Shit happens: эпичные фейлы известных IT-компаний
Не так давно Facebook и Instagram знатно переполошили весь мир. Мы вспомнили ещё пять глупых ошибок технокомпаний и разобрались в их причинах.


Иногда даже в международных IT-компаниях происходят странные и разрушительные события, из-за которых сервисы не подают признаков жизни часами, информация из баз данных пропадает или, напротив, — начинает гулять по всему вебу. Мы собрали пять крупных факапов.
Notion заблокировали из-за жалоб на фишинг
12 февраля 2021 года примерно с 2 часов ночи по МСК Notion перестал загружаться — а пользователи, среди которых немало корпоративных клиентов, не могли получить доступ к своим данным.
В твите, который потом быстренько удалили, Notion спрашивал у подписчиков личный выход на ребят из хостинга Name.com — на нём крутится домен notion.so. В ответ Name.com твитнул, что «работает с держателями домена, чтобы решить проблему как можно быстрее». В Notion этому удивились и иронично ответили: «А не подскажете, куда именно вы нам пишете?»
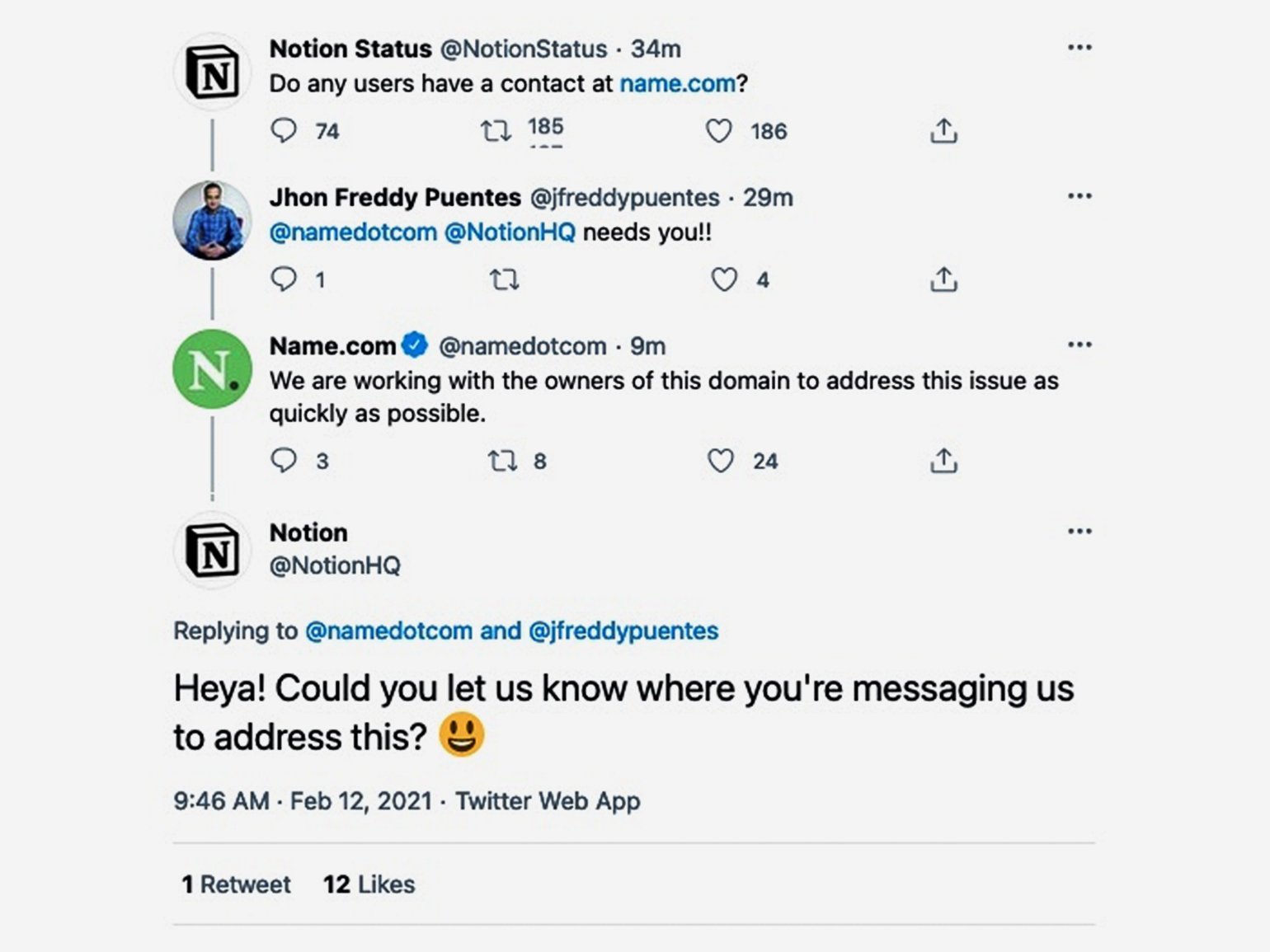
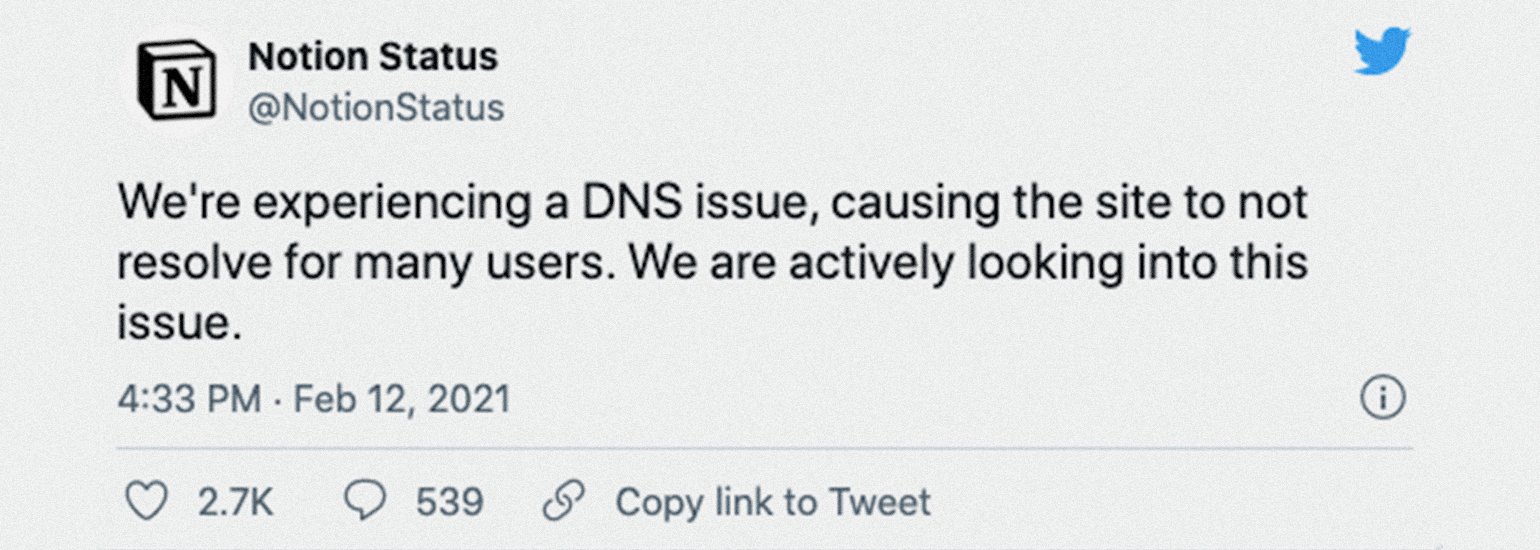
Позже ребята из Notion сообщили TechCrunch, что у них возникли неполадки с DNS, которые уже почти решены. О статусе пообещали регулярно отписываться в Twitter.
В чём было дело
Когда вы заходите на сайт, ваш браузер обращается к DNS-серверу — чтобы преобразовать домен в IP-адрес и найти сервер, на котором крутится сервис.
Notion зарегистрировала домен notion.so через Name.com, но .so-домены управляются другой компанией — Hexonet. Эта самая Hexonet помогает связать конкретный домен .so с регистраторами вроде Name.com. В этой цепочке и возник глюк, из-за которого лёг Notion.
