CRUD-приложение на Hibernate для начинающих
Становимся базированными пользователями баз данных.

Бэкендеры в работе часто сталкиваются с базами данных. MySQL, PostgreSQL, Oracle и ещё с десяток видов БД могут стать головной болью для разработчиков — у каждого из них свои особенности, команды и принципы работы. Не всегда есть время и желание копаться в их спецификациях. Хорошая новость: это и не нужно. Подружить сущности из привычного кода с базами данных поможет CRUD-приложение, которое мы сейчас создадим на Hibernate.
Сегодня разберёмся:
- что такое CRUD;
- что такое Hibernate в Java;
- для чего используют фреймворк Hibernate;
- как в Hibernate работать с базами данных;
- как написать CRUD-приложение на Hibernate;
- что следует запомнить.
Что такое CRUD
CRUD — это акроним основных операций с информацией в базах данных (БД). Расшифровывается так:
C — Create («создать»): добавляем новую запись или ресурс в БД. Например, так работает веб-форма, которая позволяет пользователям создавать новые аккаунты в социальной сети или добавлять новые записи в блог.
R — Read («прочитать»): получаем данные из базы данных или ресурса. Например, запрос к БД для получения списка всех пользователей или чтение содержимого статьи на веб-странице.
U — Update («обновить»): меняем существующую запись. Например, форма редактирования профиля пользователя, которая позволяет изменить информацию о нём.
D — Delete («удалить»): удаляем запись или ресурс из базы данных. Например, кнопка «Удалить» на веб-странице, которая позволяет пользователю удалить свой аккаунт или комментарий.
Для некоторых языков программирования существуют специальные фреймворки, реализующие CRUD-подход к работе с данными. Это позволяет разработчику работать с ними быстрее и удобнее. Например, для Java — это фреймворк Hibernate.
Что такое Hibernate в Java
Hibernate — это фреймворк для объектно-реляционного отображения баз данных (ORM, object-relational mapper), разработанный для языка программирования Java.
Можно представить, что ORM — это чертёж пульта управления базой данных. А вот Hibernate — уже сам пульт, созданный по этому чертежу. Причём пульт универсальный — он упрощает взаимодействие разработчика с разными видами баз данных, позволяя ему работать с привычными объектами Java вместо написания SQL-запросов.
Коротко: Hibernate абстрагирует написание SQL-запросов и обработку результатов, предлагая API для работы с данными и работу через привычные объекты Java.
Вот что умеет Hibernate:
- отображает объекты из кода на таблицы базы данных с помощью аннотаций или XML-конфигурации для взаимодействия с ними;
- автоматически создавать SQL-запросы на основе Java-кода и обрабатывать результаты;
- использовать транзакции и управление сеансами работы с базой данных;
- частично кэшировать данные, чтобы повысить производительность приложения;
- использовать различные виды БД и SQL-диалектов: MySQL, PostgreSQL, Oracle и другие;
- строить разные связи между объектами — «один к одному», «один ко многим» и «многие ко многим», имитируя связи различных видов баз данных.
Для чего используют фреймворк Hibernate
Hibernate позволяет разработчикам сосредоточиться на логике приложения, пряча под капот работу с базами данных. С таким подходом проще разрабатывать и поддерживать приложения — не нужно писать лишний код для прикрутки БД и следить за его актуальностью. Разберёмся в этом на примере.
Представьте себе Васю и Петю — двух Java-разработчиков, которым поручили одну и ту же задачу: написать приложение для управления проектами. Вася не читает Skillbox Media и не знает, что есть Hibernate. Он всё делает вручную:
- Создаёт базу данных — прописывает таблицы, индексы и связи с помощью скриптов.
- Сам взаимодействует с ней — пишет и оптимизирует запросы для CRUD-операций, попутно изучая SQL и мануал по конкретной базе данных.
- Вручную обрабатывает ResultSet — отображает инфу из БД на объекты в Java. Вероятно, делает много ошибок, вновь перечитывая документацию.
- Самостоятельно управляет транзакциями — начало, фиксацию или откат.
- Не получает удовольствия от всего этого.
Что делает Петя? Скачивает Hibernate! Вот что происходит дальше:
- Hibernate автоматически создаёт схему базы данных на основе классов сущностей. Пете не нужно создавать таблицы и связи вручную.
- Он использует ORM-запросы на знакомой ему Java: Hibernate предоставляет удобные средства для CRUD-операций с использованием языка запросов HQL (Hibernate Query Language) или JPQL (Java Persistence Query Language).
- Фреймворк автоматически отображает результаты запросов на Java-объекты. Пете не нужно самому выводить данные из ResultSet и писать лишний код.
- Hibernate автоматически фиксирует или откатывает транзакции в соответствии с их состоянием. Это позволяет сэкономить время и защищает данные от случайных изменений со стороны разработчика.
Результат — Hibernate упрощает создание и работу с базами данных для Java-разработчиков, снижая количество возможных ошибок.
Но это не всё. Вернёмся к Васе и Пете — созданную базу данных необходимо обновить для другого приложения.
Что делает Вася:
- Пилит новую базу данных — таблицы, индексы и связи. Всё заново.
- Адаптирует текущие запросы, а может быть, и пишет новые, чтобы те отвечали требованиям синтаксиса и прочим особенностям нового типа БД. Изучает новый SQL-диалект.
- Переносит данные — пишет скрипты или использует инструменты для переноса данных.
- Тестит приложение после переноса на новую БД, чтобы убедиться, что все запросы и операции работают корректно.
- Исправляет код до тех пор, пока он не заработает корректно.
В то время как Петя:
- Меняет конфигурацию проекта: URL-адрес подключения, опционально — имя пользователя и пароль.
