Основные понятия информатики. CS50 на русском. Лекция 0.1
Вводная статья, в которой мы разберёмся, что является предметом информатики, как компьютер хранит данные и что такое алгоритмы.


CS50 (Computer Science 50) — легендарный курс о компьютерных технологиях Гарвардского университета. Практически в любом разговоре о том, как вкатиться в программирование, опытные ребята упоминают этот курс как необходимый фундамент. В нём последовательно разбираются логика работы компьютера, работа с визуальным программированием в Scratch, основы языка C, массивы, основные алгоритмы, работа памяти, структуры данных, основы языка Python, основы SQL, HTML, CSS, JavaScript, Python-фреймворк Flask и даже эмодзи :)
Изучив материалы курса, вы разберётесь в том, как работает компьютер, узнаете универсальные принципы программирования и сможете понимать и читать код, написанный на разных языках.
В этой статье мы разберём, как в памяти компьютера выглядят числа, буквы, цвета, картинки, музыка и видео, а также познакомимся с понятиями «алгоритм» и «псевдокод». Эта статья — вводная, поэтому, если какие-то концепции вам уже знакомы, смело переходите к следующим разделам.
Содержание
- Почему мы перевели CS50 и как устроены статьи по курсу
- Оригинальное видео
- Мотивация в изучении информатики
- Как компьютер представляет числа
- Как компьютер понимает буквы
- Как компьютер хранит цвета, картинки и фотографии
- Как компьютер представляет видео и звуки
- Что такое алгоритм
- Эффективность алгоритмов
- Что такое псевдокод
- Что общего у языков программирования
Почему мы перевели CS50 и как устроена каждая статья по курсу
CS50 — это самый популярный курс в Гарвардском университете и самый посещаемый массовый открытый онлайн-курс на edX. Все материалы курса доступны бесплатно (в том числе и практические задания), но, если заплатить, можно получить сертификат и разные дополнительные плюшки.
Мы перевели видеолекции в текстовый формат, снабдили их иллюстрациями, кое-где дополнили объяснения и выкладываем в открытый доступ. Оригинальный курс доступен по лицензии Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) — его можно дорабатывать и распространять бесплатно, но только под исходной лицензией. Так что этот цикл материалов вы также сможете использовать в своей работе или общественной деятельности совершенно свободно и бесплатно в рамках той же лицензии.
Каждая статья из цикла CS50 состоит из следующих материалов:
- текстовый перевод видео (иногда — половины видео, если тема обширная);
- ссылка на оригинальное видео на английском языке;
- схемы и пояснения;
- ссылки на более подробные материалы по теме статьи;
- практические задания.

Оригинальное видео
Мотивация в изучении информатики
Хотя я уже неплохо разбирался в компьютерах, информатика казалась мне чем-то особенным. Но я быстро понял, что информатика — это не только программирование и личная работа на компьютере. Это ещё и постоянная работа с различными проблемами — причём такая работа становится одним из основополагающих принципов информатики. Вам всё время придётся искать и отлаживать различные ошибки.
А когда сталкиваешься с ошибками в программах, возникает чувство, будто бьёшься о стену. В такие моменты надо сделать шаг назад, передохнуть или даже переключиться на другие задачи. Зато, когда в итоге всё получается, ты испытываешь ни с чем не сравнимое чувство гордости — особенно когда в конце семестра с нуля создал собственный программный проект!
Изучение информатики не было для меня лёгкой прогулкой — у меня тоже постоянно возникали различные проблемы и я регулярно сталкивался с ошибками. Вот подтверждение — на прошлой неделе я заглянул в свою старую папку с материалами по CS50 (она сохранилась с тех пор, когда я сам проходил этот курс) и обнаружил фотографию своей первой компьютерной программы, написанной по заданию преподавателя. Вот она:

Эта программа печатает на экране «Hello, CS50!». Как видите, я не следовал указаниям преподавателя, из-за чего потерял пару баллов (перевод комментария от преподавателя: «–2 балла за hello.out, надо было выходить из hello, а не из make»).
Более подробно эту программу мы разберём в следующих статьях этого цикла — она очень простая.
Если вы думаете, что любой студент, который изучает этот курс, уже знает больше вас, то по статистике это не так — 2/3 студентов CS50 никогда раньше не посещали курсы по программированию.
Вернёмся к самой информатике. Для меня информатика — это решение проблем. Конечно, мы и так постоянно их решаем. Но курс информатики поможет научиться мыслить методично и тщательно — компьютер не будет делать то, что вы от него ожидаете, если ваши указания для него не будут максимально точными и корректными.
