Big data: что такое большие данные и как с ними работать
Объясняем, почему после этой статьи вам будет попадаться реклама курсов по работе с данными.


Если вы искали в «Яндексе» или Google новый смартфон, а затем начали регулярно видеть рекламу магазинов техники в своём городе — это не совпадение. Так работают системы на основе больших данных (big data).
В статье разберёмся, что такое big data, зачем они нужны и как с ними работают, и закрепим теорию на практике — проанализируем набор данных, используя инструменты дата-сайентистов.
Содержание
- Что такое big data
- Какие бывают большие данные
- Как работают с большими данными
- Кто работает с big data
- Анализируем данные с PySpark
Что такое big data
Большие данные (big data) — это массивы информации значительного объёма, независимо от её типа и структуры. На практике к ним относят данные, объём накопления которых превышает 150 ГБ в сутки. Порог условный, но он отражает масштаб задач, при котором классические инструменты не справляются.
Большие данные используют для принятия обоснованных решений. Такой подход называют data-driven. Например, дата-сайентисты маркетплейса могут проанализировать историю покупок, сезонность и поведение пользователей, чтобы определить, какие категории товаров показывать на главной странице в конкретные даты. В этом случае решения принимаются не интуитивно, а на основе анализа данных.

Для больших данных выделяют несколько общих признаков, которые называют правилом шести V:
- Volume (объём). Big data имеют такой объём, который невозможно обработать вручную или на одном компьютере. Для работы с ними используют распределённые хранилища и кластерные вычисления. Например, финансовый отчёт на 10 МБ, который можно открыть в Excel, не относится к большим данным, а вот 10 ТБ серверных логов — уже big data.
- Velocity (скорость). Большие данные отличаются высоким темпом накопления и обновления информации. Они часто генерируются непрерывно и требуют анализа в реальном времени.
- Variety (разнообразие). Большие данные отличаются по формату и источникам: это могут быть таблицы, тексты, изображения, видео, аудио, сигналы датчиков и другие типы информации. На практике такие данные часто приходится объединять и анализировать в рамках одной системы.
- Veracity (достоверность). Собранные данные могут быть неточными или «грязными»: содержать ошибки, дубликаты, повреждённые файлы и так далее. Перед анализом их очищают и проверяют.
- Value (ценность). Работа с big data имеет смысл только тогда, когда они превращаются в практическую пользу. Их задача — стать основой для управленческих решений. Например, анализ поведения покупателей маркетплейса позволяет компании увеличить средний чек, оптимизировать ассортимент или снизить отток клиентов.
- Variability (изменчивость). Объём и структура больших данных непостоянны: они могут резко меняться в зависимости от событий, сезона или поведения пользователей. Например, во время крупной онлайн-распродажи количество транзакций, событий и логов возрастает в несколько раз по сравнению с обычным днём.
Big data не стоит рассматривать как абстрактную технологию. Они незаметно работают в повседневных сервисах, которыми мы пользуемся каждый день: в банках, маркетплейсах, на стриминговых платформах, в социальных сетях, поисковых системах и так далее.
Какие бывают большие данные
В зависимости от способа организации информации большие данные делятся на структурированные, неструктурированные и частично структурированные. Разберём каждый вариант.
Структурированные данные — это информация, организованная по заранее заданной схеме. Она разбита на поля с чётко определёнными типами (дата, число, строка) и связями между ними. Чаще всего такие данные представлены в виде таблиц со строками и столбцами, хранятся в реляционных базах данных и обрабатываются с помощью языка SQL.

Читайте также:
Что такое SQL: как устроен, зачем нужен и как с ним работать
Неструктурированные данные — это информация, которая не имеет фиксированной структуры. В отличие от табличных данных с чёткими строками и столбцами, она существует в свободной форме: это тексты, изображения, видеоролики, аудиозаписи, посты в социальных сетях и так далее.
Для хранения и анализа таких данных применяют специализированные решения: NoSQL-базы данных, распределённые файловые системы, инструменты обработки естественного языка и алгоритмы машинного обучения.