- Тестирует проект с новой конфигурацией. Код поменялся автоматически, поэтому ошибок, скорее всего, не будет.
С Hibernate Петя написал на порядок меньше кода и сделал меньше ошибок… Сейчас покажем, как у него это получилось и создадим своё CRUD-приложение на Hibernate.
Как в Hibernate работать с базами данных
В общем случае работу с Hibernate можно разбить на три этапа.
Этап 1. Определение сущностей. Сначала вы создаёте Java-классы для каждой таблицы в базе данных, которые и будут являться сущностями. Добавляя аннотации или XML-маппинг, вы указываете соответствие между классами и таблицами в БД, а также связи между различными сущностями, например связи «один ко многим» или «многие ко многим».
Этап 2. Конфигурация и настройка. Затем вы настраиваете Hibernate для вашего проекта, указывая параметры подключения к базе данных, стратегии создания таблиц и другие настройки. Для этого вы можете использовать файлы конфигурации XML или аннотации в Java-коде. Этот шаг позволяет Hibernate понять, как установить соединение с базой данных и как преобразовать Java-объекты в её записи и наоборот.
Этап 3. Работа с данными. Теперь вы можете использовать сущности и сессии Hibernate для выполнения CRUD-операций (создание, чтение, обновление и удаление) с данными в БД. Вы создаёте или получаете объекты сущностей, изменяете их, а затем сохраняете или удаляете из базы данных. Hibernate автоматически генерирует соответствующие SQL-запросы и управляет соединениями с БД. Разработчику не нужно контролировать эти процессы.
Создаём CRUD-приложение на Hibernate
Дисклеймер. Вам потребуется сборщик приложений, среда разработки и база данных. Мы будем работать с Maven и IntelliJ IDEA — они идут вместе из коробки с IDE. Систему управления базами данных возьмём здесь. Для неё стандартный пользователь — postgres, а пароль нужно будет установить свой и запомнить его.
