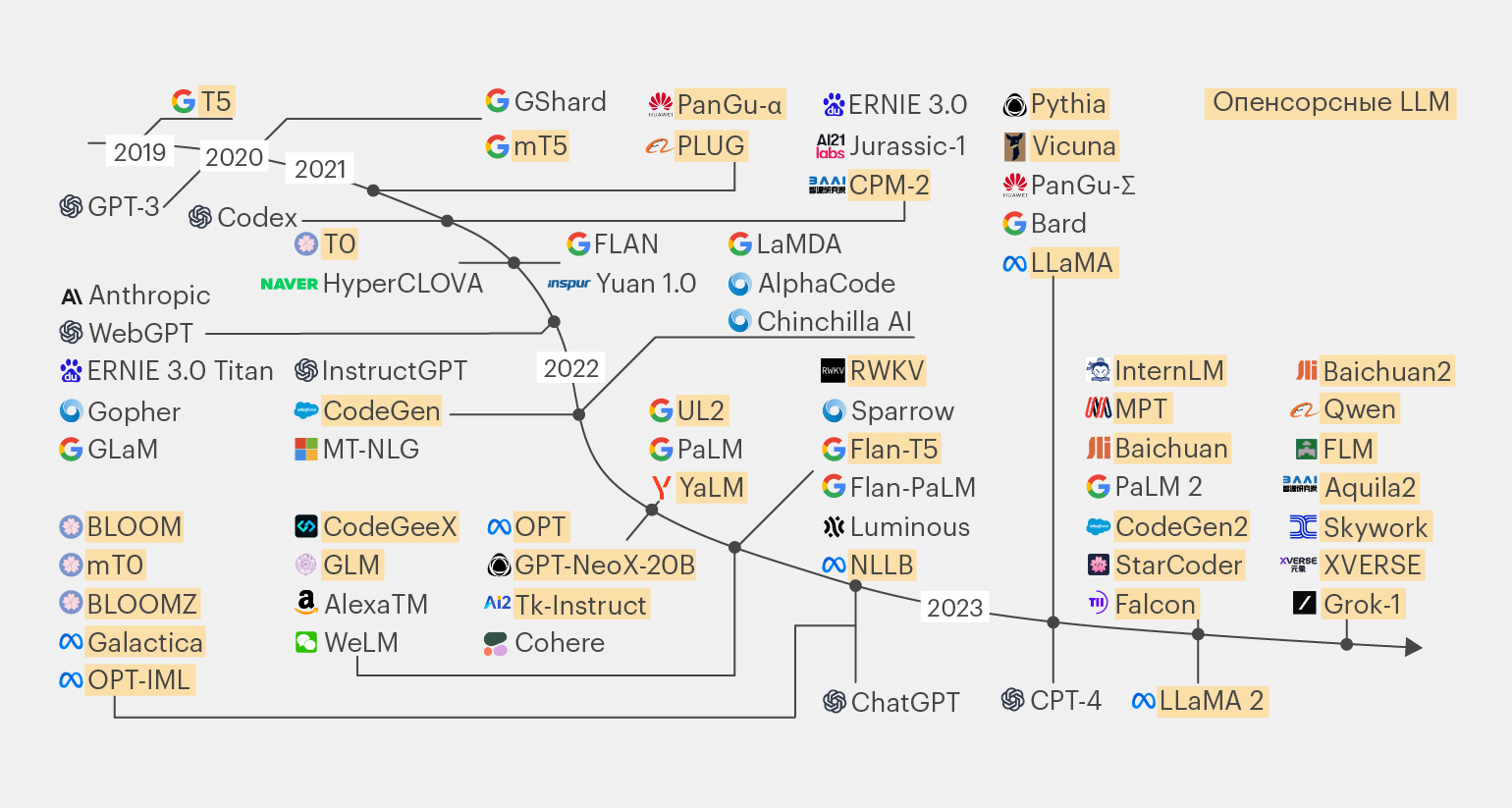
Инфографика: Майя Мальгина для Skillbox Media
Семейство LLaMA
Исходная модель LLaMA представлена в феврале 2023 года. Она имеет версии с типоразмерами 7, 13, 33 и 65 миллиардов параметров. Первые две из них можно было запустить всего на одном графическом процессоре, что стало мини-сенсацией в момент запуска.
В июле 2023 года вышла улучшенная версия LLaMA 2, разработанная в сотрудничестве с Microsoft. Эта LLM имеет варианты на 7, 13 и 70 миллиардов параметров.
Вскоре на базе LLaMA появилась её полностью свободная версия OpenLLaMA. Она стала основой для множества проектов, развивающих модель за счёт экспериментов с архитектурой и вариантов тонкой настройки и обучения.
«LLaMA 2 70B — это условно открытая модель. Есть исходный код и веса, но её нельзя применять в коммерческих целях, если пользователей будет более 700 миллионов человек в месяц. Это, пожалуй, самая известная модель после проприетарных ChatGPT и Claude 2. Она хороша во всех смыслах».
Михаил Сальников
Для этой статьи, мы попросили экспертов дать краткую характеристику популярным опенсорсным LLM из семейства LLaMA, которые они считают наиболее интересными.
«Обратить внимание стоит на следующие открытые LLM:
- Vicuna-13B от LMSYS Org — это одна из первых моделей с поддержкой русского языка, показывающая при этом неплохие результаты в остальных бенчмарках.
- Mistral — модель от одноимённого французского стартапа, превосходящая LLaMA 2 13B во всех бенчмарках. На конец сентября 2023 года была лучшей LLM с размером 7 млрд параметров.
- Zephyr-7B — это версия Mistral, прошедшая процедуру тонкой настройки (файн-тюнинга) с помощью метода Direct Preference Optimization (DPO). Имеет 90,6% частоту побед над другими нейронками в AlpacaEval Leaderboard.
