GitHub улучшил технологию поиска кода
Быстрый поиск — залог продуктивности разработчика.

8 декабря 2021 года компания GitHub объявила о выходе технологии улучшенного поиска, которая поможет быстрее исследовать код и концентрироваться на проекте:

«Разработчику сложно оставаться в состоянии потока. Всякий раз, когда вы смотрите, как использовать библиотеку, или когда тест провалился из-за того, что ваша среда разработки отличается от CI, или когда вам нужно выяснить, из-за чего возникло сообщение об ошибке, вы прерываетесь. Чем больше времени потребуется на устранение помехи, тем больше контекста вы потеряете.
Что касается поиска кода, наше ви́дение состоит в том, чтобы помочь каждому разработчику искать и открывать код, ориентироваться в нём и понимать его быстро и интуитивно. Благодаря поиску кода на GitHub весь код мира всегда у вас под рукой — на расстоянии одного поискового запроса».
ПАВЕЛ АВГУСТИНОВ, сотрудник GitHub
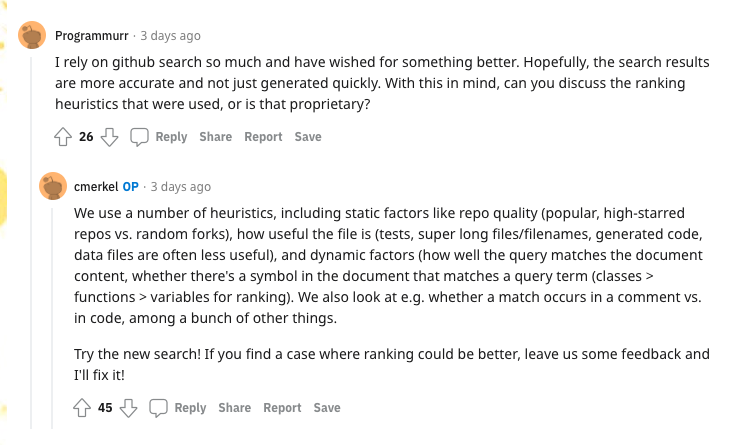
В обновлённую систему разработчики добавили интеллектуальное ранжирование, выдачу результатов по строкам, регулярным выражением и спецсимволам, а также множество дополнительных фильтров для расширенного поиска фрагментов кода.
Сейчас GitHub тестирует технологию и приглашает желающих оценить улучшенный поиск. Для этого нужно перейти на сайт cs.github.com и отправить заявку на участие.
На Reddit большинство разработчиков положительно отреагировало на новость. Оний считают поиск на GitHub полезным инструментом, который пригодится в работе.
Merry_Macabre: «Наконец-то правильная навигация по коду на GitHub. Старый способ — это такая боль, и он не всегда регистрирует определения функций, а необходимость перебирать все результаты поиска в большом проекте — это утомительно».
jantari: «Старый поиск и раньше на световые годы опережал GitLab, да и вообще никакого глобального поиска кода нет… но это просто круто!»
Programmurr: «Я сильно полагаюсь на поиск по GitHub и хотел чего-то лучшего. Надеюсь, результаты поиска будут более точными, а не просто быстрыми. Имея это в виду, можете ли вы рассказать про использованные эвристики ранжирования или это закрытая информация?»
Cmerkel: «Мы используем ряд эвристик, включая статические факторы, такие как качество репо (популярный это репозиторий с высокими оценками или случайный форк), полезность файла (тесты, сверхдлинные файлы или файлы со сверхдлинными именами, сгенерированный код, файлы данных часто менее полезны) и динамические факторы (насколько хорошо запрос соответствует содержимому документа, есть ли в документе символы, соответствующие терминам запроса: классы → функции → переменные для ранжирования). Мы также смотрим, например, есть ли совпадение в комментарии или в коде, среди множества других вещей.
Попробуйте новый поиск! Если вы найдёте случай, когда рейтинг может быть лучше, оставьте нам отзыв, и я исправлю это!»