Ещё нам понадобится Spring, чтобы не прикручивать всё это друг к другу вручную. Если у вас другие предпочтения относительно софта, ничего страшного — большинство билдеров и сред разработки умеют то же самое. Но интерфейсы могут отличаться.

Читайте также:
Разминайте пальцы — будет практика. Представьте, что ветеринарная клиника попросила вас разработать интерфейс для базы своих клиентов. ТЗ такое: в клинику обращается хозяин со своим питомцем. У владельца должны быть имя, почта и телефон, а у питомца — кличка, вид животного и информация про прививки. У одного хозяина может быть несколько животных.
Важно! Дальше в тексте мы исходим из того, что вы знакомы с основами Java — знаете базовый синтаксис, типы данных и умеете работать с IDE. Если это не так, предлагаем вам начать с нашей общей статьи про язык программирования.
Шаг 1. Создаём структуру проекта
Создавайте новый проект по шаблону Maven в IntelliJ IDEA или своей IDE. Для этого выберите Build system — Maven, и нажмите Create:
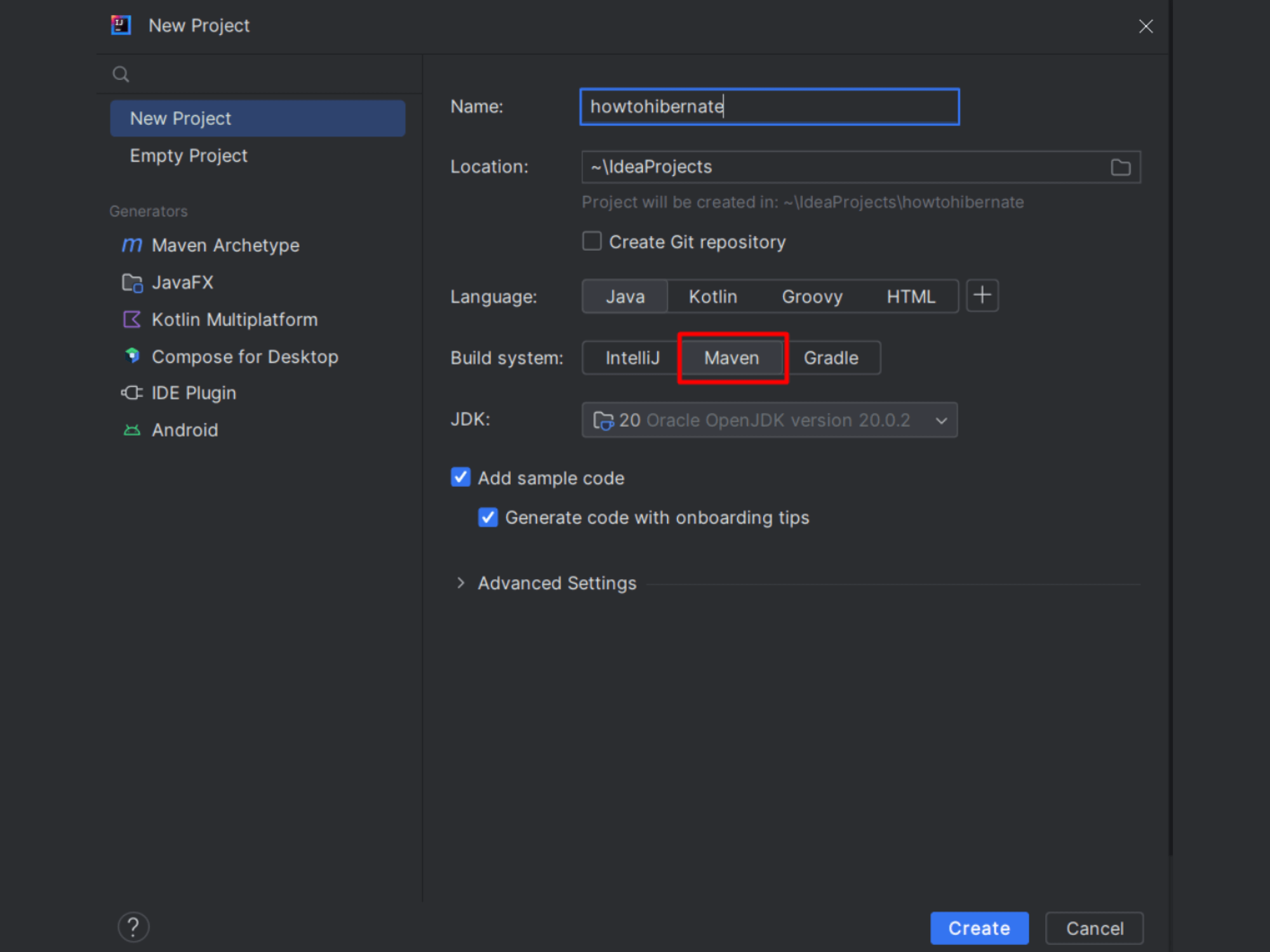
Скриншот: Skillbox Media
Структура проекта в IDE должна выглядеть так:
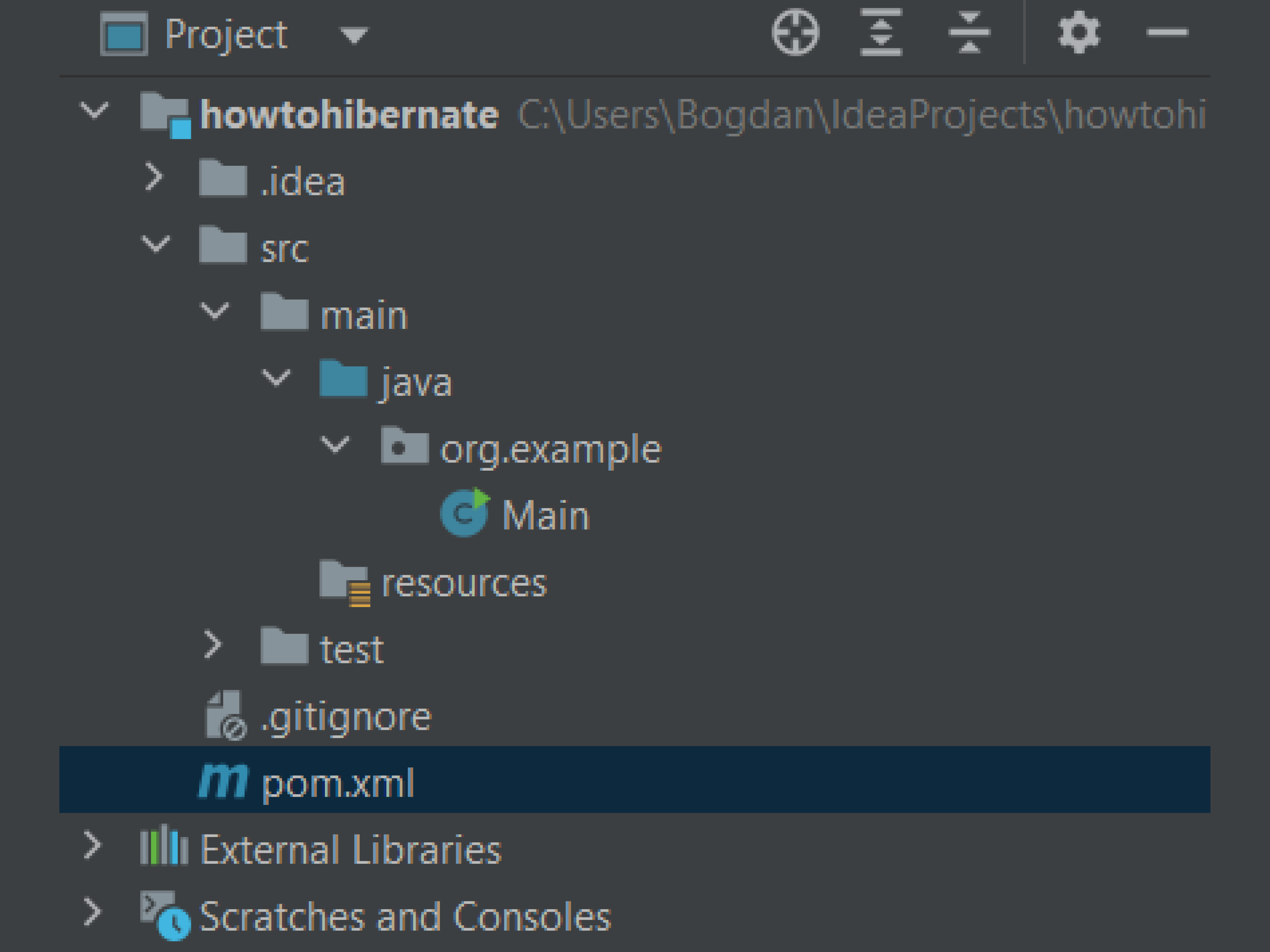
Что тут есть:
src/ — главная папка проекта.
src/main/ — здесь хранятся основные исходники:
- src/main/java/ — исходники Java: классы, интерфейсы и другие компоненты приложения.
- src/main/resources/ — ресурсы: файлы конфигурации, файлы БД, шаблоны и прочее подобное.
- src/test/ — исходные файлы для тестирования.
- src/test/java/ — исходные файлы Java для модульных тестов.
- src/test/resources/ — ресурсы для модульных тестов.
- pom.xml — это файл конфигурации проекта Maven. Здесь хранится информация о зависимостях проекта, настройках сборки, плагинах и других параметрах проекта.