- OpenChat — библиотека языковых моделей с открытым исходным кодом. По оценкам, она достигает качества ChatGPT (в версии от марта 2023 года), а также превосходит чат-бот Илона Маска Grok. Поддерживает русский язык. OpenChat 7B сделан на базе Mistral 7B, но в отличие от него проходит известный «тест на банан», который формулируется в виде вопроса к LLM: «Я на кухне, положил тарелку на банан. Затем я отнёс тарелку в спальню. Где сейчас банан?»
- Xwin-LM-70B-V0.1 — модель, созданная на базе LLaMA 2. Как утверждают разработчики, это первая модель, которая превзошла GPT-4 в бенчмарке AlpacaEval. Правда, размер у неё довольно большой — 70 миллиардов параметров».
Виктор Носко
«Mistral 7B интересна тем, что, имея всего 7 миллиардов параметров, она показывает лучшие результаты, чем версия LLaMA 2 с 13 миллиардами. Это позволяет использовать модель на почти любом современном ноутбуке.
Также я бы рекомендовал присмотреться к модели Dolly от американской компании Databricks, хотя она и не является родственницей LLaMA (основана на семействе EleutherAI Pythia). Модель полностью открыта, и её можно использовать в любых целях, что является основным преимуществом».
Михаил Сальников
ruGPT-3.5 и YaLM 100B
В России идёт разработка своих собственных LLM, ориентированных на работу с русским языком.
Среди отечественных разработок выделяется ruGPT-3.5, лежащая в основе сберовского GigaChat. В опенсорсе доступен лишь претрейн, поэтому её придётся дообучать самостоятельно.
Со сберовской разработкой конкурирует модель «Яндекса» YaGPT 2, которая ещё не выложена в открытый доступ. Но в 2022 году компания опубликовала претрейн-предшественницу — YaLM 100B, распространяемую под лицензией Apache 2.0.
Среди российских LLM можно выделить модель Saiga 2 от инженера по машинному обучению Ильи Гусева. Автор позиционирует свою разработку как «российский чат-бот на базе LLaMA 2 и Mistral».
«Главная отечественная разработка — это ruGPT-3.5 и созданный на её базе GigaChat. Пожалуй, это лучший вариант для русского языка на сегодня. Также существует YandexGPT, которая тоже отлично работает с русским языком. Но к ней открытого варианта модели создатели пока не предоставляют».
Михаил Сальников
Модели для генерации программного кода
Отдельное направление исследований в области LLM — обучение нейронок написанию программного кода. Сегодня для этого существует несколько популярных опенсорсных моделей:
- StableCode от StabilityAI, создавшей Stable Diffusion. Может программировать на Python, Java, Go, JavaScript, C, и C++.
- StarCoder — это набор моделей с 15,5 миллиардами параметров, обученных на более чем 80 языках программирования.
- SantaCoder — серия моделей с размером 1,1 миллиард параметров, созданных на базе GPT-2. Обучена генерировать код на языках Python, Java и JavaScript.
- CodeGeeX и CodeGeeX2 от китайских специалистов. Первая версия нейронки на 13 миллиардов параметров была обучена на 20 языках программирования, вторая — с размером 6 миллиардов — умеет кодить уже на 100 языках. Среди них Python, Java, C++, C#, JavaScript, PHP и Go. Может быть подключена в виде плагина к популярным IDE: Visual Studio Code, IntelliJ IDEA и Android Studio.
- Replit Code — языковая модель размером 2,7 миллиарда параметров, обученная на автодополнение кода. Обучалась на наборах данных, содержащих 20 языков, включая Java, JavaScript, Python и PHP.
- CodeT5 и CodeT5+. Семейство моделей от американской компании Salesforce Research. Как следует из названия, LLM основана на базовой открытой модели T5. Есть варианты на 220 миллионов, 770 миллионов, 2 миллиарда, 6 миллиардов и 16 миллиардов параметров. Способна кодить на Ruby, JavaScript, Python, Java, PHP, C, C++, C#.
- CodeGen2 и CodeGen2.5 — ещё одно семейство опенсорсных LLM с типоразмерами на 1, 3,7, 7 и 16 миллиардов параметров от той же Salesforce Research.
- DeciCoder 1B — скромная моделька с 1 миллиардом параметров, которая умеет завершать предложенные человеком фрагменты программного кода. Обучена на языках Python, Java и JavaScript. При этом, по заверениям разработчиков, «обеспечивает увеличение производительности в 3,5 раза, повышенную точность в тесте HumanEval и меньшее использование памяти по сравнению с широко используемыми LLM для генерации кода, такими как SantaCoder».
- Code LLaMA — версия LLaMA 2, прошедшая дообучение для работы с программным кодом. Имеет варианты на 7, 13 и 34 миллиарда параметров. Справляется с Python, C++, Java, PHP, C# и TypeScript.

Что ещё почитать
Эта статья — обзорный материал по обширной теме опенсорсных языковых моделей. Если вы хотите погрузиться в мир открытых и проприетарных LLM глубже, рекомендуем две исследовательские работы, опубликованные на портале arxiv.org:
- A Survey of Large Language Models.
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.
Следить за обновлениями мира опенсорсных LLM можно в подборках на GitHub и других ресурсах:
- Список открытых LLM, доступных для коммерческого использования.
- Коллекция открытых и проприетарных LLM.
- Список больших языковых моделей.
- Коллекция китайских моделей с открытым исходным кодом.
- Краткое руководство по наборам данных для тонкой настройки моделей.
И конечно же, мы будем рассказывать вам о главных новостях развития искусственного интеллекта и сообщества Open Source в нашем телеграм-канале.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».




