Что такое ASCII: полное руководство для начинающих
Рассказываем про дедушку всех кодировок текста.


Люди привыкли общаться словами, составленными из букв, а компьютеры понимают только последовательности нулей и единиц. Но к счастью, нам не приходится вводить команды в виде бинарного кода. Это стало возможным благодаря системам кодировки, которые сопоставляют символы — буквы, цифры, знаки препинания — с двоичными комбинациями. Одной из первых таких универсальных систем стала ASCII. В статье расскажем, как она устроена и где применяется.
Содержание
- Что такое таблица ASCII
- Как создавалась ASCII
- Структура и код ASCII
- Что такое расширенная таблица ASCII
- Что такое Unicode и UTF-8
- Как узнать код символа или получить символ по коду
- Как набрать символ по его ASCII-коду
- Как использовать ASCII в программировании
Что такое таблица ASCII
ASCII (от англ. American Standard Code for Information Interchange) — стандарт представления текстовых символов в цифровом виде. Он появился в США в 1960-х, когда инженерам нужно было научиться передавать текст между устройствами, которые понимали только нули и единицы.
Идея была простой: каждому символу — своё число. Буквы латинского алфавита, цифры, знаки препинания и даже управляющие символы вроде перевода строки (\n) или табуляции (\t) получили уникальные числовые коды от 0 до 127.
Так выглядит классическая таблица ASCII:
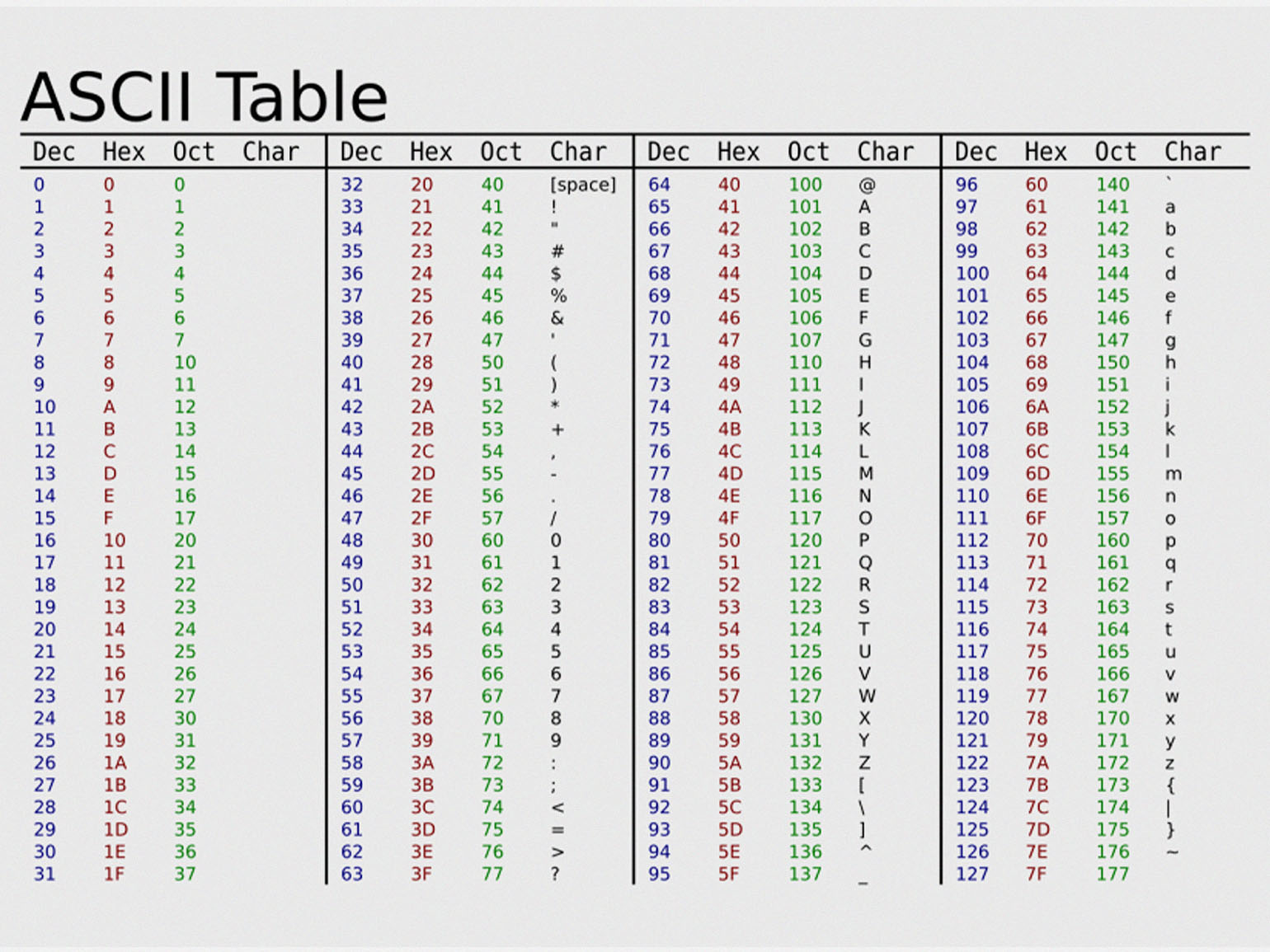
Изображение: wukong / Wikimedia Commons
ASCII стала универсальным «переводчиком» между человеком и машиной. Одни и те же байты означали одни и те же символы на любой платформе, что позволяло компьютерам считывать и выводить текст без системных ошибок. Со временем стандарт закрепился в протоколах и форматах, а в современной кодировке UTF-8 первые 128 символов полностью совпадают с ASCII.
