Что такое Prometheus и как он помогает следить за здоровьем цифровых сервисов
Простое введение для тех, кто знакомится с системами мониторинга.


Наверняка вы хоть раз получали оповещения от МЧС о заморозках, сильном ветре или тумане. Эти предупреждения формируются на основе данных метеорологических систем мониторинга, которые отслеживают погодные условия в реальном времени. Подобные системы используются и в IT-сфере для контроля работоспособности серверов, приложений и инфраструктуры.
Одна из самых популярных таких систем — Prometheus. В этой статье мы разберём её устройство, принципы работы и особенности использования.
Содержание
Что такое Prometheus
Prometheus — это система мониторинга и оповещения с открытым исходным кодом, которая в реальном времени собирает и анализирует метрики работы приложений и серверов. Название системы происходит от титана Прометея из греческой мифологии, который подарил людям огонь. Подобно своему тёзке, Prometheus «освещает» работу IT-систем — помогает администраторам следить за процессами и быстро реагировать на возникающие проблемы.
Представьте интернет-магазин, который находится под наблюдением Prometheus. Система отслеживает количество посетителей, среднюю скорость загрузки страниц, частоту критических ошибок и другие метрики. Если происходит что-то необычное — например, во время распродажи резко возрастает поток покупателей — Prometheus тут же оповещает администратора, чтобы тот мог предотвратить сбои в работе магазина.
История Prometheus началась в 2012 году в компании SoundCloud, когда произошёл переход на микросервисную архитектуру — подход, при котором приложение разбивается на множество небольших, независимых сервисов. Тогдашние инструменты мониторинга не справлялись с отслеживанием такого большого количества сервисов, особенно когда их число постоянно менялось из-за масштабирования системы. В результате команда SoundCloud создала Prometheus — собственный инструмент мониторинга, разработанный специально для современных распределённых систем.
В 2016 году Prometheus вошёл в состав Cloud Native Computing Foundation (CNCF) и стал вторым после Kubernetes проектом в этой организации. Поддержка CNCF позволила Prometheus быстро развиться и стать одним из самых популярных инструментов мониторинга для облачных систем.

Как работает Prometheus
Процесс мониторинга в Prometheus включает несколько основных этапов: сбор метрик, хранение данных и обработку полученных запросов.
Сбор метрик. На этом этапе Prometheus по заданному расписанию опрашивает настроенные точки мониторинга через HTTP-эндпойнты и собирает числовые показатели их работы. Например, каждые 15 секунд система получает данные о загрузке процессора, объёме используемой памяти, количестве активных пользователей, времени отклика сервера, сетевых задержках и других ключевых параметрах производительности.
Хранение данных. Все собранные показатели Prometheus сохраняет в специализированной временной базе данных (TSDB). Эта база организована как таблица с двумя колонками: временем измерения и значением метрики. Например, каждые 15 секунд Prometheus записывает использование памяти сервера: в 17:00 — 80%, в 17:00:15 — 82%. Такая структура позволяет легко отслеживать изменения показателей за любой выбранный период.
Если выражаться более техническим языком, Prometheus хранит метрики в формате временных рядов — это структура данных, похожая на таблицу, где каждая запись включает значение метрики и время измерения. Также к метрикам можно добавлять специальные метки (labels) — дополнительную информацию для более точной идентификации и классификации данных.
Например, когда мы измеряем количество HTTP-запросов метрикой http_requests_total, мы добавляем метки method (GET для получения данных или POST для отправки) и endpoint (конкретный адрес запроса). Это похоже на маркировку папок с документами — вместо простой надписи «Документы» мы указываем «Документы по проекту X за 2025 год». Такая детальная маркировка позволяет быстро находить нужную информацию.
Обработка запросов. После сохранения метрик во временной базе (TSDB) администратор приступает к настройке мониторинга:
- Создаёт запросы на языке PromQL для извлечения и анализа данных. Например, можно написать запрос rate(http_requests_total[1h]) для подсчёта среднего количества HTTP-запросов за последний час или count(error_count > 0) для отслеживания числа ошибок в минуту.
