Нейросети неидеальны. Разбираем 5 нюансов, которые точно нужно знать
Почему ИИ галлюцинирует, додумывает и игнорирует инструкции — и что с этим делать.


Нейросети для многих стали привычным инструментом — быстрым, удобным и действительно полезным. Но чем дольше специалисты работают с ИИ, тем чаще замечают, что нейросети далеки от идеала.
Во время подготовки этой статьи мы поговорили с экспертами из разных сфер. Многие из них говорят об одних и тех же проблемах ИИ, но каждый видит и формулирует их через свою профессиональную оптику: кто-то сталкивается с потерей контекста, кто-то — с выдуманными цифрами и источниками, а кто-то — с неожиданными интерпретациями в творческих задачах. Это не отменяет ценности нейросетей, но показывает, что они требуют осознанного подхода.
В этом материале редакции «Маркетинг» Skillbox Media мы собрали типичные ошибки нейросетей, с которыми сталкиваются практики, и сформулировали выводы, которые помогут использовать ИИ эффективнее и безопаснее.
- Нейросети галлюцинируют
- Придумывают цифры и факты
- Додумывают смыслы
- Игнорируют прямые инструкции
- Забывают требования спустя время
Нейросети галлюцинируют — уверенно выдают выдумку за факт

Тимур Угулава
Совладелец digital-агентства «Медиасфера», эксперт «Яндекса» по обучению, нейроактивист и автор телеграм-канала «Тимур Угулава»
— В работе с нейросетями я постоянно сталкиваюсь с галлюцинациями, когда модель с уверенным видом сообщает ерунду как проверенный факт. Особенно часто это происходит на больших объёмах данных и длинных текстах.
Нейросеть не «знает» информацию в человеческом смысле — она предсказывает, какое слово должно быть следующим. Если в обучающих данных есть пробелы или противоречия, модель заполняет их вероятностной выдумкой — и делает это максимально убедительно.
Например, ИИ придумывает несуществующую статистику, ссылается на исследования, которых нет, смешивает реальные факты со своими догадками или создаёт «экспертные мнения» от вымышленных людей.
Я выделяю три причины, почему появляются подобные галлюцинации:
- Пробелы в данных — если точного ответа нет, модель угадывает.
- Конфликтующие источники — в интернете много противоречий, а модель не отличает правду от ошибки и усредняет версии.
- Шаблоны — нейросеть запоминает структуры вроде «исследование показало…» и воспроизводит их даже без реального исследования.
Такие галлюцинации особенно опасны там, где высока цена ошибки. Например, в медицине и праве, в статистике и финансах. Осторожность также нужна в узкоспециализированных технических темах, где модели уверенно ошибаются из-за нехватки контекста.
Что с этим делать? Главный принцип работы с нейросетями — не доверяй, а проверяй. ИИ хорошо помогает с черновиками, структурой и скоростью, но ответственность за итог всегда на человеке. В работе с нейросетями я использую три «слоя защиты»:
- Слой 1 — промпт: прошу нейросеть отвечать только на основе предоставленных данных и прямо писать, если информации нет.
- Слой 2 — перекрёстная проверка: все факты, цифры и ссылки перепроверяю через независимые источники и собственный опыт, особенно перед публикацией.
- Слой 3 — промпт для глубокого фактчекинга: я придумал отдельный запрос, который заставляет модель критически пройтись по тезисам и отметить сомнительные места.
Изображение: Тимур Угулава
Галлюцинации — скорее особенность нейросетей, чем случайный сбой. С ними можно работать эффективно, если держать в голове простую мысль: помимо электромозга нужен ещё и мозг пользователя.
Придумывают цифры и ссылки в исследованиях