Как создавалась ASCII
В начале 1960-х каждая компания, выпускавшая телетайпы, компьютеры или коммуникационное оборудование, использовала собственные таблицы кодов. Один и тот же символ мог обозначаться по-разному: например, буква A на одной машине имела код 41, а на другой — 91. Из-за этого при обмене данными устройства буквально «разговаривали» на разных языках.
Чтобы устранить хаос, Американский национальный институт стандартов (ANSI) создал рабочую группу во главе с инженером Бобом Бемером. Задачей команды было разработать единый набор символов, который понимали бы все устройства.
Новый стандарт должен был отвечать трём условиям:
- быть компактным, чтобы данные легко передавались по каналам связи;
- включать буквы, цифры, знаки препинания и управляющие коды;
- оставаться совместимым с телетайпами и терминалами.

Читайте также:
Рабочая группа собирала предложения от производителей телетайпов и компьютеров, телекоммуникационных компаний и даже правительственных структур. В итоге инженеры остановились на 7-битной кодировке, которая позволяла закодировать 128 символов.
В других вопросах инженеры не сразу сошлись во мнениях. Одни предлагали расположить строчные и заглавные буквы рядом, другие настаивали, что первые коды должны быть зарезервированы за управляющими символами. Обсуждали даже порядок алфавита и необходимость включения некоторых «редких» знаков.
Особо примечательным оказалось предложение Бобa Бемера добавить escape-символ (ESC). Изначально его сочли странным, но со временем ESC стал одним из ключевых элементов: он позволял терминалам отличать текст от команд, очищать экран, перемещать курсор и менять формат вывода.
Первая версия таблицы вышла в 1963 году под названием ANSI X3.4. В 1967–1968 годах её доработали, уточнив порядок символов и поведение некоторых кодов. После этого ASCII быстро вышел за пределы США и превратился в мировой стандарт. Его стали использовать в протоколах связи, операционных системах, компиляторах и языках программирования.
Структура и код ASCII
Таблица ASCII выглядит очень просто. В ней всего 128 символов, каждому из которых соответствует уникальное число от 0 до 127. Но за этой простотой стоит продуманная инженерная логика.
Каждому символу в таблице отводится ровно 7 бит. Это не случайное число, а строго рассчитанное: именно столько комбинаций (от 0000000 до 1111111) нужно, чтобы закодировать 128 значений.
В 1960-е годы инженеры старались экономить каждый бит. Уже появлялись 8-битные системы, но разработчики ASCII сознательно оставили один бит «свободным». В то время его часто использовали для проверки чётности или других служебных функций.

Читайте также:
Давай те детально рассмотрим, какие символы есть в ASCII-таблице и в каком порядке они идут.
Управляющие символы (коды 0–31 и 127)
Коды от 0 до 31 и 127 зарезервированы под непечатные символы. Их нельзя увидеть на экране, но они выполняют команды для устройств ввода-вывода или форматирования текста. Большинство таких кодов пришло из эпохи телетайпов — например, «возврат каретки» действительно возвращал печатающую головку в начало строки.
Примеры управляющих символов:
- 0 — NUL, «пустой символ», чаще всего обозначает конец строки.
- 10 — LF, перевод строки.
- 13 — CR, возврат каретки.
- 27 — ESC, escape-символ, применяется для управляющих последовательностей в терминалах.
- 127 — DEL, символ удаления.
Сегодня они редко используются напрямую, но всё ещё встречаются в протоколах, терминальных интерфейсах и форматах передачи данных.