Частично структурированные данные — это информация с внутренней логикой и разметкой, которая не укладывается в жёсткие табличные рамки. Такие данные содержат теги, ключи или метки, что позволяет легко находить и извлекать нужные элементы. Типичные форматы хранения — JSON и XML, а для эффективной работы с ними применяют NoSQL-базы данных.
Как работают с большими данными
Работа с big data — это процесс превращения массивов информации в конкретные решения. Например, результатом может стать изменение ассортимента товаров или обновление правил блокировки банковских карт после подозрительных транзакций. Для этого данные проходят цикл, включающий их сбор, хранение, обработку, анализ и использование. Рассмотрим каждый этап по порядку на примере работы маркетплейса.
Сбор данных
У маркетплейса десятки источников данных: клики на сайте, действия в мобильном приложении, остатки на складах, оценки и отзывы, поисковые запросы, упоминания в соцсетях и так далее. Эта информация поступает в разном формате и с разной скоростью, поэтому её необходимо привести к единому стандарту и объединить в общую систему.
Для этого используют технологии потоковой передачи данных — например, Apache Kafka. Они превращают разрозненные «ручейки» информации в единый поток, с которым можно работать дальше: хранить, обрабатывать и анализировать.
Хранение данных
Обычный жёсткий диск с большими данными не справится. Поэтому для big data используют распределённые файловые системы — например, HDFS.
Идея проста: большой файл разбивается на части, а части хранятся на разных серверах, объединённых в кластер. Данные обязательно дублируются. Если один сервер выходит из строя, информация не теряется: копии лежат на других узлах.

Читайте также:
При работе с big data важно выбрать подход к хранению собранных данных. Он зависит от их типа:
- Структурированные данные — например, историю заказов — размещают в data warehouse. Это упорядоченное хранилище с заранее заданной схемой — как правило, в виде таблицы.
- Неструктурированные данные — необработанные логи, изображения или тексты — отправляют в data lake. В нём они хранятся в исходном виде. Такой подход полезен и в тех случаях, когда требуется сохранить информацию, но сейчас нет свободных ресурсов на её обработку.
- Современный подход — data lakehouse. Это гибридный вариант, который подойдёт для данных как в сыром, так и в структурированном виде.
К концу этапа информация надёжно сохранена и собрана в одном месте — теперь её можно обрабатывать и анализировать.
Обработка данных
Обработка данных включает два подэтапа: очистку и обогащение.
Очистка. В собранных данных могут встречаться опечатки, дубликаты операций, пропущенные значения, расхождения в форматах дат и единиц измерения. Если от них не избавиться, то можно получить искажённые результаты на следующих этапах.
Для очистки данных используется специальные инструменты и алгоритмы. Например, Apache Spark или библиотека Pandas для Python.
Обогащение. После очистки данные расширяют за счёт дополнительных источников, чтобы добавить контекст. Например, маркетплейс может сопоставить историю заказов с погодой в регионе пользователя, календарём праздников или рекламной активностью. Если анализ покажет, что спрос на зонтики стабильно растёт в дождливые дни, эту закономерность можно учитывать в системе рекомендаций и управлении запасами на складах.
Анализ
Это ключевой этап работы с big data. Именно здесь массивы информации превращают в практические выводы и решения.
Для анализа используют распределённые движки обработки — например, Apache Spark. Они позволяют параллельно обрабатывать терабайты информации на кластере серверов и выполнять сложные вычисления за минуты.

