Java Stream API. Копилка рецептов
Если вы не любите стримы, возможно, вы пока не умеете их готовить :) Приглашаем поучиться.


В этой статье почти нет теории, зато много практики и кода. Разберём семь типичных ситуаций, когда стримы бывают полезны. Сравним решения с классическими императивными реализациями.
Stream API — что это вообще такое
Это способ работать со структурами данных Java, чаще всего коллекциями, в стиле функциональных языков программирования.
О началах функционального программирования и лямбдах в Java читайте здесь.
Стрим — это объект для универсальной работы с данными. И это вовсе не какая-то новая структура данных, он использует существующие коллекции для получения новых элементов.
Затем к данным применяются методы. В интерфейсе Stream их множество. Каждый выполняет одну из типичных операций с коллекцией: отсортировать, перегруппировать, отфильтровать. Мы разберём некоторые из этих методов дальше.
Думайте о стриме как о потоке данных, а о цепочке вызовов методов — как о конвейере.
Каждый промежуточный метод получает на вход результат выполнения с предыдущего этапа (стрим), отвечает только за свою часть работы и возвращает стрим.
Последний (терминальный) метод либо не возвращает значения (void), либо возвращает результат иного, нежели стрим, типа.
Преимущества
Стримы избавляют программистов от написания стереотипного кода всякий раз, когда нужно сделать что-то с набором элементов. То есть благодаря стримам не приходится думать о деталях реализации.
Есть и другие плюсы:
- Стримы поддерживают один из основных принципов хорошего проектирования — слабую связанность (low coupling). Чем меньше класс знает про другие классы — тем лучше. Алгоритму сортировки не должно быть важно, что конкретно он сортирует. Это и делают стримы.
- С помощью стримов операции с коллекциями проще распараллелить: в императивном подходе для этого бы понадобился минимум ещё один цикл.
- Стримы позволяют уменьшить число побочных эффектов: методы Stream API не меняют исходные коллекции.
- Со Stream API лаконично записываются сложные алгоритмы обработки данных.
А теперь, когда вы почти поверили, что стримы — это хорошо, перейдём к практике.
Подготовим данные
Работу методов Java Stream API покажем на примере офлайновой библиотеки. Для каждой книги библиотечного фонда известны автор, название и год издания.
Для читателя библиотеки будем хранить ФИО и электронный адрес. Каждый читатель может взять в библиотеке одну или несколько книг — их тоже сохраним.
Ещё нам понадобится флаг читательского согласия на уведомления по электронной почте. Рассылки организуют сотрудники библиотеки: напоминают о сроке возврата книг, сообщают новости.
Вот как это выглядит на Java:
import java.util.Objects;
public class Book {
private String author; //Автор
private String name; //Название
private Integer issueYear; //Год издания
public Book(String author, String name, Integer issueYear) {
this.author = author;
this.name = name;
this.issueYear = issueYear;
}
public String getAuthor() {
return author;
}
public String getName() {
return name;
}
public Integer getIssueYear() {
return issueYear;
}
@Override
public String toString() {
return "Book{" +
"author='" + author + '\'' +
", name='" + name + '\'' +
", issueYear=" + issueYear +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Book book = (Book) o;
return author.equals(book.author) &&
name.equals(book.name) &&
issueYear.equals(book.issueYear);
}
@Override
public int hashCode() {
return Objects.hash(author, name, issueYear);
}
}import java.util.ArrayList;
import java.util.List;
public class Reader {
private String fio; //ФИО
private String email; //электронный адрес
private boolean subscriber; //флаг согласия на рассылку
private List<Book> books; //взятые книги
public Reader(String fio, String email, boolean subscriber) {
this.fio = fio;
this.email = email;
this.subscriber = subscriber;
this.books = new ArrayList<>();
}
public boolean isSubscriber() {
return subscriber;
}
public String getFio() {
return fio;
}
public String getEmail() {
return email;
}
public List<Book> getBooks() {
return books;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
Reader reader = (Reader) o;
return fio.equals(reader.fio);
}
@Override
public int hashCode() {
return Objects.hash(fio);
}
}
public class EmailAddress {
private String email; //электронный адрес
private String someData; /*доп. информация для формирования письма. В примерах не используем — добавили, чтобы оправдать существование отдельного класса :)*/
public EmailAddress(String email) {
this.email = email;
}
public String getEmail() {
return email;
}
public String getSomeData() {
return someData;
}
public void setSomeData(String someData) {
this.someData = someData;
}
}import java.util.ArrayList;
import java.util.List;
public class Library {
private List<Book> books;
private List<Reader> readers;
public Library() {
init();
}
private void init() {
books = new ArrayList<>();
books.add(new Book("Оруэлл", "1984", 2021));
//и так далее для других книг
readers = new ArrayList<>();
readers.add(new Reader("Иванов Иван Иванович", "ivanov.email@test.ru", true));
//и так далее для других читателей
readers.get(0).getBooks().add(books.get(1));
//и так далее для других читателей и взятых книг
}
public List<Book> getBooks() {
return books;
}
public List<Reader> getReaders() {
return readers;
}
}Для сортировки — sorted()
Этот метод используется для сортировки элементов стрима. По умолчанию применяется сортировка по возрастанию (с числами всё понятно, а вот заглавные и строчные буквы рассматриваются отдельно).