Проще всего понять, в чём заключается суть информатики, можно по такой схеме:
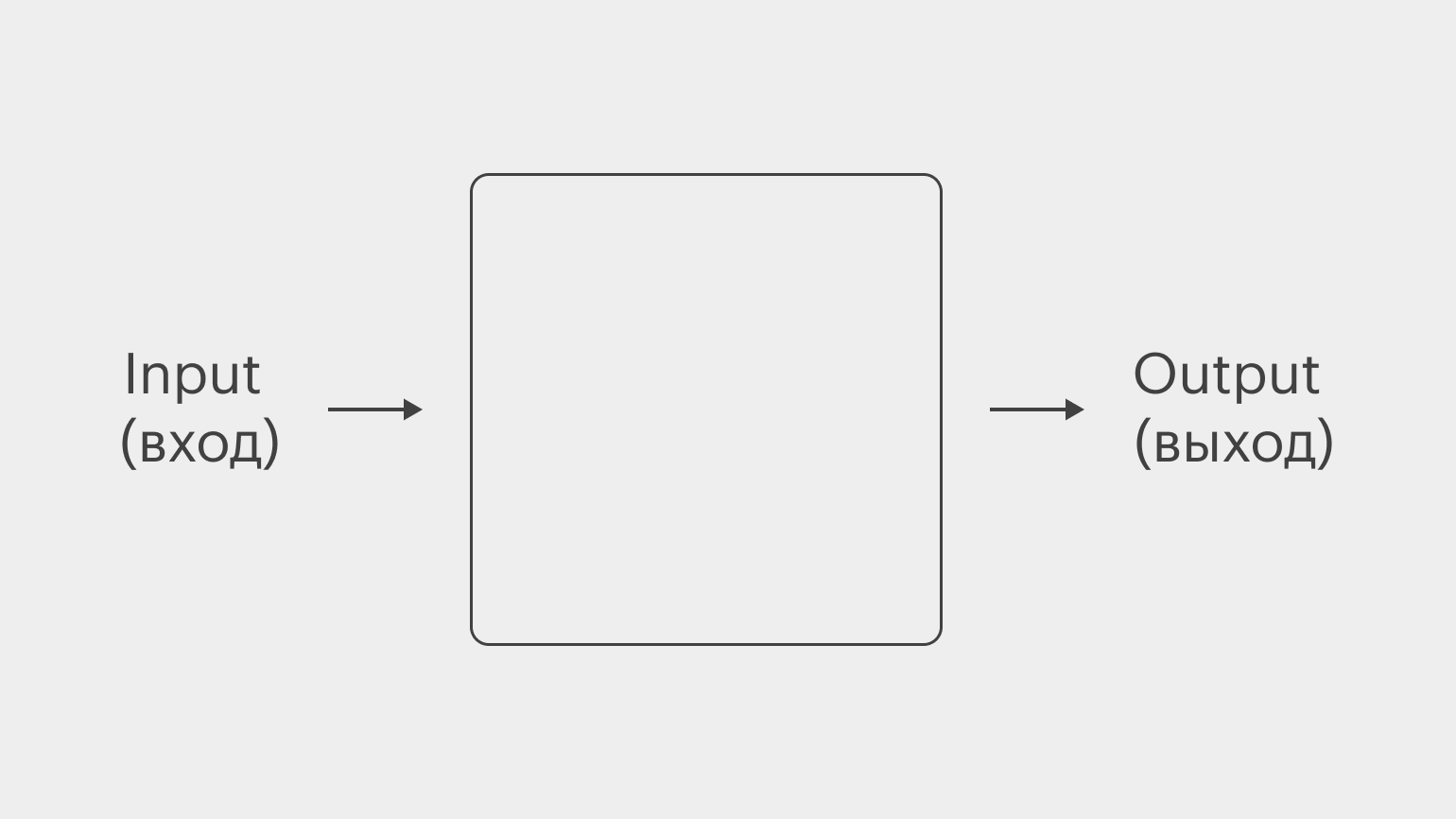
То есть каждый раз, когда вы пишете программу, вам необходимо создать какое-то решение, которое позволяет перейти от данных на входе к какому-то результату на выходе с помощью языка, понятного вашему девайсу.
Поэтому для начала рассмотрим, как компьютер воспринимает данные. Возможно, вы уже слышали, что компьютеры понимают только нули и единицы, но, с другой стороны, вы на личном опыте могли убедиться, что компьютеры могут обрабатывать числа в Excel, отправлять текстовые сообщения, создавать изображения, показывать фильмы и делать многое другое. Чтобы разобраться, как из набора нулей и единичек рождается фильм, посмотрим на то, как компьютер считает.
Как компьютер представляет числа
Числа, с которыми мы встречаемся в обычной жизни, состоят из цифр от 0 до 9. Как же компьютер их понимает, если работает только с нулями и единицами? Взгляните на шаблон:

Здесь три нуля. Если мы представим с помощью этого шаблона число 1 в двоичном формате, оно будет выглядеть как 001, число 2 — как 010, 3 — как 011 и так далее до числа 7, которое будет выглядеть как 111.
Подробнее о двоичной системе счисления и математических операциях с двоичными числами можно почитать в нашей статье.
Почему мы используем для компьютера именно такой шаблон? Дело в том, что любое электронное устройство упрощённо можно представить в виде набора переключателей (транзисторов), которые можно включать и выключать. В компьютерах используются миллионы транзисторов, и единица измерения информации, привязанная к одному из них, называется битом. Бит может принимать значение 0, если транзистор включён, и 1, если он выключен.
Подробнее об истории, принципах работы транзисторов и о том, как компьютер проводит с их помощью разные операции, можно почитать в нашем спецпроекте.
Но биты слишком малы — работать с ними неудобно. Поэтому учёные решили использовать для хранения и обработки информации последовательность из 8 бит — то есть байты. Один байт уже может хранить не два значения — единичку или ноль, а целых 256 — от 0 до 255. Это как раз 2 в восьмой степени.
Итак, тысячи байтов называются килобайтами, миллионы — мегабайтами, миллиарды — гигабайтами, триллионы — терабайтами.
На самом деле всё несколько сложнее. В разных случаях используются разные кило-, мега- и тому подобные байты. Например, при указании объёма жёстких дисков принято считать килобайтом 10 в третьей степени байтов (то есть 1000). Хотя по классике, чтобы получить килобайт, надо умножить 1 байт на 2 в десятой степени (то есть 1024). Соответственно, классический гигабайт равен 1 073 741 824 байтам, тогда как «жесткодисковый» — всего 1 000 000 000 байтам.
Рассмотрим работу транзисторов на примере трёх лампочек. Если светильники не горят, то у нас будет число 0 (000).
Теперь включим одну лампочку:
Это будет 1 (001).
Теперь выключим первый светильник и включим второй.
Получим число 10 (010), это будет 2 в десятичной системе счисления. А если включить все лампочки, то получится число 111 (7 в десятичной системе). Это — максимальное значение, которое можно записать с помощью трёх бит (2 в третьей степени).