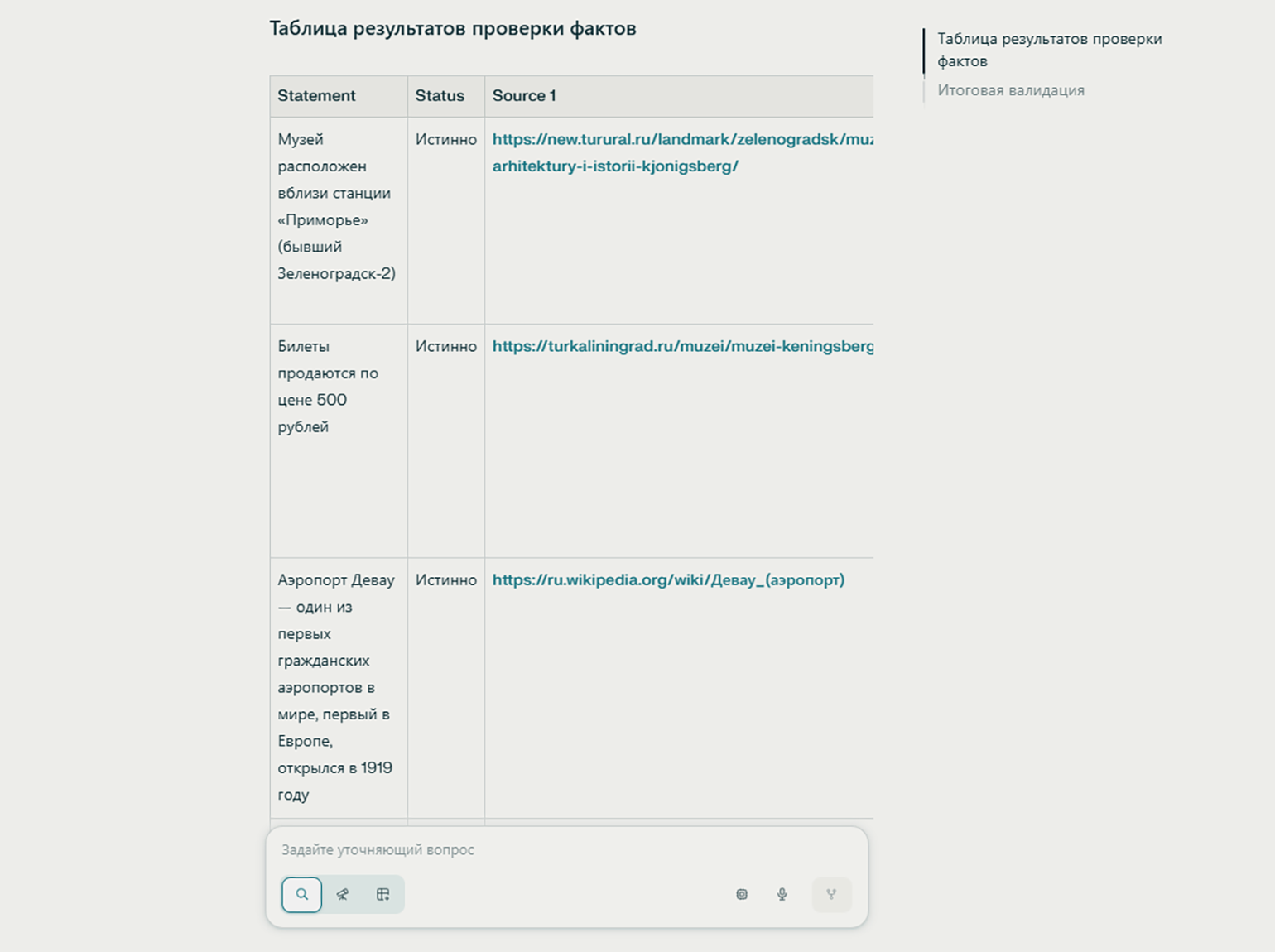
— Я чаще всего использую нейросети для поиска информации и исследовательских задач. И регулярно вижу одну проблему: LLM могут увлечься и начать приводить «факты» с цифрами и даже ссылками на исследования, которых на самом деле нет.
Например, ищешь, какой процент сотрудников крупных компаний применяли в работе AI-редакторы текста, и получаешь точные проценты — хотя никто такие данные не замерял. Начинаешь проверять и понимаешь: это не статистика из отчёта, а вывод самой нейросети, к которому она просто дорисовала цифры.
Что с этим делать. Ошибки проще не ловить вручную, а предотвращать настройками и тестами — так, чтобы нейросеть не могла уйти в общие формулировки.
Один из рабочих подходов — Structured Output. Это функция в работе с LLM, которая заставляет ИИ отвечать по заданной структуре: например, отдельно выдавать факты, цифры и источники. Но и это не гарантирует, что число или формулировка будут корректно перенесены из первоисточника. Поэтому в критичных задачах нужны ручные проверки, чтобы убедиться, что данные совпадают с документом-источником.
Если проект сложный и в нём много деталей, нейросеть может не уловить логику целиком. В таких задачах помогает такой подход: сначала просим модель расписать путь, функции и логику работы, а уже потом — делать выводы.
В итоге самый надёжный способ не пропустить ошибку — закладывать в процесс перепроверку результата: настраивать проверки на уровне структуры ответа и дополнительно просматривать результат вручную перед тем, как использовать данные в работе.
Додумывают смыслы в творчестве и могут увести результат в неожиданное русло