Примечание. Метод подходит только для сортировки объектов, которые реализуют интерфейс Comparable.
Если же классы наших объектов не реализуют этот интерфейс или нужна иная логика сортировки, то можно передать в качестве аргумента свой алгоритм сравнения элементов.
В результате работы метода получается новый стрим.
Задача
Получить список всех книг библиотеки, отсортированных по году издания.
Без лямбд
У интерфейса List есть метод для сортировки — sort(). В него тоже можно передать алгоритм сравнения. До появления лямбд для этого создавали свои классы, реализующие интерфейс Comparator, или анонимные классы:
public static List<Book> doWithoutLambda(List<Book> books) {
books.sort(new Comparator<Book>() {
@Override
public int compare(Book o1, Book o2) {
return o1.getIssueYear().compareTo(o2.getIssueYear());
}
});
return books;
}Метод sort() не возвращает результат, он преобразует исходную коллекцию. Поэтому в нашем примере пришлось вынести сортировку в отдельный метод, чтобы не менять текущий порядок книг.
С лямбдами
Library library = new Library();
List list = library.getBooks().stream()
.sorted(Comparator.comparing(Book::getIssueYear))
.collect(Collectors.toList());Для передачи алгоритма сравнения элементов в метод sorted() используется лямбда-выражение Comparator.comparing(Book: :getIssueYear).
Оно равносильно анонимному классу в примере выше: означает, что книги сравниваются по году издания.
Метод collect(Collectors.toList()) замыкает стрим в список (List).
Создавать отдельный метод для сортировки не пришлось. И в целом код выглядит компактнее.
Для преобразования — map()
Метод используется для преобразования объектов. Это может быть простое извлечение значения одного поля или создание объектов другого типа по данным объекта-источника.
Задача
Требуется создать список рассылки (объекты типа EmailAddress) из адресов всех читателей библиотеки. При этом флаг согласия на рассылку учитывать не будем: библиотека закрывается, так что хотим оповестить всех.
Без лямбд
List<EmailAddress> addresses = new ArrayList<>();
for (Reader reader : library.getReaders()) {
addresses.add(new EmailAddress(reader.getEmail()));
}Здесь мы не только используем цикл, но и меняем экземпляр нового списка в ходе итерирования. Если понадобятся хоть какие-то условия отбора, конструкция ещё больше усложнится.
С лямбдами
List<EmailAddress> addresses = library.getReaders().stream()
.map(Reader::getEmail)
.map(EmailAddress::new)
.collect(Collectors.toList());При первом использовании map() получаем из списка читателей список электронных адресов. На следующем шаге создаем экземпляры нужного нам класса EmailAddress, а далее собираем полученные адреса в список.
Для фильтрации — filter()
Метод фильтрует стрим согласно переданному в метод условию-предикату. Позволяет записать условие в одну строчку без громоздких конструкций if-else.
Задача
Снова нужно получить список рассылки. Но на этот раз включаем в него только адреса читателей, которые согласились на рассылку. Дополнительно нужно проверить, что читатель взял из библиотеки больше одной книги.
Без лямбд
List<EmailAddress> addresses = new ArrayList<>();
for (Reader reader : library.getReaders()){
if (reader.getBooks().size() > 1 && reader.isSubscriber())
addresses.add(new EmailAddress(reader.getEmail()));
}Как видим, к циклу добавилась ещё пара условий. Проверяться они будут для каждого читателя.
С лямбдами
List<EmailAddress> addresses = library.getReaders().stream()
.filter(Reader::isSubscriber)
.filter(reader -> reader.getBooks().size() > 1)
.map(Reader::getEmail).map(EmailAddress::new)
.collect(Collectors.toList());На первом шаге (первое использование filter()) сокращаем число читателей: работаем со списком тех, кто дал согласие на рассылку.