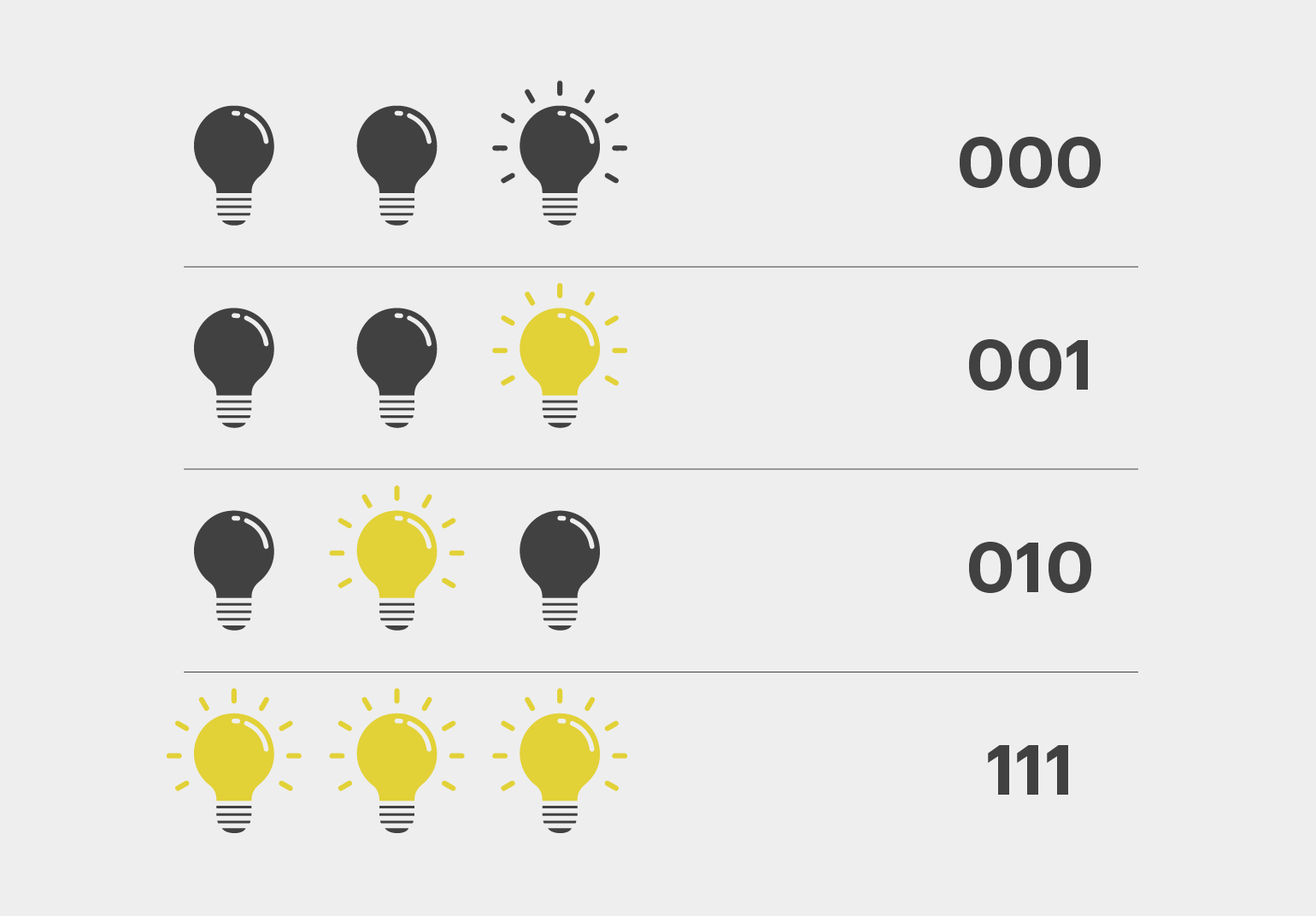
Наверняка вы уже догадались, что, когда компьютер производит операции над десятичными числами, он переводит их в двоичную систему счисления.
Например, десятичное число 123 мы можем разложить на степени числа 10 и простые множители:
123 = 1 × 102 + 2 × 101 + 3 × 100
Аналогичный трюк сработает и в случае двоичного числа 111 — только из цифр у нас будут 1 и 0.
111 = 1 × 22 + 1 × 21 + 1 × 20
Как компьютер понимает буквы
С числами разобрались — но как в памяти компьютера выглядят буквы? Люди договорились, что буквы в памяти тоже будут представляться в виде цифр. Заглавная A английского алфавита, например, представлена числом 65 (01000001 в двоичном коде), буква B — числом 66 (01000010), C — числом 67 (01000011) и так далее.
Эта система кодирования называется ASCII (англ. American standard code for information interchange — американский стандартный код для обмена информацией). Её разработали в 1963 году. ASCII содержит коды для представления десятичных цифр, букв латинского алфавита, знаков препинания и управляющих символов. Каждый ASCII-символ имеет числовой код в диапазоне от 0 до 255 и, соответственно, фиксированную длину в 8 бит (1 байт).
