Kandinsky, GigaChat и иже с ними: как работают мультимодальные нейросети
Краткое пособие по мультимодальным нейросетям от одного из разработчиков модели OmniFusion.


«Разговорные» нейросети недолго пробыли главной технологической сенсацией десятилетия. Теперь в ходу — мультимодальные ИИ, которые одинаково хорошо пишут тексты и код, рисуют картинки, сочиняют музыку и умеют, кажется, всё на свете. Теперь можно скормить ИИ постироничный мем и получить внятное объяснение — или, например, получить инструкцию по сборке велосипеда по одной лишь фотографии деталей.
О том, как работают такие модели, рассказал Матвей Михальчук — один из разработчиков команды OmniFusion. В рамках эфира Skillbox Code Experts он рассказал, что такое мультимодальные LLM, как они работают и чем отличаются от других своих «собратьев по разуму».

Матвей Михальчук
AI-исследователь в лаборатории Fusion Brain института AIRI. Один из ключевых разработчиков модели OmniFusion. Автор научных работ о глубоком обучении и больших языковых моделях.
Как обучают большие языковые модели
Развитие нейросетей напоминает слоёный пирог: сначала появились языковые модели, заточенные на работу с текстом, а затем, слой за слоем, стали добавляться и другие модальности — например, картинки, видео и аудио. Поэтому разговор о мультимодальных ИИ логично начать именно с классических текстовых нейросетей.
Несмотря на производимый вау-эффект, большие языковые модели устроены довольно просто. Более того, механика их работы напоминает знакомый многим T9. Модель принимают на вход начало предложения, а затем самостоятельно его продолжают. Задача разработчиков в том, чтобы обучить нейронные сети предсказывать, каким будет следующее слово в предложении по его началу.
Если углубиться в технические детали, то модели предсказывают не конкретное слово, а токен. Токенизация — это преобразование текста (последовательности букв) в последовательность чисел. Токеном может быть как слово, так и его часть. Всё предложение разбивается на токены, и модель работает с их последовательностью. Например, по последовательности из десяти слов модель может предсказать одиннадцатое — и так, шаг за шагом, сгенерировать предложение.
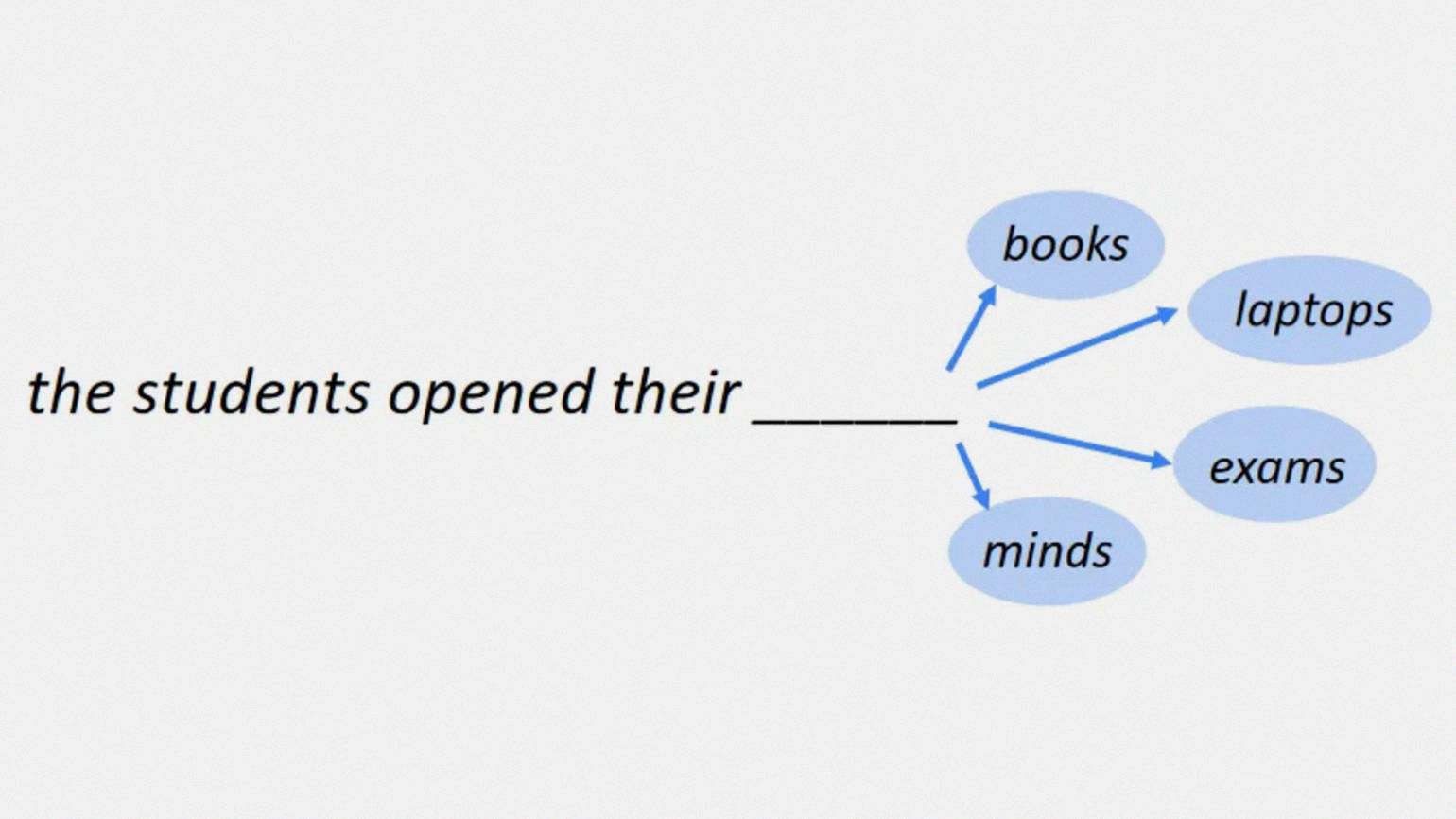
На картинке ниже можно увидеть, как это работает: у нас есть начало предложения — «the students opened their», — а дальше возможны варианты. Из всех возможных вариантов токенов, которых конечное количество, как букв в языке, мы каждый раз выбираем одну из 33 букв. Таким образом нейронная сеть обучается генерировать текст.