- Настраивает информативные панели мониторинга (дашборды) в Grafana или других системах визуализации. На этих панелях в виде графиков и диаграмм отображаются основные показатели работы системы, что помогает быстро замечать проблемы и изменения.
- Выставляет пороговые значения для ключевых метрик в Alertmanager — системе оповещений Prometheus. Например, если загрузка процессора превышает 90% более пяти минут, система должна отправить SMS дежурному администратору. Или, если число HTTP-ошибок превысит десять в минуту, — предупредить всю команду через Telegram.
После завершения настройки Prometheus переходит в автоматический режим: он регулярно собирает метрики, анализирует данные по заданным правилам и отправляет уведомления при обнаружении нарушений.
Основные компоненты архитектуры Prometheus
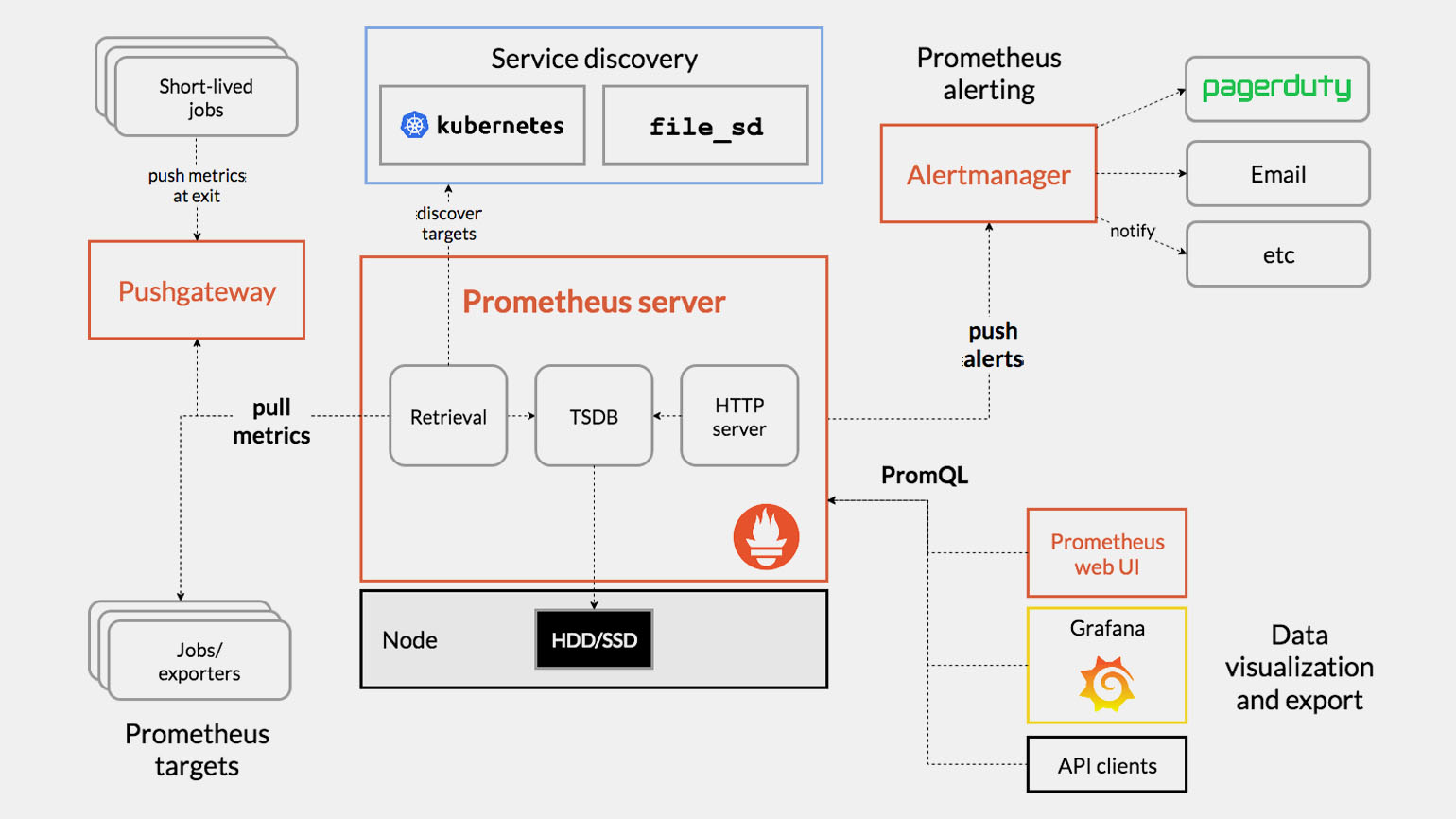
Prometheus server — центральный элемент системы мониторинга. Он выполняет рад задач:
- собирает метрики с серверов и приложений (Retrieval);
- хранит их в базе (TSDB);
- позволяет выполнять запросы через HTTP (HTTP server).
