Библиотека Requests для Python: код и практика
Разбираемся в методах работы с HTTP-запросами в Python на практике.


Библиотека Requests для Python позволяет работать с HTTP-запросами любого уровня сложности, используя простой синтаксис. Это помогает не тратить время на написание кода, а быстро взаимодействовать с серверами.
Почему стоит выбрать Requests?
Python Requests — это библиотека, которая создана для быстрой и простой работы с запросами. Стандартные HTTP-библиотеки Python, например та же Urllib3, часто требуют значительно больше кода для выполнения одного и того же действия, а это затрудняет работу. Давайте сравним код для простой задачи, написанный с помощью Urllib3 и Requests.
Urllib3:
import urllib3
http = urllib3.PoolManager()
gh_url = 'https://api.github.com'
headers = urllib3.util.make_headers(user_agent= 'my-agent/1.0.1', basic_auth='abc:xyz')
requ = http.request('GET', gh_url, headers=headers)
print (requ.headers)
print(requ.data)
# ------# 200# 'application/json'
Requests:
import requests
r = requests.get('https://api.github.com', auth=('user', 'pass'))
print r.status_codeprint r.headers['content-type']
# ------# 200# 'application/json'
Количество строк различается в два раза: на Urllib3 — восемь строк, а на Requests — четыре. И это только один небольшой запрос.
Устанавливаем библиотеку
Писать код на Python лучше всего в специальной IDE, например в PyCharm или Visual Studio Code. Они подсвечивают синтаксис и предлагают автодополнение кода — это сильно упрощает работу программиста. Весь код из этой статьи мы писали в Visual Studio Code.
Для начала работы с библиотекой Requests её необходимо установить в IDE. Для этого откройте IDE и введите команду в терминале:
pip install requestsБиблиотека готова к работе. Остаётся только импортировать её:
import requestsИспользуем метод GET
Из всех HTTP-запросов наиболее часто используется GET. Он позволяет получить данные из указанного источника — обычно с какого-то веб-сайта. Чтобы отправить GET-запрос, используется метод requests.get(), в который в качестве параметра добавляется URL-адрес назначения:
requests.get('https://skillbox.ru')Этот код совершает одно действие — связывается с указанным адресом и получает от сервера информацию о нём. Когда вы вводите домен в адресную строку браузера и переходите на сайт, под капотом выполняются те же самые операции. Единственное различие в том, что Requests позволяет получить чистый HTML-код страницы без рендеринга, то есть мы не видим вёрстку и разные визуальные компоненты — только код и техническую информацию.
Для проверки ответа на запрос существуют специальные НТТР-коды состояния. Чтобы воспользоваться ими, необходимо присвоить запрос переменной и «распечатать» её значение:
res = requests.get('https://skillbox.ru') # Создаём переменную, в которую сохраним код состояния запрашиваемой страницы.
print(res) # Выводим код состояния.Если запустить этот код, то в терминале выведется <Response [200]>. Это хороший результат — значит, запрос прошёл успешно. Но бывают и другие HTTP-коды состояний.
HTTP-коды состояний
Коды состояний имеют вид трёхзначных чисел от 100 до 500. Чаще всего встречаются следующие:
- 200 — «OK». Запрос прошёл успешно, и мы получили ответ.
- 400 — «Плохой запрос». Его получаем тогда, когда сервер не может понять запрос, отправленный клиентом. Как правило, это указывает на неправильный синтаксис запроса, неправильное оформление сообщения запроса и так далее.
- 401 — «Unauthorized». Для выполнения запроса необходимы актуальные учётные данные.
- 403 — «Forbidden». Сервер понял запрос, но не может его выполнить. Например, у используемой учётной записи нет достаточных прав для просмотра содержимого.
- 404 — «Не найдено». Сервер не нашёл содержимого, соответствующего запросу.
Кодов состояния намного больше. С полным списком можно ознакомиться здесь.
