HDFS: как хранятся большие данные
Распутываем узлы больших данных и знакомимся с кластерами в Hadoop.

Big data — это не только сами данные, но и инфраструктура для их хранения и обработки. Создать её можно с помощью разных инструментов. Один из них — Hadoop от компании Apache. Она позволяет параллельно обрабатывать данные на кластере компьютеров, ускоряя их анализ.
HDFS — это файловая система Hadoop. Она похожа на файловую систему вашего компьютера, но данные хранятся кусочками на десятках и сотнях серверов, а не на одном устройстве. И это не все особенности. Например, HDFS следит за сохранностью информации и умеет восстанавливать её в случае потери.
Сегодня вы узнаете:
- Что такое HDFS
- Какая архитектура используется в HDFS
- Почему распределённая файловая система стала популярной и какие недостатки у неё есть
Что такое HDFS
HDFS (Hadoop Distributed File System) — это файловая система, предназначенная для работы с большими данными в экосистеме Hadoop на распределённых кластерах. Её можно сравнить с файловой системой на вашем компьютере — в ней также есть папки, подпапки и файлы. Только всё это распределено между сотнями и тысячами устройств. Давайте вернёмся к основному определению и разберём каждый термин, чтобы лучше понять, как HDFS связана с большими данными.
Большие данные — это такие данные, которые отличаются разнообразием и быстро накапливаются, в результате чего не могут быть обработаны на одном компьютере. Специалисты относят к термину не только саму информацию, но и методы работы с ней — от хранения до анализа. HDFS как раз один из подобных методов, обеспечивающих обработку и хранение данных.
Hadoop — это платформа с открытым исходным кодом, написанная на Java и позволяющая распределять данные для анализа по кластеру компьютеров.

Читайте также:
Кластер — группа компьютеров, которые представляют собой аппаратный ресурс, выполняющий работу как единое целое. То есть задача одновременно выполняется на всех из них, что ускоряет её решение.
HDFS разделяет данные на множество блоков и хранит их на серверах в кластере. Блок — это кусочек файла стандартного размера. Во второй версии HDFS, которая сейчас считается основной, это 128 МБ. Соответственно, исходный файл разделяется на блоки по 128 МБ, которых может быть десять, а несколько тысяч.
Каждый блок с информацией реплицируется на несколько узлов для обеспечения отказоустойчивости. Если один из серверов перестаёт работать, например, из-за сбоя в оборудовании, данные не пропадают, а восстанавливаются с целых узлов. Когда вышедший из строя узел вернётся в работу, данные автоматически синхронизируются.
Такой подход позволяет HDFS обеспечить высокую скорость передачи данных и надёжность, что делает её «золотым стандартом» файловой системы для работы с большими данными в Hadoop.
Архитектура HDFS
Каждый вычислительный кластер под управлением Hadoop Distributed File System включает четыре компонента: клиент, главный узел, вторичный главный узел и узлы данных.