Service discovery — автоматически обнаруживает сервисы для мониторинга. Например, в Kubernetes или через файлы конфигурации.
Alertmanager — управляет системой оповещения и отправляет уведомления при сбоях.
Источники метрик (targets)
- Exporters — собирают метрики из сервисов (например, MySQL, Redis).
- Short-lived jobs — передают данные через Pushgateway.
- Node Exporter — отправляет системные метрики (нагрузка на CPU, использование дисков HDD/SSD и так далее).
Инструменты визуализации
- Prometheus Web UI — базовый интерфейс для просмотра данных.
- Grafana — создаёт дашборды и графики.
- API Clients — позволяют интегрировать Prometheus с другими приложениями.
Как пользоваться Prometheus
Для начала перейдите на сайт prometheus.io и скачайте актуальную версию приложения для вашей операционной системы. После этого распакуйте архив и запустите исполняемый файл prometheus.exe. В результате вы должны увидеть командную строку с логами сервера, информацией о загрузке конфигурации, инициализации компонентов и сборе метрик.
Эти логи нужны для отладки и мониторинга работы Prometheus. Не закрывайте окно командной строки — это основной процесс, который должен работать в фоновом режиме. При закрытии окна сервер остановится.
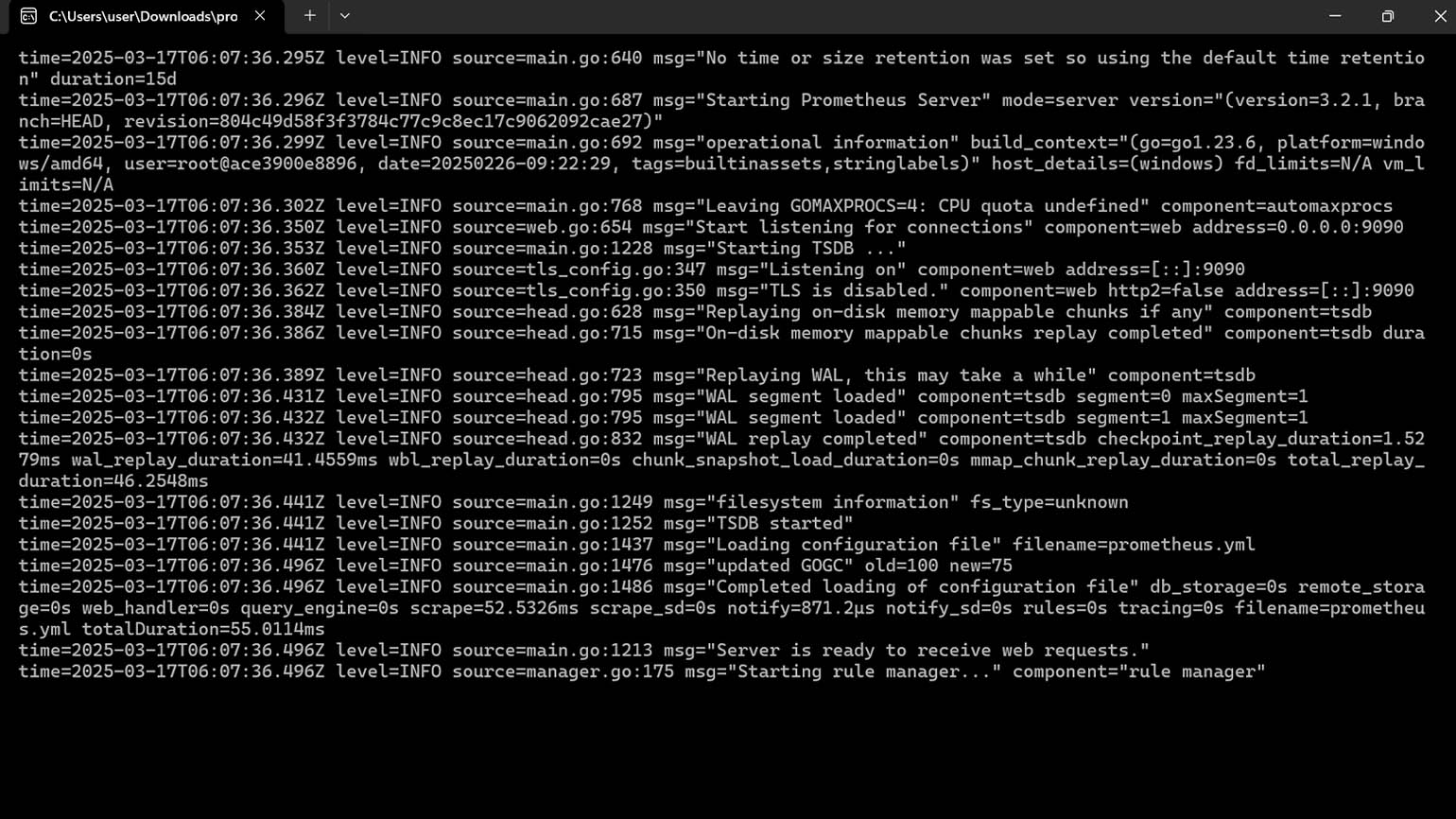
Скриншот: командная строка Windows / Skillbox Media