На втором шаге из этого ограниченного числа читателей выбираем тех, кто взял более одной книги.
Далее уже знакомыми map() и collect() получаем email-адреса, преобразуем их к нужному типу и собираем в список.
Для преобразования и создания линейного списка — flatMap()
Результат работы flatMap() получается в два действия, на которые намекает само название метода. Эти слова и эти операции:
- map (мы уже знаем, что это преобразование);
- и flat — дословно «плоский».
Если применить обычный map() к стриму из списков List<AnyType>, то на выходе получим стрим из списков списков — List<List<NewType>>.
flatMap() позволяет получить «плоский» одномерный список — List<NewType>, в который будут последовательно добавлены преобразованные значения из всех списков, полученных после применения map().

А далее о случае, когда эта операция бывает полезной.
Задача
Получить список всех книг, взятых читателями. Список не должен содержать дубликатов (книг одного автора, с одинаковым названием и годом издания).
Без лямбд
Set<Book> result = new LinkedHashSet<>();
for (Reader reader : library.getReaders()) {
result.addAll(reader.getBooks());
}
return new ArrayList<>(result);Чтобы получить список уникальных книг, мы создали Set (множество), последовательно прошлись по всем читателям и добавили их книги в это множество. Только после этого преобразовали множество в список (ArrayList).
С лямбдами
List<Book> bookList = library.getReaders().stream()
.flatMap(reader -> reader.getBooks().stream())
.distinct()
.collect(Collectors.toList());После применения flatMap() уже получаем стрим, состоящий из всех книг всех читателей, а distinct() отвечает за то, чтобы в этом стриме остались только уникальные значения.
Вот так — без дополнительных полей и циклов.
Для проверки, есть ли хоть что-то подходящее, — anyMatch()
Простой метод, который принимает на вход условие-предикат и возвращает флаг:
- true, если в стриме есть объект, который удовлетворяет условию;
- false — если такого объекта там нет.
Задача
Проверить, взял ли кто-то из читателей библиотеки какие-нибудь книги Оруэлла.
Без лямбд
boolean result = false;
for (Reader reader : library.getReaders()){
for (Book book :reader.getBooks()){
if ("Оруэлл".equals(book.getAuthor())){
result = true;
break;
}
}
}
return result;Организуем два (!) вложенных цикла и вводим дополнительную переменную для хранения промежуточного результата. Цикл прерывается при первой встрече с Оруэллом.
С лямбдами
boolean match = library.getReaders().stream()
.flatMap(reader -> reader.getBooks().stream())
.anyMatch(book -> "Оруэлл".equals(book.getAuthor()));С помощью flatMap() получаем стрим из всех взятых книг, а anyMatch() определяет, есть ли среди авторов Оруэлл.
Чтобы остался только один — reduce()
Метод reduce() берёт стрим и редуцирует (сокращает) его до одного значения. Для этого в метод передаются начальное значение (необязательный параметр) и функция-аккумулятор с двумя параметрами.
Сначала эта функция применяется к начальному значению и первому элементу стрима, затем к полученному на этом шаге результату и следующему элементу стрима — и так до последнего элемента стрима.
Есть и более сложные варианты редукции, когда нужен третий параметр — функция комбинирования. Она полезна при распараллеливании задач или несовпадении типов аргументов функции-аккумулятора и результата этой функции.
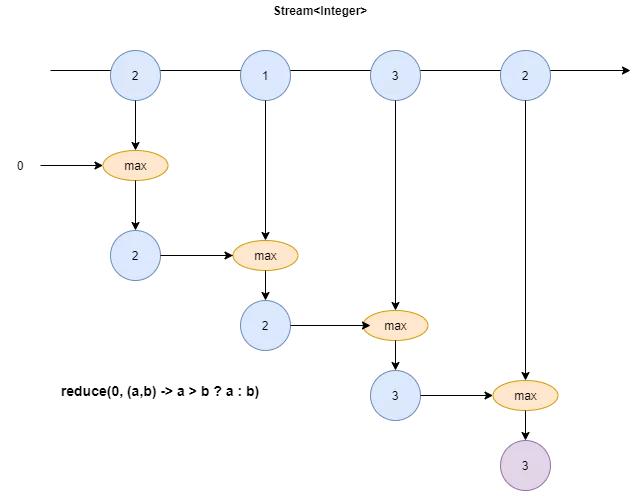
Задача
Узнать наибольшее число книг, которое сейчас на руках у читателя.