Одна из архитектур, которая умеет это делать, — GPT. Это так называемая трансформерная декодерная архитектура. Модель принимает на вход набор токенов, которые потом кодируются в виде векторов.
Вектор — набор чисел фиксированной длины. У модели (токенизатора) есть фиксированный набор токенов, где каждому токену соответствует вектор, состоящий из параметров модели. При кодировании последовательности токенов каждый токен (число) из последовательности заменяется на вектор, соответствующий данному токену. В итоге последовательности токенов кодируются в последовательность векторов. Именно по этим векторам модель и предсказывает, какое слово будет следующим.

Языковые модели обучаются на больших наборах текстов в несколько этапов. Разберём их по очереди.
Первый этап — pretraining, или претренинг. На этом этапе языковой модели «скармливают» огромные наборы разнообразных текстовых данных. Например, отрывки книг, статьи с сайтов и другой контент.
На этом этапе важно показать модели, как устроен естественный язык, поэтому для претрейна используют огромные наборы данных, собранных, как правило, из интернета. Данные эти обычно не очень качественные — например, они могут содержать грамматические ошибки или плохо отфильтрованные элементы веб-разметки сайтов.
На этапе претрейна используются огромные наборы текстов — в закодированном виде их размер часто достигает десятков триллионов токенов. Поэтому обучение больших моделей требует значительных вычислительных ресурсов и стоит очень дорого. Часто обучение занимает несколько месяцев работы вычислительных кластеров с сотнями или тысячами специализированных видеокарт.

На этом этапе модель узнаёт, как устроен язык, и учится генерировать правдоподобные предложения наподобие тех, что были в обучающей выборке. Однако этого пока недостаточно, чтобы получить чат-бота вроде GigaChat и ChatGPT, способных отвечать на вопросы пользователя.
Второй этап — supervised fine-tuning (файнтюн, или дообучение). На этапе «тонкой настройки» модель учится отвечать на вопросы пользователей. Для этого используют меньший, чем для претрейна, набор данных, которые часто получают с помощью разметки людьми. В этих датасетах содержится уже не просто текст, который модель научилась продолжать, а набор вопросов и ответов. Важную роль в этом играет размер и качество обучающей выборки.
На втором этапе (SFT) важно использовать качественные диалоговые датасеты. Поскольку такие датасеты сложно собрать автоматически, часто они создаются вручную людьми — разметчиками. Поэтому объём SFT-выборки гораздо меньше объёма выборки для претрейна.
Третий этап — reinforcement learning from human feedback, или обучение с помощью обратной связи от человека (RLHF). На этом этапе люди вручную исправляют ответы модели, чтобы они соответствовали ожиданиям. На этапе RLHF мы собираем варианты диалогов и обучаем модели генерировать именно такой ответ, какой хотим видеть.
Например, модель должна этично отвечать на вопросы, связанные с расами. А на вопросы, как сделать бомбу или устроить теракт, тактично предлагать сменить тему :) Именно такие точечные правки в модель вносятся на этапе дообучения с подкреплением. Этот этап применялся не для всех моделей — только для самых крупных, вроде GPT-4.