Теперь откройте в браузере адрес http://localhost:9090. Если всё корректно работает, перед вами должен появиться веб-интерфейс Prometheus:
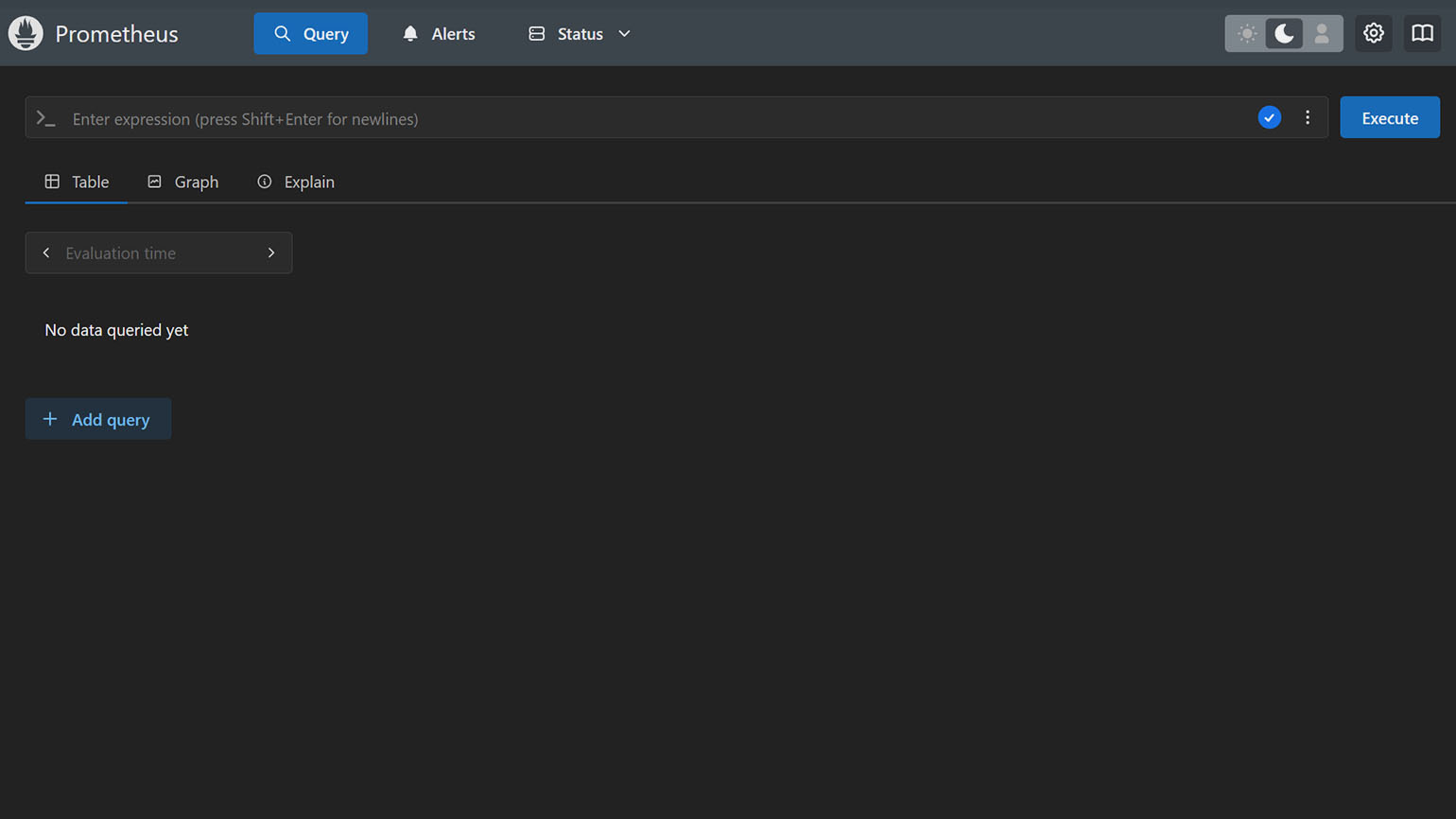
Скриншот: Prometheus / Skillbox Media
Следующий шаг — выбор объекта для мониторинга. Это может быть веб-сервер, база данных или операционная система. Кроме того, вам потребуется экспортер — специальный инструмент, который собирает метрики с сервиса и преобразует их в формат, понятный для Prometheus.
Самый простой способ начать — установить Node Exporter для Linux и macOS или Windows Exporter. После настройки экспортера Prometheus начнёт собирать основные метрики компьютера: загрузку процессора, сетевой трафик, использование памяти, состояние дисков и другие показатели.