Без лямбд
int max = 0;
for (Reader reader : library.getReaders()){
if (reader.getBooks().size() > max)
max = reader.getBooks().size();
}
return max;На старте принимаем за максимум наименьшее возможное число книг у каждого читателя, то есть 0. Потом перебираем всех читателей, смотрим, сколько у кого книг, и при необходимости обновляем максимум.
С лямбдами
Integer reduce = library.getReaders().stream()
.map(reader -> reader.getBooks().size())
.reduce(0, (max, size) -> size > max ? size : max);На первом шаге с помощью map() соотносим с каждым читателем число взятых им книг, а затем с помощью reduce() находим максимальный элемент в этом новом стриме.
Это важно. При каждом вызове функции-аккумулятора создаётся новый объект. Если вы хотите, чтобы на выходе reduce() оказался сложный объект — например, коллекция, и ходите в функции-аккумуляторе добавлять в неё значения, то на каждом шаге будет создаваться новая коллекция.
Это плохо сказывается на производительности. В таких случаях лучше использовать collect().
Для группировки — collect() + Collectors.groupingBy() и Collectors.mapping()
Методы groupingBy() и mapping() вовсе не обязательно применять вместе. Первый позволяет разбить стрим на группы по заданному признаку. Если эти группы нужны в виде списков, то второй метод не понадобится.
mapping() выручит, если полученные группы нужно хитрым (или не очень) образом преобразовать (например, сгруппировать по другим признакам).
Задача
Вернёмся к нашим баранам email-рассылкам. Теперь нужно не просто отправить письма всем, кто согласился на рассылку, — будем рассылать разные тексты двум группам:
- тем, у кого взято меньше двух книг, просто расскажем о новинках библиотеки;
- тем, у кого две книги и больше, напомним о том, что их нужно вернуть в срок.
То есть надо написать метод, который вернёт два списка адресов (типа EmailAddress): с пометкой OK — если книг не больше двух, или TOO_MUCH — если их две и больше. Порядок групп не важен.
Без лямбд
Приготовьтесь, сейчас будет страшно.
Map<String, List<EmailAddress>> result = new HashMap<>();
for (Reader reader : library.getReaders()) {
if (reader.isSubscriber()) {
if (reader.getBooks().size() > 2) {
if (!result.containsKey("TOO_MUCH")) {
result.put("TOO_MUCH", new ArrayList<>());
}
result.get("TOO_MUCH").add(new EmailAddress(reader.getEmail()));
} else {
if (!result.containsKey("OK")) {
result.put("OK", new ArrayList<>());
}
result.get("OK").add(new EmailAddress(reader.getEmail()));
}
}
}
return result;Цикл и три уровня ветвлений. И это всего для двух групп!
С лямбдами
Map<String, List<EmailAddress>> map = library.getReaders().stream()
.filter(Reader::isSubscriber)
.collect(groupingBy(r -> r.getBooks().size() > 2 ? "TOO_MUCH" : "OK",
mapping(r -> new EmailAddress(r.getEmail()), Collectors.toList())));На первом шаге фильтруем читателей: оставляем только тех, кто согласился на рассылку. Дальше настраиваем параметры метода collect():
- задаём группировку — нужно разбить стрим на две группы по числу книг: «TOO_MUCH» или «OK»;
- в каждой группе берём email-адреса читателей (new EmailAddress (r.getEmail())) и собираем их в списки (Collectors.toList()).
Вариации на тему
1. Если нужны не адреса, а просто списки читателей в каждой группе:
Map<String, List<Reader>> readerstMap = library.getReaders().stream()
.filter(Reader::isSubscriber)
.collect(groupingBy(r -> r.getBooks().size() > 2 ? "TOO_MUCH" : "OK"));2. Если для каждой группы нужны ФИО читателей из этой группы, перечисленные через запятую. И ещё каждый такой список ФИО нужно обернуть фигурными скобками.
Например:
TOO_MUCH {Иванов Иван Иванович, Васильев Василий Васильевич}
OK {Семёнов Семён Семёнович}
Map<String, String> readersFIOMap = library.getReaders().stream()
.filter(Reader::isSubscriber)
.collect(groupingBy(r -> r.getBooks().size() > 2 ? "TOO_MUCH" : "OK",
mapping(Reader::getFio, joining(", ", "{", "}"))));Что дальше?
Ещё больше о Stream API вы узнаете из официальной документации и на нашем курсе «Профессия Java-разработчик».