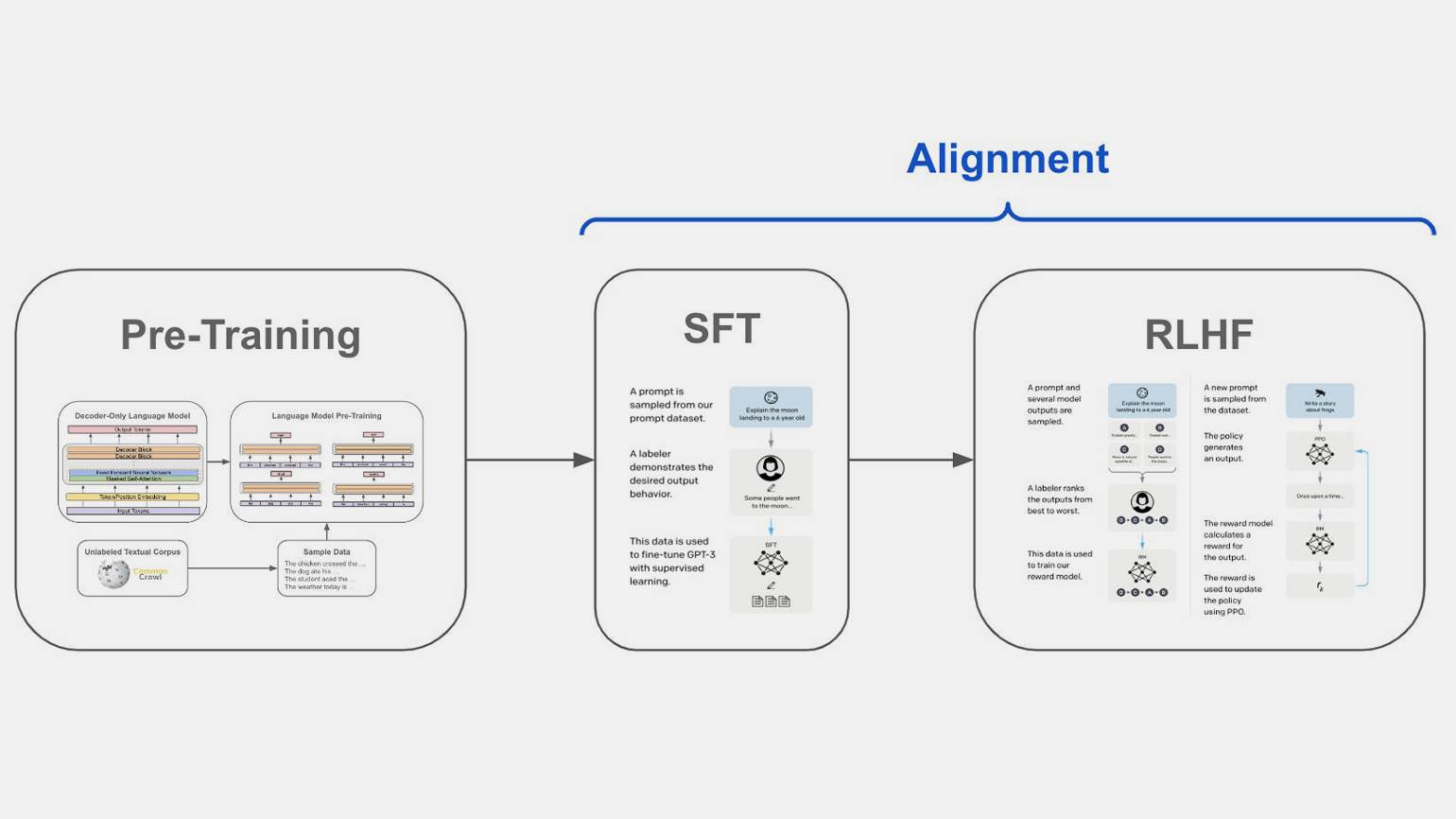
На схеме выше подробно описан пайплайн обучения модели GPT. Видно, что на самых последних рубежах мы учим модель не делать плохих вещей — не проявлять ненависть, токсичность, неэтичность и так далее.
На последних этапах обучение происходит уже на меньших наборах данных. Мы лишь чуть-чуть корректируем модель и учим её подавать ответ в той форме, в которой ожидаем.
Мультимодальные модели
В 2023 году рынок начали активно штурмовать модели, работающие не только с текстом, но и с картинками, аудио, видео и другими данными. До этого мультимодальность тоже развивалась, но гораздо медленнее. Выходили в основном простые модели, которые умели генерировать подписи к картинкам, но были неспособны вести полноценный диалог.
На графике ниже показан рост числа публикаций по мультимодальным чат-ботам. Можно заметить, что в 2023 году количество публикаций по этой теме практически удвоилось.
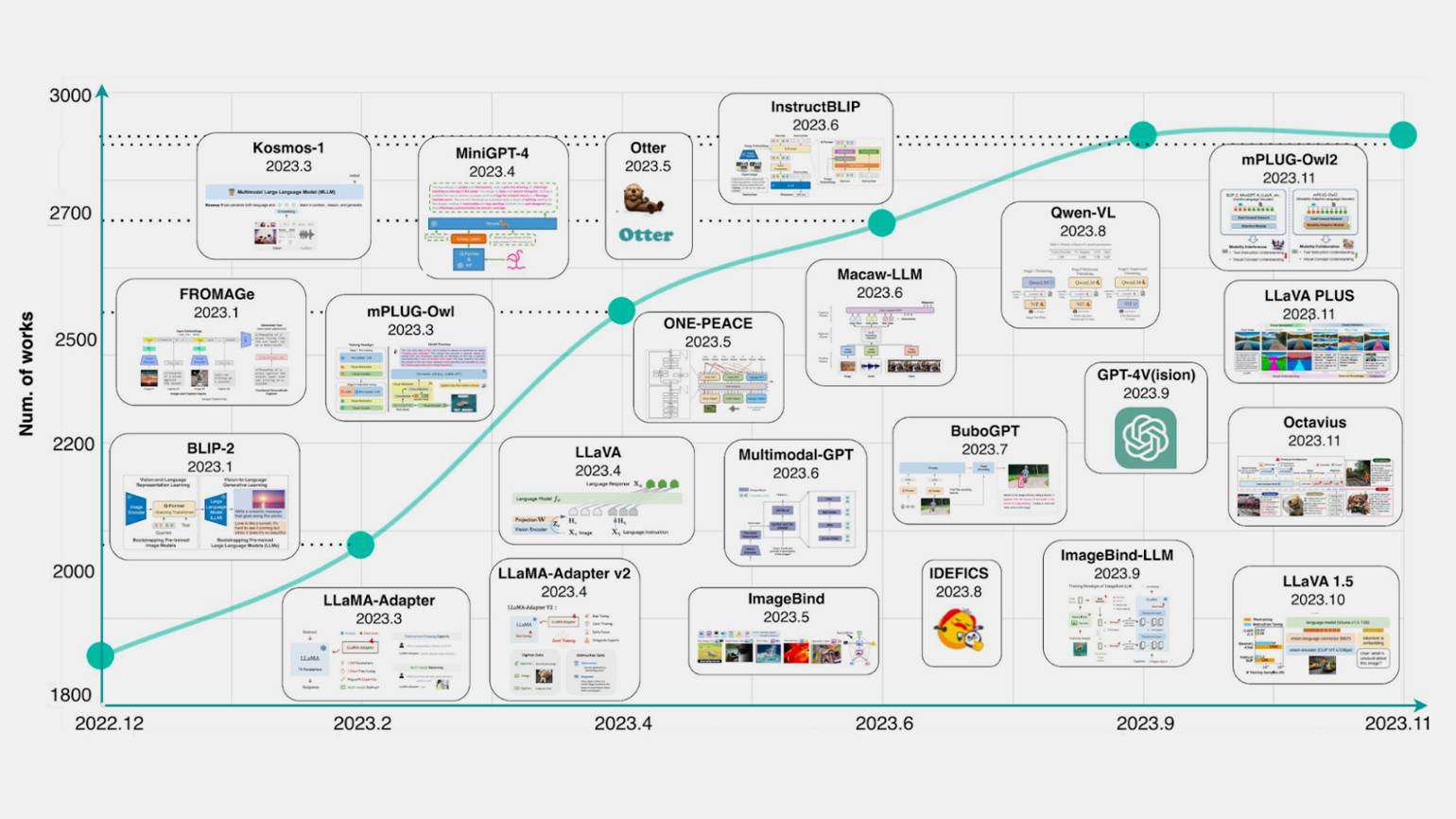
В этот период появилась целая россыпь мультимодальных нейросетей: GPT-4 Vision, ImageBind, Fromage, Kosmos, LLaVA. Мало того, репозитории HuggingFace и GitHub наводнили опенсорсные LLM, на базе которых компании и энтузиасты стали собирать свои решения. Количество терминаторов-универсалов стало расти в геометрической прогрессии.

Читайте также:
Зачем же понадобилось добавлять в языковые модели новые модальности? На это есть несколько причин.
Первая причина в том, что тексты зарекомендовали себя как отличный источник данных для обучения. А другой — в чатах мы общаемся не только текстом, но и используя картинки, аудио, видео, мемы. И если мы хотим получить AI-ассистентов, способных понимать людей и отвечать им в любых удобных форматах, нужно обучить модель работать не только с текстом, но и со всеми привычными людям типами данных.
Другая причина в том, что мультимодальные данные содержат больше знаний о мире, а потому может выдавать более осмысленные ответы. Данные из одной модальности дополняют и обогащают данные из другой: скажем, понятие «человек» для такой нейросети — это не просто слово, но и голос, одежда, внешность, манера движения.
Обученная на разных типах данных нейросеть сможет отвечать на вопросы, связанные цветами, геометрией, музыкой и даже мемами. А вдогонку ещё и генерировать эти самые картинки и мемы и цвета в качестве ответа. Причём с каждым годом творчество нейросетей становится всё качественнее.