В электронном письме TechCrunch представитель Name.com Джаред Эви заявил:

«Hexonet получила жалобы на созданные пользователями Notion страницы, которые задействовались в целях фишинга. Поэтому Hexonet на время заблокировала домен Notion. После этого команды трёх компаний работали сообща, чтобы восстановить сервис. Теперь мы разрабатываем новые протоколы, чтобы в будущем избежать подобных инцидентов».
GitLab потерял базу данных
В январе 2017 года GitLab потерял данные за шесть часов: репорты о проблемах, запросы на слияние, данные пользователей, комментарии и так далее. Репозитории Git, wiki и экземпляры GitLab с собственным хостингом не пострадали. Но пропало всё, что пользователи занесли в базу данных с 17:20 до 23:25 UTC. Техподдержке пришлось восстанавливать данные из резервной копии — причём чуть ли не вручную.
Хроника событий
31 января 2017 года в 18:00 по UTC в GitLab обнаружили, что спамеры забивают базу данных, создавая сниппеты. Это снизило стабильность базы данных, и техническая команда сервиса начала бороться с проблемой.
В 21:00 по UTC ситуация ухудшилась и GitLab заблочил все операции записи в базе данных. Система встала.
Но техническая команда сервиса не зря ест свой хлеб с маслом — исходную проблему пофиксили:
- вычислили и заблокировали спамеров по IP-адресу (любители порубиться в контру или кваку по сетке из нулевых оценят);