Получаем содержимое страницы
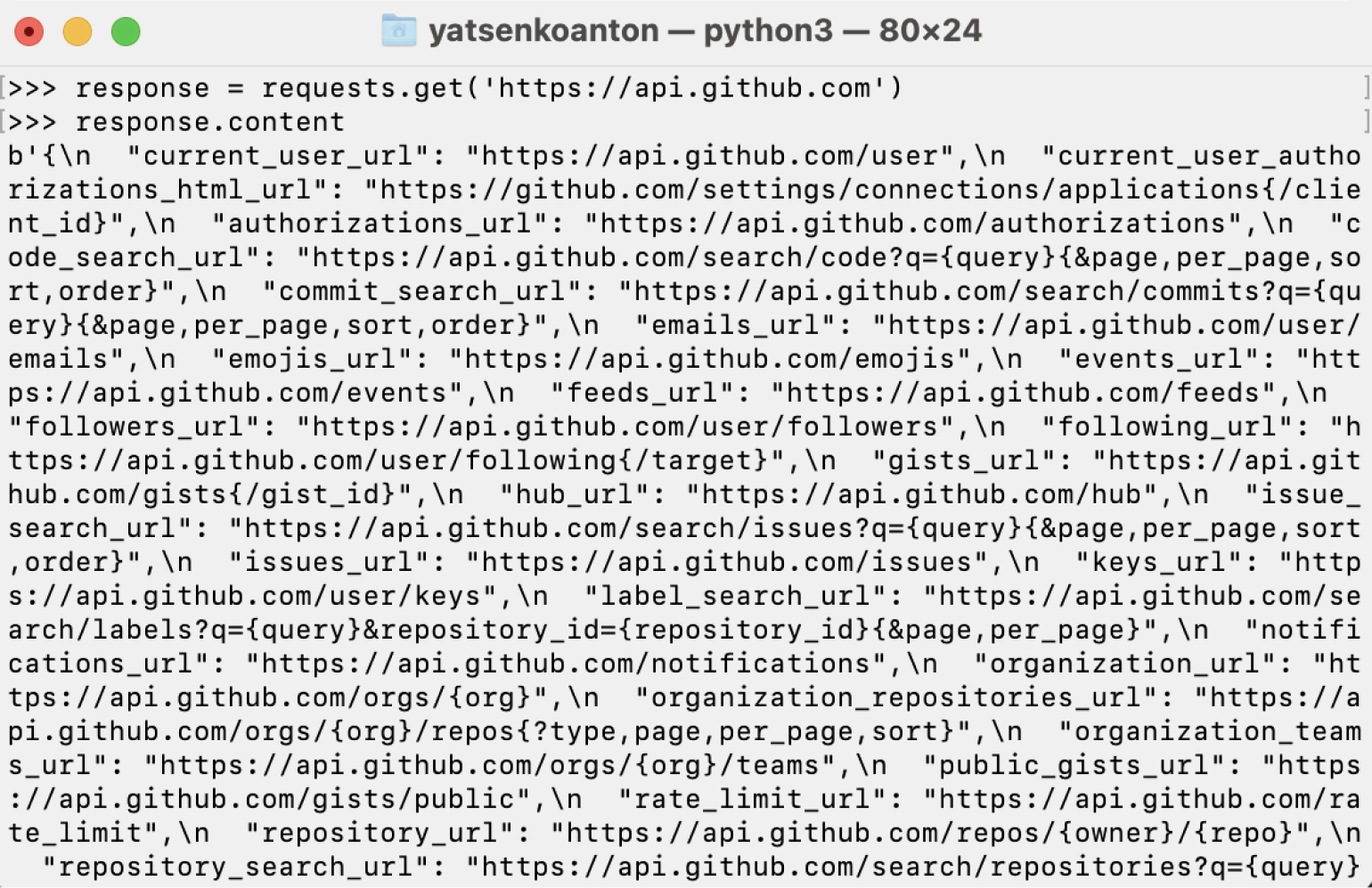
Для получения содержимого страницы используется метод content. Он позволяет получить информацию в виде байтов, то есть в итоге у нас будет вся информация, не только строковая. Запустим его и посмотрим на результат:
response = requests.get('https://api.github.com')
response.content