Например, недавно OpenAI выпустила модель Sora, которая на данный момент считается самой передовой нейросетью для генерации видео. К сожалению, модель закрытая, нельзя скачать её параметры или посмотреть исходный код. Однако качество генерации поражает.
Как создаются мультимодальные нейросети

Существует три основных подхода к мультимодальности. Разберём каждый из них по отдельности.
Tool-augmented LLM
Суть метода в том, чтобы совместить в одном продукте сразу несколько независимых моделей. Например, у вас есть модель GigaChat, которая работает только с текстом, и есть Kandinsky, создающая только картинки. Совмещаем эти модели, и вуаля — получаем мультимодальный ИИ. Так устроены, например, актуальные версии GigaChat и ChatGPT.
Допустим, мы хотим сделать нейросеть, которая будет в чате генерировать картинки. Чтобы этого добиться, можно взять текстовую модель, научить её составлять запрос для генерации изображения (так называемый текстовый промпт) и передавать её на модель text2image, генерирующую картинки.
При этом подходе пользователь общается с языковой моделью и текстом просит её что-то нарисовать. Языковая модель, в свою очередь, сначала генерирует текстовый ответ вроде «сейчас нарисую, подожди», а затем прямо в этом тексте генерирует специальную команду, содержащую промпт (например: сейчас нарисую <img_prompt> сгенерированный_промпт </img_prompt>).
Плюс этого подхода в том, что он не требует серьёзного дообучения. Всё, что вам нужно, — это обучить текстовую модель составлять запросы, а для этого не нужно слишком много данных и ресурсов. Из минусов — так называемый lack of information exchange between modalities.
Это значит, что между моделями будет очень плохая связка. Графической нейросети будет поступать очень мало информации о картинке — только та, что содержится в коротком текстовом запросе. Плюс ко всему, «картиночная» нейросеть не видела огромного массива текстов, на которых обучалась её текстовая визави — поэтому может не «понять» часть важных для генерации деталей.
Получается, что у нас есть две большие умные модели, но умные лишь в своей области. Настоящая же мультимодальность предполагает единую систему, которая внутри себя оперирует представлениями и о картинках, и о текстах, что позволяет ей лучше понимать окружающий мир.
End-to-end multimodal LLM
End-to-end multimodal LLM переводится как «модель сквозного обучения». Это чуть более продвинутый подход — вместо того чтобы использовать отдельные модели для текста и картинок, такая модель обучается сразу на всех необходимых типах данных, в рамках единой структуры.
