Ну напридумывали... Ловите новые крутые фишки языков программирования
Неизменяемость, мультиметоды и все-все-все.


Джереми Грифски
(Jeremy Grifski)
об авторе
Программист-энтузиаст. Получает докторскую степень в области инженерных наук, хочет стать преподавателем. Любит писать о коде. Сайт автора: The Renegade Coder.
Продолжаем рассказывать о самых крутых возможностях языков программирования. Если пропустили первую часть статьи — она здесь. А сегодня самый сок: неизменяемость, множественная диспетчеризация и — о ужас! — ассемблер, встроенный ассемблер.
Неизменяемость
Одна из самых прикольных фишек языков программирования — это неизменяемость (immutability). Впервые я столкнулся с ней, когда проходил курс по языкам высокого уровня.
В одном из заданий нам нужно было оценить и сравнить возможности примерно десяти языков программирования. И среди них была передача по значению, которая подразумевает неизменяемость.
Примечание переводчика
При передаче по значению значения параметров копируются и все действия с ними в подпрограмме выполняются уже над копией.
При передаче по ссылке в подпрограмму передаётся ссылка на исходную переменную, копия не создаётся. По ссылке можно получить доступ к переменной — и изменить её значение.
Неизменяемость описывает переменные, которые не меняются после создания (в частности, константы). Во многих языках этим свойством обладают и строки. Именно поэтому не рекомендуется склеивать строки в цикле:
my_string = ""
for i in range(10):
my_string += str(i) # на каждом шаге создаст новую строку
print(my_string) # выведет "0123456789"По этой же причине я не использовал конкатенацию (склейку) в своей серии статей «Разворачиваю строку задом наперёд (на разных языках)».
Разработчики языков программирования, конечно, знают о подобных ловушках и тратят немало усилий, чтобы оградить от них кодеров.
Примечание переводчика
Ловушка здесь в том, что для каждой новой строки, которую неопытный разработчик неявно создаёт при склейке строк, нужно выделить место в памяти. Если итераций много, а компьютер слабоват, его памяти может и не хватить.
Разработчики языков программирования всеми силами пытаются оптимизировать подобные операции. Например, в Java есть класс StringBuilder. В отличие от String, он не immutable. Так что места в памяти для той же склейки требуется меньше, а результат легко приводится к строковому типу.
Кроме того, в Java есть пул строк, в который попадают все литералы — явно объявленные строки. В примере ниже строка "string" при первом упоминании попадёт в этот пул, а при исполнении оператора присваивания для s2 новый объект типа String создан не будет — s2 просто укажет на уже существующий в пуле объект.
String s1="string"; // строка "string" попадёт в пул строк
String s2="string"; // s2 будет указывать на эту строку в пулеЯ не видел языков, где неизменяемость распространялась бы на что-то кроме строк. А потом попробовал написать Hello World на Elm.
В языке Elm переменные неизменны, прямо как в математике. Так что вот такой код не скомпилируется:
a = 2
a = a - 5Проблема тут в рекурсии. Сначала мы присваиваем переменной a значение. А потом пытаемся переопределить a как функцию самой себя. Программисты, которые привыкли к императивным языкам, не увидят в этом ничего криминального. А вот с точки зрения математика со вторым присваиванием явно что-то не так.
Прелесть неизменяемости в том, что значение после первой операции присваивания будет всегда одинаковым — а значит, оно точно не изменится без вашего ведома.
Мультиметоды
Как и лямбда-выражения (про них читайте в первой части. — Пер.), это не такая уж новая фича. Но всё равно одна из самых крутых. Мультиметоды (multimethods) и множественная диспетчеризация (multiple dispatch) позволяют делать забавные вещи. Например, прямо в рантайме выбирать конкретную реализацию метода, общего для объектов, связанных иерархией наследования.
Я вспомнил про эту фичу, когда писал статью «Hello World на Julia». Julia — это язык, разработанный для численного анализа. Он напоминает Python и R, но вполне тянет на язык программирования общего назначения. И, в отличие от Python, Julia поддерживает мультиметоды, или множественную диспетчеризацию.