Шаг 2. Прописываем настройки и зависимости в pom.xml
Мы планируем использовать Hibernate вместе со Spring и будем взаимодействовать с базой данных, поэтому необходимо прописать соответствующие зависимости в pom.xml. Так Maven автоматически загрузит их и нам не придётся делать это вручную.
В файле pom.xml проекта указываем параметры — groupId и artifactId. В groupId обычно указывается доменное имя сайта организации или сайта проекта. А artifactId — название самого проекта.
<groupId>org.example</groupId>
<artifactId>howtohibernate</artifactId>
<version>1.0-SNAPSHOT</version>Теперь перейдите к секции <dependencies> и пропишите:
<!-- Maven -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.24</version>
</dependency>
<!-- Hibernate ORM -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.5.7.Final</version>
</dependency>
<!-- PostgreSQL JDBC Driver -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.24</version>
</dependency>
<!-- Spring Framework -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.9</version>
</dependency>
<!-- Spring Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.5.3</version>
</dependency>
<!-- Spring Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.5.3</version>
</dependency>
</dependencies>
Здесь мы указываем всё что планируем использовать в проекте: Maven, Hibernate, PostgreSQL, JDBC Driver, Spring и Spring Data JPA. Если секции <dependencies> нет, то создайте её после секции <properties>.
Обратите внимание, что мы указали конкретные версии зависимостей для Maven, Hibernate, PostgreSQL, JDBC Driver, Spring и Spring Data JPA. Когда будете писать своё приложение, зайдите на официальные сайты компонентов и убедитесь, что эти версии актуальны.
После сохранения изменений в файле pom.xml Maven автоматически загрузит Hibernate, PostgreSQL и Spring. Ничего делать вручную не надо.
Шаг 3. Подключаемся к базе данных PostgreSQL и прописываем properties
Перед работой с Hibernate нужно настроить подключение к вашей БД. Зайдите во вкладку Databases в IDE:

Скриншот: Skillbox Media
Теперь нажмите плюсик:

Скриншот: Skillbox Media
Выберите PostgreSQL. Заполните поля с пользователем (postgres), именем БД (postgres) и введите пароль, который задали при её установке.
Жмите Apply:

Скриншот: Skillbox Media
Проверяем. Нажмите Test Connection — если результат Successful — всё в порядке. Жмём OK.
Давайте добавим базу данных ветклиники. Для этого придётся создать небольшой скрипт. Откройте любой текстовый редактор без автоматического форматирования текста и скопируйте в него:
CREATE TABLE owners (
owner_id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
phone VARCHAR(20)
);
CREATE TABLE pets (
pet_id SERIAL PRIMARY KEY,
owner_id INTEGER REFERENCES owners(owner_id),
name VARCHAR(100),
animal_type VARCHAR(50),
breed VARCHAR(50),
age INTEGER,
vaccinations VARCHAR(100)
);
INSERT INTO owners (name, email, phone)
VALUES
('Scott Turner', 'sturner@cpd.gov', '911'),
('Michael Dooley', 'dooley@cpd.gov', '911'),
('Sabrina Spellman', 'iamnotawitch@hotmail.com', '555-0117'),
('Jon Snow', 'jonsnow@nightwatch.org', '555-1439'),
('Joe Camber', 'castlerockcarservice@hotmail.com', '555-7125'),
('Ellie Creed', 'misscreed@yahoo.com', '555-2559'),
('Emily Elizabeth', 'ihateflorence@hotmail.com', '555-2559'),
('Daenerys Targaryen', 'dracomama@veryhotmail.com', '555-0309'),
('Vic', 'itslegalinpostap@somemail.com', '555-1335'),
('Yorick Brown', 'lastman@hotmail.com', '555-0001');
INSERT INTO pets (owner_id, name, animal_type, breed, age, vaccinations)
VALUES
(1, 'Hooch', 'dog', 'french mastiff', 11, 'all'),
(2, 'Jerry Lee', 'dog', 'german sheperd', 7, 'all'),
(3, 'Salem', 'cat', 'domestic cat', 500, 'none'),
(4, 'Ghost', 'dog', 'direwolf', 4, 'unknown'),
(5, 'Cujo', 'dog', 'saint bernard', 8, 'all, except rabies'),
(6, 'Church (Winston Churchill)', 'cat', 'domestic cat', 10, 'all'),
(7, 'Clifford', 'dog', 'big red dog', 2, 'unknown'),
(8, 'Viserion', 'dragon', 'dragon', 3, 'unknown'),
(8, 'Rhaegal', 'dragon', 'dragon', 3, 'unknown'),
(8, 'Drogon', 'dragon', 'dragon', 3, 'unknown'),
(9, 'Blood', 'dog', 'bobtail', 12, 'none'),
(10, 'Ampersant', 'monkey', 'capuchin', 4, 'all');Сохраните файл с расширением .sql. Теперь создайте базу данных с этим скриптом. Для этого в Databases щёлкните правой клавишей по postgres@localhost и выберите SQL Scripts → Run SQL Script. Укажите сохранённый ранее sql-файл.