Самый простой способ обучить такую модель — собрать датасет на базе диалогов, в которых есть и текст, и картинки. Однако «простота» здесь только кажущаяся. Подготовить качественный диалоговый датасет — нетривиальная задача, да и вычислительных ресурсов такой способ требует немало.
Modality bridging with pretrained models
Modality bridging with pretrained models — это устранение разрыва между модальностями, их объединение.
В этом подходе, как и в первом, у нас есть две модели, отвечающие за текст и картинки. Однако связь между ними устроена более хитро — модели обмениваются данными не посредством текстового запроса, а с помощью математических векторов.
Допустим, нам нужно научить чат-бот описывать изображение и отвечать на вопросы о нём. Для этого возьмём кодировщик изображений — модель, которая кодирует изображение в пространство векторов. Каждому изображению она выдаёт свой набор чисел — вектор, который математически описывает содержание. Похожим картинкам соответствуют похожие наборы чисел.
Затем возьмём вторую, большую языковую модель, которая пока может работать только с текстами. И добавляют к ней так называемый адаптер, который будет внутри сращивать две модели между собой.
Обучают только адаптер — он содержит гораздо меньше параметров и требует меньше обучающих данных, чем большая языковая модель. В датасетах для адаптера содержатся только пары «картинка + подпись». На втором этапе используют семплы в виде «картинка + диалог по картинке» (чередующиеся вопросы и ответы).
Языковую модель или совсем не учат, или учат незначительно, потому что она и так неплохо обучена под свою задачу — писать текст и вести диалоги. Её достаточно лишь немного дообучить, чтобы она научилась извлекать информацию из изображений от адаптера.
В отличие от первых двух способов, связь между моделями происходит не через тексты, а через адаптер. От энкодера изображений к LLM передаётся сигнал в виде набора векторов-признаков — это гораздо более естественный и информативный для нейросетевых моделей способ обмена данными между моделями.
Этот подход используется в таких моделях, как LLaVA, Fromage, Flamingo. На этом подходе сконцентрировались и мы, создавая OmniFusion.
Как мы обучали OmniFusion
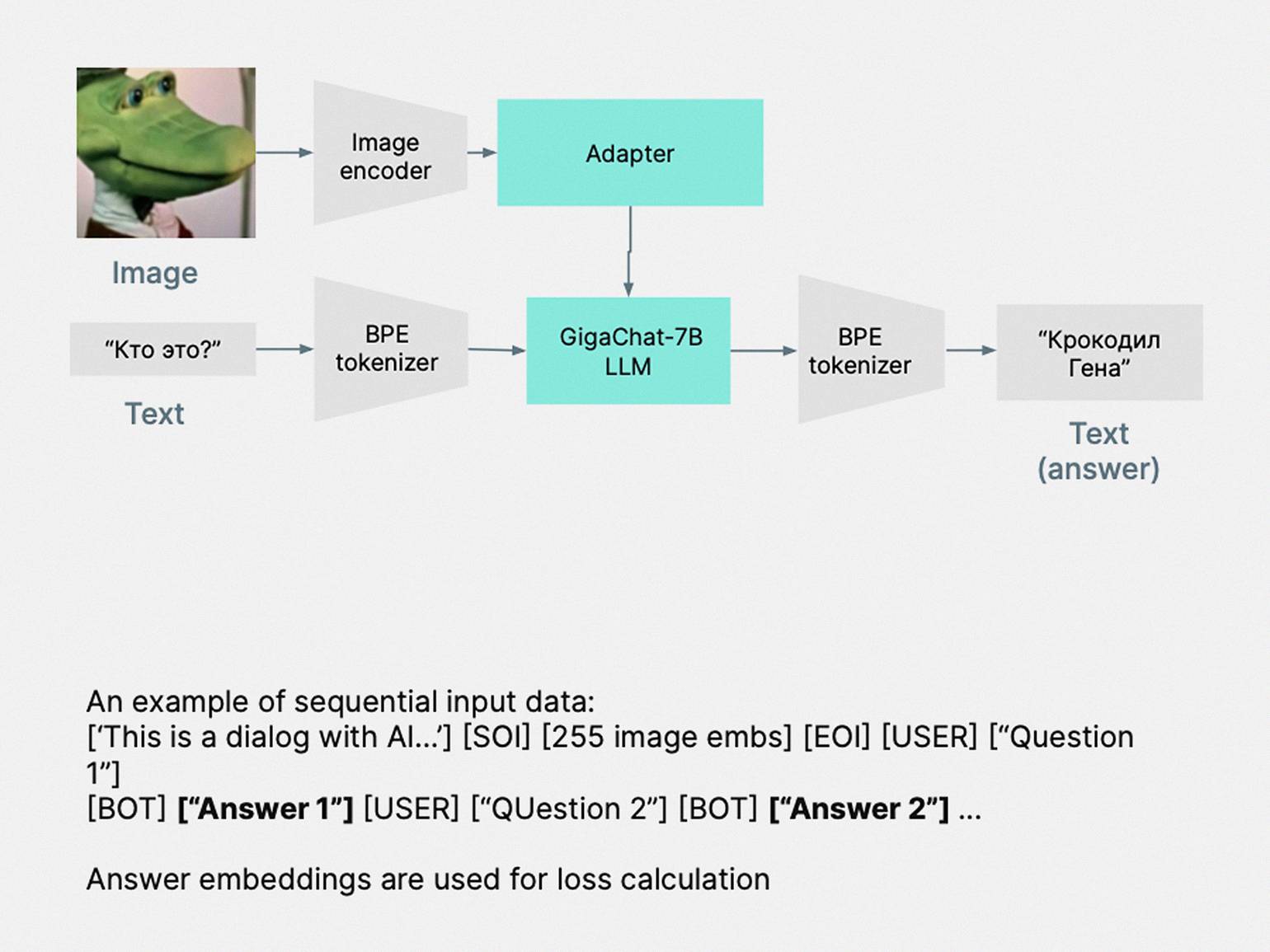
По архитектуре OmniFusion — большая языковая модель, в которую мы добавили кодировщик изображений и адаптер, чтобы она смогла отвечать на вопросы по изображениям.