— Генеративный ИИ в творчестве я активно использую с лета 2022 года. Только в Midjourney, которую считаю лучшей графической нейросетью, у меня больше 70 тысяч сгенерированных картинок. По моему опыту, графические, музыкальные и видеонейросети — это в какой-то степени лотерея: чем лучше вы понимаете сервис и чем точнее описываете то, что хотите увидеть, тем выше шанс получить нужный результат.
Это хорошо заметно на абстрактных словах. Если ввести в запрос просто love, нейросеть вероятнее всего покажет влюблённые пары: она выбирает самый распространённый и средний смысл. Но любовь может означать что угодно: любовь к родителям, профессии, стране, и у каждого человека за этим стоят разные образы.
В таких случаях без подробного запроса не обойтись, иначе модель подставит своё обобщённое представление. При этом перегружать запрос деталями тоже не стоит: даже продвинутые нейросети плохо справляются с большим количеством смыслов и объектов одновременно и начинают терять композицию.
Однажды такая особенность проявилась очень наглядно. Мы с командой делали карточную игру для медиков в духе «Имаджинариума», и мне нужно было сгенерировать гемартроз — это скопление крови в полости сустава. Я попробовал общий запрос, рассчитывая на медицинскую иллюстрацию, но вместо этого получил красивый дарк-арт.

Изображение: Максим Мельников / Midjourney
У нейросети, судя по всему, не было чёткого «знания» редкого термина, но она уловила общие ассоциации — «медицина + кровь» — и начала додумывать, трактуя запрос скорее как художественный образ. В результате картинка получилась эффектной, но не соответствующей задаче.
Что с этим делать. В зависимости от ситуации можно пробовать простой или подробный подход к запросу — или оба сразу, если позволяет тарифный план.
Простой запрос подходит, если вам нужны идеи, вариативность и своего рода магия интерпретации. Такой запрос:
- задаёт лишь общее направление;
- даёт больше неожиданных деталей;
- чаще уводит в сторону, если слово или выражение абстрактное или редкое.
Подробный запрос лучше использовать, если нужен предсказуемый результат и минимум додумываний. Он особенно полезен для сложных терминов и узких тем. В этом случае важно:
- подробно уточнять, что именно вы имеете в виду;
- задавать контекст и ограничения.
Если задача точная, как в кейсе с гемартрозом, лучше не оставлять нейросеть догадываться, а сразу объяснять контекст и желаемую визуальную трактовку — иначе модель легко превратит термин в художественную фантазию.
Игнорируют прямые инструкции

— Нейросети могут «не услышать» простое и понятное ТЗ. Вы просите выполнить пять пунктов, а модель делает четыре и как будто забывает про пятый. Чем больше информации попадает в контекстное окно, тем выше вероятность, что часть данных ИИ проигнорирует, потеряет или исказит.
Что с этим делать:
- Создавать новый чат под каждую новую задачу, а не вести всё в одном бесконечном диалоге.
- Не забивать контекст лишним — например, эмоциональными репликами вроде: «Я уже 500 раз это говорил!» Это не улучшает результат, но увеличивает вероятность ошибок.
- Разбивать большие задачи на маленькие шаги, и для каждого шага давать отдельную инструкцию, в идеале — даже маленькие шаги обсуждать в отдельном диалоге.
- Собирать ключевую информацию по проекту в отдельный документ и прикладывать его к каждому новому чату в качестве короткого онбординга с самым важным.
Вот как можно дробить задачи на примере запроса про SEO-текст. Вместо просьбы «Напиши весь SEO-текст целиком» лучше идти по этапам. Сначала попросите нейросеть собрать семантику, затем — собрать фактуру, далее — составить тезисный план, написать первый раздел, второй, третий и так далее.
Забывают заданные требования спустя время