Скриншот: Skillbox Media
В итоге вкладка должна выглядеть так:
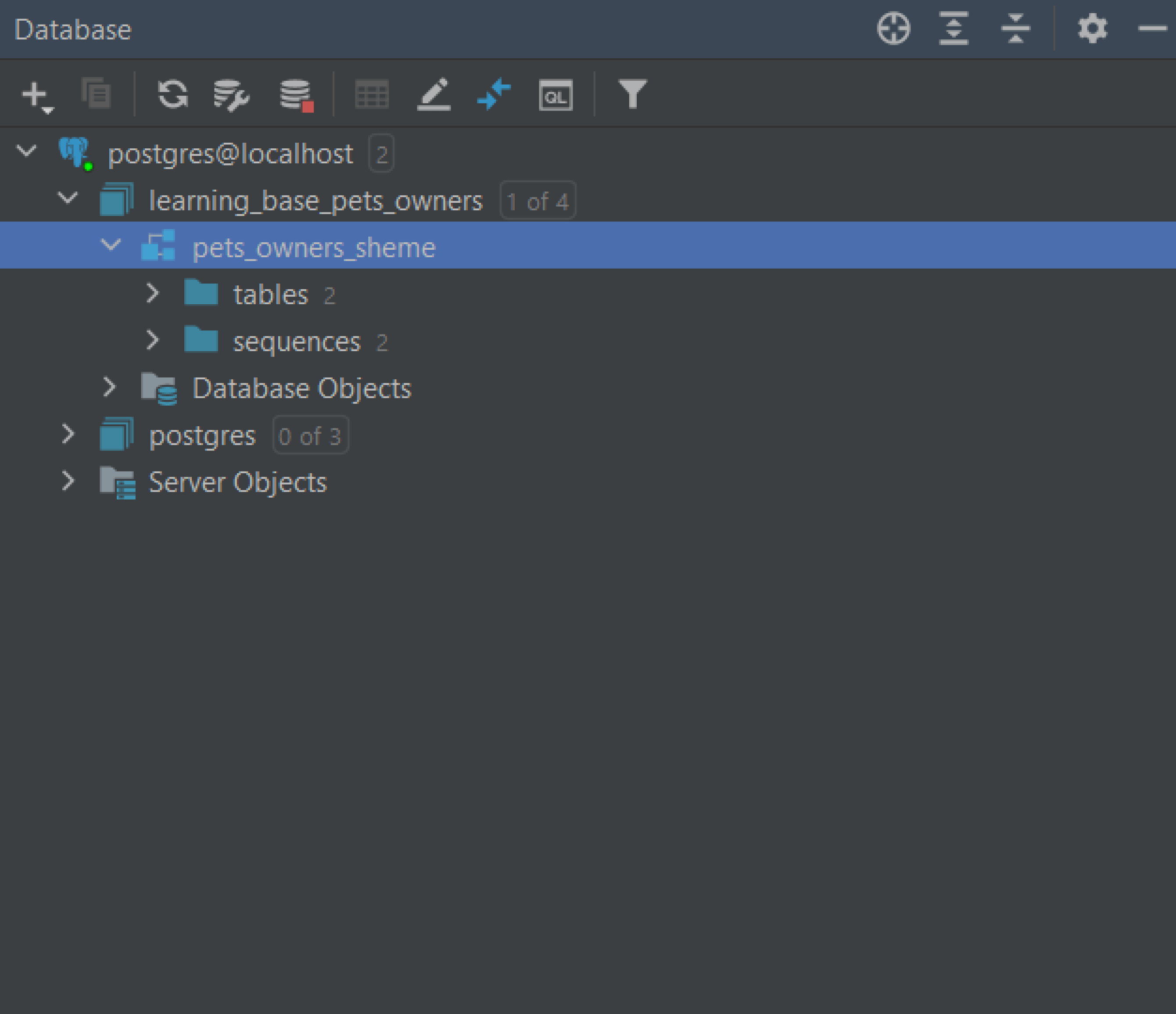
Скриншот: Skillbox Media
Если добавленная база не отображается, то нажмите на номер справа от postgres@localhost и отметьте галочкой нужную базу. Остальные базы для удобства можно скрыть, убрав галочки.
Теперь подружим нашу базу данных со Spring. Для этого создайте файл applications.properties. В проекте нажмите правой клавишей на resources → New → File. Заполним новый файл:
# PostgreSQL
spring.datasource.url=jdbc:postgresql://localhost:5432/learning_base_pets_owners
spring.datasource.username=postgres
spring.datasource.password=*****
# Hibernate
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.hibernate.ddl-auto=update
# Spring Boot
spring.application.name=my-awesome-pet-owners-app
server.port=8080В строках первого блока указываете URL-адрес нашей базы данных, её название, имя пользователя и пароль. В нашем коде имя БД пользователя, а пароль не скажем — он у вас будет свой.
Во втором блоке мы указываем диалект SQL — PostgreSQL в нашем случае, и стратегию создания таблиц — update.
В последнем блоке spring.application.name можете указать любое имя для своей базы данных. А вот номер порта не трогайте.
Мы подготовили всё для работы и теперь можем писать код.
Шаг 4. Создание сущностей (Entity) в проекте Hibernate
Сущности (Entity) представляют объекты, которые будут сохраняться в базе данных. Вам нужно создать классы, которые соответствуют таблицам в БД и содержат поля, представляющие столбцы таблицы.
Для нашей задачи у нас есть две таблицы — owners и pets. Создадим классы для каждой из них:
- Щёлкните правой кнопкой мыши на каталоге src/main/java и выберите New → Package.
- Введите имя пакета для сущностей, например com.example.myapp.model, и нажмите OK.
- После создания пакета нажмите правой кнопкой мыши на нём и выберите New → Java Class.
- Введите имя класса для сущности, например Owner, и нажмите OK.