Читайте также:
Для поиска закономерностей и связей между данными применяют статистические методы и алгоритмы машинного обучения.
Например, анализируя данные о покупках на маркетплейсе, специалисты могут обнаружить закономерность: покупатели корма для кошек часто покупают пледы для мебели. Это можно использовать для увеличения продаж — показывать карточки пледов на главной странице тем пользователям, у кого в корзину уже добавлен корм.
Использование результатов
Найденные на этапе анализа инсайты превращаются в конкретные действия. К примеру, сайт автоматически меняет порядок товаров в выдаче, а на складе популярные позиции перемещают ближе к зоне отгрузки. Вместе с этим маркетинговый отдел запускает персональные рассылки или корректирует рекламные кампании.
Так большие данные напрямую влияет на продукт и операционные процессы.
Далее цикл замыкается: пользователи реагируют на изменения, их новые действия снова попадают в систему и возвращаются на этап сбора данных.
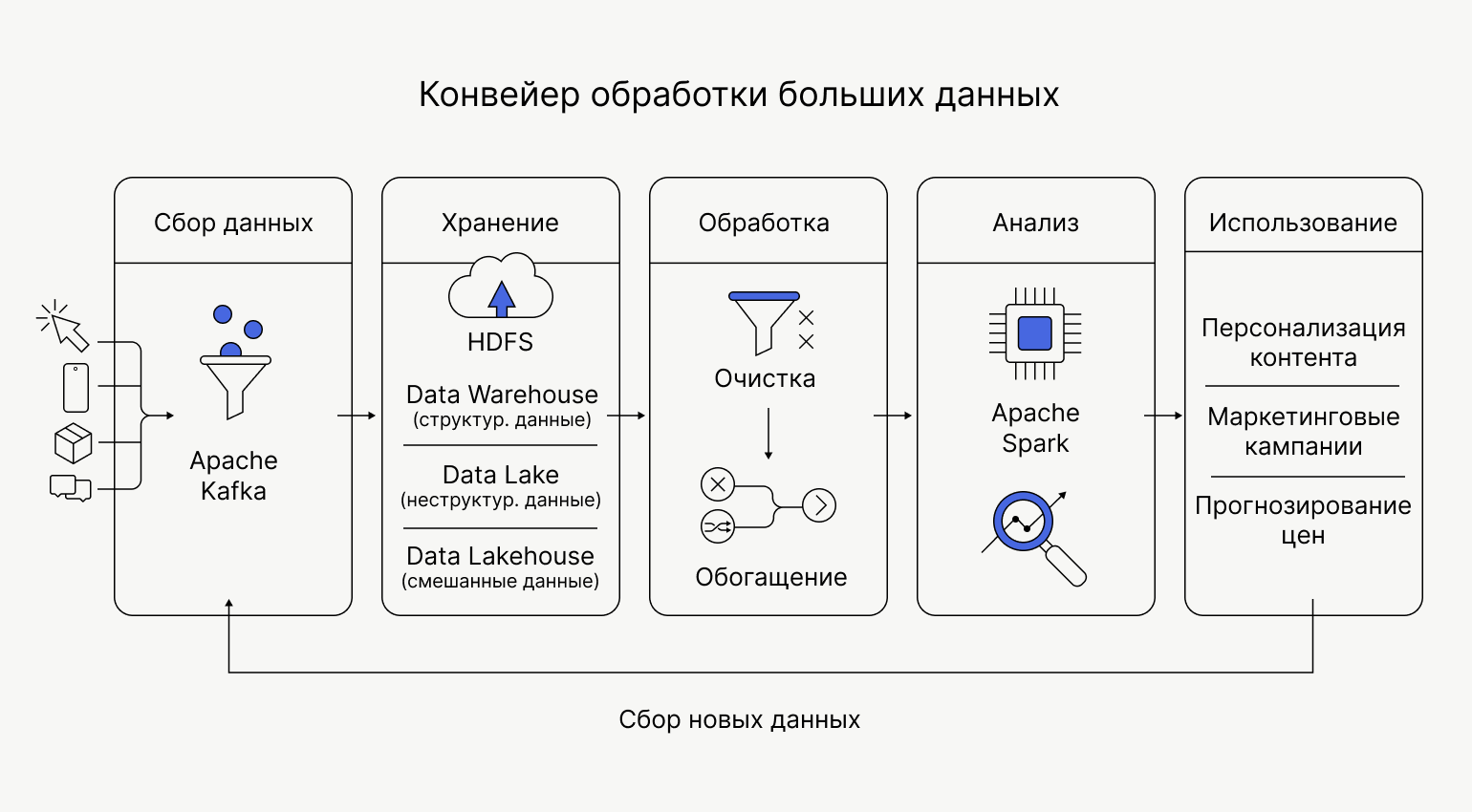
Иллюстрация: Polina Vari для Skillbox Media
Кто работает с большими данными
С big data работают разные специалисты, обеспечивая их сбор, хранение, анализ и использование. Посмотрим на основные профессии.
Дата-инженеры (data engineers) отвечают за инфраструктуру хранения данных. Они настраивают их сбор, проектируют хранилища, пишут ETL-процессы и обеспечивают стабильную работу системы под нагрузкой.
Дата-инженеры работают с языками Python и SQL, фреймворками для big data (Spark, Kafka), облачными хранилищами (Snowflake, BigQuery, ClickHouse) и инструментами управления процессами (Airflow, dbt).