Ответ:
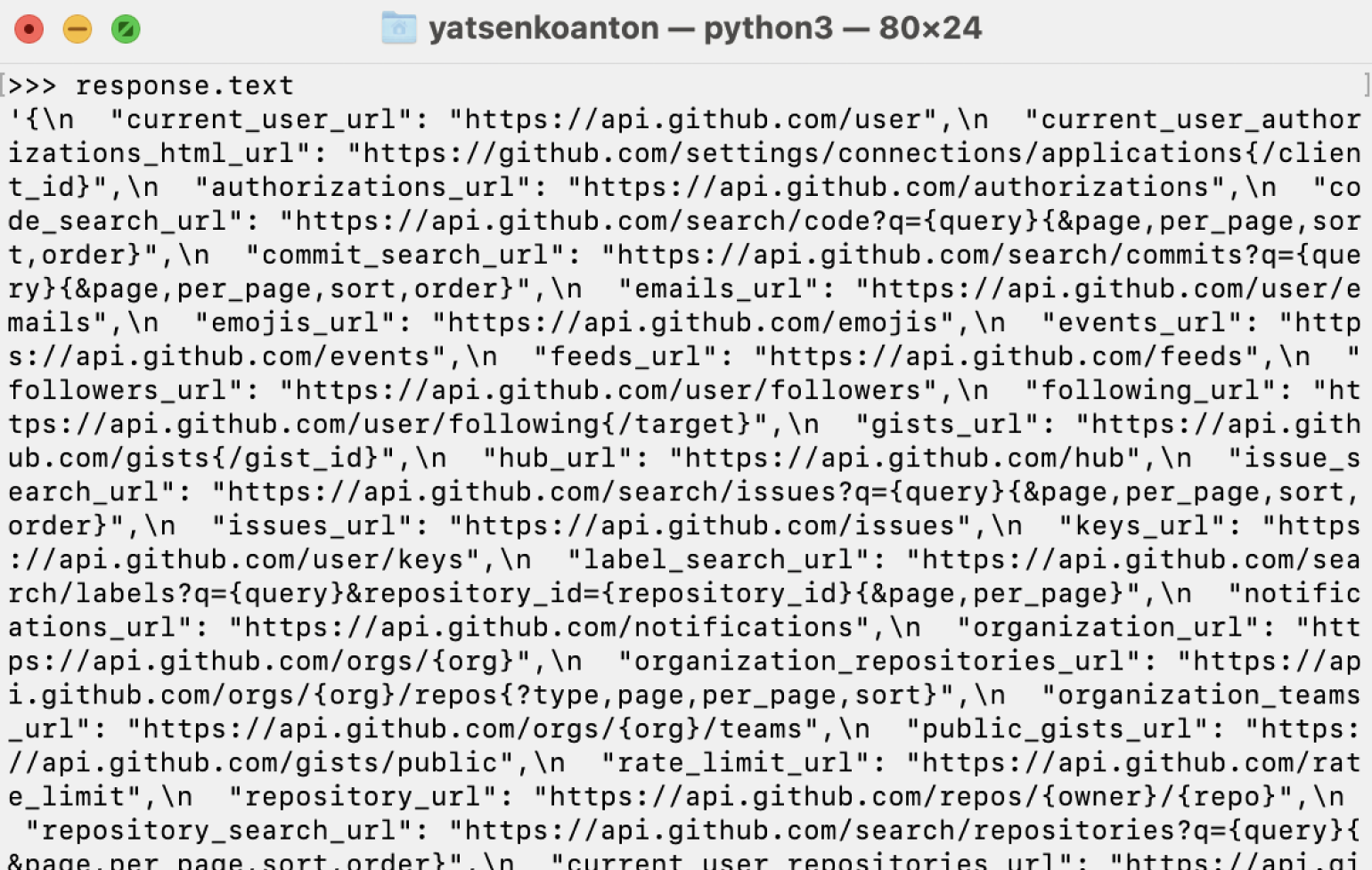
Информацию из байтового вида в строковый можно декодировать с помощью метода text:
response = requests.get('https://api.github.com')
response.text
Ответ:
В обоих случаях мы получаем классический JSON-текст, который можно использовать как словарь, получая доступ к нужным значениям по известному ключу.