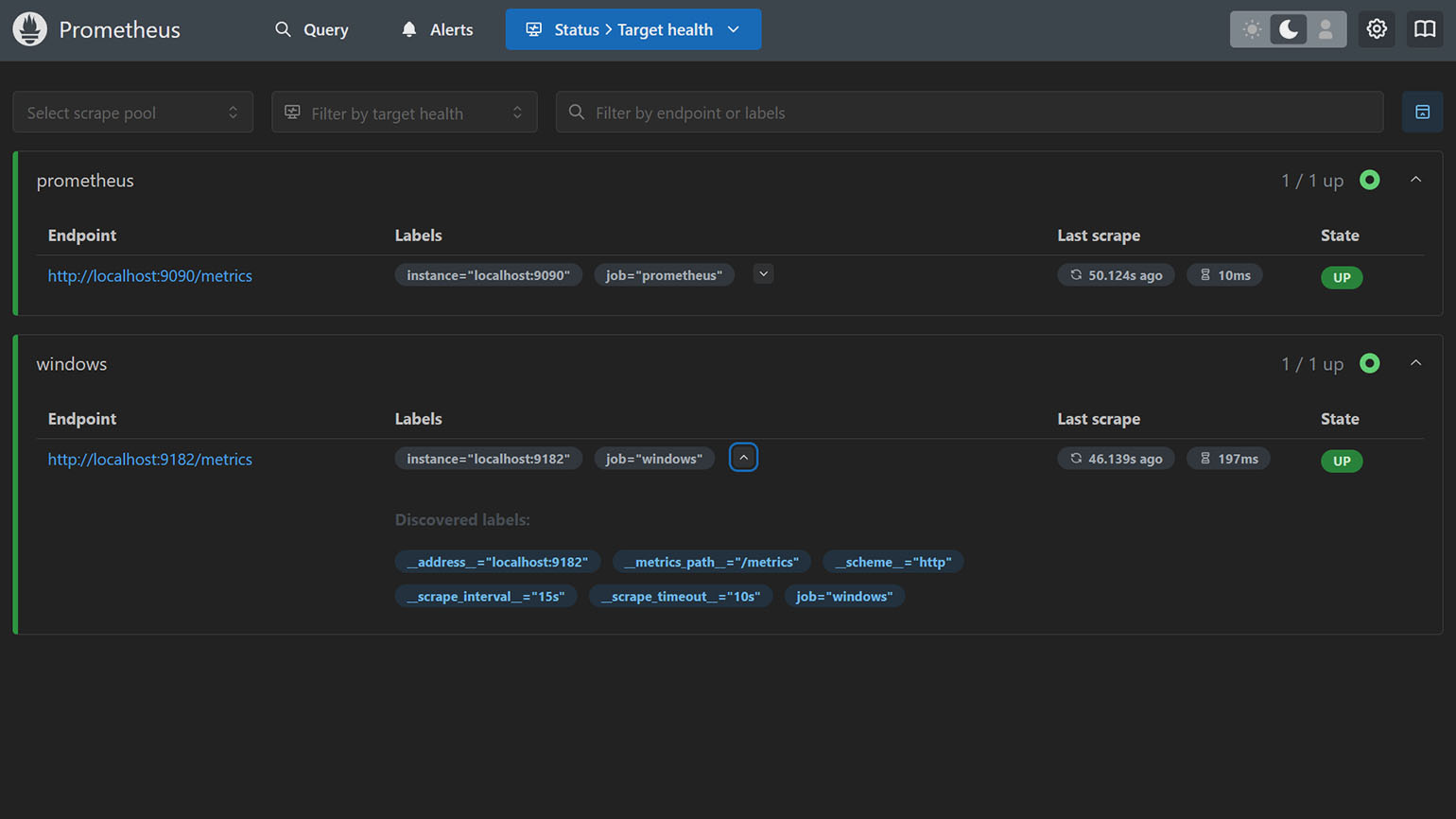
Скриншот: Prometheus / Skillbox Media
После добавления экспортера в Prometheus вы сможете анализировать данные с помощью языка запросов PromQL и встроенных инструментов визуализации. Например, чтобы отследить изменение загрузки процессора в пользовательском режиме за последние пять минут, введите следующий запрос:
rate(windows_cpu_time_total{mode="user"}[5m])Затем перейдите на вкладку Graph, чтобы увидеть результаты в виде графика. В этом режиме вам