Читайте также:
Дата-сайентисты (data scientists) строят прогнозные модели на основе собранных больших данных. Они используют математику, статистику и машинное обучение, чтобы предсказывать поведение клиентов, спрос на товары, прогноз погоды и так далее.
Дата-сайентисты используют в работе языки программирования (Python, R, SQL), библиотеки для анализа (Pandas, NumPy) и машинного обучения (Scikit-learn, PyTorch, TensorFlow), среды разработки (Jupyter Notebook, VS Code), а также инструменты визуализации (Tableau, Power BI, Matplotlib).

Дата-аналитики (data analysts) ищут в данных закономерности и превращают цифры в понятные выводы для бизнеса. Они анализируют продажи, поведение пользователей, эффективность маркетинга и операционные показатели, формируют отчёты и дашборды, помогают командам принимать решения на основе фактов.
Аналитики данных используют в работе языки программирования (Python, R, SQL), системы бизнес-аналитики (Power BI, Tableau), электронные таблицы (Excel, Google Sheets) и инструменты визуализации (Tableau, Power BI, Matplotlib).

Читайте также:
Анализируем данные с PySpark
Если вы задумываетесь о карьере аналитика данных или дата-сайентиста, попробуйте решить небольшую практическую задачу. Такой тест-драйв позволит оценить интерес и понять, насколько вам подходит эта роль.
Мы не будем разворачивать кластер из сотни серверов, но используем те же инструменты и подходы, которыми пользуются дата-сайентисты и аналитики, — в компактном формате.
Наша задача: проанализировать транзакции интернет-магазина и понять, какие категории товаров приносят больше всего денег. При этом важно учесть возвраты и отмены заказов.
В работе будем использовать Google Colab — это бесплатный облачный сервис для программирования на Python. Он популярен у аналитиков данных и дата-сайентистов, так как позволяет писать код и сразу видеть результаты его выполнения.