Вот из каких компонентов состоит OmniFusion:
- GigaChat — большая языковая модель на 7 млрд параметров.
- Энкодер — нейросеть, кодирующая изображение. Она генерирует вектор по нашей картинке — набор чисел, который её описывает. Потом этот вектор подаётся на адаптер.
- Адаптер — это небольшая нейросеть, представляющая собой слой трансформера-энкодера. Адаптер передаёт информацию от картиночной к текстовой нейросети с помощью набора векторов.
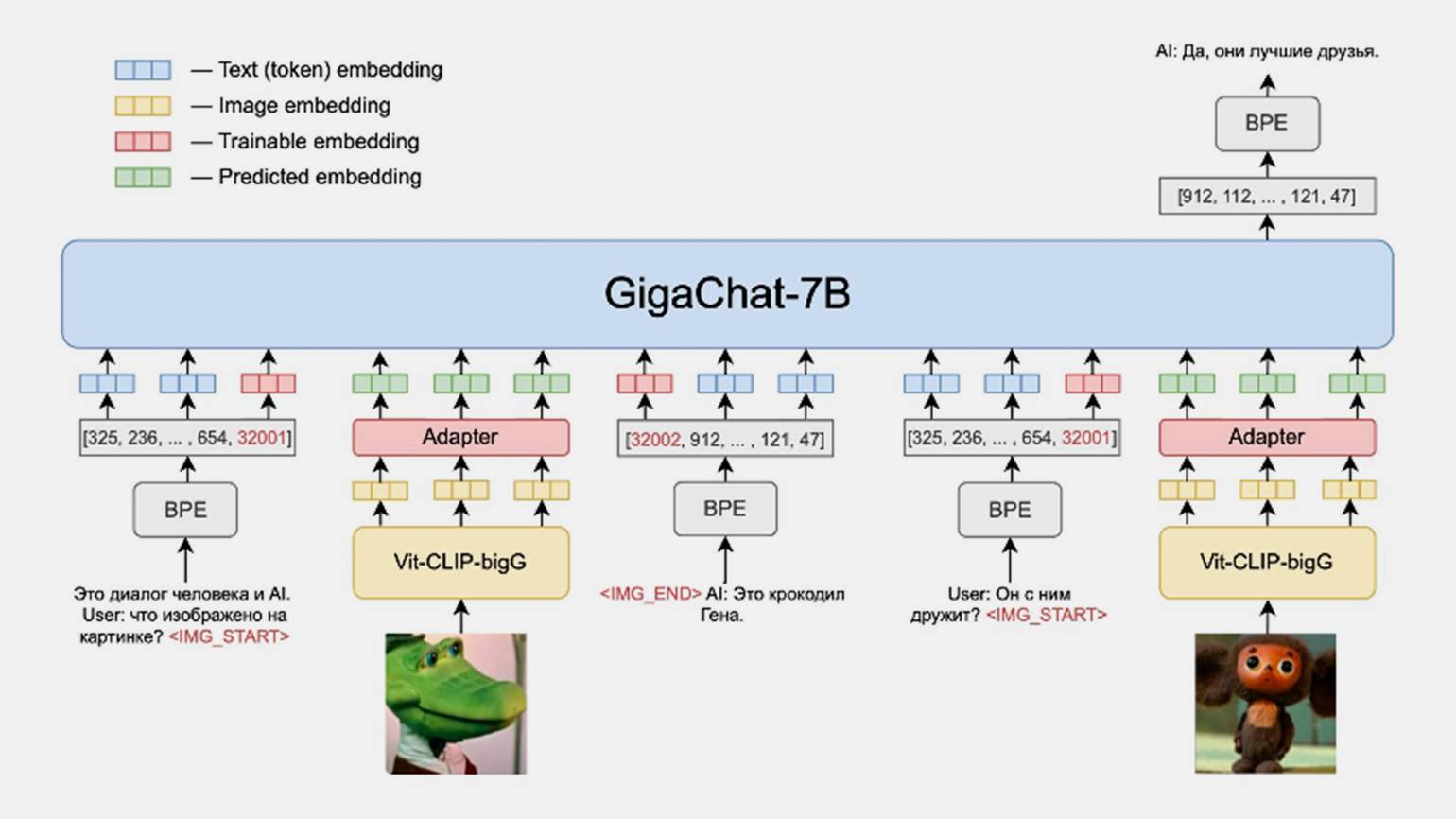
Обучение происходило в два этапа. На первом мы учили нашу систему просто генерировать подписи к картинкам. Набор данных состоял из пар «картинка + подпись». Например, если на картинке нарисован Крокодил Гена, то элемент данных будет состоять из портрета персонажа и краткой подписи — «Крокодил Гена» :)
Такие данные легко собрать, потому что их много в интернете. Мы использовали порядка 600 тысяч сэмплов из открытых наборов плюс использовали наши внутренние наборы данных, которые собирали сами.