доступны настройки временного диапазона и других параметров визуализации для детального анализа данных:
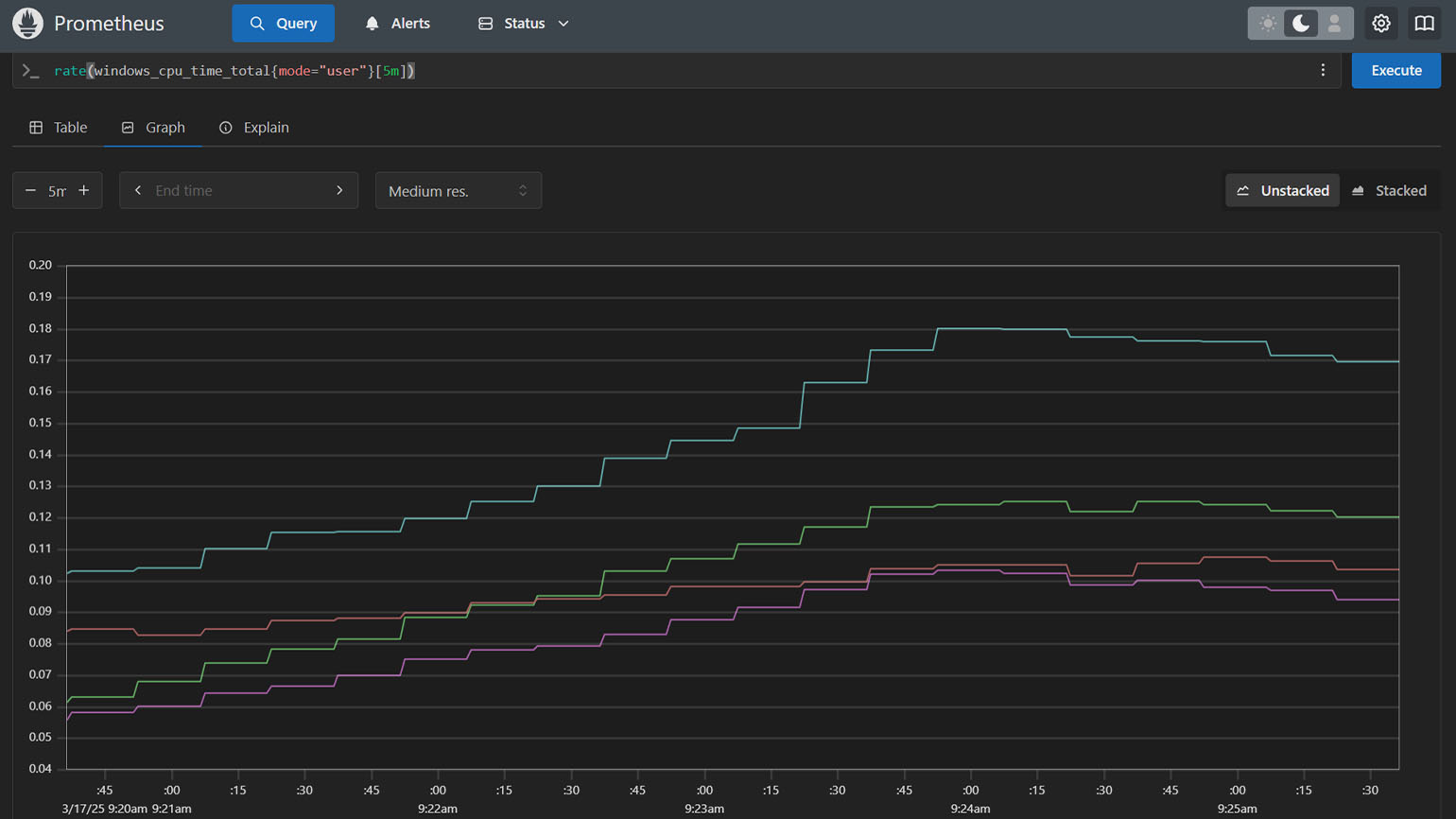
Скриншот: Prometheus / Skillbox Media
После основ вы можете перейти к более продвинутым возможностям: настройке сложных запросов, подключению Grafana для более наглядной визуализации и использованию других инструментов мониторинга. Вот полезные ресурсы для углублённого самостоятельного изучения:
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!