IntelliJ IDEA откроет новый файл Java с именем Owner.java:
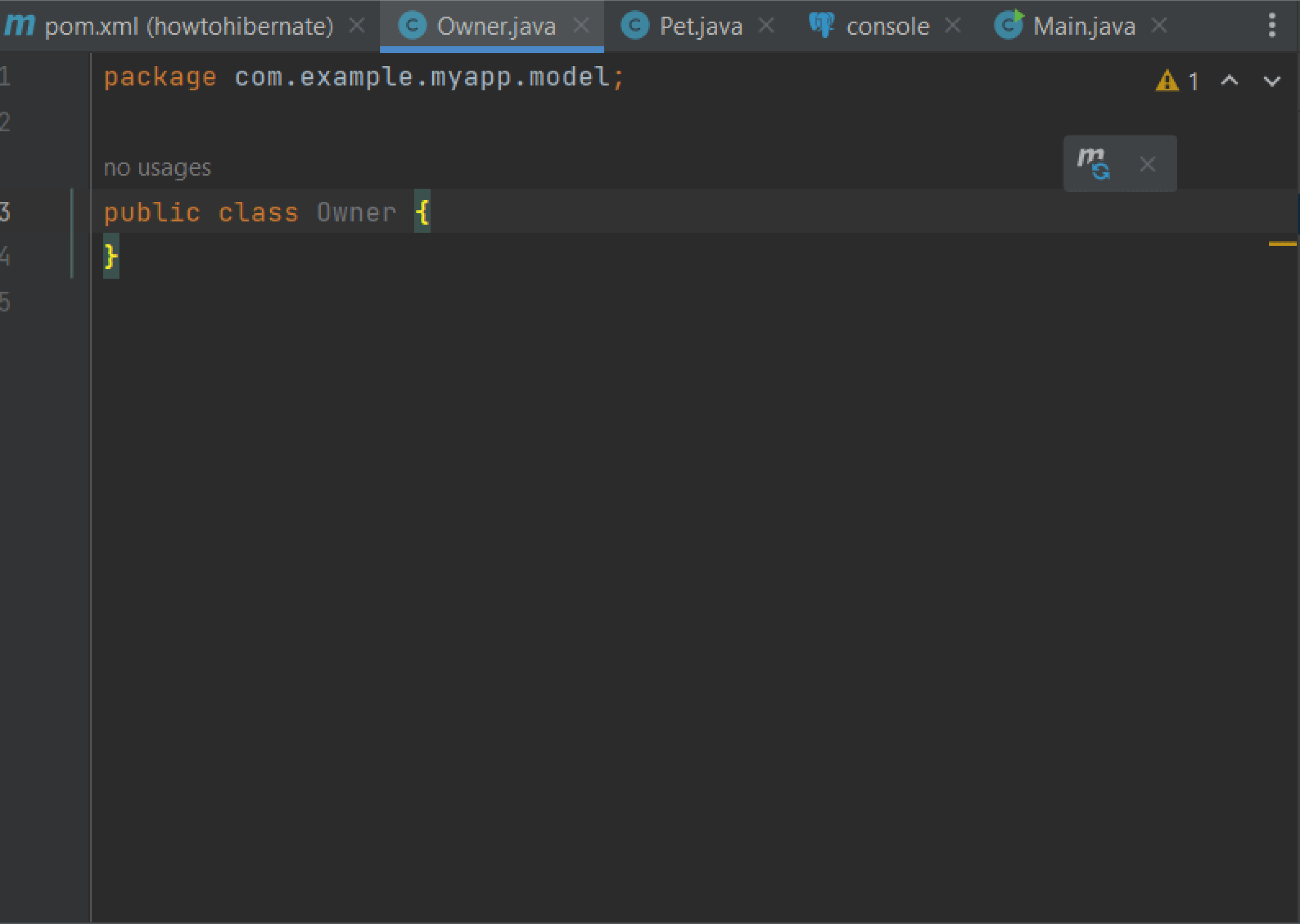
Аналогично создайте файл для Pet.java.
В файле Owner.java создадим все необходимые сущности в соответствии со структурой наших баз данных:
package com.example.myapp.model;
import javax.persistence.*;
@Entity
@Table(name = "owners")
public class Owner {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "owner_id")
private Long id;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "phone")
private String phone;
public Long getId() {
return id;
}
// Добавлены сеттеры
public void setId(Long id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setEmail(String email) {
this.email = email;
}
public void setPhone(String phone) {
this.phone = phone;
}
}
Аналогично создайте новый Java-класс с именем Pet в пакете com.your_username.skillbox.model. Там пишем по аналогии:
package com.example.myapp.model;
import javax.persistence.*;
@Entity
@Table(name = "pets")
public class Pet {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "pet_id")
private Long id;
@ManyToOne
@JoinColumn(name = "owner_id", referencedColumnName = "owner_id")
private Owner owner;
@Column(name = "name")
private String name;
@Column(name = "animal_type")
private String animalType;
@Column(name = "breed")
private String breed;
@Column(name = "age")
private Integer age;
@Column(name = "vaccinations")
private String vaccinations;
public Long getId() {
return id;
}
// Добавлены сеттеры
public void setId(Long id) {
this.id = id;
}
public void setOwner(Owner owner) {
this.owner = owner;
}
public void setName(String name) {
this.name = name;
}
public void setAnimalType(String animalType) {
this.animalType = animalType;
}
public void setBreed(String breed) {
this.breed = breed;
}
public void setAge(Integer age) {
this.age = age;
}
public void setVaccinations(String vaccinations) {
this.vaccinations = vaccinations;
}
}
Обратите внимание, что мы используем аннотации JPA (Java Persistence API), такие как @Entity, @Table, @Id, @GeneratedValue, @Column и @ManyToOne, чтобы указать, какие поля соответствуют столбцам таблицы и как устанавливаются связи между таблицами.
Теперь у вас есть два класса сущностей, которые соответствуют таблицам owners и pets в базе данных.