И тут я, наверное, должен объяснить разницу между одиночной и множественной диспетчеризацией. Одиночная диспетчеризация (виртуальные методы) — это одновременно и свойство языка программирования, которое позволяет пользователю реализовать в иерархии объектов один и тот же метод по-разному, и механизм, выбирающий нужную реализацию на основе фактического типа объекта, для которого этот метод был вызван.
Рассмотрим пример на Java:
pikachu.tackle(charmander);
charmander.tackle(pikachu);Предполагается, что у нас есть два объекта — экземпляры классов из семейства Pokemon: pikachu (Пикачу) и charmander (Чармандер). В классах для этих объектов переопределяется общий метод tackle (физическая атака, при которой покемон разгоняется и врезается в противника всем телом. — Пер.). Когда мы запускаем этот код, JVM способна разобраться и вызвать правильный метод tackle.
Но в языках программирования с одиночной диспетчеризацией всё не так хорошо, потому что динамически определяется только вызов метода, а для параметров всё ещё приходится полагаться на типы, выведенные статически на этапе компиляции.
То есть суть множественной диспетчеризации в том, что мы вызываем метод на основе реальных конкретных типов, которые переменные имеют к моменту вызова.
Давайте представим, что charmander был создан как экземпляр более общего класса Pokemon. В случае одиночной диспетчеризации pikachu будет использовать метод tackle для этого общего класса, а не специфическую реализацию, заточенную под charmander. В результате pikachu может промахнуться и провалить атаку.
При множественной диспетчеризации такого не случится, потому что метод выбирается во время выполнения программы. И раз будет выбран более специфический вариант метода, pikachu атакует успешно.
Чтобы лучше разобраться с множественной диспетчеризацией, советую прочитать статью Эли Бендерского (Eli Bendersky) «Множественная диспетчеризация для полиглотов».
Деструктуризация
Помните, я писал про сопоставление с образцом (pattern matching)? Так вот, деструктуризация (destructuring), или повторяющаяся распаковка (iterable unpacking), — это разновидность сравнения с образцом. С её помощью извлекают данные из коллекций.
Примечание переводчика
Про сопоставление с образцом автор говорил в первой части статьи. Напомним, что сопоставление с образцом (англ. pattern matching) — это метод анализа и обработки структур данных в языках программирования. В зависимости от того, совпадает или нет переданный аргумент с образцом, выполняются какие-то действия. Образцом может быть константа, тип данных или другая конструкция, которую поддерживает язык.
Этот метод используется, например, в регулярных выражениях.
Вот пример на Python:
start, *_ = [1, 4, 3, 8]
print(start) # выводит 1
print(_) # выводит [4, 3, 8]Здесь мы извлекаем первый элемент списка и игнорируем все остальные. То же самое легко проделать и для последнего элемента:
*_, end = ["red", "blue", "green"]
print(end) # выводит "green"Таким образом, используя сопоставление с образцом, мы можем извлечь из набора нужные данные — достаточно знать их структуру:
start, *_, (last_word_first_letter, *_) = ["Hi", "How", "are", "you?"]
print(last_word_first_letter) # выводит "y"Встроенное тестирование
Я не уверен, что правильно назвал эту фичу, — да и вообще не знаю, есть ли у неё общепринятое название. Тем не менее встроенное тестирование (inline testing) — одна из самых прикольных языковых фишек, которые я когда-либо видел.
Впервые я наткнулся на неё в Pyret. Этот язык создан для обучения программированию. В Pyret модульные тесты (unit tests) — часть базового синтаксиса языка. Другими словами, для запуска тестов не нужно импортировать сторонние библиотеки и создавать специальные обёртки.
Вместо этого в синтаксисе Pyret есть несколько конструкций для тестирования:
fun sum(l):
cases (List) l:
| empty => 0
| link(first, rest) => first + sum(rest)
end
where:
sum([list: ]) is 0
sum([list: 1, 2, 3]) is 6
endМы видим замечательную функцию для суммирования списка. Для пустого списка она выдаст 0, в остальных случаях просуммирует все значения в списке и вернёт результат.