Представьте, что вам пришло сообщение по электронной почте, текст которого закодирован последовательностью чисел 72 73 33 (или 01001000 01001001 00100001 в двоичной системе). Оно означает «HI!». Это сообщение легко можно расшифровать по таблице ASCII:
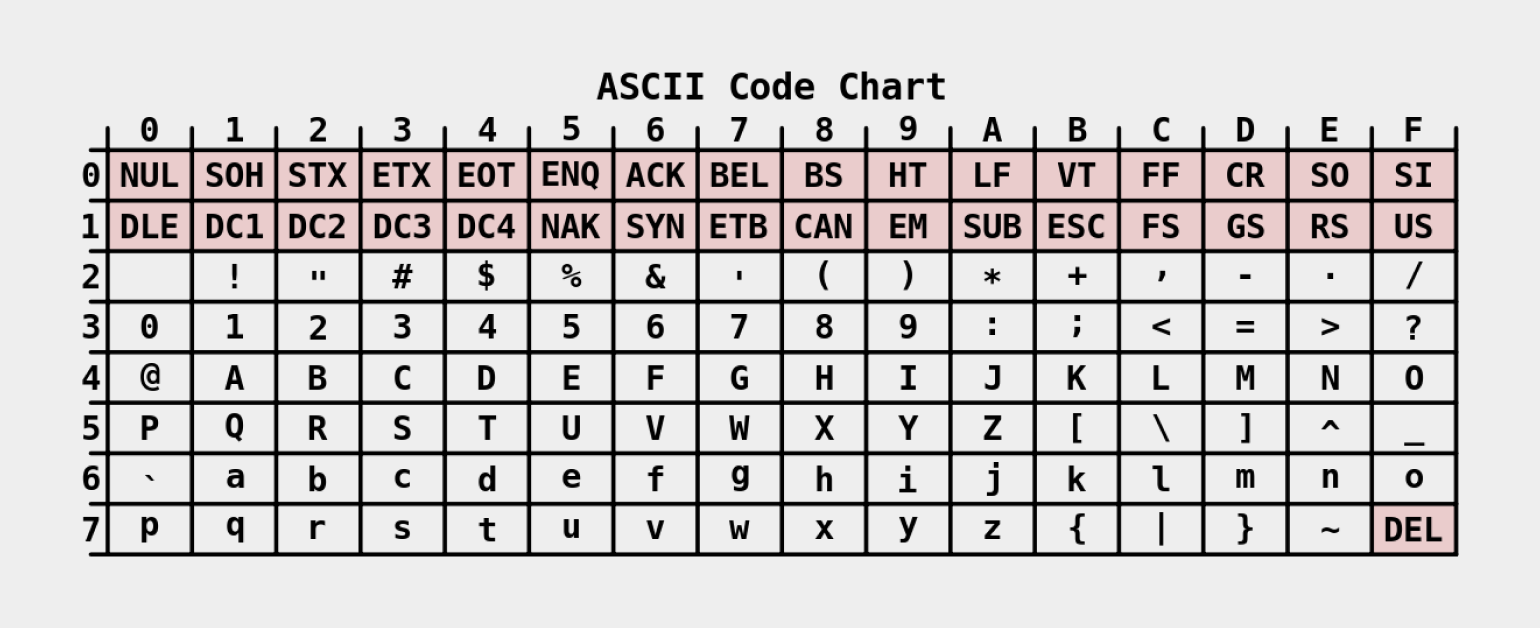
Изображение: Wikimedia Commons
ПК, Мac, смартфоны и другие вычислительные устройства сконструированы так, чтобы понимать эту таблицу.
Однако с ASCII быстро возникла проблема — с её помощью можно закодировать только 256 символов. Этого достаточно, если вы используете английский язык. Но в мире есть множество других языков, которым требуется гораздо больше символов. Поэтому в 1991 году был принят стандарт Юникод (англ. Unicode), который включает в себя знаки почти всех языков мира: китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, диакритику, символы музыкальной нотной нотации и даже эмодзи. На сегодня в таблице Unicode хранится уже почти 150 000 символов.
Символы в кодировке Unicode занимают различное число бит — есть стандарты на 8, 16 и 32 бита (1, 2, 4 байта). Рассмотрим вот такой 4-байтный код:

За ним скрывается эмодзи с медицинской маской:

Таблицу Юникода мы приводить не будем — уж слишком много в ней символов :)
Как компьютер хранит цвета, картинки и фотографии
Для кодирования цветов существует специальная модель — RGB (от англ. red, green, blue), c помощью которой каждый цвет представляется в виде комбинации красного, зелёного и синего цветов разной насыщенности.
Чтобы понять, как это работает, используем числа 72, 73 и 33 в онлайн-сервисе, который позволяет смотреть разные цвета в различных цветовых пространствах, — программе для создания и редактирования графических изображений. Пусть 72 — это насыщенность красного цвета, 73 — зелёного, а 33 — синего. Чтобы посмотреть, как выглядит каждый из них в отдельности, введите соответствующее значение цвета в строку RGB, а ненужные цвета в этой строке выставьте на ноль. Например, чтобы посмотреть оттенок синего, поставьте на ноль R и G (то есть красный и зелёный): 0, 0, 33. Вот какие цвета мы получили по отдельности:

Смешивая эти цвета, мы получим такой жёлто-зёленый оттенок:

Можете поэкспериментировать с разными значениями и смешивать разные цвета.
Подробнее разобраться в цветовых пространствах поможет наша статья.
Теперь перейдём к изображениям. Возможно, вы уже слышали слово «пиксель» — точка на экране. На наших ноутбуках и телефонах их уже миллионы. Но если взять «медицинский» смайлик, который мы использовали выше, и очень сильно увеличить его, эти пиксели, то есть «квадратики», станут заметны. Из таких же квадратиков или точек состоит любое изображение на экране.

То есть все изображения на компьютерах состоят из отдельных точек, каждая из которых использует 24 бита для представления цвета по модели RGB. А ваша графическая карта понимает, что это за цвета, и выводит их на экран.
Как компьютер представляет видео и звуки
Видео добавляет понятие времени — это не просто одно изображение, а уже последовательность изображений, быстро сменяющих друг друга, — например, 24 или 30 кадров в секунду. Мы интерпретируем их с помощью глаз и мозга и видим движение на экране. То же самое происходит со звуком и музыкой.