Печатаемые символы (коды 32–126)
Начиная с кода 32, в таблице идут печатаемые символы — те, что можно увидеть в тексте. Они расположены логично и группами:
| Диапазон | Символы |
|---|---|
| 32 | Пробел (space) |
| 33-47 | Знаки препинания и спецсимволы: ! " # $ % & ’ ( ) * + , - . / |
| 48-57 | Цифры: 0–9 |
| 58-64 | Спецсимволы: : ; < = > ? @ |
| 65-90 | Заглавные латинские буквы: A—Z |
| 91-96 | Скобки и акценты: ` [ \ ] ^ _ `` |
| 97-122 | Строчные латинские буквы: a—z |
| 123-126 | Дополнительные символы: { | } ~ |
Благодаря последовательному расположению букв алфавита их удобно обрабатывать в коде. Например, вывести английский алфавит в Python можно всего одним циклом for:
for code in range(65, 91): # A-Z
print(chr(code), end=' ') # → A B C ... ZРазница между заглавной и строчной буквой — ровно 32. Так, код заглавной буквы A равен 65, а чтобы узнать номер строчной, надо к 65 прибавить 32: 65 + 32 = 97. Это свойство можно использовать в коде для быстрой смены регистра символов.
Расширенная таблица ASCII
Базовый ASCII включает лишь 128 символов: латинский алфавит, арабские цифры, знаки препинания и управляющие коды. Для английского этого хватало, но для большинства европейских и тем более нелатинских языков — уже нет.
Чтобы восполнить пробелы, разработчики начали использовать восьмой бит, который изначально не задействовали. Так появились расширенные таблицы: диапазон 0–127 повторял классический ASCII, а коды 128–255 отводились под новые символы.
Ниже список популярных расширений ASCII:
- Windows-1251 — набор кириллических символов в Windows. Его использовали до появления UTF-8.
- ISO 8859-1 (Latin-1) — расширение для французского, польского, немецкого, испанского и других языков, использующих латиницу.
- ISO 8859-2 (Latin-2) — набор для польского, чешского, хорватского и других центральноевропейских языков.
- Windows-1252 (или ANSI Latin 1) — расширение, построенное на базе ISO 8859-1, но с добавлением специальных символов € , ”. Его использовали в англоязычной версии Windows.
- CP437 — кодировка MS-DOS, которая содержит английские символы и псевдографику: рамки, уголки, блоки, стрелки. Раньше этот стандарт использовали для создания интерфейсов в DOS-программах.
- CP866 — кириллическая версия CP437.
В чём проблема
Расширенные таблицы решили вопрос нехватки символов, но породили новую проблему — несовместимость кодировок.
Если вы пользовались компьютером лет 10–15 назад, то наверняка сталкивались с «кракозябрами» вместо текста. Это происходило, когда файл создавался в одной кодировке, а открывался в другой: нумерация символов в таблицах не совпадала.
Именно эту проблему окончательно решил стандарт Unicode, который стал универсальной кодировкой для всех языков и символов.
Unicode и UTF-8: как компьютеры научились понимать все языки мира
В 1990-х, чтобы решить проблему множества несовместимых кодировок, инженеры придумали стандарт Unicode. Он присваивает каждому символу уникальный номер независимо от языка и платформы.
Сегодня в Unicode более 150 тысяч символов: буквы всех языков мира, эмодзи, символы валют, математические знаки и даже символы древних письменностей. Номер каждого символа состоит из префикса U+ и числа в шестнадцатеричном формате:
- A → U+0041;
- а → U+0430;
- € → U+20AC;
 → U+1F604.
→ U+1F604.
Однако Unicode лишь описывает символы и их номера, но не определяет способ хранения в памяти. Для этого существуют форматы кодирования: UTF-8, UTF-16 и UTF-32. Сегодня почти все сайты и приложения используют UTF-8.
Сам формат в 1992 году предложили разработчики Кен Томпсон и Роб Пайк. Для каждого Unicode-символа в UTF-8 выделяется от 1 до 4 байтов. Например, для латиницы и цифр достаточно одного байта, так как номера этих символов совпадают с ASCII, а для современных эмодзи требуется уже 4 байта:
- A → 01000001 (1 байт)
- € → 11100010 10000010 10101100 (3 байта)
 → 11110000 10011111 10011000 10000000 (4 байта)
→ 11110000 10011111 10011000 10000000 (4 байта)
Благодаря UTF-8 компьютеры смогли корректно отображать все символы мира — от латиницы до современных эмодзи.