В большинстве языков программирования на этом всё и закончится, а о тестировании, возможно, задумаются позднее. В Pyret же всё не так. Для тестов нужно просто добавить секцию where. В ней мы проверим, что и для пустого списка, и для списка, сумма элементов которого равняется 6, функция вернёт корректные значения.
Когда исполняется код, запускаются и тесты. Но тесты вовсе не блокируют работу программы. Она продолжит работать, если не возникнет каких-то совсем уж катастрофических проблем.
По-моему, это отличная фишка. И с ней гораздо удобнее сопровождать код. По крайней мере, при программировании на Pyret вы никогда не забудете о тестировании.
Встроенный ассемблер
Думали, что встроенное тестирование — единственная прикольная инлайн-фича? А вот и нет — познакомьтесь со встроенным ассемблером. Я узнал о нём, когда писал Hello World на D.
Как оказалось, встроенный ассемблер — это инструмент, который позволяет разработчику напрямую обращаться к архитектуре системы. Например, с ним заработает такой код:
void *pc;
asm
{
pop EBX ;
mov pc[EBP], EBX ;
}Выглядит как смесь C/C++ и обычного ассемблера. И это действительно так! Мы написали код, который работает напрямую с базовой архитектурой, — и точно знаем, что происходит под капотом.
Мне эта фишка показалась интересной, потому что языки программирования стремятся к высокому уровню — абстракциям. А в языке D мы можем отказаться от встроенной функциональности и написать свою реализацию на самом низком уровне.
Соглашения об именах библиотек
Однажды в комментариях к моей статье кто-то упомянул ещё одну классную фичу Python:
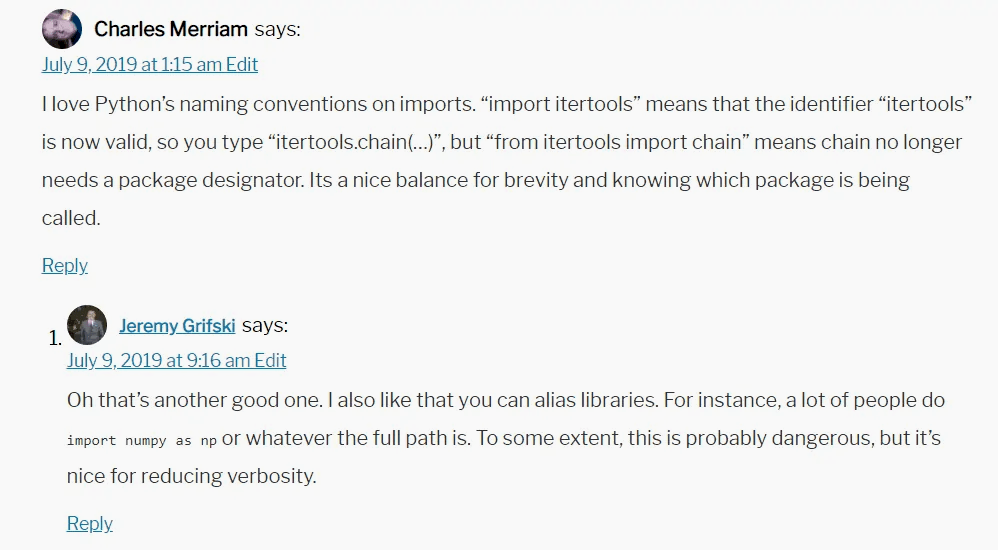
Я полностью согласен с вышесказанным! Мне и правда кажется, что дополнительные имена могут усложнить чтение кода.
Что дальше?
Это далеко не все крутые фишки языков программирования. Автор регулярно пополняет коллекцию — за свежей версией на английском приходите сюда. Ну а если хотите познакомиться поближе с какими-то языками, то предлагаем начать с Python и Java.