- удалили пользователя, который юзал репозиторий как сеть доставки контента (CDN). Из-за этого 47 000 IP-адресов залогинились в системе и чуть не обвалили БД;
- поудаляли пользователей за спам.
В 22:00 по UTC GitLab получил сообщение, что синхронизация содержимого копий БД (репликация) сильно отстаёт и фактически остановилась. Это произошло из-за всплеска количества операций записи, которые база данных не смогла обработать.
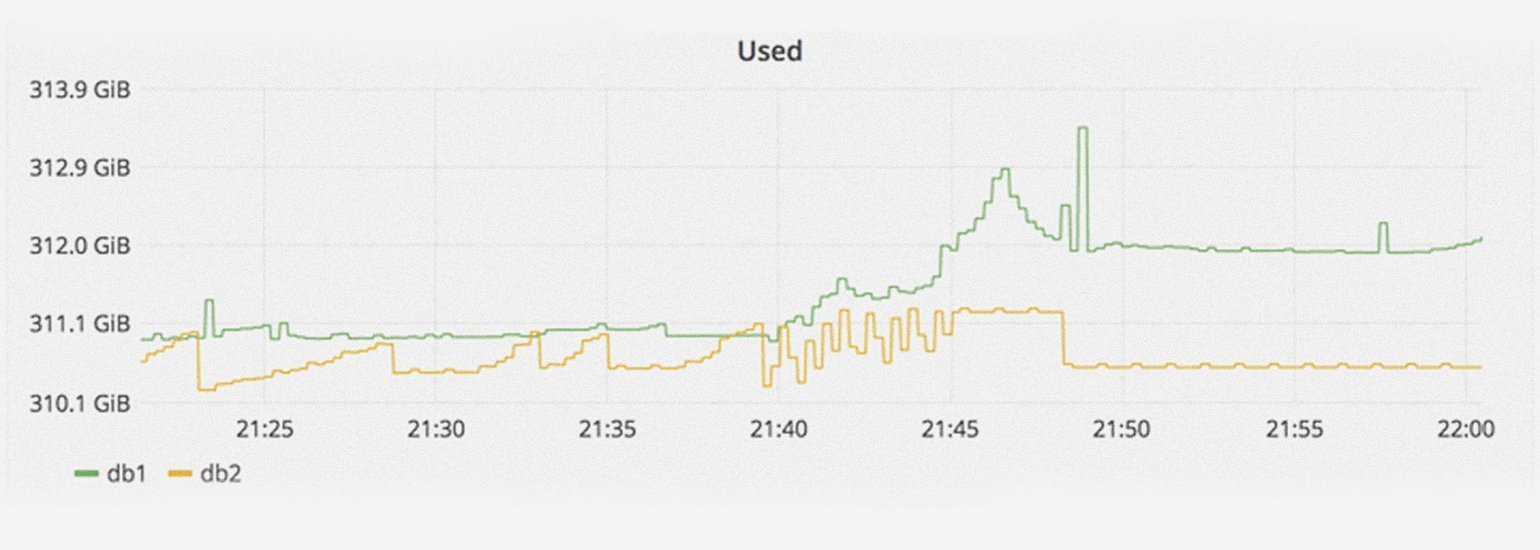
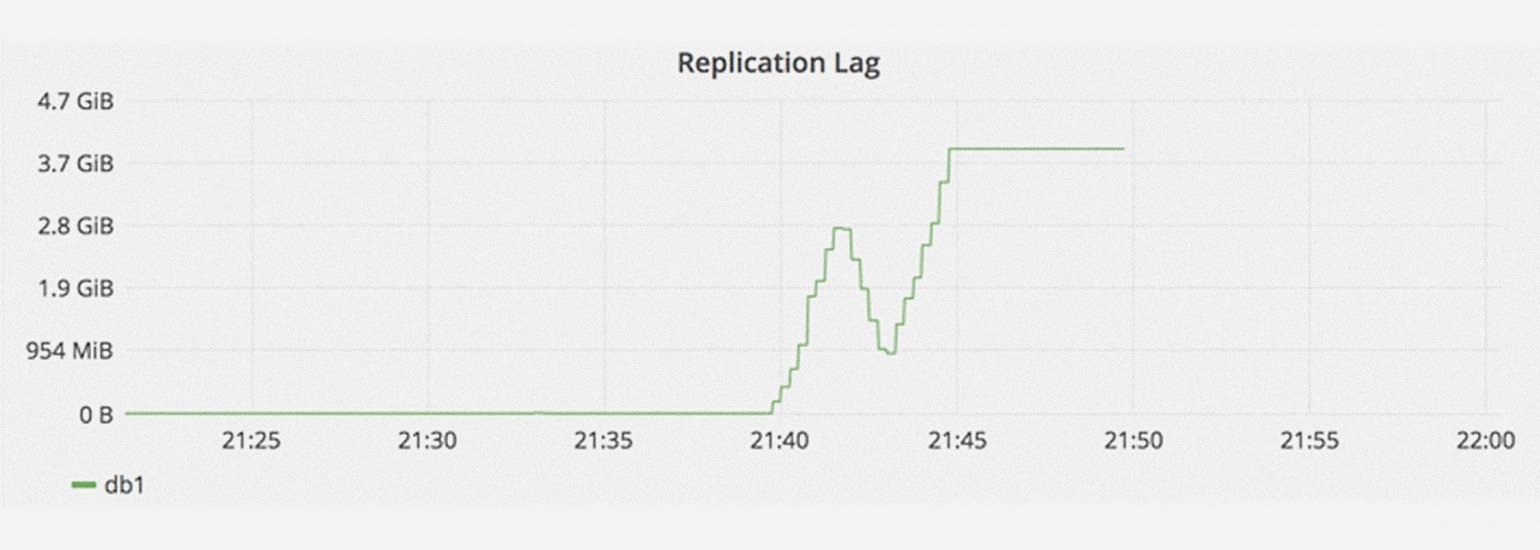
Оказалось, что запись содержимого db2 отстала на 4 ГБ. В результате db2.cluster не смог синхронизироваться с другими копиями и самоочистился. Он не смог подключиться к db1 из-за слишком низкого ax_wal_senders — параметра ограничения количества репликаций клиентов. Сотрудники компании попытались перезагрузить PostgreSQL на db1, но она отказалась запускаться. После ещё одной попытки PostgreSQL всё-таки стартанула, правда, репликации с db2.cluster всё равно не произошло. Кластер просто завис.
В 23:00 по UTC разработчик из GitLab предположил, что бэкап базы данных не работает из-за пустого каталога PostgreSQL. Чтобы решить проблему, он удалил каталог, но стёр его не на реплике, а на db1.cluster.gitlab.com. Когда он осознал свою ошибку, было уже поздно: из 300 ГБ данных осталось только около 4,5 ГБ.