Шаг 5. Прописываем репозитории, сервисы и контроллеры
Теперь укажем, как пользователи будут взаимодействовать с нашими Pets и Owners. Создайте три пакета по аналогии с предыдущим шагом — com.example.myapp.repository, com.example.myapp.service, com.example.myapp.controller. В каждом пакете создаём по два класса — один для каждой сущности. Структура будет такая:

Выделенные файлы нужно создать в соответствующих пакетах. А потом — прописать:
// OwnerRepository.java
package com.example.myapp.repository;
import com.example.myapp.model.Owner;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface OwnerRepository extends JpaRepository<Owner, Long> {
// Здесь можно добавить дополнительные методы для запросов к базе данных, если необходимо
}
Здесь при помощи аннотации @Repository мы просим Spring автоматически реализовать интерфейс репозитория для нашего класса Owner. OwnerRepository нужен для обеспечения доступа к данным в БД, связанным с сущностью Owner в нашем приложении:
// PetRepository.java
package com.example.myapp.repository;
import com.example.myapp.model.Pet;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface PetRepository extends JpaRepository<Pet, Long> {
// Здесь можно добавить дополнительные методы для запросов к базе данных, если необходимо
}
Теперь создадим аналогичный интерфейс репозитория для класса Pet:
// OwnerService.java
package com.example.myapp.service;
import com.example.myapp.model.Owner;
import com.example.myapp.repository.OwnerRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class OwnerService {
private final OwnerRepository ownerRepository;
@Autowired
public OwnerService(OwnerRepository ownerRepository) {
this.ownerRepository = ownerRepository;
}
public List<Owner> getAllOwners() {
return ownerRepository.findAll();
}
public Owner getOwnerById(Long id) {
return ownerRepository.findById(id).orElse(null);
}
public Owner createOwner(Owner owner) {
return ownerRepository.save(owner);
}
public Owner updateOwner(Owner owner) {
return ownerRepository.save(owner);
}
public void deleteOwner(Long id) {
ownerRepository.deleteById(id);
}
}
// PetService.java
package com.example.myapp.service;
import com.example.myapp.model.Pet;
import com.example.myapp.repository.PetRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class PetService {
private final PetRepository petRepository;
@Autowired
public PetService(PetRepository petRepository) {
this.petRepository = petRepository;
}
public List<Pet> getAllPets() {
return petRepository.findAll();
}
public Pet getPetById(Long id) {
return petRepository.findById(id).orElse(null);
}
public Pet createPet(Pet pet) {
return petRepository.save(pet);
}
public Pet updatePet(Pet pet) {
return petRepository.save(pet);
}
public void deletePet(Long id) {
petRepository.deleteById(id);
}
}
OwnerService и PetService служат прослойками между нашими контроллерами, которые обрабатывают HTTP-запросы, и репозиториями, которые взаимодействуют уже с базой данных.
При помощи аннотации @Service мы реализуем интерфейс класса. А при помощи @Autowired мы просим Spring перенести методы наших Repository-классов в соответствующие Service-классы.
// OwnerController.java
package com.example.myapp.controller;
import com.example.myapp.model.Owner;
import com.example.myapp.service.OwnerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/owners")
public class OwnerController {
private final OwnerService ownerService;
@Autowired
public OwnerController(OwnerService ownerService) {
this.ownerService = ownerService;
}
@GetMapping
public List<Owner> getAllOwners() {
return ownerService.getAllOwners();
}
@GetMapping("/{id}")
public Owner getOwnerById(@PathVariable Long id) {
return ownerService.getOwnerById(id);
}
@PostMapping
public Owner createOwner(@RequestBody Owner owner) {
return ownerService.createOwner(owner);
}
@PutMapping("/{id}")
public Owner updateOwner(@PathVariable Long id, @RequestBody Owner owner) {
owner.setId(id);
return ownerService.updateOwner(owner);
}
@DeleteMapping("/{id}")
public void deleteOwner(@PathVariable Long id) {
ownerService.deleteOwner(id);
}
}
Повторим то же самое для PetController.java:
// PetController.java
package com.example.myapp.controller;
import com.example.myapp.model.Pet;
import com.example.myapp.service.PetService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/pets")
public class PetController {
private final PetService petService;
@Autowired
public PetController(PetService petService) {
this.petService = petService;
}
@GetMapping
public List<Pet> getAllPets() {
return petService.getAllPets();
}
@GetMapping("/{id}")
public Pet getPetById(@PathVariable Long id) {
return petService.getPetById(id);
}
@PostMapping
public Pet createPet(@RequestBody Pet pet) {
return petService.createPet(pet);
}
@PutMapping("/{id}")
public Pet updatePet(@PathVariable Long id, @RequestBody Pet pet) {
pet.setId(id);
return petService.updatePet(pet);
}
@DeleteMapping("/{id}")
public void deletePet(@PathVariable Long id) {
petService.deletePet(id);
}
}
Здесь мы указали контроллеры. Они работают с HTTP-запросами. Разберём код подробнее.
@RestController говорит Spring, что этот класс является RESTful-контроллером — будет обрабатывать HTTP-запросы и возвращать данные в формате JSON или других форматах, если это требуется.
@RequestMapping() указывает, что все методы этого контроллера будут обрабатывать запросы, начинающиеся с пути /owners или /pets. Например, GET /owners будет обрабатываться методом getAllOwners.
@Autowired позволяет нам использовать методы Owner- или PetService в соответствующем контроллере.