Посмотрите на эти ноты:

Человек, владеющий нотной грамотой, легко исполнит их на музыкальном инструменте. Компьютеры тоже могут воспроизводить эти звуки. Например, популярный формат аудио, который называется MIDI, представляет каждую ноту как последовательность чисел:

Но музыка — это не только ноты до, ре, ми и так далее, есть ещё знаки альтерации: диез, бемоль, бекар. Имеет значение и то, как долго и громко звучит та или иная нота, на каком инструменте её играют. Учитывая все эти детали, мы сможем записывать музыку и воспроизводить её на компьютере. Но в каком бы формате ни хранилась информация, компьютер переводит её во всё те же нули и единицы.
В медиафайлах приходится хранить огромные объёмы информации. Так, для голливудского фильма, длящегося час-полтора, используется частота 24 или 30 кадров в секунду. Представьте, сколько картинок одновременно хранится в видеофайле! При этом даже одна фотография может весить несколько мегабайт. Спойлер: полтора часа фильма — это 5400 секунд и 162 000 изображений при частоте 30 кадров в секунду.
Поэтому со временем люди разработали такие форматы файлов, которые с помощью разных умных алгоритмов уменьшают объём хранимой информации.
Мы ещё рассмотрим их более подробно в последующих статьях.
Что такое алгоритм
И вот мы переходим к одному из центральных понятий информатики — алгоритму. Повторим схему, которая уже приводилась выше:
Алгоритм — это пошаговые инструкции для решения какой-либо задачи. Когда вы пишете программу, то реализуете один или несколько алгоритмов и используете тот или иной язык программирования. Но, независимо от языка, компьютер будет представлять то, что вы печатаете, используя только нули и единицы.
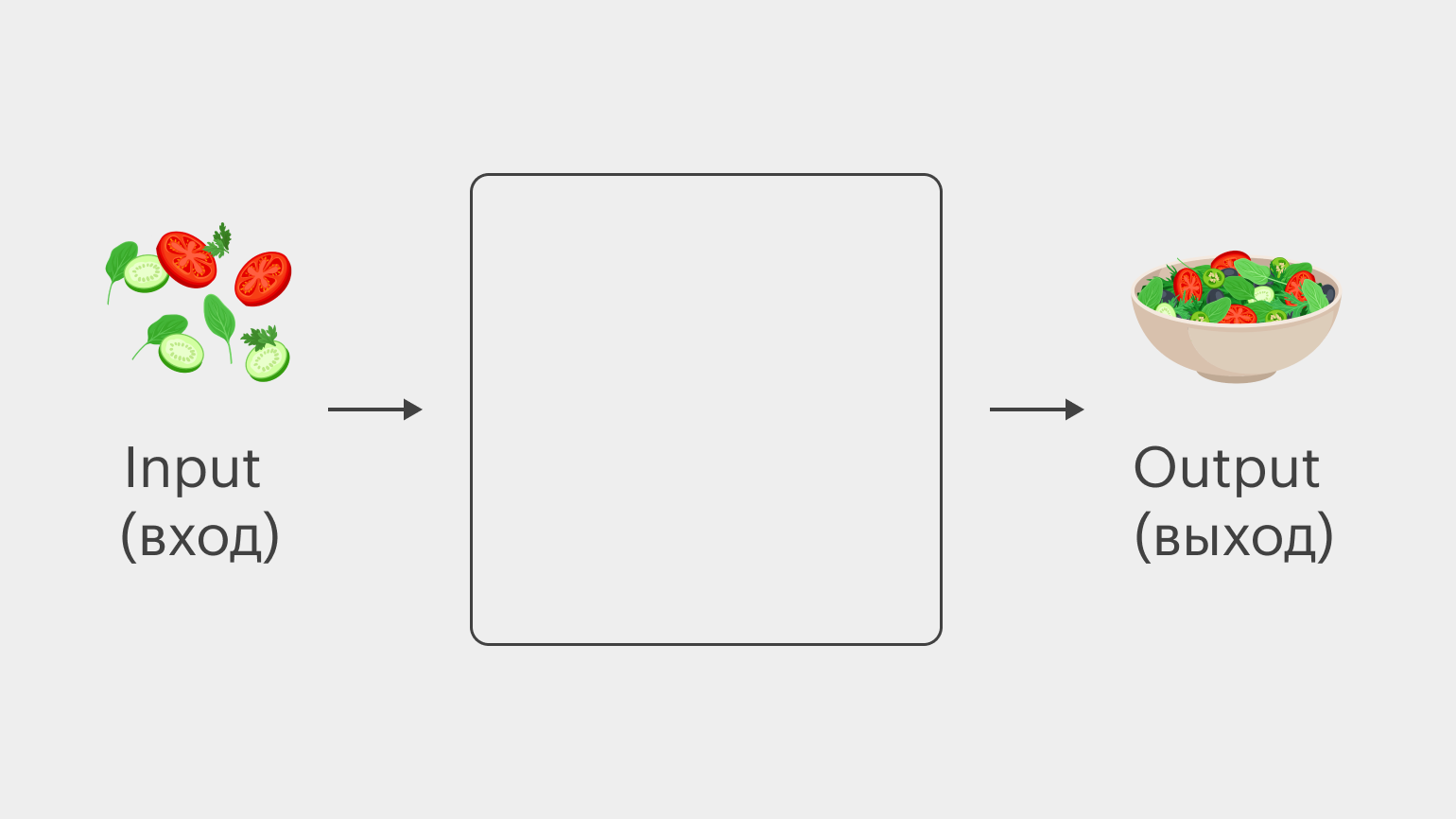
Если говорить об этой схеме, то алгоритм — это то, что скрыто в нашем синем квадрате. Входные данные обрабатываются по определённому алгоритму (то есть к ним последовательно применяется набор каких-то операций), и получаются выходные данные, какой-то результат.