HTTP-заголовки в ответе
Заголовки ответа — важная часть запроса. Хотя в них и нет содержимого исходного сообщения, зато там можно обнаружить множество важных деталей ответа: информация о сервере, дата, кодировка и так далее. Для работы с ними используется метод headers:
print(response.headers)
Ответ:
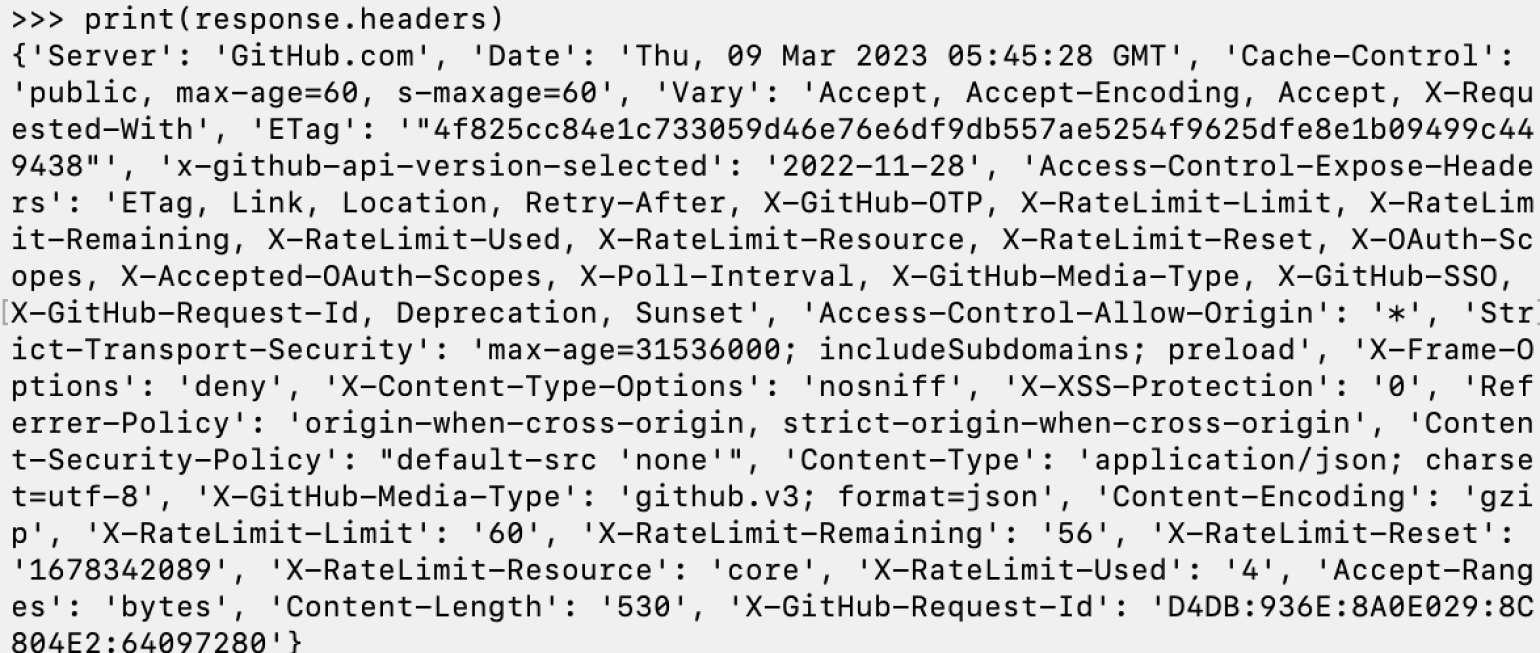
Зачем это надо? Например, таким образом мы можем узнать дату и время на сервере в момент получения запроса. В нашем случае ответ пришёл 9 марта в 05:45:28 GMT. Это помогает логировать действия для их последующей оценки, например, при поиске ошибок выполнения.