На этапе файн-тюнинга мы обучали модель уже не просто генерировать подписи, но и отвечать на вопросы по изображению. Для этого использовались более сложные данные, которые содержали в себе картинку и диалог по этой картинке. Данные брали из открытых англоязычных сетов, переводов этих сетов на русский, сгенерированных синтетических данных с помощью LLM и картинок с подписями, размеченными людьми.
Чтобы проверить качество работы модели, используются другие наборы данных, которые называются бенчмарками. Это наборы тестовых вопросов и ответов по картинке, по которым мы можем понять, как работает модель, измерить качество. Например, в бенчмарке может быть картинка с котиком и вопрос: «Какого цвета кот на изображении?»
Такого рода бенчмарки мы запускали в виде чат-бота в Telegram. Работает просто: отправляете чат-боту картинку и какой-то вопрос по этой картинке, а модель отвечает вам на этот вопрос.


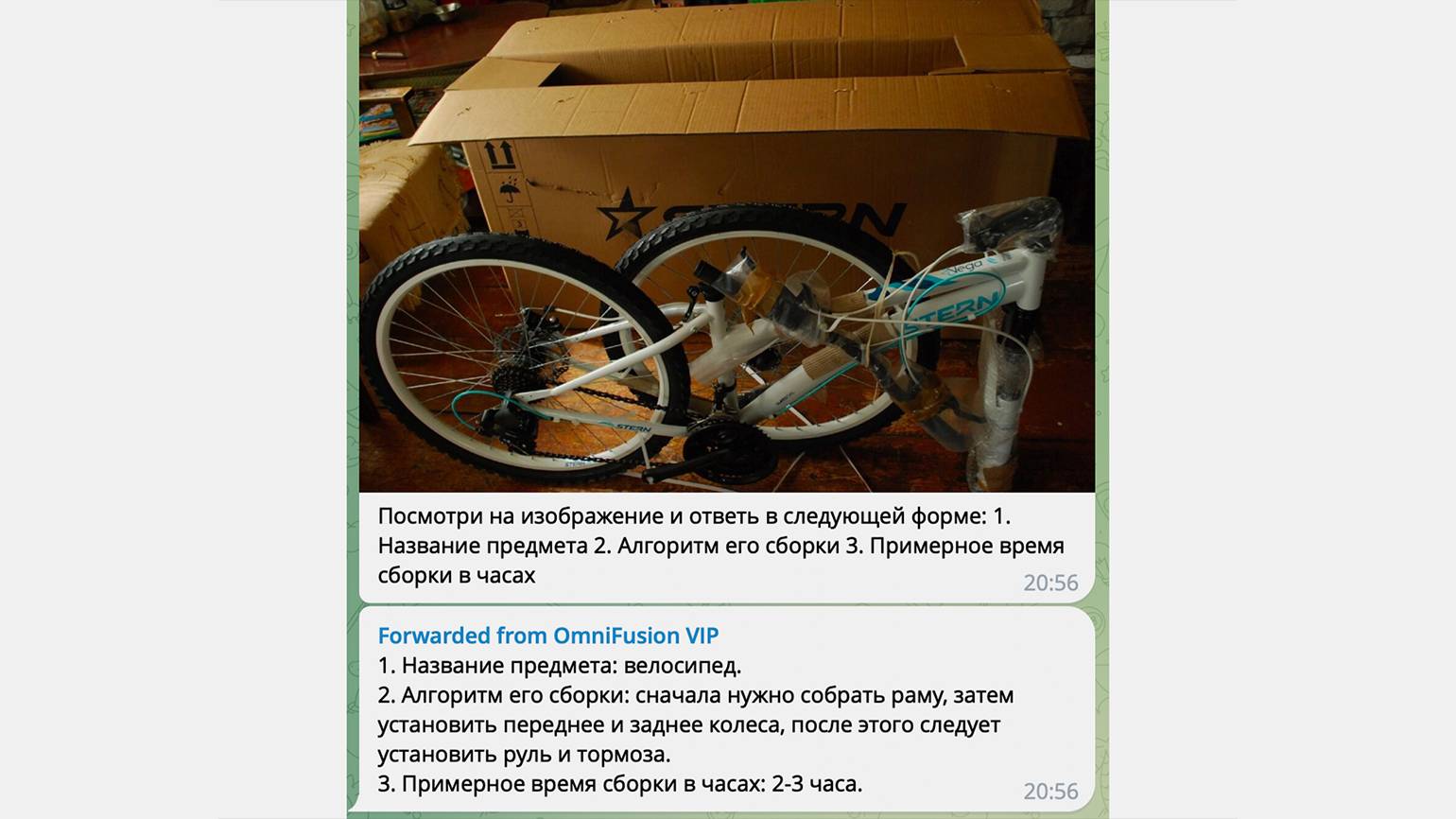
Модель может описывать изображение, рассуждать о том, что происходит на картинке, распознавать города, читать текст на изображении и даже решать капчу. Помимо этого, она неплохо понимает пространственные закономерности: что находится слева, а что справа. Например, описывает расположение планет Солнечной системы.
Однако лучше всего у модели получается решать задачи, связанные с распознаванием текста. Например, в ходе тестов мы отправили модели картинку с формулой и попросили описать, что это за формула.

Ещё был эксперимент, в ходе которого мы целенаправленно учили модель лучше распознавать тексты на картинках. Так у нас случайно возникла интересная функция: можно сделать, например, скриншот новости, и задать по ней вопрос — скажем, попросить кратко рассказать, что случилось.