Для анализа данных используем PySpark — Python-обёртку над Apache Spark. Она позволяет запускать распределённые вычисления и обрабатывать большие объёмы данных, используя привычный синтаксис Python.
Скачайте на компьютер CSV-файл big_data_sales.csv. В нём 10 000 записей о покупках. В реальной жизни данных было бы в миллионы раз больше, но логика работы в PySpark останется точно такой же.
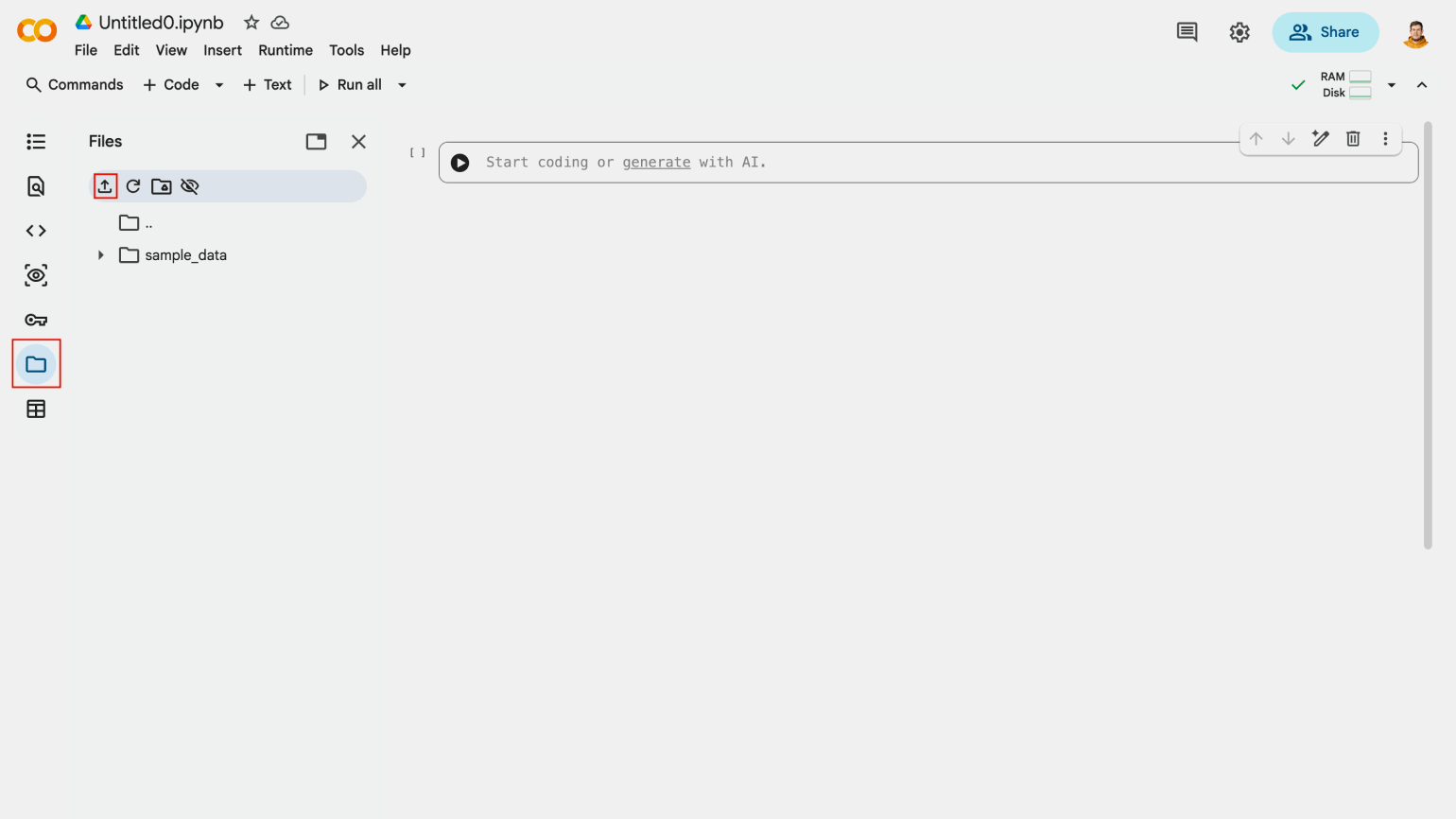
Откройте Google Colab и нажмите кнопку Создать блокнот. Теперь нажмите на значок папки в левом меню и выберите пункт Загрузить в сессионное хранилище, который отмечен иконкой загрузки. Выберите файл с данными big_data_sales.csv.
Скриншот: Google Colab / Skillbox Media
После этого скопируйте в ячейку редактора код:
# 1. Установка библиотеки (если запускаем в первый раз)
!pip install pyspark
# 2. Импорт модулей
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum, desc
# Создаём сессию Spark
spark = SparkSession.builder.appName("BigDataAnalysis").getOrCreate()
# 3. Загрузка данных из CSV-файла
# Мы указываем header=True, чтобы первая строка файла стала заголовками колонок
# inferSchema=True заставляет Spark автоматически определить типы данных (числа, строки)
df = spark.read.csv("big_data_sales.csv", header=True, inferSchema=True)
print("Первые 5 строк загруженных данных:")
df.show(5)
# 4. Анализ данных
# Задача: Найти топ категорий по выручке, исключив возвраты
# Шаг А: Фильтрация
# Оставляем только те строки, где статус не равен 'returned' (возврат) и не равен 'cancelled' (отмена), чтобы считать только реальные продажи
clean_df = df.filter((col("Status") != "returned") & (col("Status") != "cancelled"))
# Шаг Б: Группировка и агрегация
# Группируем по категории и суммируем выручку (Amount)
result_df = clean_df.groupBy("Category").agg(_sum("Amount").alias("Total_Revenue"))
# Шаг В: Сортировка
# Сортируем от большего к меньшему
final_df = result_df.orderBy(desc("Total_Revenue"))
# 5. Вывод результата
print("Топ категорий по выручке (только успешные сдаелки):")