HTTP-методы в Python
| Метод | Описание |
|---|---|
| GET | GET-метод используется для обычного запроса к серверу и получения информации по URL. |
| POST | Метод запроса POST запрашивает веб-сервис для приёма данных, например для хранения информации. |
| PUT | Метод PUT просит, чтобы вложенный в него объект был сохранён под определённым URI. Если URI ссылается на уже существующий ресурс, он модифицируется, а если URI указывает на несуществующий ресурс, сервер может создать новый ресурс с этим URI. |
| DELETE | Метод DELETE удаляет объект с сервера. |
| HEAD | Метод HEAD запрашивает ответ, идентичный запросу GET, но без тела ответа. |
| PATCH | Метод используется для модификации информации на сервере. |
Подробнее о методах можно прочитать в официальной документации.
Python Requests: параметры запроса
Запрос GET можно настроить с помощью передачи параметров в методе params. Посмотрим, как это работает на простом примере — попробуем найти изображение на фотостоке Pixabay.
Для начала создадим переменную, которая будет содержать необходимые нам параметры:
query = {'q': 'Forest', 'order': 'popular', 'min_width': '1000', 'min_height': '800'}Наш запрос для поиска изображений на стоке Pixabay представлен словарём, где:
- q — передаём ключевые слова для поиска;
- order — порядок фильтрации поиска, в нашем случае — по популярности;
- min_width и min_height — минимальная ширина и высота соответственно.
Напишем запрос и посмотрим на результат выполнения:
req = requests.get('<a
href="https://pixabay.com/en/photos/">https://pixabay.com/en/photos/</a>', params=query)
req.url
В ответе мы получим ссылку с нужными параметрами запроса:
'<a href="https://pixabay.com/en/photos/?order=popular_height=800&q=Forest&min_width=1000">https://pixabay.com/en/photos/?order=popular_height=800&q=Forest&min_width=1000</a>'
Откроём её в браузере:
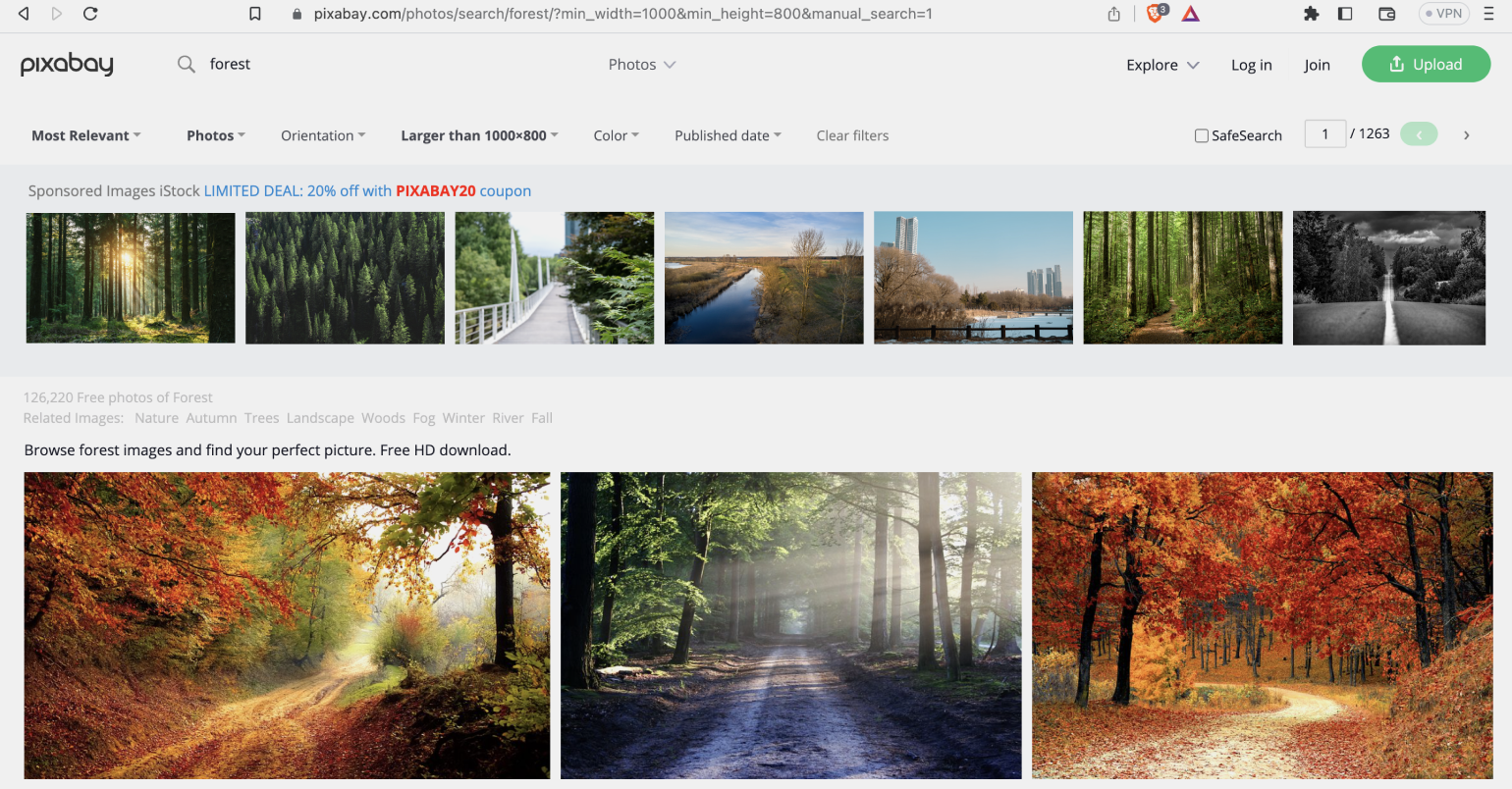
Всё получилось. У нас правильно настроена сортировка и размеры изображений.
Requests и аутентификация HTTP
Аутентификацию используют в тех случаях, когда сервис должен понять, кто вы. Например, это часто необходимо при работе с API. Аутентификация в библиотеке Requests очень простая — для этого достаточно использовать параметр с именем auth. Попробуем написать код для доступа к API GitHub. Для него вам потребуются данные учётной записи на сервисе — логин и пароль. Поставьте их в нужные места кода:
from getpass import getpass # Импортируем метод getpass из одноимённой библиотеки для ввода пароля доступа.
requests.get('https://api.github.com/user', auth=('username', getpass())При запуске кода вам будет необходимо ввести пароль от своего профиля. Если пароль правильный, вернётся ответ 200, если нет — 401.
Работа с SSL-сертификатами в Requests
SSL-сертификат указывает на то, что установленное через HTTP соединение безопасно и зашифровано. Важно, что библиотека Requests не только умеет работать с SSL-сертификатами «из коробки», но и позволяет настраивать взаимодействие с ними. Для примера отключим проверку SSL-сертификата, передав параметру функции запроса verify значение False:
requests.get('https://api.github.com', verify=False)Ответ:

Мы видим, что ответ на запрос содержит предупреждение о неверифицированном сертификате. Всё дело в том, что мы отключили его получение вручную в коде выше с помощью функции verify.
Контролируем выполнение запросов с помощью класса Session
Метод GET позволяет работать с запросами на высоком уровне абстракции, не разбираясь в деталях их выполнения, при этом надо настроить лишь базовые параметры.
Однако возможности библиотеки Requests на этом не заканчиваются: с помощью класса Session мы можем контролировать выполнение запросов и увеличивать скорость их выполнения.
Класс Session позволяет создавать сеансы — базовые запросы с сохранёнными параметрами (то есть без повторного указания параметров).
Напишем код для простой сессии, позволяющей получить доступ к GitHub:
import requests
from getpass import getpass
with requests.Session() as session:
session.auth = ('login', getpass())
response = session.get('https://api.github.com/user')
# Выведем ответ на экран.
print(response.headers)
print(response.json())Запустим его и введём пароль. Как видим, всё сработало:

Запрос возвращает информацию с сервера при этом работает с помощью session. То есть теперь нам не придётся вводить повторные параметры авторизации при следующих запросах.
Что дальше?
Библиотека Requests — простой инструмент для работы с HTTP-запросами разного уровня сложности. Рекомендуем подробно изучить возможности библиотеки, методы и примеры их использования в официальной документации.