Компании пришлось отключить gitlab.com и сообщить о проблеме в Twitter:

Оказалось, что из пяти развёрнутых решений для резервного копирования не сработало ни одно. В итоге ребята из GitLab сумели восстановить только копию шестичасовой давности.
В Google Cloud не хватило памяти
14 декабря 2020 года, примерно в 14 часов по МСК, перестали работать сервисы Google Cloud: невозможно было открыть свои документы или отправить письмо в Gmail. Пользователей встречало не очень весёлое сообщение: «Попробуйте перезагрузить эту страницу или вернуться к ней через несколько минут. Приносим извинения за неудобства». Проблемы с доступом продлились около часа.
Компания написала, что причиной сбоя стала система аутентификации.
«Сегодня в 3:47 утра по тихоокеанскому времени (США) в Google примерно на 45 минут произошёл сбой системы аутентификации из-за проблемы с квотами внутренней памяти. Проблему устранили в 4:32. Все службы снова работают».

Как поясняют в The Guardian, проблема была в том, что внутренние системы компании не смогли выделить достаточное количество места для сервисов аутентификации. Система должна была автоматически расширить место для хранения данных, но этого не произошло.
Сбой в Google привёл ко множеству побочных проблем. Пользователи не могли включить свет в Google Home, провести встречи в Google Meet и посетить урок в Google Classroom, а главное — у них не получалось войти в Slack и другие сервисы, авторизация в которых шла через аккаунт Google.
Facebook* прилёг на сутки
Да, недавнее падение сервисов Facebook** не первое в истории. Так, 13 марта 2019 года около полудня Facebook**, Facebook** Messenger и Instagram* по всему миру не работали почти весь день. Пользователи WhatsApp сообщали о проблемах с отправкой фотографий, а пользователи Facebook** видели сообщение, что сайт отключён для проведения «технического обслуживания».
Даже собственная платформа отчётов об ошибках Facebook*, в которой сообщается, какие сервисы не работают, была отключена. Поэтому компания сообщала об обновлениях в Twitter — одной из немногих крупных социальных сетей, которой она не владеет. Примерно в 15 часов по МСК в Facebook* заявили, что знают о проблеме и пытаются с ней разобраться, также в Facebook* отметили, что отключение не было связано с DDoS-атакой:
В четверг Instagram* опубликовал в Twitter сообщение, что проблемы устранили. А затем новостью, что всё заработало, поделились и в Facebook**.
Лишь через 24 часа после сбоя Facebook* наконец дал пояснения. Официальной причиной падения стали «изменения конфигурации сервера».
«Вчера в результате изменений в конфигурации сервера у многих возникли проблемы с доступом к нашим приложениям и сервисам. Мы всё исправили, и наши системы восстанавливаются. Приносим извинения за неудобства и благодарим всех за терпение».
Сообщение Facebook* в Twitter
AOL раскрыла данные поисковых запросов своих пользователей
4 августа 2006 года AOL Research раскрыла данные 650 тысяч пользователей интернет-провайдера AOL. Компания опубликовала на одном из своих веб-сайтов сжатый текстовый файл, содержащий 20 млн ключевых слов. Данные предназначались для внутреннего исследования.
7 августа AOL извинилась перед пользователями и удалила данные со своего сайта, но к тому моменту они уже разлетелись по интернету. При этом компания даже не воспринимала случившееся как проблему, пока кто-то не увидел публикацию об этом в одном из блогов.
База данных, попавшая в сеть, содержала поисковые запросы пользователей за три месяца: с 1 марта по 31 мая 2006 года с привязкой к user_id. Данные также включали историю и результаты поиска, а также ссылки, по которым переходили пользователи.