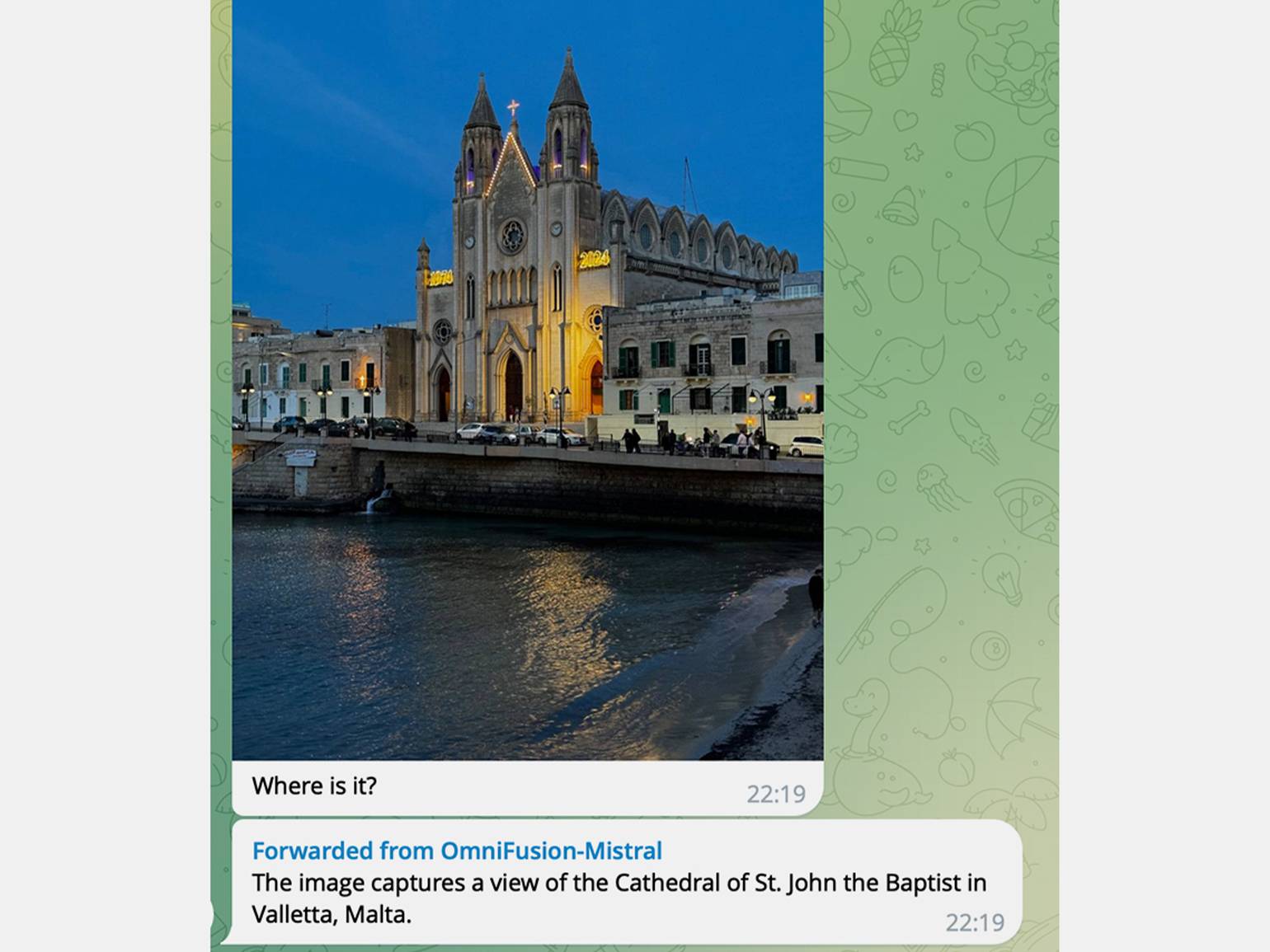
OmniFusion способна даже распознавать местонахождение отдельных зданий!

Что дальше
В будущем мы хотим добавить в модель новые модальности, чтобы она работала не только с картинками, но и с видео и аудио. Сначала хотим сделать так, чтобы модель отвечала на вопросы по аудио и видео — а затем расширить функциональность, чтобы пользователь мог сам генерировать ролик или музыкальный трек.
В похожем направлении сейчас, кстати, развивается GPT-4 от OpenAI. У флагманской нейронки «открытой лаборатории» уже есть возможность задавать вопросы по картинке, генерировать новые изображения и работать с PDF-файлами. Можно загрузить большой PDF-файл и получить ответы на ваши вопросы по нему или краткое описание.
Помимо этого, мы исследуем разные варианты применения нашей модели в робототехнике. Очевидно, что, если обучить модель на нескольких модальностях, у неё будет неплохое представление о мире. Это можно использовать для задач управления роботами и взаимодействия со средой. Например, Google уже представил ИИ RT‑2, предназначенный как раз для управления роботами.
Дополнительная информация
Чтобы лучше понять, как работает модель OmniFusion, рекомендуем вам изучить следующие источники:
- GitHub-профиль проекта OmniFusion
- Страница проекта OmniFusion
- Научная статья про OmniFusion
- Статья на «Хабре» про прошлую версию OmniFusion
- Статья на «Хабре» про новую версию OmniFusion
- Репозиторий проекта на HuggingFace
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!