Например, чтобы из огурцов, помидоров, сметаны, соли и перца (входные данные, input) получить вкусный салат (выходные данные, output), необходимо применить следующие операции:
- помыть помидоры и огурцы;
- нарезать помидоры и огурцы;
- положить их в миску;
- добавить сметану;
- добавить соль;
- добавить перец;
- тщательно перемешать.
Это и есть алгоритм!
Эффективность алгоритмов
Рассмотрим ещё один пример алгоритма. Допустим, в адресной книге вашего телефона хранится множество контактов — имён, фамилий, номеров, адресов электронной почты и тому подобного. Они отсортированы в алфавитном порядке: по имени или фамилии, от «А» до «Я» или по какому-то другому символу.
Для демонстрации используем бумажную телефонную книгу Гарварда, в которой 1000 страниц и целая куча имён, отсортированных по алфавиту. Предположим, что мы хотим найти Джона Гарварда.
Алгоритм 1. Мы можем просто пролистывать книгу с самого начала, просматривая одну страницу за другой. Если имя Джона Гарварда есть в телефонной книге, то в конце концов мы доберёмся до него. Так что этот алгоритм верен. Но эффективен ли он? Нет, поиск займёт много времени.
Алгоритм 2. Мы можем пролистывать и по 2 страницы. Но будет ли это правильно? Нет, ведь если мы начнём с первой страницы, то будем просматривать только нечётные страницы и можем пропустить Джона Гарварда, если его имя находится на чётной странице.
Алгоритм 3. А теперь раскроем книгу посередине.

Похоже, что я нахожусь на букве «M». Значит, Джон Гарвард будет в левой части книги. Оторвём правую половину книги — она нам больше не нужна. Количество страниц для поиска уменьшилось с 1000 до 500.
Опять раскроем страницы посередине. Сейчас я оказался на букве «Е». Значит, Джон Гарвард, если он вообще тут есть, окажется в левой части книги. Разорвём её и отбросим ещё 250 страниц.