final_df.show()Для запуска кода нажмите кнопку Play слева от ячейки или используйте сочетание клавиш Ctrl + Enter на Windows и Linux либо Cmd + Enter в macOS.
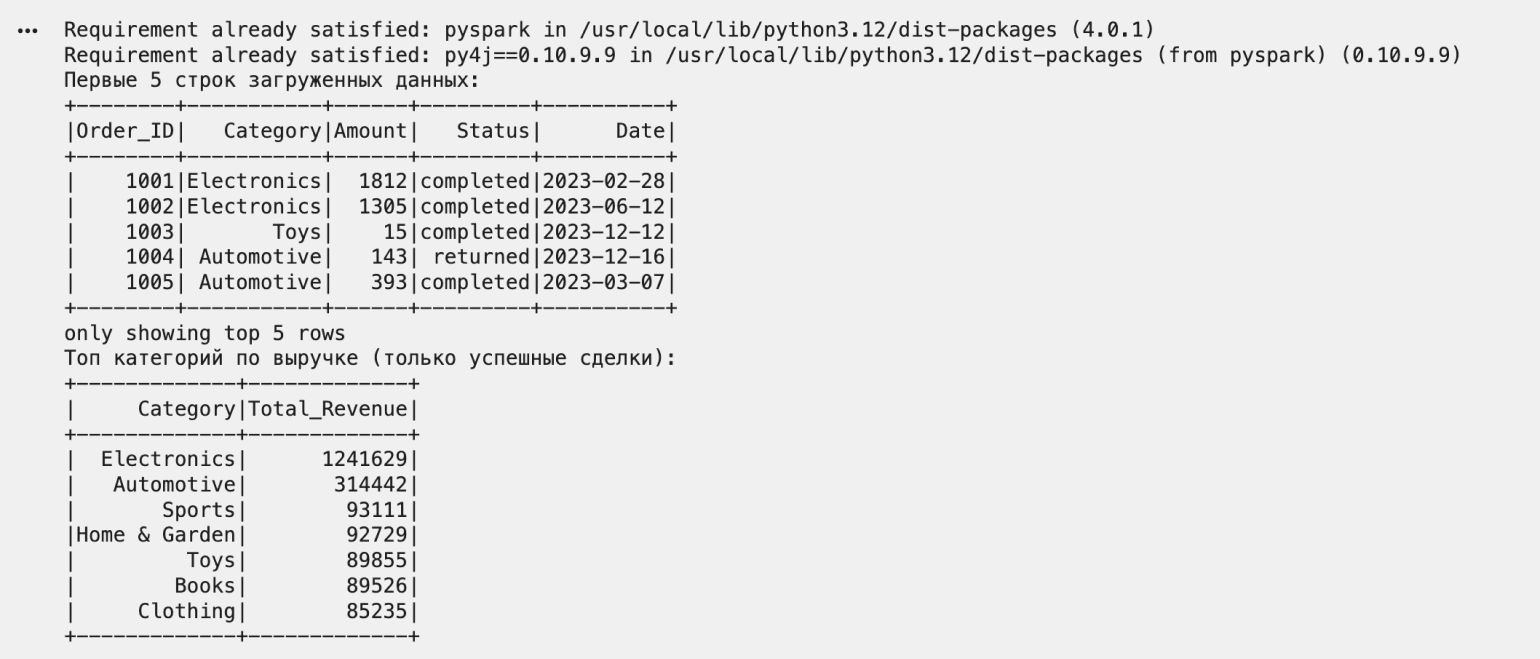
Сначала система потратит несколько секунд на установку PySpark. Затем вы увидите две таблицы: первые пять строк загруженных данных, которые позволяют оценить исходную информацию, и результат анализа, где категории отсортированы от самой прибыльной к наименее прибыльной. При этом будут учтены только реальные продажи, без учёта возвратов и отмен.
Скриншот: Google Colab / Skillbox Media
Поздравляем! Вы только что проанализировали данные тем же инструментом, который используют в Netflix и Uber. Конечно, в меньшем масштабе.
Что дальше
Мир big data огромен, и эта статья — лишь верхушка айсберга. Вот несколько книг, которые помогут погрузиться в мир больших данных.
- «Большие данные», Виктор Майер-Шенбергер и Кеннет Кукьер. Книга объясняет, что такое big data и почему переход от «малых» выборок к анализу массивов изменил экономику и управление.
- «Теоретический минимум по Big Data. Всё, что нужно знать о больших данных», Ын Анналин и Кеннет Су. Книга объясняет, как устроены большие данные — от базовых понятий и архитектуры распределённых систем до инструментов вроде Hadoop и Spark, — а также помогает понять, почему классические подходы к хранению и обработке информации перестают работать при росте объёмов и какие технологии приходят им на смену.
- «Голая статистика», Чарльз Уилан. Доступное введение в статистическое мышление без сложных формул. На практических примерах автор объясняет, как работают корреляции, выборки, вероятности и где чаще всего возникают манипуляции цифрами.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!
Курс с помощью в трудоустройстве

Профессия Data scientist + ИИ
- Реальные задачи от «СберАвтоподписки» и «СберМаркета»
- 8 сильных проектов в портфолио
- Спикеры из VK, ВТБ, «Сбера», Wildberries