Google анонсировал нейросеть Lumiere для генерации видео по текстовому описанию
Модель машинного обучения создаёт реалистичные ролики длиною в пять секунд.

Google представил нейросеть Lumiere, предназначенную для генерации коротких видео. Система может создавать ролики по текстовому описанию или исходному изображению либо изменять в готовом видео только выбранные детали. Код нейросети пока остаётся закрытым.
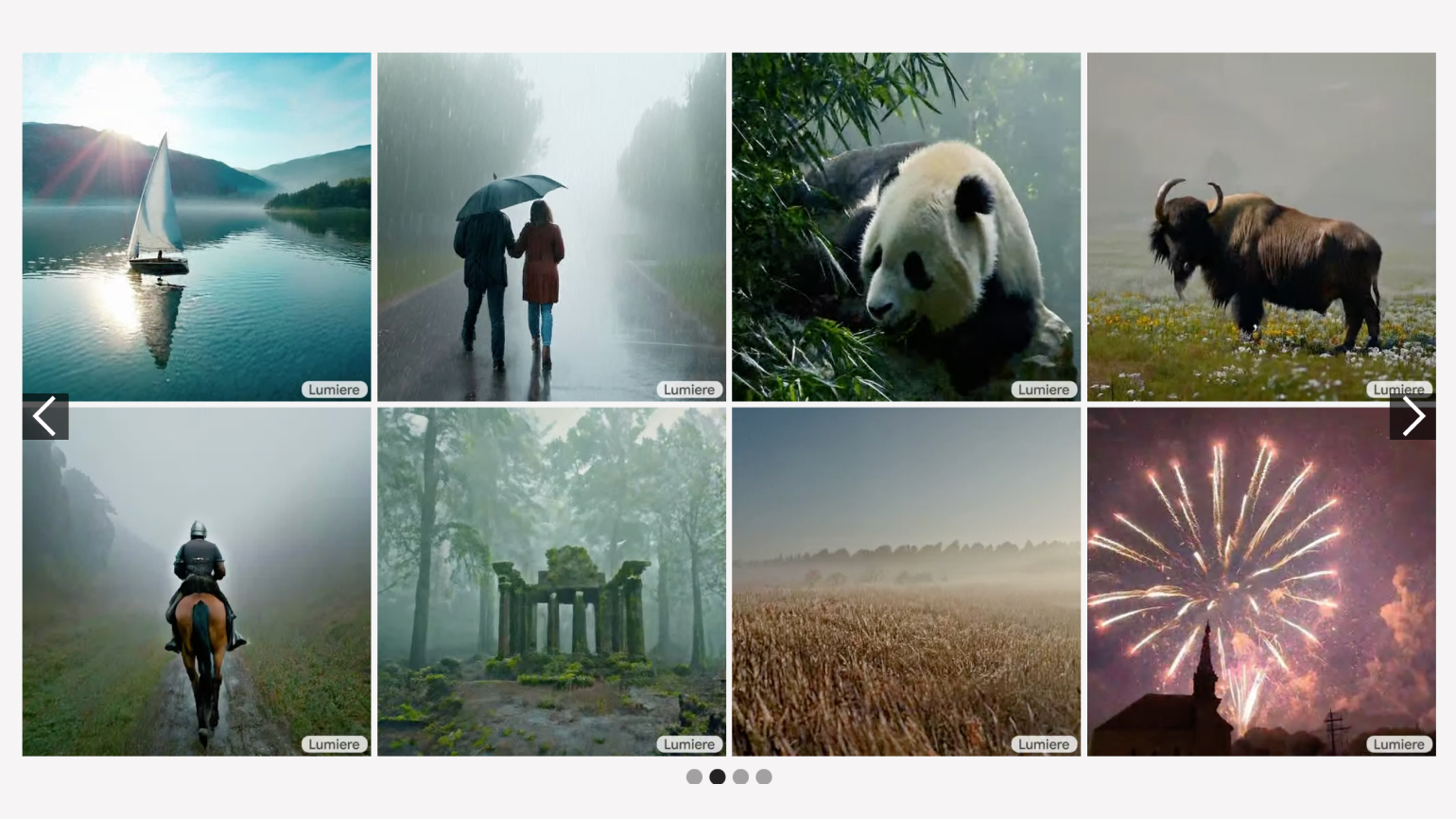
Скриншот: Google / Skillbox Media
Как работает Lumiere
В основе Lumiere лежит модель «пространственно-временной диффузии» (STUNet, Space-Time-U-Net). Её главная особенность в том, что видео генерируется за один проход. Другие решения сначала создают ключевые кадры, а потом заполняют пространство между ними. Из-за этого часто возникают ошибки и несогласование кадров.
Для обучения модели использовали набор данных из 30 млн видеороликов в разрешении 128×128 пикселей, частотой 16 кадров в секунду и продолжительностью в пять секунд. К каждому из них подготовили детально текстовое описание происходящего. Обученная модель создаёт ролики с разрешением 1024×1024 пикселей.