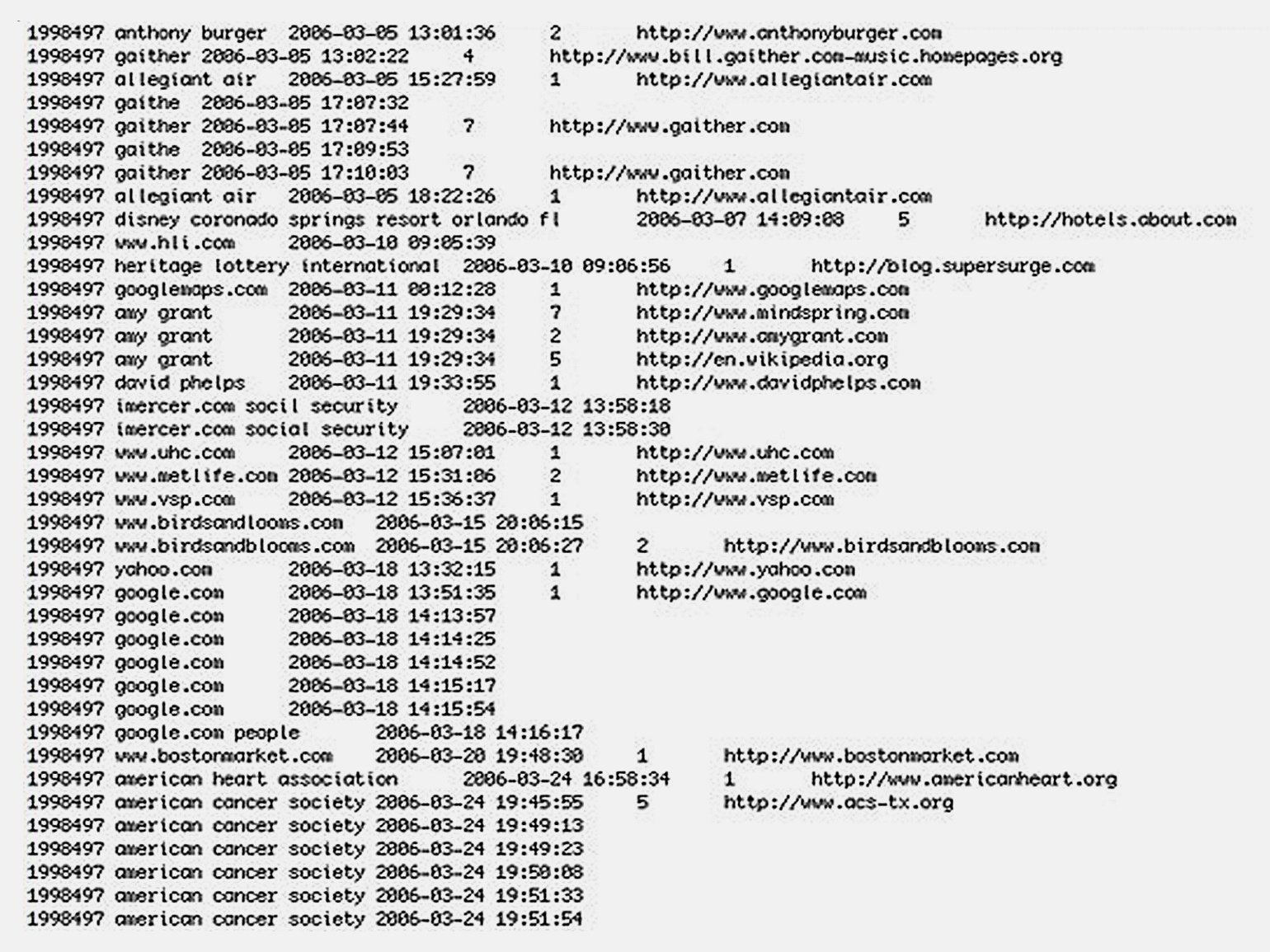
Хотя запросы привязаны к случайным user_id, по ним можно однозначно идентифицировать многих пользователей. Часто люди вводят в поисковую строку собственные имена или имена своих друзей и родственников, чтобы узнать, какая информация о них доступна в сети. Поэтому многие запросы включают имена, адреса, номера соцстрахования и другие личные данные.
В январе 2007 года журнал Business 2.0 Magazine на CNNMoney присвоил этому инциденту 57 место в рейтинге «101 глупейший момент в бизнесе».
Из-за скандала технический директор компании подал в отставку.
От ошибок нельзя застраховаться, но их вероятность можно снизить, если хорошо освоить профессию. Выбирайте курсы в разделе «Программирование» на сайте Skillbox и учитесь у матёрых разработчиков из крупных IT-компаний.