Как узнать код символа или получить символ по коду
Иногда при отладке полезно заглянуть «под капот» текста и узнать, какой код у символа, во что он превращается в байтах и как из числа снова получить букву. Для этого есть несколько приёмов.
Ручная проверка
Если нужный символ находится в диапазоне от 0 до 127, то можно просто заглянуть в ASCII-таблицу. Базовая таблица есть даже в этой статье, а расширенную можно найти на портале ASCII Code.
Windows
В Windows есть платформа PowerShell, которая умеет напрямую конвертировать символы и коды:
# Узнать код символа (Unicode code point)
[int][char]'A' # 65
[int][char]'€' # 8364
# Узнать символ по коду (code point)
[char]65 # 'A'
[char]0x20AC # '€'
Читайте также:
В Linux или macOS
В Unix-подобных системах, таких как Linux и macOS, тоже есть стандартные утилиты для работы с кодировками:
- Узнать байты символа можно с помощью echo. В ответ система выведет шестнадцатеричный ASCII-код:
echo -n "A" | xxd -p # 41
echo -n "€" | xxd -p # e282ac- Символ по коду можно вывести в терминал с помощью printf:
printf '\x41\n' # A
printf '\xE2\x82\xAC\n' # €- Десятичный код символа также можно узнать с помощью printf:
printf '%d\n' "'A" # 65
Читайте также:
Как набрать символ по его ASCII-коду
Иногда нужно ввести символ, которого нет на клавиатуре: знак копирайта, греческую букву, валюту или спецсимвол. В Windows для этого есть система Alt-кодов — способ ввода символов по их числовому коду.
Как использовать Alt-код:
- Убедитесь, что включена функция Num Lock. Если включена, то на клавиатуре должен гореть светодиод Num.
- Зажмите клавишу Alt.
- На цифровой клавиатуре (справа) введите код символа.
- Отпустите Alt — символ появится.
Alt-коды от 0 до 127 — это классический набор ASCII, коды от 128 до 255 — расширенная таблица, включающая символы с диакритиками, графику, валюты:
- A — Alt + 65;
- © — Alt + 0169;
- ± — Alt + 0177;
- ™ — Alt + 0153;
- ø — Alt + 0248.
В Windows есть и другие способы ввода нестандартных символов:
- Таблица символов. Нажмите Win + R, введите charmap → Enter. Откроется таблица символов: можно выбрать нужный, скопировать и вставить его в текст.
- Меню эмодзи и спецсимволов. нажмите Win + . (точка). Появится встроенное меню с эмодзи, символами валют и математическими знаками.
Как использовать ASCII в программировании
Даже после появления Unicode таблица ASCII остаётся важным инструментом для обработки текста с помощью кода. С её помощью можно:
- искать фрагменты текста, сортировать и фильтровать символы;
- парсить данные, форматировать данные и разбирать протоколы;
- шифровать информацию и работать с ней на бинарном уровне;
- реализовывать символьные операции — например, преобразовывать строки и менять регистр.
Почти во всех языках программирования есть встроенные функции для получения ASCII-кода символа и обратного преобразования. Рассмотрим на примере Python:
- Базовые операции для получения кода символа и символа по коду:
printf '%d\n' "'A" # 65- Преобразование строки в список кодов и обратно:
text = "I like ASCII"
# Строка -> список ASCII-кодов
codes = [ord(c) for c in text]
print(codes)
# [73, 32, 108, 105, 107, 101, 32, 65, 83, 67, 73, 73]
# Список кодов -> строка
restored = ''.join(chr(c) for c in codes)
print(restored)
# "I like ASCII"- Сортировка строк по ASCII-кодам:
s = "I like ASCII"
sorted_s = ''.join(sorted(s))
print(sorted_s)
# " ACIIISeikl"
Читайте также:
Самое важное
- ASCII — это стандарт для цифрового представления текстовых символов. С его помощью компьютеры кодируют буквы, цифры, знаки препинания и управляющие символы.
- Первая версия ASCII появилась в 1963 году и включала всего 128 символов. Она стала универсальным «языком» для обмена текстом между устройствами.
- Со временем стандарт вырос в Unicode, который охватывает более 150 тысяч символов: буквы всех языков мира, эмодзи, символы валют, математические и древние знаки.
- ASCII и Unicode используются для обработки текста, передачи данных и шифрования. Например, на основе таблицы ASCII легко написать алгоритм для перевода строчных букв в прописные и обратно или реализовать другие операции с символами.
- Стандарты кодирования, такие как UTF-8, позволяют корректно хранить и передавать все символы Unicode в памяти компьютера и по сети.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!