А дальше прописываем методы для наших операций:
getAllOwners() и getAllPets() обрабатывают GET-запрос на /owners или /pets соответственно и возвращают список всех владельцев или питомцев.
getOwnerById (Long id) и getPetById (Long id) обрабатывают GET-запрос на /owners/{id} или /pets/{id}, где {id} — переменная в пути, и возвращают владельца или питомца с указанным идентификатором.
createOwner (Owner owner) и createPet (Pet pet) обрабатывают POST-запрос на /owners или /pets и создают нового владельца или питомца на основе данных, переданных в теле запроса (в формате JSON).
updateOwner (Long id, Owner owner) и updatePet (Long id, Owner owner) обрабатывают PUT-запрос на /owners/{id} или /pets/{id} и обновляют информацию о владельце или питомце с указанным идентификатором, используя данные из тела запроса.
deleteOwner (Long id) и deletePetr (Long id) обрабатывают DELETE-запрос на /owners/{id} или /pets/{id} и удаляют владельца или питомца с указанным идентификатором.
Шаг 6. Пишем код в main
Создайте класс MyApp в пакете com.example.myapp и пропишите:
package com.example.myapp;
import com.example.myapp.model.Owner;
import com.example.myapp.model.Pet;
import com.example.myapp.service.OwnerService;
import com.example.myapp.service.PetService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class MyApp {
private final OwnerService ownerService;
private final PetService petService;
@Autowired
public MyApp(OwnerService ownerService, PetService petService) {
this.ownerService = ownerService;
this.petService = petService;
}
public static void main(String[] args) {
SpringApplication.run(MyApp.class, args);
}
@Bean
public CommandLineRunner demo() {
return args -> {
// Здесь можно добавить код для тестирования вашего приложения
// Например, вызвать методы вашего сервиса для создания, чтения, обновления и удаления данных
// и выводить результаты на консоль
// Пример:
Owner owner = new Owner();
owner.setName("John");
owner.setEmail("john@example.com");
owner.setPhone("123456789");
ownerService.createOwner(owner);
Pet pet = new Pet();
pet.setOwner(owner);
pet.setName("Fido");
pet.setAnimalType("Dog");
pet.setBreed("Golden Retriever");
pet.setAge(3);
pet.setVaccinations("All");
petService.createPet(pet);
Owner savedOwner = ownerService.getOwnerById(owner.getId());
System.out.println("Saved Owner: " + savedOwner);
Pet savedPet = petService.getPetById(pet.getId());
System.out.println("Saved Pet: " + savedPet);
};
}
}
В этом классе мы использовали аннотацию @SpringBootApplication, которая объединяет аннотации @Configuration, @EnableAutoConfiguration и @ComponentScan. Она сообщает Spring, что это главный класс приложения, и Spring автоматически сканирует компоненты и настраивает контекст.
Бин CommandLineRunner будет выполняться после запуска. В методе demo() мы добавили пример кода для тестирования OwnerService и PetService. Можете добавить туда свой код для тестирования.
Теперь у вас есть полноценное CRUD-приложение на Hibernate, которое позволяет управлять данными о владельцах животных и их питомцах. Давайте потестим. Если вы всё сделали правильно, то после запуска MyApp увидите что-то такое:

Скриншот: Skillbox Media
Если же появилась ошибка, то проверьте внимательно все шаги, которые мы прошли до этого момента.
Давайте подытожим. Что умеет приложение:
- Создавать записи о новых владельцах животных и их питомцах.
- Читать информацию о владельцах и питомцах по их идентификаторам.
- Обновлять информацию о владельцах и питомцах.
- Удалять сведения о владельцах и питомцах из базы данных.
Как пользоваться приложением
Запустите приложение с помощью метода main в классе MyApp.
Создание владельцев и питомцев
- В браузере перейдите по адресу http://localhost:8080/owners для создания записей о новых владельцах.
- Введите данные владельца (имя, электронная почта, телефон) и отправьте форму.
- Затем перейдите по адресу http://localhost:8080/pets для создания новых питомцев.
- Введите данные питомца (владелец, имя, тип животного, порода, возраст, прививки) и отправьте форму.
Чтение информации о владельцах и питомцах
Чтобы просмотреть информацию обо всех владельцах, перейдите по адресу http://localhost:8080/owners.
Чтобы просмотреть информацию обо всех питомцах, перейдите по адресу http://localhost:8080/pets.
Обновление информации о владельцах и питомцах
- Чтобы обновить информацию о владельце, перейдите по адресу http://localhost:8080/owners/{id}, где {id} — это идентификатор владельца, которого вы хотите обновить.
- Введите новые данные в форму и отправьте её для сохранения изменений.
- Аналогично, чтобы обновить информацию о питомце, перейдите по адресу http://localhost:8080/pets/{id} и внесите необходимые изменения.
Удаление владельцев и питомцев
Чтобы удалить владельца, перейдите по адресу http://localhost:8080/owners/{id}/delete, где {id} — это идентификатор владельца, которого вы хотите удалить.
Аналогично, чтобы удалить питомца, перейдите по адресу http://localhost:8080/pets/{id}/delete и подтвердите удаление.
Поздравляем! У вас есть готовое приложение для работы с базой данных! Теперь вы знаете, что не нужно знать диалекты SQL, чтобы работать с базами данных, — достаточно знать нативный язык и освоить ORM-фреймворк или аналогичную библиотеку. Например, у Python есть SQLAlchemy, у C++ есть ODB, а у PHP — Doctrine. Общий рецепт такой — гуглить ORM-инструменты для своего языка и осваивать их.
Что запомнить
Подведём итоги и вспомним, что мы сегодня узнали про CRUD-приложения и Hibernate:
- CRUD — это акроним от основных операций с информацией в базах данных: Create («создать»), Read («прочитать»), Update («обновить»), Delete («удалить»).
- Hibernate — это фреймворк для объектно-реляционного отображения баз данных (ORM, Object Relational Mapper), разработанный для языка программирования Java. Он позволяет разработчику общаться с базами данных через привычные объекты и классы, а не через SQL-запросы.
- Работу с базами данных в Hibernate проходит в три этапа: определение сущностей, конфигурация и настройка и работа с данными.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!