Так мы будем повторять до тех пор, пока у нас не останется одна страница. На ней будет имя Джона Гарварда, если оно есть в книге, или его там не будет, если его в книге нет. В тех частях, что я отбросил, его нет 100%.
Почему такой алгоритм лучше, чем первый или второй, даже если во втором случае возвращаться к нечётным страницам, если мы перескочили Джона Гарварда? Чтобы понять это, построим график: на оси X будем отмечать количество просмотренных страниц, а на оси Y — время для их просмотра. Здесь n — количество страниц, которые нужно просмотреть, чтобы найти Джона Гарварда.
Два первых алгоритма дадут линейные графики, так как время, потраченное на просмотр страниц, будет прямо пропорционально их количеству. Конечно, во втором случае просмотр пойдёт быстрее, так как мы будем просматривать только нечётные страницы.
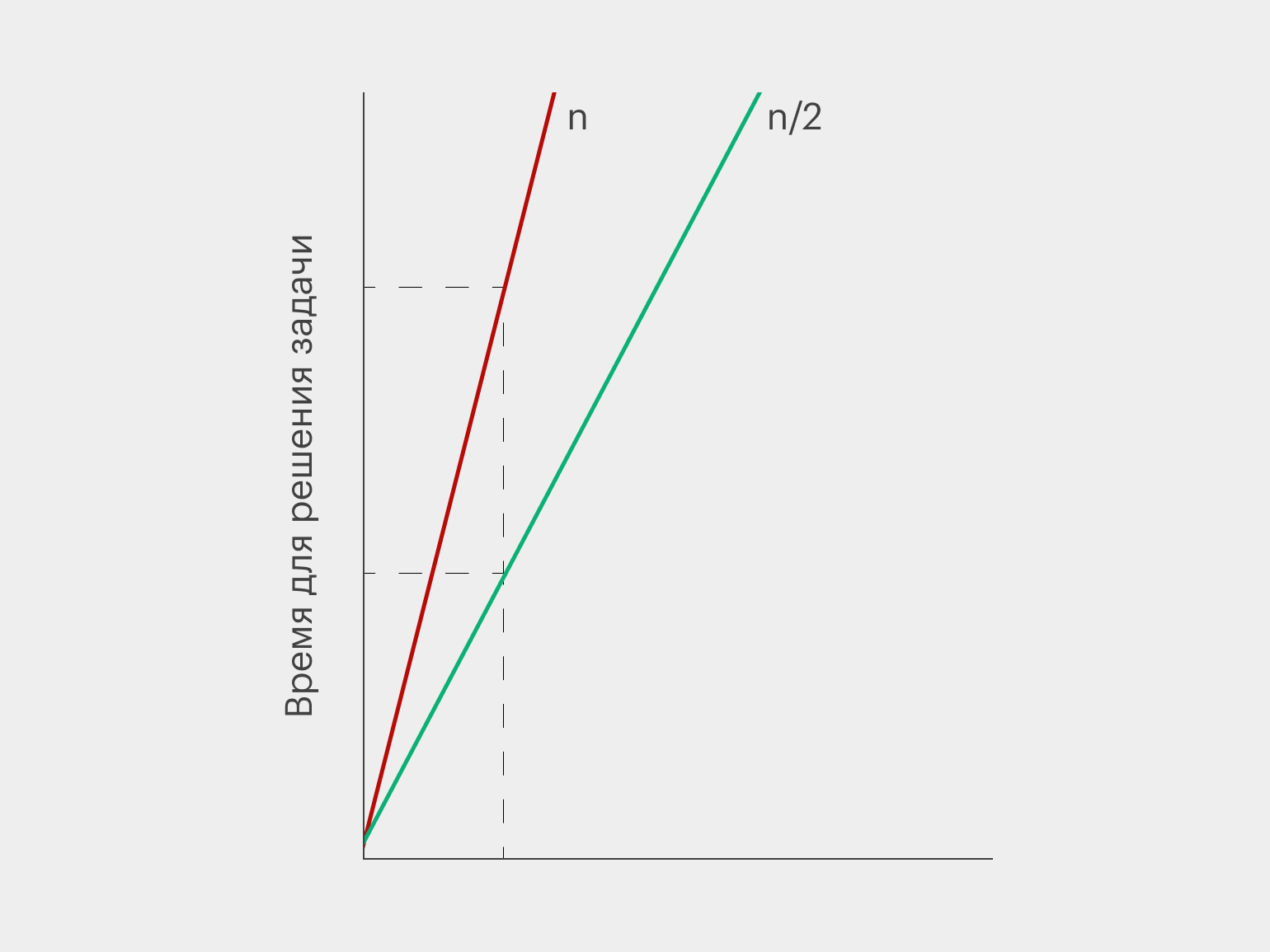
Но график третьего алгоритма будет выглядеть иначе:
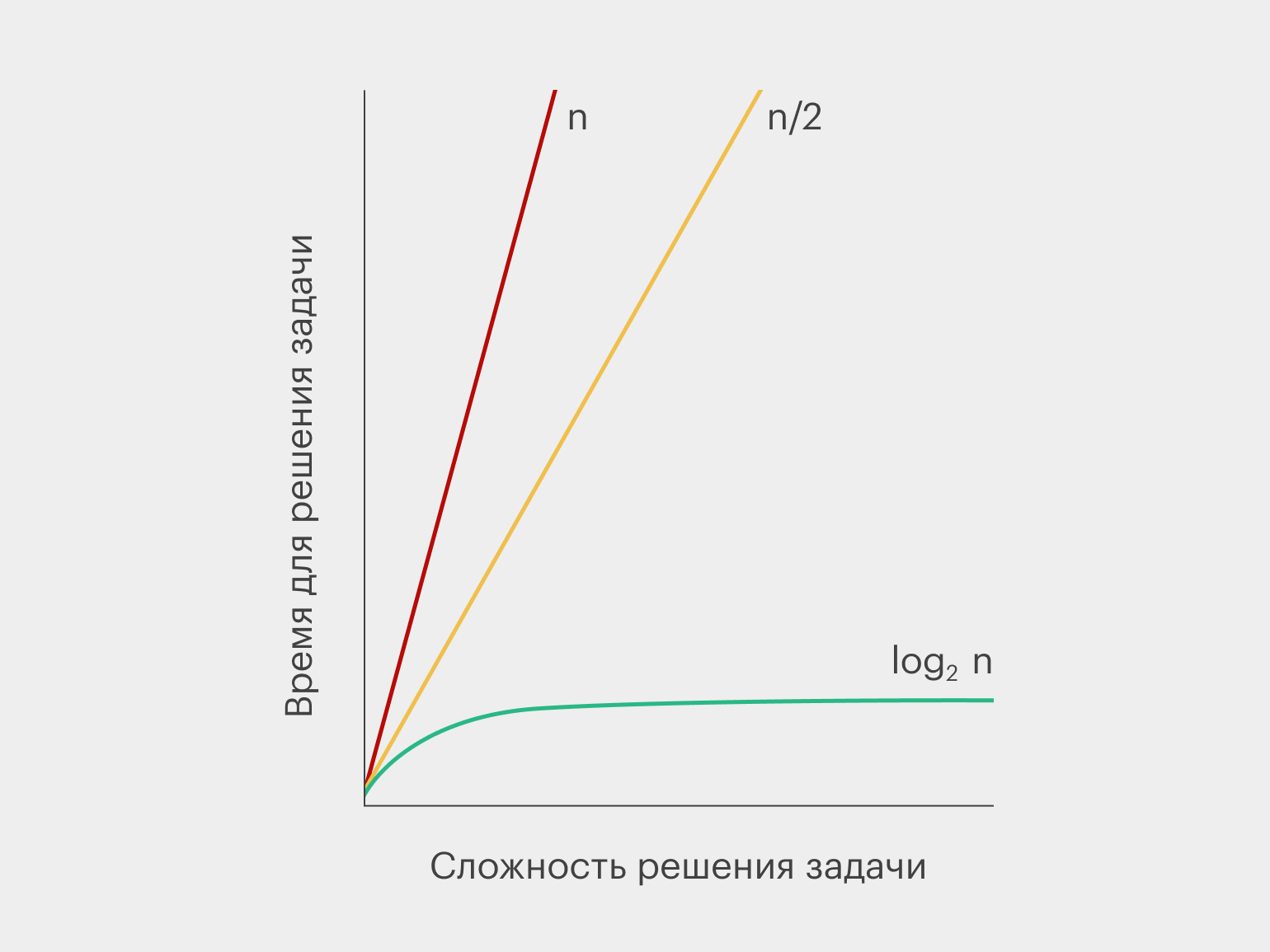
Это логарифмическая кривая. Здесь принципиально иное соотношение между объёмом задачи и количеством времени, необходимого для её решения. Даже если в телефонную книгу добавятся ещё два города и она станет в два раза толще, зелёная линия не намного сдвинется с места. Почему? Да потому, что вы просто разорвёте телефонную книгу пополам, а не будете перелистывать 2000 страниц, чтобы добраться до цели.
Алгоритмы различаются по вычислительной сложности — существует даже специальная система Big O Notation, которая позволяет определять и обозначать сложность алгоритма с точки зрения временных затрат. У нас есть об этом отдельная подробная статья.
Алгоритм — штука непростая. Например, в них необходимо учитывать все возможные случаи, даже те, которые происходят редко. Если их не учесть в алгоритме, программа просто завершится с ошибкой. В случае с поиском контакта в телефонной книге нам надо обработать ситуацию, при которой такого контакта в книге нет вообще — или есть несколько контактов с одинаковым именем. Что должна делать программа в подобных случаях?