Дарья Чепурнова
Шеф-редактор направлений «Маркетинг», «Управление», «Бизнес» и «Деньги» в Skillbox Media и автор телеграм-канала «Даша шеф-рыдачит»
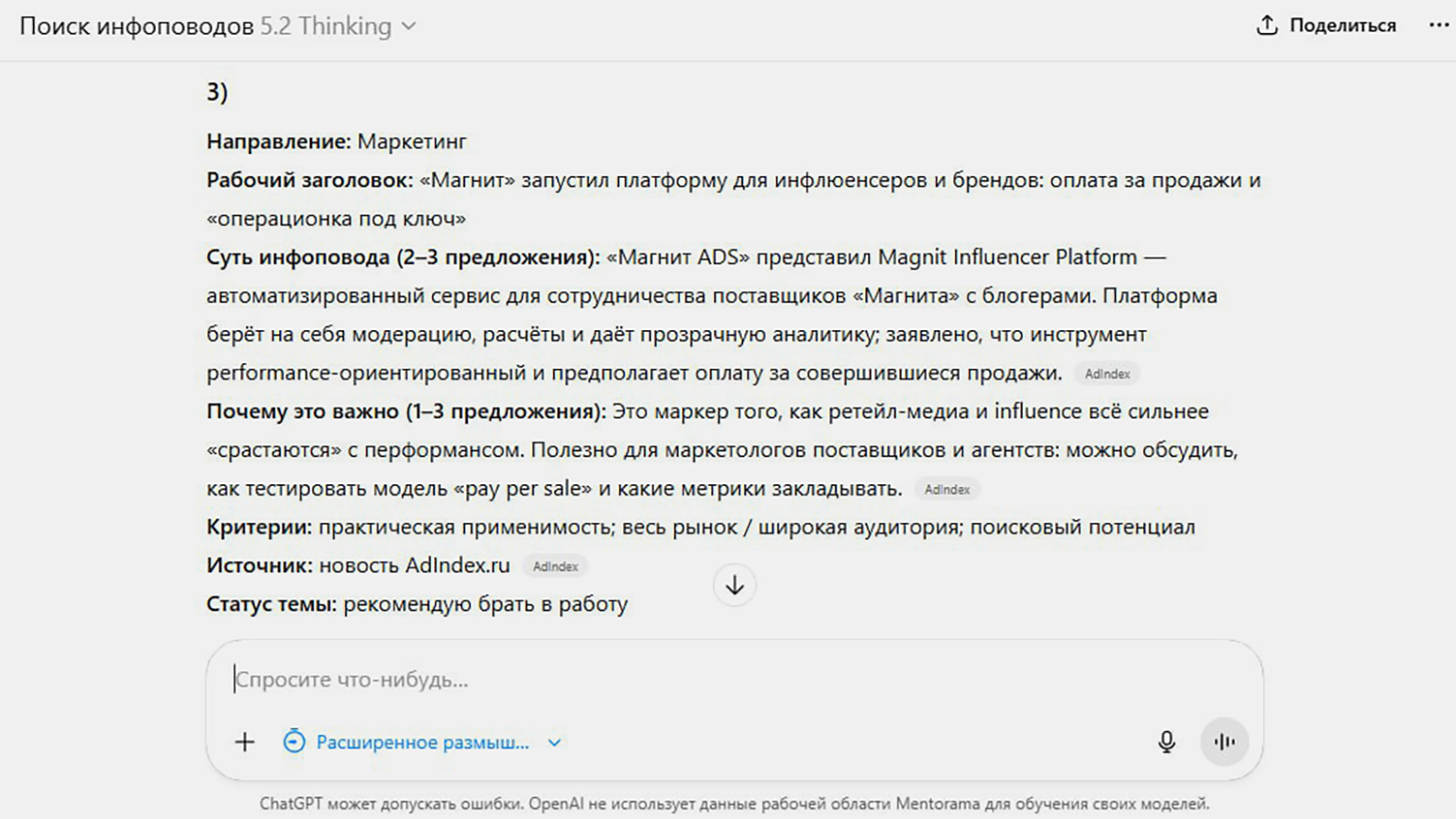
— В работе я использую несколько агентов ChatGPT под разные задачи. И почти все они регулярно забывают требования, которые я задала в начале. Из-за этого результат оказывается не совсем тем, который нужен.
Например, один из агентов анализирует медиапространство и предлагает инфоповоды для редакции. У него есть чёткий запрет: не приносить новости о том, что очередной бренд запустил очередной продукт. Я прямо прописывала это ограничение в чате и отдельно напоминала о нём в обратной связи. Агент соглашался, но спустя несколько дней снова начинал предлагать такие инфоповоды.
Изображение: Дарья Чепурнова
Часто проблема возникает из-за слишком сложных и перегруженных инструкций. Если попросить человека выполнить задачу по чек-листу из ста пунктов, он с высокой вероятностью пропустит часть требований. С нейросетями работает тот же принцип: чем больше условий, тем выше риск, что некоторые из них будут проигнорированы.
Что с этим делать? Если нейросеть регулярно нарушает правила, попробуйте сократить промпт или инструкцию. Оставьте только ключевые требования — так модель будет реже терять фокус и начнёт выдавать более точный результат.
Ещё 5 статей про нейросети от Skillbox Media
- Что за зверь этот ваш вайбкодинг и зачем он маркетологу
- Смириться нельзя бороться: что делать с обрушением трафика из-за ИИ
- Маркировка ИИ-контента не за горами? Обсуждаем с участниками рынка
- Ищем работу с помощью нейросетей: советы и промпты со скриншотами ответов
- Как я заменил сотрудников нейросетями: личный опыт фаундера контент-агентства