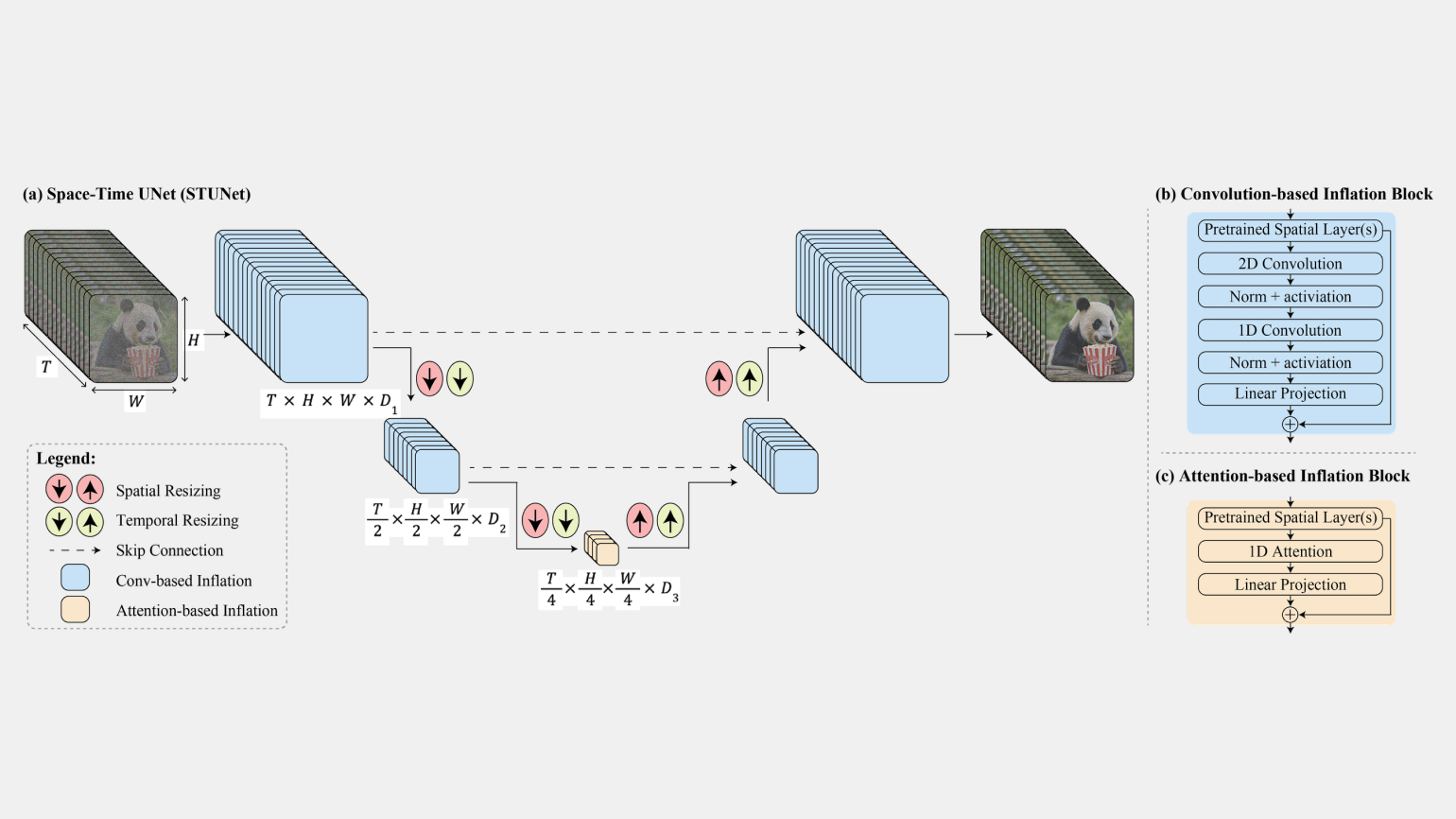
Скриншот: Google / Skillbox Media
Режимы работы
Кроме возможности преобразовывать текст в видео Lumiere оснастили следующими функциями:
- Генерация видео по изображению. Нейросеть использует картинку с текстовым описанием желаемого результата для создания анимации.
- Общий стиль. Lumiere может запомнить художественный стиль промпта и на его основе создавать другие видео.
- Изменения стиля на ходу. В качестве промпта передаётся исходное видео с описанием общего стиля, а на выходе можно попросить сделать объекты в кадре игрушечными или в виде бумажных фигур.
- Анимация только части изображения. На пейзажной фотографии можно анимировать движение облаков.
- Дополнение кадров. Нейросеть дорисовывает объекты в кадрах, основываясь на текстовом описании. Это, например, позволяет добавить шарф человеку, если его не было изначально.
Код Lumiere закрыт, и инженеры Google пока не рассказали о планах сделать модель общедоступной. Пока компания опубликовала только исследование, в котором рассматривается новый метод генерации видео.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!