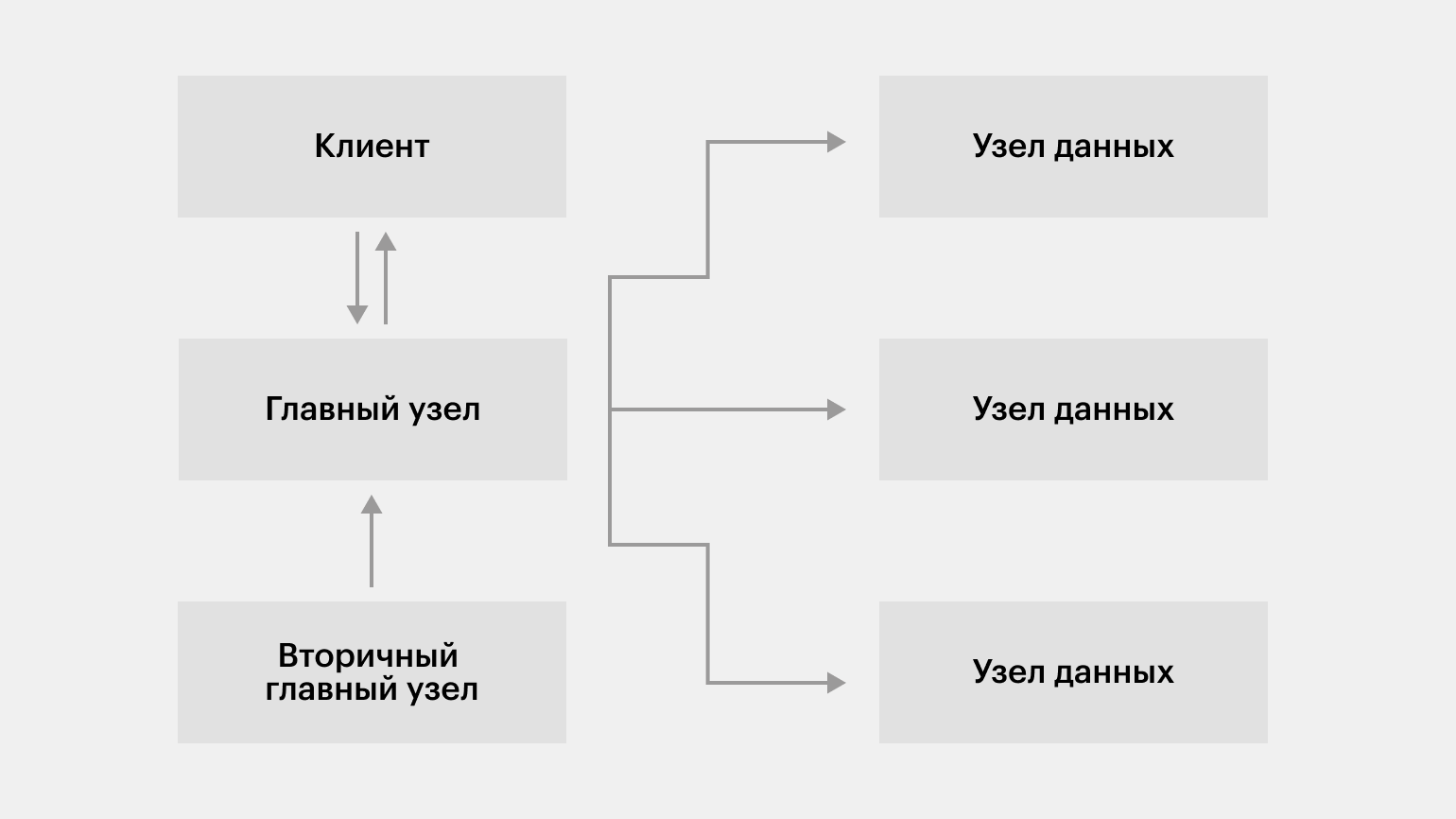
Изображение: Skillbox Media
Клиент
Клиент — это приложение, обеспечивающее взаимодействие пользователя через API с главным узлом, то есть с HDFS в целом. С помощью него пользователь работает с файлами: создаёт новые, удаляет существующие, редактирует, просматривает и перемещает их.
Главный узел (NameNode)
Это сервер, наличие которого обязательно для работы HDFS. Главный узел управляет пространством имён файловой системы, хранит «карту» распределения файлов по блокам и их метаданные. Например, имена файлов и каталогов.
Кроме хранения метаданных, NameNode управляет данными — разделяет их на блоки стандартного размера и распределяет по узлам данных в кластере. Если какой-либо блок данных или узел становятся недоступными, главный узел переносит блоки данных с работающих узлов и реплицирует их, сохраняя информацию.
Когда клиент запрашивает доступ к данным, NameNode обрабатывает этот запрос. Он предоставляет информацию о расположении блоков данных, однако сам не взаимодействует с ними напрямую. Это делают узлы данных, о которых мы расскажем позже.