Что такое псевдокод
Описывать алгоритм словами, как в рецепте, — неудобно и долго. Посмотрите на пример реализации алгоритма по поиску контакта в телефонной книге:
- Взять телефонную книгу.
- Раскрыть её посередине.
- Посмотреть на страницу.
- Если нужное имя человека на этой странице,
- Позвонить ему.
- Иначе, если имя человека может быть на предыдущих страницах,
- Открыть левую часть книги посередине.
- Перейти к шагу 3.
- Иначе, если имя человека может быть на последующих страницах,
- Открыть правую часть книги посередине.
- Перейти к шагу 3.
- Иначе
- Выход.
Если нужного имени нет ни на открытой странице, ни в левой, ни в правой части, значит, его нет в книге. В нашем псевдокоде это предусмотрено в пунктах 12 и 13.
В принципе, всё довольно понятно — но многословно. Представлять так алгоритмы всё равно неудобно. Гораздо лучше было бы описывать их в какой-то системе нотации, где разные операции обозначаются какими-то краткими, понятными командами и символами.
Конечно, можно использовать для записи алгоритмов какой-то конкретный язык программирования, но это тоже так себе решение. У каждого языка есть свои синтаксические особенности, которые не нужны для обозначения алгоритма и будут только запутывать — какие-то импорты, вызовы дополнительных процедур и тому подобное. Они отвлекают от сути и как бы «замусоривают» суть.
Именно поэтому был разработан так называемый псевдокод — специальная система нотации для описания компьютерных алгоритмов. Он сделан интуитивно понятным и простым, а кроме того, в нём нет каких-то дополнительных синтаксических «обвесов» — только чистое значение. Хотя «сделан» — слишком громкое слово, потому что единого стандарта для псевдокода, по сути, не существует. Команды псевдокода можно писать по-русски или по-английски «если» — if, «пока» — while и так далее. Главное — чтобы программа, написанная псевдокодом была понятна тем, для кого она пишется.
Примеры псевдокода можно найти как в учебниках по информатике, так и в статьях и книгах по алгоритмам. Выглядеть они могут примерно так:
ЕСЛИ строка1 содержит строку2
ВЫВОД («строка1 содержит строку2»)Что общего у языков программирования
Конечно, чтобы компьютер смог что-то вычислить и выполнить наш алгоритм, его нужно написать на понятном нашему цифровому помощнику языке — то есть на языке программирования. Языков программирования очень много, и они довольно сильно различаются: командами, возможностями, задачами, для которых они подходят, и тому подобным. Но при этом у них есть общие черты.
Например, в большинстве языков программирования есть функции — выделенные блоки кода, которые решают небольшую задачу. Если последовательно расположить несколько разных функций, то можно решить более крупную задачу. Например, одна функция может искать контакт человека в телефонной книге, а другая — звонить этому человеку или редактировать контакт.
Однако помимо функций в языках программирования есть ещё несколько фундаментальных сущностей. Посмотрим на наш алгоритм:
- Взять телефонную книгу.
- Раскрыть её посередине.
- Посмотреть на страницу.
- Если нужное имя человека на этой странице,
- Позвонить ему.
- Иначе, если имя человека может быть на предыдущих страницах,
- Открыть левую часть книги посередине.
- Перейти к шагу 3.
- Иначе, если имя человека может быть на последующих страницах,
- Открыть правую часть книги посередине.
- Перейти к шагу 3.
- Иначе
- Выход.
Жирным выделены условия — места в алгоритме, когда дальнейшее действие зависит от ответа на какой-то простой вопрос: выражение верно или выражение неверно? Условия похожи на дорожные развилки: вы можете пойти налево, направо, прямо или куда-то ещё — в зависимости от того, куда вам надо попасть.
Например, если вы оказались на развилке, где одна дорога ведёт в Москву, а другая в Санкт-Петербург, вы можете задаться вопросом: «Хочу ли я в Москву?» Если да, то вы выбираете дорогу, ведущую в Москву, иначе выбираете дорогу на Санкт-Петербург.
Ещё в нашем импровизированном псевдокоде есть циклы, то есть команды, которые выполняют какой-то кусочек алгоритма несколько раз (останавливаются циклы как раз благодаря определённым условиям).
- Взять телефонную книгу.
- Раскрыть её посередине.
- Посмотреть на страницу.
- Если нужное имя человека на этой странице,
- Позвонить ему.
- Иначе, если имя человека может быть на предыдущих страницах,
- Открыть левую часть книги посередине.
- Перейти к шагу 3.
- Иначе, если имя человека может быть на последующих страницах,
- Открыть правую часть книги посередине.
- Перейти к шагу 3.
- Иначе
- Выход.
В нашем случае используются самые «глупые» циклы — команды «перейти к такому-то шагу» (или GO TO). В современных языках программирования используются другие команды, потому что каждый раз следить за тем, на какую строку отправляет нас оператор GO TO — настоящее мучение. Особенно в больших программах. Современные циклы выглядят более компактно, как отдельный блок кода:
ДЛЯ (а в диапазоне от 1 до 10) {
<делай что-нибудь полезное>
}Как видите, благодаря условиям и циклам мы можем написать программу всего на 13 строк, и она эффективно найдёт нужный телефон в телефонной книге на 1000 страниц. Настоящая уличная магия!
В следующей статье по CS50 мы попробуем реализовать разные алгоритмы в среде визуального программирования Scratch. Будет весело!
Итоги
- Это первая статья из большого цикла материалов по курсу CS50. Статья — вводная, поэтому в ней нет практических заданий.
- Мы разобрали, как компьютер видит числа, буквы, картинки, цвета, видео и аудио.
- Посмотрели на алгоритмы, немного попользовались псевдокодом.
- Узнали об основных сущностях, которые присущи почти всем языкам программирования: условия, функции, циклы.