В главном узле хранятся два вида файлов — FSImage и EditLogs.
FSImage содержит сведения о файловой системе — каталоги и файлы с учётом их вложенности. Его также называют файловым образом, поскольку он отражает структуру хранения данных.
EditLogs хранит информацию об изменениях в файловой системе и используется для обновления FSImage при перезапуске главного узла.
Вторичный главный узел (Secondary NameNode)
Вторичный главный узел поддерживает актуальной собственную копию FSImage, периодически получая файлы EditLogs из NameNode. Это ускоряет работу системы при перезапуске. Если бы вторичный главный узел отсутствовал, то в EditLogs накапливалось бы большое количество изменений, так как их переход в FSImage главного узла происходит при перезапуске HDFS. А HDFS может работать без перезапуска несколько дней или недель.
Поэтому разработчики HDFS предложили использовать вторичный главный узел, который обновляет собственный файл FSImage во время работы главного узла. То есть при перезапуске системы у неё сразу же будет актуальная версия файлового образа.
Важно! Вторичный главный узел не является резервной копией главного узла, то есть не может быть использован для его восстановления в случае критических ошибок.
Узел данных (DataNode)
Это серверы, которые непосредственно работают с блоками данных. DataNode выполняет команды главного узла, обеспечивает репликацию данных и отправляет в NameNode периодические сообщения (heartbeats) о состоянии блоков данных.
Узлов данных, в отличие от главного узла и вторичного главного узла, обычно много — именно они распределены по кластерам.
Основные характеристики HDFS
HDFS стала популярна благодаря своим свойствам, позволяющим удобно хранить и обрабатывать большие данные. Рассмотрим главные среди них.
Распределённое хранение. HDFS разбивает файлы на небольшие блоки и хранит их на разных узлах в кластере серверов. Это равномерно распределяет нагрузку на кластер и позволяет ускорить работу с данными за счёт одновременной обработки сотен и тысяч файловых блоков.
Репликация данных. Каждый блок данных в HDFS дублируется на несколько узлов. Если один узел выходит из строя, информация может быть восстановлена из других.
Работа в формате потока данных. Обработка данных может идти в режиме реального времени в процессе их получения, что ускоряет работу. Серверу не нужно ждать, пока поступление данных закончится.
Простота обслуживания и устойчивость. Благодаря репликации и системе сообщений узлов данных HDFS автоматически обнаруживает сбои и восстанавливает данные из реплицированных узлов.
Масштабируемость. HDFS легко масштабируется по горизонтали. Если объём данных или нагрузка увеличиваются, то можно просто добавить больше серверов в вычислительный кластер. Система будет автоматически использовать их для хранения и обработки данных.
Поддержка различных типов данных. HDFS поддерживает хранение разнообразных данных — структурированных (таблицы), полуструктурированных (JSON, XML) и неструктурированных (видео и изображения).
Интеграция с экосистемой Hadoop. HDFS плотно интегрирована с другими компонентами экосистемы Hadoop — Apache Spark, Apache Hive, Apache Pig и другими. Вместе они обеспечивают полный цикл обработки данных — хранение, распределение, загрузку, анализ, визуализацию и прочие способы представления данных.
Но у HDFS есть недостатки, которые ограничивают её широкое применение:
- Низкая эффективность работы с файлами меньше размера одного стандартного блока — 128 МБ. Работа с ними приведёт к замедлению работы из-за многократного повышения нагрузки на NameNode, хранящего пространство имён в HDFS.
- Работа системы полностью зависит от главного узла. Если по какой-либо причине он перестанет работать, то вся HDFS выйдет из строя. Восстановить его из вторичного главного узла невозможно.
- Низкая безопасность данных, так как при получении доступа к главному узлу можно получить доступ ко всей хранящейся в файловой системе информации.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!






